Ускоряем Go: известные и не очень методы оптимизации и связанные с ними штуки
Привет, Хабр)
В этой статье хотел бы поделиться приёмами, которые позволяют повысить производительность Golang-кода. Некоторые из этих вещей довольно известные и их могут делать за вас линтеры, например go-critic, noctx (эти 2 касаются defer и отправки запросов без контекста).
Обсудим:
простые правила, которые не стоит забывать
мифы о производительности в духе «А я слышал, что X повышает скорость на Y%»
более интересные штуки, типо замены
switchнаmap, проведём пару тестов, поэкспериментируем
Ну и помним, что преждевременная оптимизация — корень всех зол, не стоит сразу пытаться писать скоростной код, это может быть не так просто.
t.me/Golang_google — полезные в работе гайды, фреймворки и примеры с кодом в моем телеграм канале для Golang разработчиков.
https://t.me/+w216niFfF39mMDQy — папка для всех, всем, кто интересуется GO .
Поехали!
Всем давно известно, что
— Лучше избегать использование defer в цикле. defer приводит к увеличению стека, а стек очищается только после завершения функции; к тому же, это может привести к не очень очевидным ошибкам.
— Отправка запросов без контекста. Скажем, у нас есть какой-то набор хендлеров, отправляются запросы, между запросами есть какой-то таймаут допустим 3 сек. И если мы не укладываемся в этот таймаут, то хорошо бы прекратить обрабатывание запроса.
— Нужно правильно использовать make. Нужно изначально создавать структуру нужного размера, чтобы не требовалось потом выделять для неё место в runtime, задерживая тем самым остальные процессы.
— Лучше использовать буферизированные каналы. Как всем известно, когда мы пишем в небуферизированный канал, пишущая горутина блокируется до того момента, пока другая горутина не прочитает из этого канала. Чтобы избежать этой блокировки, можно использовать буферизированный канал на 1 элемент.
Простые правила, которые лучше не забывать
Правильно обращаемся со слайсами
Аллоцируем память. В частности, если нам заранее известно количество элементов n, которые мы хотим положить в slice, правильно будет сразу создать slice с такой ёмкостью. Таким образом мы избегаем лишних аллокаций памяти, что всегда дорого:
make([]T, 0, n)Итерируемся. Если мы итерируемся по слайсу так:
for i, v := range slice то в переменную v попадает копия слайса, что особенно неприятно, если это слайс каких-то тяжёлых структур с кучей полей. Вместо этого лучше брать элементы из слайса по индексу:
for i := range sliceЭто телодвижение бессмысленно, если slice не хранит в себе ничего тяжёлого, а вот если наш слайс именно такой, с массой больших структур — то оптимизация будет кстати.
Оптимизируем парсинг JSON
Стандартный encoding/json не очень производительный, потому что использует под капотом рефлексии, которые всё-таки тяжёлые операции.
Поэтому можно использовать другие библиотеки для парсинга JSON, например fastjson или easyjson. И вот как-то так они используются:
// fastjson
s := []byte(`{"foo": [123, "bar"]}`)
fmt.Printf("foo.0=%d\n", fastjson.GetInt(s, "foo", "0"))// easyjson
someStruct := &SomeStruct{}
err := easyjson.Unmarshal(rawBytes, someStruct)
Пару мифов о производительности
Довольно часто приходится слышать что-то в духе «Говорят, X увеличивает производительность аж на Y%». Давайте разберём несколько таких мифов.
Есть разница в производительности между передачей параметра по ссылке и по значению (нет)
Будем использовать такую эталонную функцию:
// наш эталон производительности
var testInt64 int64
func BenchmarkDirect(b *testing.B) {
for i := 0; i < b.N; i++ {
incDirect()
}
}
func incDirect() {
testInt64++
}Напишем функцию, которая делает то же самое, но передавать аргумент ей мы будем по ссылке:
func BenchmarkDirectByPointer(b *testing.B) {
for i := 0; i < b.N; i++ {
incDirectByPointer(&testInt64)
}
}
func incDirectByPointer(n *int64) {
*n++
}Сравним скорости их выполнения:
BenchmarkDirect-4 2000000000 1.46 ns/op
BenchmarkDirectByPointer-4 2000000000 1.47 ns/opТа же скорость ±, ничего не поменялось.
Анонимные функции медленнее (нет)
Напишем анонимную функцию, сравним с эталонной:
func BenchmarkDirectAnonymous(b *testing.B) {
for i := 0; i < b.N; i++ {
func() {
testInt64++
}
}
}Запускаем сравнение:
BenchmarkDirect-4 2000000000 1.46 ns/op
BenchmarkDirectAnonymous-4 2000000000 1.44 ns/opВсё та же скорость, миф развеян.

Хмм, а если мы заменим switch на Map? Будет быстрее?
Ну, во-первых, switch бывают разные, можно затестить на switch размерами 10, 100 и 1000 кейсов (на 1000 в реальном проде, конечно, не пишутся ручками, а автогенерируются, обычно это type-switch). Во-вторых, switch можно затестить для 2 типов: int и string.
Поглядим на скорость:
BenchmarkSwitchIntSmall-4 500000000 3.26 ns/op
BenchmarkMapIntSmall-4 100000000 11.7 ns/op
BenchmarkSliceIntSmall-4 500000000 3.85 ns/op
BenchmarkSwitchStringSmall-4 100000000 12.7 ns/op
BenchmarkMapStringSmall-4 100000000 15.6 ns/opСамым быстрым оказался switch, следом за ним идёт slice, где по int-овому индексу хранятся нужные функции. Map оказался хуже switch и для int, и для string. Кстати, switch на string в несколько раз медленнее switch на int, что можно учитывать в написании своего кода.
Что ж, перейдём к большему количеству кейсов.
100:
BenchmarkSwitchIntMedium-4 300000000 4.55 ns/op
BenchmarkMapIntMedium-4 100000000 17.1 ns/op
BenchmarkSliceIntMedium-4 300000000 3.76 ns/op
BenchmarkSwitchStringMedium-4 50000000 28.5 ns/op
BenchmarkMapStringMedium-4 100000000 20.3 ns/op1000:
BenchmarkSwitchIntLarge-4 100000000 13.6 ns/op
BenchmarkMapIntLarge-4 50000000 34.3 ns/op
BenchmarkSliceIntLarge-4 100000000 12.8 ns/op
BenchmarkSwitchStringLarge-4 20000000 100 ns/op
BenchmarkMapStringLarge-4 30000000 37.4 ns/opКак видно, Map оказывается быстрее switch только на большом количестве кейсов. При этом slice часто оказывается быстрее switch, что можно использовать, оптимизация целых 1.5 нс (!)

