The Metrix has you…
Для многих разработчиков процесс релиза их продукта похож на выбрасывание слепого котёнка в пасти диких псов. После этого главная задача авторов — отбиваться от случайно долетевших до них багов. На самом деле, приложение не заканчивает свой жизненный путь в зубах пользователей, а только начинает его. И ему нужна помощь разработчиков не меньше, чем во время становления и тестирования.
В этой статье мы рассмотрим, каким образом можно наблюдать за работой продукта и его боевым окружением, научимся собирать жизненно необходимые метрики и представлять их в удобоваримом виде. Узнаем, что такое Time Series и как они могут помочь нашим и сторонним приложениям в процессе диагностики. Подробно познакомимся с лидерами рынка инструментов для мониторинга, специализированным хранилищем InfluxDB и системой визуализации данных Grafana.
Прототипом статьи является доклад Анатолия Кулакова на DotNext 2017 Moscow. Анатолий получал образование специалиста по информационной безопасности, затем зарабатывал как суровый C++ разработчик под Linux. Когда надоело кодировать и захотелось творить, перешёл на C#. Пишет на .NET с первых его версий. Занимается проектированием и построением бизнес-приложений, распределённых и отказоустойчивых систем. Отдыхает с ES, CQRS и DDD.
Перед просмотром можно загрузить слайды в формате PDF.
Осторожно, трафик! В этом посте присутствует огромное количество картинок — слайдов и скриншотов с видео в формате 720p. На слайдах присутствует важный для понимания статьи код.
Поговорим о метриках. Почему именно о них? Дело в том, что в своей практике я сталкивался со множеством проектов, и меня всегда возмущала ситуация, что большинство команд даже не задумываются о том, что сейчас творится на их продакшне. Они просто выпустили продукт, и, по их мнению, он летит. В реальности это совсем не так, сервер может захлебываться от наплыва пользователей, могут отказывать диски, может твориться всё, что угодно. И, в большинстве случаев, об этом никто не подозревает и не знает.
К сожалению, таким образом сложилась наша культура разработчиков, что для нас главным моментом является именно процесс написание кода. Но это всего лишь маленькая часть живого продукта, поэтому со временем эта тенденция меняется, чему я весьма рад. Мы уже знаем такие страшные ругательные слова, как CI и DI, они уже не вызывают дрожь в коленках. Мы привыкли, что системы контроля версий, ведения задач, процесс планирования и тестирования являются неотъемлемой частью современного проекта.
Следующим большим шагом в данном направлении является выход за периметр своей уютной команды и нанесение добра на территории непосредственного пользователя. И это очень интересный процесс, ведь почти всегда пользователи не ведут себя с нашими программами так, как мы планировали, и обычно наши программы не готовы к тому безумству идей, на которые способны эти гении мысли. Поэтому после того, как мы начинали наблюдать за реальным использованием наших продуктов, мы обязательно открывали для себя большой интересный и увлекательный мир, полный безумия и непредсказуемости. Оказывалось что все наши оптимизации не использовались из-за случайной нелепицы, основная нагрузка приходится не на тот сервис, на который мы рассчитывали, злобные админы искусственно ограничивают ресурсы для нашего приложения, лоад балансер распределяет запросы неравномерно и т.д. Огромное количество непредсказуемых ситуаций подбрасывает нам жизнь.
Большинство из них оседают в раскаленной психике уставших пользователей. Остальные оформляются в невнятных багах, описывающих результат, по которому совершенно невозможно понять причины происшедшего. Гораздо лучше с любой стороны иметь постоянный мониторинг важных сервисов в реальном времени и понимать, чем они сейчас занимаются.
Мониторинг способен не только поведать вам о проблемах и нагрузках, он также является прекрасной площадкой для аналитики и предсказаний. Именно этим мы с вами и займемся. Разберемся, как и какими средствами можно реализовать абсолютно любые ваши вуайристические фантазии.
