Увеличение производительности дисковой подсистемы в следующем выпуске гипервизора XenServer
 Перевод. Оригинальная статья доступна в блоге Xen.Автор — Felipe Franciosi.Последние тестовые сборки XenServer Creedence Alpha отличаются повышенной производительностью дисковой подсистемы по сравнению с XenServer 6.2 (подробности в блоге Маркуса Гранадо (Marcus Granado) — Performance Improvements in Creedence). В основном, улучшения связаны с внедрением новой архитектуры дисковой подсистемы — tapdisk3. Мы опишем эту технологию организации виртуального хранилища, а также приведем и объясним результаты экспериментов, в которых достигается производительность примерно 10Gb/s одним хосте с подключенным кластерным хранилищем.
Перевод. Оригинальная статья доступна в блоге Xen.Автор — Felipe Franciosi.Последние тестовые сборки XenServer Creedence Alpha отличаются повышенной производительностью дисковой подсистемы по сравнению с XenServer 6.2 (подробности в блоге Маркуса Гранадо (Marcus Granado) — Performance Improvements in Creedence). В основном, улучшения связаны с внедрением новой архитектуры дисковой подсистемы — tapdisk3. Мы опишем эту технологию организации виртуального хранилища, а также приведем и объясним результаты экспериментов, в которых достигается производительность примерно 10Gb/s одним хосте с подключенным кластерным хранилищем.
Несколько месяцев назад я писал о проекте Karcygwins, который включал в себя серию экспериментов и исследований, направленных на изучение особенностей работы дискового ввода-вывода. Мы сосредоточились на случае, когда нагрузку генерирует одна ВМ с одним виртуальным диском. В частности, нас интересовало понимание природы дополнительных затрат (overhead) на виртуализацию, особенно на устройствах с малыми задержками, например — современных SSD. Сравнивая разные способы виртуализации дискового ввода-вывода, доступные пользователю (то есть blktap и blktap2), мы сумели объяснить, где и почему возникают дополнительные затраты, а также как их значительно уменьшить. Подробнее о проекте Karcygwins можно прочитать по ссылке.С этого момента мы расширили круг исследований на случаи с более сложной структурой нагрузки. Особенно нас интересовала совместная нагрузка от нескольких ВМ, полостью загружающих хранилище. Мы изучали особенности новой подсистемы tapdisk3, разработанной для XenServer Таносом Макатосом (Thanos Makatos). Tapdisk3 написан для упрощения архитектуры и вынесения ее полностью в пространство пользователя, а это, в свою очередь, приводит к существенному повышению производительности.
Между tapdisk2 и tapdisk3 есть два существенных различия. Первое — это способ, которым tapdisk соединяется с подсистемой дискового ввода-вывода: старый tapdisk обращается к устройствам blkback и blktap2 внутри гипервизора, а новый — напрямую к паравиртуальному драйверу внутри ВМ. Второе — метод, которым гостевая ВМ и гипервизор обмениваются данными: старый tapdisk использует доступ к отображаемым страницам памяти в памяти ВМ и последующее их копирование в адресное пространство гипервизора, второй же использет технологию копирования при доступе (grant copy).
Все же остальные модификации необходимы для того, чтобы сделать возможным такое изменение архитектуры. Большая их часть затрагивает уровень управления виртуальными машинами (control plane). Для этого мы изменили стек управления (xapi) таким образом, чтобы он поддерживал постоянную связь с модулем tapdisk. Из-за этих изменений (а так же из-за некоторых других, относящихся к тому, как tapdisk3 обрабатывает поступающие данные) изменился и способ представления виртуальнго диска в памяти гипервизора. Поскольку tapdisk3 пока еще не выпущен официально, в будущем возможны и другие изменения.Чтобы измерить достигнутую в рамках tapdisk3 производительность, мы выбрали самый быстрый из имеющихся у нас сервер и самое быстрое хранилище.
Платформа Dell PowerEdge R720 64 GB ОЗУ Процессор Intel Xeon E5–2643 v2 @3.5 GHz 2 сокета, 6 ядер на сокет, hyperthreading = 24 pCPU Частота в режиме Turbo — 3.8 GHz Планировщик CPU гипервизора переведен в режим «Performance» (по-умолчанию установлен в «On Demand» для сохранения электроэнергии). Рэйчл Берри (Rachel Berry) в своем блоге описала работу планировщика более подробно. В BIOS установлен режим «Performance per Watt (OS)», режим «Maximum C-State» установлен в 1 4 x Micron P320 PCIe SSD (175 Гб каждый) 2 x Intel 910 PCIe SSD (400 ГБ каждый) Каждый из них представлен как 2 SCSI устройства по 200 Гб каждое (всего — 4 устройства и 800 Гб в сумме) 1 x Fusion-io ioDrive2 (785 Гб) После установки XenServer Creedence с номером сборки 86278 (примерно на 5 номеров старше XenServer Creedence Alpha 2) и дисков Fusion-io мы создали хранилище на каждом доступном устройстве. Получилось 9 хранилищ и примерно 2,3 Тб свободного места. На каждом хранилище мы создали 10 виртуальных дисков в формате RAW по 10 Гб каждый. Каждый виртуальный диск мы соединили с его виртуальной машиной, выбирая диски «по кругу», как это показано на диаграмме ниже. В качестве гостевой ОС была выбрана Ubuntu 14.04 (архитектура x86_64, 2 логических CPU, жестко не привязанных к реальным, 1024 Мб ОЗУ). Мы также передали 24 логических CPU гипервизору и решили не ассоциировать с их с реальными (в статье XenServer 6.2.0 CTX139714 более подробно описана методика привязки логических CPU к реальным).

