Умный поиск: как искусственный интеллект hh.ru подбирает вакансии к резюме
Больше половины соискателей ничего не ищут, а создают резюме и просто ждут, когда их пригласят на собеседование или хотя бы пришлют подходящую вакансию. Когда мы думали, как для них должен выглядеть сайт по поиску работы, то поняли, что им нужна всего одна кнопка.

Делать такую систему мы начали полтора года назад — решили построить на машинном обучении алгоритм, который сам выбирал бы подходящие пользователю вакансии. Но мы очень быстро поняли: вакансии, похожие на резюме, и вакансии, на которые владельцу резюме хочется откликнуться, — далеко не одно и то же.
В этой статье я опишу, как мы сделали умный поиск — со всеми проблемами, тонкостями и компромиссами, на которые пришлось пойти.
Начали с рекомендательной системы
На hh.ru существуют рассылки с подходящими вакансиями. За них мы и взялись в первую очередь: начали с создания рекомендательной системы, которая будет приносить соискателям подходящие вакансии сама.
Чтобы разобраться в вопросе, мы сделали логирование того, какие вакансии показываются пользователям и что пользователи делают с ними дальше. Разработали систему a/b-тестов, инфраструктуру для того, чтобы с помощью машинного обучения прогнозировать вероятность отклика для пары «резюме/вакансия».
В production добавили расчёт статических признаков при индексации и последовательное применение к вакансиям для резюме нескольких фильтрующих моделей с увеличивающейся ресурсоёмкостью, а потом и модели для финального ранжирования.
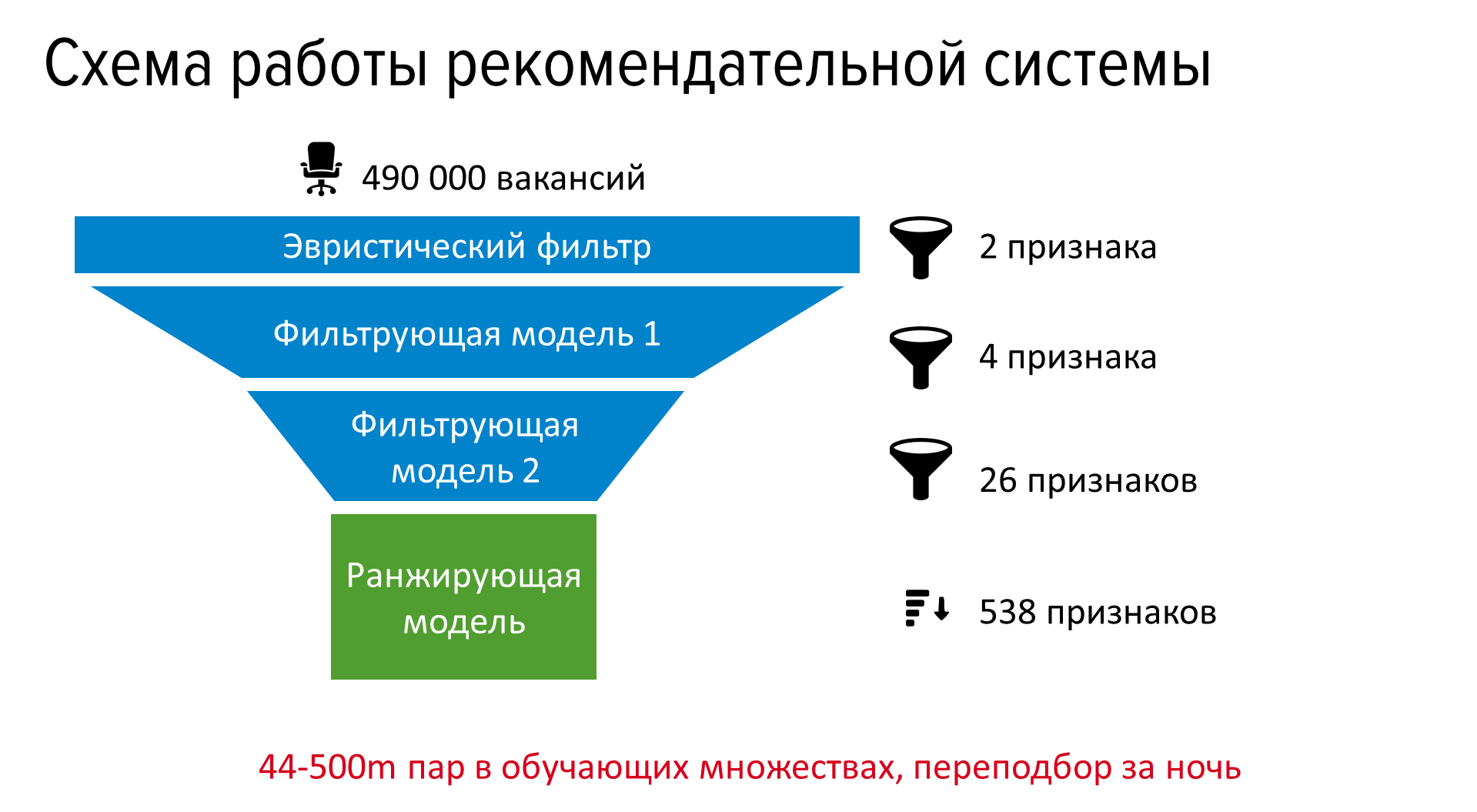
Система стала приносить нам около 1,2 миллиона дополнительных откликов в месяц, а это примерно 120 тысяч приглашённых на собеседование и 20 тысяч нанятых. Отобранные рекомендательной системой вакансии приходят по почте, показываются в блоке «Рекомендуем лично вам» на главной hh.ru и в подходящих вакансиях для резюме.
Но даже сравнительно небольшое улучшение в поиске выгоднее большого в рекомендательной системе. Поэтому следующим шагом стало применение машинного обучения в поиске.
Поиск по пустому запросу
