Топ-5 провальных решений при разработке на Tarantool

Tarantool — гибкий инструмент для разработки высоконагруженных систем хранения данных. На нём пишут очереди, кеши и мастер-хранилища с разной топологией.Часто разработчики начинают работать с Tarantool, имея большой опыт работы с SQL, и пытаются применять привычные подходы из реляционных баз данных. В результате приложения становятся «хрупкими», теряют данные или деградируют в производительности.
Меня зовут Игорь, и сегодня я покажу, как антипаттерны влияют на производительность и стабильность приложений, и с какими пятью провальными решениями при разработке на Tarantool я столкнулся, работая с крупными продами. А также предложу способы избегания этих проблем.
Это текстовая версия доклада, который я рассказывал на HighloadFoundation 2022.
Map-reduce, который убивает select (nil)

Если вы когда-нибудь писали приложения на Tarantool, вы точно сталкивались с этой проблемой. Много продов легло из-за того, что разработчики забыли передать аргумент в вызов space:select().
Почему это так опасно: space:select() — аналог SELECT * в SQL. Он не отдаёт управление другим функциям, которые работают в Tarantool, пока не выберет все записи из спейса. Отменить эту команду после запуска не получится. И если вы случайно сделали select(nil) на большом спейсе, то получите full scan, который еще и выгружает данные в Lua-память, ограниченную двумя гигабайтами. Есть два варианта развития событий — либо закончится память, либо Tarantool на очень долгое время перестанет отвечать на запросы. select(nil) — гарантированный способ положить экземпляр Tarantool.
Как себя обезопасить? Во-первых, в select можно передавать параметр, который ограничит количество отбираемых записей, например, вот так:
space:select(nil, {limit = 1000})
Но лучше всего будет в этой ситуации использовать итератор pairs():
space:pairs():take_n(1000):totable()
Такой подход приучает разработчика явно указывать количество записей, которые нужно вытащить из спейса. А ещё итератор можно обернуть в функцию, которая будет периодически отдавать управление другому коду. Вот пример такой функции на Github.
Пагинация через смещение
Рано или поздно нам понадобится прочитать значительное количество данных из спейса, например, с помощью пагинации. Помня про space:pairs(), мы можем написать такой код:
space:pairs():drop_n(1000):take_n(1000):totable()
Кажется, что этот код должен пройтись по записям, начиная с 1000 и заканчивая 2000. Но на самом деле он пройдёт по записям 0–2000 и отбросит первые 1000. Если такой код попадёт в цикл, который должен считывать все данные из спейса, мы получим full scan. Он будет работать все хуже и хуже на каждой итерации и очень скоро превратится в select(nil).
Как правильно. В pairs() есть опциональные аргументы: ключ, по которому производится сравнение, и таблица с опциями, в которые можно передать { iterator = 'GE' }. Он позволит отобрать 1000 записей начиная с last_key.
space:pairs(last_key, { iterator = 'GE' }):take_n(1000):totable()
Фильтрация в cluster join
Даже после того, как мы починим все single node-запросы, перед нами останется проблема кластерных запросов. Давайте представим, что у нас есть БД SQL, в которой мы можем сделать такой запрос:
SELECT working_group, MIN(start_date)
FROM department JOIN employee
ON employee.employeeId = department.employeeId
AND department.departmentId IN $departmentIds
WHERE employee.jobType = 1 OR employee.position = 'senior'
GROUP BY working_group
Попробуем переписать его на Tarantool:
function get_employee_aggregation(bucket_id, groupId, departmentIds)
return yield_every(500, fun.iter(departmentIds)):reduce(function(acc, departmentId)
yield_every(500, department.index.employment_date:pairs({groupId, departmentId},
{iterator = 'REQ'})):each(function(y)
yield_every(500, employee.index.working_group:pairs({bucket_id, y.employeeId},
{iterator = 'EQ'}))
:filter(function(x) return x.jobType == 1 or or x.position == 'senior') end)
:each(function(x)
if not acc[y.working_group] then
acc[y.working_group] = {
working_group = y.working_group,
start_date = x.start_date,
}
end
end)
end)
return acc
end, {})
end
Такой код читать очень сложно, а при тестировании и отладке мы обязательно пропустим какой-нибудь corner-case, который выстрелит на проде. Подобный код может начать тормозить или стрелять ошибками 500 без явных причин. Может быть, не хватает передачи управления? Или какой-то из наших инструментов не очень хорошо подходит?

На самом деле мы просто написали неоптимальный код. Кластерные запросы — это сложно, и им можно посвятить отдельную статью. Здесь я покажу пример плохого JOIN«а и способ его исправления.
Пусть у нас есть кластер с двумя спейсами, по которым нам нужно сделать JOIN:
SELECT * FROM
SPACE_1 JOIN SPACE_2
ON SPACE_1.FK = SPACE_2.FK
WHERE …

Наивная реализация такого запроса может быть следующей:
- Делаем
SELECTиз каждого узла. - Отправляем данные на router.
- Делаем JOIN.
