Участвуем в соревновании по Data Science. Первый опыт01.12.2020 10:48
Привет, Хабр!
Давно я не писал никаких статей и, вот думаю, пришло время написать о там, как мне пригодились знания по data science, полученные по ходу обучения небезывестной специализации от Яндекса и МФТИ «Машинное обучение и анализ данных». Правда, справедливости ради надо отметить, что знания до конца не получены — спецуха не завершена :) Однако, решать простенькие реальные бизнесовые задачи уже можно. Или нужно? На этот вопрос будет ответ, буквально через пару абзацев.
Итак, сегодня в этой статье я расскажу уважаемому читателю о своем первом опыте участия в открытом соревновании. Хотелось бы сразу отметить, что моей целью соревнования было не получение каких-либо призовых мест. Единственное желание было попробовать свои силы в реальном мире:) Да, в добавок так вышло, что тематика соревнования практически никак не пересекалась с материалом из пройденных курсов. Это добавило некоторые сложности, но с этим соревнование стало еще интереснее и ценнее опыт вынесенный оттуда.
По сложившейся традиции, обозначу кому может быть интересна статья. Во-первых, если Вы уже прошли первые два курса указанной выше специализации, и хотите попробовать свои силы на практических задачах, но стесняетесь и переживаете, что может не получиться и Вас засмеют и т.д. После прочтения статьи, такие опасения, надеюсь, развеятся. Во-вторых, возможно, Вы решаете схожую задачу и совсем не знаете с чего зайти. А здесь готовенький простенький, как говорят настоящие датасайнтисты, бэйзлайн :) Здесь следовало бы уже изложить план исследования, но мы немного отвлечемся и попробуем ответить на вопрос из первого абзаца — нужно ли новичку в датасайнсе пробовать свои силы в подобных соревнованиях. Мнения на этот счет расходятся. Лично мое мнение — нужно! Объясню почему. Причин много, все перечислять не буду, укажу наиболее важные. Во-первых, подобные соревнования помогают закрепить теоретические знания на практике. Во-вторых, на моей практике, почти всегда, опыт, полученный в условиях приближенных к боевым, очень сильно мотивирует на дальнейшие подвиги. В-третьих, и это самое главное — во время соревнований у Вас появляется возможность пообщаться с другими участниками в специальных чатах, можно даже не общаться, можно просто почитать, о чем пишут люди и это а) частенько наводит на интересные мысли о том, какие еще изменения провести в исследовании и б) придает уверенность в подтверждении своих собственных идей, особенно, если они высказываются в чате. К этим плюсам нужно подходить с определенной предусмотрительностью, чтобы не возникло ощущения всезнания…
Теперь немного о том, как я решился на участие. О соревновании я узнал буквально за несколько дней до его начала. Первая мысль «ну если бы я знал о соревновании месяц назад, то подготовился бы, по изучал бы какие-нибудь дополнительные материалы, которые могли бы пригодиться для проведения исследования, а так, без подготовки могу не уложиться в сроки…», вторая мысль «собственно, что может не получиться, если целью является не приз, а участие, тем более, что участники в 95% случаях говорят на русском языке, плюс есть специальные чаты для обсуждения, будут какие-то вебинары от организаторов. В конце концов, можно будет вживую увидеть настоящих датасайнтистов всех мастей и размеров…». Как вы догадались, вторая мысль победила, и не зря — буквально несколько дней плотной работы и я получил ценнейший опыт пусть и простенькой, но вполне себе бизнесовой задачи. Поэтому, если Вы на пути покорения вершин науки о данных и видите намечающееся соревнование, да на родном языке, с поддержкой в чатах и, у Вас есть свободное время — не задумывайтесь надолго — пробуйте и да прибудет с Вами сила! На мажорной ноте мы переходим к задаче и плану исследования.
Сопоставление названий
Не будем мучить себя и придумывать описание задачи, а приведем оригинальный текст с вэб страницы организатора соревнования.
Задача
При поиске новых клиентов СИБУРу приходится обрабатывать информацию о миллионах новых компаний из различных источников. Названия компаний при этом могут иметь разное написание, содержать сокращения или ошибки, быть аффилированными с компаниями, уже известными СИБУРу.