Мы начали с анализа поисковых запросов. Оказалось, что в 35% запросов пользователи, у которых есть резюме, оставляют поисковую строку пустой. Если считать и анонимные запросы, то количество пустых поисковых запросов достигает 50%.
Для случаев, когда у пользователя есть резюме, мы решили применить рекомендательную систему: заменить ранг по текстовому соответствию на ранг от рекомендательной системы. Это не требовало больших изменений и получилось сделать довольно быстро.
Использование ранга от рекомендательной системы дало несколько тысяч дополнительных откликов в сутки. Но эффект был меньше ожидаемого. Так как пользователи просматривают в среднем только первые полторы страницы выдачи, то в больших городах изменения касались, по сути, только премиальных вакансий. Система показывала вверху подходящие «Премиумы», а потом неподходящие, даже если были более подходящие вакансии типа «Стандарт», «Стандарт+» и бесплатные.
Поэтому мы решили попробовать сделать так, чтобы вакансии разделялись на две группы: сначала шли «Премиумы», «Стандарт+» и «Стандарт», и бесплатные, для которых прогнозируемая вероятность отклика больше определённого значения, а потом в таком же порядке все остальные.
Так как нам обязательно было нужно, чтобы текущие вакансии для наших клиентов-работодателей не стали работать хуже, то мы очень тщательно подошли к этим изменениям, даже эксперимент на 5% подкрепили расчётами и обоснованиями. В результате мы сделали эксперимент и увидели прирост откликов для всех типов вакансий.
Производительность системы
До того, как применять модели, нужно посчитать по резюме и по вакансии признаки, а потом — парные для их сочетания. В рекомендательной системе, нагрузка на которую была не столь высока, статические признаки для вакансий уже считались при их индексации и клались в специальный индекс, а резюме и парные считались в момент обработки запроса.
Так как мы понимали, что при включении поиска по пустому запросу нагрузка на поисковую систему вырастет примерно в 6 раз, нам потребовалось кешировать признаки для резюме. Сначала мы попробовали считать признаки для резюме и класть их в Cassandra. Но добиться нужной производительности от неё не получилось. Поэтому всё решилось таблицей в PostgreSQL.
