В нативный код из уютного мира Java: путешествие туда и обратно (часть 1)

Java и другие управляемые языки просты и удобны во многих случаях, но иногда их возможностей недостаточно — например, если нужна библиотека, написанная только на C или C++. Иногда хочется позвать пару методов из системного API, или попытаться улучшить производительность для модуля — и тогда прямой путь в нативный код.
Но тут возникают подводные камни: написать нативный метод и вызвать библиотеку может быть и легко, но JVM начинает крашиться в случайных местах, производительность падает, сборщик мусора перестает справляться с работой, а в репозитории царствуют бесконечные C-шные файлы с буквами JNI. Что же могло пойти не так?
Иван Углянский (dbg_nsk) из Huawei разбирается со всем по порядку: что необычного в интеропе между Java и нативным кодом, как оно работало раньше и что нужно делать для их нормальной совместной работы (и можно ли это вообще сделать). Иван рассказывает, как избежать просадок производительности, внезапных OOM и размышляет на тему будущего — в контексте проектов Panama и Sulong.
Мы подготовили текстовую версию доклада о работе с нативами в Java. В первой части:
- Зачем вообще работать с нативным кодом в Java.
- С какими ошибками и проблемами придётся столкнуться при работе с нативами.
Во второй части подробнее расскажем, какие есть варианты, что из них быстрее и лучше, и есть ли универсальная библиотека — всё с примерами кода и подсказками.
Далее — повествование от лица спикера.
Сегодня мы говорим про нативный код, про путешествие из Java в него и обратно. Дело в том, что я JVM-инженер, 7.5 лет работал в Excelsior, где мы делали собственную виртуальную машину Excelsior JET, а вот уже чуть больше года работаю в компании Huawei, в команде Excelsior@Huawei, где мы продолжаем заниматься своим любимым делом: компиляторами, JVM и новыми языками программирования.
В результате я довольно много копаюсь во внутреннем устройстве JVM, смотрю, как это устроено, правлю — в том числе, и в реализации связки JVM с нативным кодом. Поэтому сегодня хочу вам про это рассказать.
В Java есть такая интересная фича — вы можете написать методы без тел, зато со специальным ключевым словом native:
public class JavaToNative {
static native void goNative();
static native void goThere(Callback andBackAgain);
}Это означает, что реализацию этих методов стоит искать где-то ещё, например, в подгружаемых динамических библиотеках. И написана она может быть на каких-то других языках, например, на C/C++ или любом другом языке, где можно сделать C-like бинарные интерфейсы.
Бывают как простые сценарии, так и более сложные, что показывают уже методы на примере выше. Если вызываете первый метод goNative, то просто переходите из Java в C. А вот метод goThere позволяет перейти из Java в C, передать туда Java-объект callback и вызвать от него уже Java-метод.

Таким образом, во время исполнения вашего приложения в call stack могут чередоваться java и нативные фреймы.
Зачем нам нужны нативы
Java — замечательный managed-язык, в котором очень много всего сделано для вашего удобства.
Там есть автоматическое управление памятью, и вы, наверное, уже отвыкли от проблем, типа утечек памяти, висячих ссылок и прочего — всё это осталось где-то в районе C, а в Java есть GC, который с этим хорошо справляется.
И вообще Java — безопасный язык. Даже если вы, например, выйдете за пределы массива, вместо ужасного развала, как было бы в С, вы получите красивое исключение, которое можно обработать, понять, что произошло, и с этой ситуацией разобраться.
Получается, что Java — это такой Шир из Средиземья: абсолютно безопасное, удобное, приятное для жизни место, где все стараются сделать так, чтобы у вас всё было хорошо, и ничего не ломалось.
Если вы не будете выходить за его границы, то, скорее всего, ничего плохого действительно не произойдет.
А вот нативный код — это его полная противоположность. Это Мордор, где шаг влево-вправо, и вас сжирает горный тролль.
Но знаете, иногда нужно выходить из уютного Шира и идти в путешествие к Роковой горе.
На то могут быть различные причины. Первый тип мотивации — в мире огромное количество библиотек, написанных не на Java или подобных, а на C/С++ языках. От компьютерной графики OpenGL до машинного обучения Tensorflow, от огромного количества матбиблиотек до сертифицированной ФСБ библиотеки криптографии. Всё это не Java, а, скорее всего, С. И чтобы всё это использовать, нужно полагаться на механизмы нативных методов.
Кроме того, вы можете захотеть получить что-то напрямую от операционной системы. Допустим, вы хотите узнать, какой прокси стоит у вашего пользователя — напрямую из Java вы этого не сделаете, вам опять-таки нужно опуститься на уровень нативного кода и дёрнуть метод, например, из WinAPI в случае Windows.
Есть ещё одна мотивация. Многие люди привыкли думать, что Java тормозит, а вот C++ — это очень быстро. Поэтому если взять и переписать самый performance critical модуль проекта на плюсы, связать всё это через нативы, то получится огромное ускорение производительности. Почему эта мотивация довольно сомнительная, я покажу ниже, но в любом случае она присутствует.
Наконец, в самом JDK много чего реализовано через нативные методы. Поэтому вы в любом случае сталкиваетесь с этим каждый день, так что неплохо было бы понимать, как это работает.
И вот вы полны энтузиазма, написали своё приложение наполовину на С, наполовину на Java, запускаете, ожидаете, что сейчас всё ускорится, а в результате… получаете SIGSEGV, Exception_Access_Violation или ещё один SIGSEGV.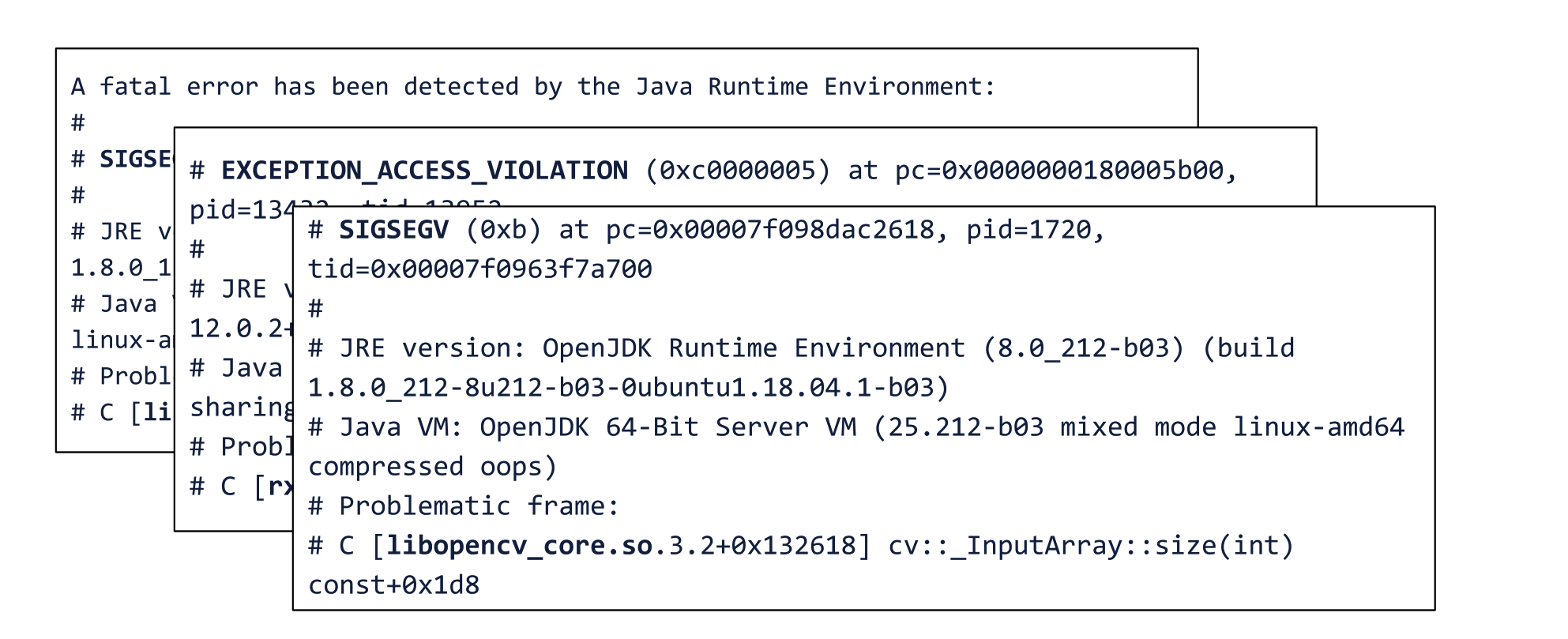
В общем, ваше путешествие из Шира в Мордор заканчивается очень быстро, как у Боромира. Развал страшный, выглядит так, будто вообще сломалась сама виртуальная машина. Некоторые даже репортят баги, мол, JVM развалилась.
На самом деле чаще всего проблема в том, что они неправильно используют нативы.
В этом посте я в первую очередь хочу разобраться, почему так много проблем, почему люди получают SIGSEGV с нативами, во-вторых, показать вам безопасный путь, как можно пройти из Шира в Мордор, не отстрелить себе ногу, и не получить SIGSEGV, чтобы всё было безопасно и хорошо.
По ходу повествования мы будем все время сверяться вот с такой картой «Как позвать натив?»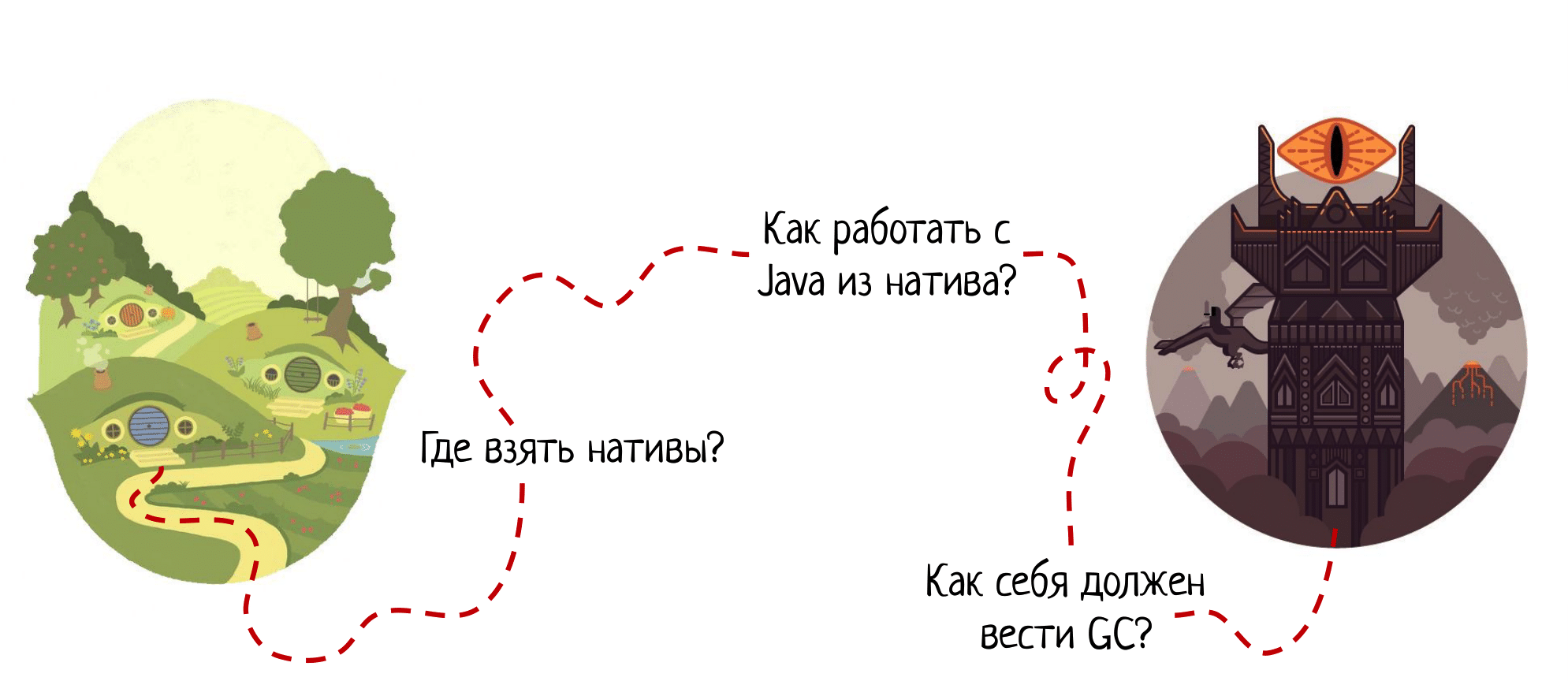
Если вы идете из Шира в Мордор, вам нужно ответить на три вопроса:
- Где виртуальная машина должна взять реализацию тех самых нативных методов?
