У нас DevOps. Давайте уволим всех тестировщиков
Можно ли автоматизировать всё, что угодно? Потом всех тестировщиков уволим, конечно. Зачем они теперь нужны, «ручного» тестирования не осталось. Правильно ведь?
Это рассказ о будущем тестирования с точки зрения DevOps. Здесь будут конкретные цифры и чисто практические выводы, как так получается, что у хороших специалистов всегда есть работа. (Или нет работы! Глядите на фотографию Шекспира и бойтесь, сейчас будет решаться ваша судьба).

В основе материала — расшифровка доклада Баруха jbaruch Садогурского, Developer Advocate в компании JFrog. Текстовая версия и видео доклада — под катом.
Всем привет! Видите цитату из Шекспира на картинке чуть выше? Это «Генрих VI», предложение убить всех адвокатов. Сами понимаете, с тех пор у нас более вегетарианские способы избавляться от неправильных профессий. Убивать мы никого не будем, просто возьмем и всех уволим.
Точней, есть такая возможность. Станем ли мы кого-то увольнять — давайте поговорим.
Это Вася. Как-то утром он приходит на работу и проходит мимо самой главной переговорки. А там его шеф приветствует нового консультанта. Консультант по эффективности приходит в компанию и говорит: «Мы будем делать DevOps как в netflix*. Мы специально летали в Кремниевую долину на конференцию, и там нам рассказали, как делают в netflix».
* дисклеймер: в этой статье часто используется фирма Netflix как недостижимый идеал DevOps. Это использование носит нарицательный характер.
Обсуждение того, действительно ли в фирме Netflix идеальный DevOps, выходит за рамки этой статьи (скорее всего, кстати, нет).

Они ставят Spinnaker, потом запускают Chaos Monkey, и все автоматизируют. И мы так будем делать и будем очень эффективными.
Шеф спрашивает, а как же тестировщики. «А у нас как в нетфликсе — freedom и responsibility. Разработчики будут сами писать тесты».
И тут Васе становится нехорошо, потому что он смотрит на свою визитку, а там…

Вася начинает переживать: в прошлый раз, когда приходил консультант по эффективности, уволили его знакомую, Наташу, работавшую сисадмином. Потому что всюду DevOps. И тут он понимает, что скоро все будет очень плохо.
Но, конечно, тут Вася просыпается.

Меня зовут Барух Садогурский, я Developer Advocate в компании JFrog. Редактор этой статьи специально попросил написать пару абзацев, чтобы никто не сомневался в моих полномочиях рассказывать, как мы будем увольнять тестировщиков.
Компания JFrog — это стартап в Кремниевой долине, последняя наша оценка была более миллиарда долларов. Мы официально unicorn, и мы занимаемся автоматизацией DevOps. Наши продукты — Artifactory, Xray, Mission Control и так далее — инструменты для той самой автоматизации, превращающий омский мясокомбинат в netflix.
Я сам не тестировщик, поэтому, возможно, буду рассказывать какую-то чушь. В программке конференции, на которой изначально читался этот доклад, есть специальное обозначение — картинка с бутылкой с зажигательной смесью. Значит, докладчик собирается нести какую-то ересь, и у слушателей будет подгорать. Это про меня. В твиттере я @jbaruch. Как вы уже поняли, я очень веселый парень, меня надо срочно зафолловить.
У меня для вас есть новости: 80% разработчиков пишут тесты. Разработчикам устраивают всякие опросы. Вот нам компания JetBrains устраивает очень хороший State of Developer Ecosystem Report. Там спрашивают, кто пишет юнит-тесты.
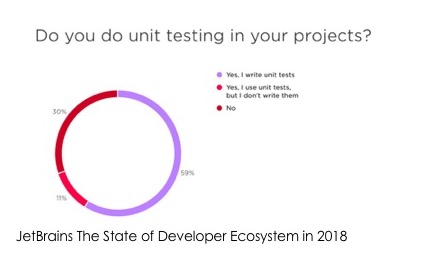
- 59% пишут сами,
- 11% видят в своем коде юнит-тесты и не знают, откуда они приходят.
Итого 70% разработчиков пользуются юнит-тестами. Это круто.
Есть более углубленное исследование компании Hubstaff о тестировании с помощью разработчиков, оно чуть-чуть постарее — 2014 года. Согласно нему:
- 85% разработчиков пишут юнит-тесты,
- 15% нет;
- 40% работают по методологии test-driven development;
- хорошее покрытие — между 34 и 66 у 31% разработчиков.
Подавляющее большинство разработчиков утверждают, что они еще и ручками что-то тестируют. Врут, конечно, но статистика такова.
