Управляем пользователями и топиками Apache Kafka с помощью оператора Kubernetes
Всем привет!
Меня зовут Иван Гулаков, я техлид DevOps-команды, отвечающей за инфраструктуру, где работают облачные сервисы #CloudMTS.
Сегодня я расскажу, как с помощью самописного оператора Kubernetes мы автоматизировали управление пользователями и топиками наших Kafka-кластеров.
Как мы используем Kafka
В инфраструктуре #CloudMTS Kafka используется:
- для асинхронного взаимодействия микросервисов облачной платформы;
- в качестве буфера для логов, которые потом вычитываются kafka-connect и отправляются в elasticsearch для дальнейшего анализа и хранения;
- для сбора метрик в формате Prometheus для дальнейшей отправки в VictoriaMetrics.
Для этого даже написали свой агент.
Всего в инфраструктуре #CloudMTS насчитывается около десятка on-premise-кластеров Kafka, расположенных в различных регионах и дата-центрах. Мы используем версию от Confluent.
Как было раньше
Когда численность команды облака была совсем небольшой, мы единожды сконфигурировали TLS, аутентификацию и авторизацию для кластеров (вернее, написали файлы ответов для плейбуков от Confluent).
Аутентификацию мы настроили SASL/SCRAM. В отличие от PLAIN/SASL, с помощью нее новых пользователей можно добавлять динамически без перезагрузки брокеров.
Авторизацию выбрали на основе ACL: она универсальна и работает в том числе на Apache Kafka, да и знакомо с ней большое число людей.
А вот с автоматизацией добавления пользователей/топиков/ACL мы не заморачивались, она была разрозненна и сделана на полуручном приводе. Когда число сотрудников перевалило за сотню, а количество сервисов — за несколько десятков, такой подход стал стопорить работу. Пришлось сесть и спроектировать решение, которое раз и навсегда избавит нас от головной боли.
Что хотелось получить
Вопрос с менеджментом кластеров хотелось закрыть целиком и убить всех зайцев сразу, а их было немало:
- Централизованно создавать топики в кластере. До этого топики создавались клиентами самих приложений при их инициализации. Росло число команд разработки, появился целый зоопарк библиотек для взаимодействия с Kafka. Разработчики часто пользовались дефолтными настройками библиотек, и стали происходить забавные ситуации. Например, создавались мертворожденные топики, у которых количество реплик было меньше заданного в кластере min.insync.replicas, и такие топики блокировались на запись.
Кроме того, манипуляции с топиком из приложения — это отличный способ выстрелить себе в ногу. Можно добавить нежелательные параметры, удалить и пересоздать топик и потерять данные.
- Стандартизировать именование пользователей в кластере. Testuser«ы должны были умереть.
- Автоматизировать добавление ACL. Таскать за собой портянку переменных для ansible, а уж тем более набивать длинные команды руками изрядно надоело.
Но была и еще одна проблема: ошибки при конфигурации ACL, которые допускали разработчики. Например, при веточном деплое в dev или на личном стенде разработчика иногда происходили ситуации, когда отладочное приложение начинало «красть» сообщения у основной версии и происходили различные неприятные казусы.
- И самое главное — сделать так, чтобы все вышеперечисленное мог делать сам разработчик запуском без помощи инженеров по эксплуатации. Я имел дело с заведением всех этих сущностей по заявкам на другом месте работы, и возвращаться к подобному опыту совсем не хотелось. Было жалко и команды разработки, которым пришлось бы тратить время на дополнительное заполнение тикетов по шаблону, что у них точно не вызовет восторга, и своих инженеров, которым бы эти заявки пришлось выполнять.
Как выбирали решение
Очевидно, что следующий вопрос, который вставал перед нами, —, а как это нормально централизовать и стандартизировать?
Вариант с заявками мы не рассматривали, хотя этот способ решал одну важную проблему — контроль создаваемых в кластере сущностей, пускай и порождая синдром вахтера.
Следующей на очереди была идея с неким центральным репозиторием с IAC в Gitlab.
Но за этим репозиторием опять кто-то должен был постоянно следить, запускать прогон пайплайна. Отдельной проблемой было то, что в такой конфигурации бы все равно приходилось предварительно идти в одно место, настраивать инфраструктуру и только потом выкатывать приложение.
Рассматривали вариант с запуском во время деплоя приложения неких отдельных джобов, которые подготовят кластер Kafka. Но тоже отмели, так как в этом случае мы жертвовали бы скоростью деплоя приложения (ведь сперва должны отработать джобы по настройке Kafka) и терялась единая точка правды о состоянии инфраструктуры.
