Влияние Transparent Huge Pages на производительность системы
Статья публикуется от имени Ахальцева Иоанна, Jiga
Tinkoff.ru сегодня — это не просто банк, это IT-компания. Она предоставляет не только банковские услуги, но ещё выстраивает экосистему вокруг них.
Мы в Tinkoff.ru заключаем партнерство с различными сервисами для повышения качества обслуживания своих клиентов, и помогаем становиться этим сервисам лучше. Например, мы проводили нагрузочное тестирование и анализ производительности одного из таких сервисов, которые помогли найти узкие места в системе — включенные Transparent Huge Pages в конфигах ОС.
Если вы хотите узнать каким способом провести анализ производительности системы и что из этого получилось у нас, то добро пожаловать под кат.
Описание проблемы
На текущий момент архитектура сервиса представляет собой:
- Веб-сервер nginx для обработки http-соединений
- Php-fpm для управления процессами php
- Redis для кеширования
- PostgreSQL для хранения данных
- Монолитное решение для обработки покупок
Основная проблема, которую мы обнаружили при высокой нагрузке во время очередной распродажи под высокой нагрузкой — высокая утилизация cpu, при том что время работы процессора в режиме ядра (system time) росло и было больше, чем время работы в пользовательском режиме (user time).
- User Time (время пользователя)– время, которое процессор тратит на выполнение задач пользователя. Это основное, за что вы платите при покупке процессора.
- System time (время системы) — количество времени, которое система тратит на подкачку, смену контекста, запуск задач по расписанию и другие системные задачи.
Определение первичных характеристик системы
Для начала мы собрали нагрузочный контур с ресурсами близкими к продуктивным, и составили профиль нагрузки, соответствующий нормальной нагрузке в обычный день.
В качестве инструмента обстрела выбрали Gatling версии 3, а сам обстрел производили внутри локальной сети через gitlab-runner. Расположение агентов и мишени в одной локальной сети обусловлено сокращением сетевых издержек, таким образом мы ориентируемся на проверку выполнения самого кода, а не на быстродействие инфраструктуры, где развернута система.
При определении первичных характеристик системы подходит сценарий с линейно-возрастающей нагрузкой с http конфигурацией:
val httpConfig: HttpProtocolBuilder = http
.baseUrl("https://test.host.ru")
.inferHtmlResources() //Скачивает все найденные ресурсы на странице
.disableCaching // Отключение кеша, каждый новый цикл сценарий выполняется "новым" пользователем.
.disableFollowRedirect // Отключение редиректов
/// MULTIPLIER задаётся через JAVA_OPTS
setUp(
Scenario.inject(
rampUsers(100 * MULTIPLIER) during (200 * MULTIPLIER seconds))
).protocols(httpConfig)
.maxDuration(1 hour)
На данном этапе реализовали сценарий открытия главной страницы и скачивание всех ресурсов

Результаты данного теста показали максимальную производительность в 1500 rps, дальнейшее увеличение интенсивности нагрузки привело к деградации системы, связанной с увеличивающимся softirq time.


Softirq представляет собой механизм отложенных прерываний и описан в файле kernel/softirq.с. При этом они забивают очередь команд к процессору, не давая делать полезные вычисления в пользовательском режиме. Обработчики прерываний также могут откладывать дополнительную работу с сетевыми пакетами в потоках ОС (system time). Кратко о работе сетевого стека и оптимизациях можно почитать в отдельной статье.
Подозрение на основную проблему не подтвердилось, потому что на проде при меньшей сетевой активности был куда больший system time.
Пользовательские сценарии
Следующим шагом было решено развивать пользовательские сценарии и добавить, что-то большее, чем простое открытие страницы с картинками. В профиль вошли тяжелые операции, которые задействовали в полной мере код сайта и базы данных, а не веб-сервер отдающий статические ресурсы.
Тест со стабильной нагрузкой запущен на меньшей интенсивности от максимальной, в конфигурацию добавлен переход по редиректам:
val httpConfig: HttpProtocolBuilder = http
.baseUrl("https://test.host.ru")
.inferHtmlResources() //Скачивает все найденные ресурсы на странице
.disableCaching // Отключение кеша, каждый новый цикл сценарий выполняется "новым" пользователем.
