Тред Ариадны: как перестать бояться и полюбить JSR-133. Доклад Яндекса
Многоядерные процессоры — обыденность. Рано или поздно любому программисту-практику придется зайти в лабиринт многопоточного программирования и встретиться с населяющими его «чудовищами». Поговорим о том, с чего начать этот путь и какие инструменты и подходы помогут выйти победителем.
— Меня зовут Сева Миньков. Я работаю в отделе облачной инфраструктуры поискового департамента. Занимаюсь в основном бэкендом. Пишу на разных языках, но чаще всего это Java и языки, запускаемые на Java Virtual Machine (JVM).
Наша команда занимается разработкой внутреннего облака, в котором запускаются практически все сервисы Яндекса — как публично известные типа Поиска, Почты и Алисы, так и всевозможные внутренние сервисы, виртуальные машины, а также короткоживущие MapReduce-задачи и задачи машинного обучения.
Наше облако не статично: компания растет, увеличивается количество сервисов и потребляемых ими ресурсов. И наша команда очень часто сталкивается с задачами масштабирования и улучшения производительности. Мы достигаем этого применением всего доступного инструментария, включая вертикальное масштабирование — то есть ускорением отдельных компонентов системы вплоть до переписывания некоторых однопоточных алгоритмов, чтобы они работали быстрее. Делаем и горизонтальное масштабирование: дробление системы на мелкие части с целью добиться лучшей производительности за счет добавления серверов, процессоров, ядер и т. д.
И в этом всем нам очень помогает многопоточное программирование. О нем сегодня и поговорим — откуда оно взялось, почему это актуально; что такое модель памяти, и как она вообще представлена в Java. Коснемся некоторых практических аспектов в том, как тестировать ваши приложения и проверять их корректность.