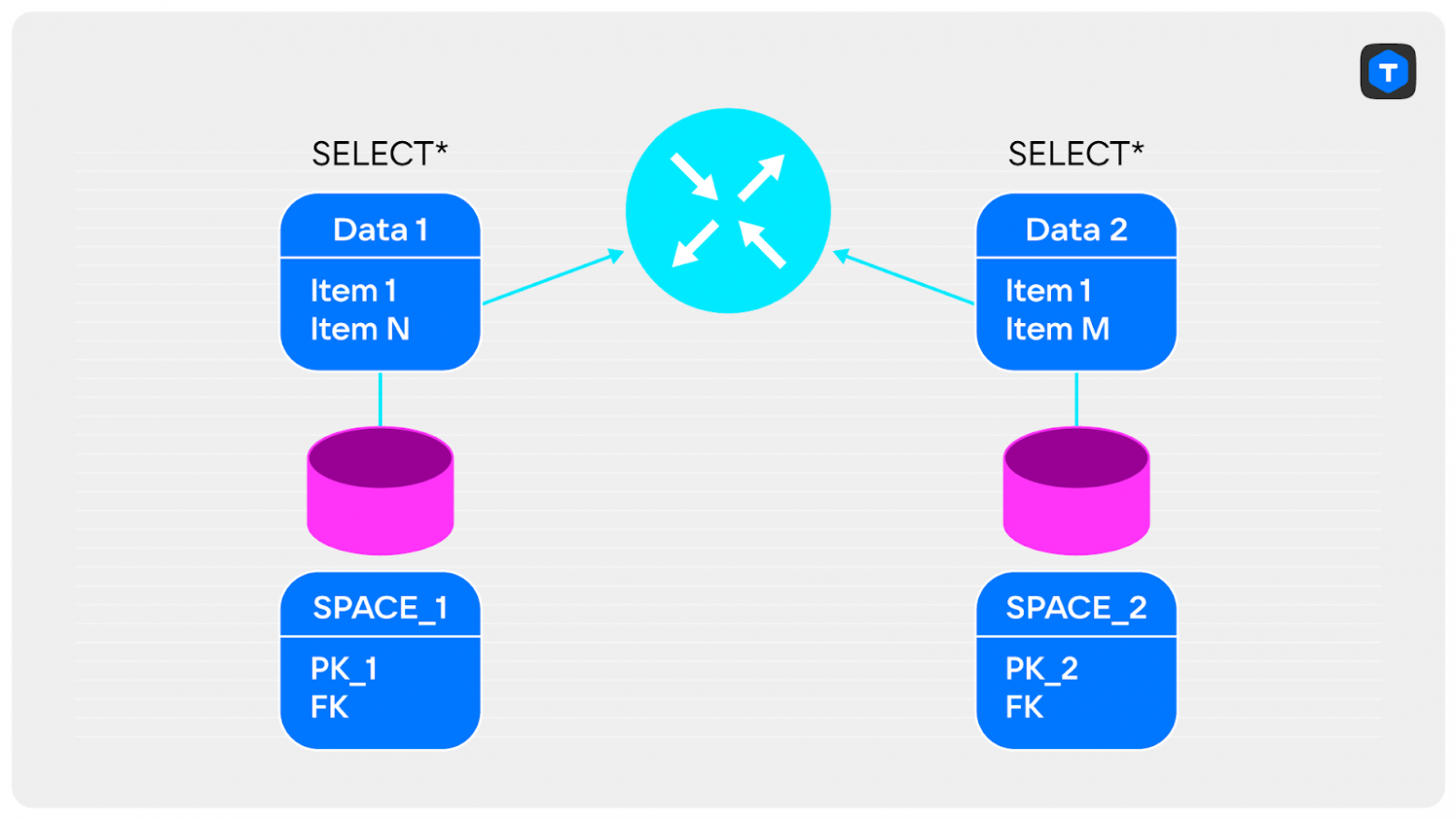
Какие проблемы у такого решения?
- Большие объёмы данных, которые нужно отправлять по сети.
- Может не хватить памяти для объединения данных.
Как можно починить?
Всё зависит от ваших данных. Например, можно достать из спейса только ключи, по которым выполняется объединение, и отправить их на router. Такие данные быстро передаются по сети и точно