Начиная с 2011 года наша самая любимая цитата: «Every company is a software company». Включая, естественно, омский мясокомбинат, на котором Вася работает. Везде есть софт и все на этом софте пытаются зарабатывать. Что хотят компании? Грести бабло лопатой. Откуда берутся деньги? От довольных клиентов. А что хотят клиенты? Новых фич. А когда они хотят новых фич? Сейчас!
CEO из комикса Dilbert — начальник начальника Васи. Он тоже слушал всякие интересные доклады. Он считает, что если клиенты хотят новых фич — значит, нужно новые фичи чаще релизить. Логично. Для этого нужно уменьшать трение в командах.
Надо ли чаще релизить? Например, в 2017 году Java перешла на более частые релизы, потому что все хотят фичи и, казалось бы, надо релизить побыстрее. Каждые полгода выходит новая Java. Но никто ее не использует.
У нас недавно был Joker, мы на нем устраивали Java Puzzlers. В начале мы всегда спрашиваем, кто на какой Java, чтобы понять, какие паззлеры спрашивать.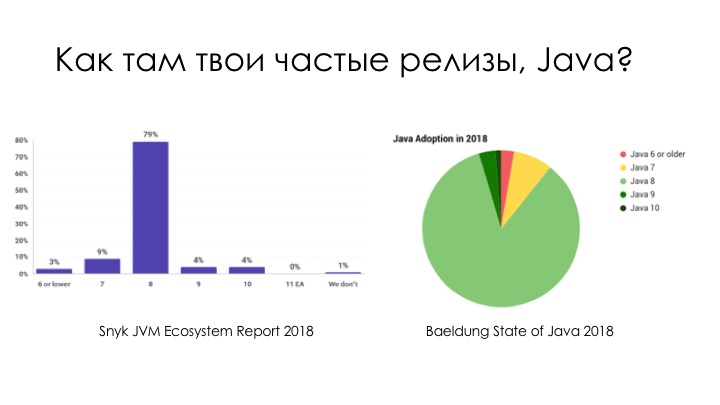
Картинка не изменилась: 80%, а то и больше, всё ещё сидят на Java 8, которая вышла сто лет назад. Ни девятую, ни десятую, ни одиннадцатую не берет никто.

Чтобы понять, почему не используют, надо понять, как мы принимаем решение о том, брать какие-то обновления или нет. Давайте представим, как мы ставим любые апдейты — операционной системы, приложений, браузера — чего хотите.
Как мы ставим апдейты
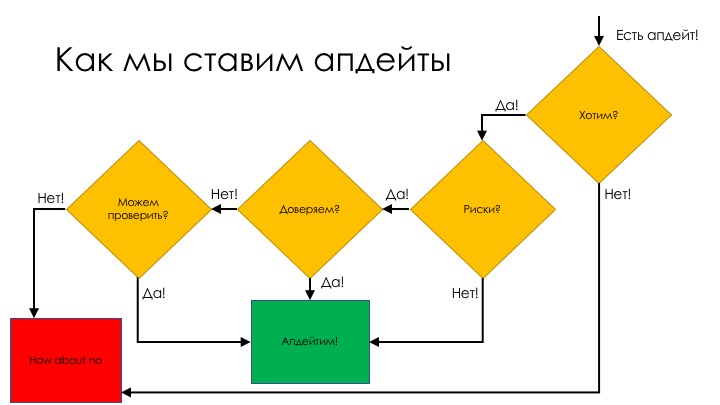
Приходит уведомление, что у нас есть апдейт, давайте поставим новую операционную систему. Мы хотим этого? Там есть что-то полезное или у нас кассовый аппарат, который работает на Windows 98 Embedded, и больше нам ничего не надо?
Если мы хотим это обновление, следующий вопрос — насколько оно опасно. Одно дело, когда фейсбук проапдейтится, и у нас поедет скроллинг, и мы не сможем лайки ставить. Совсем другое дело, когда в больнице отключится система жизнеобеспечения. Если нам наплевать на риски, давайте апдейтить. Если риски есть, то вопрос в доверии тому, кто выкатывает обновление.
С компанией Apple раньше не было проблем: есть новая операционная система — давай возьмем. Это было раньше, а сейчас мы уже боимся обновляться, нет былого доверия. Если мы доверяем — нет проблем, обновляемся. Если же не доверяем — нужно тестировать.
Мы делаем то, что называется приемочные тесты (acceptance tests). Вот нам сообщают: вышла новая Java, и к примеру, мы — компания Baidu. Хайлоад, 100500 серверов, клауд, JVM везде. Мы берем какую-то часть серверов, начинаем менять Java. Куче инженеров приходится что-то сделать и всё это проверить. Раз в три года нормально, но раз полгода… Вы что, охренели? Мы только проверять её полгода будем. Конечно, мы не будем брать эту вашу новую Java.
Поэтому, если мы можем проверить быстро, стоит обновиться. А вот если придётся проверять долго, то можно и пропустить пару версий. Ничего не случится, если переползём с восьмой версии сразу на двенадцатую.
