VShard — horizontal scaling in Tarantool
Hi, my name is Vladislav, and I am a member of the Tarantool development team. Tarantool is a DBMS and an application server all in one. Today I am going to tell the story of how we implemented horizontal scaling in Tarantool by means of the VShard module.
Some basic knowledge first.
There are two types of scaling: horizontal and vertical. And there are two types of horizontal scaling: replication and sharding. Replication ensures computational scaling whereas sharding is used for data scaling.
Sharding is also subdivided into two types: range-based sharding and hash-based sharding.
Range-based sharding implies that some shard key is computed for each cluster record. The shard keys are projected onto a straight line that is separated into ranges and allocated to different physical nodes.
Hash-based sharding is less complicated: a hash function is calculated for each record in a cluster; records with the same hash function are allocated to the same physical node.
I will focus on horizontal scaling using hash-based sharding.
Older implementation
Tarantool Shard was our original module for horizontal scaling. It used simple hash-based sharding and calculated shard keys by primary key for all records in a cluster.
function shard_function(primary_key)
return guava(crc32(primary_key), shard_count)
end
But eventually Tarantool Shard became unable to tackle new tasks.
First, one of our eventual requirements became the guaranteed locality of logically related data. In other words, when we have logically related data, we always want to store it on a single physical node, regardless of cluster topology and balancing changes. Tarantool Shard cannot guarantee that. It calculated hashes only with primary keys, and so rebalancing could cause the temporary separation of records with the same hash because the changes are not carried out atomically.
This lack of data locality was the main problem for us. Here is an example. Say there is a bank where a customer has opened an account. The information about the account and the customer should be stored physically together so that it can be retrieved in a single request or changed in a single transaction, e.g. during a money transfer. If we use the traditional sharding of Tarantool Shard, there will be different hash function values for accounts and customers. The data could end up on separate physical nodes. This really complicates both reading and transacting with a customer«s data.
format = {{'id', 'unsigned'},
{'email', 'string'}}
box.schema.create_space('customer', {format = format})
format = {{'id', 'unsigned'},
{'customer_id', 'unsigned'},
{'balance', 'number'}}
box.schema.create_space('account', {format = format})
In the example above, the id fields of the accounts and the customer can be inconsistent. They are connected by the customer_id field of the account and the id field of the customer. The same id field would violate the uniqueness constraint of the account primary key. And Shard cannot perform sharding in any other way.
Another problem was slow resharding, which is the fundamental problem of all hash shards. The bottom line is that when changing cluster components, the shard function changes because it usually depends on the number of nodes. So when the function changes, it’s necessary to go through all the records in the cluster and recalculate the function. It may also be necessary to transfer some records. And during data transfer, we don’t even know if the required record? In the request data has already been transferred or is being transferred at the moment. Thus, during resharding, it is necessary to make read requests with both old and new shard functions. Requests are handled two times slower, and this is unacceptable.
Yet another issue with Tarantool Shard was the low availability of reads in the case of node failure in a replica set.