Для более эффективной обработки информации о потенциальных клиентах, СИБУРу необходимо знать, связаны ли два названия (т.е. принадлежат одной компании или аффилированным компаниям).
В этом случае СИБУР сможет использовать уже известную информацию о самой компании или об аффилированных компаниях, не дублировать обращения в компанию или не тратить время на нерелевантные компании или дочерние компании конкурентов.
Тренировочная выборка содержит пары названий из разных источников (в том числе, пользовательских) и разметку.
Разметка получена частично вручную, частично — алгоритмически. Кроме того, разметка может содержать ошибки. Вам предстоит построить бинарную модель, предсказывающую, являются ли два названия связанными. Метрика, используемая в данной задаче — F1.
В этой задаче можно и даже нужно пользоваться открытыми источниками данных для обогащения датасета или поиска дополнительной важной для определения аффилированных компаний информации.
Дополнительная информация о задаче
Раскрой меня для получения дополнительной информации
Аффилированными компаниями считаются компании, принадлежащие одному холдингу или группе компаний. Например, все компании из списка: Сибур Нефтехим, ООО Сибур, Sibur Digital, СИБУР ИТ, Sibur international GMBH являются вариациями названий аффилированных компаний, а компания «Сибирь International GMBH» не является. Названия компаний могут писаться на разных языках: тренировочная и тестовая выборки содержат названия компаний на русском, английском и китайском языках. В названиях могут присутствовать сокращения, опечатки и дополнительная информация о компании, например, названия стран и провинций. Публичная (50%) и приватная (50%) части тестового множества не пересекаются.
Правила использования внешних источников
Безвозмездность Источник должен быть бесплатен для всех. Например, нельзя пользоваться данными, к которым у вас есть корпоративный доступ.
Верифицируемость У организаторов должна быть возможность воспроизвести ваш способ сбора данных за 1 день для выборки в 1 000 000 уникальных компаний. На практике количество проверяемых компаний намного больше данных в рамках соревнования (миллионы компаний). К тому же, одним и тем же способом сбора данных могут пользоваться сразу несколько участников и в случае строгих лимитов мы не сможем верифицировать решение.
Публичность Источник должен быть заявлен в чате до 24:00 6 декабря 2020 с хэштегом #внешниеданные и одобрен организаторами.
Добросовестность Способ, который вы используете при работе с источником, и происхождение данных не должны нарушать законы РФ и правила, которые установлены оператором источника. Если, например, автоматический парсинг какого-либо сайта запрещен владельцами сайта, то вы можете пользоваться им только вручную.
Источник должен допускать коммерческое использование.
Если для использования источника нужно зарегистрироваться, но в остальном противоречий правилам нет, то его можно использовать.
Один участник может заявить не более 10 источников информации.
Использование API поисковых систем, к сожалению, противоречит пункту 2.
Правила относительно строгих замен, ручной разметки и данных, собранных вручную, в т.ч. с использованием crowdsource
Все «ручные» данные должны быть собраны участниками команды без использования crowdsource платформ и аналогичных методов. Вряд ли мы сможем это проверить, но давайте играть честно:)
Замены общего характера можно использовать без ограничений, если при необходимости вы можете объяснить их происхождение.
Это касается legel entities, стран, городов и т.д. Например, исключение слова Industries из всех названий допустима.
Замена значимых элементов названия компании возможна только на основании внешних данных. Ручная замена не разрешается.
Нельзя использовать строгие правила сравнения названий, использующие значимые элементы. Например, нельзя проверять вхождение подстроки «Сибур» в каждый элемент пары и на основании этого вычислять целевую переменную.
Все данные, использованные при решении задачи, должны опираться только на обучающую выборку и данные, полученные из разрешенных внешних источников. Использовать данные, полученные при анализе тестовой выборки, нельзя.
В случае, если вы используете собственноручно собранные словари, вам нужно описать воспроизводимую логику их составления.
Использование open source
Вы можете пользоваться любыми open source инструментами, выпущенными под разрешительными лицензиями. Если инструмент явным образом включает в себя словари замены или аналогичные данные — о нем нужно сообщить в чате соревнования или в чате задачи в соответствии с правилами для внешних источников. В противном случае сообщать о таком инструменте не нужно.