Проблема именно в доверии. Если мы не доверяем, то обновляться будет тяжело. Если вопрос доверия решен, то с апдейтами проблем нет. Или у нас есть фича, или нам наплевать.
Возьмите Chrome. Он, начиная с какой-то версии, апдейтится вообще никого не спрашивая. Риски там небольшие, но все-таки есть. Но с другой стороны, мы доверяем тем, кто Chrome пишет. Чаще всего, когда выходит новый релиз Chrome, ничего там не ломается. По сути, у нас нет проблем с доверием, и мы идем по этому пути.
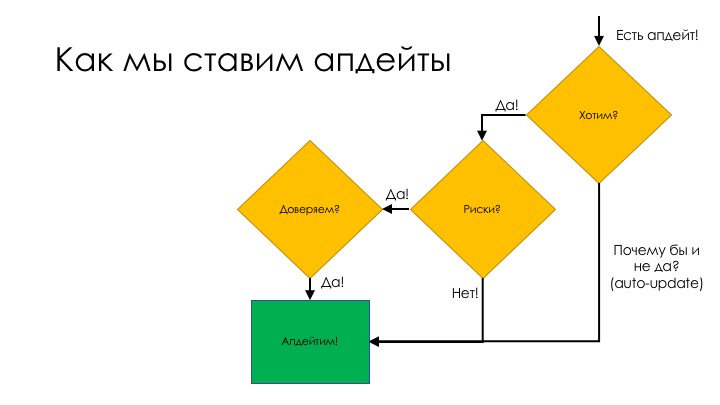
У нас есть апдейт, риски не важны, доверяем — апдейтим. А еще нас не будут спрашивать, хотим мы или нет, поэтому мы всегда будем апдейтить. Именно так это и делается.
Представьте, netflix выкатывает новый апдейт, и теперь мы можем пропускать не только титры и заставку, но и все скучные места. Крутой апдейт? Крутой. Мы его хотим? Хотим. Он будет работать? Скорее всего, да. В крайнем случае мы пойдем на YouTube, мультики посмотрим, если netflix сломался.
Вопрос доверия тут критичный. Как мы его решаем? Под словом «мы» имеются в виду два сооснователя JFrog, Фред Саймон (Fred Simon), Йоав Ландман (Yoav Landman) и ваш покорный слуга. Мы написали книжку, которая советует, как решать эту проблему.
Допустим, мы уговорили нашего CEO, он прочитал Liquid Software, и теперь он понимает, зачем ему апдейт. Он спрашивает у консультанта, как мы будем чаще апдейтить. Agile! DevOps! А что такое DevOps?
DevOps
Давайте я вам расскажу немного теории, что такое DevOps, поскольку мы на этом зарабатываем. Взгляните на картинку, у нас были вот эти группы, команды, отделы:
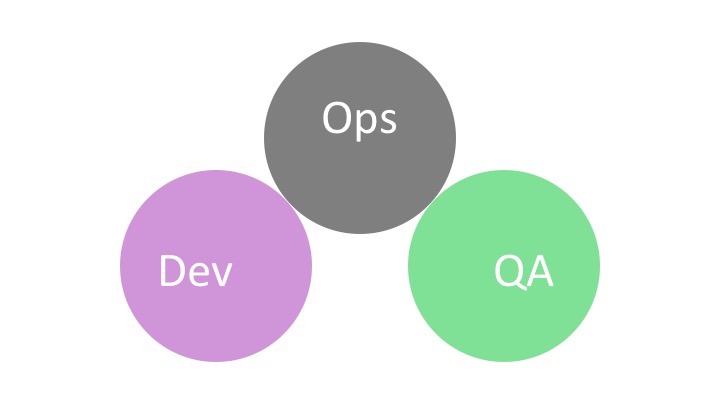
Есть разработчики, есть Ops — сисадмины, которые берут то, что разработчики написали, и выкидывают на прод. И еще посередине между разработчиками Ops есть QA, которые тестируют. То есть, разработчики сели, написали, потом отнесли тестировщикам, потестировали, отнесли сисадминам, и они на прод залили. Для этого у нас были отдельные отделы.
Русский язык прекрасен: отдел всегда отдельный, это корень слова. На английском этой прелести нет, поэтому эти разные отделы называются silos. Лучший перевод этого слова на русский привел Антон Вайс, который был лучшим докладчиком DevOops. Он называет silos «колодцами». Разные отделы — глубокие колодцы. Чтобы туда загрузить какую-то работу, нужно спуститься, а потом вытащить оттуда работу — подняться. Удобнее всего делать это группами. Как мы группируем вещи, которые из колодца достаем?
Естественно, ведрами. То есть, у нас есть такие «ведра работы». Разработчики что-то в колодце написали, мы это загрузили в ведра, достали это из колодца, отнесли ведра тестировщикам, спустили к ним в колодец.
