Переход на Metal

А зачем?
Причина первая: уход на пенсию OpenGL для iOS/OSX. В 2018 году Apple объявила, что прекращает поддержку этого графического API, и это только вопрос времени, когда она удалит его из своих операционок и запретит выкладывать в App Store приложения, использующие GLES (OpenGL for Embedded Systems — подмножество API OpenGL для встроенных систем, например, мобильных устройств). А кому надо впопыхах интегрировать незнакомый API? Правильно, никому. Плюс, нет-нет да и случаются какие-то неприятные падения где-то под капотом OpenGL, починка которых сводится к мольбам, что очередной точечный фикс кода всё исправит.
Причина вторая: технические трудности разработки. Сейчас OpenGL просто своим существованием блочит и/или замедляет работу целому пласту iOS-разработчиков. Во-первых, счастливчики, которым довелось поиметь M1, вынуждены страдать со сборкой и Rosetta (программное решение от Apple для запуска x86_64 приложений на ARM64 процессорах, коим и является M1). Или вот ещё история: если собрать приложение в Xcode версии 13.3+ и запустить его на симуляторе iOS 15.4+, то OpenGL падает на первом кадре. Почему? Никто не знает. На issue-трекерах разных проектов много кто от этого страдает, а мы решили просто перейти на Metal.
Причина третья (продуктовая): производительность. Чисто теоретически, Metal обладает большей производительностью: меньше аллокаций, больше буферов можно переиспользовать, меньше инициализаций в render-потоке. Apple анонсировала Metal на одной из WWDC (Worldwide Developers Conference — международная конференция для разработчиков на платформах от Apple) и утверждала, что он может быть до 10 раз быстрее OpenGL. В реальности — вопрос сложный. Сильно зависит от того, где и как Metal используется, а именно, насколько вы следуете гайдлайнам. Потому что, очевидно, не всегда есть возможность сохранить удобный интерфейс для совершенно разных графических API. Производительность в рамках нашего продукта ещё обсудим.
Первый прототип
Итак, имеем следующие вводные:
Есть большая кодовая база, которая активно использует OpenGL, и которую, по понятным причинам, хочется как можно больше переиспользовать.
Несмотря на то, что другой API для рендера в момент старта перехода на Metal мы не использовали, всё равно наш код более-менее готов к этому, потому что для тестовых целей мы когда-то придумали «пустой рендерер», который высокоуровнево делает всё то же самое, но в реальности просто играется с данными, ничего не рисуя.
Текущая архитектура нашего графического движка OpenGL-центрична, потому что затачивались именно на него. Конечно, когда-то поддерживали DirectX, но со смертью винфона отказались от этой идеи.
OpenGL и Metal высокоуровнево сильно различаются, и подружить их на одной кодовой базе местами будет очень серьёзной головоломкой.
Никто в команде у нас никогда не занимался Metal всерьёз, поэтому решили начать с простого. Впервые изучая новый графический API, люди сначала учатся рисовать треугольник, так и мы хотим реализовать некий Proof-of-Concept — нарисовать карту хоть как-нибудь, чтобы иметь представление, как мы будем всё это дело интегрировать.
С какой стороны подойдём к этой задаче?
