Виртуализация²
В предыдущей статье я рассказал об Intel® VT-x и расширениях данной технологии для увеличения эффективности виртуализации. В этой статье я расскажу о том, что предлагается тем, кому готов сделать ещё один шаг: запускать ВМ внутри ВМ — вложенная виртуализация. Источник изображения
Источник изображения
Итак, ещё раз о том, чего хочется добиться и что стоит на пути к счастью.
ЗачемКому придёт в голову запускать ещё один монитор виртуальных машин под управлением уже запущенного монитора? На самом деле, кроме чисто академического любопытства, этому есть и практические применения, подкреплённые уже существующими реализациями в мониторах [3, 5].Безопасная миграция гипервизоров. Тестирование виртуальных окружений перед запуском. Отладка гипервизоров. Поддержка гостевых сценариев со встроенным монитором, например, Windows 7 с Windows XP Mode, или упоминавшийся на Хабре cценарий разработки под Windows Phone 8. Теоретическая возможность виртуализации как имитации работы одного компьютера на другом была показана ещё отцами вычислительной техники. Достаточные условия для эффективной, т.е. быстрой виртуализации также были теоретически обоснованы. Практическая их реализация состояла в добавлении специальных режимов работы процессора. Монитор виртуальных машин (назовём его L0) может использовать их для минимизации накладных расходов по управлению гостевыми системами.Однако, если посмотреть на свойства виртуального процессора, видимого внутри гостевой системы, то они будут отличаться от тех, что имел настоящий, физический: аппаратной поддержки виртуализации в нём не будет! И второй монитор (назовём его L1), запущенный на нём, будет вынужден программно моделировать всю ту функциональность, которую L0 имел напрямую из аппаратуры, значительно теряя при этом в производительности.
Nested virtualization
Сценарий, который я описал, получил название nested virtualization — вложенная виртуализация. В нём участвуют следующие сущности.L0 — монитор первого уровня, запущенный непосредственно на аппаратуре.
L1 — вложенный монитор, исполняющийся в качестве гостя внутри L0.
L2 — гостевая система, исполняемая под управлением L1.
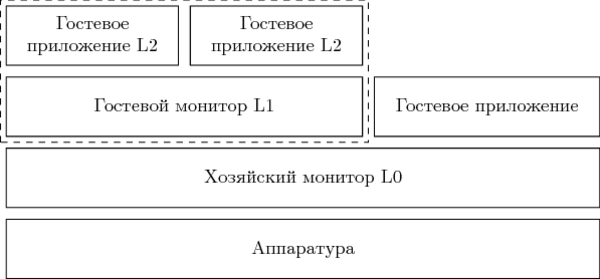
L0 и L1 — это «бюрократический» код, исполнение которого нежелательно, но неизбежно. L2 — это полезная нагрузка. Чем больше времени проводится внутри L2 и чем меньше в L1 и L0, а также в состоянии перехода между ними, тем более эффективно работает вычислительная система.Повысить эффективность можно следующими способами:
Понизить задержки при переходах между режимами root и non-root. В новых микроархитектурах Intel длительность такого перехода медленно, но верно уменьшается. Уменьшить число выходов из L2, разрешив большему числу операций исполняться без генерации VM-exit. Естественно, это также ускорит сценарии простой одноуровневой виртуализации. Уменьшить число выходов из L1 в L0. Как мы увидим далее, часть операций вложенного монитора может быть исполнена напрямую, без выхода в L0. Научить L0, L1 «договариваться» друг с другом. Это приводит нас к идее паравиртуализации, которая сопряжена с модификацией гостевых окружений. Я не буду рассматривать этот сценарий в данной статье (как «неспортивный»), однако подобные решения существуют [4]. Итак, аппаратура не поддерживает напрямую L2, а все возможности по ускорению были использованы для обеспечения работы L1. Решение состоит в создании плоской структуры из гостей L1 и L2.