Что пришлось добавить, чтобы добиться от системы нужной производительности:
- Пересчёт кеша при изменении признаков. Для пользователей, которые не обновляли резюме и не заходили на сайт больше двух лет, кеш не считается, а рассылка рекомендуемых вакансий идёт по текстовому соответствию. Если вам приходят так себе подходящие вакансии, дело может быть в этом: нужно просто обновить резюме.
- Мы заметили, что если каждый сервер с базовым поиском будет продолжать заниматься индексацией всех объектов для индексов, которые у него есть (вакансий, резюме, компаний) по отдельности, то заказанных серверов нам не хватит. Поэтому мы переделали систему индексации вакансий и резюме с «каждый базовый сам себе мастер» на «главный мастер — запасной мастер — базовые поиски, забирающие сегменты индексов», где индексацией занимаются только мастера, с оптимизацией и последовательным перекачиванием всей базы каждую ночь (по московскому времени), чтобы уменьшить объём индексов.
- Сделали failfast — быстрый ответ http 500 на базовых поисках, если при обработке запроса возникла ошибка. С машинным обучением время ответа в некоторых случаях сильно увеличивается, и вместо накаливания таких запросов в очереди базовый поиск выдаёт среднему метапоиску быстрый ответ http 500, после чего средний метапоиск успевает сделать повторный запрос и в большинстве случаев выдать пользователю результаты. После этого мы сделали speculative retry: если от базового поиска нет ответа более чем 2/3 таймаута, то средний метапоиск заранее обращается к другому базовому поиску.
Упрощённо, с точки зрения компонентов и потоков данных между ними, рекомендательно-поисковая система устроена так.

Потоки данных в системе:
- красными стрелками, (1) — (15) — контур ответа на поисковый запрос, запускается автоматически при каждом поисковом запросе;
- синими стрелками, (16) — (24) — контур индексации, запускается автоматически при изменении вакансий, резюме, компаний;
- зелёными стрелками, (25) — (33) — контур машинного обучения, запускается вручную при каждом изменении моделей (изменения в лингвистике, векторизации, признаках, целевых функциях, моделях, просто повторное обучение моделей по более актуальным данным);