- Если вы перешли в натив, то как вы можете взаимодействовать с Java-миром?
- Как сборщик мусора должен реагировать на тот факт, что какой-то поток взял и ушёл в натив, что с этим нужно делать?
Ответы на эти вопросы подсветят нам самые больные места в механизме нативных вызовов и помогут избежать проблем.
История до нашей эры
Сначала чуть-чуть истории.
Нативы можно было вызывать в Java ещё в самом начале, буквально в JDK 1.0 уже был Native Method Invocation, который позволял вызывать C-шные методы. Но он был заточен на детали реализации одной конкретной виртуальной машины, а именно на Sun JVM. На то, как там лежат объекты в памяти, какой сборщик мусора там используется.
Были и альтернативы. Например, Microsoft предлагала свой Raw Native Interface. Он был в чем-то лучше, в чем-то хуже, но тоже работал только с одной виртуальной машиной — теперь уже Microsoft J++.
Были попытки сделать нейтральные решения, как у Netscape, но в целом это были тёмные времена. Когда вы писали натив, вы не могли быть уверены, что это будет работать на всех JVM или хотя бы на каких-то.
Наша эра: JNI — Java Native Interface
Наша эра начинается с появления знаменитого Java Native Interface или JNI. Это был единый интерфейс, чтобы править всеми, и он был прекрасен, потому что был JVM нейтрален.
Он никак не затачивался на то, как сделана конкретная виртуальная машина, не важно, какая раскладка по объектам в памяти, неважно какой GC.
Если виртуальная машина поддерживает JNI, гарантируется, что ваш натив там заработает. Далее я буду говорить про JNI много плохого, но хочу акцентировать внимание: на тот момент это был огромный прогресс для всей отрасли, наконец-то мы могли писать нативы без страха, что они где-нибудь не заведутся.
Давайте посмотрим, как это работает.
Со стороны Java всё выглядит довольно мило, вы это уже видели.
public class JavaToNative {
static native void goNative();
static native void goThere(Callback andBackAgain);
public static void main(String[] args) {
System.LoadLibrary("NativeLib»);
goThere (new Callback("Eagles»));
}Пишем методы без тела, пишем где искать реализацию, например, в System.LoadLibrary говорим подгрузить dll-ку, и после этого просто вызываем этим методы и переходим в С или С++.
Callback — это просто класс, у которого есть метод call, ничего не возвращающий, который печатает строку «Ok, we are in Shire again!», в моём случае мы вернулись в Шир на орлах.
Как получить заголовку функций?
Теперь давайте попробуем написать нативную часть на языке С.
Здесь всё будет уже не так красиво, но нам нужно это сделать.
public class JavatoNative {
static native void goThere (Callback and BackAgain);
}Допустим, у вас был какой-то класс, где вы описали нативный метод без тела. Чтобы получить реализацию вы в первую очередь компилируете его с помощью javac с флажком -h.
javac JavaToNative. java -h .В таком режиме javac ищет все нативы и генерирует сишный .h-файл с заголовками соответствующих уже сишных функций.
В результате мы получаем JavaToNative.h со всеми заголовками, но при этом то, что там написано, не очень-то похоже на нашу функцию.
JNIEXPORT void JNICALL Java_JavaToNative_goThere
(JNIEnv *, jclass, jobject);Здесь появились какие-то заклинания типа JNICall. Здесь совсем другое имя метода: оно содержит еще и package и имя класса. И сигнатуры отличаются! У нас был 1 аргумент типа Callback, а здесь их уже три и они совсем другие.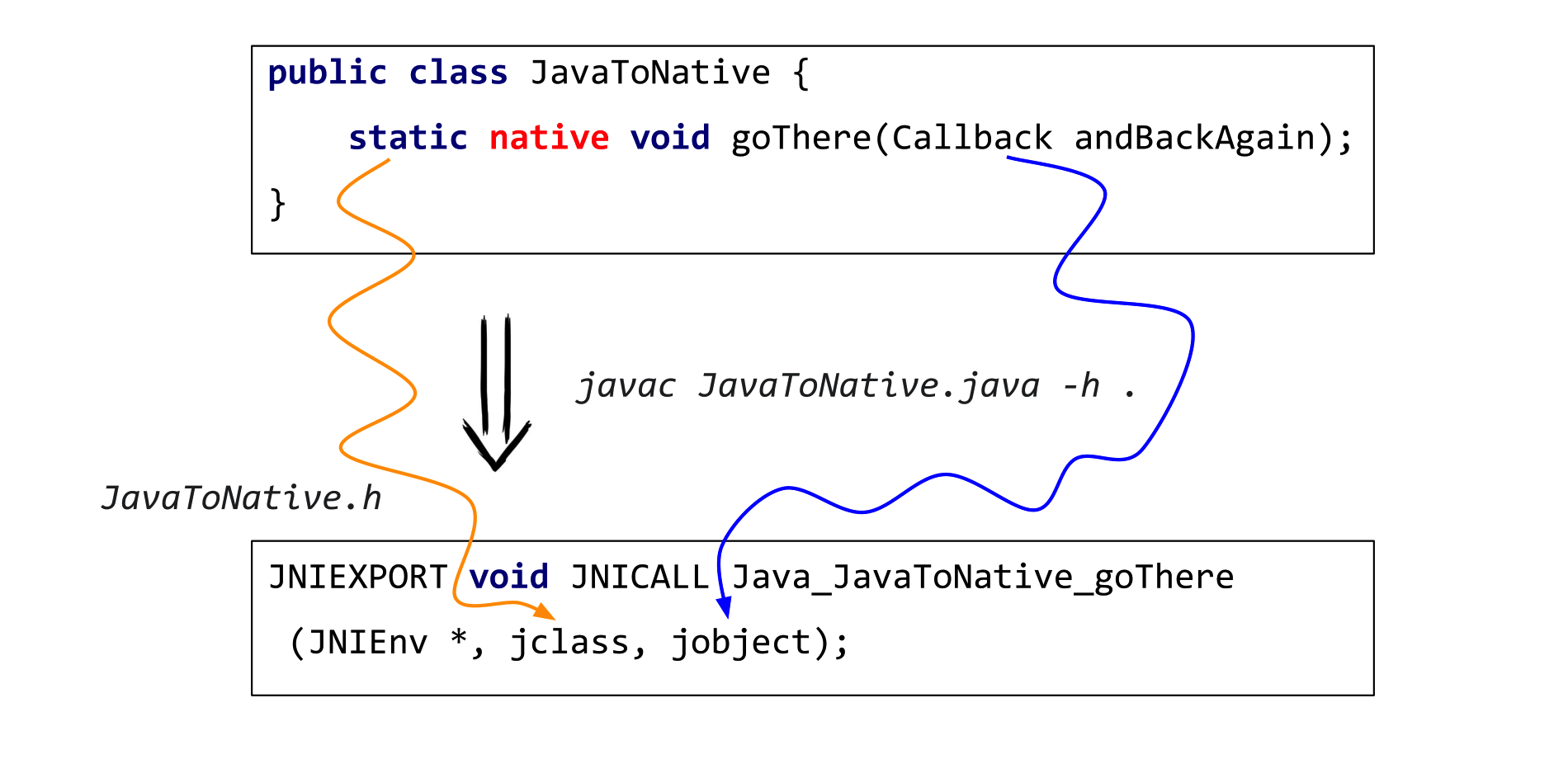
Что за аргументы?
jclass появился, потому что натив был статическим и этим параметром передается Java-класс, чей статический метод вызывается. Callback превратился в jobject и появился новый JNIEnv со звёздочкой (про него чуть позже).
Правила, по которым генерируются заголовки, очень четкие и описаны в JNI-спецификации. Все примитивные типы превращаются в соответствующие примитивные C-шные (заданные макросами и базирующиеся на С-шных примитивных типах), все референс-типы превращаются в jobject или в редких исключениях в его наследников — jclass, jstring, jthrowable, jarray.
Это ответ на первый вопрос в нашей карте — как виртуальная машина должна находить реализации методов. Она это делает по именам, знает все эти правила и в подгруженной библиотеке ищет соответствующие правильно называющиеся нативные методы.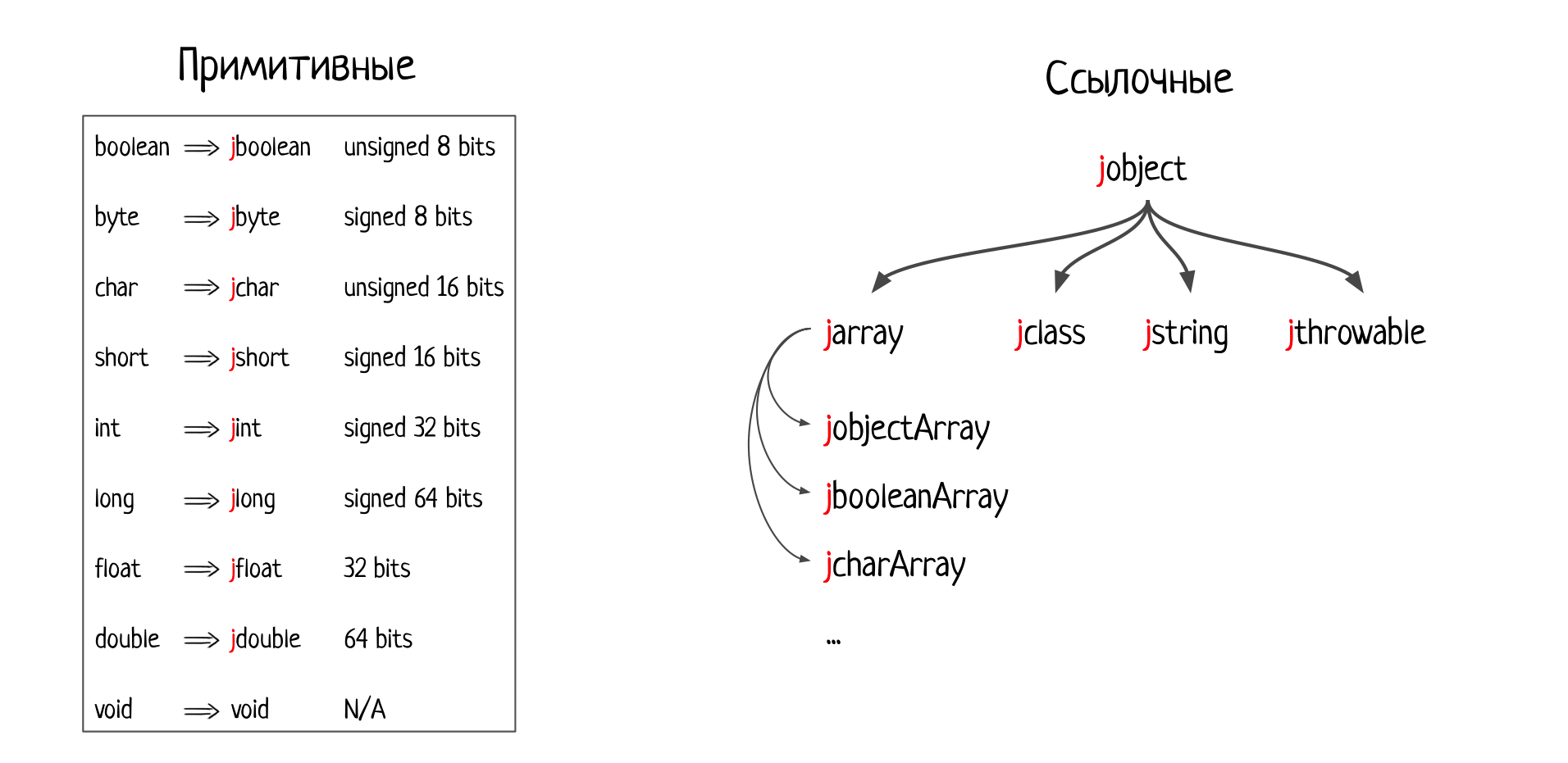
Даже если вы хорошо знаете JNI спецификацию, не советую вам руками писать эти заголовки, javac замечательно справляется сам, если указать ему -h. Так что лучше использовать его, чтобы свести к минимуму человеческий фактор.
