Tinkoff: Cracking AI Research
Машинное обучение давно вышло за пределы академий и развивается семимильными шагами в индустриальных лабораториях благодаря широкой применимости. Используя машинное обучение и искусственный интеллект во многих бизнес-процессах компании, мы решили пойти дальше и показать не только world-level AI-продукты, но и world-level AI-исследования от Тинькофф.
Рассвет AI в Тинькофф
В ноябре 2020 Тинькофф объявил о создании Центра Технологий Искусственного Интеллекта, который объединил все, что связано с машинным обучением и искусственным интеллектом. А в январе 2021 в этом центре появился отдел исследований.
Отдел исследований отличается от привычных продуктовых команд. Он развивает темы и направления, которые важны для области в целом. Применимость этих решений не сиюминутная, ее можно увидеть только спустя какое-то время. Основная задача отдела — показать лидерство Тинькофф в развиваемых Центром областях искусственного интеллекта, которые каждый день используются в продуктах компании.
Если успех продукта измеряется прибыльностью, то успех исследовательского отдела — научными публикациями. Чем больше публикаций и чем крупнее конференции и журналы, в которых они были опубликованы, тем лучше. Для AI-исследований есть три крупнейшие конференции: NeurIPS, ICLR и ICML. Публикация на них — огромное достижение для любой исследовательской группы. В этом году у нас таких публикаций было целых две, о них мы сегодня и расскажем.
Showing Your Offline Reinforcement Learning Work: Online Evaluation Budget Matters
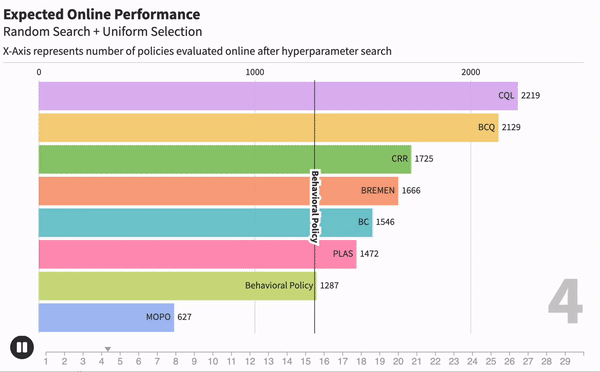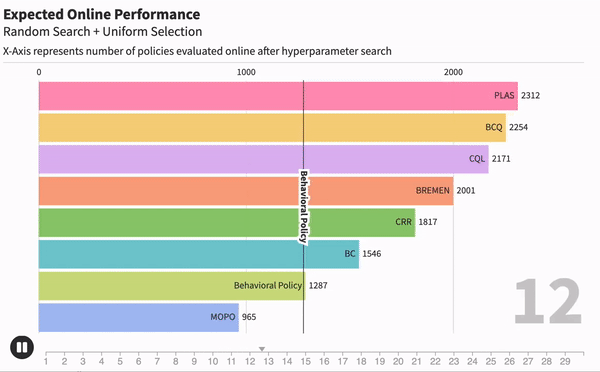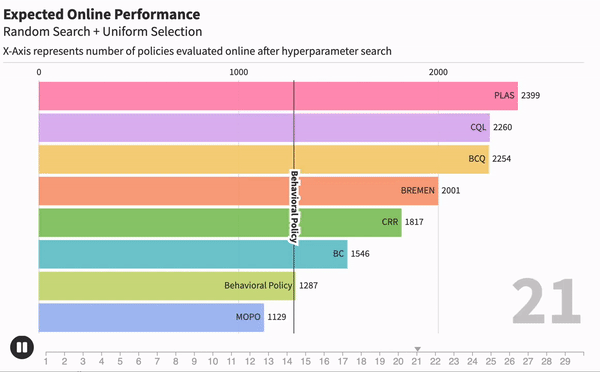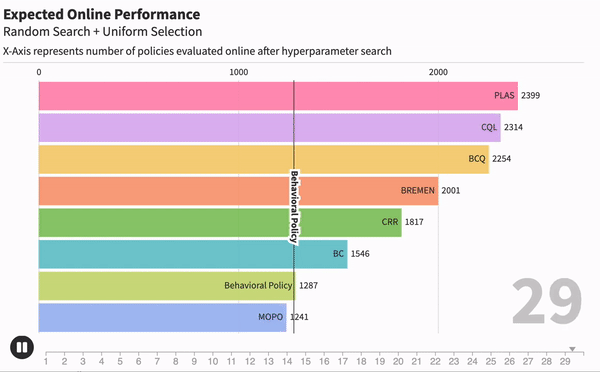
Когда мы занимаемся машинным обучением, очень важно понимать, насколько хорошо работает тот или иной метод. Для каждой модели могут существовать десятки метрик, которые оценивали бы ее. Например, возьмем модель текстовой классификации, чтобы находить негативные комментарии. Одной из метрик качества может быть точность работы — отношение правильных предсказаний ко всем сделанным предсказаниям.