поместятся в память. Далее мы их объединяем на экземпляре router и получаем уменьшенное множество ключей.
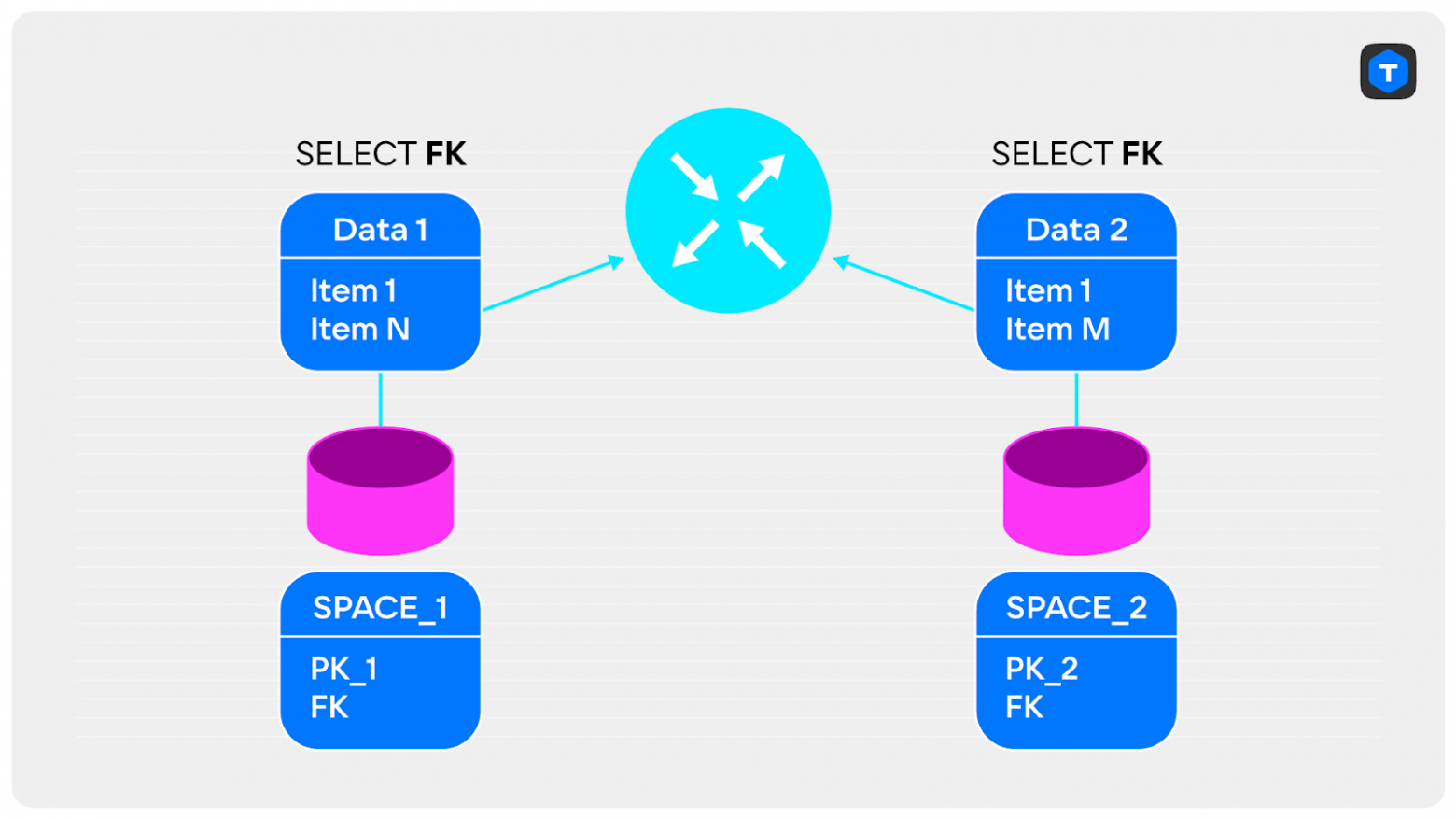
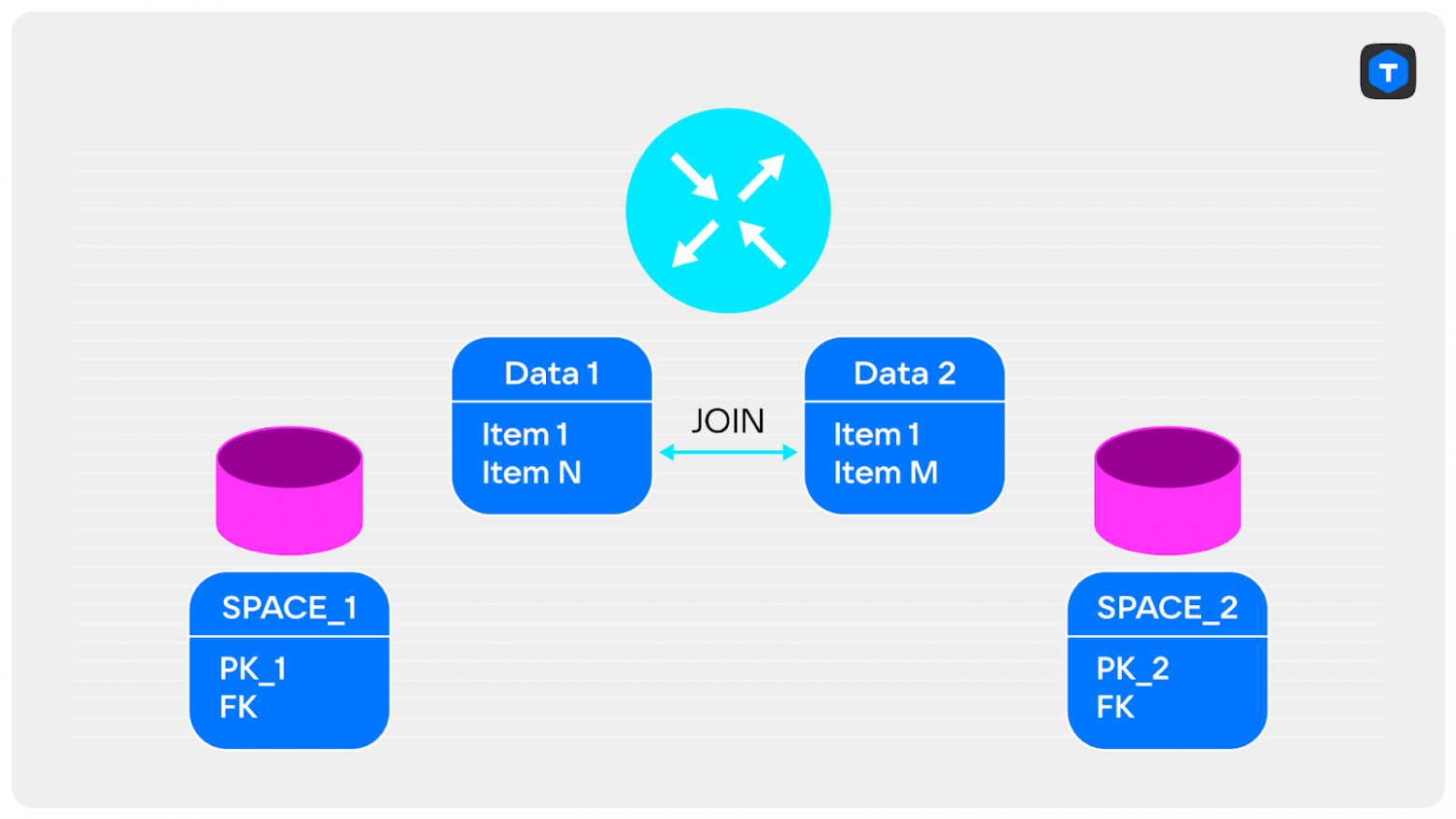
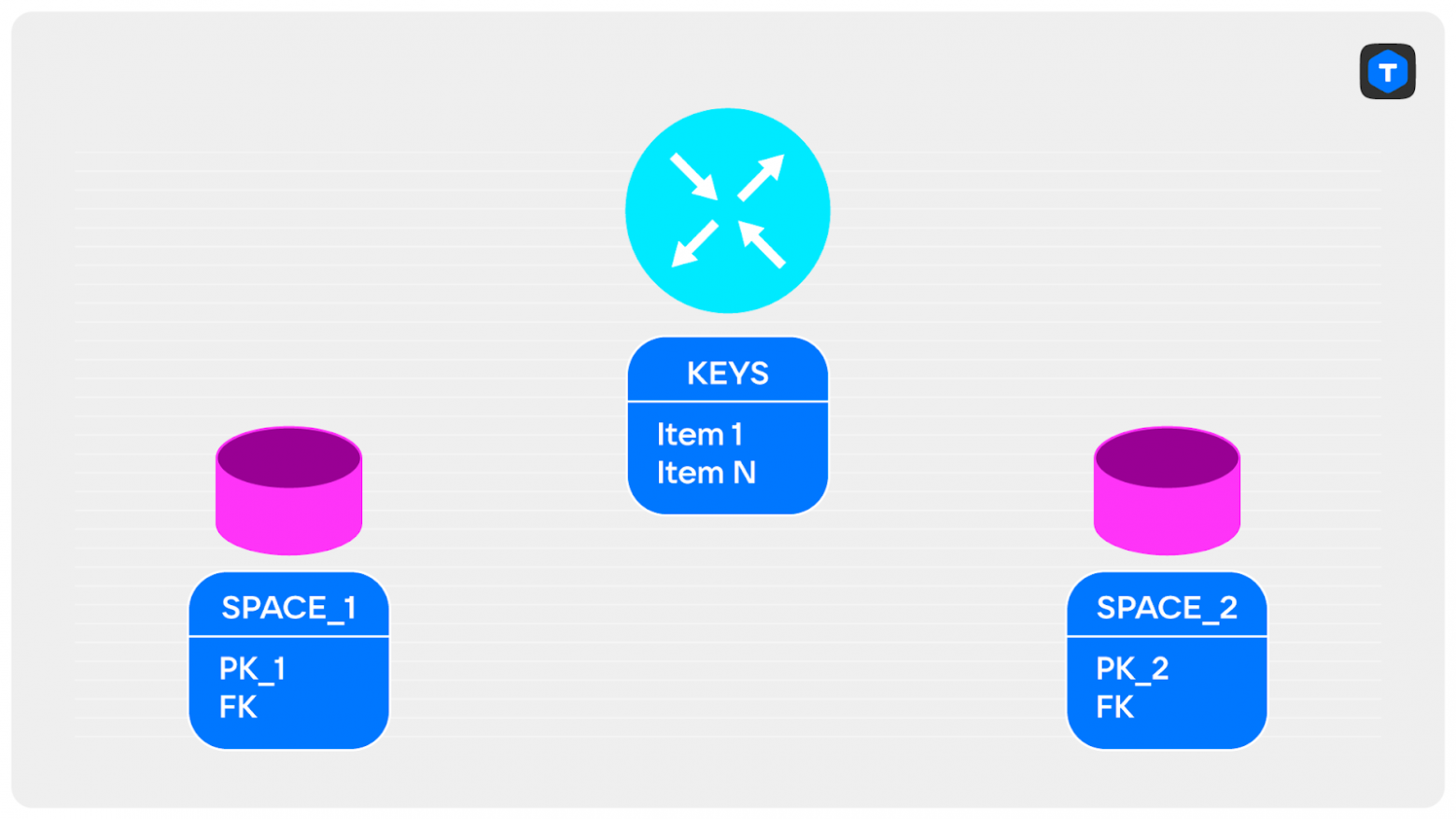
Теперь эти ключи можно отправить в экземпляр storage и отобрать записи, которые подходят под них, а затем передать записи на router и вернуть клиентам итоговый JOIN.