Что за JNIEnv?
Аргумент JNIEnv * — это указатель на таблицу из 214 специальных функций, которая называется JNINativeInterface.
Вот некоторые из них: 
А вот некоторые важные из них, которые, скорее всего, чаще всего используются.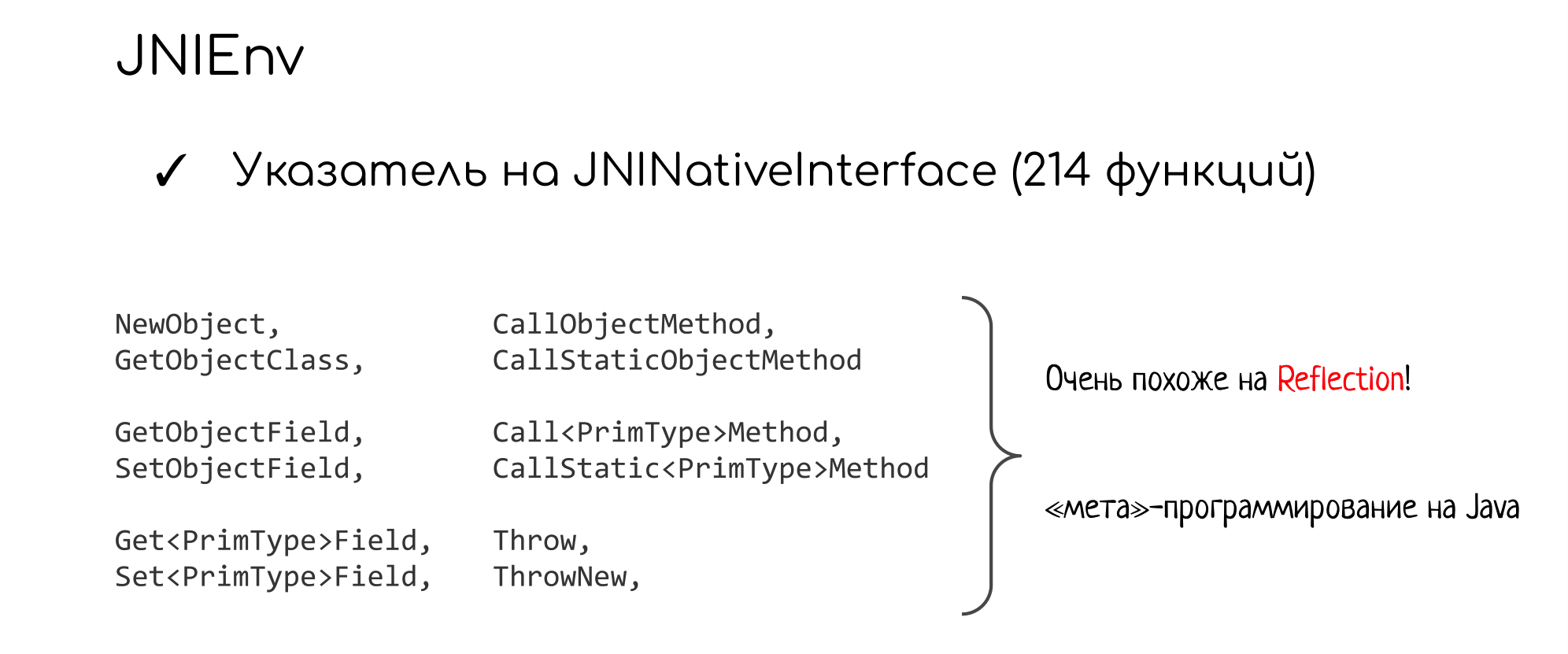
JNINativeInterace помогает нам программировать на метауровне — как будто бы на Java, но используя мета-сущности: handle для классов, методов и так далее. Например здесь вы можете получить handle Java-класса, через него создавать его экземпляры (Java объекты), вызывать Java методы через специальные функции Call*Method, выбрасывать исключения.
Это очень похоже на рефлексию, только вы занимаетесь этим не в Java-коде, а в C.
Все эти функции JNI-интерфейса — единственный способ хоть как-то взаимодействовать с Java-миром: либо с объектами, либо просто получить информацию от виртуальной машины.
И это ответ на второй вопрос в нашей карте: как взаимодействовать с JVM. Вот так — через 214 функций, которые являются вратами в Шир.
Теперь давайте напишем нашей функции тело.
/*
* Class: JavaToNative
* Method: goThere
* Signature: (LCallback;)V
*/
JNIEXPORT void JNICALL JAVA JavaToNative goThere (JNIEnv * env, jclass klass, jobject andBackAgain) {
printf("ok, we are in Mordor now! \n");
jclass cls = (*env) ->GetObjectClass (env, andBackAgain);
jmethodID method = (*env)->GetMethodID(env, cls, "call", "()V");
(*env)->CallVoidMethod(env, andBackAgain, method);
}Делаем .c файл, копируем туда наш заголовок из .h, открываем фигурные скобки и начинаем писать обычный C-шный код. В первую очередь я printf-ом напечатаю, что мы пришли в Мордор, а потом я хочу вернуться в Java, позвать Callback.
Для этого я получаю jclass, соответствующий классу моего аргумента, нахожу в нём метод, который называется call, возвращающий void, и вызываю этот метод с помощью JNI-функции CallVoidMethod. Должна напечататься строка, что мы вернулись на орлах и всё ок.
Как все это собрать?
Наконец, давайте обсудим, как все полученное ранее собрать.
Я использую Windows, поэтому гуглю заклинание, как собрать нативную библиотеку для JNI на этой системе: 
В результате у нас получается библиотека NativeLib.dll.
Это, конечно, довольно неприятно с точки зрения кроссплатформенности. Потому что, если вы собираете библиотеку для Linux или macOS — заклинания будут другими.
К счастью, есть замечательные тулы, которые позволяют от всего этого абстрагироваться. Например, Nokee plugins. Это кроссплатформенное решение, которое позволяет удобно добавить таргет в gradle скрипт и в результате собрать библиотеку под интересующие вас платформы.
Окей, тем или иным способом мы библиотеку собрали, после чего запускаем наше Java приложение, и получаем…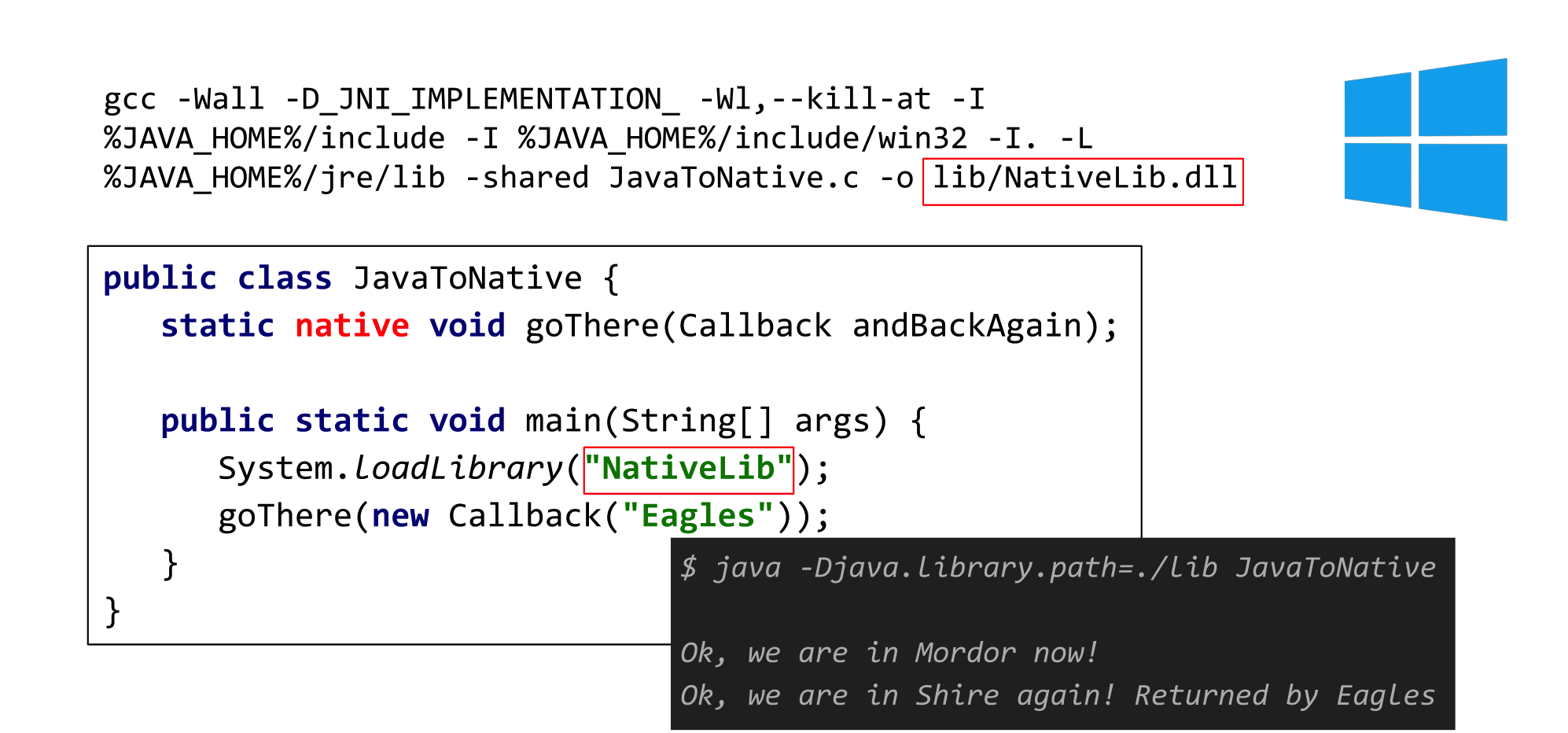
Ура, мы только что совершили свое первое путешествие в Мордор и вернулись обратно. Теперь давайте поговорим, что же при этом может пойти не так. Кроме того, что нам пришлось пописать на не самом приятном языке C, да и выглядит это все довольно ужасно.
Что может пойти не так?
А пойти не так может очень много вещей…
В первую очередь, когда вы переходите в нативный код, вы теряете статическую типовую информацию.
Да, вы передавали объект callback, но он превратился в jobject, и какой был тип изначально — сходу не видно.
Допустим, у меня был бы какой-то другой аргумент, теперь уже java.lang.Object. И он бы тоже представлялся в нативном коде, как jobject, а потом я могу совершенно случайно по невнимательности позвать CallVoidMethod, передав туда в качестве аргумента не Callback, а какой-то java.lang.Object и попытаться из него позвать метод call (которого там, конечно, нет).
