Устройство 64-битных счётчиков транзакций в Postgres Pro Enterprise
Введение
Эта статья описывает реализацию 64-битных счётчиков транзакций (XID, ксидов) в СУБД Postgres Pro Enterprise, которая создана на основе свободной, опенсорсной объектно–реляционной СУБД Postgres. Она ориентирована на тех, кто имеет практический опыт в работе с СУБД Postgres Pro Enterprise, но будет интересна и тем, кто интересуется развитием СУБД Postgres, так как описывает сравнение этих двух систем. Статья также описывает устройство таблиц на диске и организацию формата хранения данных отношений.
Postrges старается быть максимально гибким в конфигурации, чтобы удовлетворить запросы как можно большего числа своих пользователей. Большинство параметров, например, таких, как: размер страницы BLCKSZ (по умолчанию 8 кБ), размер сегмента SEGSIZE (по умолчанию 1 Гб), могут быть изменены при сборке Postgres.
Хотелось бы сразу обозначить, что мы будем рассматривать 64-битный вариант сборки Postrges, в котором все параметры имеют значение по умолчанию. Также мы не будем углубляться в мультитранзакции. Для целей этой статьи будет достаточным предположения, что они в данном контексте аналогичны «обычным» транзакциям.
Мы выложили наш вариант реализации в сообщество, а также занимаемся активным продвижением его в сообществе разработчиков Postgres. Он не на 100% идентичен коду, используемому в Postgres Pro Enterprise (в частности, там ксиды всё ещё образуют кольцо), но общая идея такая же, как изложена в статье. На текущий момент патч ожидает ревью. Мы верим, что этот патч положительно скажется на удобстве использования и устойчивости Postgres, надеемся, что он будет принят сообществом в ближайшем будущем. Тем не менее по этому вопросу предстоит ещё много работы. Поэтому мы будем благодарны всем желающим и небезразличным за посильное участие в его развитии.
1. Счётчики транзакций
Рассмотрим подробнее: для чего они нужны в Postrges и какие проблемы могут возникать при их использовании.
1.1. Кратко об MVCC
Сложилось такое мнение, что базы данных — это механизм хранения данных, но это не совсем верно. Базы данных не только дают возможность хранения данных, но и обеспечивают согласованный и непротиворечивый и чаще всего многопользовательский доступ к этим данным. И именно это их свойство позволяет нам организовывать сложные многопользовательские системы хранения и обработки данных. Для тех, кто глубоко интересуется этой темой, можно упомянуть, что в основе работы большинства реляционных СУБД лежит набор свойств, известный как ACID. К таким СУБД относится и Postgres. Требования ACID накладывают на транзакционную систему, которой, безусловно является СУБД, ряд требований: атомарность, согласованность, изоляция и устойчивость. К сожалению, обсуждение этих принципов не является целью сегодняшней статьи, так что придётся оставить его за рамками изложения. Но интересующиеся либо уже знают про них, либо могут легко с ними ознакомиться, благо информации по этой тематике предостаточно, в том числе и в свободном доступе. Например, в книге Егора Рогова PostgreSQL изнутри, которая имеется в свободном доступе, или в The Internals of PostgreSQL Хиронобу Сузуки (Hironobu Suzuki).
1.2. Как MVCC реализовано в Postgres
В Postgres используется многоверсионный вариант протокола изоляции на основе снимков. В случае таблиц мы говорим не просто о строках, а о версиях строк (row versions, tuples), поскольку многоверсионность предполагает существование нескольких версий одной и той же строки (PostgreSQL изнутри, стр. 77). Такой механизм позволяет обходиться минимальным количеством блокировок. Фактически блокируется только повторное изменение одной и той же строки. Все остальные операции могут выполняться одновременно: пишущие транзакции никогда не блокируют читающие транзакции, а читающие вообще никогда никого не блокируют (PostgreSQL изнутри, стр. 54).