Если Вы сомневаетесь в том, можно ли использовать какой-то конкретный источник — просто спросите в чате. Возможно, нам придется в будущем расширить этот список, если будет найден какой-то очевидно нечестный по отношении к другим участникам способ, который, тем не менее, соответствует этим правилам.
Данные
train.csv — тренировочное множество
test.csv — тестовое множество
sample_submission.csv — пример решения в правильном формате
Naming baseline.ipynb — код базовое решение
baseline_submission.csv — базовое решение
Обратите внимание, организаторы конкурса позаботились о подрастающем поколении и выложили базовое решение задачи, которое дает качество по f1 около 0.1. Я первый раз участвую в соревнованиях и первый раз такое вижу :)
Итак, ознакомившись с самой задачей и требованиями по ее решению, перейдем к плану решения.
План решения задачи
Настройка технических инструментов
Загрузим библиотеки Напишем вспомогательные функции
Предобработка данных
Загрузим данные Посмотрим на данные и сделаем копии Переведем все символы из текста в нижний регистр Удалим названия стран Удалим знаки и спецсимволы Удалим цифры Удалим… первый список стоп-слов. Вручную! Проведем транслитерацию русского текста в латиницу Запустим автоматическое составление списка топ 50 самых часто встречающихся слов & Drop it smart. Первый ЧИТ
Генерация и анализ фич
Посчитаем дистанцию Левенштейна Посчитаем нормированную дистанцию Левенштейна Визуализируем фичи Сопоставим слова в тексте для каждой пары и сгенерим большую кучу признаков Сопоставим слова из текста со словами из названий топ 50 холдинговых брендов нефтехимической, строительной отраслей. Получим вторую большую кучу признаков. Второй ЧИТ Готовим данные для подачи в модель
Настройка и обучение модели
Итоги соревнования
Источники информации
Теперь, когда мы ознакомились с планом проведения исследования, перейдем к его реализации.
Настройка технических инструментов
Загрузка библиотек
Собственно здесь все просто, для начала установим недостающие библиотеки
Установим библиотеку для определения списка стран и последующего их удаления из текста
pip install pycountry
Установим библиотеку для определения дистанции Левенштейна между словами из текста друг сдругом и со словами из различных списков
pip install strsimpy
Установим библиотеку, с помощью которой проведем транслитерацию русского текста в латиницу
pip install cyrtranslit
Подтянем библиотеки
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslit
Напишем вспомогательные функции
Хорошим тоном считается вместо копи паста большого куска кода указывать функцию в одну строчку. Мы так и будем делать, почти всегда.
Утверждать, что качество кода в функциях отлиное не буду. Местами его точно следует оптимизировать, но в целях быстрого исследования, достаточно будет только точности расчетов.
Итак, первая функция переводит текст в нижний регистр
Код
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()
Следующие четыре функции помогают визуализировать пространство исследуемых признаков и их способность разделять объекты по целевым меткам — 0 или 1.
Пятая функция предназначена для формирования таблицы угадываний и ошибок алгоритма, более известной как таблица сопряжения.
Иными словами, после формирования вектора прогнозов, нам потребуется сопоставить прогноз с целевыми метками. Результатом такого сопоставления должна получиться таблица сопряжения для каждой пары компаний из обучающей выборки. В таблице сопряжения для каждой пары будет определен результат соответствия прогноза к классу из обучающей выборки. Классификация соответствия принята такой: 'True positive', 'False positive', 'True negative' или 'False negative'. Эти данные очень важны для анализа работы алгоритма и принятия решений по доработке модели и признакового пространства.
Шестая функция предназначена для формирования матрицы сопряжения. Не путайте с таблицей сопряжения. Хотя одно следует из другого. Вы сами все увидите дальше
Седьмая функция предназначена для визуализации отчета о работе алгоритма, который включает в себя матрицу сопряжения, значения метрик precision, recall, f1
Код
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')
С помощью восьмой и девятой функции проведем анализ на полезность признаков для используемой модели из Light GBM с точки зрения значения коэффициента 'Information gain' для каждого исследуемого признака
Десятая функция нужна для формирования массива количества совпадающих слов для каждой пары компаний.
Эту функцию также можно использовать для формирования массива НЕ совпадающих слов.
