Удивительная однозвенка на MS SQL
… с объектной ориентированностью, сериализацией, reflection, полиморфизмом, визуальным программированием, no-code, блэкджеком и шлюхами — и это на MS SQL 6.5 1995 году!
Знакомые с историей IT при слове «однозвенка» вспомнят dBase и Clipper. Однако, я расскажу об ERP однозвенке. Интерфейсная программа для этой ERP общалась с базой через несколько интерфейсных таблиц и несколько процедур. То есть фактически она является браузером, который за слой не считается. Да, это #ненормальное программирование, которое дало ряд уникальных свойств.
Иногда ведь хочется ручку настройки повернуть до максимума и довести идею до абсурда логического завершения. Как говорили родители одному из героев фильма «О чем говорят мужчины, продолжение» — »Так ты дойдешь до черте-чего! », а он думал »Так уже хочется взять и дойти до этого черте-чего! ».
Система называлась Ultimа-S, она же Nexus. Судьба ее была незавидна — эта ERP делалась на продажу, а продаж не было. Что, впрочем, было естественно — мы, в том числе автор этих строк, не имели ни малейшего понятия о маркетинге и продажах. Зато я имел удовольствие развлечься за счет работодателя. Итак,
Поехали
Берем установочные скрипты и устанавливаем систему на MS SQL 2019. Правда, базу пришлось загнать в compatibility mode. Запускаем exe. Он, кстати, крошечный (мне пришлось найти ntwdblib.dll):

и в памяти занимает примерно столько же, сколько Notepad:
 fg
fgЗапускаем nexus.exe, и открываем иерархию классов:

При использовании возникает очень интересное чувство, которое я не испытывал со времен MS DOS. Многие операции отрабатывают мгновенно. Нет, реально мгновенно. В современных программах, даже WinForms (я уж не говорю про Web), код настолько тяжел, столько динамически отводит памяти и столько раз вызывает GC, что глаз замечает видимые задержки. Мы к ним привыкли и не замечаем. Но когда программа реально рисует окно после нажатия на клавишу за время одного фрейма экрана, то это удивляет. А когда-то, во времена MS DOS, это было нормально.
Как это работает?
Вся коммуникация с сервером происходит через несколько процедур и три (с небольшим) таблицы. Хочется раскрыть папку — вызываем процедуру, передавая id папки, а в результирующую таблицу сваливается список документов, которые там находятся. Причем клиента не интересует, как этот список получился.
Делаем right click и хотим получить список свойств?
Тоже через таблицу. Пользователь видит user friendly имена свойств, а еще у них есть системные id, среди которых — как правило 'view' (read only просмотр по умолчанию) и 'edit' (основное редактирование).
Наконец, мы выбрали свойство и хотим посмотреть документ. Результат выдается через таблицу Detailed где есть id полей, значения (есть колонки для разных типов) и колонку форматирования. Это поле в первой букве содержит тип значения int, float, money, string, document (который на самом деле тоже int), а дальше название для человека и некие теги указывающие поведение, например: fширина^min=0^max=10.0
Вас конечно заинтересовало, если таблицы для коммуникации общие, то как могут одновременно работать много клиентов? Все очень просто — у всех этих таблиц есть поле spid (=@@spid). А все клиенты открывают ровно одну коннекцию и используют только ее (да, такой дизайн был нормой). Никаких connection pools. Представляете как легко сделать пессимистичные блокировки — по spid вы точно знаете что клиент не отсох и даже с какого hostnamе он работает!
Обычно клиент располагает поля сверху вниз, но для важных документов могут быть задизайнены красивые формы. И да, теперь языком дизайна был бы наверняка HTML, а языком сценариев (min^ max^ и полее сложные пересчетом totals) был бы JS.
Объектная ориентированность
Все документы в системе произведены от общего класса Doc. При создании производных классов создаются документы типа Класс, осуществляя своеобразный Reflection. Часть иерархии классов вы могли видеть на первом скриншоте. Классы могут быть и абстрактными.
При выполнении операции (раскрытия папки, получения свойств и отображения) вызываются процедуры с именами вида Class_operation_ID_, причем вначале идет волна 'pre' свойств, начиная от Doc к листьевому классу, а потом 'post', в обратном направлении, от листа к корню. Как правило, все свойства pre, а post полезен для удаления данных (удаления лучше делать обратном порядке, от detail таблиц к master).
Для pre свойство очередного класса 'видит' что натворили классы под ним, поэтому может не просто добавить поле или свойство, но и 'надругаться' над тем, что сделано до него — переименовать свойство или вообще убрать его, сделать поля read-only, дать им умолчания или вообще скрыть поля с помощью специального флага (но не удалять — иначе будут проблемы при записи)
Ниже вы видите пример процедур на SQL, к которому был прикручен самописный макроязык. Обратите внимание как производный класс изменяет friendly name свойства пользователя, а также иногда добавляет новое свойство.