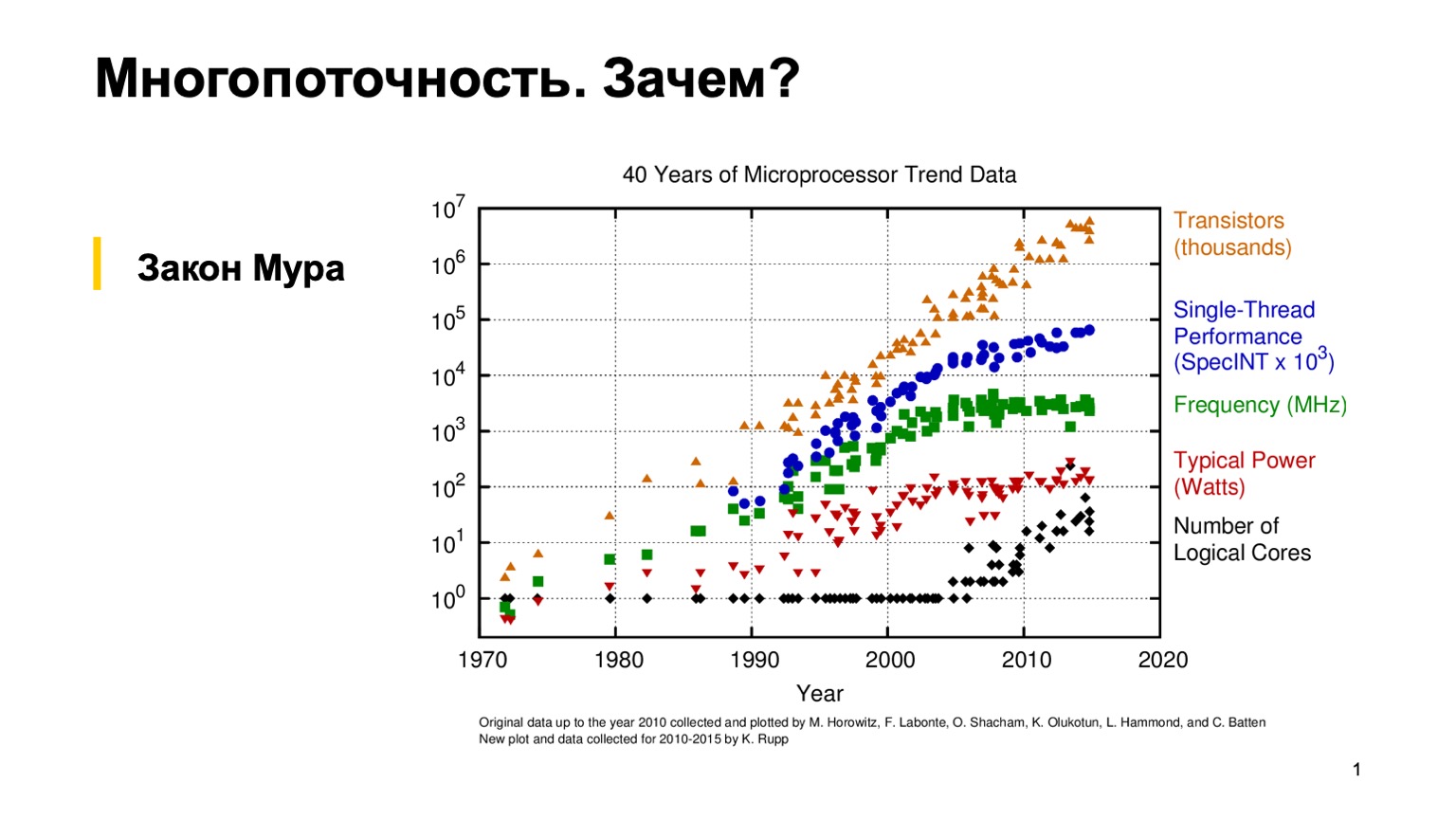
Для начала давайте посмотрим на этот интересный график, который показывает тренды характеристик микропроцессоров за последние 40 лет. Лет 10–15 назад, когда трава была зеленее и процессоры были однопоточные, обычный программист мог однажды написать корректную однопоточную программу, а потом надеяться на эмпирический закон Мура. Он говорит, о том, что процессоры становятся вдвое быстрее каждые два года. Как можно видеть, где-то в районе 2005 года по разным причинам производители микропроцессоров перешли на многоядерную архитектуру и начали увеличивать количество логических ядер. А прирост производительности отдельного ядра перестал подчиняться закону Мура, и вычислительная мощность одного ядра стала расти медленнее. Это произвело революцию, и обычным программистам, чтобы задействовать весь этот самый прирост производительности, пришлось применять параллельное программирование.
Так как мы с вами практики, попробуем написать простую многопоточную программу и своими глазами увидеть, как это работает.
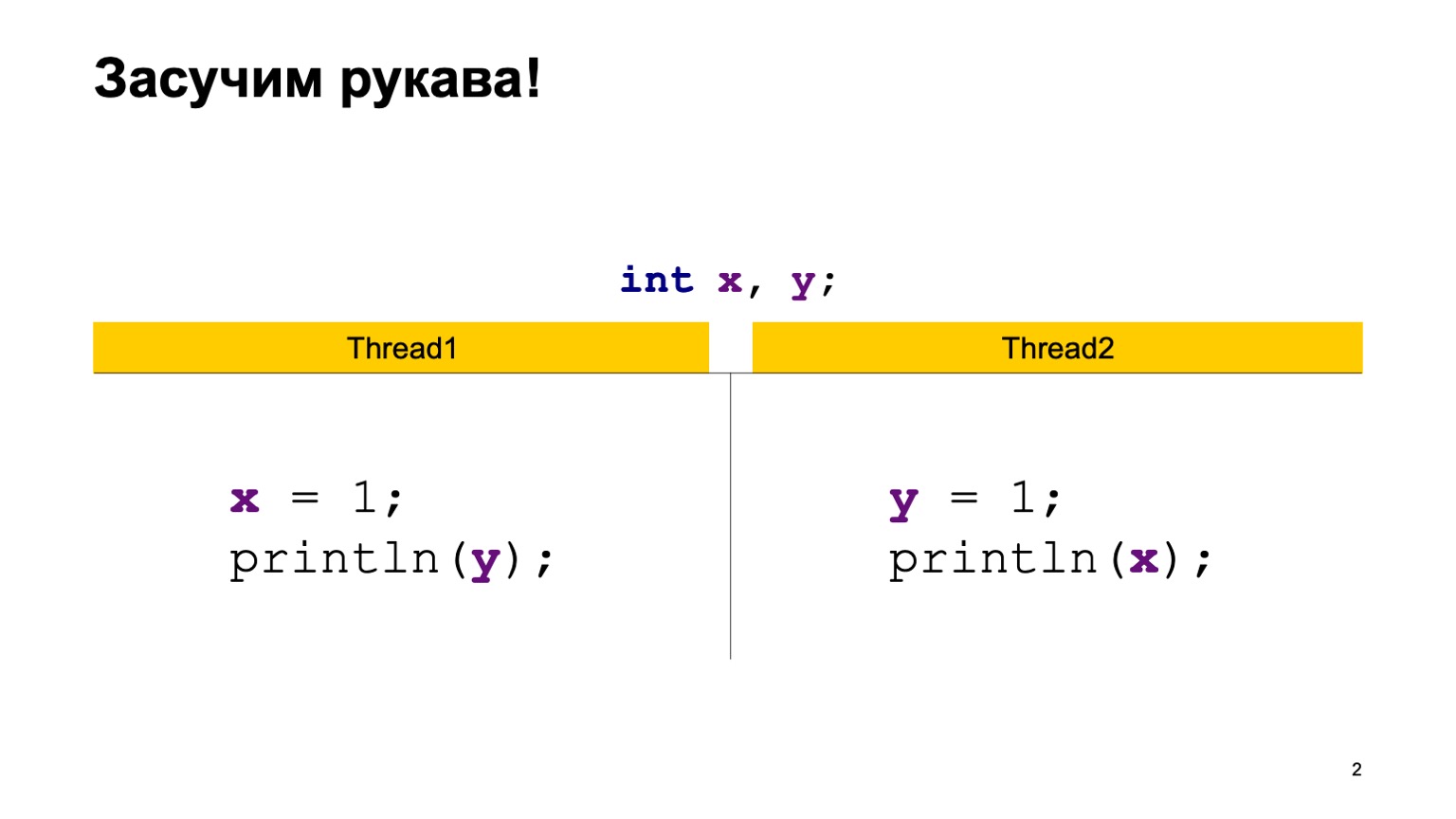
В качестве примера возьмем довольно простую задачку перекрестного чтения записей. Пусть у нас будет две разделяемые переменные X и Y, вначале проинициализированные дефолтным значением (нулем), и два потока. Каждый поток пишет в одну переменную и читает другую. В этом случае Thread1 у нас пишет в X единичку и читает Y. Второй поток делает то же самое, только задом наперед.
Простейшая реализация на Java может выглядеть примерно следующим образом.

