Вижу, значит существую: обзор Deep Learning в Computer Vision (часть 2)
Продолжаем постигать современную магию (компьютерное зрение). Часть 2 не значит, что нужно сначала читать часть 1. Часть 2 значит, что теперь всё серьёзно — мы хотим понять всю мощь нейросетей в зрении. Детектирование, трекинг, сегментация, оценка позы, распознавание действий… Самые модные и крутые архитектуры, сотни слоёв и десятки гениальных идей уже ждут вас под катом!

В прошлой серии
Напомню, что в первой части мы познакомились со свёрточными нейросетями и их визуализацией, а также с задачами классификации изображений и построения их эффективных представлений (эмбеддингов). Мы даже обсудили задачи распознавания лиц и ре-идентификации людей.
Ещё в предыдущей статье поговорили про разные типы архитектур (да, те самые таблички, которые я делал месяц,), и тут Google времени зря не терял: они выпустили ещё одну крайне быструю и точную архитектуру EfficientNet. Они создали её, используя NAS и специальную процедуру Compound Scaling. Ознакомьтесь со статьёй, оно того стоит.

Ну, а пока некоторые исследователи анимируют лица и ищут в фильмах поцелуи, мы займёмся более насущными проблемами.
Вот люди говорят: «распознавание изображений». Но что такое «распознавание»? Что такое «понимание (сцены)»? На мой взгляд, ответы на эти вопросы зависят от того, что именно мы хотим «распознать», и что именно хотим «понять». Если мы строим Искусственный Интеллект, который будет извлекать информацию о мире из визуального потока также эффективно (или даже лучше), как люди, то нужно идти от задач, от потребностей. Исторически сложилось, что современное «распознавание» и «понимание сцены» можно разделить на несколько конкретных задач: классификация, детектирование, трекинг, оценка позы и точек лица, сегментация, распознавание действий на видео и описание картинки текстом. В этой статье речь пойдёт о первых двух задачах из списка (уп-с, спойлер третьей части), поэтому текущий план такой:
- Найди меня, если сможешь: детектирование объектов
- Детектирование лиц: не пойман — не вор
- Много букв: детектирование (и распознавание) текста
- Видео и трекинг: единым потоком
Let’s rock, superstars!
Найди меня, если сможешь: детектирование объектов

Итак, задача звучит просто — дана картинка, необходимо найти на ней объекты заранее заданных классов (человек, книга, яблоко, артезиано-нормандский бассет-гриффон и т.д.). Для того, чтобы решить эту задачу с помощью нейросетей, поставим её в терминах тензоров и машинного обучения.
Мы помним, что цветная картинка — это тензор (H, W,3) (если не помним, то есть часть 1). Раньше мы умели только классифицировать картинку целиком, теперь же наша цель — предсказать положения интересующих объектов (координаты пикселей) на картинке и их классы.
Ключевая идея здесь в том, чтобы решать сразу две задачи — классификацию и регрессию. Используем нейросеть, чтобы регрессировать координаты и классифицировать объекты внутри них.
Но координаты объекта, вообще говоря, можно по-разному формализовать, в DL есть три основных способа: детектирование (боксы объектов), оценка позы (ключевые точки объектов) и сегментация («маски» объектов). Сейчас поговорим про предсказание именно bounding box«ов, точки и сегментация будут дальше по тексту.