/// MULTIPLIER задаётся через JAVA_OPTS
setUp(
MainScenario
.inject(rampUsers(50 * MULTIPLIER) during (200 * MULTIPLIER seconds)),
SideScenario
.inject(rampUsers(100 * MULTIPLIER) during (200 * MULTIPLIER seconds))
).protocols(httpConfig)
.maxDuration(2 hours)
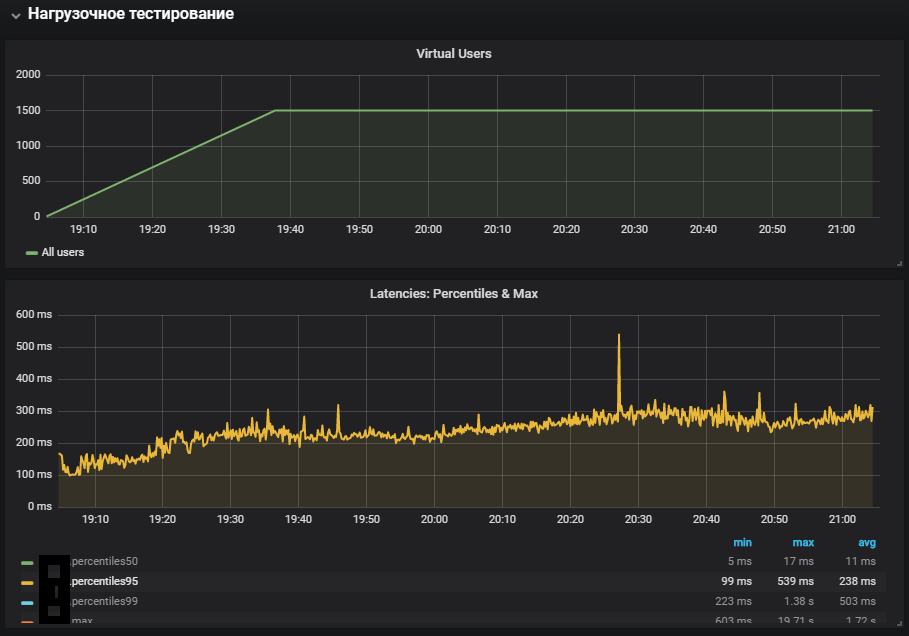

Наиболее полное задействование систем показало увеличение метрики system time, а также её рост во время теста стабильности. Проблема с продуктивной среды была воспроизведена
Сетевое взаимодействие с Redis
При анализе проблем очень важно иметь мониторинг всех компонентов системы, чтобы понимать как она работает и какое влияние на неё оказывает подаваемая нагрузка.
При появлении мониторинга Redis, стало возможно смотреть не на общие метрики системы, а на её конкретные компоненты. Также был изменён сценарий на стресс-тестирование, что совместно с дополнительным мониторингом помогло приблизиться к локализации проблемы.

В мониторинге Redis увидели аналогичную картину с утилизацией cpu, а точнее system time значительно больше user time, при том что основная утилизация cpu приходилась на операцию SET, то есть выделение оперативной памяти для хранения значения.

Для исключения влияния сетевого взаимодействия с Redis было решено проверить гипотезу и переключить Redis на UNIX сокет, вместо tcp сокета. Сделано это было прямо во фреймворке, через который php-fpm подключается к БД. В файле /yiisoft/yii/framework/caching/CRedisCache.php заменили строчку с host: port на хардкодный redis.sock. Подробнее про быстродействие сокетов можно почитать в статье.
/**
* Establishes a connection to the redis server.
* It does nothing if the connection has already been established.