В этом случае на L0 возлагается задача управления гостями как L1, так и L2. Для последних приходится модифицировать контрольные структуры, управляющие переходами между режимами root и non-root, чтобы выход происходил именно в L0. Это не совсем соответствует представлениям L1 о том, что происходит в системе. С другой стороны, как будет показано уже в следующем параграфе статьи, L1 всё равно не имеет прямого контроля над переходами между режимами, и поэтому при правильной реализации плоской структуры никто из гостей не сможет заметить подмены.
Теневые структуры
Нет, это не что-то из области криминала и теории заговора. Прилагательное «теневой» (англ. shadow) для элементов архитектурного состояния постоянно используется во всевозможной литературе и документации по виртуализации. Идея тут в следующем. Обыкновенный GPR (англ. general purpose register) регистр, модифицируемый гостевым окружением, не может повлиять на корректность работы монитора. Поэтому все инструкции, которые работают только с GPR, могут исполняться гостем напрямую. Какое бы значение в нём не сохранилось бы после выхода из гостя, монитор при необходимости всегда может загрузить в регистр новое значение пост-фактум. С другой стороны, системный регистр CR0 определяет в том числе как будут отображаться виртуальные адреса для всех доступов в память. Если бы гость мог записывать в него произвольные значения, то монитор не смог бы работать нормально. По этой причине создаётся тень — копия критичного для работы регистра, хранимая в памяти. Все попытки доступа гостя к оригинальному ресурсу перехватываются монитором и эмулируются, используя значения из теневой копии.Необходимость программного моделирования работы с теневыми структурами является одним из источников потери производительности работы гостя. Поэтому некоторые элементы архитектурного состояния получают аппаратную поддержку тени: в режиме non-root обращения к такому регистру сразу перенаправляются в его теневую копию.В случае Intel® VT-x [1] как минимум следующие структуры процессора получают тень: CR0, CR4, CR8/TPR (англ. task priority register), GSBASE.Shadow VMCS
Итак, реализация теневой структуры для некоторого архитектурного состояния в L0 может быть чисто программная. Однако ценой этому будет необходимость постоянного перехвата обращений к нему. Так, в [2] упоминается, что один выход из «non-root» L2 в L1 на вызывает около 40–50 настоящих переходов из L1 в L0. Значительная часть этих переходов вызвана всего двумя инструкциями — VMREAD и VMWRITE [5].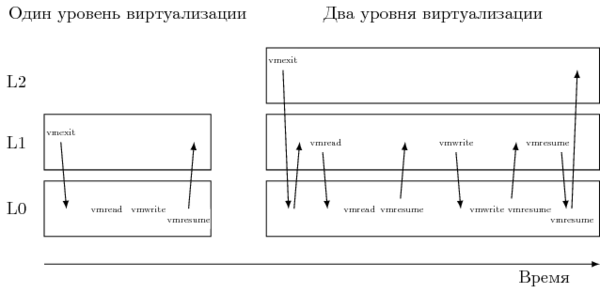
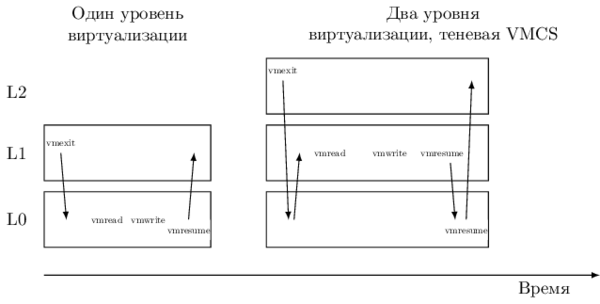
Эти инструкции работают над структурой VMCS (англ. virtual machine control structure), контролирующей переходы между режимами виртуализации. Поскольку напрямую монитору L1 нельзя разрешать её изменять, монитор L0 создаёт теневую копию, а затем эмулирует работу с ней, перехватывая эти две инструкции. В результате время обработки каждого выхода из L2 возрастает значительно.Поэтому в последующих версиях Intel® VT-x VMCS обзавелась теневой копией — shadow VMCS. Эта структура хранится в памяти, имеет аналогичное обычной VMCS содержание и может быть прочитана/изменена с помощью инструкций VMREAD/VMWRITE, в том числе из режима non-root без генерации VM-exit. В результате значительная часть переходов L1 → L0 устраняется. Однако, shadow VMCS не может быть использована для входа/выхода в non-root и root режимы — для этого всё так же используется оригинальная VMCS, управляемая L0.