В основном датасеты для детектирования размечены box«ами в формате: «координаты левого верхнего и правого нижнего углов для каждого объекта на каждой картинке» (этот формат ещё называют top-left, bottom-right), и большинство нейросетевых подходов предсказывают именно эти координаты.
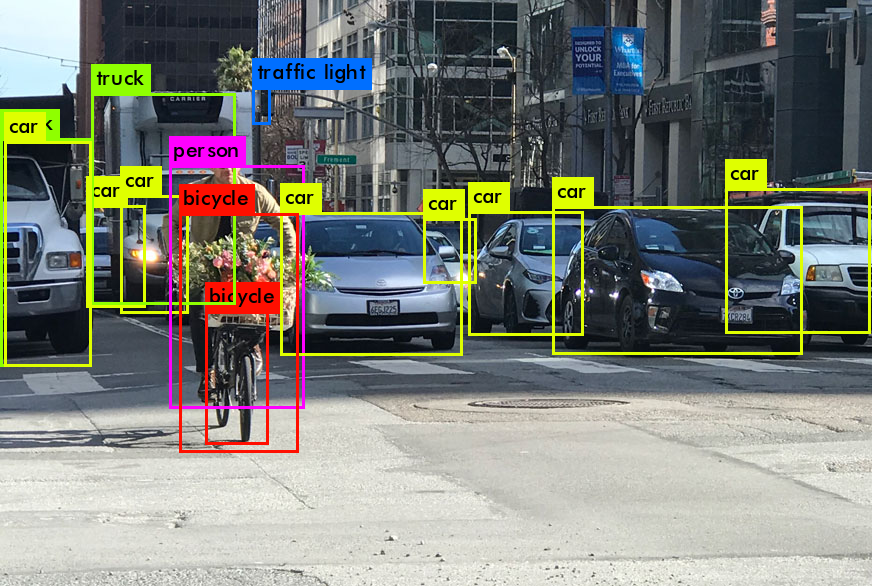
Перед тем как окунуться в виды нейросетей для детекции, давайте вместе подумаем, как вообще можно решать задачу детектирования чего-либо на изображениях. Наверное, если мы хотим найти определённый объект на картинке, то мы примерно знаем, как он выглядит и какую должен занимать на изображении площадь (хотя она может и изменяться).
Если шаблона нет, но есть нейросеть-классификатор, то можем поступить так: будем идти окном фиксированного размера по картинке и предсказывать класс текущей области картинки. Потом просто скажем, что самые вероятные регионы объектов — те, где классификатор ответил уверенно. Таким образом проблему того, что объект выглядит внешне по-разному, мы нейросетью решить можем (так как она обучалась на классификацию на весьма разнообразной выборке).
Но тут же всплывает проблема — объекты на картинках имеют разный размер. Тот же футбольный мяч может быть во всю высоту/ширину картинки, а может быть далеко у ворот, занимая всего 10–20 пикселей из 1000. Хочется написать Brute Force алгоритм: будем просто в цикле перебирать размеры окна. Допустим, у нас 100×200 пикселей, тогда будем идти окном 2×2, 2×3, 3×2, 2×4, 4×2, 3×3…, 3×4, 4×3… Думаю, вам стало понятно, что количество возможных окон будет 100×200, и причём каждым мы проходимся по картинке, совершая (100-W_window) * (200 — H_window) операций классификации, что занимает немало времени. Боюсь, мы не дождёмся, пока такой алгоритм отработает.
Можно, конечно, выбрать наиболее характерные окна в зависимости от объекта, но это тоже будет весьма долго работать, а если и быстро, то вряд ли точно — в реальных приложениях будет безумное количество вариаций размеров объектов на изображениях.
Далее я иногда буду опираться на новый обзор области детектирования от января 2019 (картинки тоже будут из него). Это просто must read, если хотите быстро получить максимально широкий взгляд на DL в детекции.
Одной из первых статей, посвящённых детектированию и локализации с помощью CNN, была сеть Overfeat. Авторы утверждают, что впервые использовали нейросеть для детектирования на ImageNet, переформулировав задачу и изменив лосс. Подход, кстати, был практически end-to-end (ниже — схема Overfeat).

Следующей важной архитектурой стала изобретённая исследователями из FAIR в 2014 году нейросеть Region-based Convolutional Neural Network (RCNN). Суть её в том, что она предсказывает сначала много так называемых «регионов интереса» (RoI’s), внутри которых потенциально могут быть объекты (с помощью алгоритма Selective Search), и уже их классифицирует и уточняет координаты боксов с помощью CNN.