Напишем класс ReadWriteTest, у него будет две статические переменные Х и Y. Прямо в методе main мы сконструируем два потока Thread1 и Thread2, подадим каждому из них на вход некоторую лямбда-функцию, которая будет выполнена в момент исполнения потока. Поместим туда код с предыдущего слайда и запустим два потока.
Порядок, в котором запустятся потоки, в некотором смысле непредсказуем. Это зависит от того, как операционная система зашедулит потоки. Соответственно, у нас могут быть разные варианты исполнения. Кажется, чтобы понять, как это все работает, нам придется запустить эту программу много раз, потом сагрегировать результат вывода и посмотреть, как часто тот или иной ответ будет встречаться в программе.

Ссылка со слайда
Чтобы не переизобретать велосипед, можем воспользоваться уже готовым инструментом. Это так называемый jcstress — утилита Java Concurrency Stress tests, которая входит в состав проекта OpenJDK.
Эта утилита предоставляет некоторый фреймворк для написания стресс-тестов. В данном случае код с предыдущего слайда переписывается довольно легко. В первую очередь, мы на класс повесим аннотацию jcstress Test, которая просто делает наши тестовые сценарии видимыми утилите. Также пометим его классом State, который говорит, что класс содержит данные, которые могут меняться: как модифицироваться, так и читаться из разных потоков. Объявим два метода, thread1 и thread2, и пометим их аннотацией Actor. Аннотация Actor означает, что метод должен быть исполнен в отдельном потоке. jcstress гарантирует, что каждый такой метод будет выполнен в отдельном потоке ровно на одном экземпляре класса State. Специально не оговаривается порядок, в котором они будут запущены. А результат будем записывать в некоторый объект II_Result, приведенный на слайде. Можно считать, что это тупл из двух численных значений, которые подаются как раз способом Dependency Injection, про который рассказывал Кирилл в предыдущем докладе.
Прежде чем запустить этот тест, давайте подумаем о том, какие выводы могут давать команды и какие значения мы можем сложить в r1 и в r2.

Для этого воспользуемся так называемой моделью чередования. Так или иначе каждая из операций: чтение или запись у нас выполняется в каком-то порядке. Достаточно просто комбинаторно перебрать все эти варианты и посмотреть, какие результаты у нас будут.

Допустим, один из возможных вариантов событий — поток один целиком выполнился до потока два. Сперва мы сложили в Х единичку, прочитали из Y ноль, поскольку туда не было записей. Потом записали в Y единичку и прочитали из Х один, поскольку первый поток уже успел это сделать.
Первый вариант ответа ноль-один.

Второй вариант развития событий с точностью до наоборот: поток два выполнился вперед потока один.

Соответственно, мы получаем зеркальный результат один-ноль.

Есть еще примерно четыре варианта, дающие один и тот же результат, когда у нас потоки выполнение потоков полностью перепутывается. Например, мы записали в одном потоке в Х единицу, во втором успели в Y единицу, и высчитываем один-один. Можете потом в качестве домашнего упражнения посмотреть, какие там еще есть варианты.

Кажется, мы все возможные варианты перебрали, больше ничего нет. Давайте запустим утилиту и посмотрим, какой вывод она даст.

Ссылка со слайда
Вывод выглядит как таблица. В первой колонке перечислены результаты, которые мы сложили в II_Result — утилита запускает этот код миллионы раз — и количество случаев, когда тот или иной результат вообще встретился. Но не было бы, наверное, этого доклада, если бы все было так просто.
На самом деле в этом выводе мы можем видеть еще результат ноль-ноль, который сложно объяснить моделью чередования. Такое ощущение, что один из возможных вариантов — что кто-нибудь прямо в коде потока взял и переставил строчки местами.
Давайте подумаем, почему так вышло и как нам с этим жить. Еще прошу обратить внимание на то, что вариант один-один встречался конкретно на моей машине крайне редко. Из 130 млн исполнений только 154 исполнения привело к результату один-один. А ноль-ноль наоборот встречается очень часто, практически в 30% случаев.

