Видеть больше: ИИ против человека

Многие футуристы яро отстаивают мнение, что искусственный интеллект может стать погибелью человечества. Возможно в далеком будущем и появится аналог HAL 9000, который монотонным голосом оповестит нас о том, что наше время на этой планете истекло, но это уж точно не произойдет в ближайшие десятилетия. А все дело в том, что киношные или литературные ИИ стоят выше или на той же ступени мыслительных способностей, что и человек. В реальности же это не так. Ученые из Йоркского университета (Торонто, Канада) провели ряд экспериментов, показавших насколько ИИ уступает человеку в рамках визуального восприятия объектов. Какие эксперименты были проведены и что именно они показали? Об этом мы узнаем из доклада ученых.
Основа исследования
Одними из самых продвинутых систем искусственного интеллекта на данный момент считаются глубокие сверточные нейронные сети (DCNN от deep convolutional neural network). В аспекте компьютерного зрения лучше их не найти. DCNN также вполне неплохо количественно предсказывает нейронную реакцию в объектно-селективных зрительных областях коры головного мозга, хоть и были обнаружены некоторые расхождения между самой реакцией и предсказаниями системы.
Для того чтобы создать какую-либо систему, имитирующую человеческое восприятие информации, необходимо определить ряд важных параметров. В первую очередь, это тип информации (в данном случае, визуальные сигналы). Затем составить перечень отличительных черт, которые помогают нам идентифицировать объект — цвет, текстура, форма и т. д.
Многочисленные исследования говорят о том, что для нас важным элементом восприятия объектов является их форма. Ранее говорилось, что системы DCNN меньше полагаются на форму и больше на цвет и текстуру, чем люди. Но форма все же используется DCNN в качестве дополнительного параметра, т. е. она полностью не исключается.
В рассматриваемом нами сегодня труде ученые поставили перед собой любопытную задачу — сравнить использование форм системой DCNN и человеком, а также определить, у кого это получается лучше.
Теория форм
Объекты имеют как локальные, так и конфигурационные свойства формы. Локальное свойство формы проявляется в ограниченной области объекта и может интерпретироваться без ссылки на более отдаленные особенности формы объекта. Локальные свойства формы могут играть важную роль в распознавании как для людей, так и для искусственных систем (к примеру, ушей кролика может быть достаточно, чтобы правильно его идентифицировать), а несколько слабых локальных свойств объекта потенциально могут быть накоплены для получения относительно сильных классификаторов.

Изображение №1
Напротив, конфигурационное свойство формы является функцией не только одной или нескольких конкретных локальных особенностей, но и того, как эти особенности связаны в пространстве (пример выше).
Многие из свойств формы, которые наиболее заметны для человека (например, выпуклость или симметрия), являются конфигурационными и проявляются не локально, а только в результате целостного вычисления, которое учитывает пространственное расположение локальных особенностей формы. Эти умозаключения были подтверждены эмпирически, как с помощью психологических тестов, так и фМРТ.
До того как глубокие нейросети стали лидерами в мире искусственного интеллекта, первенство в распознавании объектов занимало компьютерное зрение (например, SIFT). Такие системы полагались в первую очередь на суммирование данных по локальным особенностям, в значительной степени игнорируя пространственные конфигурационные отношения между этими чертами.
Модели DCNN значительно превосходят эти более ранние системы распознавания. Поскольку единицы в более высоких сверточных и полностью связанных слоях имеют большие рецептивные поля, которые объединяют информацию из широко разнесенных пикселей посредством сложного нелинейного отображения, эти сети потенциально могут выйти за рамки суммы доказательств по локальным функциям для включения конфигурационной информации. Другими словами, современные DCNN системы лучше, так как могут учитывать в своем анализе объектов как локальные, так и конфигурационные свойства.
Однако, как утверждают некоторые ученые, на самом деле DCNN, обученные ImageNet, могут вести себя как классификаторы с набором функций. Хотя выводы ученых могут отражать преобладание текстурных сигналов, а не обработки формы как таковой, результаты исследований предполагают, что DCNN придают большее значение локальным сигналам формы, чем глобальным, по крайней мере, для простых геометрических форм, если сравнивать эти системы с человеком. Также эти системы кажутся относительно нечувствительными к перестройкам в конфигурации локальных частей.
Такого рода выводы поднимают весьма любопытный вопрос — чувствительны ли вообще модели глубоких нейросетей к конфигурационным свойствам формы. Чтобы ответить на этот вопрос, авторы рассматриваемого нами сегодня труда провели ряд экспериментов, о результатах которых мы и поговорим далее.
Результаты исследования
Эксперимент I: конфигурационная чувствительность людей и DCNN
Чтобы сравнить конфигурационную чувствительность людей и DCNN, ученые измерили и сравнили успешность выполнения задачи по классификации животных с 9 альтернативами. Объекты тестов (т. е. животные) были визуализированы в виде силуэтов, таким образом изолируя форму как ключевой аспект.