Правда подобный пайплайн делал всю систему медленной, ведь мы прогоняли через нейросеть каждый регион (тысячи раз делали forward pass). Уже через год тот же Ross Girshick из FAIR улучшил RCNN до Fast-RCNN. Здесь идея была в том, чтобы поменять местами Selective Search и предсказание сетью: сначала пропускаем через предобученную нейросеть всю картинку, а потом поверх выданного feature map«а сети-backbone’а предсказываем регионы интереса (например, с помощью того же Selective Search, но там есть и другие алгоритмы). Было всё ещё довольно медленно, куда медленнее, чем real-time (пока что будем считать, что real-time — это меньше 40 миллисекунд на одну картинку).

На скорость влияла больше всего уже не CNN, а сам алгоритм генерации боксов, поэтому решено было заменить его на вторую нейросеть — Region Proposal Network (RPN), которая будет обучаться предсказывать регионы интереса объектов. Так появилась Faster-RCNN (да, над названием явно долго не думали). Схема:

Потом было ещё улучшение в виде R-FCN, о нём подробно говорит не будем, но хочу упомянуть Mask-RCNN. Mask-RCNN — уникальную в своём роде, первая нейросеть, которая решает и задачу детектирования, и instance-сегментации одновременно — она предсказывает точные маски (силуэты) объектов внутри bounding box«ов. Её идея на самом деле довольно проста — есть две ветки: для детекции и для сегментации, и нужно обучать сеть на обе задачи сразу. Главное — иметь размеченные данные. Сам по себе Mask-RCNN устроен очень похоже на Faster-RCNN: backbone тот же, но в конце две «головы» (так часто называют последние слои нейросети) под две разные задачи.

Это были так называемые Two-Stage (или Region-based) подходы. Параллельно с ними в DL-детектировании развивались аналоги — One-Stage подходы. К ним можно отнести такие нейросети, как: Single-Shot Detector (SSD), You Only Look Once (YOLO), Deeply Supervised Object Detector (DSOD), Receptive Field Block Network (RFBNet) и многие другие (см. карту ниже, из этого репозитория).

One-stage подходы, в отличие от two-stage, не используют отдельный алгоритм для генерации боксов, а просто предсказывают несколько координат боксов для каждого feature map«а, выданного свёрточной нейросетью. Подобным образом действует YOLO, SSD слегка отличается, но идея одна: 1×1 свёртка предсказывает из полученных feature map«ов много чисел по глубине, однако мы заранее договариваемся, какое число что значит.


Например, предсказываем из feature map«a размера 13×13х256 feature map 13×13х (4*(5+80)) чисел, где по глубине мы для 4 боксов предсказываем по 85 чисел: первые 4 числа в последовательности всегда — координаты бокса, 5-ое число — уверенность в боксе, и 80 чисел — вероятности каждого из классов (классификация). Это нужно, чтобы потом подать нужные числа в нужные лоссы и правильно обучить нейросеть.

Хочу обратить внимание на то, что качество работы детектора напрямую зависит от качества работы нейросети для извлечения признаков (то есть backbone-нейросети). Обычно в этой роли выступает одна из архитектур, о которых я говорил в предыдущей статье (ResNet, SENet и др.), однако иногда авторы придумывают собственные более оптимальные архитектуры (например, Darknet-53 в YOLOv3) или модификации (например, Feature Pyramid Pooling (FPN)).
Снова отмечу, что мы обучаем сеть и на классификацию, и на регрессию одновременно. В сообществе это принято называть multi-task loss: в одном лоссе фигурирует сумма лоссов для нескольких задач (с некоторыми коэффициентами).
Недавно вышли статьи от 2019 года, в которых авторы заявляют о ещё лучшем соотношении скорость/точность в задаче детекции с помощью предсказания боксов на основе точек. Я говорю о статьях «Objects as Points» и «CornerNet-Lite». ExtremeNet является модификацией CornerNet. Кажется, сейчас их можно назвать SOTA в детекции с помощью нейросетей (но это не точно).

