Урок по оптимизации серверной части веб-приложений

Привет, Хабр! Меня зовут Алексей Приставко, я директор по веб-проектам в компании DataLine. Моя сегодняшняя статья посвящена тому, как исправить или предотвратить проблемы с производительностью бэк-энда веб-приложений.
Речь пойдет о том, как оптимизировать веб-приложения, которые страдают от хронических проблем с масштабируемостью, производительностью или надежностью.
Всем заинтересовавшимся — добро пожаловать под кат!
Терминология
Давайте для начала разберемся в терминологии. Говоря о производительности веб-проектов или веб-систем, я в первую очередь имею в виду back-end и серверную составляющую. То, что происходит при загрузке страниц в браузере — это совершенно другая история, которой, скорее всего, посвящу отдельную статью.
- Мерилом производительности приложения у нас будет являться количество обрабатываемых запросов в секунду (RPS) и скорость их выполнения (TTFB — Time to First Byte).
- Соответственно, под масштабируемостью системы мы будем понимать пул возможностей для увеличения RPS.
Теперь о надежности. Здесь обязательно нужно разделять два понятия: отказоустойчивость и катастрофоустойчивость.
- Устойчивость к отказам — способность системы при отказе одного или нескольких серверов к продолжению работы в рамках требуемых параметров.
- Устойчивыми к катастрофам считаются системы, имеющие полное дублирующее резервирование (т.н. второе плечо) и способные без сильной просадки работать при полном отказе одного из дата-центров.
При этом катастрофоустойчивая система ≠ отказоустойчивая система. Ситуация, в которой катастрофоустойчивая, но не отказоустойчивая система продолжает работать только на одном «плече», вполне нормальна. Но если откажет один из серверов, система также выйдет из строя.
Теперь, когда мы разобрались с ключевыми понятиями и освежили актуальную терминологию, пора переходить непосредственно к азам оптимизации и лайфхакам.
С чего начать оптимизацию

Как понять, с чего начать оптимизацию? Прежде, чем вы броситесь оптимизировать, сделайте глубокий вдох и потратьте время на исследование работы приложения.
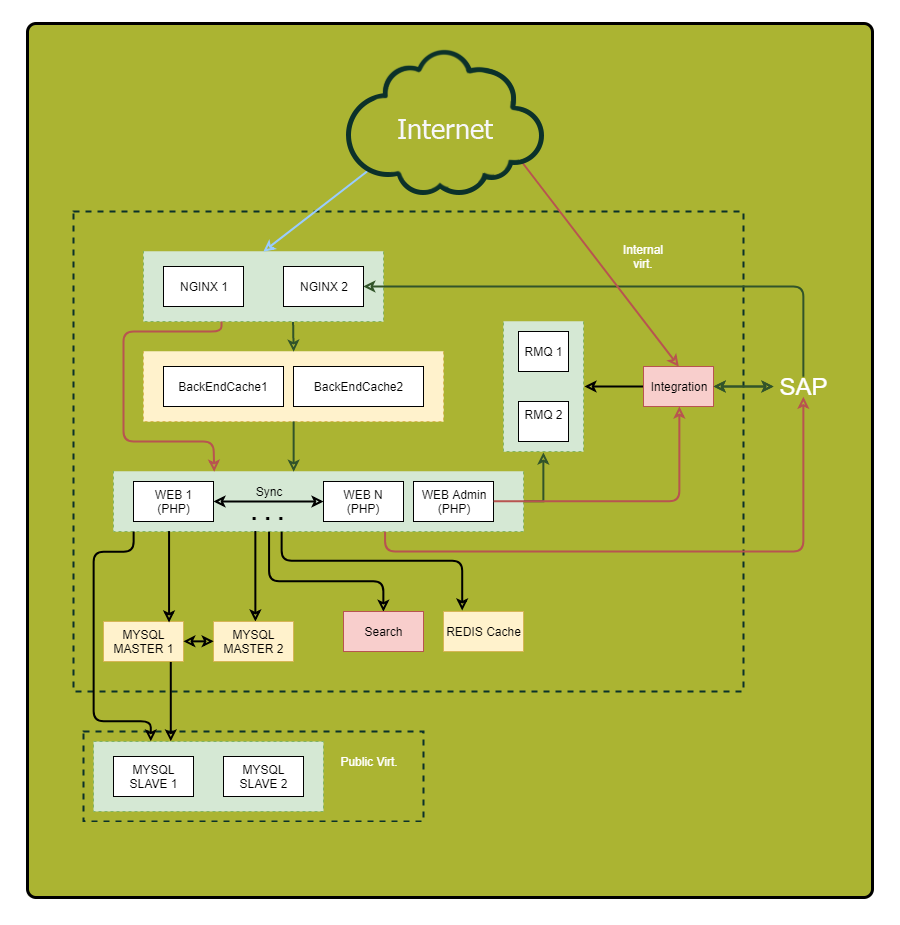
Обязательно нарисуйте подробную схему. Отобразите на ней все компоненты приложения и их взаимосвязи. Изучив эту схему, вы сможете обнаружить ранее неприметные уязвимости и потенциальные точки отказа.