* @throws CException if connecting fails
*/
protected function connect()
{
$this->_socket=@stream_socket_client(
// $this->hostname.':'.$this->port,
"unix:///var/run/redis/redis.sock",
$errorNumber,
$errorDescription,
$this->timeout ? $this->timeout : ini_get("default_socket_timeout"),
$this->options
);
if ($this->_socket)
{
if($this->password!==null)
$this->executeCommand('AUTH',array($this->password));
$this->executeCommand('SELECT',array($this->database));
}
else
{
$this->_socket = null;
throw new CException('Failed to connect to redis: '.$errorDescription,(int)$errorNumber);
}
}
К сожалению, большого эффекта это не возымело. Утилизация CPU немного стабилизировалась, но не решило нашей проблемы — большая часть утилизации CPU приходилась на вычисления в режиме ядра.
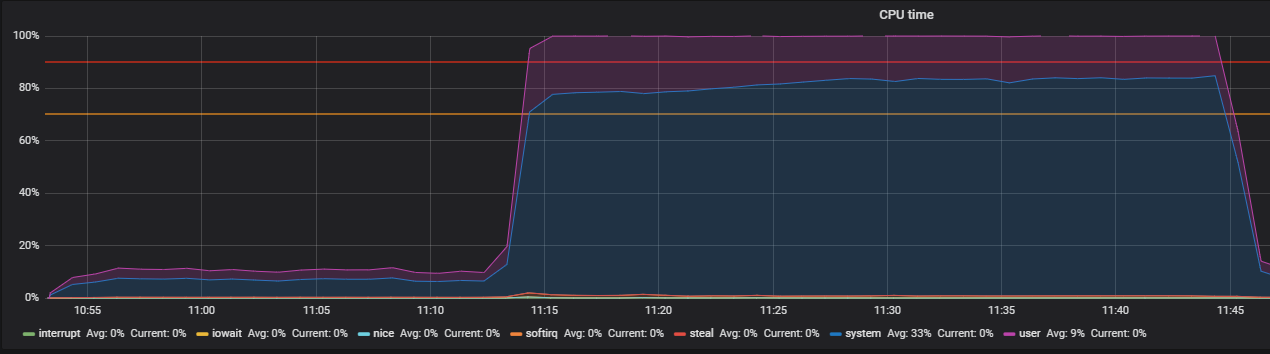
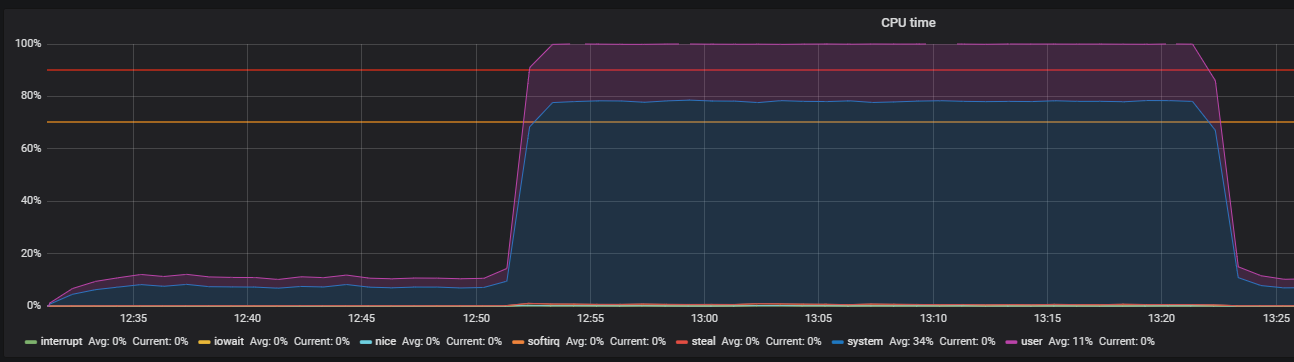
Бенчмарк с помощью stress и выявление проблемы THP
Для локализации проблемы помогла утилита stress — простой генератор рабочей нагрузки для POSIX-систем, которая может нагрузить отдельные компоненты системы, например, CPU, Memory, IO.