Я уверен, что когда я описывал суть проблемы, многие подумали о логировании. Действительно, можно удалённо собрать логи, проанализировать их и сделать выводы, а что же там такое творится на этом вашем продакшне. И это недалеко от истины. На самом деле, это родственные инструменты, которые решают схожие задачи. Если вам интересно послушать введение о правильном современном логировании, то рекомендую обратить внимание на доклад «Structured logging».
Но в этой статье мы сфокусируемся именно на метриках. Чем же отличаются метрики и логирование? Итак, основное содержимое логов — это любая информация об окружающем мире, бизнес-процессе, ожиданиях и ошибках. Если вы знаете, как готовить их правильно, то без труда сделаете аналитику по их содержимому. Но существует огромный пласт задач, в котором гибкость и мощь логирования являются избыточным явлением, и даже больше — вредят.

Например, вам хочется постоянно наблюдать за загрузкой процессора. Конечно, можно эту информацию каждую секунду записывать в логи, а потом анализировать. Но тут мы сталкиваемся с целым рядом проблем, основные из которых — это объём данных и скорость их обработки. Количество счётчиков, за которыми мы захотим наблюдать, легко начинается с десятков (процессор, память, GC, запросы, ответы). А в крупных проектах без особых усилий доходит до сотен.

Представьте, что у вас есть двести хостов, и они снимают по сто метрик каждые десять секунд. При условии того, что у нас в сутках 86 400 секунд, мы ежедневно будем получать в своих логах 172 800 000 значений.