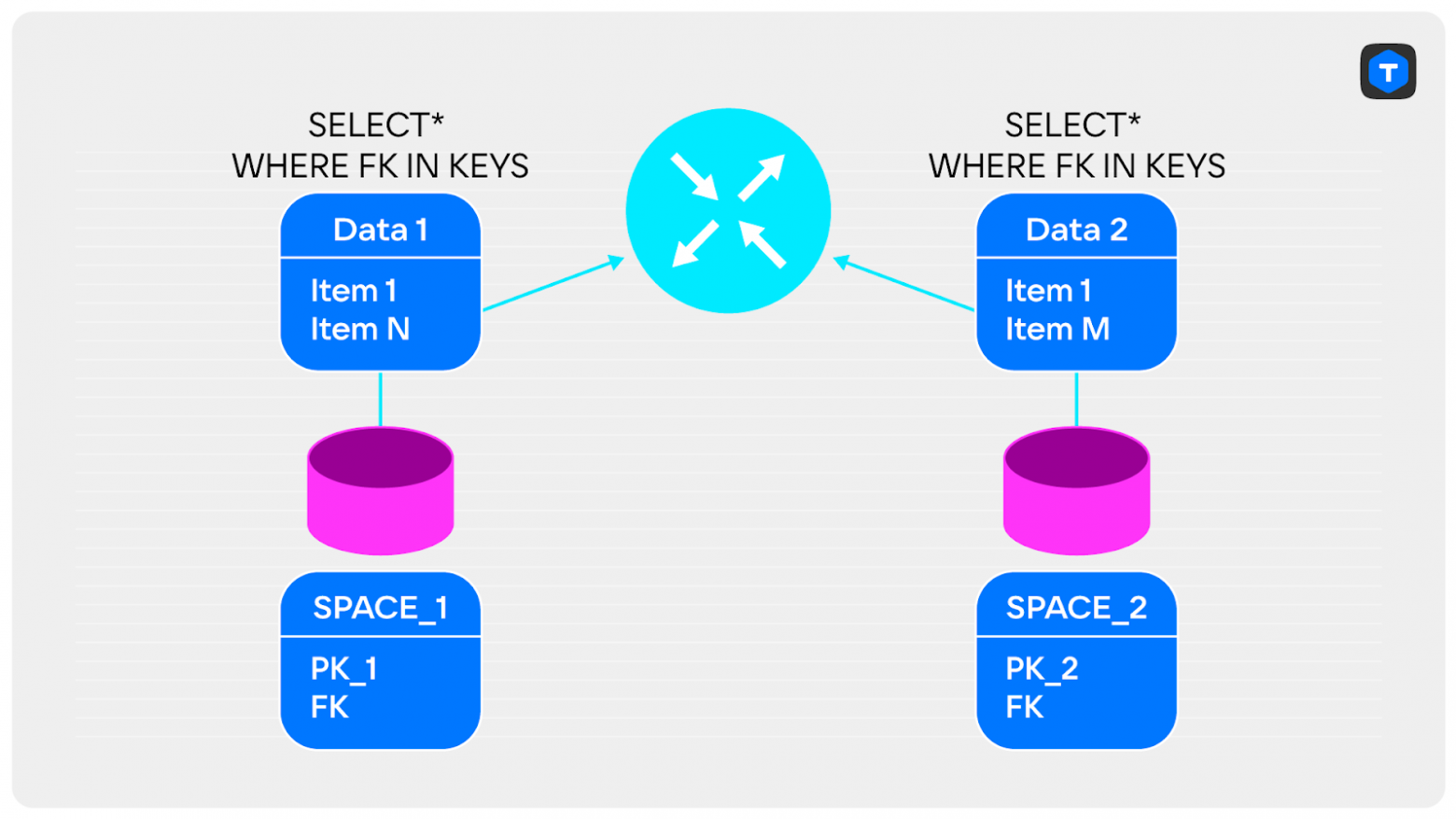
Это всего лишь один из способов решения проблемы с кластерным объединением. Общие принципы проектирования запросов:
- Хранение связанных данных вместе уменьшит количество походов по сети.
- Фильтрация на storage снизит объём передаваемых данных.
- Агрегация на экземплярах router разгрузит экземпляры storage.
- Сортировка по индексу позволяет не сортировать данные второй раз.
- Использование temporary-спейсов полезно в случаях, когда нужно объединять большие объёмы данных.
Что посмотреть по теме
SPOF
Есть множество способов получения единой точки отказа в кластере. Рассмотрим вариант, от которого пострадал я сам, работая с одним из продов.
