Устройство TCP/Реализация SYN-flood атаки

В данной статье мы кратко поговорим об устройстве протокола TCP, самой популярной атаке на него — SYN-flood, реализуем её на практике, а также узнаем как с ней бороться.
Часть 1. Устройство TCP
Что такое TCP и зачем он нужен?
TCP расшифровывается как Transmission Control Protocol — протокол контроля передачи. Как понятно из названия, он используется для того, чтобы контролировать передаваемые по сети данные: упреждать и исправлять различные казусы, могущие возникнуть при передачи данных по сети.
Но что же такого может случиться при отправки пакетов по сети? На самом деле возможны две ситуации:
1. Нарушение порядка следования пакетов
Передаваемые нами данные, дробятся на пакеты, которые далее маршрутизируется протоколами динамической маршрутизации, и может статься так, что одна часть пакетов пойдет по более быстрому маршруту, а другая будет передаваться по маршруту с более низкой пропускной способностью, ввиду чего придет позже.
Пусть, к примеру, нам нужно последовательно передать узлу сети четыре пакета: A, B, C и D. Мы ожидаем, что он получит их в такой же последовательности, в которой они были отправлены, но исходя из вышеизложенного вполне возможна ситуация, при которой получатель будет иметь при приеме последовательность ACBD или, например, DACB. Следовательно, TCP должен каким-то образом восстанавливать исходный порядок полученных пакетов.
2. Потеря пакетов
Ввиду ошибки маршрутизации или плохо сконфигурированной сети наши пакеты могут передаваться по очень медленному пути, либо попасть в петлю, в которой они будут блуждать, пока не исчерпают свой запас хопов и не уничтожатся. В таком случае TCP должен иметь возможность запрашивать потерянные или погрязшие в пакетной пробке данные.
Если мы общаемся с кем-то по аудио или видеосвязи, то такие исходы нас мало волнуют, но если мы скачиваем, к примеру, iso-образ некой ОС, то подобные ситуации мы должны полностью исключить.
Также TCP (как и другие протоколы транспортного уровня) используется для того, чтобы перенаправлять данные с одного порта, на другой порт, то есть от одного прикладного процесса к другому.
TCP-сегменты

Рис 1. Работа TCP с сегментами
Для передачи данных по сети TCP получает их от протокола прикладного уровня, буферизует и при готовности отправлять новую порцию данных, «отрезает» потребный кусочек байтов без учета их смысла или внутренней структуры. Каждый такой кусочек называется TCP-сегментом. Важно, что TCP рассматривает данные именно, как неструктурированный поток байтов. В отличие от протокола UDP, создающего дейтаграммы на основе логически обособленных единиц данных (сообщений, генерируемых приложениями). На стороне получателе модуль TCP получает пакеты, сохраняя их в буфер, а затем передает их протоколу прикладного уровня
Отметим, что сегментом называют как единицу передаваемых данных в целом (поле данных и заголовок протокола TCP), так и отдельно поле данных.
Заголовок TCP-сегмента
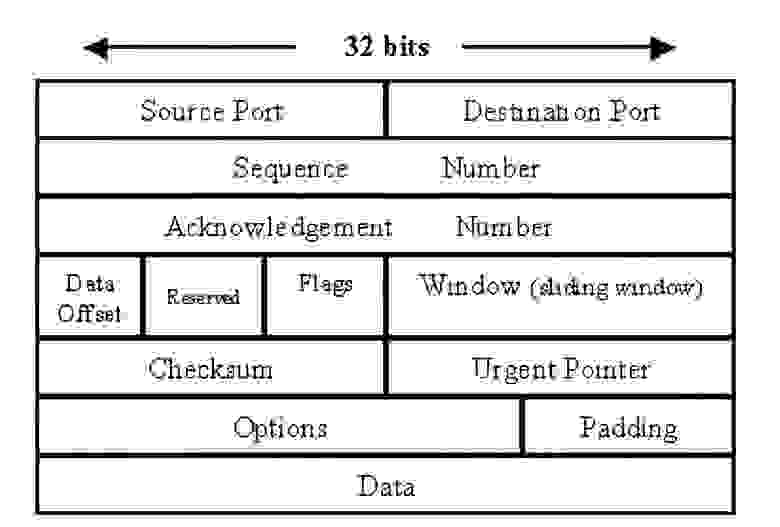
Рис 2. Структура TCP-сегмента
В последующем изложении нам понадобится знание полей заголовка, потому изложим их краткие описания, к которым читатель может вернуться в любой момент:
Source Port и Destination Port (16 бит каждый) — порт отправителя и получателя соответственно.
Sequence number (32 бита) — номер первого байта в сегменте, указывающий на его смещение, относительно всего потока байт.
Acknowledgment number (32 бита) — номер последнего байта, полученного в сегменте, увеличенного на единицу.
Data Offset (4 бита) — указывает на длину заголовка (смещение данных от начала сегмента)
Reserved (3 бита) — зарезервированные биты, которые могут использоваться в дальнейшем.
Flags (9 бит) — флаги, указывающие на то, какую информацию в себе несет сегмент.
Window (16 бит) — размер окна, показывающий сколько байт данных получатель готов принять.
Checksum (16 бит) — контрольная сумма. Некоторое значение, рассчитанное по набору данных путём применения хэш-функции и используемое для проверки целостности данных.
Urgent Pointer (16 бит) — порядковый номер байта, которым заканчиваются важные данные (принимается во внимание только при установленном флаге URG)
Options (12 бит) — опции, в которых содержаться параметры соединения.
Padding — фиктивное поле переменной длины, используемое для доведения размера заголовка до целого числа 32-битных машинных слов.
Data — поле переменной длины, в котором непосредственно содержатся передаваемые данные.
Установка TCP-соединения