Очень много действий совершается для передачи работы между разными колодцами. Когда мы группируем задачи, чтобы сэкономить на этой работе, мы начинаем нагружать эти ведра. Само собой, чем больше ведро, тем больше мы сэкономим на этом процессе передачи. Поэтому ведра делают большими.
В чем проблема с большими ведрами? В том, что их долго наполнять. Поэтому когда у нас есть важные фичи, которые надо срочно выпустить на продакшн, потому что стоит очередь клиентов с деньгами — мы не можем этого сделать. У нас же колодцы, давайте мы лучше побольше в ведро соберём. Поэтому важные фичи ждут всякую ерунду, пока у нас будет достаточно, чтобы этот колодец наполнить. Это плохо, как вы сами понимаете. Решается это тем, что мы всех из этих колодцев достаем и смешиваем.
Я не виноват! Я просто взял три изначальных цвета, положил их один на другой, и вот этот цвет получился. Теперь у нас все делают всё. У нас есть такие инженеры, которые и швец, и жнец, и на дуде игрец. Это Dev, QA и Ops. Он и код пописал, и потестировал, и потом еще и на продакшн все это выложил — такой вот единорог.
В чем проблема единорогов? В том, что они не существуют. А те, которые существуют, их уже давно netflix нанял. Поэтому нам остается делать смесь.
Смесь
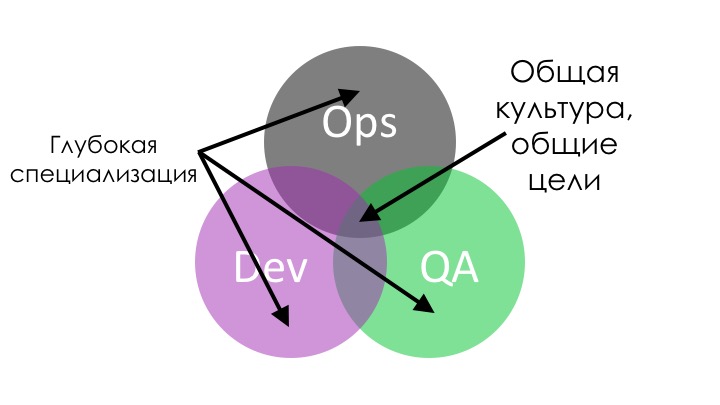
У нас есть общая культура, общие цели. Мы вышли из колодцев, мы теперь все вместе, но у нас осталась глубокая специализация. Разработчик все-таки больше разработчик, чем Ops, а тестировщик — больше тестировщик, чем разработчик. Но тем не менее, они понимают все. Они понимают, что они делают, зачем они это делают и как оно работает.
То есть у нас появляются T-shaped people, «люди в форме буквы T».
У них есть глубокая специализация, они очень хорошо знают, что делают. Они достаточно широко знают и всё остальное тоже. Например, разработчики немножко понимают, как правильно тестировать, как работают процессы выкладывания на прод и так далее.
DevOps — это:
- Культура того, что у нас теперь есть общие цели, мы понимаем, что мы делаем вместе.
- Автоматизация, чтобы релизить чаще.
Скорость и качество
Давайте поговорим про предположение о том, что существует обратная зависимость скорости и качества. Грубо говоря, чем быстрее мы будем релизить, тем хуже получится качество. И наоборот: если мы не будем спешить, то успеем все хорошенько потестировать. У нас трейд-офф! 
Для того, чтобы понять, действительно ли эта зависимость существует, обратимся к научным трудам и поговорим о докладе State of DevOps от организации DORA. Я вам очень рекомендую в этот доклад хорошенько посмотреть.
Насколько ему можно доверять? В докладе говорится о том, что за пять лет опрошено больше 30 000 человек, а в 2018 году почти 2000 человек. Это очень большая выборка и на основании такого количества, например, делают прогнозы на выборах в США. Поэтому исследованию можно доверять.
Кроме того, Николь Форсгрен, возглавляющая DORA, в отличие от нас, — ученый, поэтому там все серьезно. Давайте посмотрим, что же DORA нам расскажет про эту обратную корреляцию.
Во-первых, они поделили всех опрашиваемых на три группы: Low performers, Medium Performers и High Performers.
Кроме того, есть еще Elite. Это Netflix (на самом деле нет, смотри дисклеймер выше).