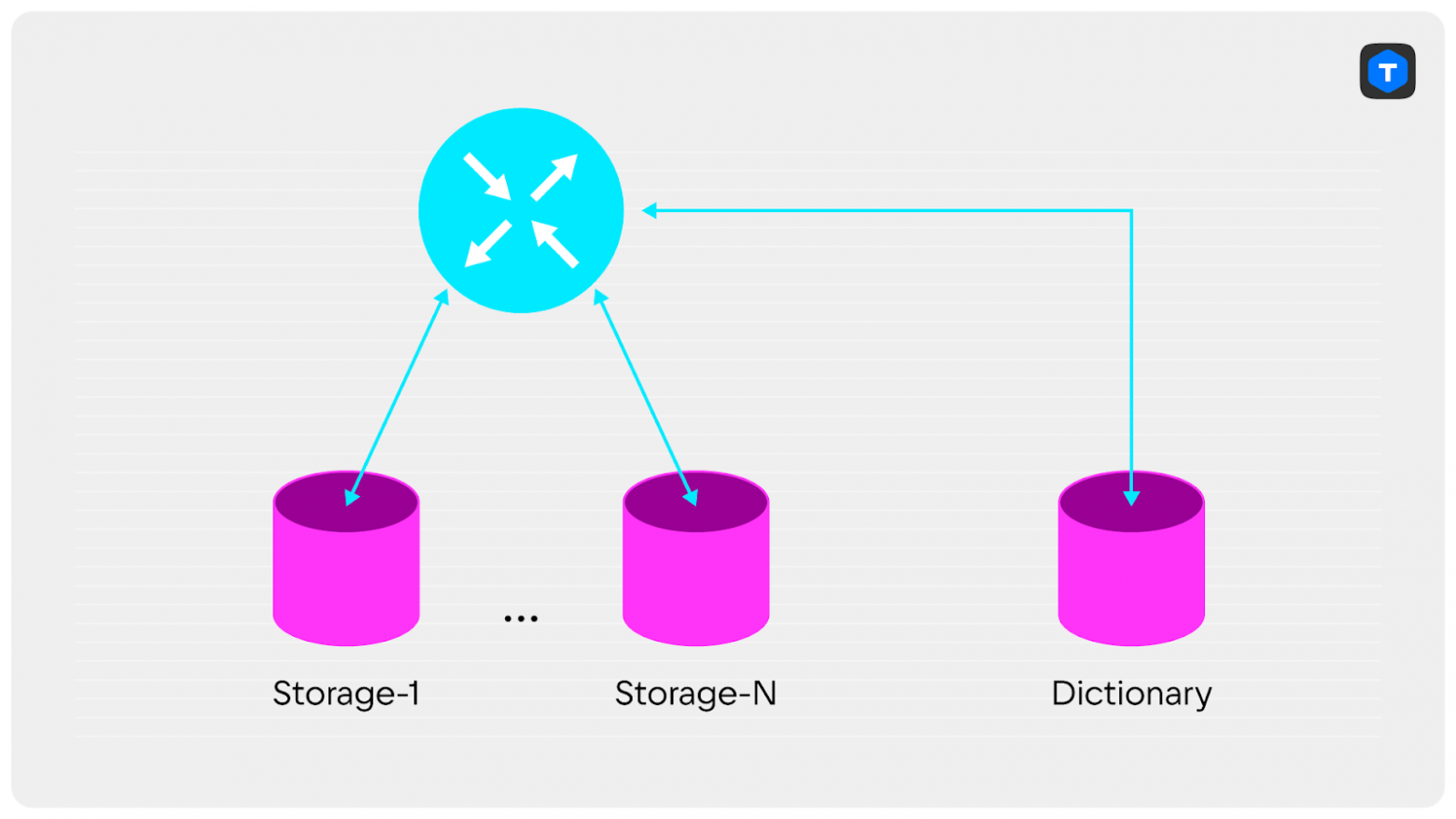
Представьте себе шардированный кластер, в котором есть отдельно стоящий узел. На нём хранятся словари — редко изменяемые данные, которые требуются для формирования ответов клиентам. Каждый запрос в кластере требует обращения к словарю:
SELECT *
FROM SPACE JOIN DICTIONARY
WHERE ...
Какие проблемы у такого решения?
Слишком много сетевых походов на один cluster JOIN. А если Dictionary не выдержит нагрузку, ведь каждый запрос в кластере требует обращения к этим данным? При увеличении количества запросов мы увидим, как Dictionary начнёт «мигать» и отвечать ошибками 500 на самые нетребовательные запросы. Ведь если нагрузка на остальные экземпляры storage распределена равномерно, то на Dictionary приходится гораздо больше запросов.
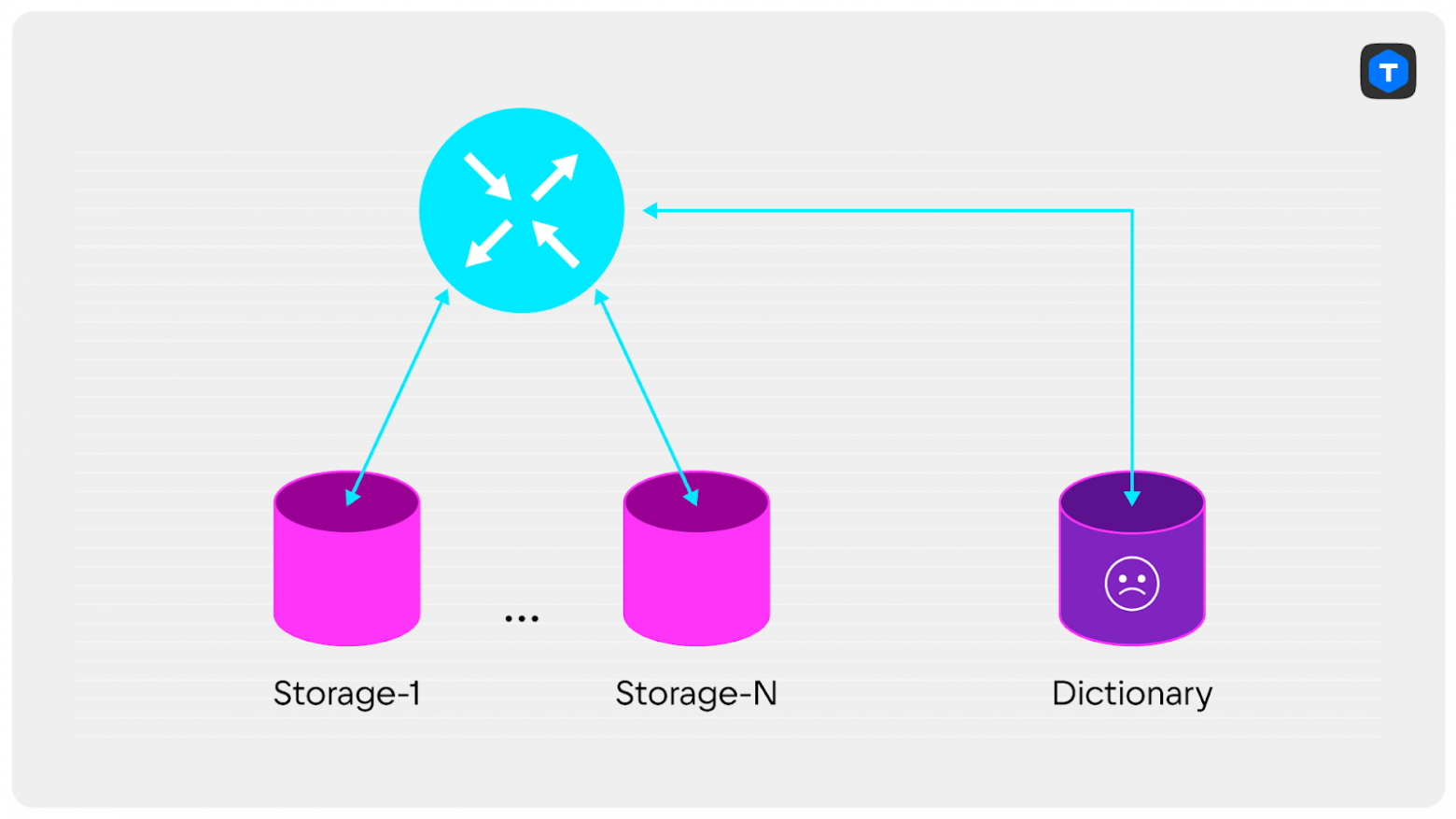
Как можно починить?
Например, объединить router и словари в один экземпляр Tarantool. Это избавит от необходимости ходить по сети лишний раз и сильно удешевит запросы.