Рис 3. Установка TCP-соединения
Перед началом непосредственной передачи данных отправителю и получателю необходимо установить соединение, в рамках которого будет производиться передача данных. При установке соединения отправитель и получатель обмениваются параметрами соединения: указывают ACK-номер, размер окна, тип квитирования и т.д. (обо всем этом будет подробно рассказано далее). Происходит это все в три этапа:
Отправитель посылает на сервер TCP-сегмент со своими параметрами, устанавливая флаг SYN (от англ. synchronization) и переходит в состояние SYN-SENT.
Сервер, получив SYN-флаг начинает подготавливать инфраструктуру для поддержания соединения, запрашивая у ОС различные ресурсы (счётчики, таймеры, буфера и т.д.) После отправляет TCP-сегмент со своими параметрами и флагами SYN и ACK (от англ. acknowledgement), переходя в состояние SYN-RECEIVED.
Отправитель, получив от сервера SYN-ACK-сегмент, отправляет ему сегмент с флагом ACK и переходит в состояние ESTABLISHED. Сервер, получив данный сегмент, также переходит в данное состояние, и начинается отправка данных.
Методы квитирования
Для того чтобы решать проблемы, поставленные перед TCP, было решено использовать квитирование пакетов. Идея проста: отправитель отсылает данные, а получатель подтверждает их получение квитанциями. Если отправитель вовремя не получает квитанции на переданные данные, то он передает их повторно. TCP реализует два метода квитирования пакетов, которые используют концепцию скользящего окна
Концепция скользящего окна

Рис 4. Скользящее окно
Идея заключается в следующем: отправитель имеет ряд пронумерованных пакетов, на котором определяется окно с заданным размером, регулирующее процесс передачи пакетов. Самый первый пакет, входящий в окно, называется базовым. Все, что левее него считается переданным. Пакеты, находящиеся в пределах окна разрешается передавать. Пакеты, которые находятся за правой границей окна, передавать запрещено. При получении квитанции на базовый пакет окно сдвигается на один пакет влево. При исчерпании окна передачи отправитель останавливается и ждет поступления квитанции. Окно также может быть и у получателя, которое ограничивает номера пакетов, которые он может принять.
На следующем рисунке представлен идеализированный пример, который показывает работу скользящего окна на стороне отправителя