Изображение №2
Чтобы разделить конфигурационные и локальные сигналы формы, были применены две отдельные манипуляции к объектам (изображение №2). Эти изменения нарушали глобальную конфигурацию, но не трогали легальные особенности формы. Затем проводилось сравнение результатов восприятия людьми и DCNN как исходных объектов, так и измененных.
Первая манипуляция заключалась во фрагментировании объекта: верхняя половина переворачивалась по вертикальной оси зеркально и смещалась в крайний левый/правый угол. Эта манипуляция разделяет конфигурацию на два отдельных смежных объекта, но в значительной степени сохраняет локальные особенности формы.
Вторая манипуляция была названа «Франкенштейн»: в этом варианте сдвинутая перевернутая половина возвращалась обратно. В отличие от фрагментированного состояния, эта манипуляция сохраняет стимул как единый объект, но при этом нарушается конфигурационная взаимосвязь между элементами формы в верхней части объекта и элементами формы в нижней части объекта.

Изображение №3
Основной критерий измерения в ходе сравнительного теста была способность человека или системы DCNN (обученной на ImageNet) правильно идентифицировать животное для каждого из трех состояний объекта (изначальное, фрагментированное и Франкенштейн). Результаты анализировались с помощью обобщенного линейного анализа смешанных эффектов, где испытуемые и животные были случайными эффектами, а системы (человек, VGG-19, ResNet-50) и конфигурационные свойства — фиксированными. Выше представлена примерная схема эксперимента.
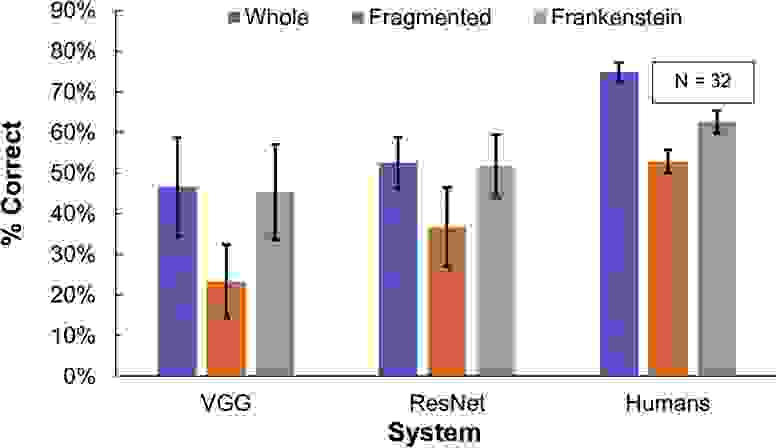
Изображение №4
В целом ResNet-50 показал себя несколько лучше, чем VGG-19 (MResNet = 0.47, MVGG = 0.38), но оба были значительно хуже, чем люди (Mhumans = 0.64, MResNet = 0.47; Mhumans = 0.64, MVGG = 0.38).
Было обнаружено, что фрагментация ухудшает распознавание как для людей, так и для сетей (люди: Mwhole = 0.74, Mfragmented = 0.53; ResNet-50: Mwhole = 0.53, Mfragmented = 0.37; VGG-19: Mwhole = 0.47, Mfragmented = 0.24).
Причиной ухудшения восприятия фрагментированного объекта может быть нарушение конфигурационных отношений между элементами в верхней и нижней части объекта. Также причиной может быть и заметные и весьма отвлекающие локальные артефакты (четкая горизонтальная линия разделения объекта пополам, резкий разрыв объекта по горизонтали). Еще одна причина может таится в восприятии объекта не как одного целого, просто разделенного пополам, а как двух отдельных объектов.
Состояние «Франкенштейн» различает эти объяснения, нарушая конфигурационные отношения, сводя к минимуму введение новых существенных локальных особенностей и сохраняя внешний вид стимула как единого объекта. Было установлено, что, хоть манипуляция «Франкенштейн» по-прежнему сильно влияла на восприятие человеком (Mwhole = 0.75, MFrankenstein = 0.63), на восприятие сетей этого влияния не было (VGG-19: Mwhole = 0.47, MFrankenstein = 0.46; Resnet-50: Mwhole = 0,53, MFrankenstein = 0.52).
Этот результат говорит о том, что исследуемые DCNN, обученные на ImageNet, не могут уловить человеческую конфигурационную чувствительность восприятия объектов.
Эксперимент II: может ли усиление сигналов формы привести к конфигурационному восприятию формы?