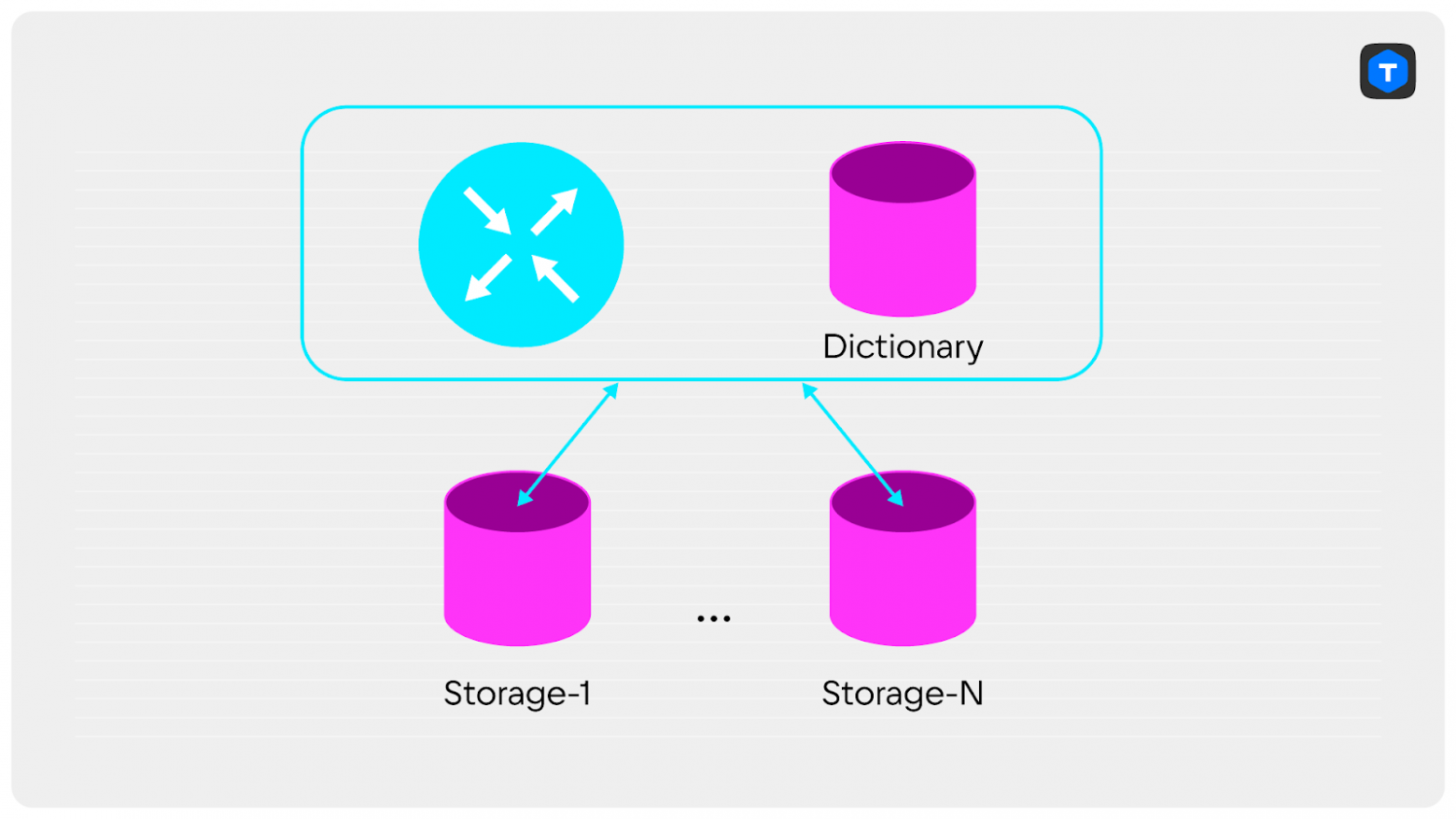
Если у вас уже есть единая точка отказа, то можно повысить доступность словарей:
- поднять дополнительные реплики и балансировать запросы между репликами;
- если нужно писать словарные данные:
Что почитать по теме
Неструктурированные данные
Tarantool — очень гибкий инструмент, он позволяет хранить данные как форматированными, так и без формата. Давайте разберём ситуацию, когда нужно хранить массив данных, в который мы часто вносим изменения, и сравним два варианта: с форматом и без.
box.space.storage1:format({
{name = 'key', type = 'string'},
{name = 'data', type = 'any'},
-- data: {name: string, value: number}
})
Чтобы поменять конкретное значение в массиве data, нужно пройтись по всем значениям в массиве:
local tuple = box.space.storage1:get('key')
for i = 1, 1000 do
local v = tuple.data[i]
if v.name == 'name' then
v.value = v.value + 1
end
tuple.data[i] = v
end
box.space.storage1:put(tuple)
Этот код выполнялся у меня 0,397735 секунды — для высоконагруженных систем слишком много. Давайте посмотрим, как можно исправить ситуацию, и разобьём массив данных на структурированные кусочки:
box.space.storage2:format({
{name = 'key', type = 'string'},
{name = 'pos', type = 'unsigned'},
{name = 'name', type = 'string'},
{name = 'value', type = 'number'},
})
Теперь вместо одного обновления понадобится несколько:
box.begin() -- обернем все в транзакцию
for _, v in box.space.storage2:pairs({'key'}) do
if v.name == 'name' then
box.space.storage2:update({v.key, v.pos}, {{'+', 'value', 1}})
end
end
box.commit()
Время выполнения 0,00036 секунды — это в 10 тыс. раз лучше предыдущего варианта!
Также при работе с неструктурированными данными можно не попасть в размер куска памяти, выделенного Tarantool для этих данных, и получить ошибку «Failed to allocate memory». Если вы с таким столкнулись, это можно исправить с помощью повышения параметра box.cfg slab_alloc_factor.
Что почитать по теме
Репликация мастер-мастер без триггеров
Репликация мастер-мастер — частое решение в Tarantool. Однако если писать данные одновременно в несколько узлов набора реплик, то можно столкнуться с проблемами. Например, если мы сделаем одновременные изменения на разных узлах, они отреплицируются на другой узел и мы получим разные данные на разных узлах и сломанную репликацию.