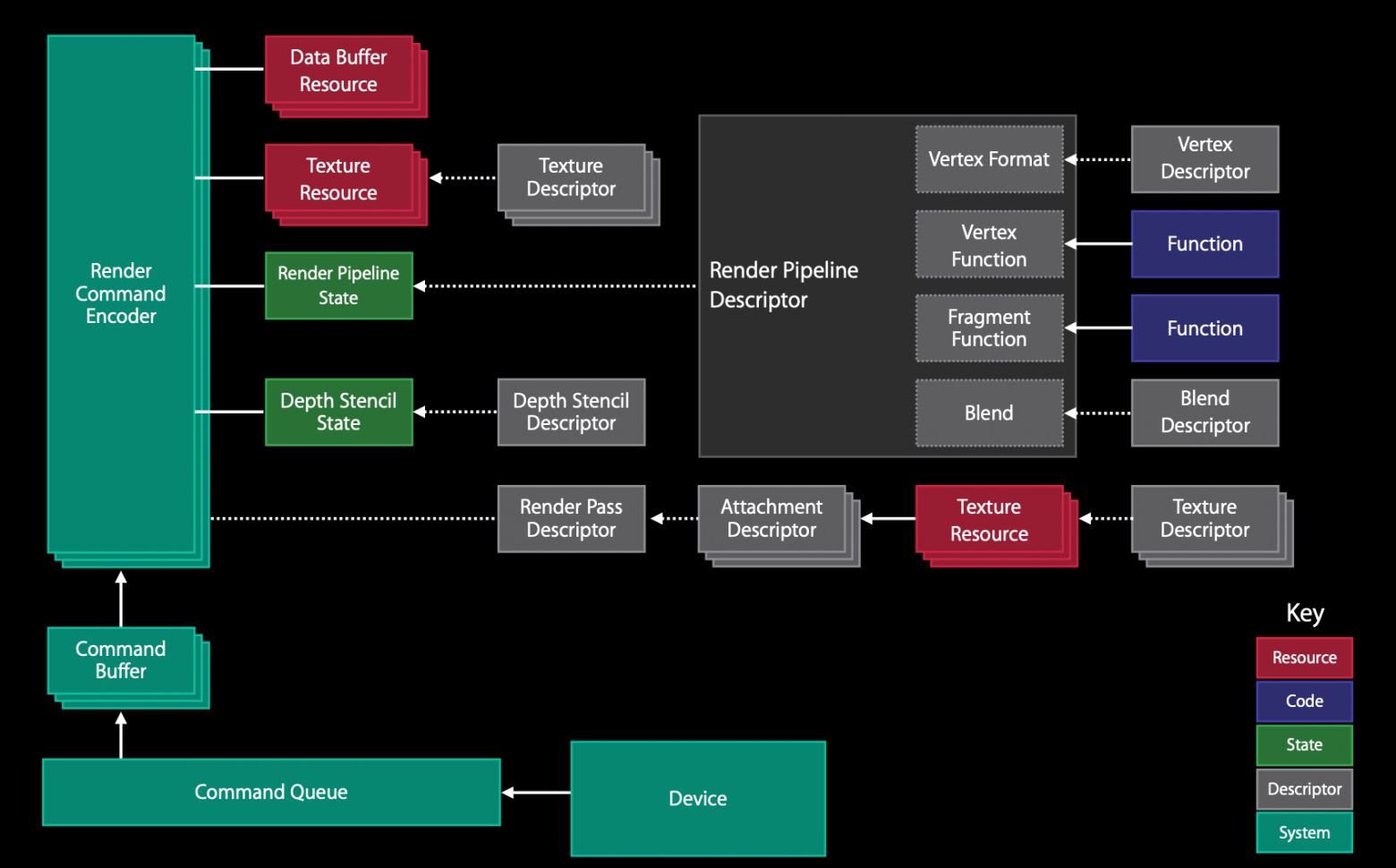
Сначала давайте посмотрим на схему работы графического конвейера (картинка отсюда, там же можно почитать подробнее):

Начнем сначала — с шейдеров. Шейдер — это небольшая программа, которая запускается на GPU. Нас интересует два вида шейдеров:
Вершинный. Конвертирует координаты вершин 3D-объектов в 2D-координаты экрана.
Фрагментный. Вычисляет финальное значение цвета пикселя.
Каждый вид объекта на карте — линия (обычная, градиентная, штриховая), здания, площадники, иконки и т.д. — рисуется с помощью какого-то своего шейдера.
У каждого API есть своя спецификация «шейдерного языка» — GLSL (OpenGL Shading Language) и MSL (Metal Shading Language) соответственно, поэтому мы не можем использовать уже существующие шейдеры в нашем прототипе. Однако переписывать или копировать шейдеры не хочется, мы ведь просто хотим нарисовать карту. Да и в долгосрочной перспективе поддерживать 2 комплекта шейдеров под каждое API будет не очень приятно. В давние времена в нашей команде уже был такой опыт, и такие комплекты постоянно расходились, потому что не всегда была возможность проверять корректность работы шейдеров DirectX под Windows: у разработчиков банально не было нужных машин.
