Tree — убийца JSON, XML, YAML и иже с ними
Здравствуйте, меня зовут Дмитрий Карловский и я… много думал. Думал я о том, что не так с XML и почему его в последнее время променяли, на бестолковый JSON. Результатом этих измышлений стал новый стандарт формат данных, который вобрал в себя гибкость XML, простоту JSON и наглядность YAML. Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу:
Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу:
Больше — лучше
JSON
XML
YAML
INI
Tree
Человекопонятность
3
1
4
5
5
Удобство редактирования
3
1
4
5
5
Произвольная иерархия
3
3
3
1
5
Простота реализации
3
2
1
5
5
Скорость парсинга/сериализации
3
1
1
5
5
Размер в сериализованном виде
3
1
4
5
5
Поддержка поточной обработки
0
0
5
5
5
Бинарная безопасность
0
0
0
0
5
Распространённость
5
5
3
3
0
Поддержка редакторами
5
5
3
5
1
Поддержка языками программирования
5
5
3
5
1
Сравнение форматовЧеловекопонятность
JSON и XML позволяют произвольно форматировать вывод пробелами и переносами строк. Однако, часто по различным причинам (основные — меньший объём, проще реализация) их форматируют в одну строку и тогда они становятся крайне не читаемыми.
{ «users» : [ { «name» : «Alice» , age: 20 } ] }
How do you do?
How do you do?
 Удобство редактирования
JSON и XML довольно неудобно редактировать без специальных редакторов, понимающих их синтаксис. Как минимум необходима разноцветная подсветка лексем. Очень помогает — автоформатирование, автодополнение и подсветка ошибок. К сожалению, экранировать спецсимволы приходится вручную во всех форматах, кроме Tree, где оно не требуется.Произвольная иерархия
INI имеет жёстко ограниченную глубину иерархии.В XML произвольные дочерние узлы могут быть только у элементов — это вынуждает использовать их вместо, например, аттрибутов, для большей гибкости и единообразия.
Удобство редактирования
JSON и XML довольно неудобно редактировать без специальных редакторов, понимающих их синтаксис. Как минимум необходима разноцветная подсветка лексем. Очень помогает — автоформатирование, автодополнение и подсветка ошибок. К сожалению, экранировать спецсимволы приходится вручную во всех форматах, кроме Tree, где оно не требуется.Произвольная иерархия
INI имеет жёстко ограниченную глубину иерархии.В XML произвольные дочерние узлы могут быть только у элементов — это вынуждает использовать их вместо, например, аттрибутов, для большей гибкости и единообразия.
JSON и YAML для создания иерархий предлагают «списки» и «мапки». Не все структуры данных хорошо представимы с их помощью. Например, различные AST, где имена узлов могут повторяться и порядок следования которых важен.
В Tree есть только один тип узлов и любой узел может содержать произвольные дочерние. Как следствие, он не накладывает никаких ограничений на иерархию.
Простота реализации JSON Довольно простая грамматика (30 паттернов), чем и обусловлено большое число реализаций под разные языки.XML Довольно сложная грамматика (90 паттернов), которая могла бы быть куда проще, если бы не требование совместимости с sgml.YAML Крайне сложная грамматика (210 паттернов). Нужно быть очень терпеливым человеком, чтобы реализовать все нюансы, и потратить много человекочасов, чтобы избавиться ото всех багов.INI Крайне простая грамматика (8 паттернов), позволяющая описывать лишь одну, довольно простую структуру (ключ-ключ-значение).Tree Очень простая грамматика (10 паттернов), что, однако, не мешает описывать с его помощью произвольные иерархические структуры.Скорость парсинга/сериализации Не вдаваясь в сравнение скорости работы конкретных имплементаций, оценим теоретические пределы скоростей работы с разными формтами.Предельная скорость обработки данных зависит от сложности синтаксиса. Именно поэтому YAML парсится на порядок дольше, чем JSON, а XML по скорости где-то между ними.
Tree помимо простой грамматики имеет ещё одно существенное преимущество — отсутствие необходимости в экранировании и разэкранировании спецсимволов.
Размер в сериализованном виде Примеры файлов на разных языках: github.com/nin-jin/tree.d/tree/master/samplesКак видно, существенно больше всех места занимает XML, даже если его минифицировать. JSON в читабельном виде и YAML где-то по середине. А самые компактные — INI, Tree и минифицированный в одну строку JSON.