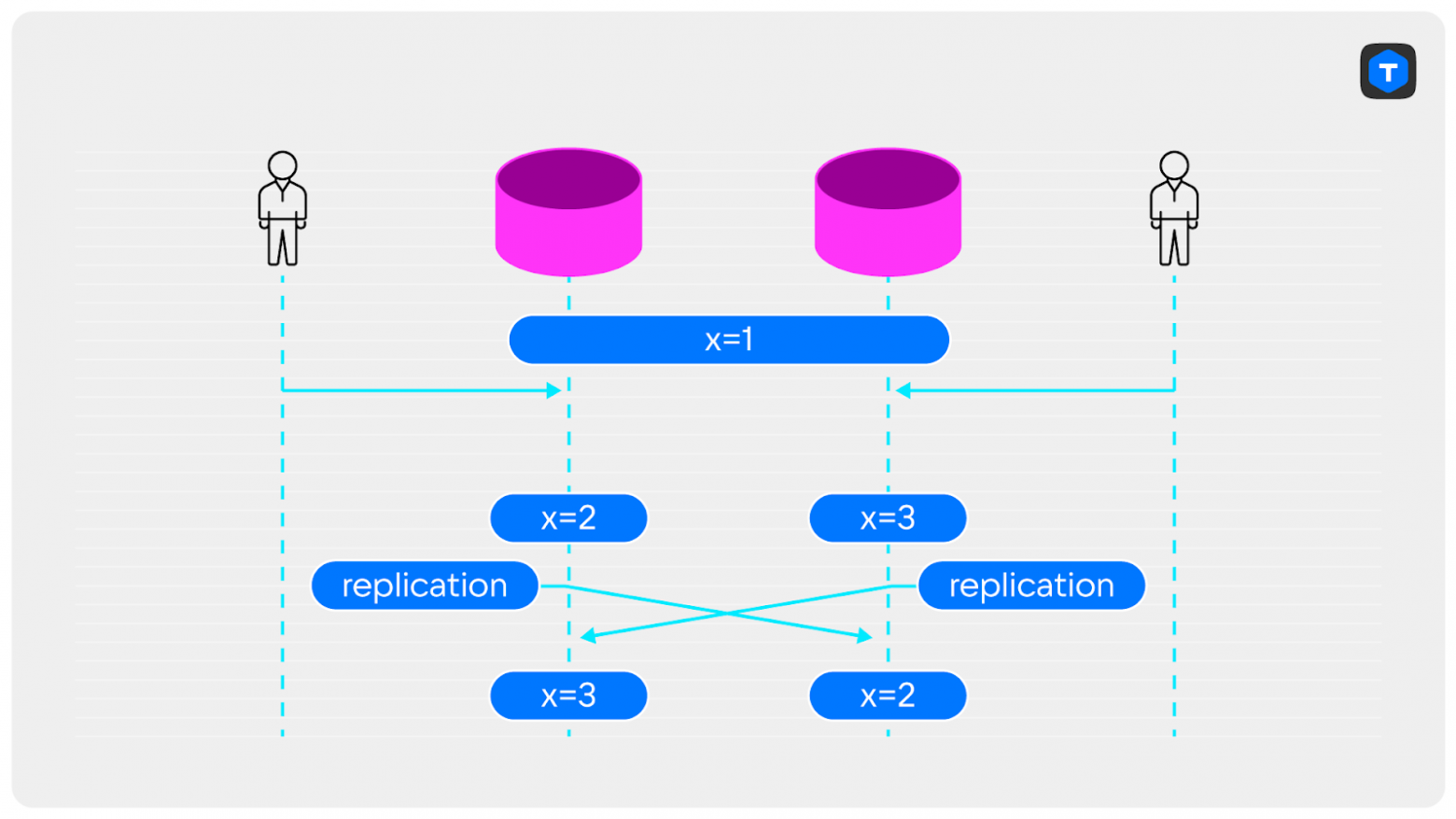
Как можно исправить?
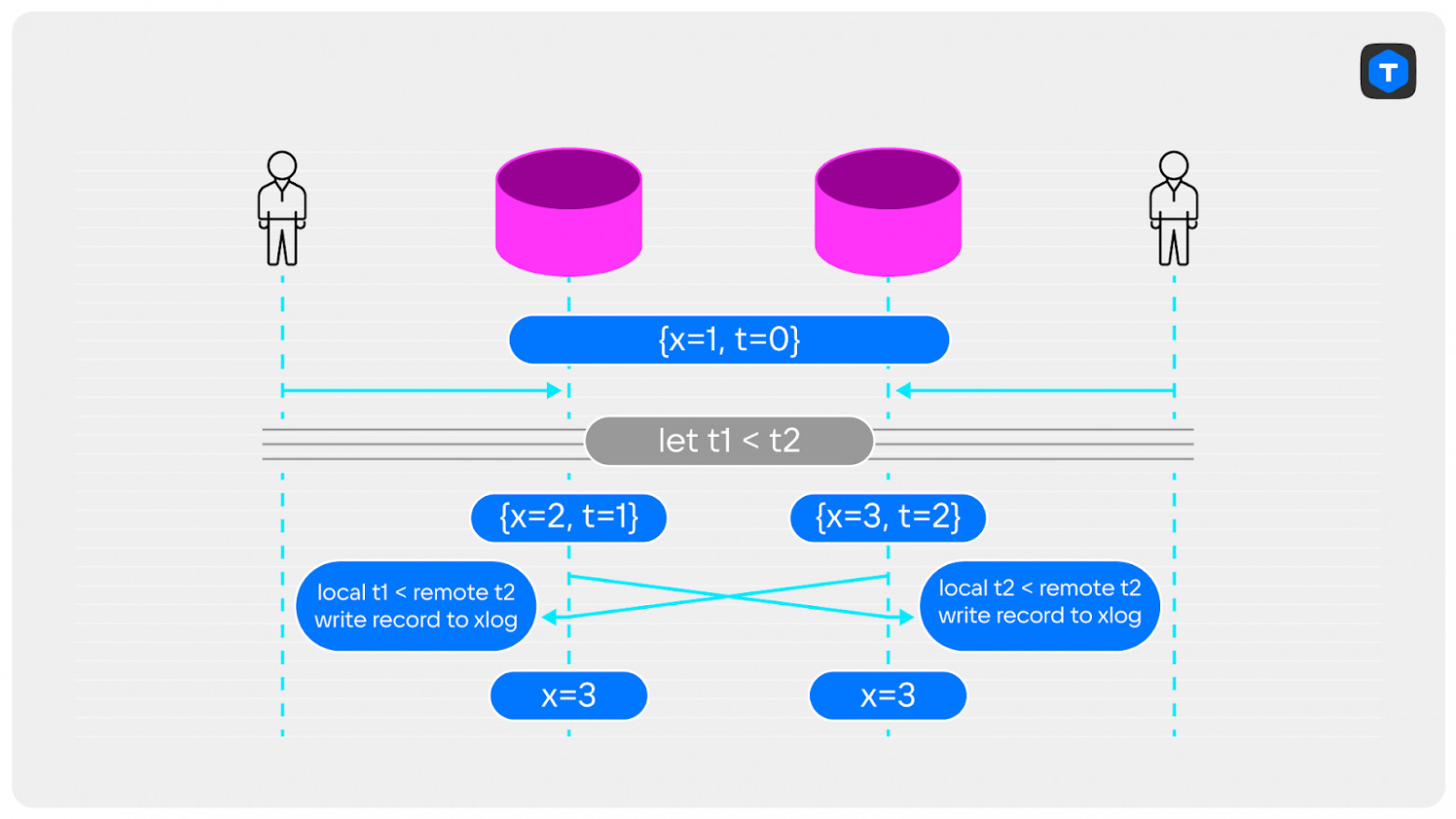
Например, заранее разделить нагрузку между узлами и отправлять данные в экземпляр в зависимости от их первичного ключа. Или, что надёжнее, написать триггер для разрешения конфликта, в котором будем выбирать из конфликтующих записей более подходящую для сохранения. Это может быть запись, которая была создана раньше; или последняя; или та, данные в которой важнее по какому-нибудь параметру.