Сначала мы измерили совокупную производительность канала между гипервизором и виртуальной машиной, если диски подключены стандартным способом tapdisk2<->lbktap2<->blkback. Для этого мы заставили одну виртуальную машину посылать 10-секундные запросы на запись на все ее диски одновременно, а затем подсчитали общий объем переданных данных. Размер запроса варьировался от 512 байт до 4 Мб. После этого мы увеличили число виртуальных машин до 10-и, а затем сменили запросы на запись запросами на чтение. Результат показан на графиках ниже:


Измерения показали, что виртуальные машины не в состоянии обращаться к диску со скоростью более 4 Гб/с. Затем мы повторили эксперимент с использованием tapdisk3. Результат явно улучшился:


В случае записи, совокупная пропускная способность дисковой подсистемы для всех ВМ достигает отметки в 8 Гб/с, в случае же чтения — 10 Гб/с. Из графика следует, что в некоторых случаях производительность tapdsik3 больше производительности tapdisk2 примерно в 2 раза на запись и 2,5 раза на чтение.
Чтобы понять, почему tapdisk3 настолько превосходит tapdisk2 в производительногсти, следует вначале рассмотреть архитектуру подсистемы виртуального хранилища, которое используют паравиртуальные ВМ и гипервизор. Мы сосредоточим внимание на компонентах, которые использует XenServer и обычная ВМ под управлением Linux. Тем не менее, следует иметь ввиду, что информация, изложенная ниже, актуальна и для ВМ под управлением Windows, если эта ОС использует установленные паравиртуальные драйверы.
Как правило, гостевая ВМ под управлением Linux при старте загружает драйвер под названием blkfront. С точки зрения гостевой ВМ это обычное блочное устройство. Отличие же в том, что вместо взаимодействия с реальным оборудованием, blkfront общается с драйвером blkback в теле гипервизора через разделяемую память и механизм событий (event channel), который используется для передачи прерываний между доменами.
Приложения внутри гостевой ОС инициируют операции чтения или записи (через библиотеки libc, libaio и т. д.) файлов или же непосредственно блочных устройств. Операции в конечном счете транслируются в запросы к блочным устройствам и передаются blkfront через случайно выбранные страницы памяти в адресном пространстве гостя. Blkfront, в свою очередь, предоставляет гипервизору доступ к этим страницам таким образом, что blkback может читать и писать в них. Этот тип доступа называется «предоставление доступа к отображаемым страницам памяти» (grant mapping).
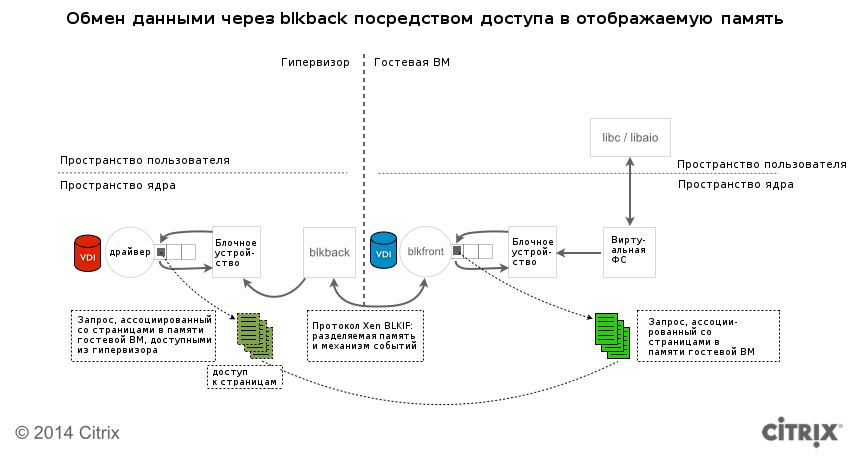
Несмотря на то, что сообщество разработчиков Xen Project проводит кампанию по улучшению масштабируемости и производительности механизма доступа к отображаемым страницам, остается еще много работы, поскольку система устроена сложно и имеет ряд ограничений, в особенности — касающихся совместного доступа к хранилищу с нескольких ВМ. Наиболее заметное недавнее изменение — набор патчей от Мэтта Вилсона (Matt Wilson) для улучшения механизма блокировок и большей производительности.
Чтобы уменьшить дополнительные затраты на выделение и освобождение памяти для каждого запроса в механизме доступа к отображаемым страницам, Роджер По Мун (Roger Pau Monne) реализовал в протоколе blkback/blkfront нововведение, названное «доступ по постоянным адресам» (persistent grant). Такой доступ может быть использован, если оба домена (гипервизора и ВМ) его поддерживают. В этом случае blkfront предоставляет blkback-у доступ к постоянному набору страниц и оба драйвера используют этот набор так долго, как только смогут.
Обратная сторона заключается в том, что blkfront не может указывать, какие страницы будут ассоциированы с запросом, поступившим с уровня блочного устройства гостевой ВМ. Ему в любом случае приходится копировать данные из запроса в этот набор перед тем, как передать запрос в blkback. Однако, даже если учесть эту операцию копирования, доступ по постоянным адресам остается хорошим методом для увеличения масштабируемости при одновременном вводе-выводе с нескольких ВМ.