Если рассуждения о том, как оценить саму модель, звучат достаточно понятно, то все становится сложнее, когда мы пытаемся оценить подход для обучения этой модели. Обученная модель — это результат комбинации множества выборов: можно использовать разные глубокие архитектуры, разные трюки при их обучении, разные способы подготовки данных и многое другое. Но как при таком разнообразии определить, что один подход лучше, чем другой?
Наивный подход к решению этой задачи заключается в том, чтобы взять метод к обучению модели, много раз изменить гипер-параметры обучения и сказать, что качество работы метода в целом равно качеству лучшей обученной модели. Такой подход широко используется в научных статьях, однако он имеет серьезный недостаток.
Рассмотрим два метода обучения: большую и сложную глубокую модель (А) и маленькую и примитивную модель (В). Если долго перебирать параметры для модели А, то в целом реально добиться качества лучше, чем у модели В. Значит ли это, что сложная и глубокая модель хуже? Не совсем.
Все дело в том, что оценивать качество подхода только по качеству лучшей обученной им модели неправильно. Возможно, то качество, которое было получено моделью А, на самом деле, получилось после короткого перебора параметров. Выбрали чуть ли не случайные параметры и модель заработала хорошо. В то время как для модели В пришлось перебирать десятки тысяч возможных комбинаций ее параметров.
В таком случае, думать о качестве метода как об «одной точке» становится неудобно. Намного лучше думать о нем как о функции, которая берет количество испробованных параметров и возвращает среднее качество модели, которого можно добиться, перебором.
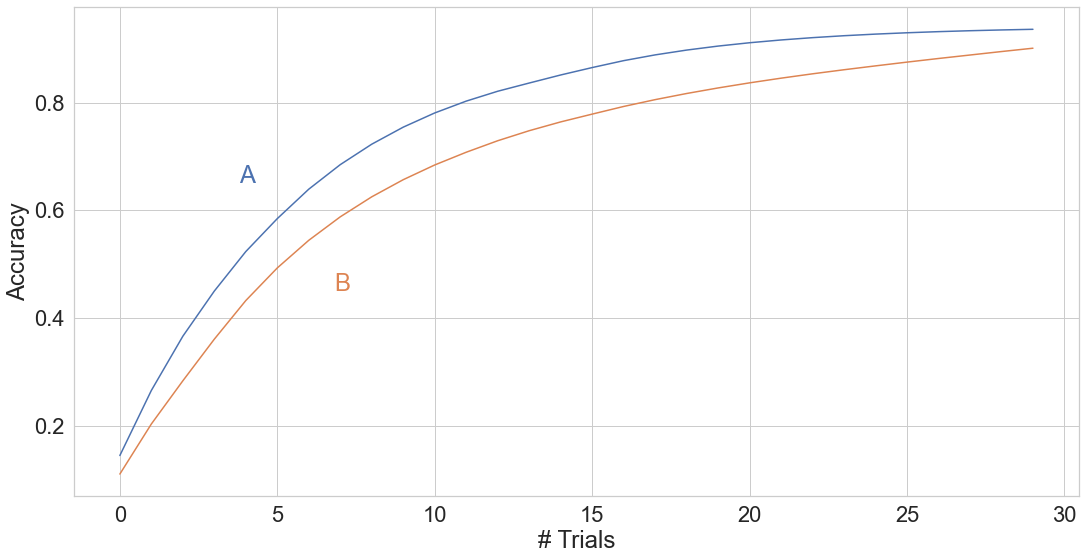
При таком подходе все становится на свои места: исходные две точки, которые мы сравнивали, — это модель А с маленьким числом испробованных параметров, и В, для которой мы перебрали множество параметров. Получается, что большая модель для любого возможного числа переборов работает лучше, чем маленькая.
