Using Flex (Fast Lexical Analyzer Generator)
Lexical analysis is the first stage of a compilation process. It’s used for getting a token sequence from source code. It gets an input character sequence and finds out what the token is in the start position, whether it’s a language keyword, an identifier, a constant (also called a literal), or, maybe, some error. A lexical analyzer (also known as tokenizer) sends a stream of tokens further, into a parser, which builds an AST (abstract syntax tree).
It’s possible to write a lexer from scratch, but much more convenient to use any lexer generator. If we define some parsing rules, corresponding to an input language syntax, we get a complete lexical analyzer (tokenizer), which can extract tokens from an input program text and pass them to a parser.
One of such generator is Flex. In this article, we’ll examine how it works in general, and observe some nontrivial nuances of developing a lexer with Flex.
A file, describing rules for Flex consists of rules. To describe a rule, it’s necessary three things: a state, a regular expression, and an executable code. So, what is a state? We can consider a lexer as a finite state machine. At the start, it has a state INITIAL. In Flex, it’s a default state and doesn’t require an explicit declaration. In most cases, for parsing a real computer language text, we need some additional states, for example, COMMENT, LINE_COMMENT и STRING. In some computer languages, like Pascal, we need more states for comments, because Pascal has two bracket forms of comments, (*comment*) and {comment}, and one-line comment (//comment), like C/C++ lang does. The main program text is processed in the INITIAL state, states COMMENT and LINE_COMMENT are for comments, obviously, and the state STRING is intended for string literals processing.
The next thing we need to describe a rule is a regular expression, which captures a lexeme. Flex always uses a greedy regex algorithm, capturing characters from an input text while they match a regex.
Flex performs rule checking in the order they are located, so a rule with higher priority must be located first.
A lexer must not fall to a segfault, it must process any chains of input symbols, including erroneous, and, if a chain doesn’t correspond to any lexeme of a language, get a special token for an error, to let a parser print corresponding error message with a number of a source text line containing an error.
It’s possible to describe a regex at the beginning of a .flex file, and then use its identifier.
Example:
DIGIT [0-9]+
...
{DIGIT} {
cool_yylval.symbol = inttable.add_string(yytext);
return INT_CONST;
}
An executable code here is run when a lexeme is captured by regex. Here we can change a finite state machine’s state:
\" {
BEGIN(string);
string_buf_ptr = string_buf;
string_buf_end = string_buf + MAX_STR_CONST;
}
Here at the symbol '»' the lexer’s state machine switches into a state «string». We can switch a state machine back to the state INITIAL this way: BEGIN (INITIAL);
Consider a lexer rule for a string literal:
(([^\"\n\\]*)(\\(.|\n))?)*[\\]?[\"\n]? {
while(*yytext) {
if(*yytext == 0x5c) {
switch(*(++yytext)) {
case 'b':
*string_buf_ptr++ = 8;
break;
case 't':
*string_buf_ptr++ = 9;
break;
case 'n':
*string_buf_ptr++ = 10;
break;
case 'f':
*string_buf_ptr++ = 12;
break;
case '\n':
*string_buf_ptr++ = '\n';
curr_lineno++;
break;
case 0:
BEGIN(INITIAL);
sprintf(string_buf, "String contains escaped null character.");
cool_yylval.error_msg = string_buf;
return ERROR;
default:
*string_buf_ptr++ = *yytext;
}
yytext++;
}
else
{
if(*yytext == '"')
{
BEGIN(INITIAL);
*string_buf_ptr = 0;
cool_yylval.symbol = stringtable.add_string(string_buf);
return STR_CONST;
}
if(*yytext == '\n') {
BEGIN(INITIAL);
curr_lineno++;
sprintf(string_buf, "Unterminated string constant");
cool_yylval.error_msg = string_buf;
return ERROR;
}
*string_buf_ptr++ = *yytext++;
}
if(string_buf_ptr == string_buf_end)
{
BEGIN(INITIAL);
sprintf(string_buf, "String constant too long");
cool_yylval.error_msg = string_buf;
return ERROR;
}
}
BEGIN(INITIAL);
sprintf(string_buf, "String contains null character.");
cool_yylval.error_msg = string_buf;
return ERROR;
}
Here we can see some nontrivial regex:
(([^\"\n\\]*)(\\(.|\n))?)*[\\]?[\"\n]?
t looks not very clear, doesn’t it? Let’s dive deeper. This regex represents the next NFA (nondeterministic finite automaton):
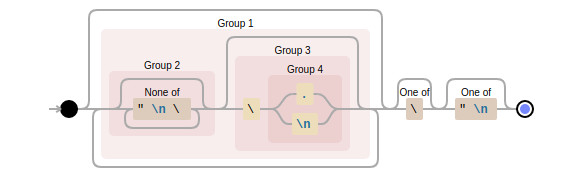
Why it’s so complex» A string literal always starts with '»' and must end with the same symbol, doesn’t it?