New solution
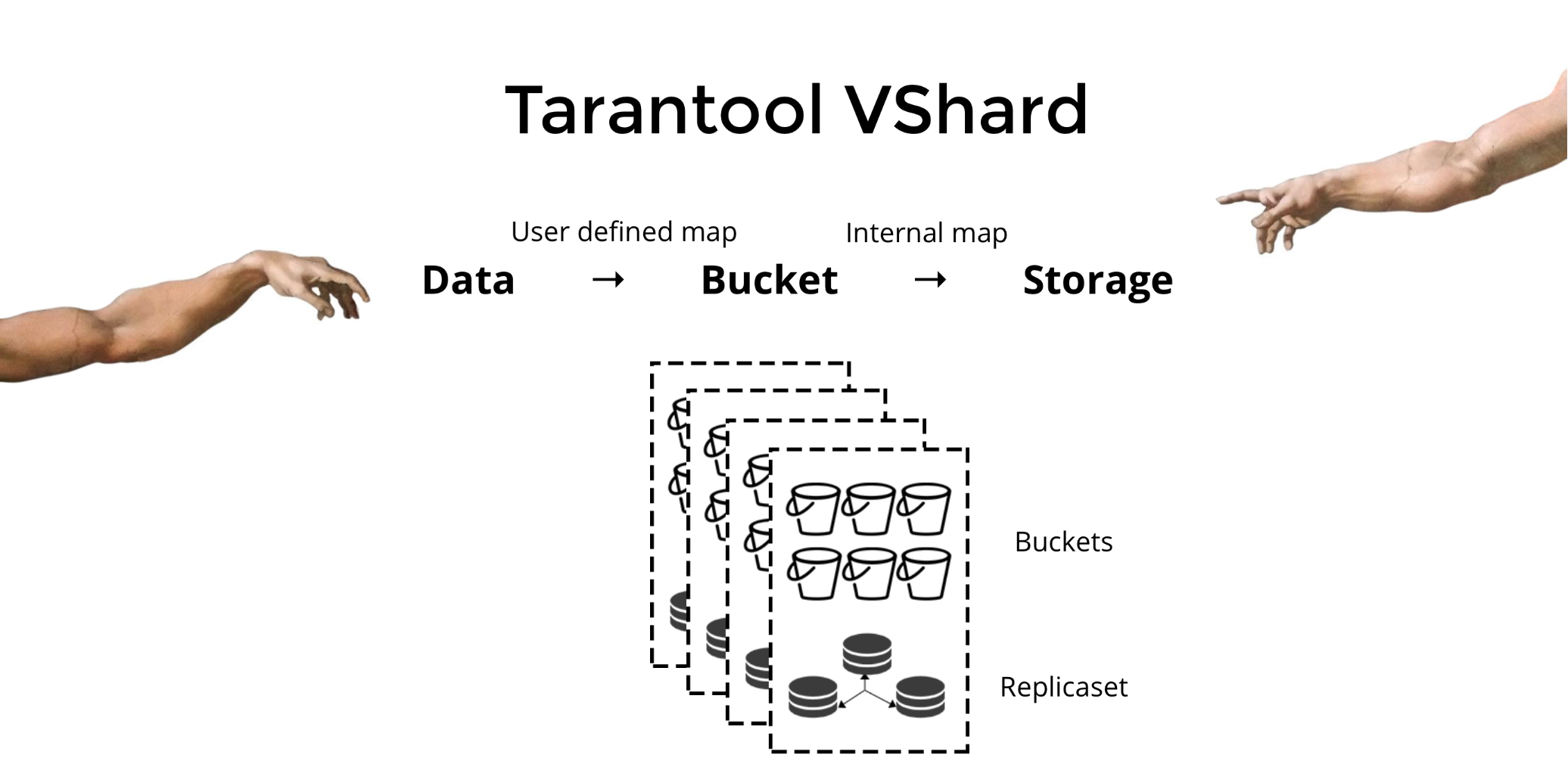
We created Tarantool VShard to solve the three above-mentioned problems. Its key difference is that its data storage level is virtualized, i.e. physical storages host virtual storages, and data records are allocated over the virtual ones. These storages are called buckets. The user does not have to worry about what is located on a given physical node. A bucket is an atomic indivisible data unit, like a tuple in traditional sharding. VShard always stores an entire bucket on one physical node, and during resharding it migrates all the data from one bucket atomically. This method ensures data locality. We just put the data into one bucket, and we can always be sure that it will not be separated during cluster changes.

How do we put data into one bucket? Let’s add a new bucket id field to the table for our bank customer. If this field value is the same for related data, all the records will be in one bucket. The advantage is that we can store records with the same bucket id in different spaces, and even in different engines. Data locality based on bucket id is guaranteed regardless of the storage method.
format = {{'id', 'unsigned'},
{'email', 'string'},
{'bucket_id', 'unsigned'}}
box.schema.create_space('customer', {format = format})
format = {{'id', 'unsigned'},
{'customer_id', 'unsigned'},
{'balance', 'number'},
{'bucket_id', 'unsigned'}}
box.schema.create_space('account', {format = format})
Why is this so important? When using traditional sharding, the data would extend to various existing physical storages. For our bank example, we’d have to contact each node when requesting all the accounts for a given customer. So we get a read complexity O (N), where N is the number of physical storages. It is maddeningly slow.