Поддержка поточной обработки Поддерживающие поточную обработку форматы, позволяют добавлять данные в файл, просто подклеивая их в конец. Яркий пример — различные логи. И наоборот — нормально распарсить данные, имея лишь некоторое число начальных строк.В случае XML и JSON такой возможности нет — документ с обрезанным концом или дополнительными данными в конце, является невалидным.
Бинарная безопасность Почти все текстовые форматы не совместимы с бинарными данными. Именно поэтому Tree — на самом деле не текстовый формат, хотя его и можно редактировать в текстовом редакторе при соблюдении некоторых ограничений (использовать только unix-переводы строк, табуляцию для отступов, и не использовать произвольные бинарные данные).Распространённость XML довольно продолжительное время был в тренде, так что нашёл применение во множестве мест. Сейчас уверенными темпами популярность набирает JSON, благодаря своей простоте, но ценой некоторой потери гибкости. INI за счёт своей ограниченности применялся лишь для различных конфигов, но сейчас замещается более гибкими форматами. YAML остаётся довольно нишевым форматом ввиду своей переусложнённости, хотя и снискал некоторую популярность у любителей «писать меньше, делать больше, а потом хоть трава не расти». Tree пока ещё вначале пути и надеюсь не в конце.Поддержка редакторами XML и JSON благодаря своей популярности поддерживаются везде. Над поддержкой YAML многие разработчики редакторов просто не видят целесообразности заморачиваться. INI настолько прост, что для него никакой особой поддержки и не нужно. С Tree в принципе та же картина, но есть один плагин к IDEA о котором будет рассказано далее.Поддержка языками программирования Тут в целом та же ситуация, что и с поддержкой редакторами. Разве что для Tree есть две реализации — на языках D и TypeScript/JavaScript.Подробнее о Tree Уровни представления • Уровень формата. Определяет базовую модель данных и представление её в сериализованном виде.• Уровень языка. Определяет семантику узлов и представление их в отличных от Tree форматах.• Уровень приложения. Определяет API для взаимодействия с моделью данных Tree.Модель данных Модель Tree крайне проста — есть только один тип узлов, и каждый узел имеет: имя, значение, список дочерних узлов. Имя и значение являются взаимоисключающими, так что условно все узлы можно разделить на 3 типа: • Имена — узлы с непустым именем и пустым значением. Используются для именования поддеревьев. В имени не может быть пробельных символов, символа перевода строки и символа равенства.• Значения — узлы с пустым именем. Используются для хранения значений. Единственное ограничение на значения — они не могут содержать символ перевода строки.• Коллекции — узлы с пустым именем и значением, но не пустым списком дочерних узлов. Используются для работы со списком узлов как с одним узлом. В результате парсинга возвращается именно коллекция, содержащая список корневых узлов.
В Tree нет комментариев или инструкций процессору, знакомых нам из XML. Нет списков или мапок из JSON и YAML. Нет специального синтаксса для секций, как в INI. Однако они и не только они могут быть введены в языках, основанных на формате Tree.
Строковое представление Tree-файл состоит из набора строк, разделённых символом перевода строки (0×0D). Каждая строка начинается с некоторого количества символов табуляции, показывающих какой из предков является родителем первого узла в строке. И далее идёт список узлов разделённых пробелами. Каждый следующий при парсинге вкладывается в предыдущий. Узлы-имена представляются просто своим именем. Узлы-значения — значением, предварёнными символом равенства.В одной строке может быть произвольное число узлов-имён, но узел-значение может быть только один, причём самым последним. Значение может содержать абсолютно любые символы за исключением символа перевода строки. Когда нужно поместить произвольные бинарные данные — их предварительно надо разбить по символу перевода строки на несколько узлов-значений. А при приведении дерева к строке именованные узлы будут отброшенны, а данные из узлов-значений будут выведены как есть и между ними будут вставлены переводы строк.
Наличие табуляции в строке означает, что первый узел в этой строке должен быть вложен в последний узел последней строки имеющей табуляцию на один меньше.