Итак, подведем некоторый промежуточный итог, что мы вообще с вами увидели. В первую очередь, мы могли понять, что взаимодействие потоков через память нетривиально. Модель чередования, которую мы с вами использовали, не работает. Мы увидели некоторую перестановку. Она могла произойти по многим причинам.
Например, мы могли видеть некоторые «релятивистские эффекты» железа. Об этом можно думать в следующем ключе: за один такт 3-гигагерцового процессора свет в вакууме успевает пройти примерно 10 см. Протокол чтения-записи в память процессора сложный и иногда требуется много сотен тактов, чтобы донести значение с одного ядра на другое. Соответственно, одно ядро может как будто бы видеть прошлое. Результат по факту записи произошел, но мы видим старое значение. Помимо этого, процессоры тоже не стоят на месте и могут менять инструкции местами.
К такой же перестановке могут привести современные оптимизирующие компиляторы. Они для достижения максимальной однопоточной производительности тоже могут менять инструкции местами так, что это не ломает корректность однопоточной программы. Но в многопоточных программах могут приводить к интересным эффектам, которые мы с вами видели.
И второй — наверное, главный вывод: мы увидели, что многопоточные программы фундаментально не детерминированы. Онопоточные программы в основном полагаются на некоторые инварианты на входе и на выходе, и детерминированы; если учесть, что генератор случайных чисел и пользовательский ввод — это входные параметры.
Это очень сильно все усложняет: сложно понимать, что делает программа, и сложно ее тестировать.
Про сложность тестирования можно добавить еще, что тот самый результат один-один встречался всего 154 раза из 130 млн вызовов. Вероятность возникновения этого результата — одна миллионная. В продакшене это означает, что такой баг может воспроизвестись спустя недели. И он обязательно произойдет где-нибудь в воскресенье ночью, когда вы этого совершенно не ждали.

Давайте подумаем, как же нам быть и что мы вообще хотим от языка, чтобы спать в воскресенье ночью спокойно. Во-первых, нужен инструмент, который бы нам позволял предсказывать поведение программы и делать суждения об ее исполнении. Во-вторых, нужны инструменты языка, которые бы нам позволили влиять на перестановки и эффекты — они могут быть от железа, компилятора и т. д. Хочется меньше знать про то, как работает конкретный процессор, какие оптимизации может делать компилятор, и пользоваться аббревиатурой, которая пришла из мира Java. Write Once, Run Anywhere — написать однажды корректный многопоточный код так, чтобы он работал на всех платформах.

Эти вопросы и требования, которые мы перечислили, они возникали в головах разработчиков очень давно и теоретиков, и практиков. Как и любая сложная задача с большим уровнем сложности, она была решена введением понятия некоторой абстрактной машины. Все мы, разработчики на высокоуровневых языках программирования, пишем не под конкретное какое-то железо, не под такую-то модель процессора, а пишем некоторую абстрактную машину. А спецификация языка призвана к тому, чтобы описать ее поведение так, чтобы помирить эти три мира. С одной стороны позволить разработчикам компиляторов и процессоров делать свои оптимизации и несильно взорвать мозг нам, программистам, которые пишут уже на конкретном языке.
Модель памяти занимает одну из центральных позиций в этой абстрактной машине. Она должна ответить на один вопрос: если я в каком-то потоке читаю переменную Х, результат какой из последних записей я могу там вообще увидеть? Попытка формализовать модель памяти была предпринята впервые именно в языке Java, все остальные модели памяти появились позже. Допустим, С++11 — это почти копипаста модели памяти Java с некоторыми изменениями.
Моделей памяти было несколько в Java. Изначально модель памяти так называемая «потоколокальная», она была признана неудачной, поскольку она затрудняла работу как программистов, которые пишут на Java, так и запрещала делать некоторые оптимизации компилятору, которые вполне себе уместные. Соответственно, в рамках community process JSR-133 была написана современная модель памяти.
Так как у нас есть священное писание в виде спецификации, давайте попробуем в нее заглянуть и понять, что же на самом деле происходит внутри.

Тут есть некоторая проблема. Поднимите руки, кто открывал спецификацию языка и читал, что там происходит. А кто из вас дочитал до модели памяти параграфа 17.4? Вас ждет небольшой сюрприз. Спецификация языка в принципе описана довольно понятным языком. Но модель памяти прямо пестрит, скажем так, некоторым математическим хард-кором. Там есть вкрапления на греческом языке, очень много математических терминов из серии транзитивное замыкание, объединение двух порядков и т. д.
К сожалению, другого пути нет. Единственное, на что вы можете полагаться, когда пишете многопоточные программы, это спецификация. Ее придется прочитать и понять. Очень вам рекомендую. Более того, когда я впервые прочитал спецификацию, у меня были примерно такие впечатления.
Почему так сложно? Я пошел неправильным путем и очень вас предостерегаю поступать, как я.
Я взял, поискал в интернете, что такое модель памяти. Нашел книжку, называется JSR-133 Cookbook for Compiler Writers. Она описывает, как разработчик компилятора может реализовать эту модель памяти простым способом. Проблема в том, что это одна конкретная реализация, и по ней нельзя судить вообще о модели памяти целиком.
Давайте все равно попробуем сделать попыточку небольшую основных выводов, которые можно понять из модели памяти Java.