Тестирование предполагается на оборудовании и версии ОС:
Ubuntu 18.04.1 LTS
12 CPU Intel® Xeon®
Установка утилиты выполняется с помощью команды:
sudo apt-get install stress
Смотрим как утилизируется CPU под нагрузкой, запускаем тест, который создаёт воркеров для расчёта квадратных корней с продолжительностью в 300 сек:
-c, --cpu N spawn N workers spinning on sqrt()
> stress --cpu 12 --timeout 300s
stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
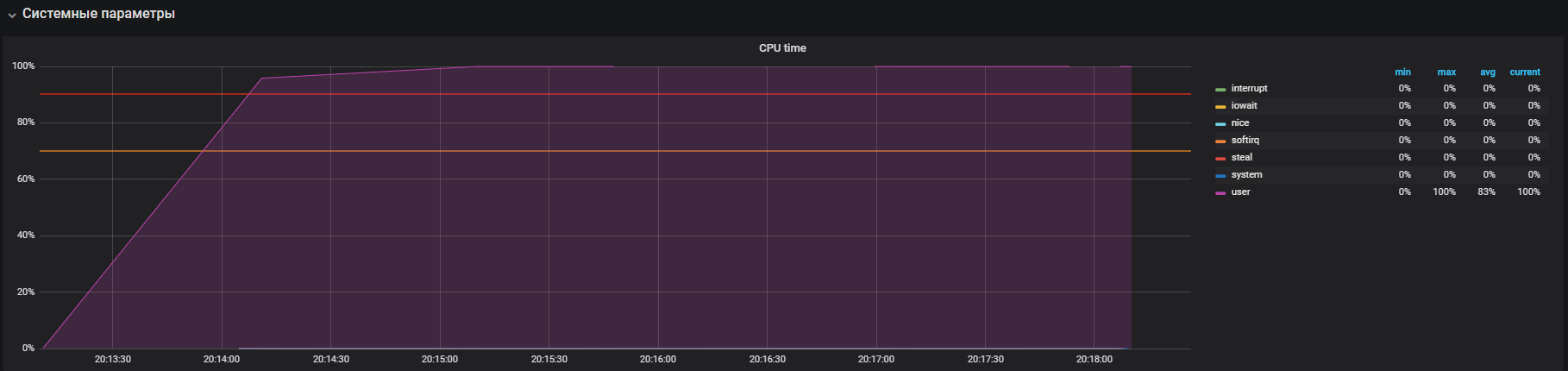
На графике видно полную утилизацию в пользовательском режиме — это значит, что загружены все ядра процессора и выполняются полезные вычисления, а не системные обслуживающие вызовы.
Следующим шагом рассмотрим использование ресурсов при интенсивной работе с io. Запускаем тест на 300 сек с созданием 12 воркеров, которые выполняют sync (). Команда sync записывает данные, буферизованные в памяти, на диск. Ядро хранит данные в памяти во избежание частых (обычно медленных) дисковых операций чтения и записи. Команда sync () гарантирует, что все, что хранилось в памяти, будет записано на диск.
-i, --io N spawn N workers spinning on sync()
> stress --io 12 --timeout 300s
stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd

Видим, что процессор в основном занимается обработкой вызовов в режиме ядра и немного в iowait, также видно >35k ops записи на диск. Такое поведение похоже на проблему с высоким system time, причины которой мы анализируем. Но здесь присутствует несколько отличий: это iowait и iops больший, чем на продуктивном контуре, соответственно это не подходит под наш случай.
Настало время для проверки памяти. Запускаем 20 воркеров, которые будут выделять и освобождать память 300 сек, с помощью команды:
-m, --vm N spawn N workers spinning on malloc()/free()
> stress -m 20 --timeout 300s
stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
Сразу видим высокую утилизацию CPU в системном режиме и немного в пользовательском режиме, а также использование оперативной памяти больше 2 Гб.
Данный случай очень похож на проблему с продом, которая подтверждается большим использованием памяти на нагрузочных тестах. Следовательно проблему необходимо искать в работе памяти. Выделение и освобождение памяти происходит с помощью вызовов malloc и free соответственно, которые в итоге будут обработаны системными вызовами ядра, а значит отобразятся в утилизации CPU как системное время.