Только представьте, во что превратятся ваши логи, если каждую секунду вы будете сливать в них тысячи метрик с низкоуровневой, безликой, неинтересной информацией. Во-первых, от логов всё-таки ожидается челове-читабельность и логичность повествования, а не гора инфраструктурного шума. Но эта проблема легко решается с помощью семантических фильтров. А вот тот размер информации, который теперь обязаны обрабатывать инструменты, создававшиеся с другими целями, — это уже проблема. Проблемы с производительностью будут на всех уровнях: в обработке, передаче, хранении, аналитике. И это чистая обыденность, существует куча других областей с несоизмеримо большими аппетитами, таких как: атомные станции, заводы, или, например, интернет вещей, где, по заявлениям бородатых аналитиков, к 2020-му году на каждого человека будет приходиться по шесть устройств, которые нужно будет постоянно мониторить.

И если мы говорим об абсолютном объёме, то размер данных, необходимых для работы с метриками, сильно превышает размер обычных логов. Всё это наводит на мысль, что нельзя для логов и метрик использовать одни и те же решения. Поэтому человечество выделило из логов такое понятие, как метрики. И разделило работу с этими данными на две независимые части, со своими инструментами, алгоритмами и подходами. И, как показывает тенденция последних 2-х лет, решение было абсолютно верным.