Если вдруг моё объяснение детекторов всё же показалось сумбурным и непонятным, в нашем видео я обсуждаю это не спеша. Возможно, сначала стоит посмотреть его.
Ниже я привёл таблицы нейросетей в детектировании со ссылками на код и кратким описанием фишек каждой сети. Я постарался собрать только те сети, которые действительно важно знать (по крайней мере, их идеи), чтобы иметь хорошее представление об object detection сегодня:
Для того, чтобы понять, как соотносятся скорость/качество каждой из архитектур, можно посмотреть в этот обзор или в более популярную его версию.
Архитектуры — это прекрасно, но детектирование является прежде всего практической задачей. «Не имей сто сетей, а имей хотя бы 1 работающую» — таков мой message. В таблице выше есть ссылки на код, но лично я редко сталкиваюсь с запуском детекторов непосредственно из репозиториев (по крайней мере, с целью дальнейшего деплоя в продакшн). Чаще для этого используется какая-либо библиотека, например, TensorFlow Object Detection API (см. практическую часть моего занятия) или библиотека от исследователей из CUHK. Предлагаю вашему вниманию очередную супер-таблицу (они ведь вам нравятся, да?):
Часто детектировать нужно объект только одного класса, но специфичного и весьма вариативного. Например, детектировать все лица на фото (для дальнейшей верификации/подсчёта людей), детектировать людей целиком (для ре-идентификации/подсчёта/трекинга) или детектировать текст на сцене (для OCR/перевода слов на фото). В целом, подход «обычной» детекции здесь до определённой степени сработает, но в каждой из этих подзадач есть свои трюки, чтобы улучшить качество.
Детектирование лиц: не пойман — не вор

Здесь появляется некоторая специфика, поскольку лица часто занимают достаточно малую часть изображения. Плюс люди не всегда смотрят в камеру, часто лицо видно лишь сбоку. Одним из первых подходов к распознаванию лиц был знаменитый детектор Виолы-Джонса на основе каскадов Хаара, изобретённый ещё в 2001 году.

Нейросети тогда были не в моде не были ещё так сильны в зрении, однако старый добрый hand-crafted подход делал своё дело. В нём активно использовались несколько типов специальных масок-фильтров, которые помогали извлекать лицевые регионы с изображения и их признаки, и далее эти признаки подавались в AdaBoost-классификатор. Кстати, этот метод действительно нормально работает и сейчас, он достаточно быстрый и запускается «из коробки» с помощью OpenCV. Недостаток этого детектора в том, что он видит только лица, развёрнутые фронтально к камере. Стоит лишь немного повернуться, и стабильность детекции нарушается.
Для подобных более сложных случаев можно использовать dlib. Это C++-библиотека, в которой реализованиы многие алгоритмы зрения, в том числе для детектирования лиц.
Из нейросетевых подходов в детектировании лиц особенно значимым является Multi-task Cascaded CNN (MTCNN) (MatLab, TensorFlow). В целом, она и сейчас активно используется (в том же facenet).

Идея MTCNN — использовать для предсказания положения лица и его особых точек три нейросети последовательно (поэтому и «каскад»). Особых точек лица в данном случае ровно 5: левый глаз, правый глаз, левый край губ, правый край губ и нос. Первая нейросеть из каскада (P-Net) используется для генерации потенциальных регионов лица. Вторая (R-Net) — для улучшения координат полученных боксов. Третья (O-Net) нейросеть ещё раз регрессирует координаты боксов и, помимо того, предсказывает 5 ключевых точек лица. Multi-task эта сеть потому, что решаются три задачи: регрессия точек боксов, классификация лицо/не лицо для каждого бокса и регрессия точек лица. Причём MTCNN делает это всё в real-time, то есть ей требуется менее 40 ms на одну картинку.