Рис 5. Идеализированный пример «скольжения» окна
Для чего вообще нужно окно? Почему не передавать все пакеты разом?
Представьте себе такую ситуацию: вы решили скачать себе на смартфон GTA San Andreas, вес которой 1,4 Гб. При отсутствии скользящего окна все 1,4 Гб отправились бы с серверов Google бомбардировать TCP-модуль вашего смартфона.
Во-первых если бы все придерживались такой концепции, то очевидным образом это привело бы к заполоненью всего Интернета огромным числом TCP-сегментов, которые бы в разы уменьшили пропускную способность каналов связи.
Во-вторых при таком раскладе вашему смартфону пришлось бы выделять буфер неограниченного размера (так как мы не можем знать заранее какой объем данных мы получим), что уже звучит абсурдно. Так как размер буфера, который ОС может выделить ограничен, то в таком случае сегменты, которые не помещаются в буфер будут откинуты. Сервер же будет думать, что с пакетами что-то случилось и будет производить повторную их отправку, бомбардируя наш смартфон, который в это время не разобрался с полученными сегментами, снова и снова.
Теперь, когда мы познакомились со скользящим окном, перейдем к рассмотрению методов квитирования, на нем основанных.
Возвращение N пакетов (Go-Back-N)
Для начала рассмотрим алгоритм работы с сегментами на стороне-получателе. При поступлении нового пакета получатель проверяет две вещи:
Является ли пакет неискаженным
Является ли он следующим по порядку в последовательности уже полученных пакетов
Если два этих действий выполняются, то получатель посылает квитанцию с номером последнего переданного пакета. Стоит отметить, что квитанции в данном методе передачи являются накопительными. То есть, если отправитель получил квитанцию с номером n-го пакета, то и все пакеты до него также были приняты, так как получатель принимает неискаженные пакеты тогда и только тогда, когда они не выбиваются из последовательности (можно сказать, что у принимающей стороны окно размером в один пакет).
Теперь же рассмотрим алгоритм на стороне-отправителе. Отправитель посылает пакеты, не выходящие за рамки окна, и устанавливает таймер, значение тайм-аута которого равно предельному времени ожидания квитанции на базовый пакет. После истечения тайм-аута отправитель считает, что пакет или квитанция были утеряны, и отправляет его и все остальные отправленные пакеты еще раз, так как если базовый пакет не был принят, то и остальные тем более (поэтому метод и называется Go-Back-N).
Может случиться так, что базовый пакет и несколько последующих были успешно приняты, но квитанции на них затерялись. В таком случае получатель отправит повторно несколько пакетов. Получатель же, увидев дубликаты, поймет, в чем дело и отправит квитанцию последнего полученного пакета (вспоминаем про куммулятивность).
Данный метод является менее ресурсозатратным чем последующий, но имеет очевидный минус. Сторона-получатель может отбрасывать целостные пакеты только из-за того, что они выбиваются из последовательности, вследствие чего, отправитель будет вынужден каждый раз по истечение тайм-аута высылать целую порцию пакетов, заполоняя тем самым избыточными пакетами канал связи.
Выборочное квитирование (Selective acknowledgement)
При выборочном квитировании, как понятно из названия, сторона-получатель может отправлять квитанции на конкретные пакеты. В таком случае ей где-то нужно хранить полученные пакеты, ибо сразу отправлять их протоколу верхнего уровня не получится, так как пакеты могут приходить в хаотичной последовательности, и между ними могут образовываться пробелы. Следовательно на стороне получателя также организовывается скользящее окно. Очевидно, что окна на обеих сторонах должны быть одинакового размера, но скользить синхронно они не обязаны; в зависимости от возникающих ошибок при передаче пакетов и квитанций окно приема может опережать окно передачи.

Рис 6. Окна передачи и примера при выборочном квитировании
Получатель в данном случае уже не отбрасывает пакеты лишь потому, что они выбиваются из последовательности. Вынудить отбросить пакет получателя может его искажение, либо выход за границы окна.
Сторона-отправитель в данном случае организует таймер не только на базовый пакет, а на все отправленные пакеты и по истечении тайм-аута для конкретного пакета отправляет его вновь.
Возможна и ситуация, в которой пакет благополучно был принят, но квитанция на него потерялась. Тогда к получателю придет дубликат пакета. Получатель не должен его игнорировать — ему следует подтвердить квитанцией прием дубликата.
Данный метод хоть и чуть более ресурсозатратен, чем предыдущий, но позволяет существенно увеличить скорость передачи и уменьшить избыточную передачу пакетов. В настоящий момент большинство узлов сети, работающих на транспортном уровне, используют именно этот метод квитирования пакетов.
Нумерация байтов
В рассмотренных нами примерах для упрощения мы нумеровали наши пакеты натуральными числами, начиная с единицы, но в реальности же дела обстоят чуть сложнее. В протоколе TCP при установке соединения каждая из сторон сообщает другой число (поле Sequence Number), начиная с которого она будет нумеровать свои байты. И номером каждого сегмента в данном случае будет выступать число, равное смещению начального байта в сегменте относительно всего потока байт + SEQ-номер.

Рис 7. Нумерация байтов
Рассмотрим пример. Пусть отправляющая сторона выбрала SEQ-номер равный 32600. Номером первого сегмента будет очевидно 32600. Так как смещение начального байта в самом первом сегменте равно нулю. Номером второго сегмента будет 34060, так как смещение его начального номера относительно начала потока байтов — 1460. Обратите внимание, что прибавив к 32600 1460 мы получим не конечный номер байта первого сегмента, а именно начальный номер второго сегмента, так как смещение начинается не с нуля, а с единицы. В точности как в массивах.