Using buckets and locality by bucket id makes it possible to read the necessary data from one node using one request—regardless of the cluster size.

In VShard, you calculate your bucket id and assign it. For some people, this is an advantage, while others consider it a disadvantage. I believe that the ability to choose your own function for the bucket id calculation is an advantage.
What is the key difference between traditional sharding and virtual sharding with buckets?
In the former case, when we change cluster components, we have two states: the current (old) one and the new one to be implemented. In the transition process, it’s necessary not only to migrate data, but also to recalculate the hash function for each record. This isn«t very convenient because at any given moment we don«t know if the required data has already been migrated or not. Furthermore, this method is not reliable, and the changes are not atomic, since the atomic migration of the set of records with the same hash function value would require a persistent store of the migration state in case recovery is needed. As a result, there are conflicts and mistakes, and the operation has to be restarted multiple times.
Virtual sharding is much simpler. We don’t have two different cluster states; we only have bucket state. The cluster is more flexible, it smoothly moves from one state to another. There are more than two states now? (unclear). With the smooth transition, it is possible to change balancing on the fly or to remove newly added storages. That is, the balancing control has greatly increased and become more granular.
Usage
Let’s say that we have selected a function for our bucket id and have uploaded so many data into the cluster that there is no space left. Now we«d like to add some nodes and automatically move data to them. That’s how we do it in VShard: first, we start new nodes and run Tarantool there, then we update our VShard configuration. It contains information on every cluster component, every replica, replica sets, masters, assigned URIs and much more. Now we add our new nodes into the configuration file, and apply it to all cluster nodes using VShard.storage.cfg.
function create_user(email)
local customer_id = next_id()
local bucket_id = crc32(customer_id)
box.space.customer:insert(customer_id, email, bucket_id)
end
function add_account(customer_id)
local id = next_id()
local bucket_id = crc32(customer_id)
box.space.account:insert(id, customer_id, 0, bucket_id)
end