Shadow EPT Отмечу, что Intel® EPT (англ. Extended Page Table), упомянутая в первой части — это также техника аппаратного ускорения работы с другой теневой структурой, используемой для трансляции адресов. Вместо того, чтобы следить за всем деревом таблиц трансляций гостя (начиная со значения привилегированного регистра CR3) и перехватывать попытки его чтения/модификации, для него создаётся своя собственная «песочница». Настоящие физические адреса получаются после трансляции гостевых физических адресов, что также делается аппаратурой.В случае вложенной виртуализации, как и в случае с VMCS, мы приходим к той же самой проблеме: теперь уровней трансляции стало три (L2 → L1, L1 → L0 и L0 → физический адрес), но аппаратура поддерживает только два. Это означает, что один из уровней трансляции придётся моделировать программно.
Если моделировать L2 → L1, то, как и следовало ожидать, это приведёт к существенному замедлению работы. Эффект будет даже более значительный, чем в случае одного уровня: каждое исключение #PF (англ. page fault) и запись CR3 внутри L2 будет приводить к выходу в L0, а не в L1. Однако, если заметить [6], что гостевые окружения L1 создаются гораздо реже, чем процессы в L2, то можно сделать программной (т.е. медленной) именно трансляцию L1 → L0, а для L2 → L1 задействовать освободившийся аппаратный (быстрый) EPT. Это напоминает мне идею из области компиляторных оптимизаций: следует оптимизировать самый вложенный цикл кода. В случае виртуализации — это самый вложенный гость.
Виртуализация³: что дальше?
Давайте немного пофантазируем о том, что может быть в будущем. Далее в этой секции идут мои собственные (и не очень) идеи о том, как нам обустроить виртуализацию будущего. Они могут оказаться полностью несостоятельными, невозможными или нецелесообразными.
А в будущем создателям мониторов ВМ захочется нырнуть ещё глубже — довести рекурсивную виртуализацию до третьего, четвёртого и более глубоких уровней вложенности. Описанные выше приёмы поддержки двух уровней вложенности становятся очень непривлекательными. Я не очень уверен, что те же самые трюки удастся повторить для эффективной виртуализации даже третьего уровня. Вся беда в том, что режим гостя не поддерживает повторного входа в самого себя.История вычислительной техники напоминает о похожих проблемах и подсказывает решение. Ранний Fortran не поддерживал рекурсивный вызов процедур, потому что состояние локальных переменных (activation record) хранилось в статически выделяемой памяти. Повторный вызов уже исполняющейся процедуры затёр бы эту область, отрезав исполнению выход из процедуры. Решение, реализованное в современных языках программирования, состояло в поддержке стека из записей, хранящих данные вызванных процедур, а также адреса возврата.Похожую ситуацию мы видим для VMCS — для этой структуры используется абсолютный адрес, данные в ней принадлежат монитору L0. Гость не может использовать эту же VMCS, иначе он рисковал бы затереть состояние хозяина. Если бы у нас был стек или скорее даже двусвязнный список VMCS, каждая последующая запись в котором принадлежала бы текущему монитору (а также всем вышестоящим над ним), то не приходилось бы прибегать к описанным выше ухищрениям по передаче L2 под командование L0. Выход из гостя передавал бы управление его монитору с одновременным переключением на предыдущую VMCS, а вход в режим гостя активировал бы следующую по списку.