Рис 8. Нумерация сегментов
К чему такие сложности? В чем проблема нумеровать байты, последовательно используя натуральные числа, начиная с единицы?
Действительно, такой выбор изначально может показаться довольно странным, но на то есть свои причины.
Смещение используется потому, что при нумерации вида 1,2,3, …, n отправителю и получателю пришлось бы согласовывать размер блока данных в начале соединения и отправлять сегменты строго такого размера, ибо в противном случае принимающей стороне пришлось бы вычислять смещения относительно начала потока байт самостоятельно, чтобы правильно расположить данные в памяти, что приводит нас к использованию смещения.
Вы можете спросить: «Ну и в чем же проблема использования фиксированного размера блока данных?» А вот вам загадка от Жака Фреско: вы используете фиксированный размер блока данных для отправки, и вдруг MTU канала связи меняется в меньшую сторону. Вопрос: как в таком случае отправлять данные? На размышление 5 секунд.
Вопрос: «Почему используется случайное число как начало отсчета?» самому автору не совсем ясен. Повально говорят о том, что это помогает от атаки при которой злоумышленник перехватывает соединение и отправляет жертве подделанные сегменты. Дескать угадать номер следующего сегмента предоставляет сложность, не зная начального SEQ-номера. Но получить валидный номер следующего сегмента можно, сложив SEQ-номер пакета с длиной блока данных, передаваемых в сегменте. Надеюсь, что более просвещенные люди дадут ответ на этот вопрос в комментариях.
Единственным оправданием использования SEQ-номера автору видится SYN-coockies, о которых речь пойдет чуть позже.
Также стоит отметить, что для квитирования используется поле Acknowledgment Number, в который указывается номер последнего полученного байта, увеличенного на единицу.
Для более лучшего понимания работы протокола читателю рекомендуется самостоятельно просниффить трафик и посмотреть, как происходит процесс рукопожатия и обмена информацией.
Часть 2. Атака SYN-flood
Суть атаки
Syn-flood атака — это одна из разновидностей DoS-атак. Принцип следующий: злоумышленник посылает огромное количество запросов установки соединения на атакуемый сервер. Сервер, видя сегменты с флагом SYN, выделяет необходимые ресурсы для поддержания соединения и отправляет в ответ сегменты с флагами SYN, ACK, переходя в состояние SYN-RECEIVED (такое состояние еще называют полуоткрытым соединением). Злоумышленник, не шлет ответные ACK сегменты, а продолжает бомбардировать сервер SYN-запросами, тем самым вынуждая сервер создавать все больше и больше полуоткрытых соединений. Сервер, понятное дело, располагает ограниченными ресурсами, и потому имеет лимит на количество полуоткрытых соединений. Ввиду этой ограниченности, при достижении предельного числа полуоткрытых соединений сервер начинает отклонять новые попытки соединения; таким образом и достигается отказ в обслуживании (Denial of Service).

Рис 9. Принцип SYN-flood атаки
Реализация атаки
Для проведения атаки нами будут использованы две виртуальные машины. В качестве жертвы будет выступать LMDE 6, а в качестве злоумышленника Kali 6.1.
Для начала установим лимит на количество полуоткрытых соединений на машине жертвы в 5 (по умолчанию 1024). Для этого нужно воспользоваться утилитой sysctl, которая позволяет вносить изменения в работающее ядро.

Рис 10. Задание максимального числа соединений
IP-адрес нашей машины 192.168.31.175

Рис 11. IP-адрес жертвы
Для проведения атаки воспользуемся утилитой hping3, которая является предустановленной в дистрибутиве Kali. В данном случае мы отослали 15 пакетов на 23 порт (telnet) с включенным флагом SYN, используя спуфинг IP-адресов.

Рис 12. Проведение атаки
После проведения атаки посмотрим информацию по открытым сокетам жертвы с помощью утилиты ss; -a показывает все сокеты, -t — TCP-сокеты, -o — информацию о таймерах.

Рис 13. Состояние сокетов жертвы
Как мы видим, наша машина поддерживает только 5 сокетов в полуоткрытом состоянии, хотя мы отправили 15 запросов на соединение. Если бы среди них был бы законный пользователь, то он бы получил отказ в обслуживании, чего мы и добивались.

Давайте изучим трафик, который был пойман во время проведения атаки.