As you may recall, when changing the number of nodes in traditional sharding, the shard function itself also changes. This does not happen in VShard. Here we have a fixed number of virtual storages, or buckets. This is a constant that you choose when starting the cluster. It may seem that scalability is therefore constrained, but it really isn’t. You can specify a huge number of buckets, tens and hundreds of thousands. The important thing to know is that there should at least two orders of magnitude more buckets than the maximum number of replica sets that you will ever have in the cluster.
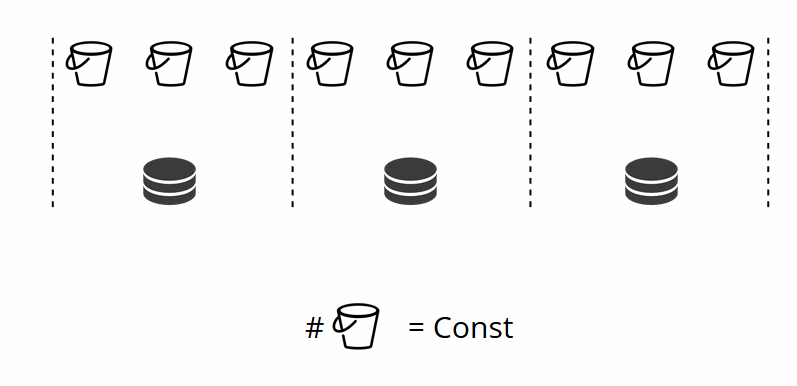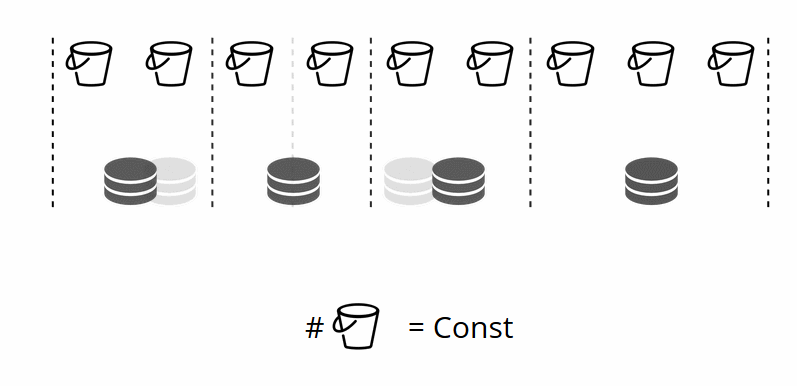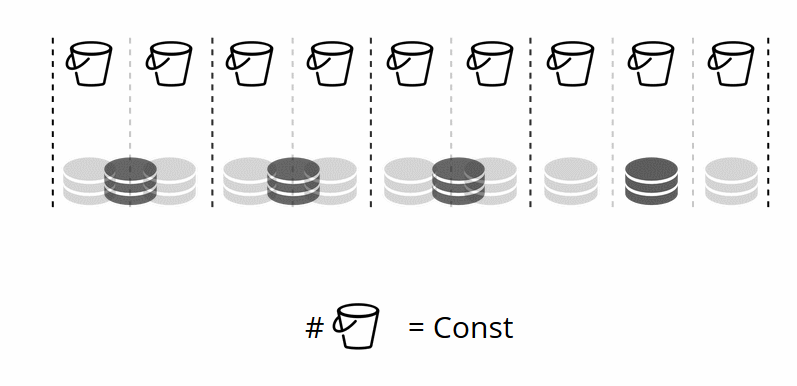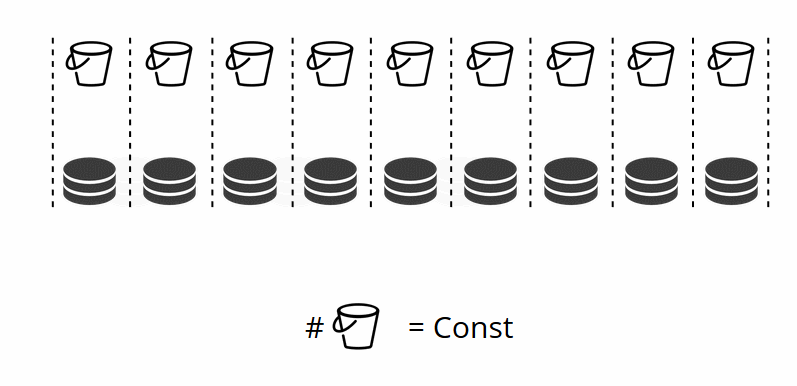
Since the number of virtual storages does not change, and the shard function depends only on this value, we can add as many physical storages as we«d like without recalculating the shard function.
So how are the buckets allocated to physical storages? If VShard.storage.cfg is called, a rebalancer process wakes up on one of the nodes. This is an analytical process that calculates the perfect balance for the cluster. The process goes to each physical node and retrieves its number of buckets, and then builds routes of their movements in order to balance allocation. Then the rebalancer sends the routes to the overloaded storages, which in turn start sending buckets. Somewhat later, the cluster is balanced.
In real-world projects, a perfect balance may not be reached so easily. For example, one replica set could contain fewer data than the other one because it has less storage capacity. In this case, VShard may think that everything is balanced but in fact the first storage is about to overload. To counteract this, we have provided a mechanism for correcting the balancing rules by means of weights. A weight can be assigned to any replica set or storage. When the rebalancer decides how many buckets should be sent and where, it considers the relationships of all the weight pairs.
For example, if one storage weighs 100 and the other one 200, the second one will store twice as many buckets as the first one. Please note that I am specifically talking about weight relationships. Absolute values have no influence whatsoever. You choose weights based on 100% distribution in a cluster: so 30% for one storage would yield 70% for the other one. You can take the storage capacity in gigabytes as a basis, or you can measure the weight in the number of buckets. The most important thing is to keep the necessary ratio.