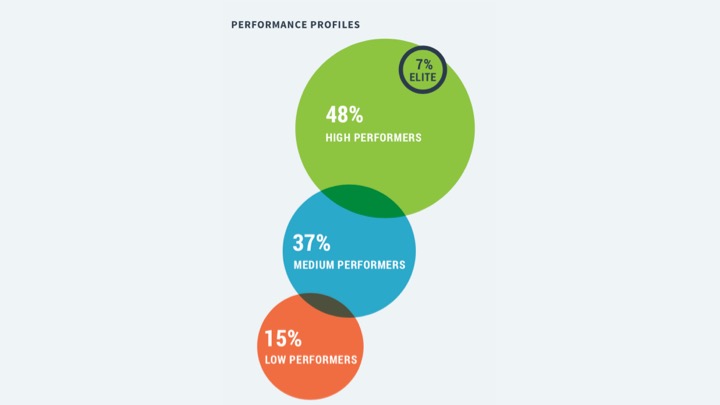
Как вы видите, пропорции меняются. Естественно, пять лет назад было намного больше Low Performers, сейчас намного больше High Performers, ведь мы уже начинаем немножко понимать, что мы делаем.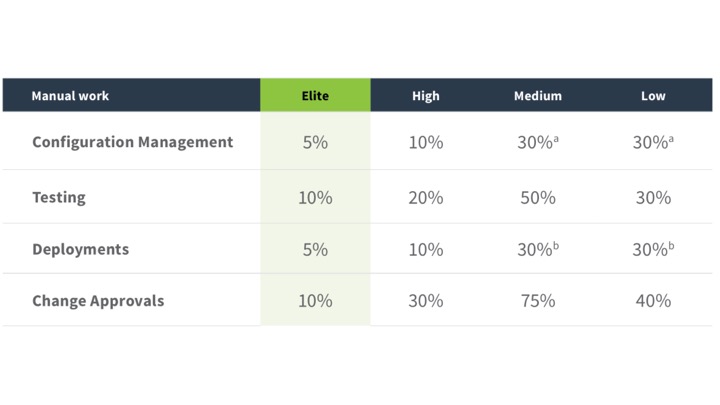
Это как-то странно. Оказывается, Medium тестируют ручками больше, чем Low. Почему? Да потому, что Low вообще ничего не тестируют.
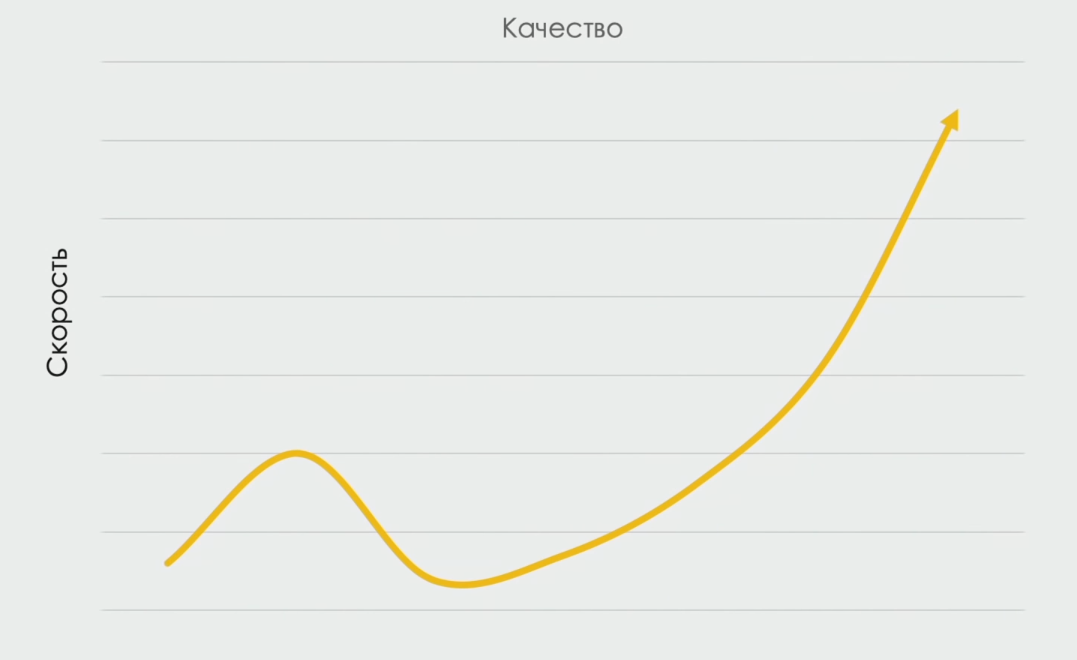
У них есть тренд, график под названием J-кривая, которая показывает ту самую корреляцию или обратную корреляцию между скоростью и качеством. И тут все очень странно. В какой-то момент мы видим подтверждение этой обратной корреляции. То есть, чем быстрее мы релизим, тем ниже качество.
Но дальше корреляция не только не обратная, она прямая. Чем быстрее мы релизим, тем лучше у нас качество. Допустим, мы Medium и тестим ручками. Все неплохо, но медленно, потому что мы верим в то, что если не будем спешить, то и протестируем всё получше. Потом приходит консультант от DevOps и говорит: «Всё, теперь автоматизируем. А тестировщики нам не нужны. Всё отлично».