Если вы когда-либо слышали о росте популярности графовых или документо-ориентированных баз данных, всё это — детский лепет по сравнению с тем хайпом, который происходит вокруг баз данных для метрик. Метрики описываются временными рядами (Time Series). Временной ряд — это последовательность некоторых значений, взятых из одного источника через определённый интервал времени. Т.е. это результаты периодических измерений чего-либо во времени. Например, этот график представляет собой результаты периодических измерений популярности баз данных, сгруппированных по модели хранения:
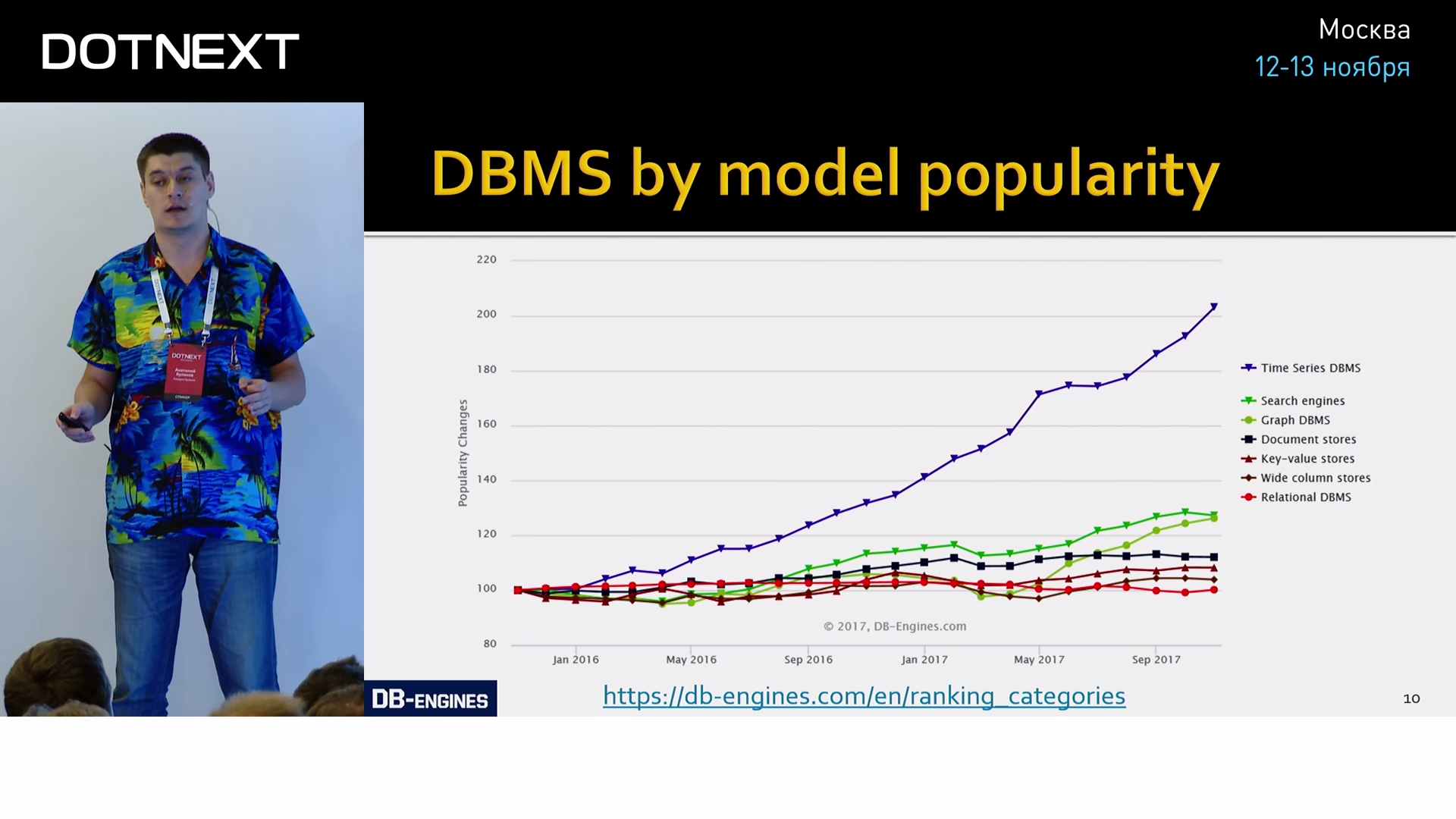
Типичным показателем того, что этот график относится к Time Series, — это наличие оси времени. Если она есть, то почти всегда график — TS. Для подтверждения давайте посмотрим другие примеры:
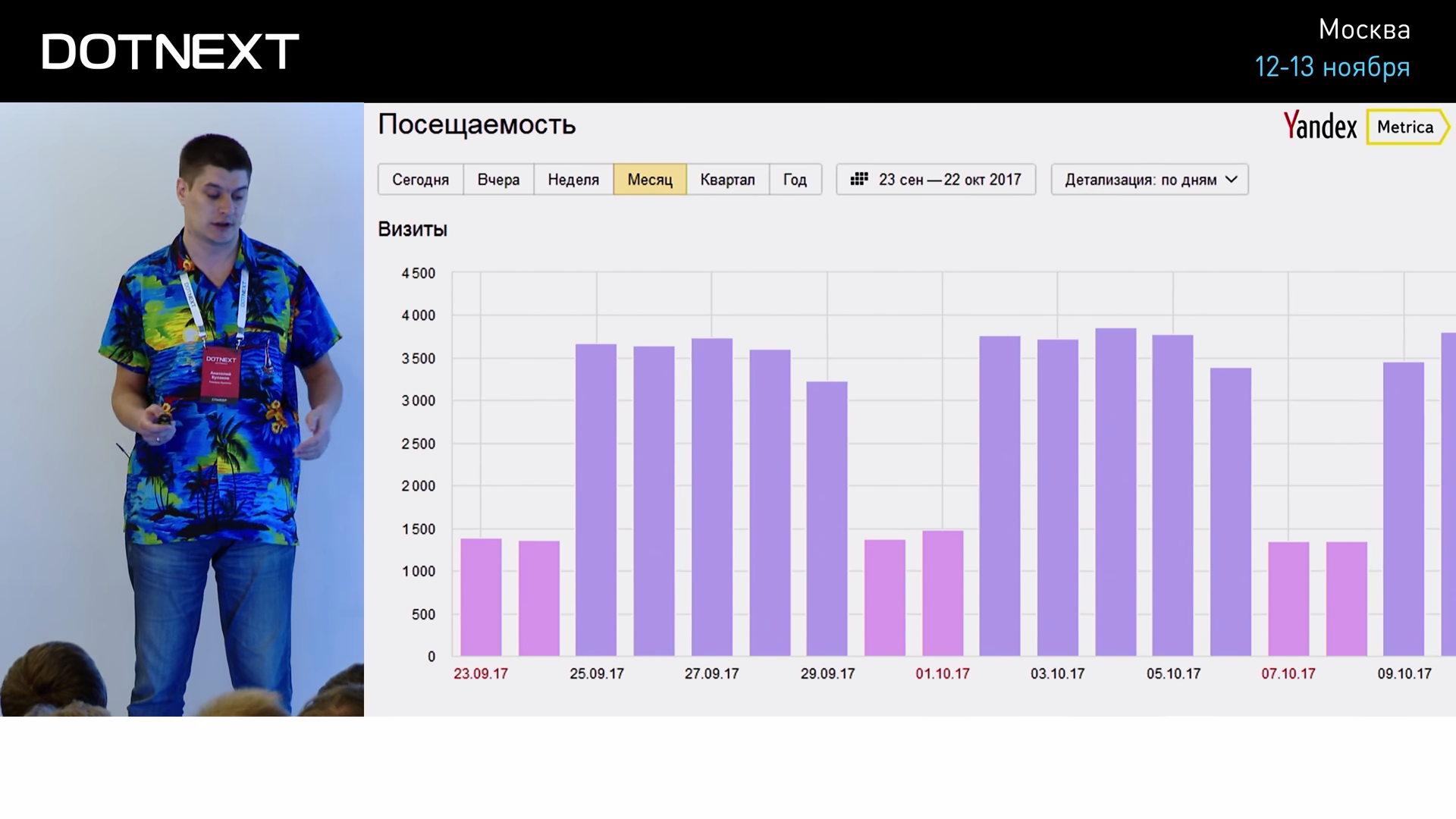
Еще один типичный пример — Яндекс.Метрика, которая показывает посещаемость вашего сайта.
Давайте разберемся подробнее, из чего состоят временные ряды на примере сетевого интерфейса:

- Прежде всего, это, конечно же, время, в которое считываются значения.
- Сами значения. Значений может быть несколько, в данном случае это количество пришедших/ушедших пакетов.
- Также бывает очень полезно к вашему значению добавить мета-информацию, описывающую, в каком контексте происходило действие. Для этого существуют теги. Им можно присвоить всё, что угодно, например имя хоста или сетевого интерфейса, на котором мы делали измерение.
Если проводить аналогию с реляционными базами данных, то совокупность всех этих трёх параметров можно представить в виде таблицы «Network».