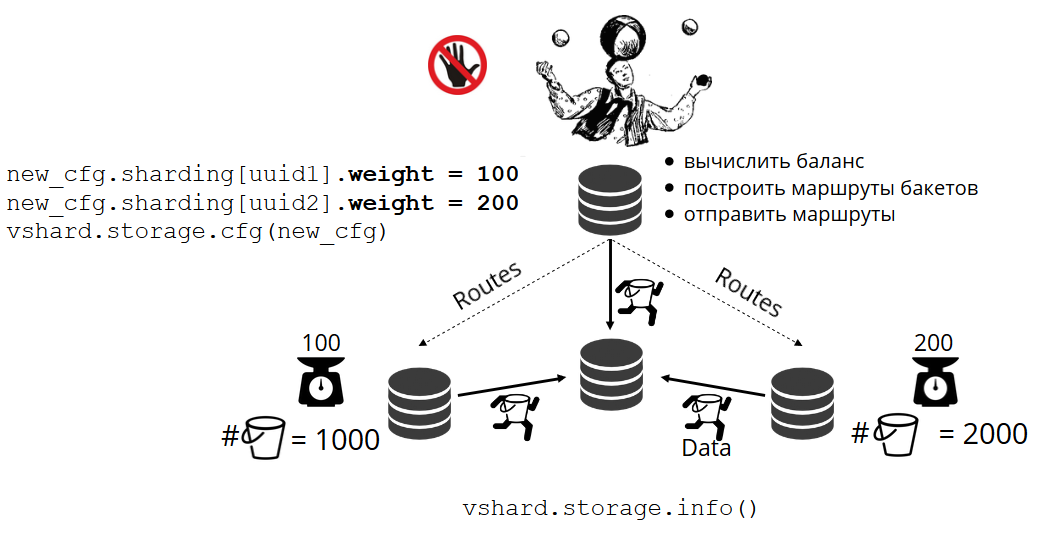
This method has an interesting side effect: if a storage is assigned zero weight, the rebalancer will make this storage redistribute all of its buckets. Thereafter, you can remove the entire replica set from the configuration.
Atomic bucket migration
We have a bucket; it accepts some reads and writes, and at a given moment, the rebalancer requests its migration to another storage. The bucket ceases to accept write requests, otherwise it would be updated during the migration, then updated again during update migration, then the update would be updated, and so on. Therefore, write requests are blocked, but reading from the bucket is still possible. Data is now being migrated to the new location. When the migration is completed, the bucket starts accepting requests again. It is still extant in the old location, but it’s marked as garbage, and later on the garbage collector deletes it piece by piece.
There is some metadata physically stored on the disk that is associated with each bucket. All the steps described above are stored on the disk, and no matter what happens to the storage, the bucket state will be automatically restored.
You may have some following questions:
- What happens to the requests that are working with the bucket when the migration starts?
There are two types of references in the metadata of each bucket: RO and RW. When a user makes a request to a bucket, he indicates whether the work should be in read-only or in read-write mode. For each request, the corresponding reference counter is increased.
Why do we need reference counters for write requests? Let’s say a bucket is being migrated, and suddenly the garbage collector wants to delete it. The garbage collector recognizes that the reference counter is above zero and so the bucket will not be deleted. When all requests are completed, the garbage collector can do its work.
The reference counter for writes also ensures that the migration of the bucket will not start if there is at least one write request in process. But then again, write requests could come in one after the other, and the bucket would never be migrated. So if the rebalancer wishes to move the bucket, then the system blocks new write requests while waiting for current requests to be completed during a certain timeout period. If the requests are not completed within the specified timeout, the system will start accepting new write requests again while postponing the bucket migration. This way, the rebalancer will attempt to migrate the bucket until the migration succeeds.
VShard has a low-level bucket_ref API in case you need more than just high-level capabilities. If you really want to do something yourself, please refer to this API.