Кроме того, в обоих случаях хромал бы процесс валидации хранимых в Gitlab манифестов.
И вот тут-то и пришло озарение — все наши приложения живут в k8s, так почему бы не воспользоваться его функциональностью и не написать оператор?
Как работают операторы
Не буду останавливаться и подробно описывать, что такое оператор, как он работает и т. д., об этом можно найти множество статей, например, вот.
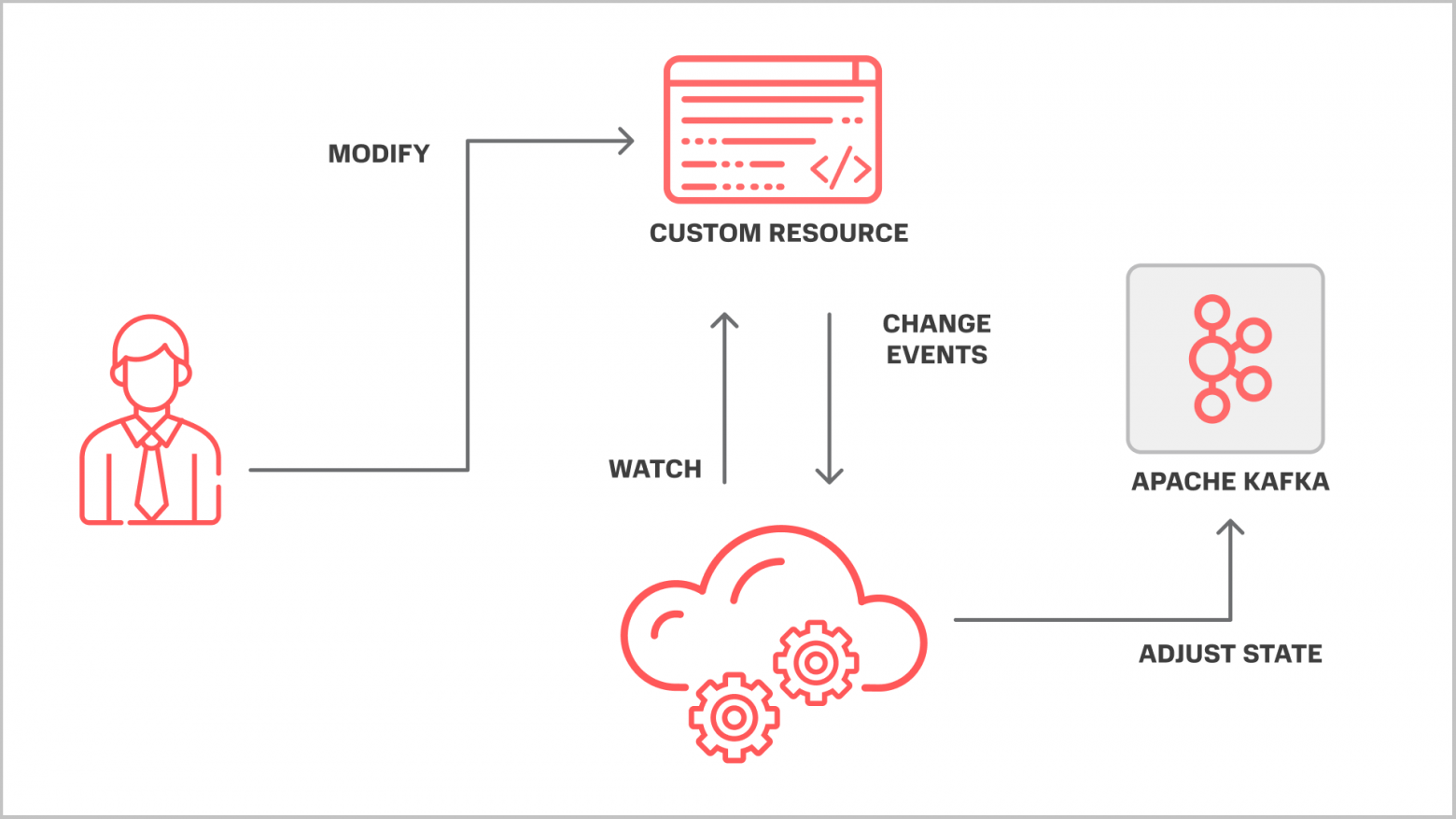
Если кратко, оператор реагирует на некие события в кластере и в зависимости от них производит некоторые действия и приводит подконтрольные ему (оператору) сущности к желаемому состоянию. Это и есть тот самый reconciliation (control loop). В нашем случае мы хотим приводить внешнюю по отношению к Kubernetes систему, то есть наш кластер Kafka, к желаемой конфигурации. Мы без проблем можем завязаться на кубовые ивенты по изменению наших CR и решить сразу несколько проблем:
- Только сами по себе CRD и CR решают два важных вопроса: как структурированно хранить информацию о пользователях/топиках/ACL и прочих штуках и заодно как эту информацию валидировать не отходя от кассы.