Исполнений вашей многопоточной программы может быть много. Мы это сами видели на примере своей программы раньше. У нас в простейшем примере было уже четыре результата ее выполнения. А задача модели памяти Java — сказать, какие из этих исполнений корректны, и какие из них нужно запретить. И постулирует три вещи. Первое — в рамках одного потока ваша задача исполняется псевдопоследовательно. Под этим подразумевается, что компилятор может менять местами операции, процессор может тоже исполнять инструкции параллельно, менять их местами. Но они должны это делать так, чтобы видимые эффекты от исполнения вашей программы были такие же, как если бы она исполнялась прямо последовательно.
Второе — в языке запрещены так называемые out of thin air значения, взявшиеся из ниоткуда. К сожалению, у нас нет времени это показать, но бывают такие случаи, что компилятор действительно может сделать такое преобразование, что в однопоточной программе все будет корректно, а в многопоточной у вас может возникнуть запись, которую вы не делали.
Соответственно, модель памяти говорит, что чтение любой переменной либо вернет значение по умолчанию, либо какой-то из результатов записи, который был когда-то сделан другой командой. А остальные действия можно трактовать как последовательные, если они связаны отношением частичного порядка happens-before. И это сейчас единственное место, где нам понадобится математика. Частичное отношение, это потому что не все операции чтения, записи переменных, они связаны отношением. Оно обладает свойствами рефлексивности, транзитивности и антисимметричности.