- Is it possible to leave the records unblocked?
No. If the bucket contains critical data and requires permanent write access, then you will have to block its migration entirely. We have a bucket_pin function to do just that. It pins the bucket to the current replica set so that the rebalancer cannot migrate the bucket. In this case, adjacent buckets will be able to move without constraints though.

A replica set lock is an even stronger tool than bucket_pin. This is no longer done in the code but rather in the configuration. A replica set lock disables the migration of any bucket in/out of the replica set. So all data will be permanently available for writes.

VShard.router
VShard consists of two submodules: VShard.storage and VShard.router. We can create and scale these independently on a single instance. When requesting a cluster, we do not know where a given bucket is located, and VShard.router will search it by bucket id for us.
Let’s look back at our example, the bank cluster with customer accounts. I would like to be able to get all accounts of a certain customer from the cluster. This requires a standard function for local search:
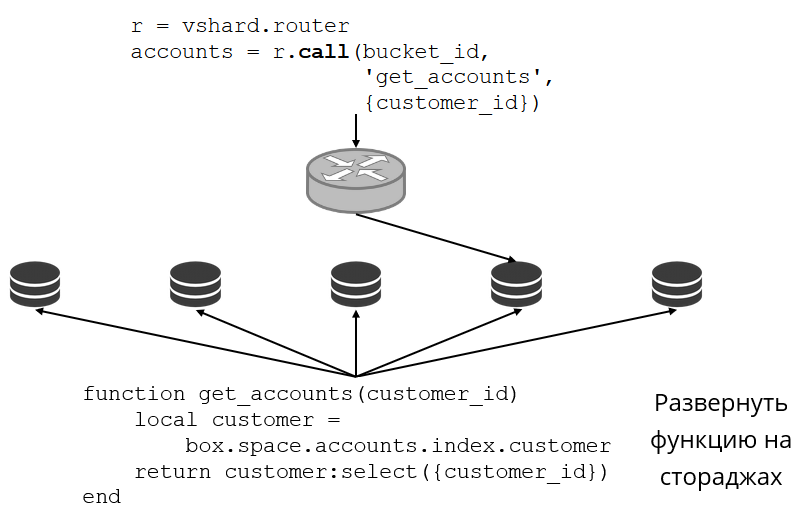
It looks for all accounts of the customer by his id. Now I have to decide where I should run the function. For this purpose, I calculate the bucket id by customer identifier in my request, and ask VShard.router to call the function in the storage where the bucket with the target bucket id is located. The submodule has a routing table that describes the locations of the buckets in the replica sets. VShard.router redirects my request.
It certainly may happen that sharding begins at this exact moment, and that the buckets begin to move. The router in the background gradually updates the table in large chunks by requesting current bucket tables from the storages.
We may even request a recently migrated bucket, whereby the router has not yet updated its routing table. In this case, it will request the old storage, which will either redirect the router to another storage, or will simply respond that it does not have the necessary data. Then the router will go through each storage in search of the required bucket. And we will not even notice a mistake in the routing table.
Read failover
Let’s recall our initial problems:
- No data locality. Solved by means of buckets.
- Resharding process bogging down and holding everything back. We implemented atomic data transfer by means of buckets and got rid of shard function recalculation.
- Read failover.
The last issue is addressed by VShard.router, supported by the automatic read failover subsystem.
From time to time, the router pings the storages specified in the configuration. Say for example, the router cannot ping one of them. The router has a hot backup connection to each replica, so if the current replica is not responding, it just switches to another one. The read requests will be processed normally because we can read on the replicas (but not write). And we can specify the priority for replicas as a factor for the router to choose failover for reads. This is done by means of zoning.