Меня не остановит компилятор, не остановит runtime ровно до тех пор, пока не случится развал из-за попытки позвать call от java.lang.Object.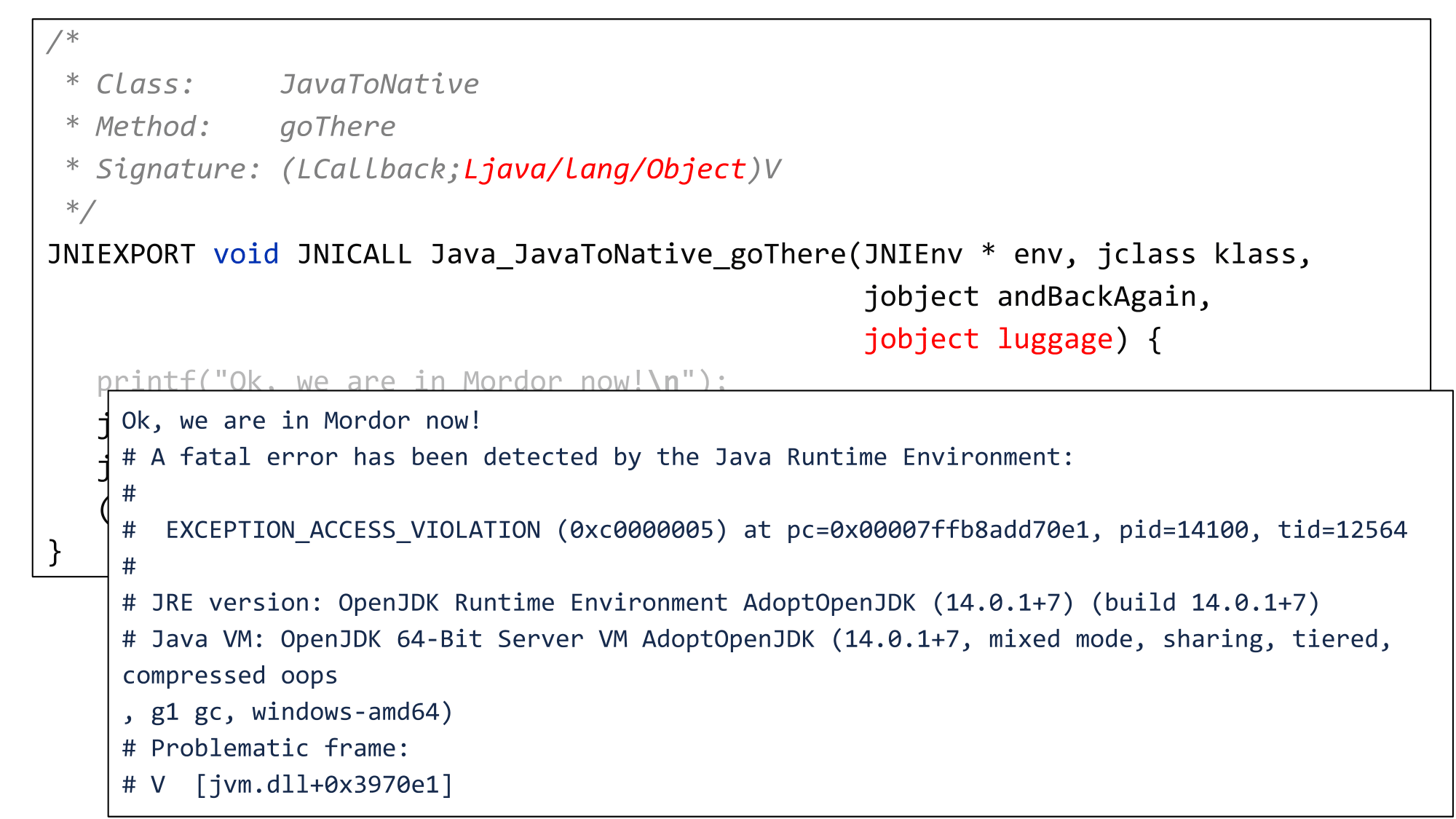
Абсолютно похожая история с тем, какую конкретно JNI-функцию вы вызываете. Никто не проконтролирует, что вы используете именно СallVoidMethod, а не CallBooleanMethod или CallStaticVoidMethod или ещё что-то — это будет ваша ответственность. Если вы ошиблись, то случается неопределенное поведение (прям как в плохих программах на С), что начнет делать виртуальная машина — неизвестно.
Еще один момент, на который стоит обратить внимание: когда вы вызываете из натива Java-метод, он вполне может выбросить исключение, после чего исполнение возвращается в натив. В Java мы привыкли, что необработанное исключение автоматически пролетает дальше, ничего дополнительного делать не нужно. Но в данном случае это снова ваша ответственность! Вы должны проверить, а не случилось ли при вызове Java-метода исключения (с помощью функций ExceptionCheck или ExceptionOccurred), и если так, то обработать его здесь (с помощью ExceptionDescribe и ExceptionClear). Если же вы этого не сделаете, то в следующий раз, когда исполнение придет в Java-код, это исключение полетит уже совсем из другого неожиданного для вас места, и вы снова получите некорректное поведение.
К счастью, 90% подобных проблем с нативами помогает решить волшебная опция: -Xcheck: jni.
Возьмем наш пример, где мы подставляли неправильный аргумент, и запустим с -Xcheck: jni.
Вместо страшного и ужасного развала вы получите привычное исключение с понятным stacktrace, где будет написано, что вы перепутали MethodID или же используете не тот объект при вызове (что, собственно, у нас и происходит!).
Это помогает быстро понять проблему и разобраться в большем проценте ошибок с нативами.
Конечно, не стоит всегда добавлять -Xcheck: jni. Это утяжеляет реализацию JNI-функций, но я очень рекомендую хотя бы в отладочных билдах прогнать приложение с ней. Она напишет вам кучу warning, возможно, сколько-то ошибок, и, после того, как вы все это поправите, вы получите относительно надежное приложение, работающее с нативным кодом.
Это не означает, что будут вылечены все проблемы, но все самые простые — да.
Garbage Collector и Native-код
А теперь поговорим про последний пункт в нашей карте — как GC должен взаимодействовать с нативным кодом.
Почему про это вообще нужно говорить? Дело в том, что в Java коде, когда JVM нужно пособирать мусор, она приостанавливает Java потоки в специальных сгенерированных компилятором точках, которые называются GC safepoints. Давайте для простоты рассматривать случай StopTheWorld-коллекторов. В таком сценарии только после того, как все Java-потоки достигли ближайших safepoints и приостановились, начинают работать GC-треды, которые, собственно, собирают мусор.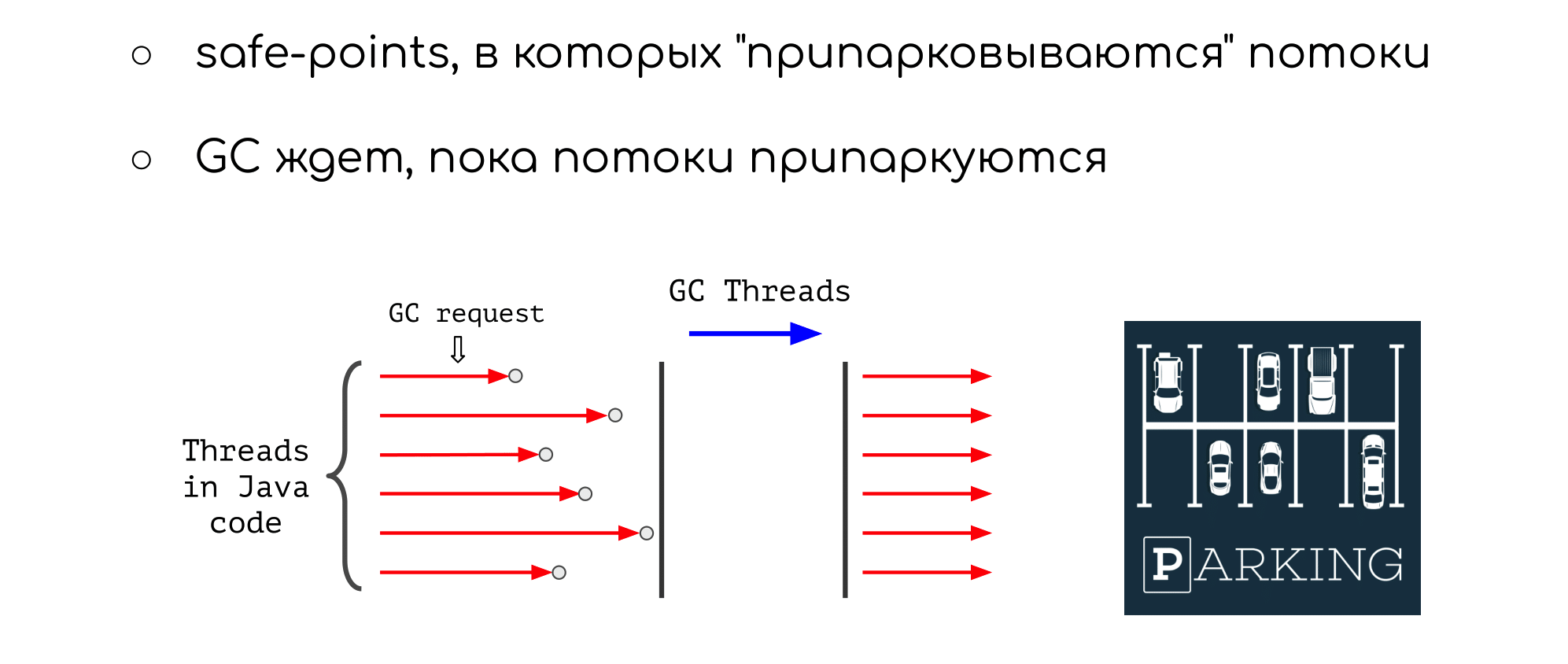
Это важно, потому что GC может двигать объекты во время своей работы. Для компактизации кучей, для своих каких-то целей — неважно. Если в этот момент кто-то из Java-тредов будет смотреть и взаимодействовать с Java хипом — читать или записывать поля некоторого Java объекта, то может случится неприятная ситуация: этот объект просто украдут у него из-под носа и перенесут в другую часть памяти. В результате вы получите некорректное поведение (например, развал).
Так вот проблема с safepoints в том, что в нативном коде такой фокус не пройдет.
Safepoints вставляют компиляторы из JVM, а если это какой-то внешний код, например на C или C++, скомпилированный clang-ом, то там нет никаких safepoint! В результате, мы просто не сможем остановить наши потоки, которые исполняют натив, чтобы пособирать мусор. Поэтому мы вынуждены смириться с тем, что нативы будут работать параллельно со сборкой мусора.