Чуть поподробнее поговорим про сам happens-before. Первое правило — оно связывает все операции внутри одного потока. Если у вас внутри одного потока написано Х равно единице, Y равно единице; утверждается, что операции записи в Х относятся в отношении happens-before Y. То есть Х happens-before Y. И так же связывает некоторые специальные действия, так называемый synchronization actions. Подробнее можно почитать в спецификации. Например, это запись и чтение из volatile переменной, lock/unlock на одном мониторе, вход в блок synchronized и выход из блока synchronized. Очень важный момент, что все synchronization actions в вашей программе потоки видит ровно в одном и том же порядке, как будто бы они выполнялись один за одним.
И happens-before связывает некоторые пары этих действий. Неважно, в каком потоке происходит synchronization actions. Важно, что они проходят, например, над одной переменной volatile. Спецификация говорит, допустим, запись в volatile переменную happens-before любого другого последующего действия. Здесь имеется в виду именно в порядке, как у нас возникали synchronization actions.
И самое главное из всего этого — есть правило happens-before consistency, которое как раз отвечает на самый главный вопрос про модель памяти. Его можно интерпретировать следующим образом. Если есть цепочка операций чтения/записи в переменную и они связаны цепочкой отношений happens-before, то чтение должно обязательно видеть последнюю запись в этой цепочке. Если ее нет — сорян, вы можете увидеть любое другое значение, любую другую запись или значение по умолчанию. Теперь можно выдохнуть, с основными определениями мы закончили.