Оптимизация итерации по массиву
Для повышения производительности мы можем итерироваться, используя указатель на массив. Тогда при помещении массива в range не создаётся его копия.
было:
for _, v := range hugeArray {
sum += v.h
}стало:
for _, v := range &hugeArray {
sum += v.h
}Если погонять тесты, то вот что мы видим — если использовать указатель на массив, скорость увеличивается в 1.5 раза:
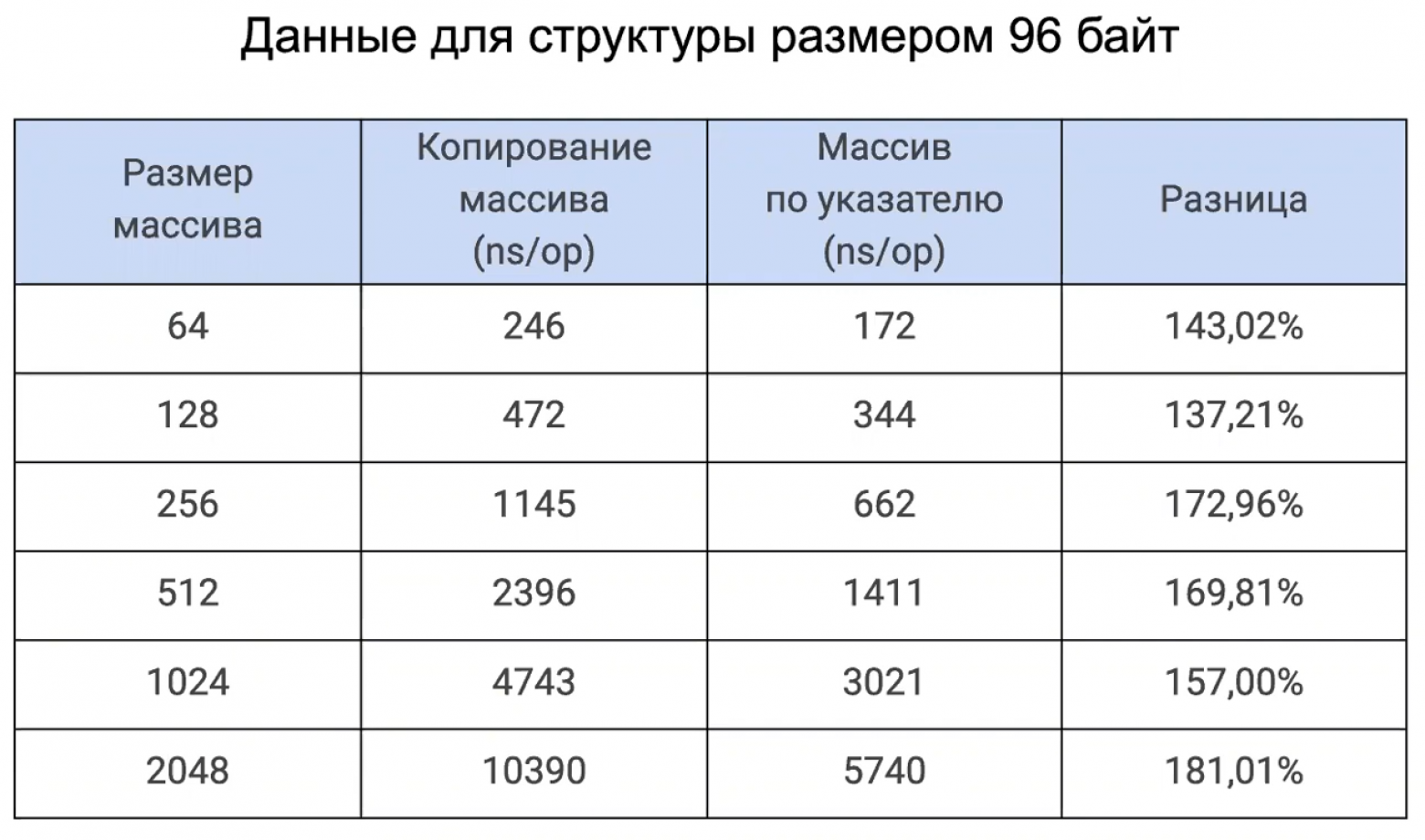
Разрыв в скорости должен увеличиться с увеличением размера массива. Что ж, возьмём массив 2Кб:

В общем, используем в range не сам массив, а указатель на него — профит!

Вместо заключения
К сожалению не получилось рассказать ещё про многое, что хотелось бы: переиспользование горутин, оптимизация syscall (например, при записи/чтении в файл), использование sync.Pool, а ещё атомики и много всего. Обязательно напишу про это как-нибудь в другой раз.
Что полезного по теме можно посмотреть:
Всем быстрого кода, прироста производительности на 1000% и всех благ)