- Пресловутая событийная модель уже реализована за нас. Не нужно придумывать какие-то велосипеды и решать, когда реагировать, а когда нет. Для это уже есть готовые SDK, есть ретраи до победного «из коробки».
- Склеить инфраструктуру и приложение в единое целое.
Почему решили писать сами
— Нам был нужен довольно узкий функционал по настройке сущностей в кластере и более тонкий контроль производимых с кластером действий. Грубо говоря, реализовали ровно столько, сколько нужно.
— Это решение в дальнейшем нужно было интегрировать в наш общий helm-чарт для валидации создаваемых ресурсов согласно нашим стандартам. В целом планировалось, что конечным пользователем оператора будет не инженер эксплуатации, а разработчик (пусть и через врапперы). У него будут простенькие статусы в CR, чтобы понять, пошло ли что-то не так или все хорошо.
— Ну и еще один момент — CRD проектировались максимально изолированными и децентрализованными, чтобы нельзя было случайно навредить соседям.
CRD и что умеет наш оператор
Коротко о том, что в итоге оператор умеет делать и как это представлено в виде CR.
Работа с пользователями. Тут все довольно просто, каких-то фишек нет.
apiVersion: kafka.cloud.mts.ru/v1alpha1
kind: User
metadata:
name: pupkin
namespace: default
spec:
user: pupkin
password: pupkin
Работа с топиками. Здесь уже интереснее — доступен полный менеджмент настроек.
Реплики, партиции, любые доступные в Confluent Kafka настройки можно прокинуть на топик в виде мапы (advanced_options). Также есть флажок для принудительного удаления топика после удаления CR. Иногда это актуально для разработчиков, если надо почистить за собой, особенно на dev.
apiVersion: kafka.cloud.mts.ru/v1alpha1
kind: Topic
metadata:
name: pupkin-topic
namespace: default
spec:
name: pupkin-topic
replication_factor: 3
partitions: 3
purge_on_service_deletion: true
advanced_options:
"cleanup.policy": "delete"
"delete.retention.ms": "86400000"
Работа с ACL. Ну и самый болезненный для нас вопрос — менеджмент ACL. История с ACL сама по себе довольно сложная и запутанная, а тут надо было еще и попытаться как-то упростить ее для разработчиков. Подробно про то, как это работает внутри, можно почитать у Confluent.
Из небольших нюансов: реализовано 2 resource_type — topic и group. Другие сущности нам не понадобились. Компоновка настроек чуть-чуть отличается от формата консольной утилиты, чтобы манифест было удобнее читать.
apiVersion: kafka.cloud.mts.ru/v1alpha1
kind: ACL
metadata:
name: pupkin-topic
namespace: default
spec:
principal: pupkin
resource_pattern: literal
resource_type: topic
resource_name: pupkin-topic
operations:
- ALTER
- ALTER_CONFIGS
- CREATE
- DELETE
- DESCRIBE
- DESCRIBE_CONFIGS
- READ
- WRITE
Ну и небольшой бонус — из-за того, что у людей возникала путаница между тем, что можно/нельзя/нужно/не нужно, реализовали простенькие хелперы в статусе ресурса.
Выглядит это так:
apiVersion: kafka.cloud.mts.ru/v1alpha1
kind: ACL
metadata:
name: pupkin-topic
namespace: default
spec:
operations:
- READ
- WRITE
- DESCRIBE
- DESCRIBE_CONFIGS
- habrahabr
principal: pupkin
resource_name: pupkin-topic
resource_pattern: literal
resource_type: topic
status:
available_operations:
- READ
- WRITE
bad_operations:
- habrahabr
help_message: >-
Controller is stuck. Remove bad operations [habrahabr] from spec.operations
before proceeding
missing_operations:
- DESCRIBE
- DESCRIBE_CONFIGS
orphaned_operations: null
synced: false
Я уже упоминал ранее, что у нас есть общий Helm-чарт для деплоя приложений.