«Что? Где? Когда?» — оптимизируем запросы
Особое внимание уделите синхронным запросам. Напомню, это такие запросы, когда в одном и том же потоке мы отправляем запрос и ждем по нему ответа. Тут как раз кроются причины серьезных тормозов, когда на другой стороне что-то идет не так. Поэтому, если можете сократить число синхронных запросов или заменить их на асинхронные, сделайте это.
Вот маленькие хитрости, которые помогут вам отследить запросы:
- Присваивайте каждому входящему запросу уникальный идентификатор. В Nginx для этого есть встроенная переменная $request_id. Передавайте идентификатор в заголовках на back-end и пишите во все логи. Так вы сможете удобно трассировать запросы.
- Логируйте не только конец запроса к внешнему компоненту, но и его начало. Так вы измерите реальную продолжительность отработки внешнего вызова. Она может существенно отличаться от того, что вы видите в удаленной системе, например, из-за проблем с сетью или тормозов DNS.
Итак, данные собраны. Теперь разберем проблемные точки. Определите:
- Где тратится больше всего времени?
- Куда приходит наибольшее количество запросов?
- Куда приходят самые «долгие» запросы?
В итоге вы получите список наиболее интересных для оптимизации участков системы.
Совет: Если какая-либо точка «собирает» множество мелких запросов, попробуйте объединить их в один большой запрос для сокращения накладных расходов. Результаты долгих запросов часто имеет смысл сохранить в кэш.
Кэшируем с умом
Существуют общие правила кеширования, на которые стоит опираться при оптимизации:
- Чем ближе кэш к потребителю, тем быстрее работа. Для приложения «ближайшим» местом будет оперативная память. Для пользователя — его браузер.
- Кэширование ускоряет получение данных и снижает нагрузку на источник.
Если десять веб-серверов делают одинаковые запросы к базе данных, централизованный промежуточный кэш, например в Redis, даст более высокий процент попаданий (по сравнению с локальным кэшем) и снизит общую нагрузку на БД, что существенно улучшит общую картину.
Совет 1: Делайте компонентное кеширование готовой странички на стороне Nginx с помощью Edge Side Includes. Оно хорошо ложится на микросервисную/SOA архитектуру и разгружает систему в целом, значительно улучшая скорость отклика.
Совет 2: Следите за размером объектов в кэше, показателем hit ratio и объемами записи/чтения. Чем больше объект, тем дольше он будет обрабатываться. Если вы пишете в кэш чаще или больше, чем читаете, такой кэш — вам не товарищ. Его стоит или убрать, или подумать над повышением его эффективности.
Совет 3: Используйте собственные кэши баз данных там, где это возможно. Их правильное конфигурирование может качественно ускорить работу.
Профили нагрузки
Переходим к профилям нагрузки. Как вы знаете, есть два основных типа: OLAP и OLTP.
- Для OLAP (Online Analytical Processing) важно количество отработанного трафика в секунду.
- Для OLTP (Online Transaction Processing) ключевой показатель — скорость отклика, миллисекундные тайминги.
Чаще всего бывает эффективно разделить эти два вида нагрузки. Как минимум, вам понадобится раздельный тюнинг базы данных и, возможно, других компонентов системы.
Совет: Запросы на чтение из админки, как правило, обрабатываются по типу OLAP. Создайте под эту задачу отдельную копию БД и веб-сервер, чтобы разгрузить основную систему.
Базы данных

Итак, мы закономерно подошли к одному из самых сложных этапов оптимизации —, а именно, к оптимизации базы данных.
Напомню вам общее правило: чем меньше объем базы, тем быстрее она работает. Сама организация базы данных имеет решающее значение, когда дело касается скорости.
По возможности храните исторические данные, логи приложения и часто используемые данные в разных базах данных. Еще лучше — разнесите их на разные сервера. Это не только облегчит жизнь основной БД, но и даст больше пространства для дальнейшей оптимизации, к примеру в ряде случаев позволит использовать разные индексы под разную нагрузку. Также «однотипность» нагрузки упрощает жизнь планировщику и оптимизатору запросов сервера БД.
И снова о важности планирования
Чтобы не ломать голову над оптимизацией там, где она не сильно нужна, выбирайте железо, исходя из задач.
- Под мелкие, но частые запросы лучше взять больше ядер процессора.
- Под тяжелые запросы — меньше ядер с более высокой тактовой частотой.