Но без тестов получается какая-то ерунда. После того, как мы осознали, что все-таки что-то надо тестировать, и надо автоматизировать правильно, мы начинаем автоматизировать правильно и дальше стремимся в заоблачные выси.
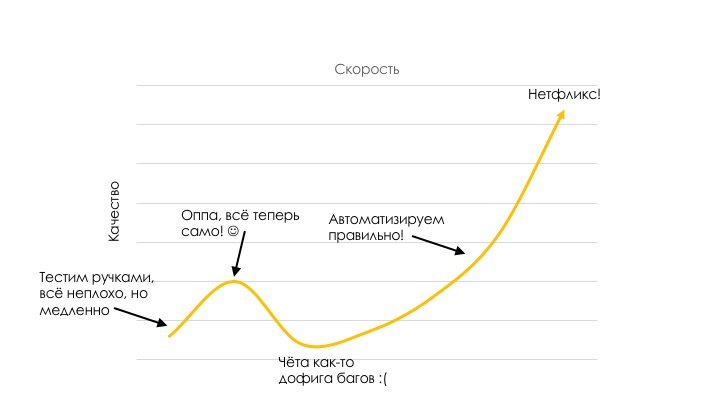
Этот провал, где появляется много багов, нужно правильно преодолеть. Как в него попасть, я думаю, вопросов нет. Вопрос, как из него вылезти.
Нам нужно ответить на вопрос, как жить без ручного тестирования. Ответ такой же, как и на вопрос, как жить без настройки серверов. Очевидно, можно. Что же меняется?
Раньше у нас был сисадмин, который выкатывал продукт на прод. Он сидел и ждал, пока разработчики закончат писать. После этого он брал этот продукт и шел CD-ROM вставлять и провода втыкать. Что в это время происходит со всеми остальными? Все остальные ждут. Это бутылочное горлышко, затык.
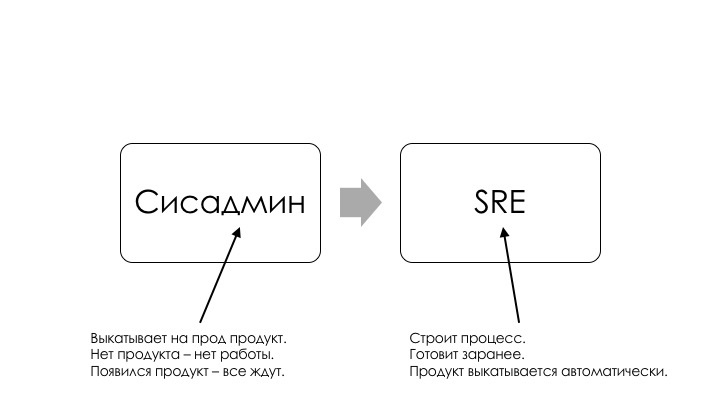
Мы это решаем правильной автоматизацией. Мы автоматизируем процесс, у нас заранее приготовлен пайплайн, и теперь продукт выкатывается автоматически, как только его закончили писать. Значит ли, что теперь эти люди не нужны? Нет. Это значит, что они нужны, но занимаются чем-то другим.
То же самое с тестированием. У нас есть тестировщики, которые тестируют продукт. Они ждут, пока им напишут продукт. Написали — пора тестировать. Что делают все остальные, пока они тестируют? Ничего не делают, сидят ждут. Как мы это решаем? 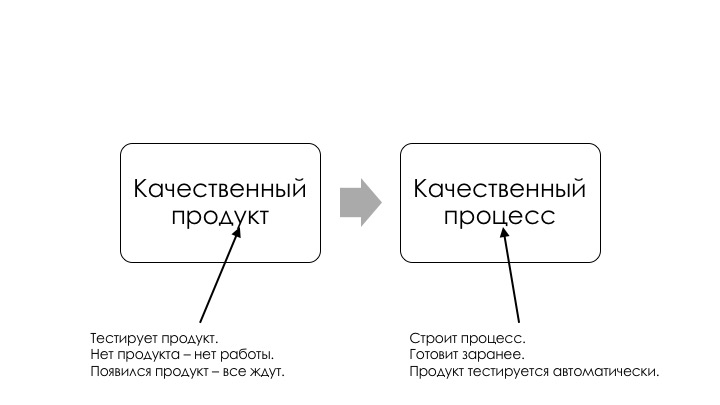
Опять же правильной автоматизацией. Мы строим процесс. Он будет гарантировать качество продукта. Мы можем подготовить этот процесс заранее, и дальше продукт тестируется автоматически.