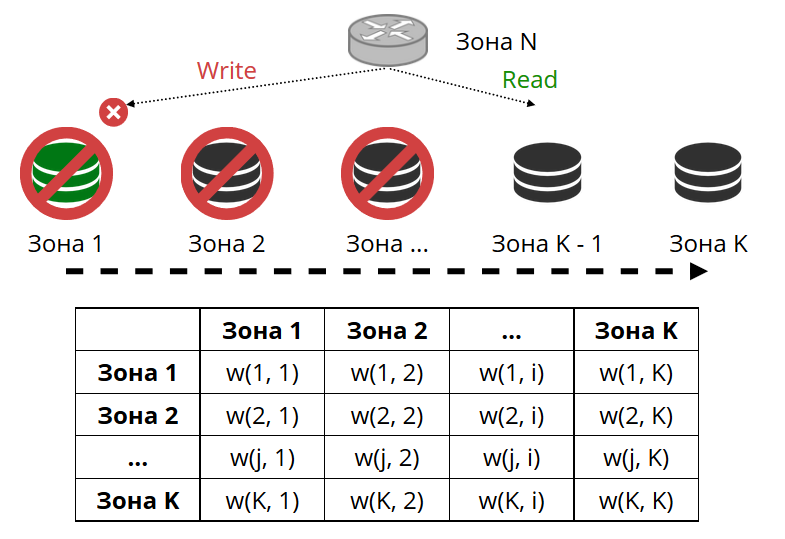
We assign a zone number to each replica and each router and specify a table where we indicate the distance between each pair of zones. When the router decides where it should send a read request, it selects a replica in the closest zone.
This is what it looks like in the configuration:
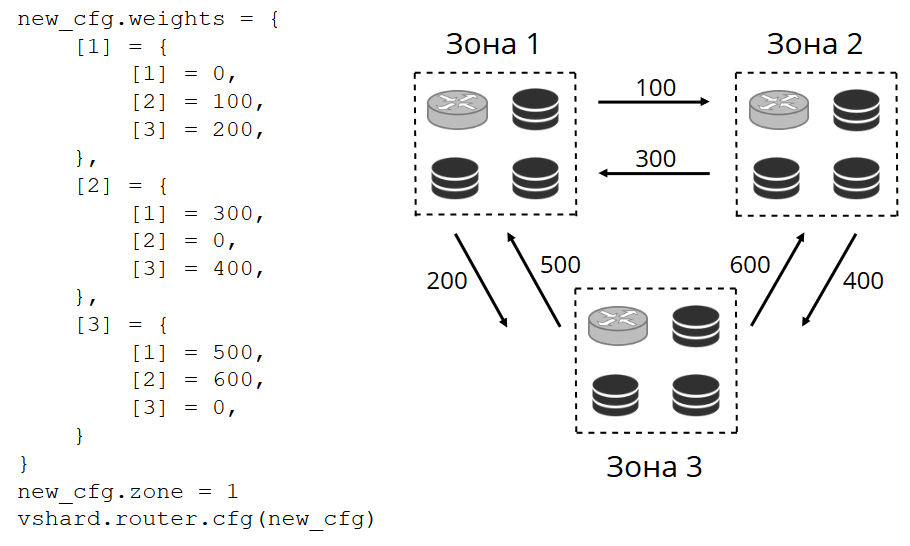
Generally you can request any replica, but if the cluster is large, complex, and highly distributed, then zoning can be very useful. Different server racks can be selected as zones so that the network is not overloaded by traffic. Alternatively, geographically isolated points can be selected.
Zoning also helps when replicas demonstrate different behaviors. For example, each replica set has one backup replica that should not accept requests but should only store a copy of the data. In this case, we place it in a zone far away from all of the routers in the table so that the router will not address this replica unless it’s absolutely necessary.
Write failover
We have already talked about read failover. What about write failover when changing the master? In VShard, the picture is not as rosy as it was before: master selection is not implemented so we will have to do it ourselves. When we have somehow designated a master, the designated instance should now take over as master. Then we update the configuration by specifying master = false for the old master, and master = true for the new one, apply the configuration by means of VShard.storage.cfg and share it with each storage. Everything else is done automatically. The old master stops accepting write requests and starts synchronization with the new one, because there may be data that has already been applied on the old master but not on the new one. After that, the new master is in charge and starts accepting requests, and the old master is a replica. This is how write failover works in VShard.
replicas = new_cfg.sharding[uud].replicas
replicas[old_master_uuid].master = false
replicas[new_master_uuid].master = true
vshard.storage.cfg(new_cfg)
How do we track these various events?