- фиолетовыми стрелками (34) — (36) — контур расчёта метрик в A/B-тестах и бизнес-метрик (запускается автоматически, раз в сутки).
В процессе нам потребовалось добавить в кластер около 10 серверов, более мощных, чем те, которые там были до сих пор. Нужно было рационально использовать их мощности. Увеличилась вероятность того, что какой-то из серверов будет недоступен. Поэтому мы переделали балансировку на meta с простого, безусловного round-robin, так, чтобы она учитывала время отклика и количество неответов и отправляла больше запросов на те серверы, где их меньше.
Кроме использования новых серверов, это также дало возможность переживать внезапный выход из строя 20% кластера без видимых для пользователей эффектов.
Упрощённо, с точки зрения слоёв архитектуры и экземпляров компонентов в них, система устроена так:
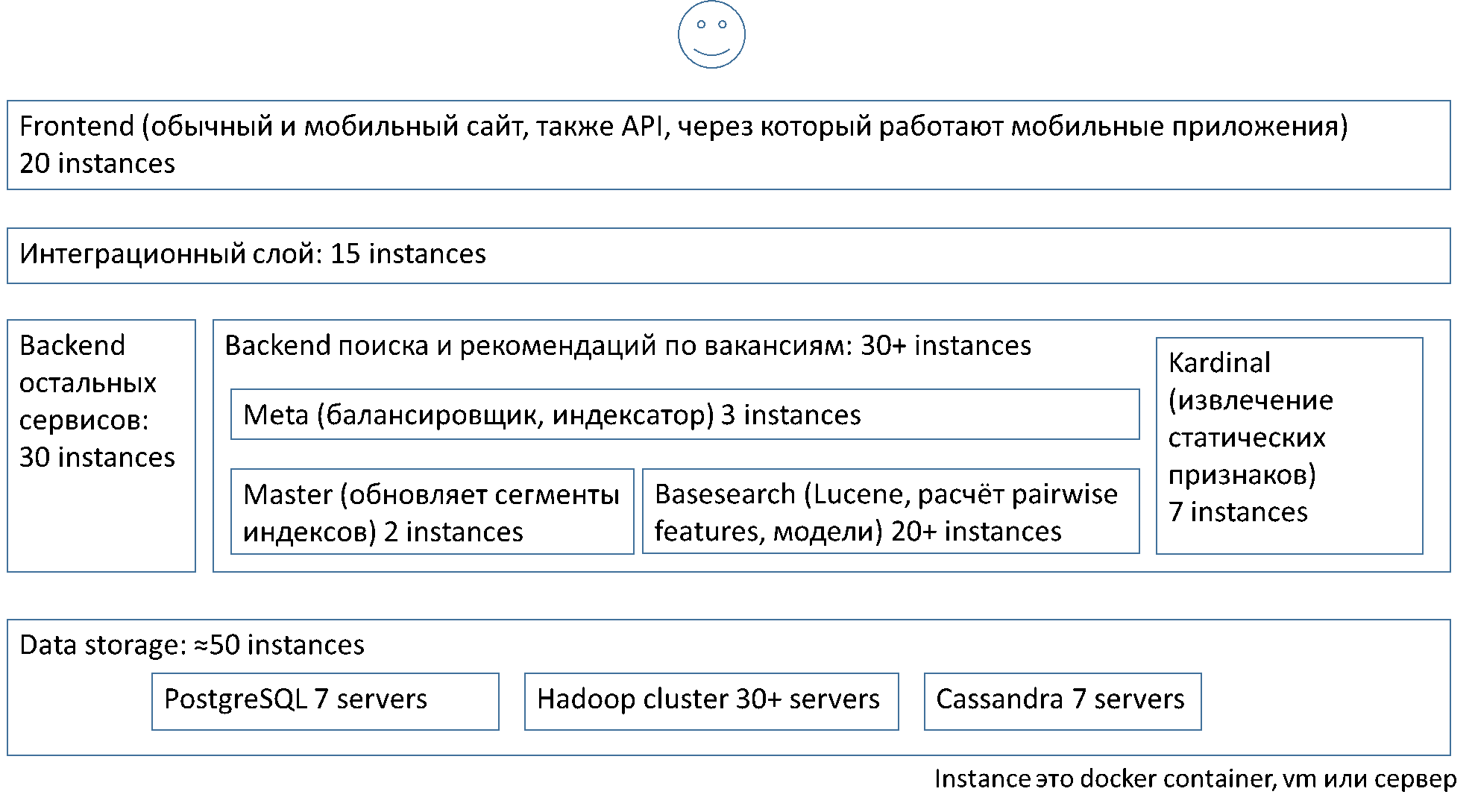
Описанная выше балансировка работает между средними метапоисками (meta) и базовыми поисками (basesearch).
Одновременно с этим мы, не переставая, дорабатывали рекомендательную систему. Включили признаки по текстовым взаимодействиям, грейдированную целевую функцию, признаки по «сырым» svd-векторам по текстам, метапризнаки по линейной регрессии над tf/idf-векторами. Было и ещё одно улучшение: мы повторили выгрузку, очистку и объединение исходных данных для машинного обучения из логов и базы и сделали так, что её можно было запустить одной командой.
Поиск по непустому запросу: машинное обучение
Почти одновременно мы начали делать поиск по непустому запросу.
Сначала мы попробовали применять к вакансиям со словами из поискового запроса, которые выдаёт Lucene, фильтры и ранжирование от рекомендательной системы. Это не дало статистически значимых улучшений. Поэтому мы сделали специальную выгрузку «запрос — резюме — вакансия — действие» и научили две модели:
- линейную: используется для того, чтобы быстро и с малой ресурсоёмкостью отделять подходящие вакансии от неподходящих и грубо ранжировать неподходящие;
- XGBoost: используется, чтобы более точно ранжировать подходящие.