- Для этого нужны, например, кроссфункциональные команды. Вот мы из колодцев поднялись и сели вместе. Теперь у нас лев возлежит с овцой, и тестировщик работает вместе с программистом.
- Мы делаем Continuous Testing. Это как автоматизированное тестирование, но умнее.
- В процессе разработки делается «брейнуальное тестирование». Это более правильный термин, чем «мануальное тестирование», потому что мануальное тестирование — оно про мозг, а не про руки. Спасибо за этот термин моему близнецу в Фейсбуке Алексею Виноградову. Брейнуальное тестирование происходит в процессе разработки. Как только появляется что-то, уже можно проверить его flow, уже можно понять, как оно работает, уже можно начать намечать какие-то corner cases, которые мы потом заавтоматизируем.
- Мы теперь следим за разработчиком. Если он сначала не написал тест, мы ему можем дать подзатыльник. Это Test Driven Development.
- Важен моментальный фидбэк. У нас должен быть пайплайн, который сразу же нам говорит, как только что-то сломалось. Потому что мы сразу же должны пойти и это моментально починить.
- Участие в дизайне. Бывает такое, что вы смотрите на что-то и думаете, как мы это говно теперь будем тестировать. Но извините, а где вы были, когда все решили, что будет говно? Вы приходите на совещания и говорите, что вы не согласны, надо делать неговно. Надо участвовать в дизайне, чтобы гарантировать, что потом вы сможете это протестировать.
- Инструменты, обвязки, стенды — то, что многие из вас делают сегодня, никуда не уходит. Наоборот, этого будет больше. Соответственно, это кто-то должен писать.
- Chaos engineering. Вы всегда мечтали запустить Chaos Monkey в продакшн, особенно если у вас есть сеть банкоматов на Windows 95. Вот ваш шанс.
- И наконец, нужно учить неучей дизайнить тесты. Мы же решили, что разработчики по крайней мере утверждают, что они пишут тесты. Вот теперь пусть пишут тесты, только надо их научить это делать. Кто их будет учить, откуда они знают, как писать тесты? Только вы. Больше некому.
Осталось все заавтоматизировать. На самом деле, мы умеем автоматизировать тестирование. Проблема в том, что автоматизировать можно определенную часть.

Вы все знаете этот анекдот про то, как тестировщик заходит в бар, заказывает пиво, заказывает 0 пива, заказывает 99999999999 пива, заказывает ящерицу, заказывает -1 пиво и заказывает… Вот тут баг, потому что это должно быть asdfgh, а не вот эта фигня.
Это легко автоматизируется. Понятно, что в цифрах вообще нет проблем. Мы ставим рандомайзер, он нам это делает. Даже ящерицу сегодня уже можно туда сгенерировать. Это фаззинг — надеюсь, что вы про него слышали, потому что я вот вчера прочитал.

А вот дальше приходит клиент, спрашивает, где туалет и все, бар сгорает, все умирают и все такое. Вот это автоматизировать нельзя. Ну, как бы можно, но сначала надо понять головой, что бар — это не только там, где напитки, это еще там, где туалет. Более того, шансов, что клиент захочет пойти в туалет, немножко больше, чем то, что он закажет ящерицу. Поэтому это проверить важнее, но для этого надо понимать бизнес, надо понимать продукт, и это могут сделать только люди с головой.
Вы видели список, там девять совершенно разношерстных требований, и совершенно понятно, что это может делать только единорог. Единорог от тестирования ничем не отличается от единорога от DevOps. Он точно так же не существует, и решение такое же. T-образные инженеры — это то, что нам нужно.
Те, кто умеет делать что-то одно очень хорошо. Вот у них «брейнуальное тестирование», они могут подумать, что в баре нужен туалет. Ну, не каждый может, но есть такие, которые могут. А есть такие, которым дай Selenium упарываться. Не вопрос, но нужно понимать и все остальное.
Поговорим о том, как делать эту трансформацию.

Автоматизаторы — там все понятно. Это люди, которые сегодня нужны, завтра будут еще нужнее. Меняется общение. Мы вышли из колодца, сели с разработчиками, с Ops-ами и давай настраивать инструменты и процессы, обвязки, стенды, упарываться вот этим всем, потому что теперь наш пайплайн должен тестировать все сам, и теперь нам нужно, чтобы это все прекрасно работало, иначе будут проблемы с качеством.

Developers in test — их девелоперский бэкграунд очень полезен, потому что они понимают, как думают окружающие. Им можно объяснить, как правильно тестировать. Участие в дизайне, чтобы сделать тестируемым ваш продукт; евангелизм — как правильно тестировать, о чем речь; внедрение TDD объясняет, какое покрытие имеет смысл, а какое нет, какие тесты имеют смысл, а какие нет. Те, кто сейчас в тестировании и имеют девелоперский бэкграунд, бесценны для этого общения.