Вторая особенность, ограничивающая производительность вложенной виртуализации — это нерациональная обработка синхронных исключений [7]. При возникновении исключительной ситуации внутри вложенного гостя LN управление всегда передаётся в L0, даже если единственная его задача после этого — это «спустить» обработку ситуации в ближайший к LN монитор L (N-1). Спуск сопровождается лавиной переключений состояний всех промежуточных мониторов.
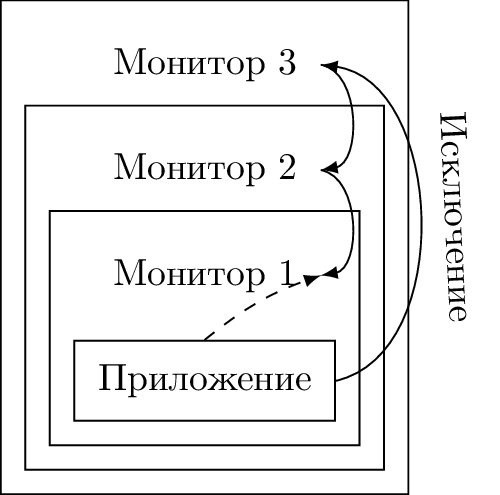
Для эффективной рекурсивной виртуализации в архитектуре необходим механизм, позволяющий менять направление обработки некоторых исключительных событий: вместо фиксированного порядка L0 → L (N-1) синхронные прерывания могут быть направлены L (N-1) → L0. Вмешательство внешних мониторов требуется только если более вложенные не могут обработать ситуацию.
Вместо заключения Тема оптимизаций в виртуализации (да и вообще любых оптимизаций) неисчерпаема — всегда найдётся ещё один последний рубеж на пути к достижению максимальной скорости. В своих трёх заметках я рассказал лишь о некоторых расширениях Intel VT-x и приёмах вложенной виртуализации и полностью проигнорировал остальные. К счастью, исследователи, работающие над открытыми и коммерческими решениями виртуализации, довольно охотно публикуют результаты своей работы. Материалы ежегодной конференции проекта KVM, а также whitepaper’ы компании Vmware — хороший источник информации о последних достижениях. Например, вопрос уменьшения числа VM-exit, вызванных асинхронными прерываниями от устройств, подробно разбирается в [8].Спасибо за внимание!
Литература Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer«s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html Orit Wasserman, Red Hat. Nested virtualization: shadow turtles. // KVM forum 2013 — www.linux-kvm.org/wiki/images/e/e9/Kvm-forum-2013-nested-virtualization-shadow-turtles.pdf kashyapc. Nested Virtualization with Intel (VMX) raw.githubusercontent.com/kashyapc/nvmx-haswell/master/SETUP-nVMX.rst Muli Ben-Yehuda et al. The Turtles Project: Design and Implementation of Nested Virtualization // 9th USENIX Symposium on Operating Systems Design and Implementation, 2010. www.usenix.org/event/osdi10/tech/full_papers/Ben-Yehuda.pdf} Intel Corporation. 4th Gen Intel® Core™ vPro™ Processors with Intel® VMCS Shadowing. www-ssl.intel.com/content/www/us/en/it-management/intel-it-best-practices/intel-vmcs-shadowing-paper.html Gleb Natapov. Nested EPT to Make Nested VMX Faster // KVM forum 2013 — www.linux-kvm.org/wiki/images/8/8c/Kvm-forum-2013-nested-ept.pdf Wing-Chi Poon, Aloysius K. Mok. Improving the Latency of VMExit Forwarding in Recursive Virtualization for the x86 Architecture // 2012 45th Hawaii International Conference on System Sciences Muli Ben-Yehuda. Bare-Metal Performance for x86 Virtualization. www.mulix.org/lectures/bare-metal-perf/bare-metal-intel.pdf