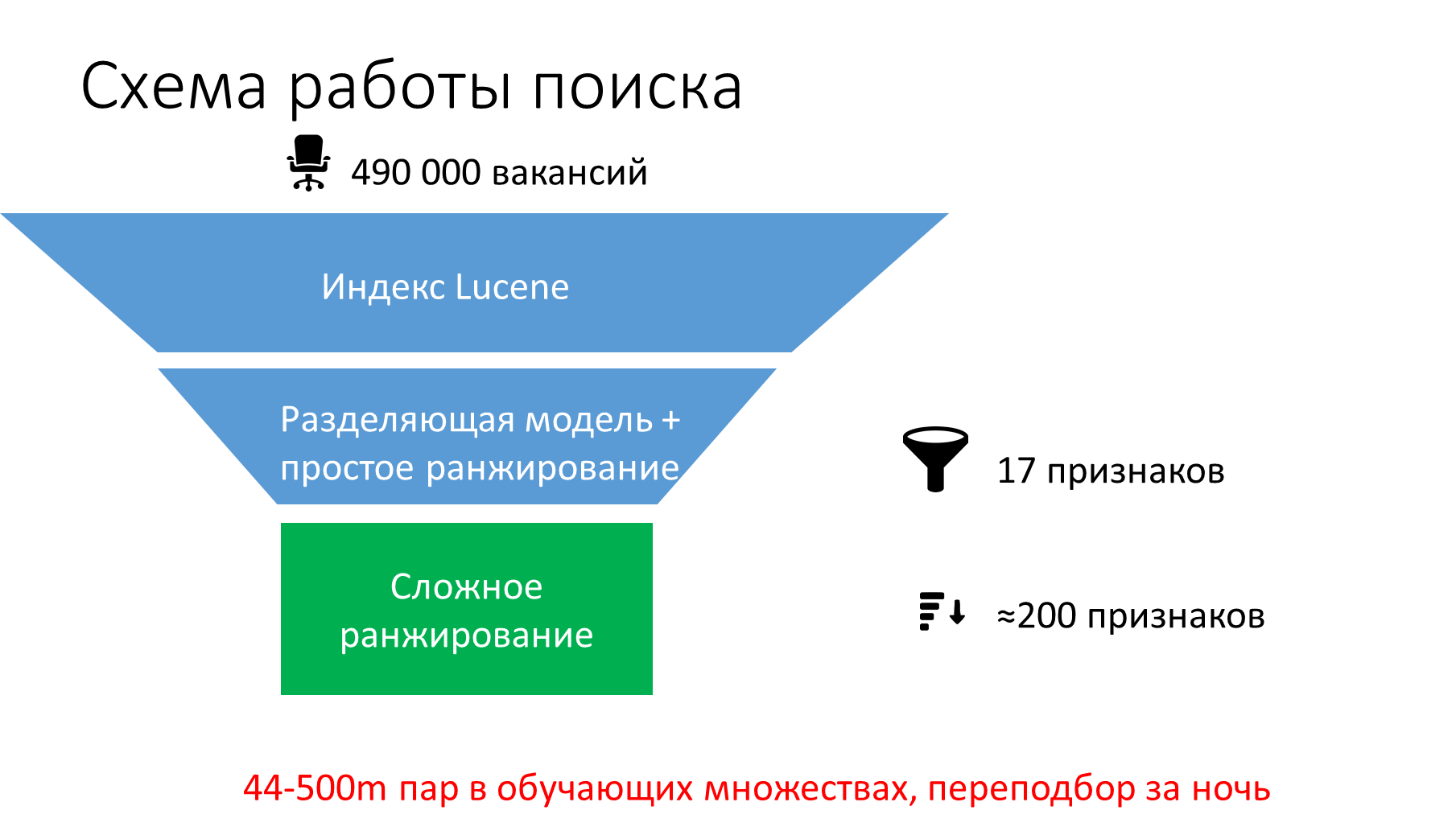
Мы повторно использовали признаки из рекомендательной системы: статические (вычисляемые до выполнения запроса), текстовые, числовые и категориальные, а также динамические, которые считаются при обработке запроса. Добавили к обычным признакам признаки, сравнивающие тексты с учётом текстовых взаимодействий.
Схематически работу машинного обучения можно изобразить так:

При расчёте рекомендованных вакансий и обработке поисковых запросов выполняется только зелёная часть, при изменении моделей (изменениях в лингвистике, векторизации, признаках, целевых функциях, моделях, просто повторном обучении моделей по более актуальным данным) — и зелёная, и синяя.