No, it doesn’t. At first, the '»' symbol can be located inside a string, if it’s screened by a backslash, such way: '\»'. The second nuance is the string can be finished not only correctly, according to the language syntax, but a user can make a mistake and doesn’t put a quotation mark at the end. In this situation, the lexer should not fall in the segfault, it must get an error message and finish the string parsing, returning to the initial state. Also, a user can put a backslash before an end of a line, then a string literal continues from the next line, according to language syntax (at least, in C and C++). Also, in very unlucky cases, a string can contain completely wrong characters, which have hexadecimal codes 0×01, 0×02, 0×03, 0×04, and which are not printable symbols at all, they were included in the ASCII table in the early epoch of Unix terminals as control symbols. And, in the worst case, a zero symbol can be placed in the middle of a string, and in most computer languages it means the end of a string, but we must process it correctly. So, a regular expression for recognizing string literals should concern a lot of possibilities, which makes it so sophisticated.
After this regex, we can see some scary executable code. Let’s dive into it.
while(*yytext) {
...
}
Here, «yytext» is a pointer to a current symbol, a lexer reads a fragment of source, captured by the regex, symbol by symbol.
if(*yytext == 0x5c) {
switch(*(++yytext)) {
case 'b':
*string_buf_ptr++ = 8;
break;
case 't':
*string_buf_ptr++ = 9;
break;
case 'n':
*string_buf_ptr++ = 10;
break;
case 'f':
*string_buf_ptr++ = 12;
break;
case '\n':
*string_buf_ptr++ = '\n';
curr_lineno++;
break;
case 0:
BEGIN(INITIAL);
sprintf(string_buf, "String contains escaped null character.");
cool_yylval.error_msg = string_buf;
return ERROR;
default:
*string_buf_ptr++ = *yytext;
}
yytext++;
}
Here, 0×5c is a backslash. The \b, \t, \n, \f combinations have a special meaning, they are control codes, 8 (backspace), 9 (tab), 10 (line feed), and 12 (form feed). A backslash at the end of a line makes the lexer insert a '\n' symbol (a new line). If we find a symbol with a zero-code after a backslash, it is a mistake, print an error message and set the initial state. A combination a backslash with any other symbols means just the same symbol (see the default branch).
Further text is rather simple:
{
if(*yytext == '"') {
BEGIN(INITIAL);
*string_buf_ptr = 0;
cool_yylval.symbol = stringtable.add_string(string_buf);
return STR_CONST;
}
if(*yytext == '\n') {
BEGIN(INITIAL);
curr_lineno++;
sprintf(string_buf, "Unterminated string constant");
cool_yylval.error_msg = string_buf;
return ERROR;
}
*string_buf_ptr++ = *yytext++;
}
And, finally, another two failure situation: a string buffer overload and a zero symbol inside a string:
if(string_buf_ptr == string_buf_end)
{
BEGIN(INITIAL);
sprintf(string_buf, "String constant too long");
cool_yylval.error_msg = string_buf;
return ERROR;
}
...
BEGIN(INITIAL);
sprintf(string_buf, "String contains null character.");
cool_yylval.error_msg = string_buf;
return ERROR;
The last failure situation: a file is finished, but string literal isn’t.
<> {
BEGIN(INITIAL);
sprintf(string_buf, "EOF in string constant");
cool_yylval.error_msg = string_buf;
return ERROR;
}
What if a lexer meets some wrong lexeme, which doesn’t match any regex?
It shouldn’t happen. All symbols that must not be in source code, but can appear due to some error, should be listed in a special rule, which prints an error message as a result:
[\!\#\$\%\^\&\_\>\?\`\[\]\\\|\0\001\002\003\004] {
string_buf[0] = *yytext;
string_buf[1] = 0;
cool_yylval.error_msg = string_buf;
return ERROR;
}
That’s all I wanted to say about building a lexer with Flex.