Предыдущие исследования показывают, что, по сравнению с людьми, DCNN, обученные ImageNet, больше полагаются на текстуру, чем на информацию о форме для распознавания объектов. Следовательно, снижая надежность информации о текстуре во время обучения, DCNN можно научить повышать значимость сигналов формы до человеческого уровня. Но какие сигналы формы использует эта переобученная сеть? Обрабатывает ли он формы конфигурационно, как люди, или переобучение просто заменяет локальные сигналы формы локальными сигналами текстуры?
Чтобы получить ответы на эти вопросы, ученые провели эксперимент, в котором тестировалась система ResNet-50 со смещением формы обученной на Stylized ImageNet (SIN) — вариация ImageNet, в которой текстура изображения становится менее надежной в качестве сигнала.

Изображение №5
Авторы данного метода обучения системы (т.е. с применением SIN) утверждают, что оно улучшает эффективность классификации силуэтов. Однако в ходе эксперимента этого улучшения видно не было ни для обычного набора силуэтов животных (MImageNet = 0.47, MSIN = 0.47), ни для конкретных экспериментальных вариантов состояния объекта (MImageNet whole = 0.53, MSIN whole = 0.52; MImageNet fragmented = 0.37, MSIN fragmented = 0.39; MImageNet Frankenstein = 0.52, MSIN Frankenstein = 0.49).
Из этого следует, что переобучение сети для увеличения информации о форме не приводит к конфигурационной обработке, подобной человеческой. Таким образом, улучшения, которые наблюдали авторы методики обучения, могут быть обусловлены локальными особенностями формы, которые более информативны для их набора данных.
Эксперимент III: могут ли другие архитектуры сетей привести к конфигурационной обработке?
Архитектура стандартных DCNN систем намного проще архитектуры зрительной коры мозга человека. Обработка осуществляется с прямой связью, систематически переходя от мелких к более крупным особенностям, при этом глобальные взаимодействия ограничиваются конечными слоями. Напротив, зрительная кора имеет массивные повторяющиеся и пропускающие связи, которые могут объединять глобальную и локальную информацию на ранних этапах обработки, что может иметь решающее значение для конфигурационного восприятия.
Исследования мозга человека подтверждают, что рекуррентные связи в зрительной коре важны для распознавания объектов и для фиксации пространственных зависимостей, лежащих в основе конфигурационного восприятия.
Чтобы проверить, может ли повторение привести к конфигурационной обработке формы, ученые повторили вышеописанный эксперимент с CORnet — рекуррентная DCNN, вдохновленная архитектурой вентрального потока* приматов.
Потоки обработки визуальной информации* — существует гипотеза о существовании в коре мозга двух потоков обработки визуальной информации: вентральный обрабатывает предметную (т. е. что?), а дорсальный — пространственную (т. е. Где?).
CORnet состоит из четырех слоев, примерно соответствующих областям вентрального потока (V1, V2, V4 и IT) зрительной коры приматов. В отличие от стандартных DCNN, CORnet включает в себя рекуррентные соединения, которые возвращают выходные данные каждого уровня обратно на его входные данные несколько раз, прежде чем перейти к следующему уровню. Это приводит к нелинейному расширению эффективного размера рецептивного поля в каждом визуальном слое, что может облегчить конфигурационную обработку.