Из современных State-of-the-Art можно отметить Dual Shot Face Detector (DSFD) и FaceBoxes. FaceBoxes имеет возможность быстрого запуска на CPU (!), а DSFD отличился лучшим качеством (вышел в апреле 2019 года). DSFD устроен посложнее, чем MTCNN, поскольку внутри сети используются специальный модуль для улучшения признаков (с dilated convolutions), две ветки их обработки и специальные типы лоссов. Кстати, с dilated convolutions мы ещё не раз столкнёмся в статьях про сегментацию в следующей части. Ниже пример работы DSFD (впечатляет, не правда ли?).

Чтобы научиться ещё и распознавать лица, не забудьте заглянуть в предыдущую статью серии, там я про это вкратце рассказал.
Много букв: детектирование (и распознавание) текста

Обратите внимание на фото выше. Легко заметить, что, если предсказывать bounding box«ы, параллельные осям координат (как мы делали раньше), то получится весьма некачественно. Часто это оказывается весьма критично, если мы хотим, например, подать потом эти боксы на вход recognition-нейросети, которая по картинке будет предсказывать текст.
В таких случаях принято предсказывать повёрнутые bounding box«ы, или и вовсе ограничивать текст многоугольниками вместо прямоугольников, если он изогнутый (примеры ниже). С предсказанием повёрнутых боксов справляется, например, EAST-детектор.

Идея EAST-детектора в том, чтобы предсказывать не координаты углов боксов, а следующие три вещи:
- Text Score Map’ы (вероятность нахождения текста в каждом пикселе)
- Угол поворота каждого бокса
- Расстояния до границ прямоугольника для каждого пикселя
Таким образом, это больше напоминает задачу сегментации (выделения масок текста), нежели детектирования. Поясняющая картинка из arxiv-статьи:

Задача распознавания текста (а значит и его детектирования) весьма популярна, поэтому есть и аналоги: TextBoxes++ (Caffe) и SegLinks, однако EAST, на мой взгляд, наиболее прост и доступен.
После детектирования текста хочется сразу скормить его другой нейросети, чтобы распознать его и выдать строку символов. Здесь можно заметить интересную смену модальности — из картинок в текст. Бояться этого совсем не стоит, ведь всё зависит лишь от того, какова архитектура сети, что именно предсказывается на последнем слое и какой используется лосс. Например, MORAN (код на PyTorch) и ASTER (код на TensorFlow) вполне справляются с поставленной задачей.

В них нет чего-то сверхъестественного, однако очень грамотно используются сразу два принципиально разных типа нейросетей: CNN и RNN. Первое нужно для извлечения признаков из картинки, а второе для генерации текста. Подробнее на примере MORAN’а: ниже архитектура его распознающей сети.

Однако несмотря на повёрнутые боксы от EAST’а, сетям-распознавателям на вход всё равно приходит прямоугольная картинка, а значит текст внутри неё может занимать далеко не всё пространство. Для того, чтобы распознавателю было проще предсказать по картинке непосредственно текст на ней, можно преобразовать её определённым способом.
Можем применить афинное преобразование ко входной картинке, чтобы растянуть/повернуть текст. Этого можно добиться с помощью Spatial Transformet Network (STN), поскольку она самостоятельно выучивает подобные преобразования и легко встраивается в другие нейронные сети (кстати, можно подобное выравнивание для любой картинки делать, не только для текста). Ниже пример до/после STN.
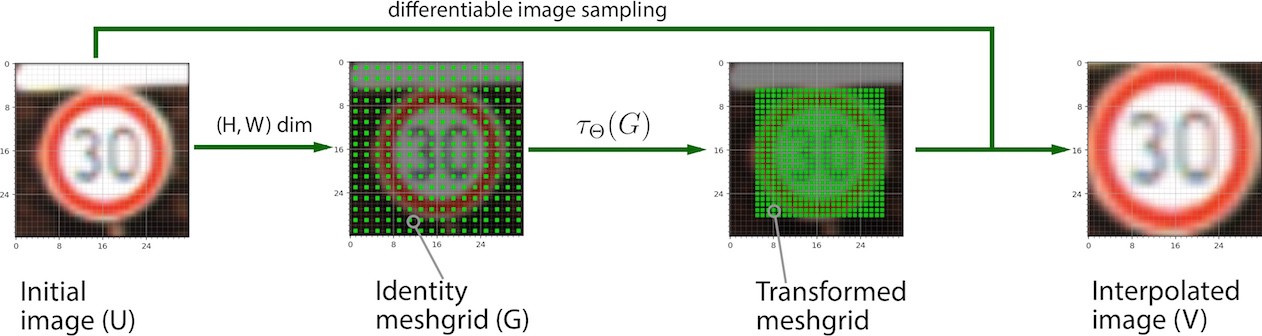
Подробно про STN здесь рассказывать нет смысла, поскольку есть замечательная статья на Хабре (картинка взята оттуда, спасибо автору) и код на PyTorch.
Но MORAN (та самая нейросеть для распознавания текста) поступает ещё умнее — она не ограничивается семейством афинных преобразований, а предсказывает для каждого пикселя входной картинки карту смещений по x и по y, таким образом добиваясь любого преобразования, которое улучшит обучение сети для распознавания. Этот метод называется rectification, то есть исправление картинки с помощью вспомогательной нейросети (rectifier’а). Ниже сравнение картинки после афинного преобразования и после ректификации:

Однако помимо подходов к распознаванию текста «модульно» (сеть детекции → сеть распознавания), есть end-to-end архитектуры: на входе картинка, а на выходе — детекции и распознанный внутри них текст. И всё это единым пайплайном, который обучается на обе задачи сразу. В этом направлении есть внушительная работа Fast Oriented Text Spotting with a Unified Network (FOTS) (код на PyTorch), где авторы также отмечают, что end-to-end подход в два раза быстрее, чем «детекция+распознавание». Ниже схема нейросети FOTS, особую роль играет блок RoiRotate, благодаря которому есть возможность «прокидывать градиенты» с сети для распознавания на нейросеть для детекции (это и правда сложнее, чем кажется).

К слову, каждый год проходит конференция ICDAR, к которой приурочены несколько соревнований по распознаванию текста на самых различных изображениях.
Текущие проблемы в детектировании
На мой взгляд, главная проблема в детектировании сейчас не качество модели-детектора, а данные: их обычно долго и дорого размечать, особенно если классов, которые нужно детектировать, очень много (но кстати есть пример решения для 500 классов). Поэтому многие работы сейчас посвящены генерации как можно более правдоподобных данных «синтетически» и получения разметки «бесплатно». Ниже картинка из моего дипломастатьи от Nvidia, в которой речь идёт как раз о генерации синтетических данных.

Но всё же здорово, что теперь мы можем точно сказать, где на картинке что находиться. И если хотим, например, посчитать количество чего-то на кадре, то достаточно лишь задетектить это и выдать количество боксов. В детекции людей хорошо работает и обычная YOLO, просто главное подать много данных. Тот же Darkflow подойдёт, а класс «человек» встречается почти во всех крупных датасетах по детектированию. Так что если хотим посчитать с помощью камеры количество людей, которые прошли мимо, скажем, за одни сутки, или количество товаров, которые взял человек в магазине, просто задетектим и выдадим количество…

Стоп. Но ведь если мы будем детектировать людей на каждом изображении с камеры, то мы можем посчитать их количество на одном кадре, а на двух — уже нет, поскольку не сможем сказать, где какой именно человек. Нам необходим алгоритм, который позволит считать именно уникальных людей в видеопотоке. Им может быть алгоритм ре-идентификации, но когда речь заходит про видео и детекцию, грех не использовать алгоритмы трекинга.
Видео и трекинг: единым потоком
До сих пор мы говорили только про задачи на картинках, но самое-то интересное происходит на видео. Чтобы решать то же распознавание действий, нам необходимо использовать не только так называемую пространственную (spatial) компоненту, но и временнУю (temporal), поскольку видео — это последовательность изображений во времени.