Такой взгляд на качество метода обучения можно изменять и адаптировать под свои нужды. Например, строить такие функции в зависимости не от количества параметров, а от времени, необходимого для того, чтобы добиться определенного качества. Можно представить себе случаи, когда один подход очень быстро достигает хорошей точности, когда другому нужны недели. Зато после недель работы второй подход покажет результат, недостижимый для других методов. Если фатально важно качество, можно выбрать второй подход и подождать эти недели. Если времени ждать нет, то первый.
Мы пошли дальше в адаптации этого подхода за пределы привычного Supervised Learning, и предложили его аналог в горячей области Offline Reinforcement Learning. В научной литературе Offline RL страдает примерно тем же, о чем мы написали выше: исследователи репортят числа лучших обученных моделей.
Чтобы измерить качество модели после офлайн-обучения, нам придется отправить эту модель в онлайн. Грубо говоря, если бы наш Offline RL алгоритм лечил людей, то мы должны были бы отправить его полечить парочку реальных пациентов и проверить, выздоровеют ли они. А потому качество лучшей модели напрямую зависит от количества RL- агентов, которых мы отправили бы в реальный мир.
Получается, что те числа, которые репортили другие исследователи, явно зависели от количества агентов, которых они испытали после обучения. Но каждый испытывал их разное количество раз. Чтобы исправить это, мы предложили новый метод оценки Offline RL алгоритмов, который оценивает качество агента от количества перебранных гипер-параметров.
Использование нашего метода позволяет исследователям более точно и обширно представлять результаты новых алгоритмов, а значит, помогает делать более надежные выводы о том, какой из алгоритмов стоит выбрать в той или иной ситуации.
PALBERT: Teaching ALBERT to Ponder

Обработка текстов была одной из первых областей глубокого обучения, в которую пришли огромные модели. Оказалось, что единственным ограничением для их роста, были вычислительные ресурсы: если у нас достаточно видеокарт для обучения и использования на практике, ничего не мешает увеличивать масштаб моделей.
В свое время этот факт был достаточно неочевидным. Конвенциональной считалась позиция, что при достижении относительно небольших, по меркам современных моделей, масштабов модели начнут переобучаться. А значит, модели будут хорошо работать на тех данных, которые использовались для их обучения, но ошибаться на новых данных, которые модель раньше не видела.
С ростом NLP-моделей пришлось активно думать о том, как жить в новом мире, в котором почти наверняка придется работать с моделью, у которой сотни миллионов (если не сотни миллиардов) параметров. И пока модели с каждым годом экспоненциально увеличивались в размерах, количество вычислительных ресурсов не сильно менялось.