В большинстве современных операционных систем виртуальная память организуется с помощью страничной адресации, при таком подходе вся область памяти делится на страницы фиксированной длины, например 4096 байт (является дефолтом для многих платформ), и при выделении, например, 2 Гб памяти, менеджеру памяти придётся оперировать более чем 500000 страниц. В таком подходе появляются большие накладные расходы на управление и для их уменьшения были придуманы технологии Huge pages и Transparent Huge Pages, с их помощью можно увеличить размер страницы, например до 2МБ, что существенно сократит количество страниц в куче памяти. Разница технологий заключается лишь в том, что для Huge pages мы должны явно настроить окружение и научить программу с ними работать, в то время как Transparent Huge Pages работает может работать «прозрачно» для программ.
THP и решение проблемы
Если погуглить информацию о Transparent Huge Pages, то можно увидеть в результатах поиска множество страниц с вопросами «Как выключить THP».
Как оказалось эту «крутую» фичу внесла в ядро Linux корпорация Red Hat, суть фичи, в том что приложения могут прозрачно работать с памятью, как будто они работают с настоящими Huge Page. Согласно бенчмаркам THP на 10% ускоряют абстрактное приложение, подробнее можно посмотреть в презентации, но на деле всё по другому. В некоторых случаях THP вызывает ничем не мотивированное увеличение потребления CPU в систем. Подробнее можно ознакомиться с рекомендациями от Oracle.