Данные в Postgres хранятся в виде кортежей (они же строки или записи) с добавлением некоторой служебной информации. Каждая транзакция в PostgreSQL имеет свой номер (идентификатор), называемый xid, который является простым, 32–х битным счётчиком. Каждая строчка в таблице, в свою очередь, имеет, помимо прочего, два дополнительных системных поля, которые не показываются в запросах пользователей: они называются xmin и xmax. Поле xmin хранит номер транзакции, которая создала данную строку, а xmax — номер транзакции, которая её удалила (если, конечно, такое произошло). Таким образом, каждая строчка может иметь несколько версий с разной областью видимости. Такой подход к организации хранения данных называется версионным.
Отдельно появляется вопрос: как определить какая транзакция следует за какой? Казалось бы, в чём может быть проблема? Если счётчик транзакций (xid) — это простое беззнаковое 32–х битное число, то это значит, что какой xid меньше, такой и был создан раньше, значит он и старше. Когда–то так и было. Но при достижении максимального значения счётчика транзакции СУБД нужно было останавливать и создавать из дампа заново.
К счастью, эти времена давно ушли. Сегодня используется механизм xid wraparound, который позволяет на работающем кластере запустить счётчик вновь с минимальным номером транзакции (как ни странно, но это номер 3, так как значения 0–2 зарезервированы для служебных целей) без пересоздания БД. Также вы можете ознакомиться с этим механизмом в статье Различия Postgres Pro Enterprise и PostgreSQL в пункте 2. Однако платить за это приходится более сложным подходом к вычислению возраста транзакций, а также необходимостью запуска вакуума в нужный момент времени.
Итак, в начале каждой транзакции создаётся соответствующий уникальный идентификатор. Его можно вывести, используя функцию txid_current (). Но при этом для транзакций не стоит использовать понятия «больше» и «меньше». Лучше использовать понятия «старше» и «младше». И вот почему: номера транзакций (xid) сравниваются друг с другом по модулю 232, то есть образуют кольцо. Все транзакции, отстоящие от текущей в сторону минуса на 231, считаются «в прошлом», а отстоящие на 231 в положительную сторону находятся «в будущем».
Графически это обычно изображается следующим образом:
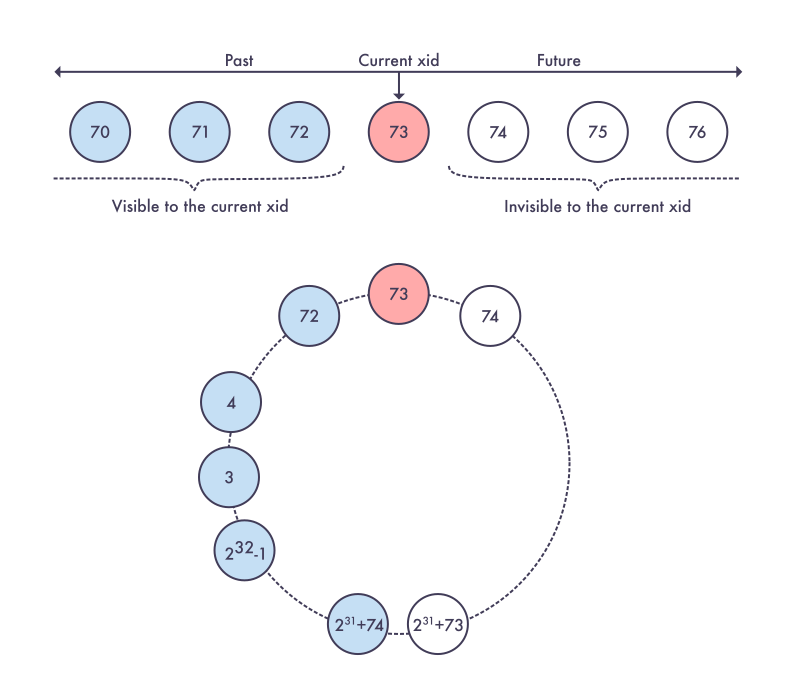 Рис. 1 — счётчики транзакций в Postgres
Рис. 1 — счётчики транзакций в Postgres
1.3. Основные проблемы существующего решения
Когда проектировался Postgres, количество транзакций в 4 миллиарда справедливо казалось огромным. Однако в современных реальных условиях эксплуатации Postgres приходится сталкиваться с тем, что xid wraparound может наступить за три и даже за два дня (!)