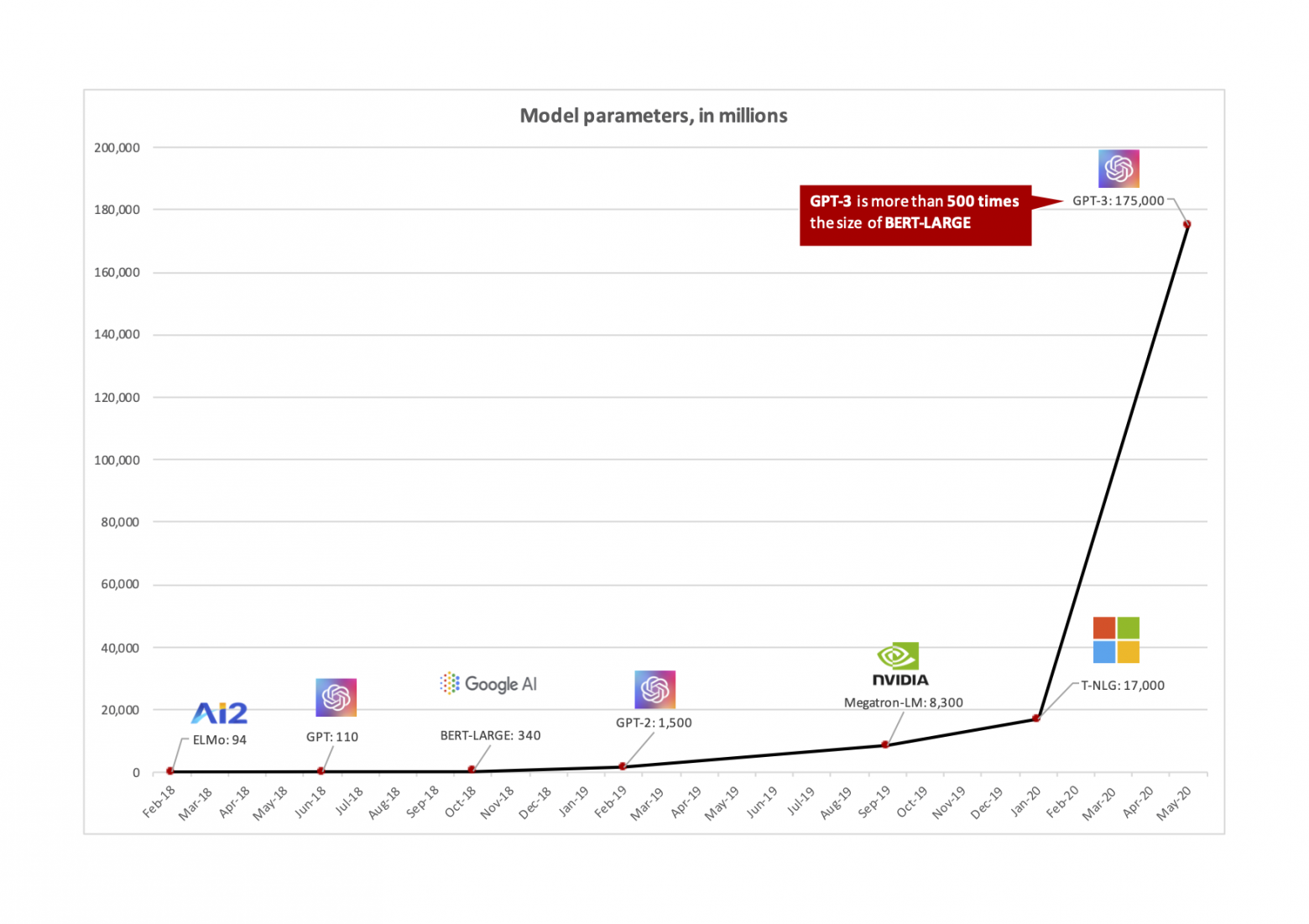
Чтобы разрешить это несоответствие, исследователи двигались в разных направлениях. Кто-то работал над более эффективным форматом представления весов модели, чтобы уменьшить их итоговый вес. Например, вместо 32 бит на хранение каждого из параметров тратить всего 8. Другие же думали о том, как организовать процесс обучения моделей таким образом, чтобы лучше утилизировать те скромные вычислительные ресурсы, которые были доступны большинству исследователей.
Мы задумались о том, как такие большие модели впоследствии использовать на практике. Дело в том, что многие NLP-модели имеют явную блочную структуру. Чтобы посчитать результат ее работы, нужно последовательно посчитать результат работы, скажем, 40 блоков. Уже давно исследователи думают, как сделать такие модели, в которых можно адаптивно считать меньшее число слоев/блоков, чем изначально было заложено.
Например, мы хотим детектировать комментарии с оскорблениями. Можно легко представить такие комментарии, над которыми не нужно особо думать, чтобы решить, оскорбительные они или нет. Аналогично можно представить случаи, когда стоит потратить чуть больше времени, чтобы принять окончательное решение. Такой взгляд явно проецируется на глубокие модели: на простые примеры стоит считать меньшее число слоев, в то время как на сложные — большее.