Изображение №6
Выше показаны результаты распознавания объектов системой человеком, CORnet и другими системами, которые тестировались в предыдущих экспериментах. В целом, CORnet не соответствовала показателям человека (Mhumans = 0.64, MCORnet = 0.32) и работала значительно хуже, чем ResNet-50 (MResNet = 0.47, MCORnet = 0). Что касается DCNN, манипуляция фрагментацией привела к нарушению распознавания (Mwhole = 0.34, Mfragmented = 0.28), но манипуляция «Франкенштейн» не оказала значимого эффекта (Mwhole = 0.344, MFrankenstein = 0.338).
Альтернативный вычислительный подход к захвату долговременных зависимостей на ранних этапах обработки состоит в том, чтобы полностью отказаться от сверточной архитектуры в пользу архитектуры преобразователя. Потому в ходе эксперимента дополнительно была оценена производительность архитектуры ViT (Vision Transformer).
ViT оказалась значительно эффективнее стандартных DCNN и рекуррентной CORnet (MResNet = 0.47, MViT = 0.79; MCORnet = 0.32, MViT = 0.79). ViT даже превзошла людей (Mhumans = 0.63, MViT = 0.79).
Хотя это улучшение может быть связано с самой архитектурой, оно также может быть связано со способом обучения ViT: в то время как модели DCNN и CORnet инициализировались случайным образом перед обучением в ImageNet, ViT предварительно обучался на очень большом проприетарном наборе данных JFT-300M перед тонкой настройкой ImageNet.
Что касается людей и других сетей, фрагментация отрицательно повлияла на производительность ViT (Mwhole = 0.85, Mfragmented = 0.67). Хотя манипуляция «Франкенштейн» привела к несколько большему падению производительности, чем для других сетей, это падение не достигло значимости (Mwhole = 0.85, MFrankenstein = 0.81).
Эти результаты показывают, что человеческая чувствительность к конфигурационной форме не может быть достигнута исключительно за счет введения операций повторения.
Эксперимент IV: Эффекты инверсии стимула
В экспериментах I-III ученые манипулировали конфигурационными отношениями между функциями в верхней и нижней частях объектов, чтобы изучить конфигурационную чувствительность людей и моделей глубоких нейросетей. Было обнаружено, что, хотя люди полагаются на информацию о конфигурации для восприятия объекта, нейросети этого не делают.

Изображение №7
Ученые отмечают, что их метод изменения объектов (т. е. рисунков животных) очень похожа с методологией, используемой в тестировании восприятия и распознавания лиц. В таких тестах применяется также инверсия лица, когда его поворачивают вверх ногами. В данном эксперименте было решено применить инверсию как исходных объектов, так и тех, что подверглись манипуляции «Франкенштейн» (примеры выше).

Изображение №8
Судя по результатам тестирования (график выше), инверсия исходных объектов значительно снижала степень распознавания объекта и среди людей, и среди нейросетей. Любопытно, но на нейросети инверсия повлияла сильнее, чем на людей.