В таких условиях критичными становятся два фактора: отсутствие долгих («висящих») транзакций в БД и корректная работа вакуума (vacuum freeze, если быть точным). Если учесть, что при описанной выше транзакционной нагрузке работа последнего может занимать до дня времени, работа по администрированию Postgres в таких случаях становится довольно непростой. Достаточно упустить момент, и база будет остановлена.
В сообществе Postgres недавно обсуждался вопрос: является ли xid wraparound проблемой или нет. В целом, непосредственно сам механизм работает корректно и не является проблемой. Более того, в идеальном мире, где все механизмы отстроены и не дают сбоев, можно жить и с существующим решением. Однако для корректной работы Postgres в ситуации высокой транзакционной нагрузки нужна корректная работа нескольких разных механизмов (вакуум и xid wraparound), постоянный мониторинг параметров (например, самой старой транзакции) и незамедлительная реакция в случае увеличения разницы между самой старой транзакцией и самой новой.
1.4. Переход на 64-битные транзакции
Переход на 64-битные транзакции в случае высокой транзакционной нагрузки даст гораздо большую свободу администраторам БД. Конечно, он не отменяет обязательную работу вакуума, как и необходимость слежки за долгими транзакциями и возрастом самой старой транзакции. Но он сможет сделать эту работу не такой напряжённой, дав больший запас времени и простор «для манёвра».
Идея перехода на 64-битные счётчики транзакций находит положительный отклик в сообществе разработчиков Postgres. Понимание этого важного шага уже давно пришло к людям. Вопрос только в его конкретной реализации.
Другой интересный факт, что при этом можно будет отказаться от механизма кольца ксидов по модулю 232. Расчёты показывают, что даже при транзакционной нагрузке, при которой 32–х битные ксиды переполняются за два дня, в случае 64-битных транзакций понадобятся сотни лет чтобы счётчик исчерпался. Именно так поступили в Postgres Pro Enterprise: в нём ксиды не образуют кольца, при этом используется сравнение на «больше» и «меньше», чтобы понять какая транзакция старше, а какая младше.
2. Варианты реализации 64-битных счётчиков транзакций
Предлагаем следующие варианты реализации 64–битных счётчиков транзакций в Postgres:
«честные 64-битные ксиды»: замена всех счётчиков транзакций на 64-битные;
«через метод доступа»: изменить формат страниц для конкретных таблиц, для которых пользователь считает это нужным;
«хранение базы»: для каждой страницы хранить некоторое смещение,
относительно которого все ксиды на страницы должны быть вычислены.
Каждое из этих решений имеет как свои плюсы, так и минусы. В СУБД Postgres Pro Enterprise используется третий вариант, как самый компромиссный из всех. С одной стороны, он не требует значительного изменения формата страницы Postgres, фактически, оставляя формат кортежей на странице в оригинальном формате, с другой — нет значительного роста занимаемого дискового пространства.
3. Размещение на диске
Прежде, чем приступить к особенностям реализации 64-битных счётчиков транзакций в СУБД Postgres Pro Enterprise, нужно разобраться в том, как хранит данные таблиц PostgreSQL. И только после этого можно будет через сравнение понять: в чем заключается отличие СУБД Postgres от Postgres Pro Enterprise. Это изложение может показаться несколько длинным, но без него не будет понятно, какую проблему мы решаем, и почему выбрано именно такое решение.
3.1. От кластера до кортежа
Итак, основной метод борьбы со сложностью — это классификация. Ещё лучше, если она является иерархической. И нам повезло, что Postgres устроен как раз таким способом.