«Брейнуальные тестировщики». Казалось бы, мы их уже отправили на покой и решили, что они не нужны, но это не так, потому что понимание продукта, понимание бизнеса — критический скилл. Эти ребята сейчас поднимаются на верхний этаж, где сидят все самые крутые перцы, и начинают им втирать про тестирование, влиять на архитектуру, понимать продакт, участвовать в совещаниях с бизнесом и приносить свою экспертизу в понимание, как правильно тестировать, в архитектуру продукта, в тестируемость продукта, евангелизм, как важно делать Continuous Testing и глобальное видение.
Для всех этих end-to-end тестирований гигантских систем идеальны ребята, которые были мануальными тестировщиками. Поэтому заголовки о том, что сотни тестировщиков были уволены, когда все перешли в DevOps, этого нет и не будет.
Безусловно, кто-то не захочет меняться, это нормально. Сегодня есть такие бородатые ребята, сисадмины закалки 70-х годов: «Никакого DevOps, мы будем ручками настраивать сервера». Даже они не безработные, потому что существует огромное количество систем, в которых они нужны.
То же самое с тестировщиками. Если есть кто-то, кто хочет делать мануальное тестирование, и все, что я сейчас рассказывал, им совершенно неинтересно, работа есть. Приведу пример: мы вчера с Леонидом Игольником (EVP Engineering, SignalFx) летели из Мюнхена, и выяснилось, что билет Леонида пропал в черную дыру между системами заказов Люфтганзы и системами заказов Юнайтед.
Обе написаны в 70-х годах на Коболе и работают на мейнфреймах. Их надо тестировать. Тот, кто не хочет меняться, добро пожаловать. Там дают много миль своим работникам, вы сможете летать на Карибы. Работа, наверное, будет не очень интересная, но это ваш выбор, без работы вы не останетесь. А те, кто хотят меняться, тут, извините меня, небо — это не предел, netflix нас всех ждет.
Вы видели, есть куда меняться, есть, что делать интересного, есть, куда идти, чтобы принимать решения, чтобы влиять на продукт, на бизнес, на процессы. Это все на самом деле очень круто. Мы не только не теряем работу, мы получаем намного более интересную.
Мы приближаемся к концу, и тут я вспомнил Леонида. Ну какой же доклад без цитаты от Леонида. «Важно лишь то качество, которое видит клиент», — сказал мне однажды Леонид, мудро почесав бороду, за ужином.

«Секундочку, — сказал я Леониду. — Мы только что полчаса обсуждали вот это все: процессы, стабильность, то, се. И ты мне тут говоришь, что клиенту глубоко наплевать, что у нас происходит, лишь бы та фича, в которой он заинтересован, работала. Так давай вообще ничего не будем делать. Вот у нас есть ручное тестирование, мы что-то там проверили, она работает и достаточно. Зачем это все втирать? Artifactory пришел продавать, засранец?!».
Я хочу вам напомнить, что эта статья и этот доклад — не про то, как тестировать лучше. Он про то, как релизить быстрее. Когда клиенты хотят новых фич? Сейчас!

Возвращаясь к DORA: чем больше работы автоматизировано, в данном случае это тестирование, тем больше у технических специалистов появляется времени делать осмысленную работу, то есть клепать новые фичи.
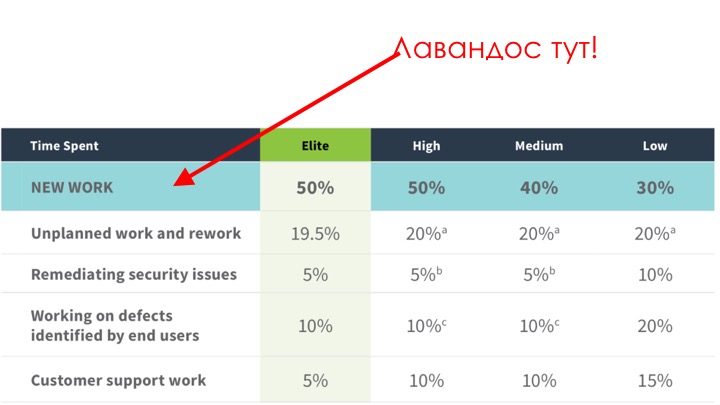
Нам нужен New Work. Обратите внимание, что New Work у Low — 30%, у Medium — 40%, у High и Elite — 50%. Половина времени (это практически в два раза больше, чем у Low) освобождается, чтобы творить, делать новые фичи.
И это очень и очень круто.
Это доклад с конференции Heisenbug 2018 Moscow, состоявшейся в декабре —, а 17–18 мая в Петербурге пройдёт следующий Heisenbug. Баруха не обещаем, но будет много других интересных спикеров. Посмотреть на программу можно на сайте конференции, приобрести билеты там же (и с первого апреля цены на билеты повысятся).