В таком случае, время всегда будет её главным ключом, кластерным индексом. Теги будут индексированными колонками, по ним очень хорошо строятся агрегаты и делаются фильтры. Сами значения — это неиндексированные колонки.
Но, в отличие от баз данных общего пользования, TSDB обладают уникальной информацией — они знают о природе этих данных, что позволяет им делать неимоверные оптимизации. Именно поэтому базы данных общего пользования всегда будут оставаться далеко-далеко позади. Например, между авторами Time Series баз существует интересная метрика, с помощью которой они меряются между собой в размерах собственного превосходства: средний размер, необходимый для хранения одной записи. Давайте сходу прикинем:

Дата и время хранятся обычно в наносекундах, занимают восемь байт. Теги могут легко перевалить за 20 байт, и поле данных, допустим double (самый распространенный тип для значений, которые хранятся в TSDB), занимает восемь байт. Ну вот если хранить так бесхитростно, то одна запись у нас будет занимать около 40 байт. Как вы думаете, какими цифрами хвастаются лидеры? Два байта.

Всего-навсего два байта, чтобы упаковать все наши значения. И это не предел, лучшие сражаются в районе одного байта. Каким образом такое вообще возможно? Как, зная специфику происхождения данных, можно всё это уложить в два байта?
Первое, что приходит на ум, — это использование стандартных алгоритмов сжатия. Обычно это плохая идея, потому что они создавались для совершенно других объемов информации, и они требуют для своей работы контекст намного больше, чем мы можем себе позволить. Ну и работают они в 30–40 раз медленнее.
Мы пойдём другим путём. Начнём с тегов. Их размер в постоянном потоке данных можно уменьшить до нуля. Каким образом это делается? Мы просто перемножаем имя метрики со всеми ключами и значениями тегов и получаем несколько слотов хранения (в примере два):

Таким образом, мы переносим теги из области данных в область схемы. Именно поэтому значения тегов не должно быть представлено случайными числами, а должно укладываться в конечный словарь. Эта часть временных рядов называется «Серией». Серия сама по себе не хранит никаких данных, она постоянна во времени, что позволяет просто пренебречь её размерами. Таким образом теги у нас схлопываются в ноль.
Если серия не занимает место, то его занимают метка времени и значение. Начнем со времени. Все алгоритмы сжатия, которые работают над Time Series, основываются на том же принципе, что и колоночные БД. Они работают с одной колонкой, с непрерывным потоком однотипных данных. Время обычно хранится с точностью до наносекунд. В 8 байтах. Для сжатия колонки со временем можно применить Delta-of-delta compression. Это алгоритм, который рассчитывает на то, что данные со счётчиков обычно снимаются периодически через равные интервалы времени. Например, через каждые 5 секунд. Мы можем вычислить дельту между этими временами и найти интервал. Имея начальное время и интервал, мы может предсказать следующее значение в колонке.