На самом «верхнем» уровне мы имеем кластер БД, то есть некоторую область на диске, которую мы будем использовать. В SQL применяется термин «кластер каталога». С точки зрения файловой системы кластер баз данных представляет собой один каталог, в котором будут храниться все данные.
 Рис. 2 — иерархия кластера
Рис. 2 — иерархия кластера
Логически кластер БД представляет собой набор баз данных, каждая из которых может состоять из таблиц, индексов и прочих объектов. В контексте данного изложения нас интересуют только таблицы (в Postgres часто в качестве синонима слова таблица используется слово heap, то есть куча) и частично индексы.
 Рис. 3 — устройство таблицы
Рис. 3 — устройство таблицы
Таблицы состоят из файлов–сегментов (они же heap files). Как только размер файла–сегмента исчерпывается, то создаётся новый файл и т.д. По умолчанию каждый сегмент равен 1 гигабайту, но его размер, конечно, может быть настроен. Делается это через опцию --with-segsize во время компиляции. Просмотр размера сегмента на работающем сервере выполняется через настройку segment_size.
Файлы–сегменты хранят данные в постраничном виде, по 8 килобайт. При этом, размер самой страницы можно менять. Для этого используется опция --with-blocksize при компиляции.
 Рис. 4 — устройство страницы на диске
Рис. 4 — устройство страницы на диске
В упрощённом представлении страницу можно представить следующим образом:
 Рис. 4.1 — устройство страницы на диске (упрощённое)
Рис. 4.1 — устройство страницы на диске (упрощённое)
Условно внутреннее устройство страницы можно разделить на три логических блока: заголовок страницы, массив указателей на кортежи и сами кортежи. При этом, каждый кортеж неявно имеет дополнительные xmin, xmax и ctid.
Эти служебные поля можно явно просмотреть, указав в запросе:
postgres=# create table foo(bar int, baz boolean);
CREATE TABLE
postgres=# insert into foo(bar, baz) select val, val % 2 <> 0 from generate_series(1, 10000) as val;
INSERT 0 10000
postgres=# checkpoint;
CHECKPOINT
postgres=# select xmin, xmax, ctid, * from foo limit 4;
xmin | xmax | ctid | bar | baz
------+------+-------+-----+-----
731 | 0 | (0,1) | 1 | t
731 | 0 | (0,2) | 2 | f
731 | 0 | (0,3) | 3 | t
731 | 0 | (0,4) | 4 | f
(4 rows)
postgres=# create extension pageinspect;
CREATE EXTENSION
postgres=# select * from page_header(get_raw_page('foo', 0));
lsn | checksum | flags | lower | upыper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/19B64D0 | 0 | 4 | 928 | 960 | 8192 | 8192 | 4 | 0
(1 row)Служебную информацию из заголовка страницы можно просмотреть, воспользовавшись контрибом (то есть дополнительно поставляемым модулем) pageinspect:
postgres=# SELECT oid::regclass AS table, relpages FROM pg_class WHERE relname = 'foo';
table | relpages
-------+----------
foo | 45
(1 row)
postgres=# create extension pageinspect;
CREATE EXTENSION
postgres=# select * from page_header(get_raw_page('foo', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/19B64D0 | 0 | 4 | 928 | 960 | 8192 | 8192 | 4 | 0
(1 row)
postgres=# select * from page_header(get_raw_page('foo', 44));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/1A4F770 | 0 | 4 | 248 | 6400 | 8192 | 8192 | 4 | 0
(1 row)Также интересно посмотреть на статистику по кортежам, и для этого воспользуемся контрибом pgstattuple:
postgres=# create extension pgstattuple;
CREATE EXTENSION
postgres=# \x
Expanded display is on.
postgres=# SELECT * FROM pgstattuple('foo');
-[ RECORD 1 ]------+-------
table_len | 368640
tuple_count | 10000
tuple_len | 290000
tuple_percent | 78.67
dead_tuple_count | 0
dead_tuple_len | 0
dead_tuple_percent | 0
free_space | 7380
free_percent | 2Получается интересная ситуация: хотя сами данные занимают 5 байт (4 байта на поле типа int и 1 байт на поле boolean), сам кортеж занимает 29 байт. Тут нет никакой загадки: 24 байта — это служебная информация кортежа и 5 байт самих данных пользователя. Естественно, это вырожденный случай, и в реальных условиях не часто может встречаться таблица из малого количества полей, но большая по размеру. Эту особенность стоит учитывать при проектировании больших баз данных.