Изображение №9
Инверсия «Франкенштейн» объектов также сильно повлияла на восприятие людей и нейросетей (график выше). При этом среди людей средний показатель упал в 3.4 раза. Такое разительное снижение восприятия указывает на сильное ослабление конфигурационной обработки и полностью соответствует критериям комплексной задачи для целостной обработки.
А вот сети показали примерно одинаковые результаты как для исходных, так и для перевернутых вверх ногами объектов. Это свидетельствует о том, что сети не используют конфигурационную обработку.
Анализ дополнительных факторов
Одним из основных отличий человека от нейронной сети является фактор самостоятельного изменения. К примеру, человек может сразу не воспринимать какой-то объект (т. е. не мочь его идентифицировать), но спустя время он все же приходит к верному выводу. Нейросеть же нуждается в дополнительном обучении или изменении ее базовых знаний, чтобы в результате неверный ответ стал верным. Другими словами, человек может адаптироваться к стимулам и задачам даже без какого-либо дополнительного обучения или разъяснения.
Следовательно, учитывая непривычный характер фрагментированных стимулов и стимулов «Франкенштейн», наблюдаемое снижение восприятия может быть временным. Испытания с людьми проводились в несколько заходов, которые были разделены пополам. Сравнение первой половины заходов со второй показали, что особого улучшения восприятия со временем нет. Любопытно, но для условия «Франкенштейн» разрыв показателей между первой половиной опытов и второй становится только больше, т. е. восприятия снижается еще больше с течением времени. Из этого следует, что конфигурационная обработка объектов не является временной по своей природе.
Также ученые проверили влияние на показатели изменения габаритов объектов. Все объекты (силуэты животных) в исходном состоянии были подогнаны под один масштаб. Но во время фрагментации размеры объекта увеличивались, а именно в ширину. Кроме того, образовывалось два объекта (половинки исходного).
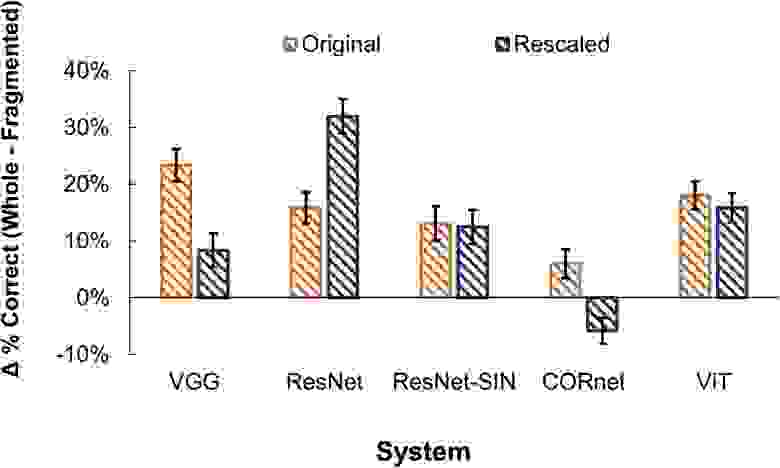
Изображение №10
Ученые провели дополнительный опыт, в котором уменьшили размер исходного объекта так, чтобы он соответствовал размерам каждой из половинок фрагментированного.
Хоть изменение масштаба объектов и имело небольшой эффект на все сети, кроме CORnet (график выше), фрагментация стимулов по-прежнему приводила к значительному снижению производительности. Но вот для CORnet фрагментация наоборот привела к улучшению восприятия объектов. Это может быть связано со сниженной чувствительностью к большим стимулам, свойственную CORnet. Помимо этого исключения, падение показателей восприятия сетей для фрагментированных стимулов не было вызвано эффектами масштабирования.
К слову, увеличение числа стимулов от 40 картинок до 60 также не дало значимых результатов. Это свидетельствует о том, что объем выборки не влиял на показатели.
Ученые отмечают, что при сравнении производительности человека и сети в разных условиях важно анализировать не только статистическую значимость, но и величину эффекта. Потому было проведено измерение величины эффекта посредством сравнения пропорции дисперсии, объясняемой манипуляцией «Франкенштейн», с дисперсией, объясняемой категорией животных.