Тут нам на помощь приходит три утилиты:
glslang позволяет транслировать GLSL в SPIRV (Standard Portable Intermediate Representation — промежуточный язык для вычислений и работы графики от Khronos Group, создателей OpenGL).
SPIRV-Cross позволяет транслировать SPIRV в MSL и генерировать рефлексию — информацию о том, как располагаются в памяти атрибуты, принимаемые на вход шейдерами.
xcrun позволяет скомпилировать полученный код в шейдерную библиотеку.
Небольшой скрипт на питоне, который вызывает все эти утилиты с нужными параметрами, позволяет нам получить готовую шейдерную библиотеку в compile-time. Просто прикрутим его в cmake и готово.
Но тут не всё идеально. У каждой из этих утилит имеется огромное количество рычажков, и узнать, какие нужны, а какие — нет, не так-то просто. Например, OSX, iOS на устройстве и iOS на симуляторе — каждый требует по-своему скомпилированную библиотеку. И подобных нюансов очень много. В процессе интеграции тот самый небольшой скрипт на питоне неплохо прибавил в размере за счёт большого количества ветвлений.
Теперь осталось найти гайд от рандомного индуса Apple с красивым названием вроде Metal Getting Started, как-нибудь инициализировать нужные ресурсы по методичке, что-то скопипастить, что-то прибить гвоздями, и вуаля:
А чо, надо было что-то настраивать?
Графические API предоставляют обширный инструментарий, которого мы пока никак не коснулись. Например, смешивание цветов, буфер глубины работают по конкретным правилам, которые задаёт пользователь. Как и с шейдерами, у каждого уникального типа объектов будет свой собственный набор этих правил. И каждый такой тип будет рендериться в рамках одного прохода отрисовки, который должен быть выставлен в состояние, удовлетворяющее этим правилам.
Следующий шаг довольно очевиден: поддержка выставления этого самого состояния в Metal.
В программировании графических движков есть одно простое, но очень важное правило: рендер-поток должен делать минимум вещей, чтобы как можно меньше блокировать появление следующего кадра на экране. То есть нам нужно максимально легковесно указывать каждому проходу отрисовки его состояние и параметры.
Давайте разберёмся, как можно подойти к этой задаче, используя наши графические API.
Все GL-ные вызовы выполняются над так называемым контекстом. Это огромный объект, который отслеживает состояние API, отправляет команды на GPU, работает с памятью и ещё куча всего. По сути является конечным автоматом, который переходит из одного состояния в другое. В Metal же весь этот контекст разделен на ряд объектов, каждый из которых делает какую-то свою одну работу:
Итак, у OpenGL есть большой монолитный контекст, и мы ограничены технологиями своего времени завязываемся на GLES 2.0, где в API ещё не появились отдельные объекты для настройки состояния. Если мы будем для каждого уникального прохода отрисовки создавать свой собственный контекст с уникальным состоянием, то получим солидный такой оверхед. Вместо этого перед каждой отправкой команд на отрисовку в GPU будем выставлять контекст в состояние, соответствующее проходу отрисовки. А ещё для каждого кадра отсортируем все команды по проходу, чтобы свести эти переключения к минимуму.
Metal же проповедует совершенно другой подход. Все его сущности в общем можно разделить на две группы:
Дескрипторы (в OpenGL они тоже есть, но там это простой GLint, который является идентификатором ресурса).
Скомпилированные объекты.
Концепция очень простая. Создание дескриптора и его компиляция — трудоёмкие операции, которые должны производиться разово (по возможности) при инициализации движка. Дескриптор, как понятно из названия, — простенький объект-описание. С ним ничего нельзя сделать, кроме как поменять это самое описание, и, в конечном итоге, скомпилировать из этого описания объект. В момент компиляции полученный объект становится ресурсом GPU, и изменить его больше нельзя, только изменять дескриптор и компилировать ресурс заново.