local my_trigger = function(old, new, _, op)
if new == nil or old == nil then
return new
end
if op == 'INSERT' then
if new[2] > old[2] then
return box.tuple.new(new)
end
elseif new[2] > old[2] then
return new
end
return old
end
-- код для добавления триггера
-- позволит обрабатывать все записи,
-- начиная с момента восстановления из snapshot'а
box.ctl.on_schema_init(function()
box.space._space:on_replace(function(_, sp)
if sp.name == 'test' then
box.on_commit(function()
box.space.test:before_replace(my_trigger)
end)
end
end)
end)
Теперь в случае конфликта в WAL попадёт только одна запись:
Что почитать по теме:
Транзакции перед подключением к реплике
Представьте ситуацию: в кластере перезапускается мастер под нагрузкой, вы проверяете сохранение последних записей и видите, что на мастере и на реплике данные разные. Что произошло?
Например, могло случится следующее: во время перезапуска по какой-то причине удалились xlog-файлы с последними записями, и мастер разрешил запись данных до того, как синхронизировался с репликой. В него сразу же начали писаться данные, а затем по репликационному потоку прилетели старые записи, которые вызвали конфликт из-за совпадающих LSN.
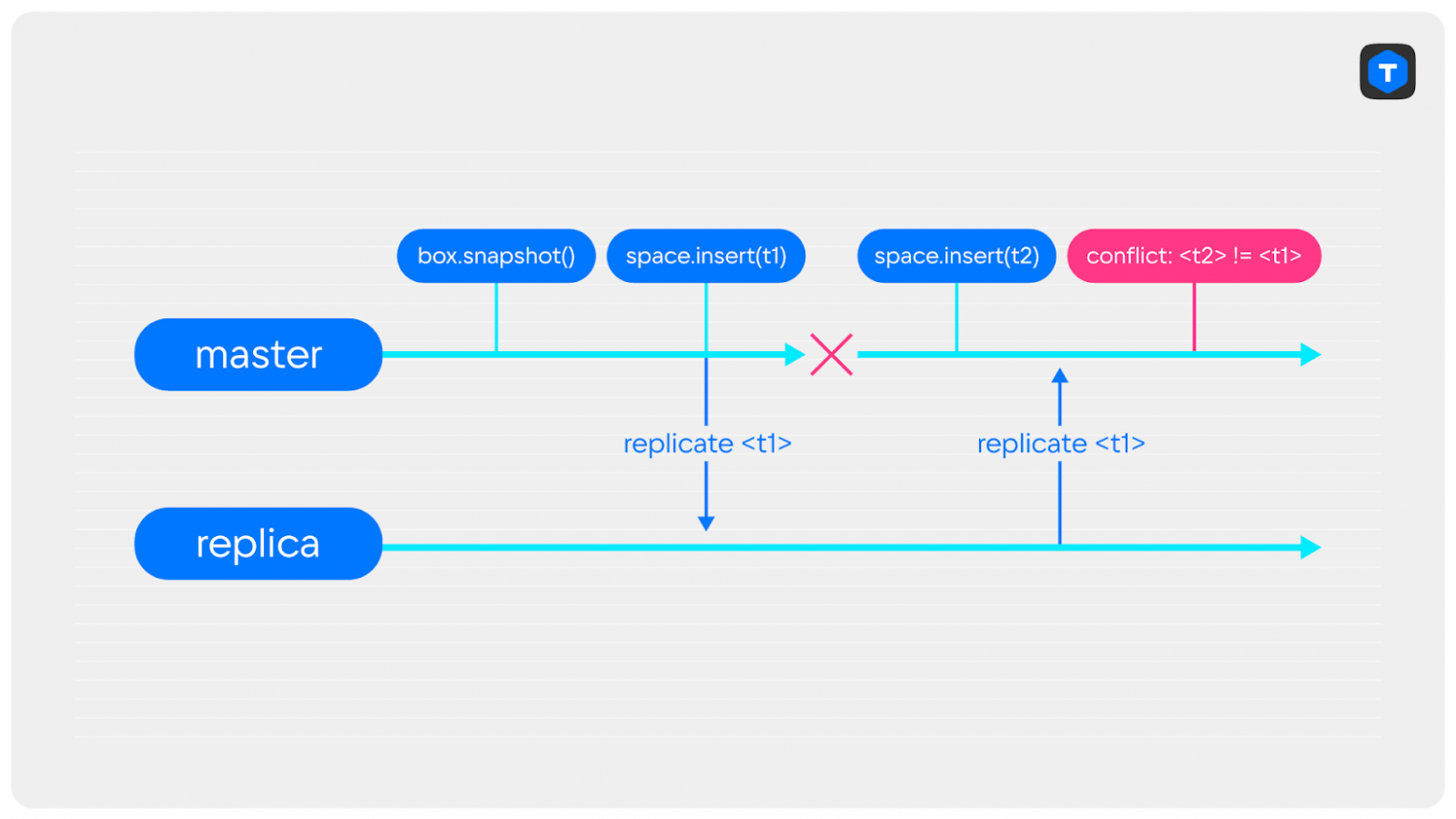
Как можно исправить? После перезапуска мастера необходимо дождаться подключения к реплике. В Tarantool за это отвечает опция box.cfg{replication_connect_quorum = N}, где N — количество реплик, к которым нужно подключиться перед разрешением записи. Чтобы не допустить проблем с началом записи до окончания синхронизации, в качестве N нужно выбрать количество всех узлов в наборе реплик.

Если нужно меньшее значение кворума, можете написать код, который запрещает запись до того, как значения box.info.vclock на всех узлах сойдутся.
Что почитать по теме
Как не допустить проблем
- Заранее закладывать расширение таблиц и кластера. Объём данных всегда будет расти, а кластеры — расширяться, и архитектура приложений должна это учитывать.
- При разработке держать в уме подводные камни. Писать код без багов пока никто не научился, но можно пытаться их минимизировать.
- Тщательно проводить нагрузочное тестирование, максимально приближенное к реальным условиям эксплуатации. Это позволит выявить очень много проблем.
- Грамотный мониторинг поможет обнаружить возникновение проблем и проанализировать их.
Что дальше
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