Рис 14. Пойманный трафик
Как мы видим, нами действительно было отправлено 15 SYN-запросов, но только на 5 из них жертва ответила. Кстати обратите внимание на красно-черные строчки: наша машина повторно отправляет SYN, ACK ответы, так как думает, что они были потеряны или искажены.
Методы защиты от SYN-flood атак
Как же защищаться от SYN-flood атак? Тут есть два подхода, которые можно комбинировать между собой.
Во-первых, можно увеличить количество полуоткрытых TCP-соединений и уменьшить время, в котором сокет может пребывать в состоянии SYN-RECEIVED.
Во-вторых можно использовать SYN-cookie.
Идея SYN-cookie очень проста: когда к нам приходит SYN-запрос мы не создаем новое соединение, а отправляем SYN, ACK ответ клиенту, где в поле Sequence Number кодируем данные о данном соединение. Если мы получаем ACK ответ от клиента, то из поля Acknowledgment Number восстанавливаем данные о соединении. Данный метод хорош тем, что мы более не будем выделять ресурсы, как только к нам придет SYN-запрос. Но есть и очевидный минус: если наш пакет затеряется, или подвергнется искажению, то мы не сможем отправить его повторно, так как информацию о соединении мы условились не сохранять.
Для того, чтобы включить SYN-cookie, нужно воспользоваться утилитой sysctl

Рис 15. Установка SYN-cookie
Попробуем провести атаку еще раз и засниффить трафик.
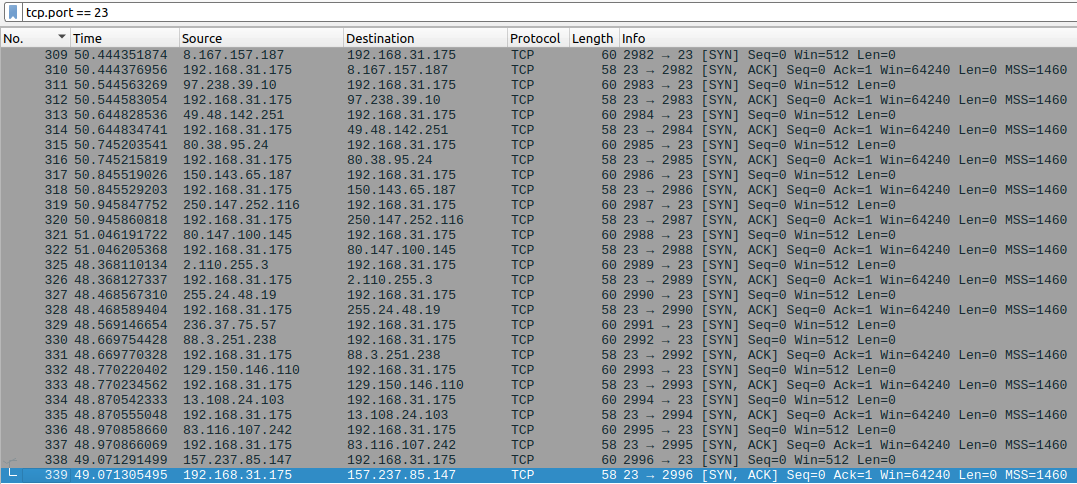
Рис 16. Траффик после включения SYN-cookie
Как мы видим, наша машина ответила уже на все запросы, но повторной отправки не последовало.
Если мы посмотрим на состояние сокетов, то увидим, что не одного полуоткрытого соединения не было создано.

Рис 17. Состояние сокетов после включения SYN-cookie
В данной статье мы познакомились с протоколом TCP, узнали об атаке SYN-flood, научились её проводить, а также защищаться от неё.
В данной статье рассматривалась только одна атака на протокол TCP, хотя в действительности их гораздо больше. Вот краткие описания каждой из них:
TCP-reset. Атака, при которой злоумышленник отправляет TCP-сегмент с флагом RST одному из участников соединения, что трактуется модулем TCP, как аварийное закрытие соединения.
TCP hijalking. Атака при которой злоумышленник вклинивается в соединение, маскируя свои пакеты под пакеты законного пользователя, тем самым поставляя жертве собственные данные.
Повторение TCP сегментов. Атака при которой злоумышленник перехватывает весь траффик, исходящий с одного источника, а затем, инициируя соединение, повторяет их вновь.
Используемая литература
Олифер Виктор, Олифер Наталья Компьютерные сети. Принципы, технологии, протоколы: Юбилейное издание. — СПб.: Питер, 2020. — 1008 с.: ил.
Олифер В.Г., Олифер Н.Ф Безопасность компьютерных сетей. — М.: Горячая линия — Телеком, 2016 — 644 с.: ил.
