Разбираемся в рекурсии
Привет, Хабр.

Про рекурсию ходит много шуток, и она традиционно считается одной из сложных для понимания тем в computer science, поэтому давайте сегодня немного о ней поговорим. А именно, давайте обсудим, как выражать доказуемо завершимые вычисления.
Зачем это надо? Рекурсия — один из краеугольных камней ФП, а некоторые из функциональных языков (например, Idris или Agda) обладают достаточно мощной системой типов, чтобы использовать их для проверки доказательств. А чтобы проверенным доказательствам на самом деле можно было доверять, было бы неплохо, чтобы логическая система, которую представляет система типов языка, была консистентна — то есть, если упрощать, чтобы в ней нельзя было доказать ложь.
Один из главных источников неконсистентности — незавершающиеся вычисления (для примера см. КДПВ), поэтому вышеупомянутые языки очень стараются дать возможность убедиться, что вычисления завершаются — соответствующая их часть даже имеет отдельное название, «termination checker». Но, увы, по фундаментальным причинам невозможно не иметь ни ложноположительных, ни ложноотрицательных результатов любой такой проверки, поэтому приходится идти на компромиссы. В доказательствах лучше перебдеть, чем недобдеть, поэтому всегда есть завершимые функции, которые этими языками отвергаются. Однако, эти функции можно переписать так, чтобы termination checker был доволен, если можно доказать, что рекурсивный вызов всегда в каком-то смысле «меньше».
Не так давно мне нужно было убедить Агду, что куча взаимно рекурсивных функций всегда завершается. Для этого пришлось почитать стандартную библиотеку и пораскрывать встречающиеся абстракции, чтобы понять, что же там на самом деле происходит. В процессе я делал заметки, а потом понял, что если добавить в эти заметки слова, то может получиться полезный кому-то ещё текст.
Сначала определим одно слово, которое дальше будет часто встречаться. Фундированное отношение на множестве — это такое отношение, у которого нет бесконечных убывающих цепочек элементов. Стандартное определение немного отличается, но для наших множеств (заведомо счётных, с другими даже идеальные Тьюринг-полные компьютеры не умеют работать) разница невелика и без аксиомы выбора. В качестве синонима в конструктивных контекстах часто используется понятие «доступности» (или как на русский перевести «accessible» в этом контексте?), которым я тоже иногда буду пользоваться.
Кроме того, немного про Агду, на которой мы и будем всё это писать. Это язык из ML-семейства с похожим на хаскель синтаксисом и с поддержкой зависимых типов. Стоит упомянуть пару синтаксических особенностей, которые не встречаются, пожалуй, ни в одном другом языке:
- Агда поддерживает миксфиксные операторы — то есть, операторы с любом числом аргументов (а не только унарные и бинарные) и с аргументами в произвольных местах. Места для аргументов указываются подчёркиваниями при определении оператора: например, можно определить оператор с именем
if_then_else_, и тогда конструкцияif a then b else cбудет эквивалентнаif_then_else_ a b c(и так и определяется условный оператор в стандартной библиотеке). Или можно определить оператор_⊢_⦂_и потом писать выражения типаa ⊢ b ⦂ c— почти как в математических статьях. Обычные бинарные операторы при этом определяются как, например,_<_. - Имена переменных (и других идентификаторов) могут содержать практически произвольные символы, кроме пробела. Например,
xa,b, или дажеΓ⊢[x↦ε]τ. Можно даже использовать эмодзи, но мы этого делать не будем.
Если читатель кода знаком с предметной областью, конечно же. Например, можно написать let Γ⊢[x↦ε]τ = sub-Γ⊢τ-head εδ Γ,x⦂σ⊢τ и получить самодокументируемое имя переменной Γ⊢[x↦ε]τ — достаточно одного взгляда, чтобы вспомнить, что в ней лежит доказательство того, что в контексте Γ выводим тип, который получился из типа τ заменой переменной x на ε. Или можно объявить функцию с именем Γ⊢ε⦂τ-⇒-Γok, которая доказывает, что из утверждения Γ ⊢ ε ⦂ τ следует утверждение Γ ok. Как это написать обычными словами в обычном языке, я не знаю. Какое-нибудь termWellformedInContextImpliesContextWellformed?
Ещё я иногда буду писать слово «свидетель утверждения X», обозначая этим терм, имеющий тип, соответствующий утверждению X.
Один из классических примеров, на котором ломаются стандартные termination checker’ы — алгоритм Евклида для нахождения наибольшего общего делителя двух чисел. При этом он достаточно прост для того, чтобы не тратить внимание на неважные детали, да и, оказывается, в стандартной библиотеке Агды он уже реализован. Нас интересует, в частности, вот эта функция: 
Здесь и дальше я буду приводить код в виде скриншотов, так как Хабр не умеет в раскрашивание Агды (что объяснимо, без запросов к тайпчекеру там не разберёшься), да и весь нужный уникод не у всех есть.