По сухому описанию довольно сложно ухватить суть, так, что далее будет множество наглядных иллюстраций…
Примеры применения Tree в разных областях
Контекстно свободные грамматики
Хоть формат Tree и не является контекстно свободным, но разбить на лексемы его можно по сравнительно не сложной контекстно свободной грамматике, которую можно выразить тоже в формате Tree: 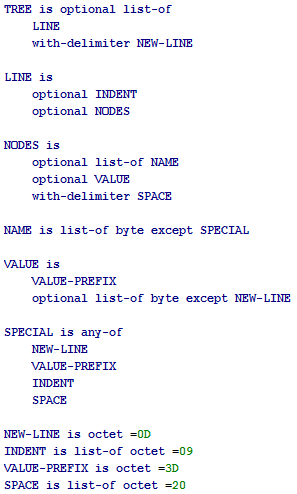
Подробнее о языке grammar.tree
Описание грамматики состоит из списка слов, для каждого из которых внутри задан соответствующий ему шаблон.is
Предикат эквивалентности. Обозначает, что родительский узел может быть заменён на последовательность дочерних шаблонов.
Данное выражение определяет STATEMENT как последовательность из некоторого «выражения», за которым следует символ «точка с запятой».
octet
Совпадает с одним октетом (8 бит) с указанным внутри шестнадцатиричным значением.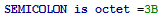
Тут мы определяем SEMICOLON как октет с заданным значением. Если значение опущено, то такой шаблон совпадает с любым значением.
optional
Допускает отсутствие дочернего шаблона.
Совпадает либо с двумя байтами: возвращения каретки после которого идёт перевода строки. Либо с одним переводом строки.
any-of
Сопоставится с одним и только одним из дочерних шаблонов.
list-of
Позволяет последовательно повторить дочерний шаблон произвольное число раз (но как минимум одно совпадение должно быть).
Тут DELIMITER совпадёт с не пустой последовательной группой пробелов.
except
Служит для исключения дочернего шаблона из родительского. Это значит, что родительский шаблон будет сопоставлен лишь с таким набором байт, с которым не может быть сопоставлен дочерний.
Тут мы определяем EXPRESSION как произвольное число байт ни один из которых не является «точкой с запятой».

А этот шаблон уже совпадёт с произвольным набором байт (в том числе содержащего «точку с запятой»), но только не с одиночной «точкой с запятой».
with-delimiter
Указывает, что совпадения сестринских шаблонов должны быть разделены дочерним шаблоном.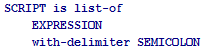
Здесь SCRIPT определён как набор выражений, разделённых заданным символом.
Лог доступа к веб-серверу
Расширяемый структурированный формат логов. Может показаться громоздким, зато очень быстро и точно парсится как человеком так и машиной.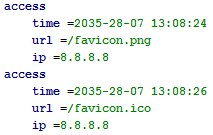
Поток сообщений от сервера в чате
Специальный разделитель »---» говорит клиенту о том, что завершилась пересылка очередной порции данных.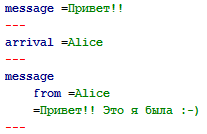
Вёрстка статической веб-страницы
Специальный DSL на базе Tree позволяет лаконично описывать XML любой сложности. Трансформер из xml.tree в xml понимает специальные узлы »@»,»!» и »?» формируя атрибуты, комментарии и инструкции процессору.
Подробнее о языке xml.tree
Структурные узлы соответствующие QName — элементы. Узлы данных — текстовые узлы.
Привет!
Хочешь, я расскажу тебе сказку?
Атрибуты представляются как узлы с QName именем, помещённые в узлы с именем »@».
Имена атрибутов повторяться не должны. Значением атрибута является текст, но также внутри может быть и дерево, которое при создании XML должно быть сериализовано в текст.Вложенные основанные на формате Tree языки помещаются в узел с именем этого языка, который помещается в узел c именем »%». От процессора требуется поддержка используемых языков, иначе он не сможет правильно собрать XML. Вложенные языки сериализуются в строку по своим правилам и вставляются в XML в качестве текстового узла.

Коментарии помещаются в узел с именем »--». Заметьте, что в коментарий помещается всё поддерево, которое сериализуется по всем правилам xml.tree.
Инструкции процессору помещаются в узлы с именем »?» и могут содержать как просто какие-то значения, так и пары ключ-значение.
Дамп реляционной базы данных
Заметьте, тут используется приём расширения языка. Сначала мы декларируем схему базы данных, а потом используем заданные в схеме имена в качестве DSL для описания данных.