3.2. Переход на 64-битные счётчики транзакций
Теперь давайте посмотрим как изменился формат страницы в Postgres Pro Enterprise при добавлении 64-битных счётчиков транзакций.
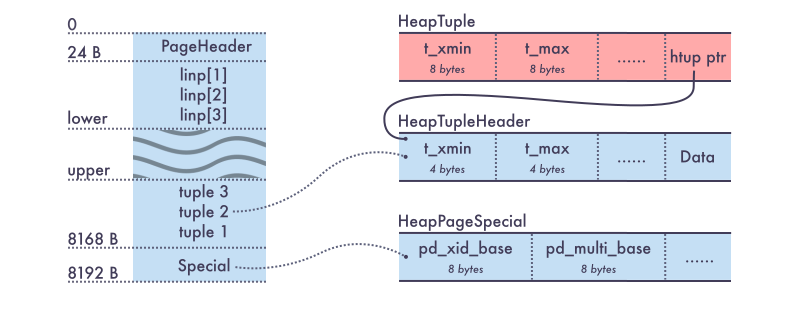 Рис. 5 — устройство страницы на диске в Postgres Pro Enterprise
Рис. 5 — устройство страницы на диске в Postgres Pro Enterprise
Видно, что размер кортежей на странице остался такой же, какой был в PostgreSQL. Для реализации 64-битных счётчиков транзакций в Postgres Pro Enterprise в конец каждой страницы таблицы (если точнее, то на страницу кучи) добавлена «специальная» область. Размер её 24 байта. Подобный механизм не уникален, он используется уже в некоторых индексах. Видно, что размер кортежей на странице остался такой же, как в PostgreSQL. Это важно, в том смысле, что страница остаётся в «оригинальном» формате, и переупаковки кортежей при обновлении с PostgreSQL на Postgres Pro Enterprise не требуется. В самой этой области находится общая информация для всех кортежей на странице:
/*
* HeapPageSpecialData -- data that stored at the end of each heap page.
*
* pd_xid_base - base value for transaction IDs on page
* pd_multi_base - base value for multixact IDs on page
* pd_prune_xid - oldest XID among potentially prunable tuples on page.
* pd_magic - magic number identifies type of page
*
* pd_prune_xid is a hint field that helps determine whether pruning will be
* useful. It is currently unused in index pages.
*
* pd_xid_base and pd_multi_base are base values for calculation of transaction
* identifiers from t_xmin and t_xmax in each heap tuple header on the page.
*
* pd_magic allows identified an type of object heap page belongs to.
* Currently, heap page may belong to an regular table heap or sequence heap.