И тогда схема меняется так: появляются новые действующие лица, треды, исполняющие нативный код. Допустим, они ушли в натив до того, как нам потребовалось пособирать мусор, и вот они спокойно будут работать параллельно с GC-тредами.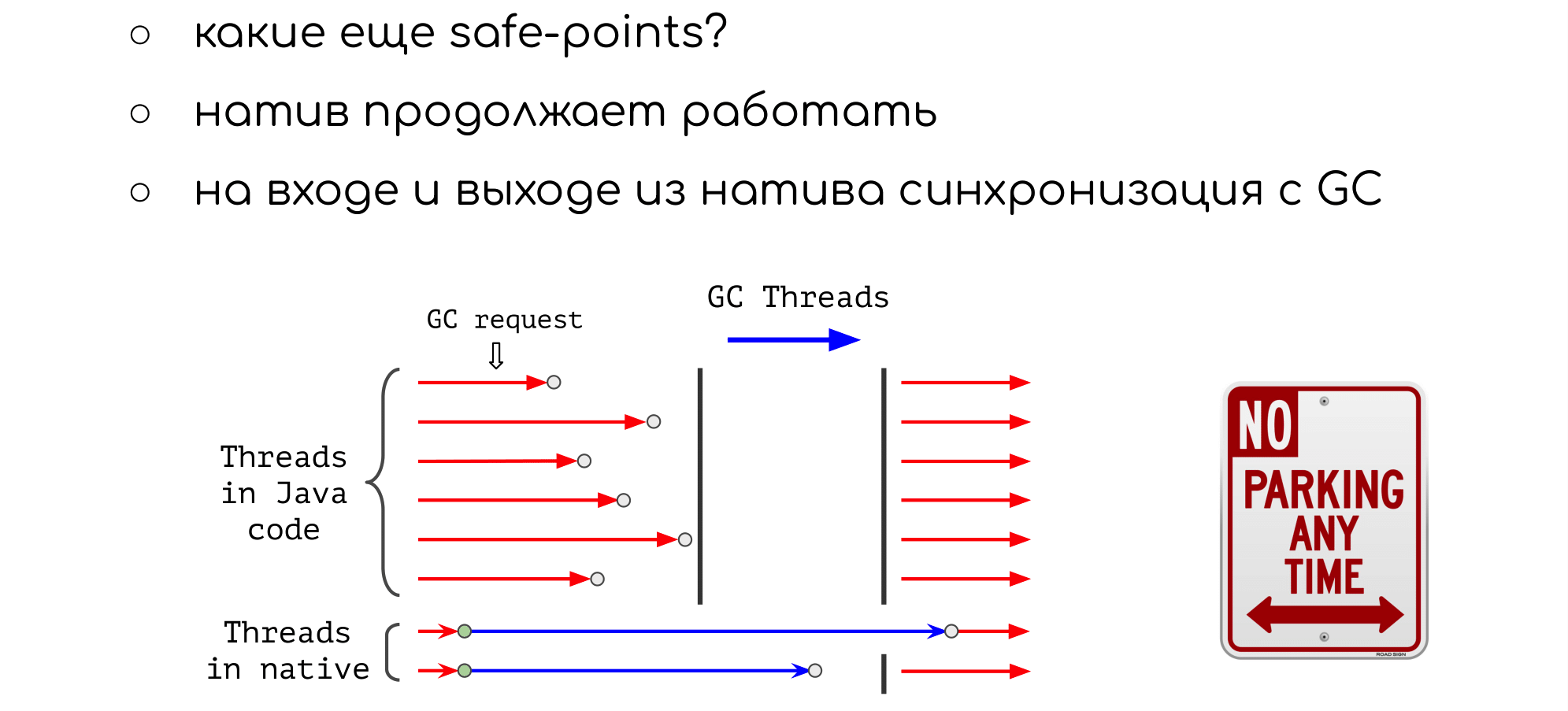
Есть ограничения. На входе в натив нам нужно сказать сборщику мусора: мы ушли в натив, не жди нас, спокойно собирай мусор. На выходе надо проверить, а не идет ли сейчас сборка мусора, и если идёт — приостановиться.
Но при этом всё ещё возникает проблема: даже в нативе вы не имеете права трогать Java-объекты, которые сейчас может взять и двигать GC.
Как вы помните, все наши Java-объекты в нативах почему-то превратились в jobject.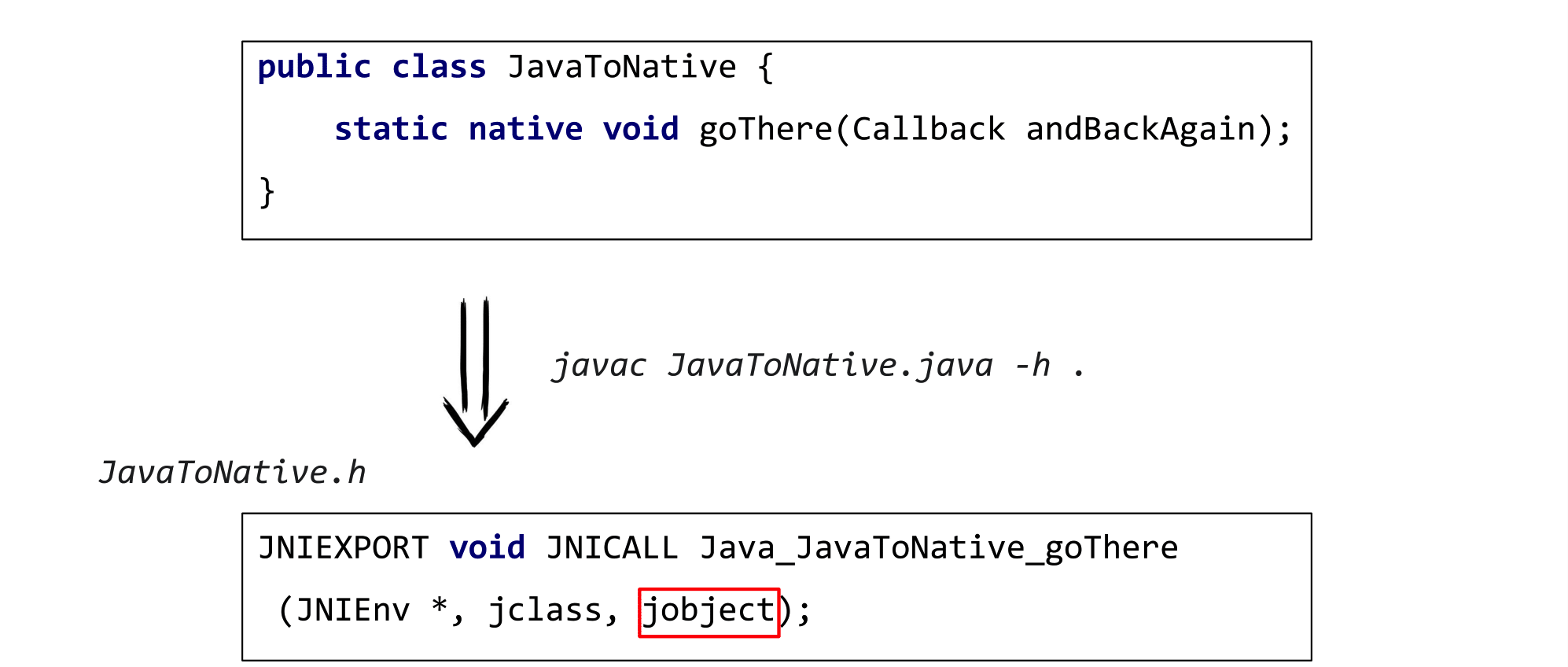
Оказывается, что jobject — не просто маппинг для Java-ссылок, а специальные низкоуровневые хендлы, которые внутри инкапсулируют адрес на реальный Java-объект.
Гарантируется, что Java-машина поддерживает связь этого адреса с реальным адресом объекта. То есть, если мы подвинули объект, то соответствующий jobject тоже будет пропатчен автоматически.
С другой стороны, единственный способ повзаимодействовать с Java-миром из натива — это JNI-функции, которые также работают с jobject. Почти во всех из них стоит синхронизация с GC, так что вы не сможете сделать с объектами ничего плохого, пока идет сборка мусора.
Если последним использованием ваших объектов была передача их в нативный код, то гарантируется, что за время исполнения этого натива их никто не соберет. Эти jobject являются своеобразными GC-root, что гарантирует выживание объекта.
Поговорим о том, какие проблемы это может вам доставить.
JNI References
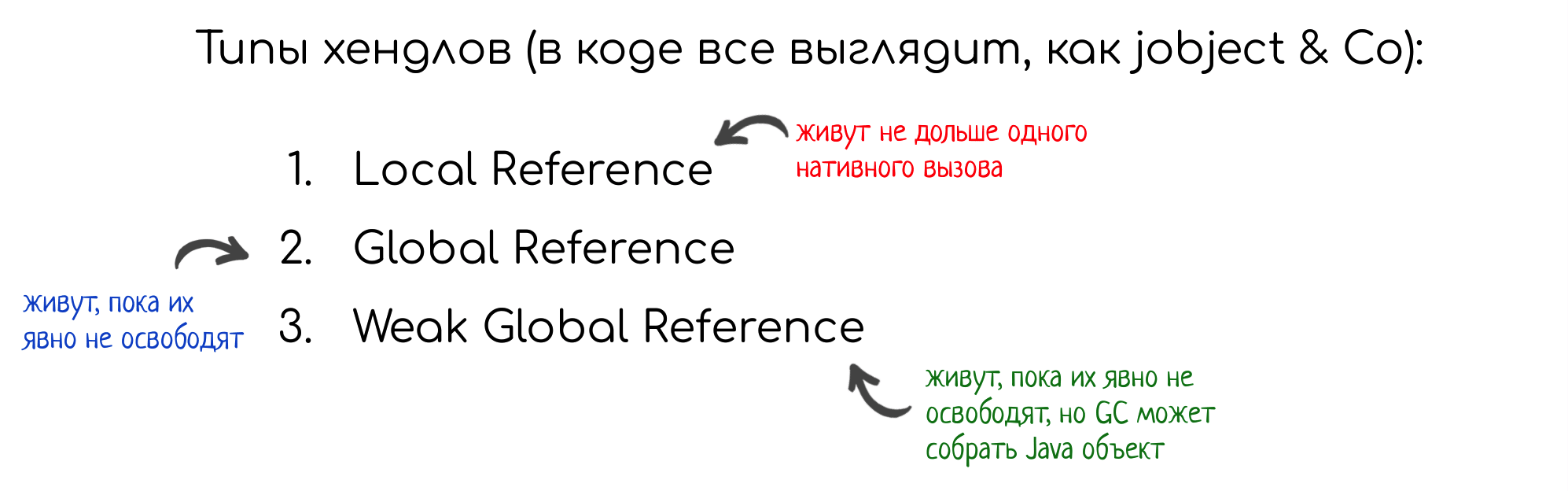
Первая и главная проблема в том, что для хендлов реализована альтернативная система управления памятью. Это не похоже ни на Java, ни на C, скорее, что-то среднее между ними. Всё, что вы в коде видите, как jobject, на самом деле является сложным объектом JNI Reference, причем они бывают трех разных типов.
Во-первых, local references.
Они называются так, потому что они существуют не дольше, чем исполняется нативный метод, в котором был создан local reference (полная аналогия с локальными переменными).
Они интересны, во-первых, тем, что большинство JNI-reference — это именно LR. Передали какие-то Java-аргументы в натив — они автоматически заворачиваются в локалрефы, вызываете JNI-функцию, создающую объект — из нее тоже вернется локалреф. А во-вторых, с этими штуками, несмотря на, казалось бы, очень естественную и простую схему очистки, чрезвычайно легко получить утечку памяти.