Так как признаков много и код для их расчёта при обучении моделей и при обработке запросов нужно было добавлять в разные места, это занимало долгое время и приводило к ошибкам. Поэтому мы решили сделать для них framework, feature group. Сделать этот framework удобно получилось не с первого раза, это даже немного увеличило сроки проекта.
Мы сделали измерение качества моделей, выбрав локальные метрики ndcg и map, на все объёмы, @10, @20, с помощью kfold по пользователям и time-based-валидации. И действительно, если без time-based-валидации увеличение сложности моделей (например, количества деревьев) показывало улучшение локальных метрик, то с ним стало видно, что при этом происходит переобучение (overfitting), что позволило подобрать нам разумные гиперпараметры.
Сначала мы попробовали учить линейную модель для прогнозирования вероятности отклика для отдельных сочетаний «запрос — резюме — вакансия», но оказалось, что результат в a/b-тестах лучше, когда линейная модель сравнивает вероятности для двух вакансий. В такой конфигурации некоторые эксперименты уже давали статистически значимые положительные результаты. Но всё равно меньше ожидаемого.
Мы добавили отдельные пороги для подходящих обычных вакансий, подходящих рекламных вакансий ClickMe, для расчёта ранжирования xgboost моделью, а также для количества деревьев из ансамбля, которые нужно считать в production. Мы понимали, что на проверку всех вариантов не хватит времени, поэтому взяли наиболее высокочастотные запросы, их переформулировки, и для соискателей с типичным резюме по соответствующим профессиям проверили качество выдачи с разными настройками, разметив вакансии.
Чтобы разметить, какие вакансии для них хорошо подходят, какие средне, а какие не очень, пришлось довольно глубоко изучить специфику профессий. Времени оставалось совсем мало, поэтому выкатили на большинство пользователей настройки, которые при разметке показали лучше всего, и ещё несколько вариантов на 5%, оставив без машинного обучения только контрольный сплит.
Оказалось, что размечали не зря, вариант, включенный на большинство пользователей, действительно показал себя лучше всего!
Новый интерфейс и реклама
Пользователи обычно не очень хорошо замечают изменения в ранжировании — чтобы сделать заметный запуск, нужно изменить интерфейс. В этих изменениях сильно проявляется отрицательный эффект новизны, улучшения должны быть очень сильными, чтобы его победить. Например, нужно сделать первый экран гораздо более полезным. Мы сделали новый графический дизайн, в котором место сверху по горизонтали и справа по вертикали не занимала реклама.
К рекламе можно относиться по-разному, но она даёт HeadHunter существенную часть прибыли. Чтобы меньше делиться этой прибылью с другими рекламными сетями, HeadHunter сделал свою сеть — ClickMe. Рекламу, которая в ней есть, можно разделить на рекламу вакансий и невакансий. В новом дизайне с помощью тех же технологий и моделей, которые используются в поисковой и рекомендательной системе, мы стали показывать вместо верхнего блока рекламы несколько подходящих рекламируемых вакансий.

Изменения в дизайне мы делали очень небольшими частями, чтобы запускать эксперименты и вовремя понять, если что-то, что мы делаем, вызывает отрицательный эффект.
В заключение
Мы всё ещё измеряем эффект от запуска умного поиска, но видно, что в первую неделю после запуска успешность поисковых сессий соискателей достигла исторического максимума. Это был один из самых быстрых и спокойных проектов по запуску систем такого класса — по крайней мере, в моём опыте работы. Во многом благодаря самой лучшей команде.
К сожалению, нельзя сделать поисковую систему раз и навсегда так, чтобы она отлично искала то, что постоянно меняется, а сама была совершенно неизменной. Поэтому мы продолжаем улучшать поиск на HeadHunter, чтобы пользователям становилось лучше. Кроме того, в HeadHunter есть ещё очень много областей, в которых будет полезно применить ML, поисковые технологии, а также метрики и a/b-тесты.
Если умеете в поисковые технологии, машинное обучение и работать руками — присоединяйтесь. Мы нанимаем, смотрите наши вакансии.