*/
typedef struct HeapPageSpecialData
{
TransactionId pd_xid_base; /* base value for transaction IDs on page */
TransactionId pd_multi_base; /* base value for multixact IDs on page */
ShortTransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
uint32 pd_magic; /* magic number identifies type of page */
} HeapPageSpecialData;Выполним такую же последовательность команд, как в предыдущем разделе:
postgres=# create table foo(bar int, baz boolean);
CREATE TABLE
postgres=# insert into foo(bar, baz) select val, val % 2 <> 0 from generate_series(1, 10000) as val;
INSERT 0 10000
postgres=# checkpoint;
CHECKPOINT
postgres=# select xmin, xmax, ctid, * from foo limit 4;
xmin | xmax | ctid | bar | baz
------+------+-------+-----+-----
753 | 0 | (0,1) | 1 | t
753 | 0 | (0,2) | 2 | f
753 | 0 | (0,3) | 3 | t
753 | 0 | (0,4) | 4 | f
(4 rows)
postgres=# create extension pageinspect;
CREATE EXTENSION
postgres=# select * from page_header(get_raw_page('foo', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/182C868 | 0 | 4 | 924 | 936 | 8168 | 8192 | 254 | 750
(1 row)Легко заметить, что добавилась «специальная область» размером 24 байта. В рамках заметки нас интересуют только pd_xid_base и pd_multi_base.При этом, можно отметить, что транзакции и мультитранзакции — это два совершенно разных механизма в Postrges, каждый из них умеет свой «счётчик», поэтому для них используются две разные базы. Более датально про механизм мультритранзакций можно узнать в PostgreSQL изнутри, стр. 253.
3.3. Вычисление ксидов для кортежей
Теперь необходимо пояснить, как происходит вычисление 64-битных значений полей xmax и xmin для каждого из кортежей на странице. Это происходит следующим образом:
 Рис. 6 — устройство страницы на диске в Postgres Pro Enterprise
Рис. 6 — устройство страницы на диске в Postgres Pro Enterprise
В случае, если для транзакции установлен признак мультитранзакции, используется поле pd_multi_base. Остальные вычисления происходят аналогичным образом.
Внимательный читатель уже хочет спросить: если xmin и xmax в кортеже остались 32–битные, то получается что на одной странице нельзя разместить данные с транзакций, отстоящих друг от друга больше, чем на 232? Да, это так. С одной стороны, для большинства старых кортежей при условии работы автовакуума будет выставлен признак заморозки, то есть для них не будет проверяться само значение xmin. С другой стороны — мы уже работаем над устранением этого ограничения. И, возможно, мы сможем от него избавиться в ближайшее время.
3.4. Дисковое представление страниц отношений
Postgres Pro Enterprise размещает на heap страницах (т.е. на страницах таблиц) специальную область, которая называется special. В ней находится дополнительная информация, называемой «базой», которая позволяет вычислить 64-битные значения полей xmax и xmin для каждого из кортежей на странице. Это позволяет соблюсти баланс между увеличением размера хранимой информации и желанием получить 64-битные транзакции.
4. Обновления с Postgres до Postgres Pro Enterprise
Учитывая то, что формат страниц кучи меняется незначительно, возникает вопрос: возможно или нет обновление с PostgreSQL до Postgres Pro Enterprise?
4.1. Возможно? Да!
Да, обновление возможно! Оно выполняется с помощью стандартной утилиты обновления pg_upgrade. Далее страницы хипа «лениво» конвертируются в новый формат 64-битных счётчиков транзакций.
4.2. Особенности обновления
Первое, что важно знать: после такого обновления текущий счётчик будет 232. Это делается для того, чтобы любая новая транзакция была заведомо старше любой старой (учитывая возможный wraparound).
Вторая особенность: как поступить в случае, если на странице не хватает места? Что делать, если специальную область не получается разместить на странице даже после удаления «мёртвых» картежей и последующей переупаковки? В этом случае используется механизм, получивший название «double xmax». Суть его довольно проста: если мы не можем изменить страницу, тогда и не будем это делать. Зато xmin в кортежах на такой странице уже не имеет значения, потому что все данные заведомо «заморожены», и мы можем смело использовать поле xmin для хранения недостающей части 64-битного xmax.
Конечно, это довольно поверхностное изложение. Настоящий механизм учитывает множество разных ньюансов и особенностей. Но общая идея именно такова.
Выводы
В Postgres Pro Enterprise используются 64-битные счётчики транзакций. Данная статья описывает базовый механизм их работы, не углубляясь в детали реализации.
Переход на 64-битные ксиды позволил СУБД Postgres Pro Enterprise эффективно функционировать в системах с высокой транзакционной нагрузкой, упростив в этом смысле администрирование.