Абстрактное Синтаксическое Дерево Эта структура данных используется языковыми трансляторами в качестве внутреннего представления обрабатываемых ими языков. Программируя на NodeJS велик соблазн использовать в качестве AST — некоторое подмножество JSON.Например, у нас есть следующий исходник на JS:
function getEl (id){
return document.getElementById (id)
}
Интуитивно кажется, что AST должен выглядеть как-то так:
[
{ «function»: {
«name»: «getEl»,
«args»: [ «id» ],
«body»: [
{ «return»: [
{ «get»: «document» },
{ «call»: {
«name»: «getElementById»,
«args»: [
{ «get»: «id» }
]
}}
]}
]
}}
]
Однако, это довольно не удобный для работы формат, так как чтобы узнать тип узла нужно проитерироваться по его свойствам и взять имя первого собственного свойства. Поэтому, чаще можно встретить формат типа такого, где первый элемент списка содержит тип узла, остальные — различный набор параметров специфичный для этого типа:
[ [ «function»,
«getEl»,
[ «id» ],
[ «return»,
[ [ «get»,
«document» ],
[ «call»,
«getElementById»,
[ «get», «id» ]
]
]
]
]
]
А теперь сравните с реализацией в Tree формате: 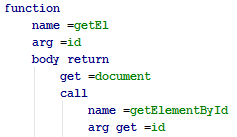
Редактирование других форматов, через Tree представление Основная фишка модели данных Tree заключается в том, что она позволяет описывать почти любые другие модели данных. Например, модель данных XML — это сильно усечённая модель данных Tree.Что это значит? А значит это, что многие форматы могут быть транслированы в некоторое подмножество Tree и обратно без потерь. То есть, вместо того, чтобы редактировать, например, XML как он есть, редактор может налету преобразовать его в xml.tree язык, позволив пользователю редактировать его в более удобной и наглядной форме, а при сохранении, делать обратное преобразование и сохранять именно XML.
Структурированный UNIX-трубопровод Суть проблематики и вариант решения с использованием JSON можно почерпнуть из статьи «JSON pipes в шелле». Вкратце: в linux все команды выводят результат в неструктурированном ориентированном на человека виде, что затрудняет компоновку их друг с другом. Там предлагается использовать JSON, который привносит структуру, но ухудшает читаемость и производительность. Формат Tree в этом случае может привнести структуру практически не теряя ни в читаемости, ни в производительности.Язык декларативного программирования Формат Tree мог бы решить основную проблему языка Lisp — неимоверное число скобочек. Если в Lisp всё описывается как списки, то в языке на основе Tree — всё есть деревья. Точно также программа представляла бы из себя некий AST, который мог бы модифицировать сам себя для создания DSL на все случаи жизни, достигая максимальной выразительности.Эталонная реализация На языке D парсинг занимает не более 50 строк, а сериализация — 20. Простейший язык запросов — 15. Итого, чуть более 100 строк занимает минимально необходимый функционал: github.com/nin-jin/tree.dПарсинг:
string data = cast (string) read («path/to/file.tree»); // read from file Tree tree = Tree.parse (data, «http://example.org/source/uri»); // parse to tree Глубокие запросы: Tree userNames = tree.select («user name»); // returns name-nodes Tree userNamesValues = tree.select («user name »); // returns value-nodes Работа с узлами: string name = userNames[0].name; // get node name string stringValue = userNames[0].value; // get value as string with »\n» as delimiter uint intValue = userNames[0].value! uint; // get value converted from string to another type Tree[] childs = tree.childs; // get child nodes array string uri = tree.uri; // get uri like «http://example.org/source/uri#3:2» Сериализация: string data = tree.toString (); // returns string representation of tree tree.pipe (stdout); // prints tree to output buffer Поддержка редакторами В данный момент есть лишь плагин подсветки синтаксиса Tree к IDEA, но он понимает только базовые конструкции формата, описанные выше. Для языков на базе Tree нужно будет сделать отдельные плагины или же один, но расширяемый с помощью схем.Заключение Надеюсь мне удалось заразить вас идеей использования замечательного формата Tree. Рассказывайте о нём другим. Пишите библиотеки на используемых вами языках. Внедряйте хотя бы опциональную его поддержку в ваши приложения. Ищите ему новые применения — уверен их ещё много. И тогда у него будет шанс на выживание в современном мире Трендо Ориентированного Программирования.