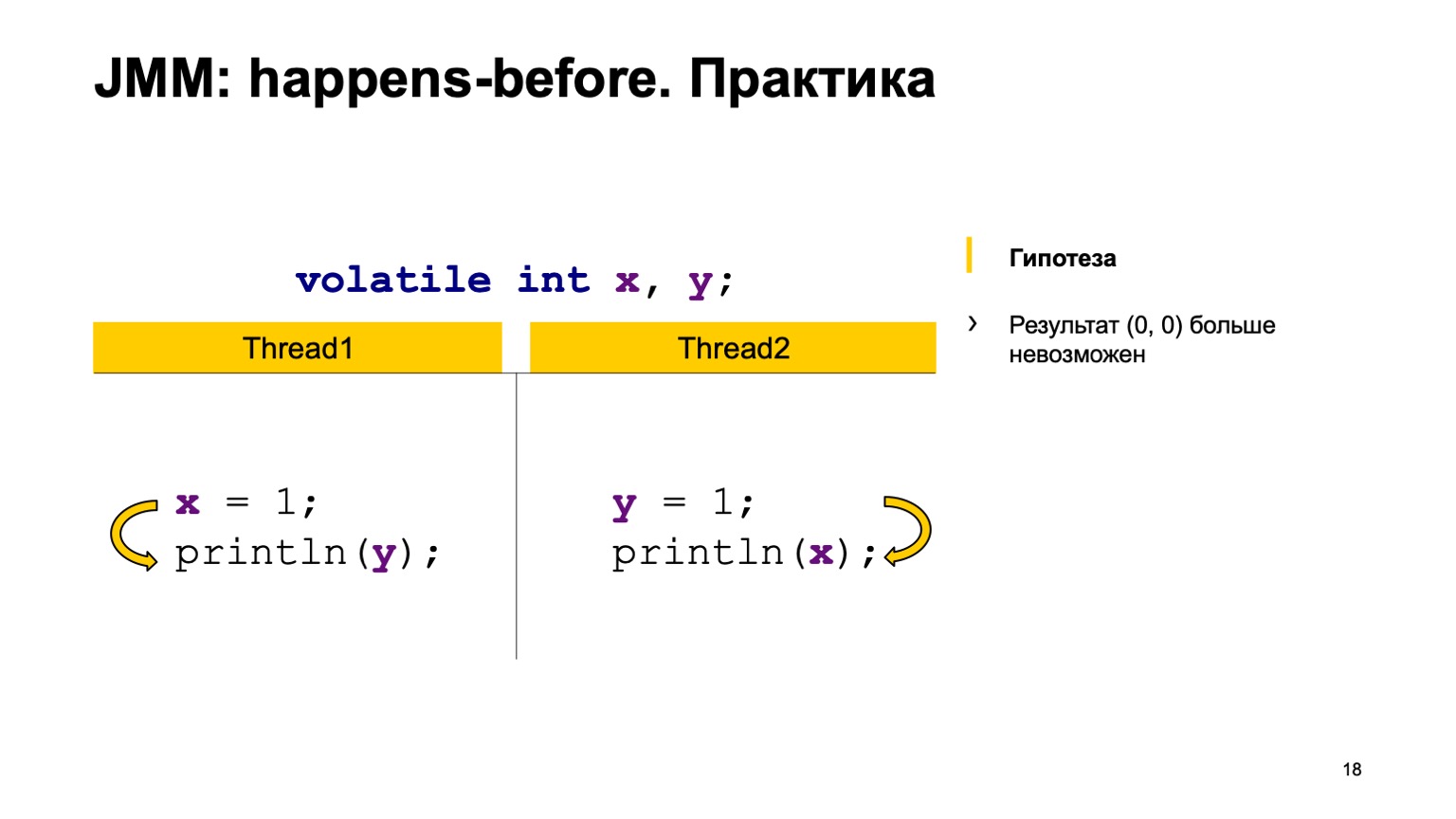
Давайте попробуем проверить теорию на практике? Возьмем пример с перекрестным чтением записей и просто добавим модификатор volatile к переменным Х и Y. Попробуем доказать гипотезу, что больше значение ноль-ноль мы не увидим. Для этого как раз воспользуемся теми правилами, которые я озвучивал выше.
Мы расставим happens-before в рамках одного потока. Запись в Х happens-before чтения из Y и во втором потоке. Запись в Y happens-before чтения из Х.
А дальше у нас есть четыре synchronization actions: запись в Х, запись в Y, чтение из Х, чтение из Y. Они могут появиться в некотором порядке, и пара может возникнуть в двух случаях.
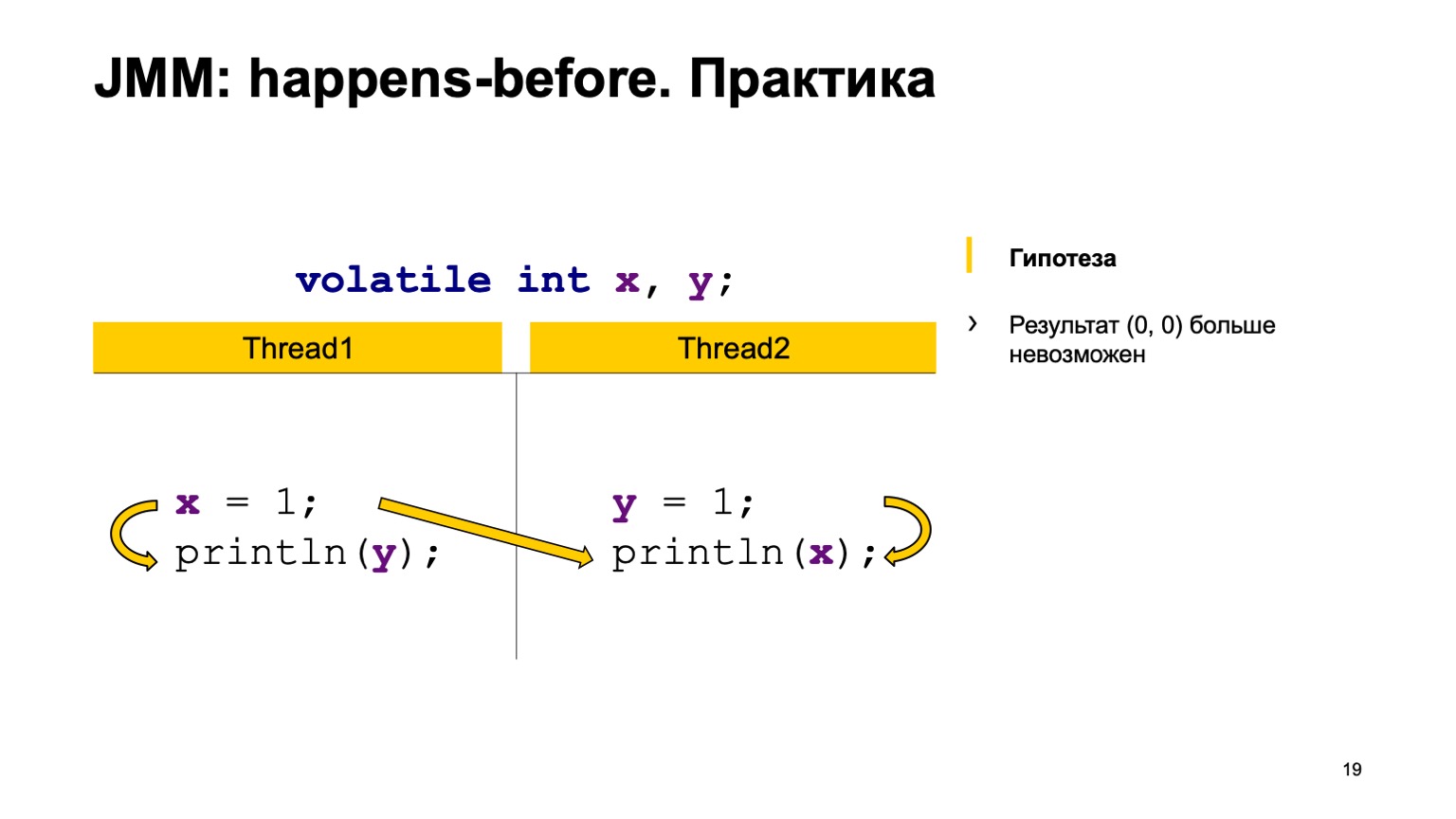
Например, запись в Х в потоке один произошла раньше, чем чтение из Х в потоке два (возникает happens-before). Как можно здесь видеть, отношением не связаны Y. Результат чтения из Y может как раз вернуть нам либо значение по умолчанию, либо значение, которое записал второй поток. А чтение из Х обязано всегда увидеть единицу. Соответственно, у нас варианты могут быть ноль-один, один-один.
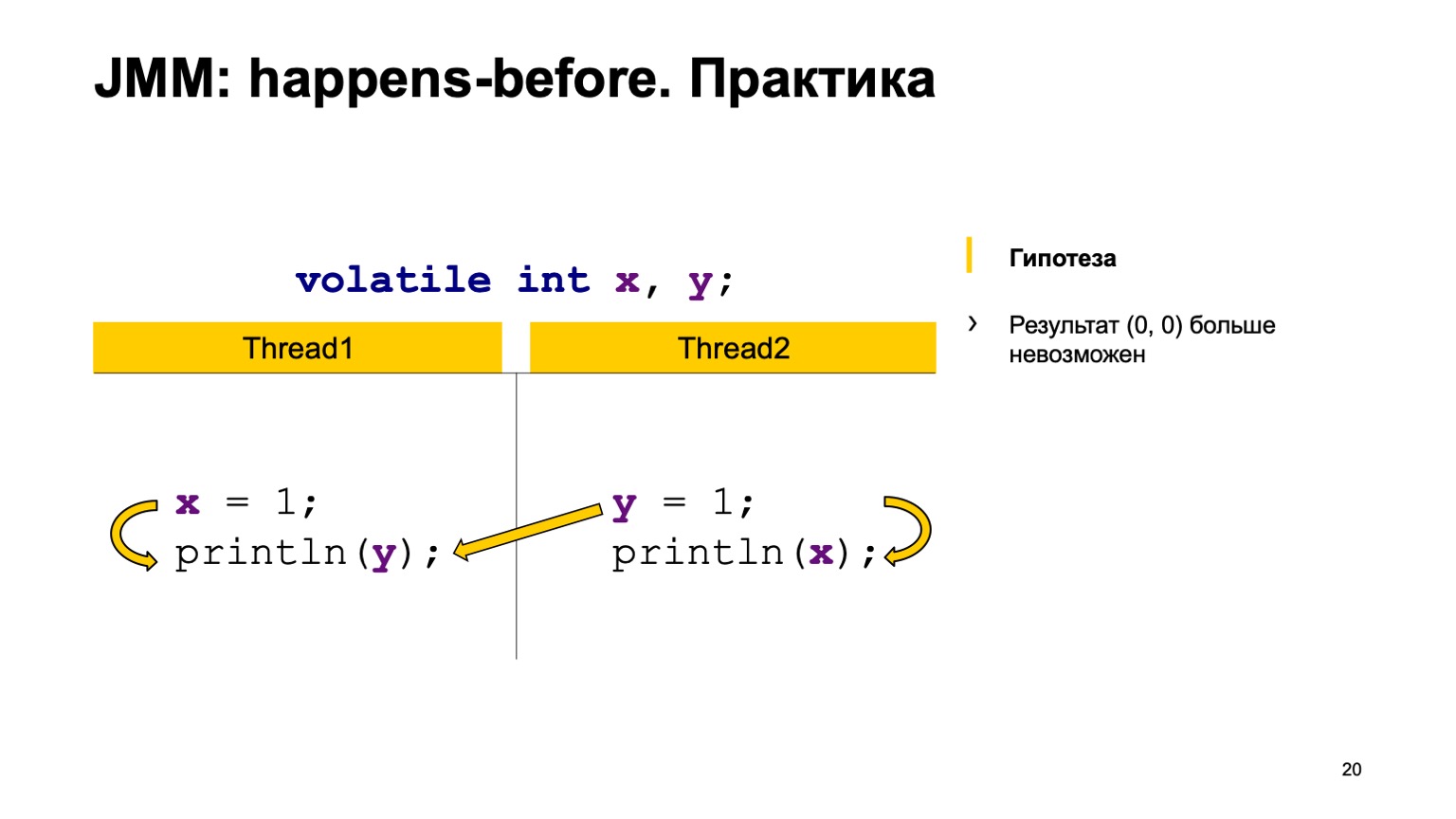
Второй случай, когда возникает связь. Это то же самое — запись в Y happens-before чтения из Y. Тоже нет связи между Х. Соответственно, результат тот же самый, только там получится один-ноль, ноль-один. Теоретически мы можем доказать наше новое поведение программы.