Идём и проверяем наш параметр. Как и оказалось THP включен по умолчанию, — выключаем с помощью команды:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
Подтверждаем с помощью теста перед выключением THP и после, на профиле нагрузки:
setUp(
MainScenario.inject(
rampUsers(150) during (200 seconds)),
Peak.inject(
nothingFor(20 minutes), rampUsers(5000) during (30 minutes))
).protocols(httpConfig)

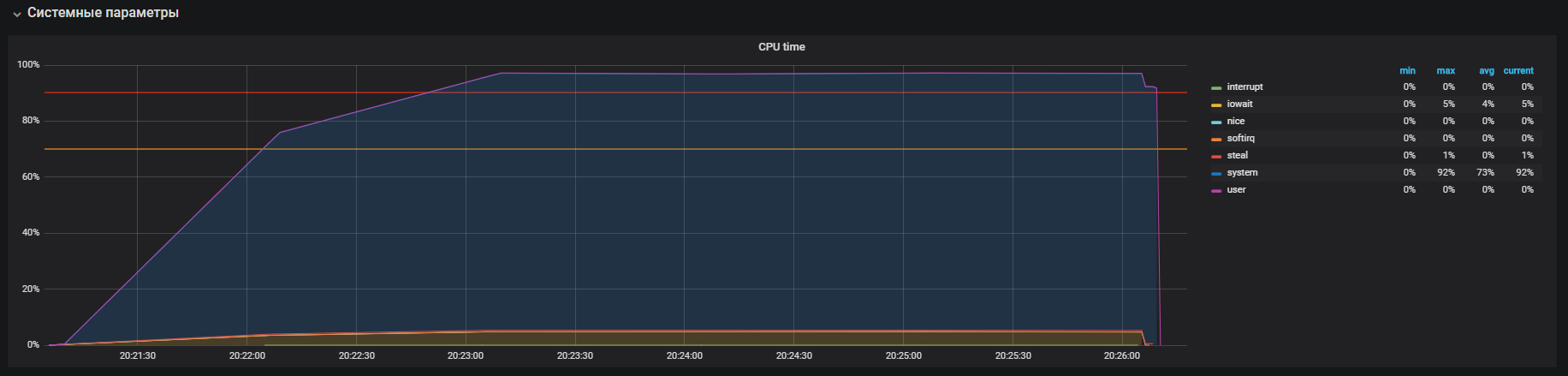
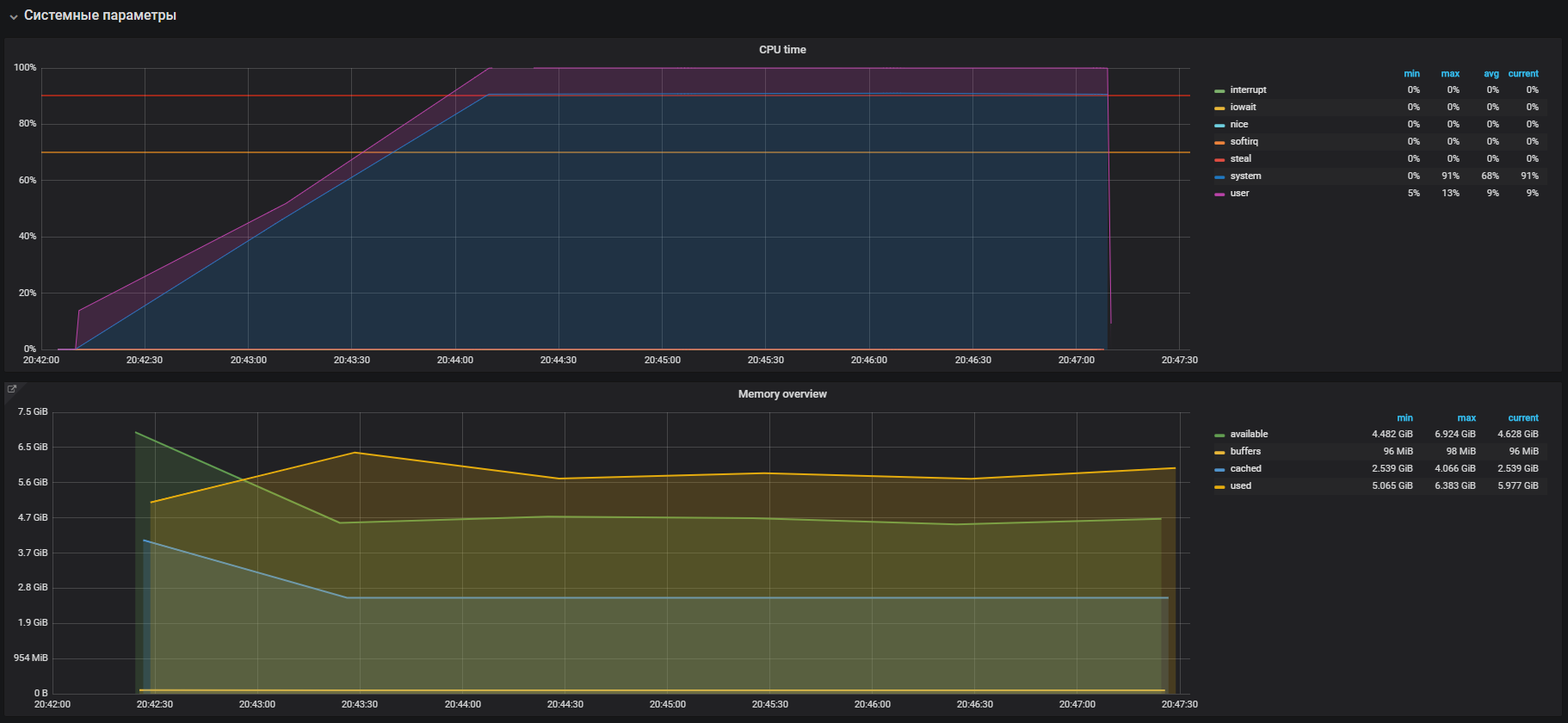
Такую картину мы наблюдали до выключения THP

После выключения THP мы можем наблюдать уже уменьшенную утилизацию ресурсов.
Основная проблема была локализована. Причиной являлся включенный по умолчанию в ОС
механизм прозрачных больших страниц. После выключения опции THP утилизация cpu в системном режиме снизилась не менее чем в 2 раза, что освободило ресурсы для пользовательского режима. Во время анализа основной проблемы, также были найдены «узкие места» взаимодействия с сетевым стеком ОС и Redis, что является поводом для более глубокого исследования. Но это уже совсем другая история.
Заключение
В заключение хотелось бы дать несколько советов, для успешного поиска проблем с производительностью:
- Перед исследованием производительности системы тщательно разбирайтесь в её архитектуре и взаимодействии компонент.
- Настраивайте мониторинг на все компоненты системы и отслеживайте, если не хватает стандартных метрик углубляйтесь и расширяйте.
- Читайте мануалы по используемым системам.
- Проверяйте настройки по умолчанию в конфигурационных файлах ОС и компонент системы.