Эта функция принимает два числа, доказательство, что одно из них меньше другого, и ещё какой-то параметр типа Acc _<_ m. Судя по всему, именно он отвечает за убеждение termination checker’а в завершимости функции. Но что это за Acc?
Если мы пройдём по цепочке импортов, то увидим, что Acc определён так: 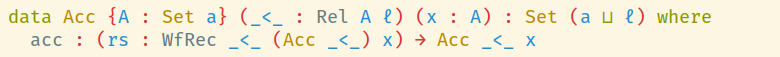
Похоже, у нас тут полиморфизм по уровням вселенных (или как там по-русски «universe levels»?) со всеми этими a и ℓ, но для развития интуиции мы можем их просто проигнорировать и считать, что мы работаем в нашей обычной вселенной обычных типов. Ну или, по крайней мере, лично мне так удобно делать — меньше вещей нужно держать в голове.
Кроме того, Acc параметризован:
- некоторым типом
A(который мы далее будем считать фиксированным), - отношением
_<_(если забыть про вселенные, то это просто функцияA → A → Set), - и элементом
xтипаA.
С типом и отношением всё понятно — в конце концов, мы говорили про «меньше», то есть, про какое-то отношение, и это отношения являются фундированными, гарантируя отсутствие бесконечных цепочек вызовов, так что они обязаны были где-то вылезти. А вот причём здесь x, непонятно, так что давайте посмотрим, как он используется в единственном конструкторе acc типа Acc.
Конструктор упоминает какой-то WfRec, который определён так: 
В принципе, можно было бы сразу подставить тело этого определения, но давайте для полноты разберёмся с типами.
Пожалуй, смысл этих типов можно было бы понять из контекста, но давайте не будем жульничать и посмотрим на определения.
Rel использует более общий REL, но в итоге, как и ожидалось, всё сводится к функции A → A → Set: 
С RecStruct всё чуть сложнее: 
Комментарий ссылается на модуль Induction.Nat, который устарел и был распилен на модули, а более новый Data.Nat.Induction не особо богат на примеры. Щито поделать.
В любом случае, если пристально посмотреть на это определение, то станет ясно, что RecStruct принимает тип A и возвращает какой-то другой тип — функцию из Pred A в себя же, а Pred A по большому счёту является функцией A → Set — как и положено всякому благочестивому предикату в теории типов.
Получается, что RecStruct A — это (A → Set) → (A → Set), и Rel A — это A → A → Set. С учётом этого, если мы раскроем WfRec в определении Acc, то получим: 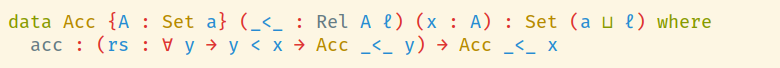
Становится понятнее. Чтобы создать значение типа Acc _<_ x, мы должны предоставить функцию, которая для любого y, меньшего x согласно отношению _<_, может создать Acc _<_ y.
Но как это вообще связано с завершимостью? Почему этого Acc достаточно, чтобы доказать, что что-то завершается?
Оказывается, что это наша старая добрая структурная рекурсия под прикрытием.
В структурной рекурсии всё в порядке, если, сильно упрощая, мы совершаем рекурсивный вызов на синтаксическом субтерме одного из наших термов-аргументов. Вот, например, привычный Фибоначчи: 
В последней строчке рекурсивный вызов происходит либо с n, либо с suc n, и оба эти терма прямо синтаксически являются кусочками терма-аргумента suc (suc n). Метатеории всех наших любимых зависимо типизированных языков гарантируют, что все значения любого типа данных «конечны», поэтому эта функция рано или поздно завершится.
В Фибоначчи используется один из самых простых типов данных в мире, тип натуральных чисел: 
но такая же логика работает и для чего-нибудь более сложного. Например, для бинарных деревьев: 
Рекурсивные вызовы на каждом из поддеревьев, естественно, вполне себе корректны и доказуемо завершимы: 
А теперь время для ключевого трюка. Заметим, что определение Tree выше изоморфно такому: 
Действительно, наш исходный конструктор node содержит два поддерева. Наш новый node' тоже содержит два поддерева, просто в виде функции, которая возвращает, например, левое поддерево, если ей передать true, и правое — если false (фанаты монады Either могут всё сделать наоборот): 
Аналогично можно поступить и с натуральными числами, просто в этом случае функция будет принимать аргумент типа, содержащего всего одно значение: 
Упражнение для читателя: напишите функцию-свидетель изоморфизма между Tree и Tree'. Напишите функцию-доказательство, что функция-свидетель на самом деле является изоморфизмом.