Продемонстрирую это на небольшом примере:
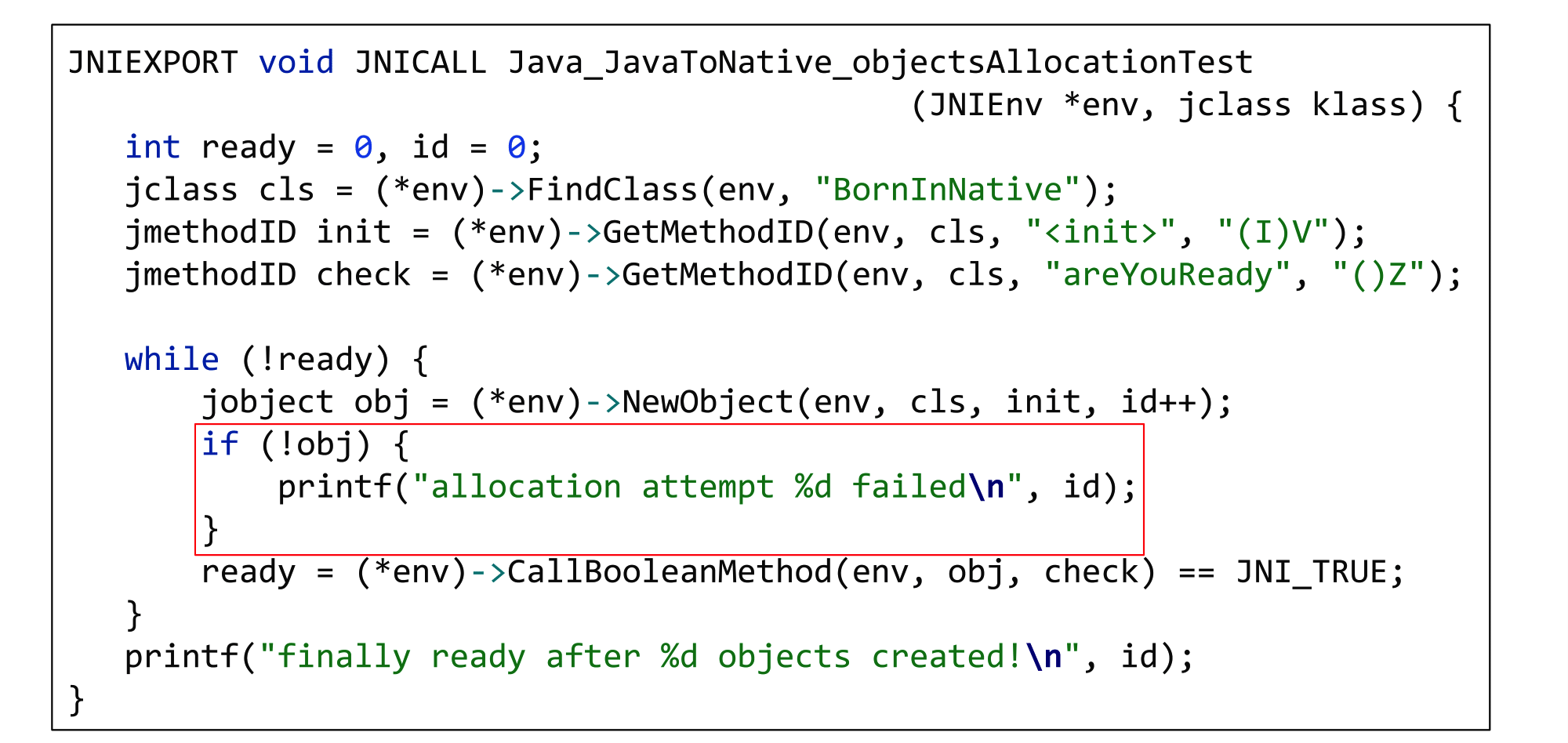
JNIEXPORT void JNICALL Java_JavaToNative_objectsAllocationTest (JNIEnv *env, jclass klass) {
jclass cls = (*env)->FindClass(env, "BornInNative");
jmethodID init = (*env)->GetMethodID(env, cls, "", "(I)V");
jmethodID check = (*env)->GetMethodID(env, cls, "areYouReady", "()Z");
int ready = 0, id = 0;
while (!ready) {
jobject obj = (*env)->NewObject(env, cls, init, id++);
ready = (*env)->CallBooleanMethod(env, obj, check) == JNI_TRUE;
}
printf ("finally ready after %d objects created!\n", id);
} Здесь мы будем аллоцировать в огромных количествах объекты прямо из нативного кода. Для этого находим соответствующий класс BornInNative с помощью JNI-функции FindClass, а получаем конструктор и метод-предикат, который будет говорить по соответствующему инстансу, нужно ли создавать следующий объект или нет. А потом просто в нативном коде с помощью JNI-функции NewObject начинаем эти объекты создавать.

NewObject аллоцирует память, вызывает конструктор, который создает объект и возвращает в нативный код ту самую local reference, которую затем сохраняем в переменную obj типа jobject. От неё вызываем предикат, чтобы понять, нужно ли дальше аллоцировать объекты или нет.
Вот если вы написали такой код на Java, у вас бы не возникло сомнений в том, что здесь всё хорошо с управлением памятью. Как только проходит очередная итерация цикла, созданный на этой итерации объект уже никому не нужен, а значит, GC когда-нибудь придёт и соберет его, например, если памяти будет не хватать для очередной аллокации.
На Java бы всё работало, но в нативном коде вам такого никто не гарантирует. Про Local reference гарантируется, что они умирают не позже, чем возврат из нативного метода. Но это и все: сами по себе от того, что вы переназначили переменную на другую LR, они умирать не обязаны и не будут.
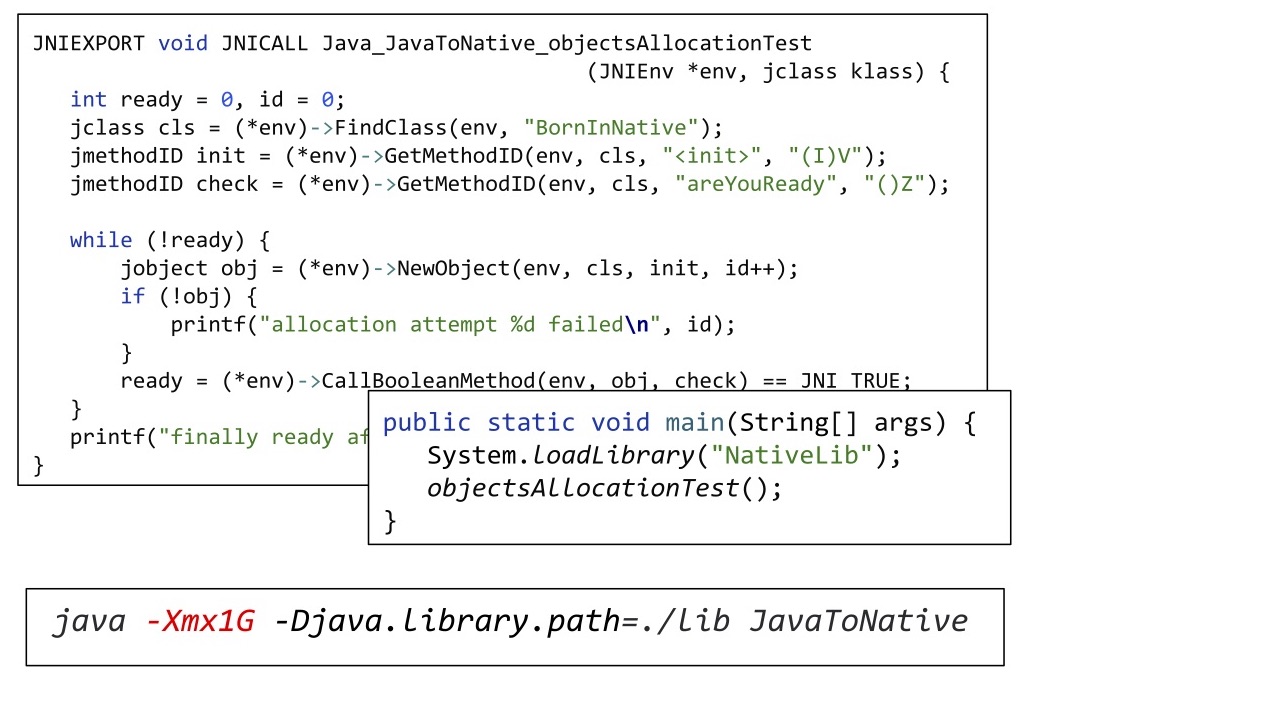
Чтобы это показать, давайте залогируем, получилась ли очередная аллокация или нет, и запустим всё это на hotspot с -Xmx 1 ГБ.
Через несколько сотен миллионов итераций мы заметим, что аллокации стали фейлиться. JVM сейчас в коматозном состоянии, она пытается выкинуть out of memory, но ничего не получается, ведь в нативе мы это не обрабатываем. Обратите внимание на потребление памяти.
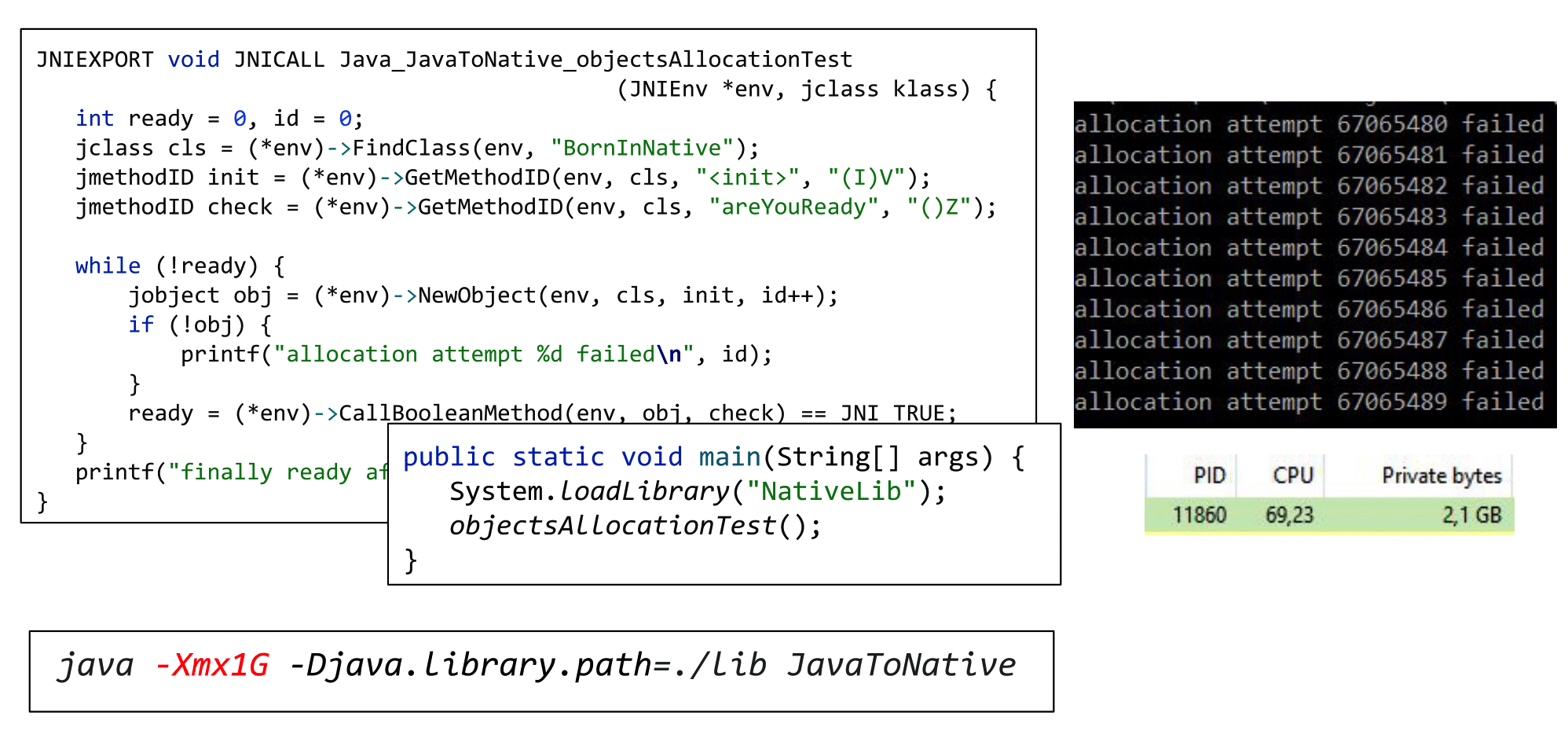
Вы заказывали 1 ГБ, но потребление на самом деле уже 2 ГБ, потому что а) все Java-объекты удерживаются в heap, б) сами неумирающие jobject тоже занимают (нативную) память. В результате реальное потребление памяти вашим приложением превысило указанный лимит на дополнительный гигабайт.
Чтобы это починить, есть специальная функция DeleteLocalRef, которая говорит JVM, что локальная ссылка больше не нужна, ее можно уничтожить, а соответствующий объект собрать во время GC.