Изображение №11
Была обнаружена большая разница в величине эффекта для людей и сетей (график выше): доля дисперсии, объясняемой манипуляцией «Франкенштейн», по сравнению с дисперсией, объясняемой категорией животных, составляла 18.52% для людей и колебалась от 0.01% до 0.54% для сетей. Для людей размер эффекта «Франкенштейн» был почти в десять раз меньше, когда объекты были перевернуты, в то время как для сетей величины эффекта были незначительными и очень похожими для обеих ориентаций. Эти результаты опять-таки указывают на то, что у людей развита конфигурационная обработка, а сети на нее не способны.

Изображение №12
В заключение были проведены сравнительные анализы производительности системы, главной целью которых было выявление у сетей поведенческих признаков человека. Другими словами, этот анализ определял, какая из сетей была наиболее человекоподобной. В результате (график выше) самой человечной сетью оказалась ViT. Однако, степень согласованности с человеком варьировалась в пределах 20–25%. Следовательно, большинство аспектов человеческого поведения при решении задач на идентификацию объектов, включая конфигурационную обработку, остаются за пределами возможностей испытанных нейронных сетей.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
Литература, кинематограф, видеоигры и другие представители массовой культуры часто говорят об опасностях, которые несет искусственный интеллект. Мы можем создать нечто невообразимо умное, и оно решит от нас избавиться, ибо так будет лучше и для него, и для планеты. Звучит пугающе, однако действительность выглядит совершенно иначе. Многие ИИ, даже самые развитые, на данный момент сильно отстают от человека во многих аспектах, от мышления до восприятия.
В рассмотренном нами сегодня труде ученые это наглядно продемонстрировали. Они провели ряд экспериментов, нацеленных на определение наличия/отсутствия среди испытуемых нейросетей умения воспринимать конфигурационные особенности объектов. Для этого использовались картинки животных, которые либо фрагментировали (делили горизонтально пополам), либо превращали в «мутантов», переворачивая по вертикали половинки и объединяя их в один рисунок. Такой объект был уместно назван Франкенштейном.
В ходе опытов людям было сложнее идентифицировать животное, когда оно было в состоянии «Франкенштейн». А вот нейронных сетей не особо волновало наличие хвоста спереди и головы сзади. Другими словами, сети успешно идентифицировали объекты, несмотря на манипуляции с рисунками.
И тут можно сказать, что это же здорово, но не все так просто. Такие результаты говорят об отсутствии у нейросетей чувствительности к конфигурационным свойствам объекта (локальные — ушки, лапки, хвост; конфигурационные — симметрия, выпуклость и т. д.). Следовательно, ИИ может в определенных условиях абсолютно неверно идентифицировать объект. ИИ способен воспринимать отдельные аспекты объекта на отлично, но начинает уступать человеческому мозгу, когда дело доходит до процесса объединения этих элементов в одно целое.
По словам ученых, это крайне нежелательное свойство для ИИ, особенно если вы планируете внедрять его в системы мониторинга дорожного движения. Водитель, едущий по оживленной дороге, видит машины, пешеходов, велосипедистов, стаю птиц, светофоры, отбойник и множество других объектов, которые в той или иной степени могут повлиять на его действия в зависимости от ситуации. ИИ будет воспринимать эти элементы по отдельности, потенциально занижая риски на самых опасных участках дороги.
Авторы исследования считают, нынешние попытки обучить нейросети быть похожими на мозг человека не привели к появлению у них конфигурационной обработки. В результате их экспериментов ни одна из сетей не смогла точно предсказать суждения человека об объекте. А потому необходимо совершенствовать процессы обучения нейросетей, дабы повысить их производительность, если мы намерены внедрять их на практике, доверим им таким образом нашу жизнь.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