Но, если Tree и Tree' изоморфны, то можно ожидать, что termination checker посчитает функцию countBiased' с последнего листинга завершающейся точно так же, как он считает завершающейся функцию countBiased. И, к счастью, это действительно так!
Подход Tree' и ℕ' выглядит более тяжеловесно и неуклюже, чем привычный способ описания типов, но у него есть два преимущества. Во-первых, этот подход хорошо обобщается и куда более выразителен. Например, можно представить себе дерево со счётно бесконечным числом поддеревьев в каждом узле: 
Или дерево, где в каждом узле конечное, но неизвестное заранее число поддеревьев: 
Во-вторых, возвращаемые значения функций, «хранящихся» в конструкторах, считаются termination checker’ом структурно меньшими, так что мы спокойно можем делать рекурсивные вызовы на этих возвращаемых значениях (и метатеория языка гарантирует, что это на самом деле всё ещё консистентно). Например, можно написать что-то в духе подсчёта глубины «диагонали» дерева с бесконечным числом детей в каждом узле: 
Визуализировать эту функцию уже не так просто, как написать, но написать можно, и termination checker вполне корректно будет считать её тотальной.
Если вернуться к нашим НОДам, то можно заметить, что Acc имеет примерно ту же форму, что и все эти забавные типы, описанные выше. В частности, конструктор Acc _<_ x принимает функцию, которая по элементу y и свидетелю y < x возвращает другой Acc (конкретнее, значение типа Acc _<_ y). Теперь мы знаем, что termination checker считает этот Acc _<_ y как структурно меньший, чем исходный Acc _<_ x (кстати, даже несмотря на то, что его тип отличается). Поэтому мы можем передать это новое значение в рекурсивный вызов, и termination checker с удовольствием посчитает это корректной завершимой рекурсией, даже если ни один из прочих аргументов не стал структурно меньше.
В каком-то смысле Acc позволяет преобразовать «меньше-согласно-отношению» в «структурно-меньше», и нам, программистам, остаётся заполнить пробелы в этом преобразовании.
Но как именно выглядит это преобразование?
Натуральные числа
Давайте для начала напишем доказательство того, что каждое натуральное x «доступно» (Acc — сокращение от «accessible») согласно обычному отношению «меньше-чем». Мы будем использовать отношение _<′_ из модуля Data.Nat.Base, которое эквивалентно _<_, но чуть более удобно в этом контексте.
Это доказательство — просто объект типа Acc _<′_ x для любого x: 
После обычных для Агды пасов мы придём к чему-то вроде такого: 
Давайте сосредоточимся на f. Как заполнить эту дырку? Если есть сомнения, делай case split! Так что давайте сделаем split по доказательству y<′x: 
Теперь первая дырка ожидает от нас некое значение типа Acc _<′_ y. Но вот что интересно: наша функция верхнего уровня, которую мы пишем, <′x-acc, возвращает ровно это значение, если ей передать y! Кроме того, такой рекурсивный вызов вполне удовлетворит наш termination checker, так как даже в худшем случае отсутствия прямого рекурсивного вызова f из f (который появится во второй дырке, которую мы заполним позже), y будет субтермом suc y, который равен x, переданному в изначальный вызов f и являющемуся формальным параметром <′x-acc. Короче, можно заполнить первую дырку как <′x-acc y.
Если теперь перейти ко второй дырке, убрать dot pattern и дать имя первому аргументу, то получим что-то такое: 
В дырке при этом будет такая цель и такой контекст:
Goal : Acc _<′_ y
--------------------------------------------------------------------------------
x : ℕ
y : ℕ
y<′x : y <′ xТут прямо напрашивается рекурсивный вызов f с передачей x, y и y<′x. Легко видеть, что результат рекурсивного вызова будет иметь нужный тип, и Агда с нами согласится. Итого, такое определение корректно и тотально: 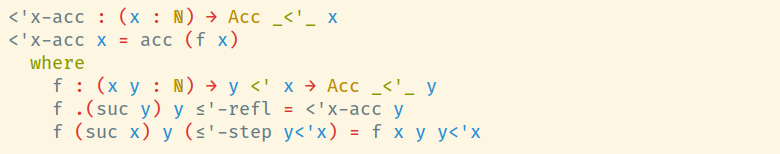
Пары чисел
Что насчёт чего-нибудь более сложного, как, например, пар натуральных чисел с лексикографическим порядком?
Такой порядок можно определить, например, так: 
Доказательство его фундированности предлагается читателю в качестве упражнения.
Ладно, шучу, мне просто лень описывать процесс разработки доказательства. Конечный результат будет выглядеть примерно так: 
Можно заметить, что доказательство имеет примерно ту же структуру: мы рекурсивно вызываем нашу основную функцию <,≤′-refl (так как мы стали меньше), а в остальных случаях мы рекурсивно вызываем нашу вспомогательную функцию f.