Таким образом, вместо одного общего контекста для каждого прохода отрисовки со своим уникальным состоянием, мы будем создавать собственный набор объектов, описывающих это самое состояние:

Теперь, когда мы с этим разобрались, остаётся несколько часов подряд погуглить, чтобы понять, как транслировать вызовы выставления опций проходов отрисовки из OpenGL в Metal, и всё, прототип готов:
Чота лагает
Картинка вроде не передаёт такой информации, но у прототипа была одна серьёзная проблема. В нем банально нельзя призумиться до уровня города. Почему? А просто не успеваем. Либо приложение падает из-за нехватки памяти или кучи аллокаций, либо подвисает на 1−2 секунды. Пока что сделаем вид, что память магически починится, и попробуем разобраться с блокировками. Для этого нужно понять, как API отличаются своим подходом к синхронизации команд.
Синхронизация вызовов в OpenGL
В общем случае утверждается, что команды отрисовки в OpenGL асинхронны. Это значит, что если пользователь вызывает какую-либо функцию glDraw*, нет гарантии, что отрисовка фактически завершится в момент выхода из функции. Вообще, вполне нормально, что он может даже не начаться. Однако API OpenGL построено на »as if» модели — все команды реализованы так, будто бы они являются синхронными. То есть реализации тратят кучу времени, отслеживая, какие вызовы что и где спродуцируют, чтобы, если пользователь сделал что-то, что требует ожидания на GPU, они могли это увидеть и подождать. Таким образом, каждая команда ведёт себя так, будто все предыдущие команды завершили свою работу. Рассмотрим на примере:
glDrawElements(...);
// ...
glReadPixels(...);
// Что-то делаем с прочитанными пикселями.
process_pixels(...);В рамках одного контекста мы сначала рисуем что-то, а потом копируем это в память приложения, чтобы как-то обработать всё это дело на CPU. glDrawElements в общем случае не будет блокирующим вызовом (нам ведь ничто не мешает просто нарисовать объект, правильно?), однако glReadPixels заблокирует поток. OpenGL после кучи своих внутренних проверок поймёт, что рендер таргет, из которого мы хотим прочитать данные, должен измениться в ходе выполнения предыдущих команд, и нужно дождаться их завершения.
Вдобавок к этому ещё придётся дождаться, пока чтение пикселей завершится — ведь API гарантирует нам синхронность. Да, API предоставляет возможность пользователю самостоятельно более гибко управлять синхронизацией, если интересно, можно начать читать отсюда, а я продолжу свой рассказ.