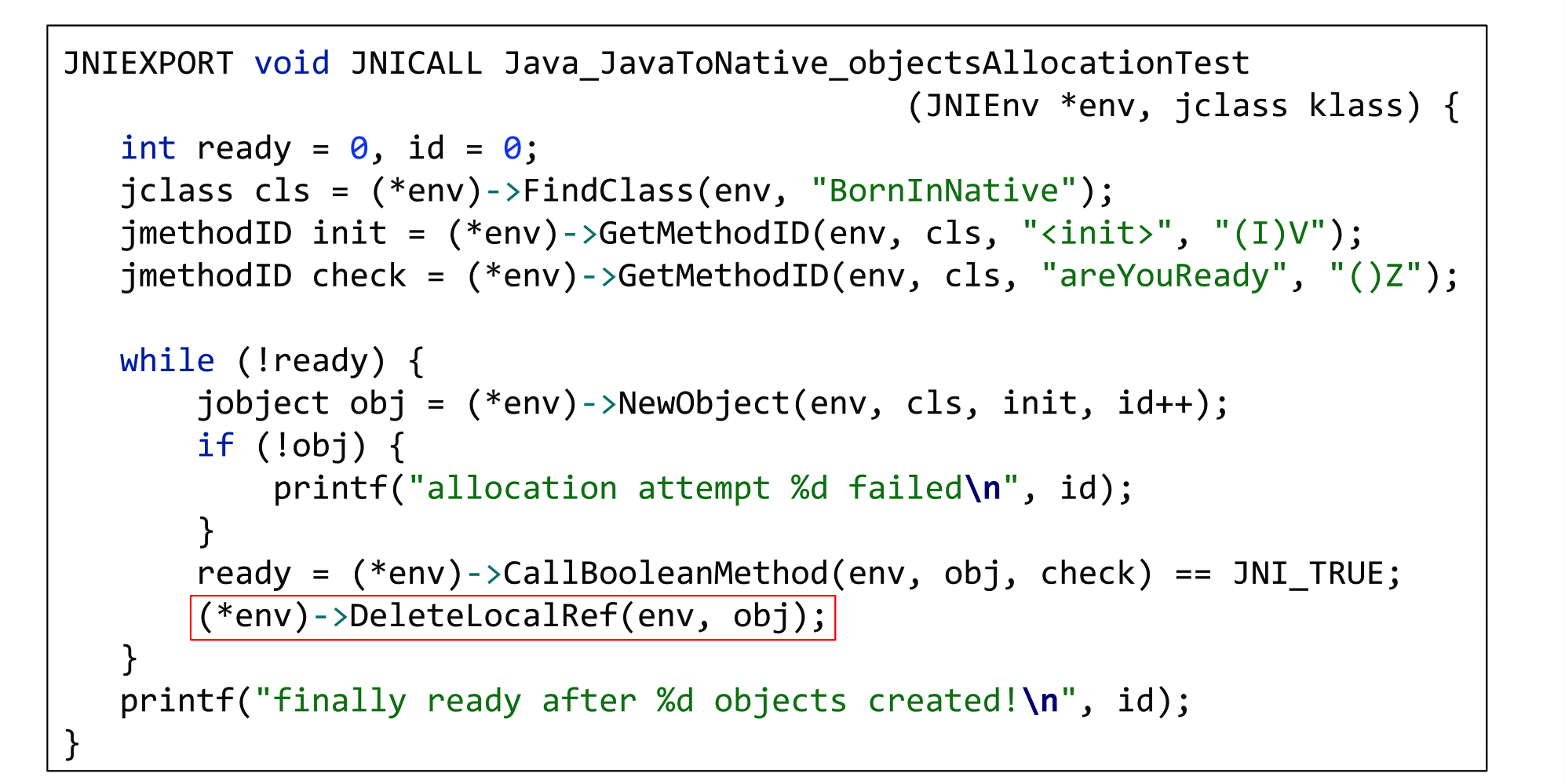
Исправленная программа будет работать с любым разумным Xmx.
Так что с local Reference легко получить memory leak, но также легко получить и висящую ссылку. Попробуйте сохранить LR в static-поле, выйти из натива, вернуться и прочитать это поле. Получите некорректное значение.
Кроме LR есть другие хендлы, например Global Reference. Такие ссылки существуют до тех пор, пока вы явно их не освободите. Здесь ещё легче получить утечку памяти (достаточно просто забыть вызвать DeleteGlobalRef), но с другой стороны они более прямолинейны, нет неожиданностей. Забыли позвать DeleteGlobalRef — значит, будет утечка.
Наконец есть Weak Global Reference, это GR, но в них не гарантируется, что GC не соберет ваш объект. Это полная аналогия со слабыми ссылками из Java. Таким образом, все проблемы с ними актуальны и для нативов тоже.
Еще больше сложностей с GC
Кроме проблем с JNI Reference стоит упомянуть, что у некоторых функций JNI-интерфейса есть очень интересные отношения со сборщиками мусора. Допустим, вы передаете в натив массив, он завернется в jobject, но получать доступ к каждому элементу по одному через jni-функции — это очень долго.
Вместо этого вы наверняка захотите получить доступ ко всему региону данных из массива за раз. Для этого есть специальные функции, например, GetIntArrayElements. Однако у нас опять есть проблема: мы не можем получить доступ к объекту, если в этот момент его может подвинуть GC. С этим нужно что-то сделать.
Есть две техники, как это можно реализовать. Во-первых, можно «запинить» объект, сказать сборщику мусора «давай мы не будем двигать пока массив, ты собирай мусор, а его не двигай».
Вторая тактика — просто скопировать его в нативную память, в нативе поработаем с копией, а потом обновим соответствующий массив.
JNI функции типа GetIntArrayElements даже поддерживают такую двойственность решения этой проблемы: у них есть третий аргумент — указатель на флажок. Если виртуальная машина решилась скопировать, то туда запишется true, если нет, то false, так что вы узнаете, что конкретно произошло.
Подводный камень здесь в том, что большинство виртуальных машин и сборщиков мусора не умеют pin-ать объекты по одному. Есть исключения, но скорее всего, как бы вы не надеялись на то, что копирования не случилось, оно произойдет. Так что при работе в нативе с массивом на 2 ГБ вы столкнетесь с копированием его в нативную память, что, конечно, может ударить и по производительности, и по общему потреблению памяти вашим приложением.
Конечно, есть особенные JNI-функции типа GetArrayElementsCritical (и другие функции с суффиксом Critical), они всячески стараются не скопировать массив.
Пиннинга в большинстве GC нет, как они выходят из ситуации?
Они говорят: «Давайте на время исполнения этой функции вообще не будет сборки мусора, пусть GC подождёт». Это может сработать и дать хорошую производительность, вы поработаете без копий, но есть и обратная сторона медали.
Вы отодвигаете GC на неопределенный срок, что уже плохо само по себе, но при самом плохом сценарии вы можете просто получить дедлок и зависание вашего приложения. Подробнее про это можете почитать в посте Алексея Шипилёва.
Производительность нативных методов
И наконец, нельзя говорить про нативы и не обсудить их производительность. Раз вы вызываете C-код, то, конечно, кажется, что это должно чертовски быстро работать по сравнению с обычной Java. На самом деле — это большое заблуждение. Дело в том, что сам вызов нативных методов — это серьезная сложность для виртуальной машины. Давайте измерять!
Все замеры будем проводить на машине: Intel Core i7–7700 @ 3.60 GHz;16GB RAM, Linux Ubuntu 18.04