Код
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum
Одинадцатая функция проводит транслитерацию русского текста в латиницу
Код
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
Двенадцатая функция нужна для переименования столбцов таблицы после агрегирования данных.
Дело в том, что после агрегации данных, названия столбцов, как бы распадаются на два уровня. В итоге, для приведения таблицы к принятому в исследовании формату, используем самописную функцию
def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return data
return text_transliterate
Тринадцатая и четырнадцатая функции нужны для просмотра и формирования таблицы дистанции Левенштейна и других важных показателей.
Что это вообще за таблица, какие в ней метрики и как она формируется? Давайте рассмотрим пошагово формирование таблицы:
Шаг 1. Определим какие данные нам будут нужны. ID пары, финишная обработка текста — оба столбца, список названий холдингов (топ 50 компаний нефтехимической и строительной индустрии).
Шаг 2. В столбце 1 в каждой паре от каждого слова замерим дистанцию Левенштейна до каждого слова из списка названий холдингов, а также длину каждого слова и отношение дистанции к длине.
Шаг 3. В случае, если значение отношения окажется меньше или равно 0.4, то от сравниваемого слова из списка названий топ холдингов определим дистанцию до каждого слова из второго столбца соответствующей id пары, а также длину каждого из слов и отношение дистанции к длине.
Шаг 4. В случае, если в очередной раз отношение оказывается меньше или равно 0.4, то все собранные метрики фиксируются.
Шаг 5. По завершению алгоритма будет сформирована таблица, в которой первый столбец ID пары, а последующие столбцы — метрики. Данные в таблице необходимо агрегировать по id пары (так как могут быть случаи сильного соответствия слов из одной id пары двум названиям холдингов). При агрегировании данных выбираем минимальные значения.
Шаг 6. Склеиваем полученную таблицу с таблицей исследования.
Важная особенность: расчет занимает продолжительное время из-за написанного на скорую руку кода
Код
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return data
Предобработка данных
Из моего небольшого опыта именно предобработка данных в широком смысле этого выражения занимает большее время. Пойдем по порядку.
Загрузим данные
Здесь все очень просто. Загрузим данные и заменим название столбца с целевой меткой «is_duplicate» на «target». Это делается для удобства использования функций — некоторые из них были написаны в рамках более ранних исследований и они используют название столбца с целевой меткой как «target».
Код
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})
Посмотрим на данные
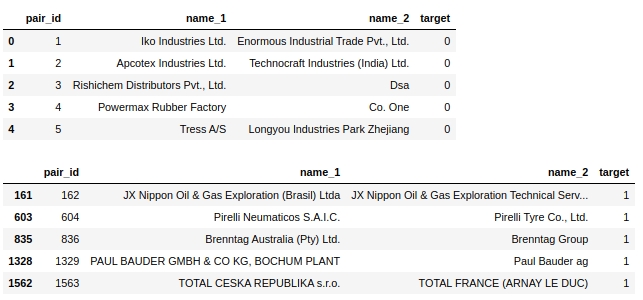
Данные загрузили. Давайте посмотрим сколько всего объектов и насколько они сбалансированны.
Код
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')
Таблица №1 «Баланс меток»
Объектов не мало — почти 500 тысяч и они вообще никак не сбалансированы. То есть из почти 500 тысяч объектов, всего менее 4 тысяч — имеют целевую метку 1 (менее 1%)
Давайте посмотрим на саму таблицу. Посмотрим на первые пять объектов с разметкой 0 и первые пять объектов с разметкой 1.
Таблица №2 «Первые 5 объектов класса 0», таблица №3 «Первые 5 объектов класса 1»
Сразу напрашиваются некоторые простые шаги: привести текст к одному регистру, убрать всякие стоп-слова, типа 'ltd', удалить страны и заодно названия географических объектов.
Собственно, примерно так в этой задаче может проходить решение — делаешь какую-нибудь предобработку, убеждаешься в том, что она работает как надо, запускаешь модель, смотришь качество и анализируешь выборочно объекты, на которых модель ошибается. Именно так я и проводил исследование. Но в самой статье дано итоговое решение и качество работы алгоритма после каждой предобработки не разбирается, в конце статьи мы проведем итоговый разбор. Иначе статья была бы неописуемых размеров :)
Сделаем копии
Если честно, то не знаю зачем я это делаю, но почему-то всегда это делаю. Сделаю и в этот раз
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)
Удалим названия стран
Надо отметить, что организаторы конкурса — большие молодцы! Вместе с заданием они дали ноутбук с очень простым baseline, в котором был предоставлен, в том числе и нижеприведенный код.