Итак, мы встретились с парой типов и отношений на них, а также доказали их вполне упорядоченность. Но что случится, если мы попытаемся доказать что-то про фундированность отношения, которое таковым не является? Где именно и что именно сломается? Доказывать, что какие-то вещи невыразимы, бывает сложно, но мы попытаемся хотя бы немножко приблизиться к интуитивному пониманию этой самой невыразимости. Да и лично я считаю, что контрпримеры так же важны для понимания, как и обычные, положительные примеры, так что давайте ломать!
Тривиальный тип
Пожалуй, самый простой пример — тип-синглтон с отношением, которое выполняется для любых двух элементов этого типа (тривиальным образом, так как у этого типа всего один элемент): 
Давайте начнём писать доказательство фундированности: 
Каков тип этой дырки?
Goal : Acc _!_ x
--------------------------------------------------------------------------------
x : ⊤Единственный способ создать значение типа Acc — через конструктор acc: 
Здесь y!x — свидетель отношений между y и x. Но этот свидетель не даёт нам никакой новой информации, так как мы и так знаем, что любое значение связано с любым, поэтому мы можем его просто проигнорировать! 
Какой тип дырки перед нами после этого?
Goal : Acc _!_ y
--------------------------------------------------------------------------------
x : ⊤
y : ⊤Похоже, что мы пришли к тому, с чего начали: нам нужно произвести некоторый Acc _!_ y для y, о котором мы ничего не знаем, и нам только остаётся ещё раз воспользоваться конструктором acc, передав в него ещё одну лямбду, и так до бесконечности. Понятно, что записать это не получится.
Ходим кругами
Что насчёт чего-нибудь поинтереснее? Давайте поиграем в камень-ножницы-бумагу, также известные как числа Пеано без аксиомы ∀x. suc(x) ≠ 0 на трёхэлементном множестве: 
Из-за конечности Obj представляется разумным попытаться доказать фундированность через case split по аргументу. Затем давайте рассмотрим произвольную ветку после сплита (я люблю метал, поэтому выберу rock): 
Если мы теперь сделаем сплит по y
с целью Acc _<_ scissors. Но мы не можем её заполнить ни через Acc _<_ rock без какой-либо дополнительной информации — то есть, снова придём к тому, с чего начали.
Бесконечные цепи уникальных элементов
Если мы вернёмся к натуральным числам, но теперь рассмотрим отношение _>_ «быть больше, чем», то у нас тоже не получится доказать его фундированность. Неформально говоря, дело в том, что для любого наперёд заданного x нам может быть дано число y, большее, чем x, для которого нужно предоставить свидетеля фундированности. Для этого y тоже может быть дано третье число z, большее, чем y. Но проблема в том, что чисел, больших, чем x, столько же, сколько чисел, больших чем y, так что мы никак не сузили наше «целевое пространство»!
Или, другими словами, пусть у нас есть такой свидетель. Тогда мы можем скормить ему 0, заем 1, затем 2, и так далее. Так как мы по факту имеем структурную рекурсию, то мы сможем написать незавершающееся вычисление, но, так как Агда консистентна, этого не может быть!
Или, в виде кода, кратко и ясно: 
Так что либо ℕ не населено (что, очевидно, не так), либо Acc _>_ x не населён для любого x.
Как же используется доказательство фундированности? Посмотрим ещё раз на функцию вычисления НОД:
Во втором случае мы знаем, что второй аргумент n меньше первого аргумента m. Из достаточно простой арифметики следует, что остаток от деления m на n меньше n, так что рекурсивный вызов происходит с корректными первыми двумя аргументами, а последний аргумент использует некую лемму m%nrec для числа n (которое, как мы помним, меньше, чем m). Termination checker всем доволен по ровно тем же причинам, как и в случае diagCount выше.
После этого маленького экскурса у меня получилось написать что-то чуть менее тривиальное, с кучей взаимно рекурсивных функций, бегающих по взаимно рекурсивным деревьям вывода в системе типов, формализацией которой я сейчас занимаюсь. Надеюсь, что если тебе, дорогой читатель, понадобится доказуемо завершимая рекурсия, эти записи помогут тебе с ней разобраться. Тем более, что, на мой взгляд, чаще всего все доказательства завершимости сводятся к введению размера как прямого отображения на множество натуральных чисел, а там с фундированностью всё просто, и 640 килобайт Acc _<_ хватит всем.
Кроме того, похожие фичи есть и в Idris в виде accInd/accRec и обёрток sizeInd/sizeRec для того самого случая размера как натурального числа. Да и, учитывая, что мы разобрали, как определяется и как работает Acc, не составит труда определить самостоятельно соответствующий примитив в любом зависимо типизированном языке.