Можно придумать разные техники, чтобы обучать такие модели. Достаточно популярным стал консенсусный метод. Если у обычной модели есть блок классификатора только после последнего слоя, то в консенсусных методах такой классификатор ставился после каждого из блоков модели. Каждый из этих классификаторов в итоге обучался решать изначальную задачу.
В таком случае из модели, у которой было бы 40 слоев, на самом деле обучается 40 моделей, у первой из которых был бы один слой, у второй — два и так далее. Когда мы хотим получить предсказание, то можем считать результат классификации после каждого из блоков. А еще можно добавить эвристику о том, что, если заранее определенное количество классификаторов (например, шесть) выдают один и тот же результат, то модель «решила», какое предсказание она готова дать, и вычисления можно не продолжать.
Такой подход легко реализовать на практике, но у него есть серьезные недостатки: далеко не всегда модель оперирует простыми блоками для классификации, иногда после каждого слоя классификатор может применяться разнообразными способами. Например, после каждого из слоев у нас может быть произвольное количество предсказаний классификатора. Как в таком случае принимать решение о консенсусе?
Конечно, можно придумать эзотерические способы реализовать консенсус и для таких ситуаций, но мы решили пойти альтернативным путем. Вместо того, чтобы надеяться на то, что несколько классификаторов в ряд дадут нам одинаковое предсказание, можно добавить к классификатору после каждого из слоев дополнительный блок, который в оригинальной статье DeepMind называл «лямбда-слоем». Задача лямбда-слоя заключается в том, чтобы предсказать вероятность того, что текущий слой должен стать последним. Используя хитрые методы для обучения, можно получить модель, которая будет явно говорить нам о том, что готова выдать результат заранее.
Сложность, с которой мы столкнулись, заключалась в том, что понять «язык» модели было не совсем тривиальной задачей. Изначально в методе авторы предлагали подбрасывать монетку во время каждого из вычислений слоев с той вероятностью, которую выдал лямбда-слой. Грубо говоря, если после первого слоя модель считает, что ей стоит остановиться с вероятностью 10%, в 1 случае из 10 мы остановим вычисления, а в 9 — продолжим.
С одной стороны, такой подход интуитивно понятен, с другой — вносит огромную неопределенность в том, как хорошо будет работать наша модель. Возвращаясь к 10% на выход, можно задаться вопросом: много это или мало? Кажется, что достаточно мало, но 10% есть 10%. Это значит, что если бы у нас было 1000 текстов, в которых бы мы столкнулись с таким предсказанием, то на 100 из них модель бы думала о них совсем мало. А такая же неопределенность возникает и на следующих слоях.
Чтобы обойти этот недостаток, мы сделали, с одной стороны, достаточно очевидный, а с другой — совершенно необоснованный трюк. Мы стали суммировать вероятности выхода с каждого слоя по ходу вычисления модели. Если первый слой выдал нам 10%, второй — 15%, а третий — 40%, то у нас была бы уверенность 10% для первого слоя, 25% для второго и 65% для третьего. В тот момент, когда эта уверенность достигала заранее определенного значения, мы заставляли модель остановить вычисления. В нашем случае нашли, что лучше всего работала граница в 50%.
Такой подход позволил:
Улучшить не только исходную модель, которая бы принимала случайное решение, но даже улучшить результат, которого достигают консенсусные модели.
Расширить границы методов для раннего выхода. Из-за того, что в этом подходе мы не пытаемся интерпретировать предсказания классификаторов для принятия решения, его можно использовать для произвольных архитектур и задач.
Вместо итогов: восход AI в Тинькофф
Несмотря на кажущуюся простоту, рассмотренные выше работы — это наши первые значимые и подтвержденные успехи в области исследований искусственного интеллекта, а не запусков AI-based продуктов от Тинькофф. Следуя стратегии AI-First Fintech, мы наращиваем теперь уже и академическую экспертизу в AI через отдел исследований и расширяем возможности AI в используемых нами областях.
Еще больше выступлений, ивентов и семинаров про ML/AI от Тинькофф доступно на нашем ютуб-канале. Если же вам интересно следить за жизнью Центра здесь и сейчас — присоединяйтесь в Желтый AI. А нам этом все, stay tuned!