Код
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)
Удалим знаки и спецсимволы
Код
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)
Удалим цифры
Удаление цифр из текста прямо в лоб, в первой попытке сильно испортило качество модели. Код я здесь приведу, но по факту он не использовался.
Также обратите внимание, что до этого момента мы проводили преобразование прямо в столбцах, которые нам были даны. Давайте теперь будем создавать новые столбцы для каждой предобработки. Столбцов получится больше, зато если где-то на каком-то этапе предобработки произойдет сбой — ничего страшного, делать все с самого начала не нужно, ведь у нас будут столбы с каждого этапа предобработки.
Код, который испортил качество. Нужно деликатнее быть
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
Удалим… первый список стоп-слов. Вручную!
Теперь предлагается определить и удалить стоп-слова из списка слов в названиях компаний.
Список мы составили на основании ручного просмотра обучающей выборки. По логике, такой список нужно составлять автоматически, используя следующие подходы:
во-первых, использовать топ 10 (20,50,100) часто встречающихся слов.
во-вторых, использовать стандартные библиотеки стоп-слов на различных языках. Например, обозначения организационно-правовых форм организаций на различных языках (ООО, ПАО, ЗАО, ltd, gmbh, inc и др.)
в-третьих, имеет смысл составить список географических названий на различных языках
К первому варианту автоматического составления списка топ часто встречающихся слов мы еще вернемся, а пока смотрим на ручную предобработку.
Код
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', 'ооо', 'ООО', 'зао', 'ЗАО', 'оао', 'ОАО', 'пао', 'ПАО', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'рус','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
Давайте выборочно проверим, что наши стоп слова были действительно удалены из текста
Таблица №4 «Выборочная проверка работы кода по удалению стоп-слов»
Вроде все работает. Удалены все стоп-слова, которые отделены пробелом. То, что мы и хотели. Двигаемся дальше.
Проведем транслитерацию русского текста в латиницу
Я использую для этого свою самописную функцию и библиотеку cyrtranslit. Вроде работает. Проверял вручную.
Код
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])
Давайте посмотрим на пару с id 353150. В ней второй столбец («name_2») имеет слово «мишлен», после предобработки слово уже пишется так «mishlen» (см. столбец «name_2_transliterated»). Не совсем правильно, но явно лучше.
Таблица №5 «Выборочная проверка кода по транслитерации»
Запустим автоматическое составление списка топ 50 самых часто встречающихся слов & Drop it smart. Первый ЧИТ
Немного мудреный заголовок. Давайте по порядку разберем, что мы тут будем делать.
Во-первых, мы объединим текст из первого и второго столбца в один массив и посчитаем для каждого уникального слова, количество раз, которое оно встречалось.
Во-вторых, выберем топ 50 таких слов. И казалось бы можно их удалить, но нет. В этих словах могут быть названия холдингов ('total', 'knauf', 'shell',…), а это очень важная информация и ее нельзя потерять, так как далее мы будем ее использовать. Поэтому мы пойдем на читерский (запрещенный) прием. Для начала, на основании внимательного, выборочного изучения обучающей выборки, составим список названий часто встречающихся холдингов. Список будет не полный, иначе это было бы совсем не честно :) Хотя, так как мы не гонимся за призовым местом, то почему бы и нет. Затем мы сравним массив топ 50 часто встречающихся слов со списком названий холдингов и выкинем из списка слова, которые совпадают с названиями холдингов.
Теперь второй список стоп-слов готов. Можно удалять слова из текста.
Но перед тем, хотелось бы вставить небольшую ремарочку касательно читерского списка названий холдингов. То, что мы составили на основании наблюдений список из названий холдингов сильно упростило нам жизнь. Но на самом деле, мы могли составить такой список другим способом. Например, можно взять рейтинги крупнейших компаний в нефтехимической, строительной, автомобильной и других отраслях, объединить их и взять оттуда названия холдингов. Но в целях нашег