В двух словах — есть репозиторий с сервисом, там есть несколько наборов *.values.yaml, на основе которых происходит прогон пайплайна выкатки, в том числе рендерится непосредственно чарт с приложением. Именно там лежат шаблоны манифестов, которые были рассмотрены выше, разработчики взаимодействуют с оператором через *values-обертку. Никаких составлений и применений манифестов вручную. Вместе с приложением приезжает и инфраструктура, то есть точка входа для настройки единая.
Выглядит это примерно вот так:
Kafka:
User: encrypted_user
Password: encrypted_pass
Topics:
- Name: licensing.billing-plugin.start-tact
ReplicationFactor: 3
Partitions: 4
PurgeOnServiceDeletion: false
AdvancedOptions:
"cleanup.policy": "delete"
ACLs:
ConsumerGroupName: licensing-billing-plugin
- Name: licensing.billing-plugin.fetch-orgs
ReplicationFactor: 3
Partitions: 4
PurgeOnServiceDeletion: false
AdvancedOptions:
"cleanup.policy": "delete"
ACLs:
ConsumerGroupName: licensing-billing-plugin
Custom:
- Principal: networks-networker
ResourcePattern: literal
Operations:
- READ
- WRITE
- DESCRIBE
Здесь мы описываем пользователя, подконтрольные нашему пользователю и сервису топики, а также доступы к ним. Часть настроек можно опустить, если устраивают дефолтные.
Как защитились от ошибок: валидация
Возникает закономерный вопрос —, а как защитить непосредственно саму Kafka от деструктивных запросов? Эту историю можно поделить на две больших части — те запросы, которые мы в принципе хотим отсекать, и то, что может быть нужно, но разработчикам мы давать делать не хотим.
Первая часть вопроса решена на уровне CRD и непосредственно самого кода (внутри использован клиент kadm).
Kubebuilder позволяет гибко настраивать и валидировать поля в CR, так что различные базовые ошибки вроде несовпадения типов и прочего отфильтровываются именно там.
А вот наши стандарты и защита от шаловливых ручек реализованы уже на уровне Helm. Стандартизированные названия топиков, разделители в именах, длина имен, защита от именования своего пользователя/топика именем чужого проекта, исключение ACL вроде CREATE — всю эту бизнес-логику мы проверяем уже на этапе деплоя приложения. Если разработчик заполнил конфиг не по конвентам и инструкции, то деплой упадет и выдаст список ошибок для исправления. Такое разделение сделано для того, чтобы можно было спокойно использовать оператор на своих стендах и ломать их как угодно, но вот сломать коммунальный кластер Kafka уже было бы нельзя.
Что в итоге получили
Оператор (в связке с Helm) в итоге решил для нас следующие проблемы:
- Единая точка правды о сущностях кластера Kafka в виде Kubernetes.
- Возможность снять дамп манифестов (CR), быстро восстановиться из него в случае аварии.
- Приложение и инфраструктура под него теперь становились одним целым — в результате установки Helm-чарта мы гарантированно получаем нужную нам конфигурацию кластера.
- Вахтер теперь может заняться более полезными делами — кнопку за него нажимает Reconciliation Loop.
- Значительное ускорение скорости деплоя приложения с точки зрения CI/CD: последовательные джобы не нужны. Более того, оператор обрабатывает событие в десятки раз быстрее, чем запуск пода с новой джобой gitlab runner’ом.
- Разработчики теперь могут самостоятельно настраивать пользователей/топики и ACL для своих приложений.
- Статусы о состоянии сущностей в Kafka можно посмотреть рядом с приложением в Kubernetes.
- Защита от деструктивных изменений и выстрелов по ногам.
Ну и парочка минусов, куда уж без них:
- Накладные расходы по разработке и поддержке решения выше, чем при использовании условных плейбуков, тут увы.
- Чисто теоретически появляется дополнительная точка отказа CI/CD-конвейера, но это небольшая цена за удобство и скорость доставки изменений в инфраструктуру.
В целом плюсы для нас значительно перевесили минусы, и мы продолжаем развивать это решение. В дальнейших планах интеграция с Vault PKI, добавление TLS-аутентификации (пользователей) и интеграция оператора с различными нашими служебными приложениями, взаимодействующими с Kafka.