Оба представленные выше изменения полностью реализованы в пространстве ядра гипервизора. Однако мы не учитываем, что запрос к блочному уровню гипервизора содержит ссылку на страницы в адресном пространстве гостя. Это может вызвать состояние гонки при использовании сетевых хранилищ, таких как NFS, и, возможно, iSCSI: если сетевой пакет (который содержит указатель на страницу обмена) помещен в очередь для повторной передачи и приходит подтверждение передачи оригинального пакета, гипервизор может повторно отправить неверные данные или даже аварийно закончить работу, поскольку страница обмена может либо содержать неправильные данные либо вообще быть освобождена.
Чтобы избежать проблем, XenServer копирует страницы в память гипервизора вместо того, чтобы использовать их напрямую. Эта функция впервые появилась в драйвере blktap2 и компоненте tapdisk2, наряду с технологиями выделения места по требованию (thin-provisioning) и перемещением дисков ВМ между хранилищами (Storage Motion). В рамках этой архитектуры blktap2 копирует страницы перед тем, как передать их tapdisk2, чтобы обеспечить безопасную работу сетевых хранилищ. По этой же причине blktap2 предоставляет гипервизору полнофункциональное блочное устройство для каждого виртуального диска вне зависимости от его природы (в том числе и «урезанным» дискам в формате thin-provisioning, размещенным на хранилищах NFS).

Как мы видим из результатов приведенных выше измерений, эта технология имеет ограничения. Она хороша для различных типов классических хранилищ, однако демонстрирует низкую производительность при работе с современными средствами хранения данных, например, SSD-дисками, подключенными непосредственно к серверу по шине PCIe. Чтобы учесть последние изменения в технологиях хранения данных, XenServer Creedence будет содержать новый компонент — tapdisk3, который использует еще один способ доступа к памяти — копирование при доступе (grant copy).
Начиная с версии ядра 3.x в качестве домена гипервизора (dom0) и появлением устройства доступа (gntdev), мы получили доступ к страницам других доменов непосредственно из пользовательского пространства гипервизора. Эта технология реализована в tapdisk3 и использует устройство gntdev, а также канал событий evtchn, чтобы обмениваться данными непосредственно с blkfront.
Копирование при доступе намного быстрее, нежели просто предоставление доступа по постоянным адресам, а затем — копирование. При таком доступе большая часть операций выполняется внутри ядра Xen Project Hypervisor, кроме того, обеспечивается присутствие данных в адресном пространстве домена гипервизора для безопасного функционирования сетевых хранилищ. Также, поскольку логика реализована полностью в пространстве пользователя, включение дополнительного функционала (вроде thin-provisioning, снэпшотов или Storage Motion) не создает особых трудностей. Чтобы обеспечить доступ гипервизора к блочному устройству, соответствующему диску виртуальной машины (для копирования диска и иных операций) мы подключаем tapdisk3 к blktap2

Последнее (но не по значению), о чем мы хотели написать: искушенный читатель может спросить, почему XenServer не использует возможности qemu-qdisk, который реализует технологию доступа по постоянным адресам в пространстве пользователя? Дело в том, что, для обеспечения безопасной работы сетевых хранилищ (в том числе и для доступа по постоянным адресам, при котором запрос к хранилищу ссылается на страницы в памяти гостевой ВМ), qemu-qdisk снимает флаг O_DIRECT при доступе к виртуальным дискам. Это приводит к тому, что данные копируются в кэш домена гипервизора, чем обеспечивается безопасный доступ к данным. Таким образом, доступ по постоянным адресам в этом случае приводит к избыточному копированию и к задержкам при обслуживании запросов. Мы считаем, что копирование при доступе — лучшая альтернатива, чем qemu-qdisk.