Трекинг — это аналог детектирования изображений, но для видео. То есть мы хотим научить сеть предсказывать не бокс на картинке, а треклет во времени (который есть по сути последовательность боксов). Ниже пример изображения, на котором показаны «хвосты» — треки этих людей на видео.

Давайте подумаем, как можно решать задачу трекинга. Пусть есть видео, и его кадры #1 и #2. Рассмотрим пока что только один объект — трекаем один мячик. На кадре #1 мы можем использовать детектор, чтобы детектировать его. На втором тоже можем детектировать мячик, и если он там там один, то всё хорошо: говорим, что бокс не предыдущем кадре — это бокс того же мяча, что и на кадре #2. Так же можно продолжать и на остальные кадры, ниже gif из курса по зрению pyimagesearch.

Кстати, в целях экономии времени можем не запускать нейросеть на втором кадре, а просто «вырезать» бокс мяча из первого кадра и искать ровно такой же на втором кадре корреляцией или попиксельно. Такой подход утилизируют корреляционные трекеры, они считаются простыми и более-менее надёжными, если мы имеем дело с простыми случаями по типу «трекинг одного мяча перед камерой в пустой комнате». Такую задачу ещё называют Visual Object Tracking. Ниже пример работы корреляционного трекера на примере одного человека.

Однако если детекций/людей несколько, то нужно уметь сопоставлять боксы с кадра #1 и с кадра #2. Первая идея, которая приходит в голову — попробовать сопоставлять бокс тому, который имеет с ним наибольшую область пересечения (IoU). Правда, в случае нескольких перекрывающихся детекций такой трекер будет нестабилен, поэтому нужно использовать ещё больше информации.