А чо там в Metal?
Один из ключевых объектов API — MTLCommandQueue. В целом он обладает только одной целью в своей жизни — создавать другой не менее важный объект (или несколько, если хочется) — MTLCommandBuffer. Каждый из них, по сути, — набор инструкций, которые Metal отправит на GPU для исполнения. Однако напрямую команды в него не записываются. Вместо этого он создает ещё один объект (это последний, честно) — MTLCommandEncoder, который как раз-таки и транслирует вызовы API в инструкции GPU и записывает их в «родительский» буфер команд. После записи нужных команд энкодер завершает свою работу и высвобождается, и потом можно будет создать новый инстанс энкодера для следующего набора команд.
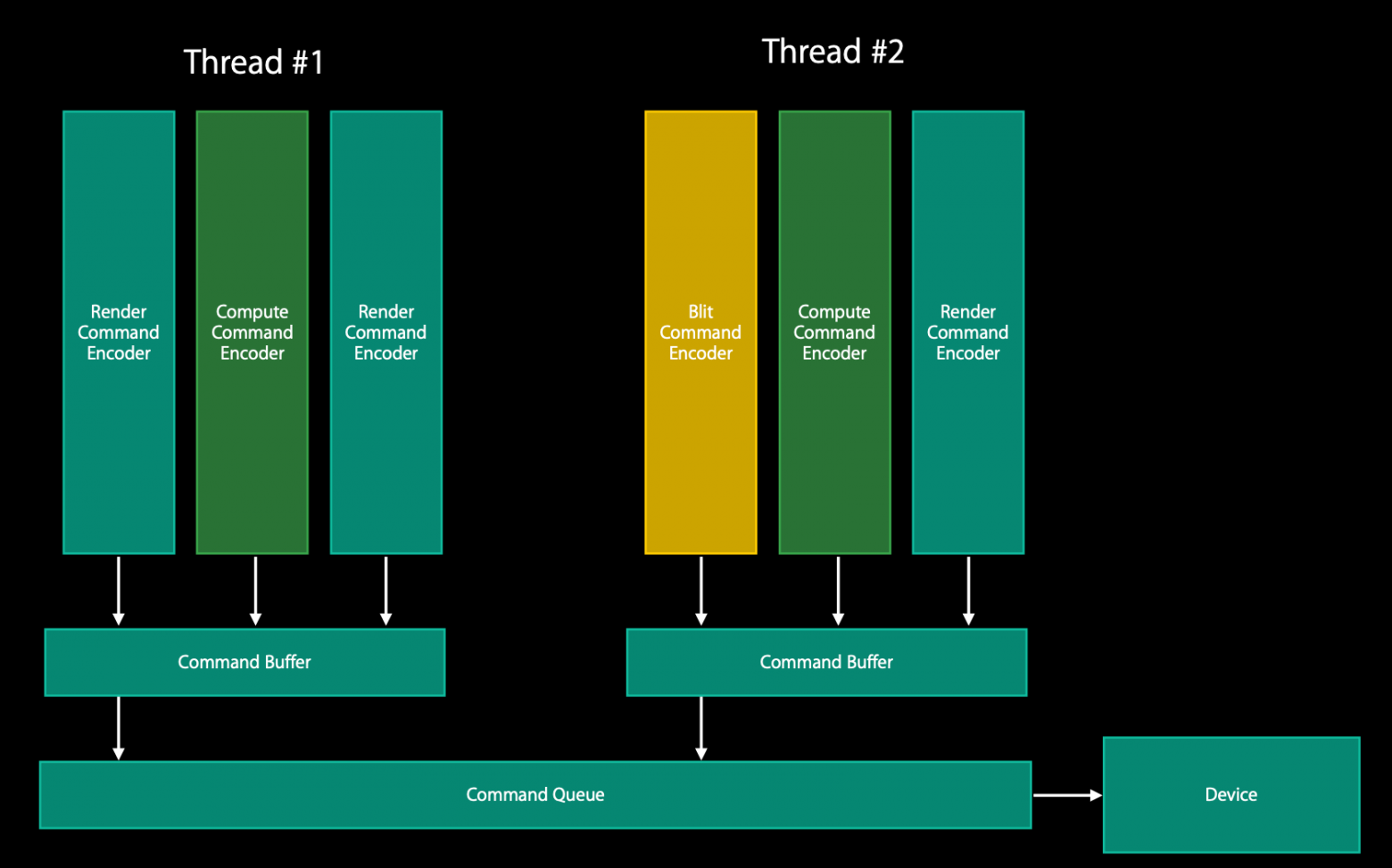
Кстати, энкодеров в Metal бывает 3 штуки:
MTLRenderCommandEncoder занимается выставлением состояния, байндингом объектов и отрисовкой.
MTLComputeCommandEncoder занимается диспатчем вычислительных шейдеров.
MTLBlitCommandEncoder занимается копированием текстур и буферов.
Теперь рассмотрим, как будет выглядеть тот же самый пример в Metal:
// Базовые объекты, создаваемые единоразово при инициализации движка.
device = MTLCreateSystemDefaultDevice();
command_queue = [device newCommandQueue];
command_buffer = [command_queue commandBuffer];
pass_descriptor = [MTLRenderPassDescriptor new];
// ...
// Создаем энкодер для отрисовки.
command_encoder = [command_buffer renderCommandEncoderWithDescriptor:pass_descriptor];
[command_encoder drawPrimitives: ... ];
// Высвобождаем, потому что буфер может иметь только один активный энкодер.
[command_encoder endEncoding];
// Теперь создаем буфер для копирования.
command_encoder = [command_buffer blitCommandEncoder];
[command_encoder copyFromTexture: ... ];
[command_encoder endEncoding];Внимательный читатель может спросить: «А куда в этом примере делась обработка пикселей?». Хороший вопрос. Штука в том, что на данный момент GPU ещё не сделал никакой работы. Для того, чтобы буфер отправил инструкции на GPU, и они начали исполняться, нужен еще один вызов API:
[command_buffer commit];Однако если мы прямо сейчас сохраним в файл то, что прочитали, с большой вероятностью получим какую-то такую ситуацию:

