В поисках обеда: распознавание активности по данным фитнес-трекера
Мне посчастливилось участвовать в проекте SOLUT, который стартовал в ЛАНИТ около года назад. Проект развивается благодаря активному участию Центра компетенции больших данных ЛАНИТ (ЦК Дата), и главное технологическое новшество проекта заключается в использовании машинного обучения для мониторинга человеческой активности. Основным источником данных для нас являются сенсоры фитнес-трекеров, закрепленные на руках работников. В первую очередь, результаты распознавания помогают поднять производительность труда и оптимизировать производственные процессы на стройке. Также анализ поведения рабочих позволяет отслеживать самочувствие человека, соблюдение техники безопасности и напоминает строителям про обед.

Источник
Строители на объекте используют наручные датчики, фиксирующие движения рук работников. Раз в день накопленные показания датчики переносят на сервер, расположенный на строительной площадке. На этапе сбора данных помимо сенсоров используются также видеокамеры, в процессе опытной эксплуатации используются только датчики. Полученные данные идут на разметку нашим профессиональным асессорам, используя которую мы работаем над моделями распознавания деятельности человека. Когда модель прошла тестирование и показала метрики качества высокого уровня, мы внедряем ее и распознаем ежедневный поток данных. У заказчика появляется возможность смотреть регулярные отчеты о деятельности сотрудников. Несмотря на простоту схемы, нам пришлось столкнуться с множеством подводных камней и неожиданных попутных задач, про которые и пойдет рассказ.
Проверка на коллегах
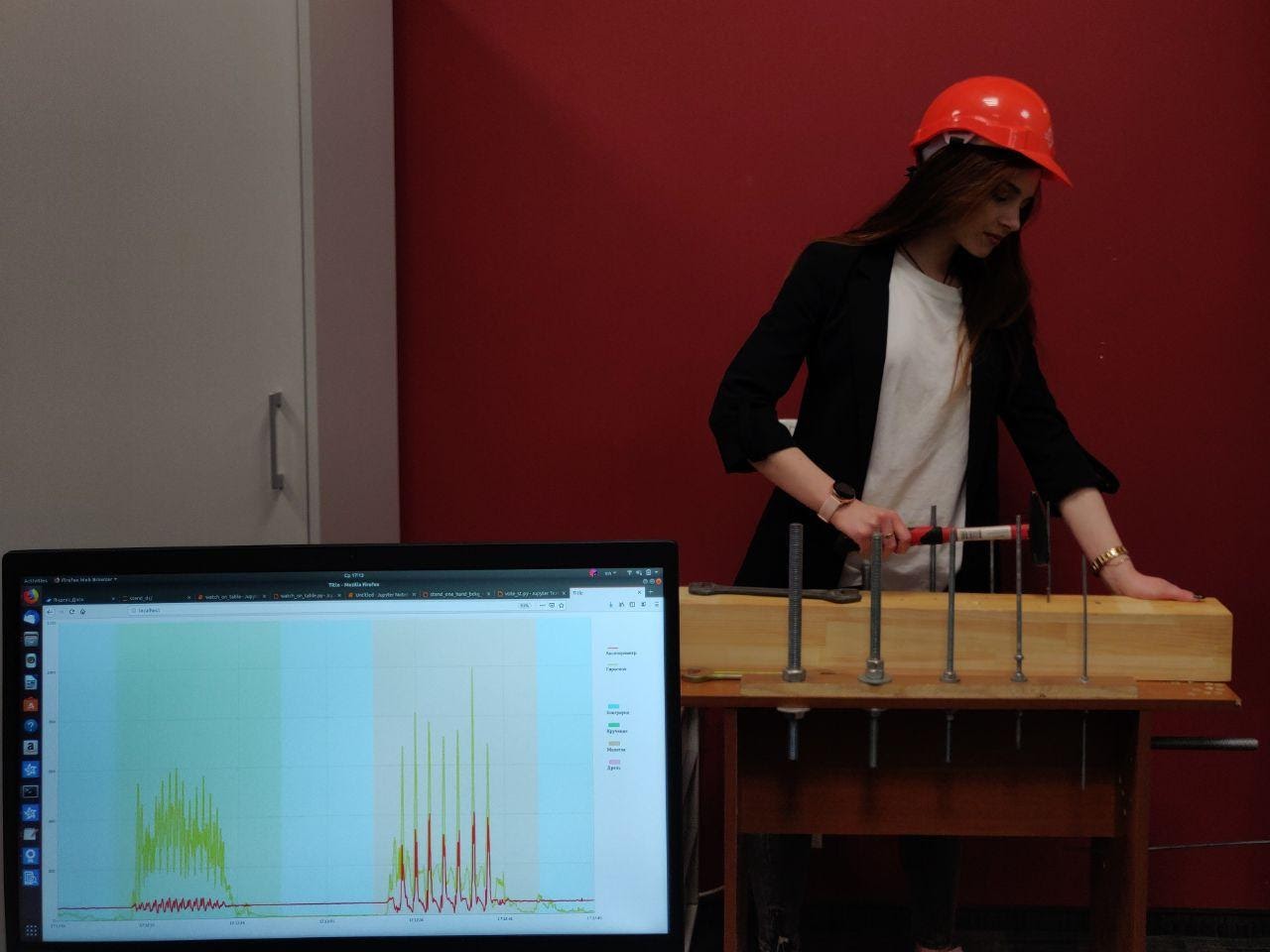
Проект начался с тестового стенда, организованного в офисе ЛАНИТ рядом со столовой. Он работал три месяца. У нас был большой поток добровольцев, готовых забить гвоздь, просверлить отверстие дрелью или закрутить пару гаек. Все эти действия человек совершал с браслетом на руке за импровизированным верстаком.

Источник
Мы перепробовали несколько вариантов фитнес-трекеров, позволяющих извлечь сырые данные, и остановились на одном из известных брендов. В первую очередь в нашей работе использовались показания акселерометра и гироскопа. Дополнительно мы используем данные GPS, барометра и пульсометра. Кстати, для измерения пульса используется прибор с интригующим названием фотоплетизмограф.

Источник
Акселерометр и гироскоп позволяли нам получать сырые показания в трёх осях координат с частотой 50 Гц, соответствующей периоду 0.02 с. Таким образом, для распознавания мы располагаем шестью временными рядами, однако по техническим причинам полученные ряды оказываются с пропусками и высоким уровнем шума. Если мы построим график, отражающий зазоры между последовательными измерениями, то получим следующую картину:
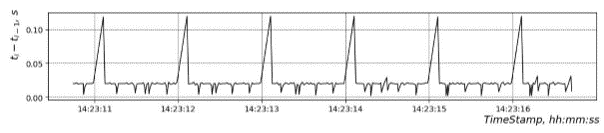
На графике видно, что в данных систематически проскакивает зазор в 0.13 с.
Проблема заполнения пропусков и шумов часто возникает в задачах, связанных с временными рядами и имеет множество решений. Решить проблему пропусков и шумов, при этом максимально сохранив информацию, нам помогли модели Гауссовского процесса. Этот подход хорошо себя зарекомендовал, в том числе и в работе с временными рядами в астрофизике (arxiv.org/abs/1908.06099, arxiv.org/abs/1905.11516).
Мы в очередной раз поняли, насколько важными при работе с моделями Гауссовских процессов являются настройки ядра. Задавая ядро Гауссовского процесса, возможно регулировать: крупномасштабную структуру временного ряда или мелкомасштабную будет использовать модель для аппроксимации и заполнения пропусков. Начать знакомство с этим подходом можно по примерам из документации sklearn. Возьмем следующий пример: чёрным цветом на графиках ниже выделены исходные данные, красным — средняя Гауссовского процесса, а голубым цветом обозначен доверительный интервал. На верхнем графике видно, что первая половина данных имеет периодическую структуру, которая не распозналась, т.к. не удалось выделить синусоидальную часть сигнала, хотя крупномасштабная структура была успешно аппроксимирована. При использовании подходящего ядра синусоидальную часть удалось аппроксимировать моделью во втором примере.
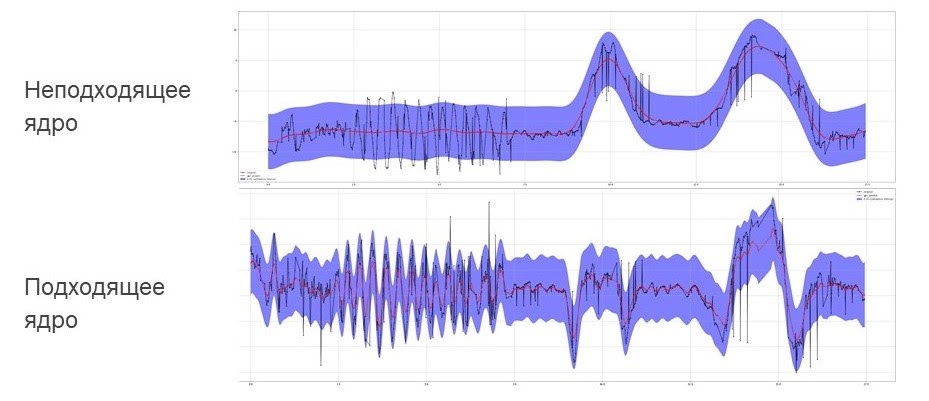
Пример подбора подходящего ядра гауссовского процесса. Чёрным цветом показаны исходные данные, красным — средняя Гауссовского процесса, а голубым цветом обозначен доверительный интервал.
После того, как была построена модель Гауссовского процесса, появилась возможность избавиться от шумов: если точки не попали в доверительный интервал, то они заменяются соответствующими точками из Гауссовского процесса.

Пример заполнения пропусков в данных
Естественно, что качество распознавания действий с помощью нейронной сети на данных с предварительной обработкой и без обработки данных будет отличаться. Так, например, в нашем случае взвешенная f1-мера вырастает с 0.62 до 0.84.
Добровольцы на нашем стенде могли видеть демонстрацию распознавания действий в реальном времени. Распознавание выглядело, как сегментация временного ряда с визуализаций показаний сенсоров фитнес-трекеров. Как видно, периоды бездействия чередуются с закручиванием гаек и, например, забиванием гвоздя.
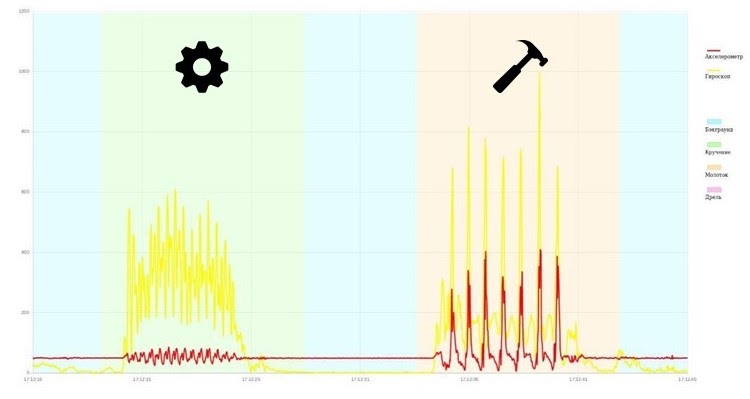
От тестового стенда мы перешли к проекту распознавания деятельности рабочих на стройке. Наши асессоры занимаются тщательной разметкой данных по видеозаписи рабочего процесса, таким образом мы располагаем разметкой данных и сводим распознавание типов деятельности к задаче классификации временных рядов.
Подготовка тренировочной выборки выглядит следующим образом: разбиваем многокомпонентный временной ряд на интервалы одинаковой длины, на каждом интервале выбираем метку класса, например, по максимуму суммы длин интервалов разметки, попавших в интервал разбиения.
В экспериментах на тестовом стенде мы сравнивали классические алгоритмы на автоматически сгенерированных признаках и нейронные сети. К удивлению, нейронные сети не смогли существенно обойти градиентный бустинг в нашем случае, что может быть связано с шумом в данных и весьма ограниченным объемом тренировочной выборки. Для нейронных сетей мы пробовали очищенные временные ряды, разностные схемы, спектрограммы, одномерные и двумерные сверточные слои, рекуррентные слои и многое другое. Однако лучший результат с минимальными трудозатратами достигается с помощью классификации градиентным бустингом из пакета lightGBM. Тем не менее, нейронные сети оказываются полезными в попутных задачах, например, в поисках обеденного перерыва, про который будет рассказано ниже.
Ошибки людей
В данных ожидаемо присутствует человеческий фактор, например, надевание часов «вверх ногами». Бороться с этим фактором оказывается легко: модель классификации с точностью более 90% определяет, правильно ли надеты часы на рабочем. В случае неправильно надетых браслетов линейное преобразование сырых данных дает возможность использовать те же самые модели распознавания активности.
Другим человеческим фактором в данных оказывается результат разметки асессоров: они также подвержены ошибкам. В этом случае помогают различные приемы и эвристики по чистке разметки.
Иерархия действий
В результате ряда экспериментов на стройке мы пришли к тому, что разделяем действия на два уровня.
- Нижний уровень, состоящий из элементарных действий. Пример: удар молотком, движение гаечным ключом. Характерный масштаб для интервалов нижнего уровня составляет около 5 секунд.
- Верхний уровень, состоящий из действий работника с точки зрения цели деятельности. Пример: подготовка к работе, работа штукатура, сварка и т. п. Характерный временной масштаб для интервалов верхнего уровня составляет около 30–60 секунд.
В итоге получается картина последовательных действий работника на протяжении всего трудового дня с детализацией до элементарных движений.


Примерный интервал работы — 5 минут
Поиск бездействия и обеда
В процессе работы над проектом стало понятно, что важны не только те действия, которые используются в рабочем процессе, но и действия, связанные с отдыхом, передышкой и т. д. Изначально этому вопросу не уделялось достаточно внимания, однако без возможности отличать работу от отдыха весь проект теряет привлекательность для заказчика. Мы работаем с элементами отдыха и бездействия как на уровне элементарных действий, так и в масштабе минут.
Естественно, модель имеет не идеальное качество, поэтому для минимизации количества ошибок оказывается полезным найти время обеденного перерыва работника. Зная интервал обеденного перерыва, возможно избежать ложных срабатываний на длительном периоде и, как следствие, значительно улучшить точность работы модели на этапе сдачи проекта. Кроме того, самим рабочим комфортно знать, что на обеденном перерыве их действия не распознаются, и они вольны отдыхать по своему усмотрению.
Асессоры не могут разметить обеденное время, так как оно не снимается на камеру. Было сделано следующее наблюдение: в начале и конце обеденного перерыва рабочие тратят некоторое время на перемещение от рабочего места до бытовки и обратно. Можно принять эти перемещения за границы обеденного времени.
Наборы и доли классов в рабочее и обеденное время различаются. Мы поняли, что определение обеденного перерыва возможно свести к решению задачи сегментации поверх результатов, полученных моделью верхнего уровня. Для решения этой задачи наша команда решила использовать нейронную сеть Unet. Отличная от классической Unet в том, что здесь все двухмерные операции заменены на одномерные, так как мы работали с временными рядами. Также добавлены слои Гауссовского шума и Dropout, чтобы минимизировать переобучение модели.
Подготовка данных для обучения
Поскольку задача сегментации решается поверх модели верхнего уровня, входные данные для Unet были выбраны в виде вектора 1024 * (кол-во классов). 1024 — так как интервалы ВУ модели — 30 секунд и рабочий день — порядка 8–9 часов.
На выходе вектор 1024×1 с бинарными значениями, (0 — интервал не относится к обеду, 1 — относится к обеду).

Так как данных немного (порядка 40 рабочих дней), была сгенерирована синтетическая выборка. День реальных рабочих разбивался на n-частей, и каждая часть относилась к одному из пяти классов: до обеда, начало обеда, обед, конец обеда, после обеда. Генерировался новый рабочий день набором случайных интервалов: сперва несколько интервалов из первого класса, затем один из второго, несколько из третьего, один из четвертого и несколько из пятого.

Схема разбиения временных интервалов на утренние (синие), обеденные (красные) и послеобеденные (зеленые). Из фрагментов распознанных действий на интервалах комбинируются синтетические данные для обогащения тренировочной выборки.
Для оценки качества анализа данных мы использовали меру Жаккара, в интуитивном понимании представляющую собой отношение пересечения и объединения множеств. В нашем случае аугментация позволила поднять качество с 0.98 до 0.99 меры Жаккара.

Все ли действия можно классифицировать?
На стройке могут происходить различные и зачастую непредсказуемые ситуации. В процессе реализации проекта на строительной площадке мы поняли, что если мы ограничимся фиксированным набором классов, то придется столкнуться с ситуацией, в которой будем использовать нашу классификацию на действиях, заведомо выходящих за рамки наблюдаемого поведения на обучающей выборке. Чтобы быть готовыми встретиться с действиями за рамками используемых классов, мы стали применять метод детекции аномалий. Детекция аномалий широко используется в задачах предиктивного обслуживания и для выявления поломок на ранних этапах в производстве. Детекция помогла нам найти:
- ошибки асессоров;
- нетипичное поведение рабочих;
- появление новых элементов в техническом процессе;
- выявление «подозрительных» работников.

«Подозрительные» работники
Если вы начинаете свое знакомство с методами детекции аномалий, то скорее всего придете к следующим наиболее популярных и простым моделям, реализованным в sklearn: OneClassSVM, Isolation Forest, Local Outlier Factor. Есть и более сложные способы (подробнее на эту тему писал ранее мой коллега).
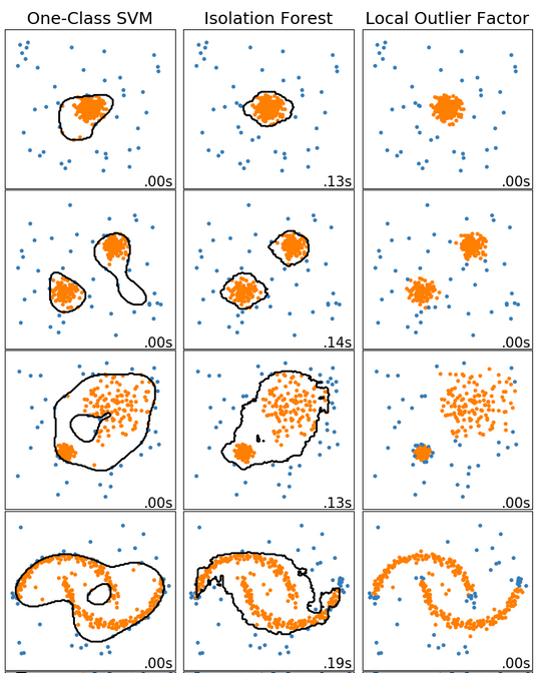
В реализации Local Outlier Factor есть возможность напрямую провести проверку на присутствие новых объектов в данных (Novelty detection). Если использовать метод Isolation Forest на тех же самых признаках, которые рассчитываются для основной модели классификации, то возможно получить «рейтинг нормальности» для каждого объекта: численную величину, характеризующую степень типичности для каждого объекта в выборке. Чем выше рейтинг, тем более типичным объектом в выборке является его обладатель. Распределение рейтинга нормальности выглядит следующим образом:
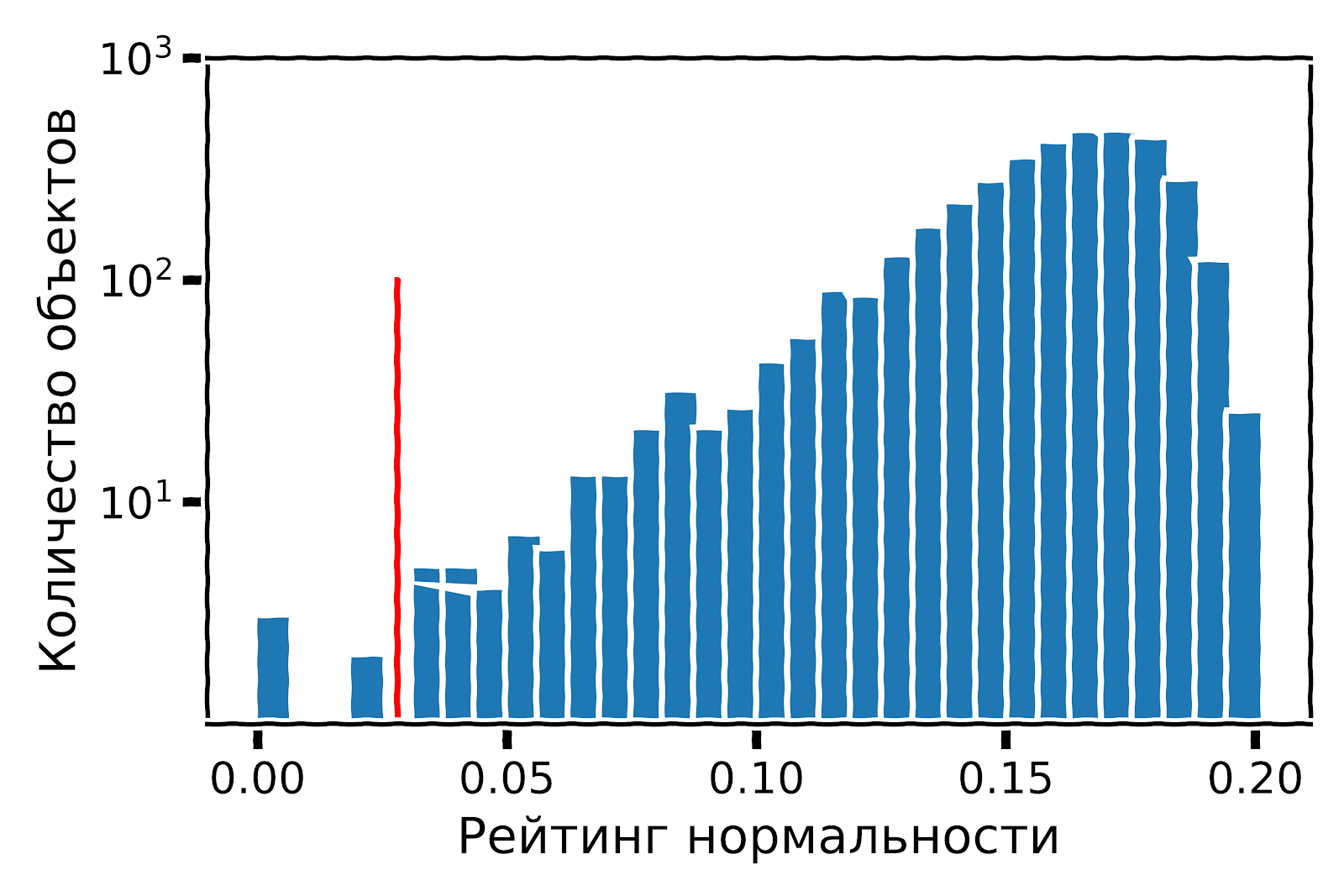
Для дальнейшего шага важно выбрать пороговое значение, начиная с которого по рейтингу нормальности будет возможно определить, является ли объект аномалией. В данном вопросе можно исходить из ожидаемой частоты появления аномалий, или выбрать пороговое значение по каким-либо дополнительным соображениям. Мы выбрали пороговое значение по распределению рейтинга нормальности: на рисунке видно, что, начиная с определенного значения, характер распределения меняется.
Важным моментом является следующее наблюдение: поиск аномалий удается продуктивно применять для каждого класса деятельности по отдельности, иначе редкие классы действий выделяются как аномалия.
Мы смогли разделить и выявить ряд аномалий для класса «перемещение», при этом асессор, проверявший выявленные интервалы, описал их следующим образом:
- работник положил рулетку и карандаш, взял одежду и одевается по пути (уже найдено перемещение за рамками типичных перемещений работников);
- работник пинает тележку ногами (опасная для здоровья деятельность);
- трясет головой с камерой, машет перед ней руками (действия, явно выходящие за рамки рабочих операций на объекте);
- производит манипуляции с датчиком на левой руке (некорректные действия).
У работы каменщика были зафиксированы следующие аномалии:
- работник зачем-то бьет молотком по неустановленным плитам (некорректные действия);
- ложится на пол, смотрит зазор между полом и панелью (нетипичное поведение);
- сначала пытается стряхнуть что-то с шапки, потом снимает ее и вытряхивает (действия, явно выходящие за рамки рабочих операций на объекте).
В ходе экспериментов с поиском аномалий нам удалось выявить один случай пьянства на рабочем месте: аномалии возникали у нетрезвого рабочего в интервалах времени, связанных с передвижением. Другим источником аномалий была работа штукатура-мужчины, в то время как в тренировочной выборке присутствовали только штукатуры-женщины.
Заключение
Мы продолжаем развивать проект и проводить различные эксперименты с нейронными сетями. Ждем того момента, когда нейронные сети обойдут градиентный бустинг. Планируем перейти от задачи классификации к задаче сегментации. Работаем над методами по очистки разметки асессоров, добавляем к данным показания новых сенсоров и экспериментируем с распознаванием совместной работы. Кроме того, мы расширяем область применения нашего мониторинга и осваиваем новые профессии.
С теми, кто дочитал статью до конца, хочу поделиться выводами, которые мы с командой сделали в процессе работы над проектом.
- При работе с физическими процессами необходимо обращать особое внимание на чистоту данных, так как в них могут быть всевозможные пропуски, выбросы и т.д. Одним из решений проблемы сырых данных может быть применение модели Гауссовского процесса.
- Хорошая аугментация может помочь поднять метрики качества модели. В аугментации можно идти от простого метода к более сложному:
○ различные перемешивания и склейки;
○ автокодировщики;
○ соревновательные сети (Generative Adversarial Networks), например arxiv.org/abs/1706.02390. - Если вы освоите один из инструментов поиска аномалий, то он может пригодиться на различных этапах Data Science проекта:
○ на этапе предварительного анализа удастся исключить выбросы;
○ на этапе разработки модели удастся найти объекты со спорной разметкой;
○ на этапе настройки мониторинга модели в промышленной эксплуатации удастся обнаружить моменты существенного изменения в данных по отношению к тренировочным.
Буду рад обсудить в статью в комментариях и с удовольствием отвечу на ваши вопросы.
Статья написана в соавторстве с olegkafanov.