Постарайтесь поместить рабочий объем базы данных в оперативную память. Если это невозможно или имеет место большое количество запросов на запись пора посмотреть в сторону перенести базы данных на SSD-диски. Они дадут существенный прирост скорости работы с диском.
Масштабирование

Выше я описал ключевые механики повышения производительности приложения без увеличения его физических ресурсов.
Теперь мы поговорим о том, как выбрать стратегию масштабирования и повысить отказоустойчивость.
Существует два вида масштабирования системы:
- вертикальное — рост объема ресурсов при сохранении количества сущностей;
- горизонтальное — рост количества сущностей.
Растём в высоту
Начнем с выбора стратегии вертикального масштабирования.
Для начала рассмотрим увеличение мощности системы. Если ваша система работает в рамках одного сервера, придется сделать выбор между повышением мощности текущего сервера или покупкой еще одного.
Может показаться, что первый вариант проще и безопаснее. Но дальновиднее будет докупить еще один сервер и бонусом к производительности получить большую отказоустойчивость. Об этом я говорил в начале статьи.
Если в вашей системе несколько серверов и стоит выбор — увеличить мощность существующих или докупить еще несколько, обратите внимание на финансовую сторону. Например, один мощный сервер может оказаться дороже, чем два на 50% «слабее». Поэтому резонно будет остановиться на втором компромиссном варианте. В то же время, при большом количестве серверов решающее значение имеет соотношение производительности, энергопотребления и стоимости полной стойки.
Растём в ширину
Горизонтальное масштабирование системы — это история про отказоустойчивость и кластеризацию. В общем случае, чем больше экземпляров одной сущности мы имеем, тем выше отказоустойчивость целого решения.
Вероятно, первое, что вам захочется масштабировать — это серверы приложений. Первое препятствие на этом пути — организация работы с централизованными источниками данных. Помимо баз данных, это еще и сессионные данные, и статический контент. Вот что я советую сделать:
- Для хранения сессий используйте Couchbase, а не привычный Memcached, так как он работает с тем же протоколом, но, в отличие от memcached, поддерживает кластеризацию.
- Всю статику, особенно большие объемы изображений и документов, храните отдельно и отдавайте с помощью Nginx, а не из кода приложения. Так вы сэкономите на потоках и облегчите управление инфраструктурой.
«Подтягиваем» базы данных
Сложнее всего масштабировать базы данных. Для этого есть две основные техники: шардирование и тиражирование. Рассмотрим их.
При тиражировании мы добавляем в систему полностью идентичные копии базы данных, при шардировании — логически разделенные части, шарды. При этом, шардирование крайне желательно проводить параллельно с репликацией (тиражированием) каждого шарда, чтобы не потерять отказоустойчивость.
Помните: зачастую кластер БД состоит из одной master-ноды, принимающей на себя поток записи, и нескольких slave-нод, используемых для чтения. С точки зрения отказоустойчивости, это немногим лучше одиночного сервера, так как общая отказоустойчивость определяется наименее устойчивым элементом системы.
Схемы с более, чем двумя мастерами баз данных (топология «кольцо») без подтверждения записи на каждом из серверов, очень часто страдают от неконсистентности. В случае сбоя одного из серверов восстановить логическую целостность данных в кластере будет крайне затруднительно.
Совет: Если в вашем случае не рационально иметь несколько мастер-серверов, предусмотрите архитектурную возможность работы системы без мастера хотя бы в течение часа. В случае аварии это даст вам время на замену сервера без простоя всей системы.
Совет: Если есть необходимость держать более 2-х мастеров баз данных, рекомендую вам рассмотреть NoSQL-решения, так как многие из них имеют встроенные механизмы приведения данных в консистентное состояние.
В погоне за отказоустойчивостью ни в коем случае не забывайте, что репликация страхует вас только от физического отказа сервера. Она не спасет от логической порчи данных из-за ошибки пользователя.
Помните: Любые важные данные необходимо бэкапить и хранить в виде независимой не редактируемой копии.
Вместо заключения
Напоследок — пара советов про производительность при создании резервных копий:
Совет 1: Снимайте данные с отдельной реплики базы данных, чтобы не нагружать активный сервер сверх меры.
Совет 2: Имейте под рукой дополнительную, слегка «отстающую» по времени реплику базы данных. В случае аварии это поможет уменьшить количество потерянных данных.
Приведенные в этой статье методы и техники ни в коем случае нельзя применять вслепую, без анализа текущей ситуации и понимания, чего бы вам хотелось достичь. Вы можете столкнуться с «переоптимизацией», и полученная система окажется лишь на 10% более быстрой, но на 50% — более уязвимой к авариям.
На этом всё. Если у вас остались какие-то вопросы, я с удовольствием отвечу на них в комментариях.