Работа через Detailed давала еще одну интересную возможность: сериализация. Ведь можно просто вызывать свойство view (например), получить ответ, и запомнить его. Получалась мертвая копия, ксерокс, но выглядела она как настоящий документ — только была read-only.
Аналогично, Аудит (история изменений) работала на уровне корневого класса Doc, сравнивая Detailed до и после редактирования. Все производные классы были освобождены от необходимости следить за аудитом редактирования!
No-code
Система позволяла мастерить новые документы прямо через интерфейс. Сейчас покажу пример. Создадим класс, производный от пользователя:

В диалоге создания класса заполним необходимые поля. Как видите, я лишь прохожусь по самым верхам — в системе много что было еще.

Теперь через right click на образовавшемся классе создадим расширение, то есть новое поле — число пальцев от 5 до 10.

Теперь мы создаем сотрудника, указав число пальцев 5, и записываем его.

Посмотрим на результат. Новое поле добавилось внизу:
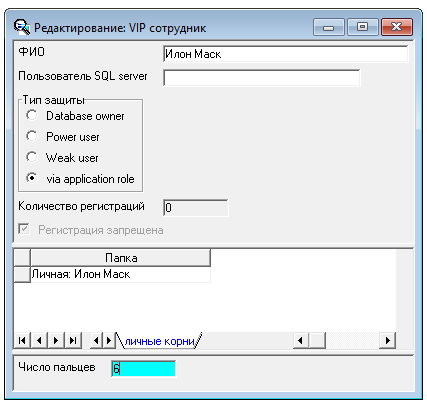
Сравним обычного пользователя и VIP пользователя. Благодаря полиморфизму (в одной папке могут быть документы любого типа) мы можем положить в папку и обычного пользователя и VIP:

С помощью No-code можно было создать сложные документы, с таблицами в духе товар-количество-цена и полем общая сумма, которая пересчитывалась автоматически — и это все без единой строчки кода. Данные ('расширения'), правда, хранились в универсальной таблице, что плохо с точки зрения производительности. Поэтому такие вещи предназначались для маленьких дополнений, а основной код все-таки писался на TSQL
Вершиной no-code был user assistant — метод переопределения поведения любых полей.
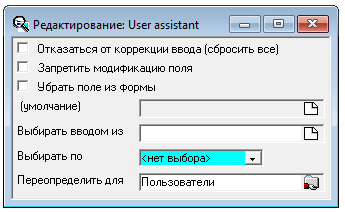
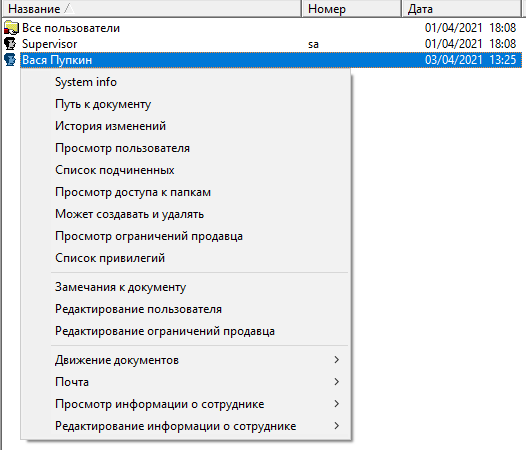
Администратор мог для любого документа, для любого поля, для определенной группы пользователей добавить умолчание, сделать поле read-only (что вместе с умолчанием заставляет использовать только определенное значение), или спрятать поле вовсе. Для полей выбора документов можно было изменить Root (папку начиная с которой выбираются документы для ввода) — например, пусть Вася Пупкин при создании платежки сможет указывать только этих трех клиентов (накидаем ссылки на этих клиентов в отдельную папочку)
Фильтрация
В системе были как обычный папки, похожие на папки для файлов, куда можно было перетаскивать документы мышкой, так и пользовательские фильтры:

Через систему событий опрашивались все классы -, а по каким полям ты умеешь фильтроваться?

Далее из этих кирпичиков пользователь мог собрать любой фильтр. Конечно, в такую папку документы перетаскивать было запрещено.
Заключение
С тех пор я не видел потенциально более гибких систем. А монстры типа SAP R/3 живут и процветают…