Начнем с простого примера. Мы из Java вызываем другой Java метод без параметров и обязательно без инлайна. Мерим это с помощью JMH, получаем 696 попугаев, (больше — лучше).
Проведем другой эксперимент и вызовем из Java нативный метод, тоже пустой, без параметров и возвращаемого значения. И получаем просадку производительности в 3,3 раза на jdk8u252.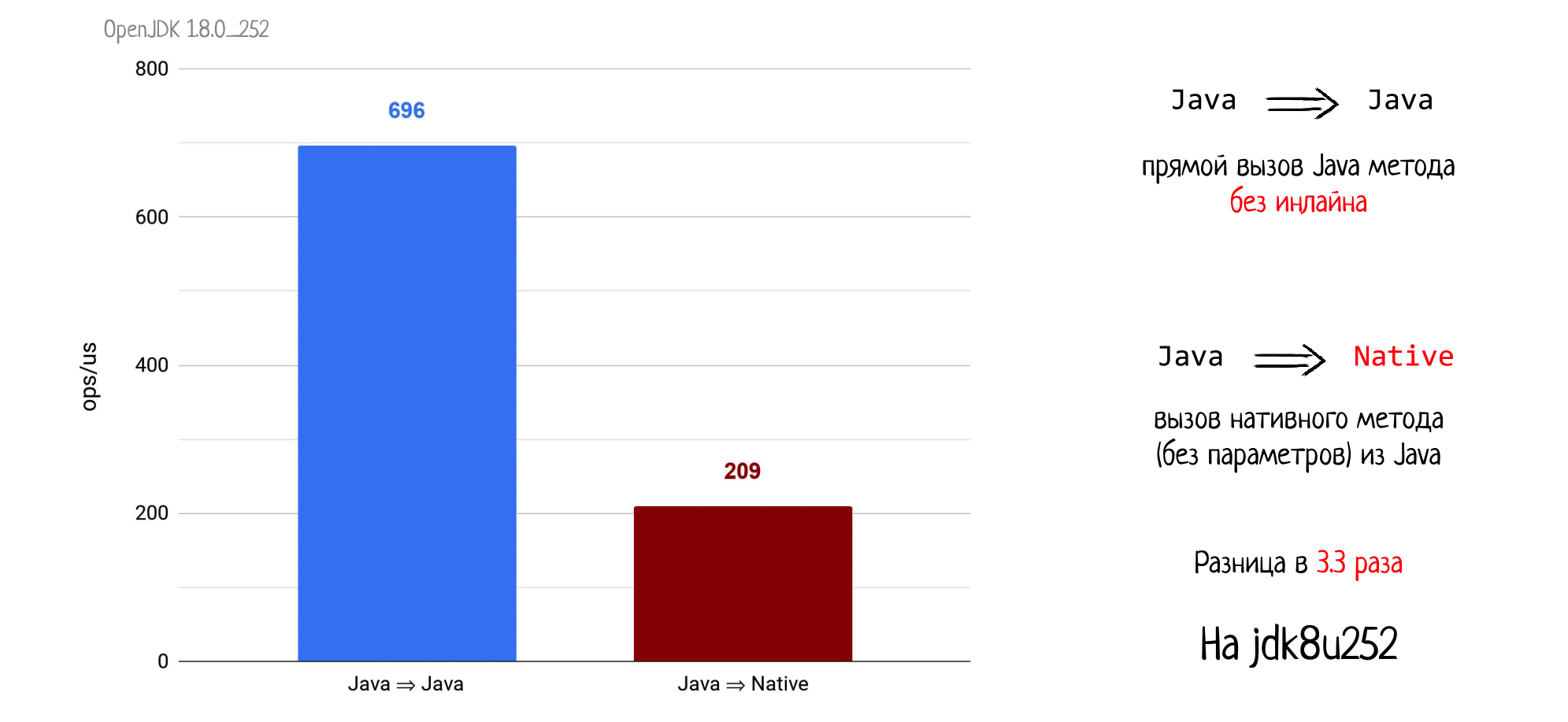
При этом на jdk11 вы уже получаете просадку уже в 6 раз. Причины такой разницы в поведении разных версий Java рассмотрим в конце доклада, а сейчас продолжим наши измерения.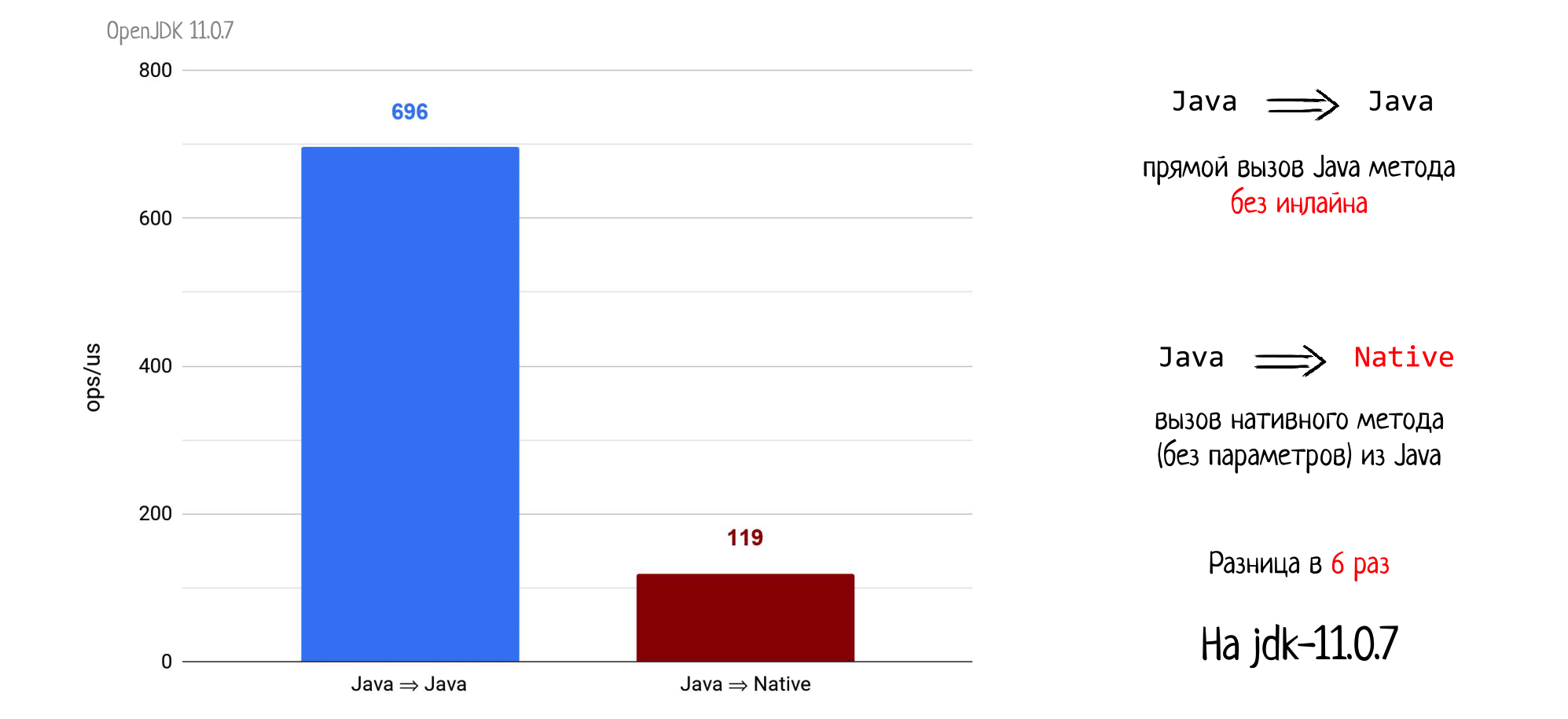
Теперь давайте проведем более зловещий эксперимент и вызовем из Java натив, а оттуда через callback позовём пустой Java-метод. Логично предположить, что здесь случится проседание раза в два (ведь стало в два раза больше работы). На самом деле просадка будет в 10 раз.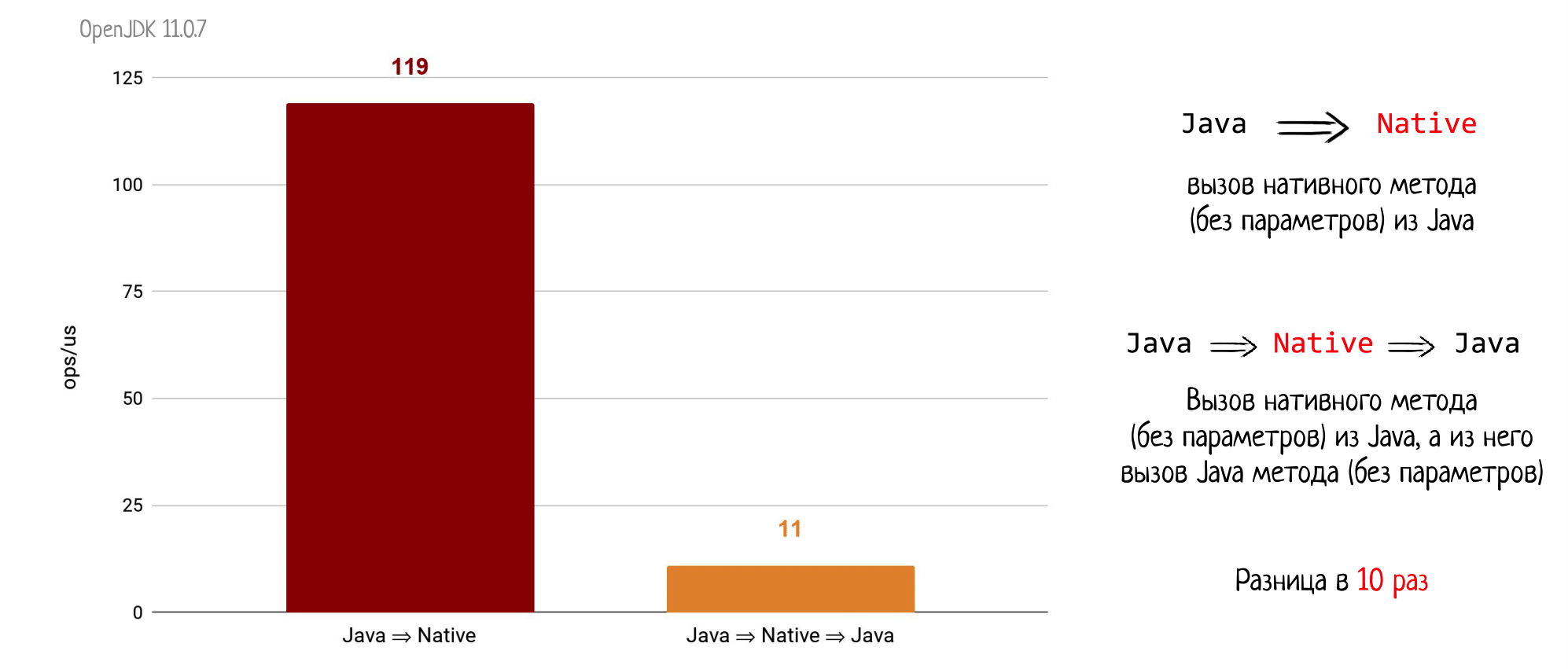
Т.е.возвращаться обратно из Java в натив дороже, чем просто уходить в натив.
Почему так происходит?
Если вы вызываете нативный метод, то, конечно, в сгенерированном коде хочется увидеть просто инструкцию call, вызывающую этот метод по какому-то адресу.
И вы этот call получите, но вокруг него есть ещё некоторое количество работы для подготовки к вызову и обработки результата.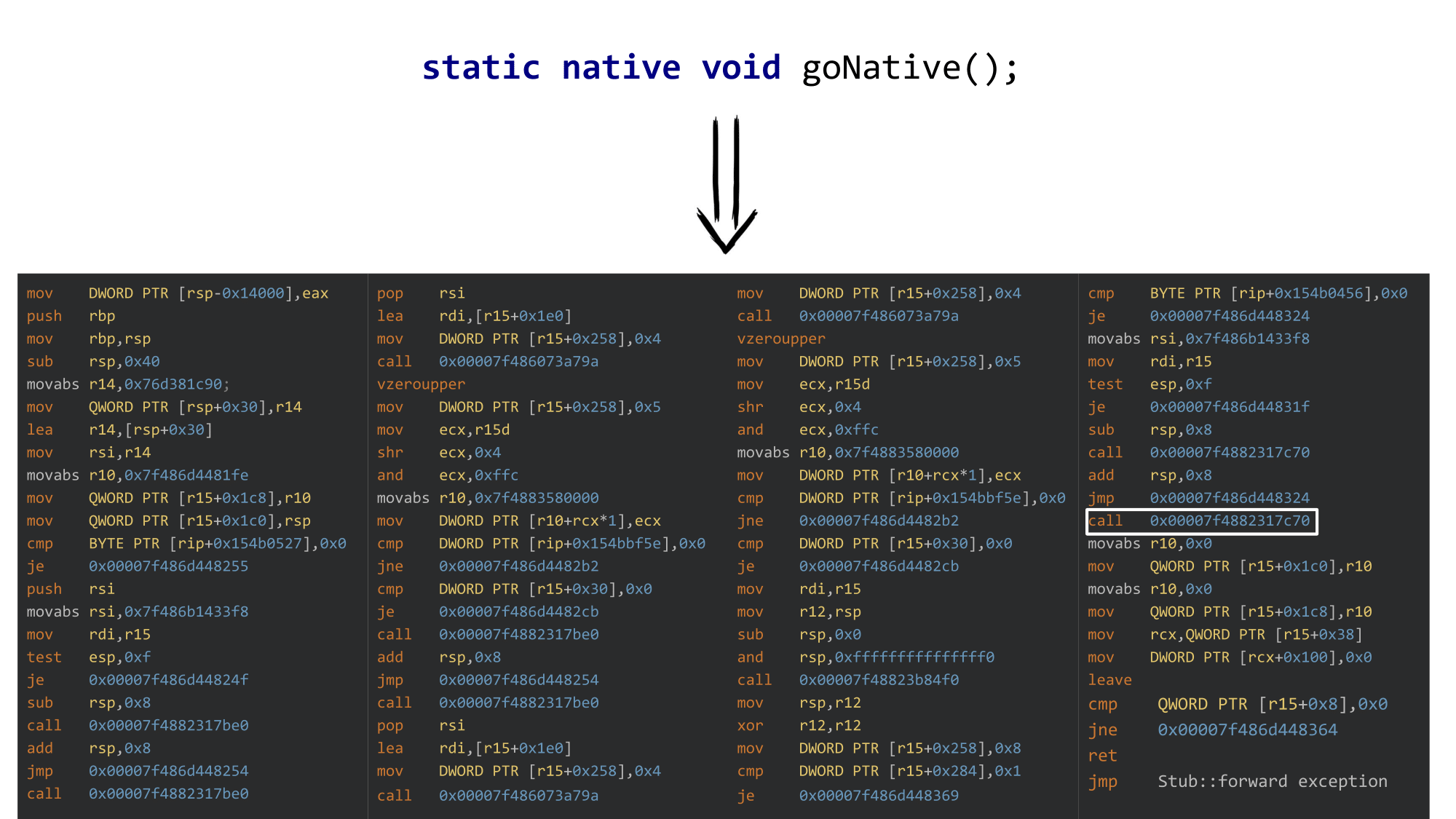
Более конкретно кроме самого вызова нам нужно:
- Синхронизироваться с GC, объявить, что вы ушли в натив или вернулись.
- Если есть аргументы, то завернуть их в Local References. При этом один параметр-то есть всегда, даже в нашем случае — это либо jclass для статического метода, либо объект, от которого вызвали метод в случае instance-метода.
- На выходе нужно сделать exception check, проверять, не полетело ли исключение.
- Есть системная работа: выравнивание стека, перекладывание параметров с одних регистров на другие, и так далее.
И всё это даёт просадку производительности в шесть раз.
Вторая волна просадки производительности происходит, когда мы понимаем, что никакого инлайна не будет. Абсолютно враждебный код, он написан на другом языке, а скомпилирован другим компилятором. У нас просто нет технической возможности проинлайнить это в Java. Поэтому в нашем первом измерении мы вызывали Java метод без инлайна, иначе разница была бы настолько огромная, что на одном графике результаты показывать уже не было бы смысла.
Ну и про возвращение обратно в Java — так медленно работает из-за реализации конкретной виртуальной машины Hotspot. Когда вы делаете callback, происходит много лишней и тяжелой работы, в других виртуальных машинах результат мог бы быть гораздо лучше.
На этой позитивной ноте мы заканчиваем разговор про JNI, и вот список практических советов по первой части доклада, следуя которым, вы скорее всего избежите неприятных проблем и развалов.
Подведем итог этой части доклада одним предложением — «Появление JNI в своё время было огромным прорывом в отрасли, но использовать его сегодня для взаимодействия с нативным кодом слишком уж больно».
В следующей части поговорим про сегодняшние альтернативы JNI, их сильные и слабые стороны, а также обсудим будущие проекты, которые вполне могут кардинально поменять все наше представление о нативах в Java: проекте Panama и Sulong.
Минутка нативной рекламы в тексте про нативный код. Раз вы здесь — похоже, вы Java-разработчик, который не боится покидать уютную хоббичью нору и покорять что-то новое для себя. В таком случае на конференции Joker (25–28 ноября, онлайн) наверняка будет интересное для вас — можете сами посмотреть программу на сайте.