VShard.storage.info and VShard.router.info are enough.
VShard.storage.info displays information in several sections.
vshard.storage.info()
---
- replicasets:
:
uuid:
master:
uri: storage@127.0.0.1:3303
:
uuid:
master: missing
bucket:
receiving: 0
active: 0
total: 0
garbage: 0
pinned: 0
sending: 0
status: 2
replication:
status: slave
Alerts:
- ['MISSING_MASTER', 'Master is not configured for ''replicaset ']
The first section is for replication. Here you can see the status of the replica set where the function is being called: its replication lag, its available and unavailable connections, its master configuration, etc.
In the bucket section, you can see in real time the number of buckets being migrated to/from the current replica set, the number of buckets working in regular mode, the number of buckets marked as garbage, and the number of pinned buckets.
The Alerts section displays the problems that VShard was able to determine itself: «the master is not configured,» «there is an insufficient redundancy level,» «the master is there, but all replicas failed,» etc.
And the last section (q: is this «status»?) is a light that turns red when everything goes wrong. It is a number from zero to three, whereby a higher number is worse.
VShard.router.info has the same sections, but their meaning is somewhat different.
vshard.router.info()
---
- replicasets:
:
replica: &0
status: available
uri: storage@127.0.0.1:3303
uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7
bucket:
available_rw: 500
uuid:
master: *0
:
replica: &1
status: available
uri: storage@127.0.0.1:3301
uuid: 8a274925-a26d-47fc-9e1b-af88ce939412
bucket:
available_rw: 400
uuid:
master: *1
bucket:
unreachable: 0
available_ro: 800
unknown: 200
available_rw: 700
status: 1
alerts:
- ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
The first section is for replication, although it doesn’t contain information on replication lags, but rather information on availability: router connections to a replica set; hot connection and backup connection in case the master fails; the selected master; and the number of available RW buckets and RO buckets on each replica set.
The bucket section displays the total number of read-write and read-only buckets that are currently available for this router; the number of buckets with an unknown location; and the number of buckets with a known location but without a connection to the necessary replica set.
The alerts section mainly describes connections, failover events, and unidentified buckets.
Finally, there is also the simple status? Indicator from zero to three.
What do you need to use VShard?
First you must select a constant number of buckets. Why not just set it to int32_max? Because metadata is stored together with each bucket, 30 bytes in storage and 16 bytes on the router. The more buckets you have, the more space will be taken up by the metadata. But at the same time, the bucket size will be smaller, which means higher cluster granularity and a higher migration speed per bucket. So you have to choose what is more important to you and the level of scalability that is necessary.
Second, you have to select a shard function for calculating bucket id. The rules are the same as when selecting a shard function in traditional sharding, since a bucket here is the same as the fixed number of storages in traditional sharding. The function should evenly distribute the output values, otherwise bucket size growth will not be balanced, and VShard operates only with the number of buckets. If you do not balance your shard function, then you will have to migrate the data from one bucket to another, and change the shard function. Thus, you should choose carefully.
Summary
VShard ensures:
- data locality
- atomic resharding
- higher cluster flexibility
- automatic read failover
- multiple bucket controllers.
VShard is under active development. Some planned tasks are already being implemented. The first task is router load balancing. If there are heavy read requests, it is not always recommended addressing them to the master. The router should balance requests for different read replicas on its own.
The second task is lock-free bucket migration. An algorithm has already been implemented that helps to keep the buckets unblocked even during migration. The bucket will be blocked only at the end to document the migration itself.
The third task is atomic application of the configuration. It isn’t convenient or atomic to apply the configuration separately because some storage may be unavailable, and if the configuration isn«t applied, what do we do next? That is why we are working on a mechanism for automatic configuration transfer.