Можно проверить его на практике. Взять и в нашем тесте добавить ключевое слово volatile. Запустить и увидеть, что, действительно, у нас это значение больше никогда не будет воспроизводиться. Таким образом happens-before — очень хороший инструмент для доказательства корректности ваших программ. У него есть еще одно интересное и полезное свойство.

Допустим, у нас еще будет такой небольшой кусочек кода. Одна volatile переменная Х и переменная Z не volatile, без разницы. Есть один поток, который только пишет в переменные Х и Z; и второй поток, который дожидается, когда Х примет значение единицы, и только потом печатает Z. Точно так же мы можем выстроить отношение happens-before в рамках одного потока и между потоками. Мы увидим, что транзитивно запись в Z в первом потоке, значение его всегда достигнет чтения в потоке два. Это на самом деле довольно мощный механизм публикации данных между потоками.
Более того, представим, что эти кусочки кода в потоке один — это у нас некоторый метод объекта put value. Второй кусочек кода — некоторый метод get value того же самого объекта. Доказав отношение happens-before между этими методами, мы можем так и написать в документации, что put value happens-before get value. Это помогает вам словно из кирпичиков строить большие блоки вашей программы, для которых вы потом можете использовать свойство happens-before точно так же, как для volatile, только уже с этими методами. В стандартной библиотеке есть много мест, где так и написано, например — put значение happens-before get.

Итак, давайте сделаем некоторые выводы. Во-первых, спецификация сложна. К сожалению, это действительно единственное место, где вы найдете правду. И сама модель памяти дает вам довольно мощный инструмент, позволяющий доказать корректность ваших программ. Есть инструменты, которые могут проверить многопоточную корректность, но у них большие ограничения. Скажем так, это на самом деле не совсем роскошь для фриков. Вы либо можете доказать, что ваша программа работает на бумаге, либо она скорее всего не работает, и у вас есть баг, который воспроизведется как раз в воскресенье ночью.
Во-вторых, не бойтесь проверять на практике, используйте jcstress. Сама утилита замечательна и по другой причине: она используется для тестирования того, насколько сама JVM соответствует модели памяти. И там есть список тестовых сценариев, который как раз поможет вам в ее изучении.
Напоследок подскажу несколько книг, которые стоит почитать. Первая — «The Art of Multiprocessor Programming» Мориса Хёрлихи. Там закладывается очень много теоретических основ о том, что такое happens-before, последовательная согласованность, линеаризуемость и т. д. Вторая книжка более практическая — «Java Concurrency in Practice» Брайана Гётца. Это сборник паттернов многопоточного проектирования, который вы можете использовать в рутинной разработке. Книга рассказывает про такие вещи, как безопасная публикация, безопасная инициализация и т. д. Очень советую ее почитать. Можно посмотреть доклады и почитать блог Леши Шипилева, который был performance-инженером в Oracle, а сейчас работает в Red Hat. Он очень много пишет про то, как Java-машина выглядит внутри, как она работает. И у него был цикл лекций про JMM.
Можно почитать блог Романа Елизарова. Он преподавал, по-моему, в ИТМО многопоточное программирование. У него немножко заброшенный блог, но можно почитать, поискать его лекции и выступления на YouTube. В общем, очень годно, советую. Всем спасибо.