Подход с IoU опирается лишь на «геометрические» признаки детекций, то есть просто пытается сопоставить их по близости на кадрах. Но ведь у нас в распоряжении целое изображение (даже два в данном случае), и мы можем использовать то, что внутри этих детекций — «визуальные» признаки. Плюс к этому мы имеем историю детекций для каждого человека, что позволяет более точно предсказывать его следующее положение на основе скорости и направления движения, это условно можно назвать «физические» признаки.
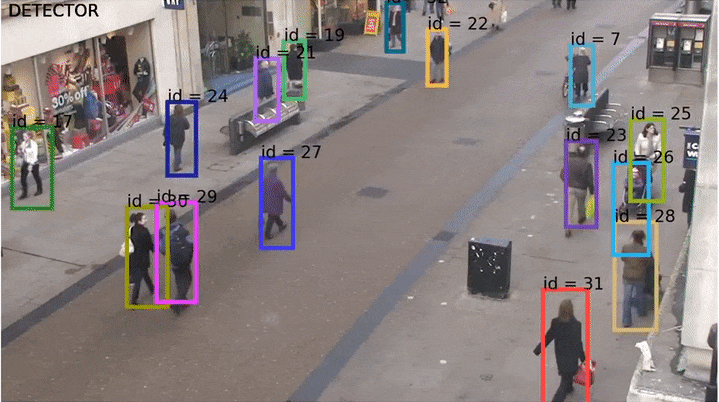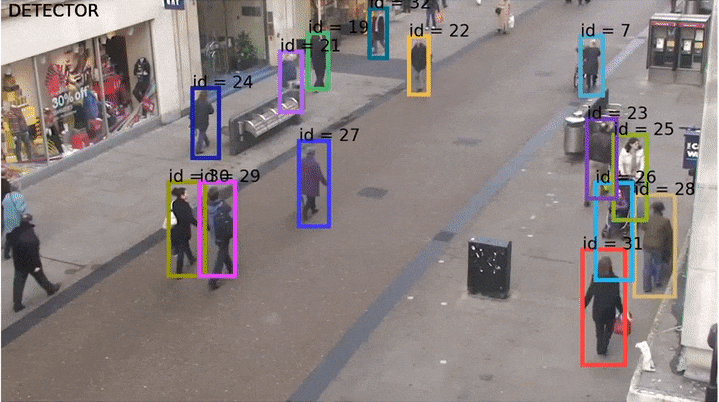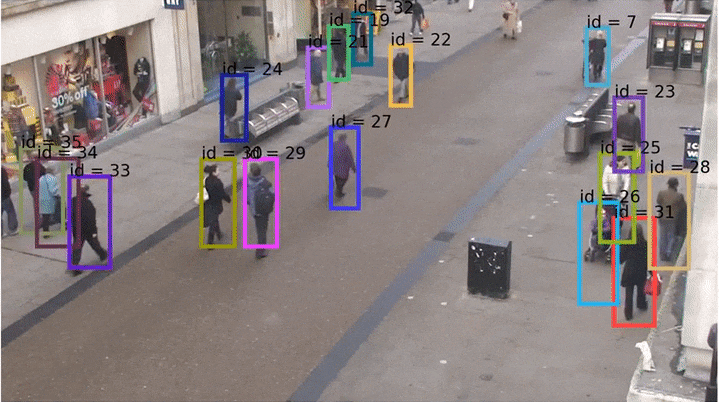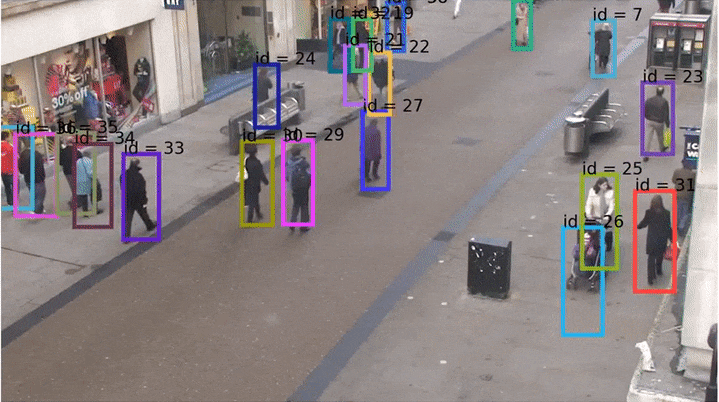
Одним из первых real-time трекеров, который был вполне надёжен и умел справляться со сложными ситуациями, был опубликованный в 2016 году Simple Online and Realtime Traker (SORT) (код на Python). SORT не использовал какие-либо визуальные признаки и нейросети, а лишь оценивал ряд параметров каждого бокса на каждом кадре: текущую скорость (по x и по y отдельно) и размер (высота и ширина). Соотношение сторон (aspect ratio) бокса всегда берутся от самой первой детекции этого бокса. Далее скорости предсказываются с помощью фильтров Калмана (они вообще добро и свет в мире обработке сигналов), строится матрица пересечений боксов по IoU и детекции назначаются венгерским алгоритмом.
Если вам кажется, что математики уже стало многовато, то в этой статье всё доступно объясняется (это ж medium:).
Уже в 2017 году вышла модификация SORT’а в виде DeepSORT (код на TensorFlow). DeepSORT уже стал применять нейросеть для извлечения визуальных признаков, используя их для разрешения коллизий. Качество трекинга выросло — не зря он считается одним из лучших онлайн-трекеров сегодня.

Область трекинга и правда активно развивается: есть и трекеры с сиамскими нейросетями, и трекеры с RNN. Следует держать руку на пульсе, ведь в любой день может выйти (или уже вышла) ещё более точная и быстрая архитектура. Кстати, за подобными вещами очень удобно следить на PapersWithCode, там всегда ссылки на статьи и код к ним (если он есть).
Послесловие

Мы уже действительно многое пережили и многое узнали. Но компьютерное зрение — крайне обширная область, а я — крайне упрямый человек. Именно поэтому мы ещё увидимся в третьей статье этого цикла (будет ли она последней? Кто знает…), где более подробно обсудим сегментацию, оценку позы, распознавание действий на видео и генерацию описания по изображению с помощью нейросетей.
P.S. хочу выразить особую благодарность Вадиму Горбачёву за его ценные советы и комментарии при подготовке этой и предыдущей статьи.