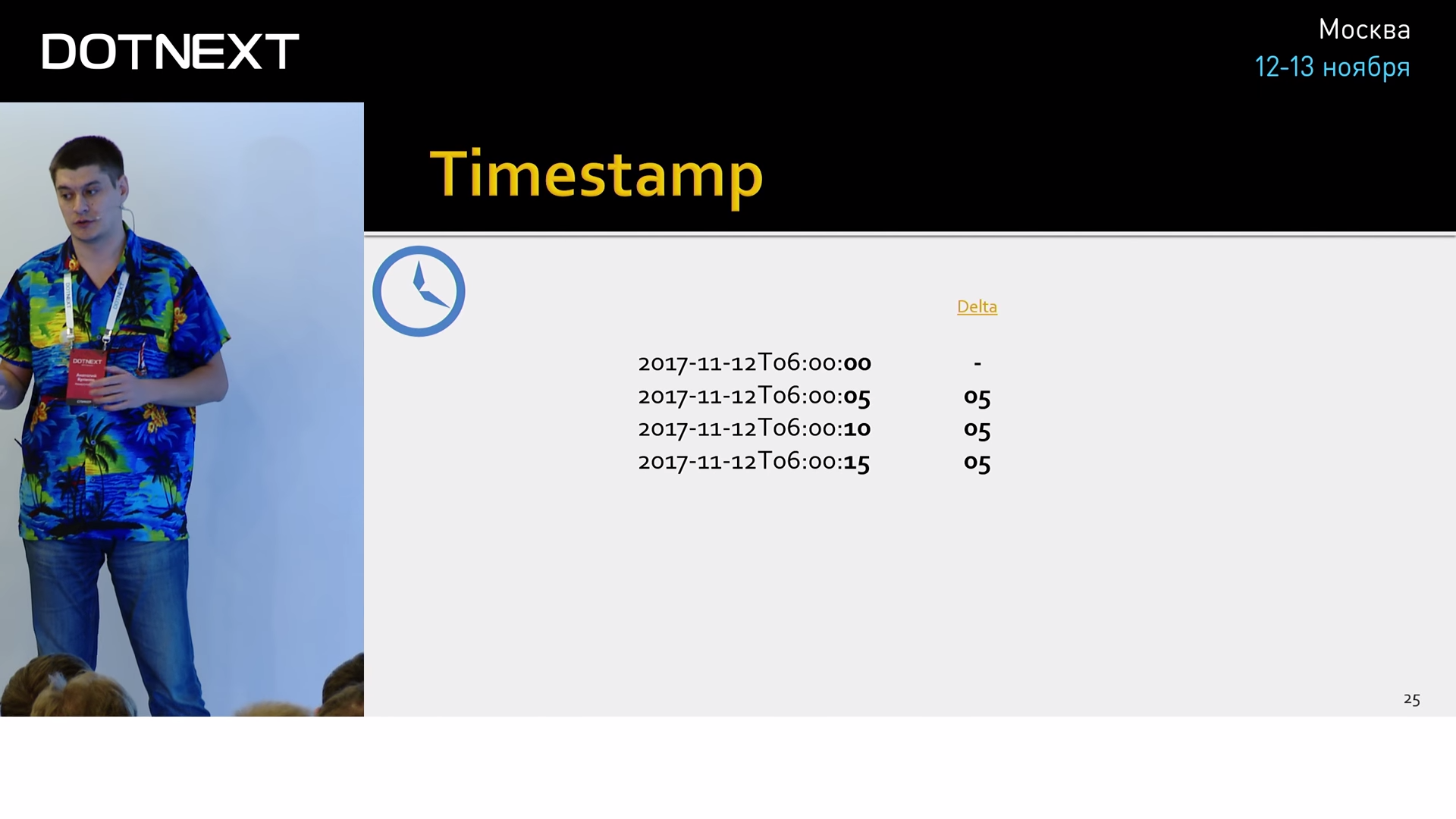
Обычно интервал не изменяется, поэтому мы можем вычислить ещё раз дельту над значением первой дельты. И обычно получается ноль. Для хранение такого специального, часто встречающегося значения достаточно одного бита (ноль у нас во второй дельте или не ноль).

Не думайте, что это слишком большие допущения и в реальном мире такого нет. По данным Facebook, они смогли упаковать 96% всех своих времён в этот один нулевой бит. Естественно, есть алгоритмы устранения небольших дребезжаний времени, пропусков и т.д.

Значения счётчиков могут быть произвольного типа. Но на практике это почти всегда числа с плавающей точкой. Именно на них нацелена основная магия по уменьшению размера полей.
Значения могут быть разбросаны непредсказуемо, поэтому предыдущий трюк с двойной дельтой тут уже не пройдёт. Другой приём основывается на том знании, что все значения приходят от одного источника, а значит имеют одинаковую точность и похожую размерность. На практике это значит, что их бинарное представление будет весьма схожим. Т.е. если мы банально заксорим соседнии значения, мы получим весьма небольшое число значащих символов:
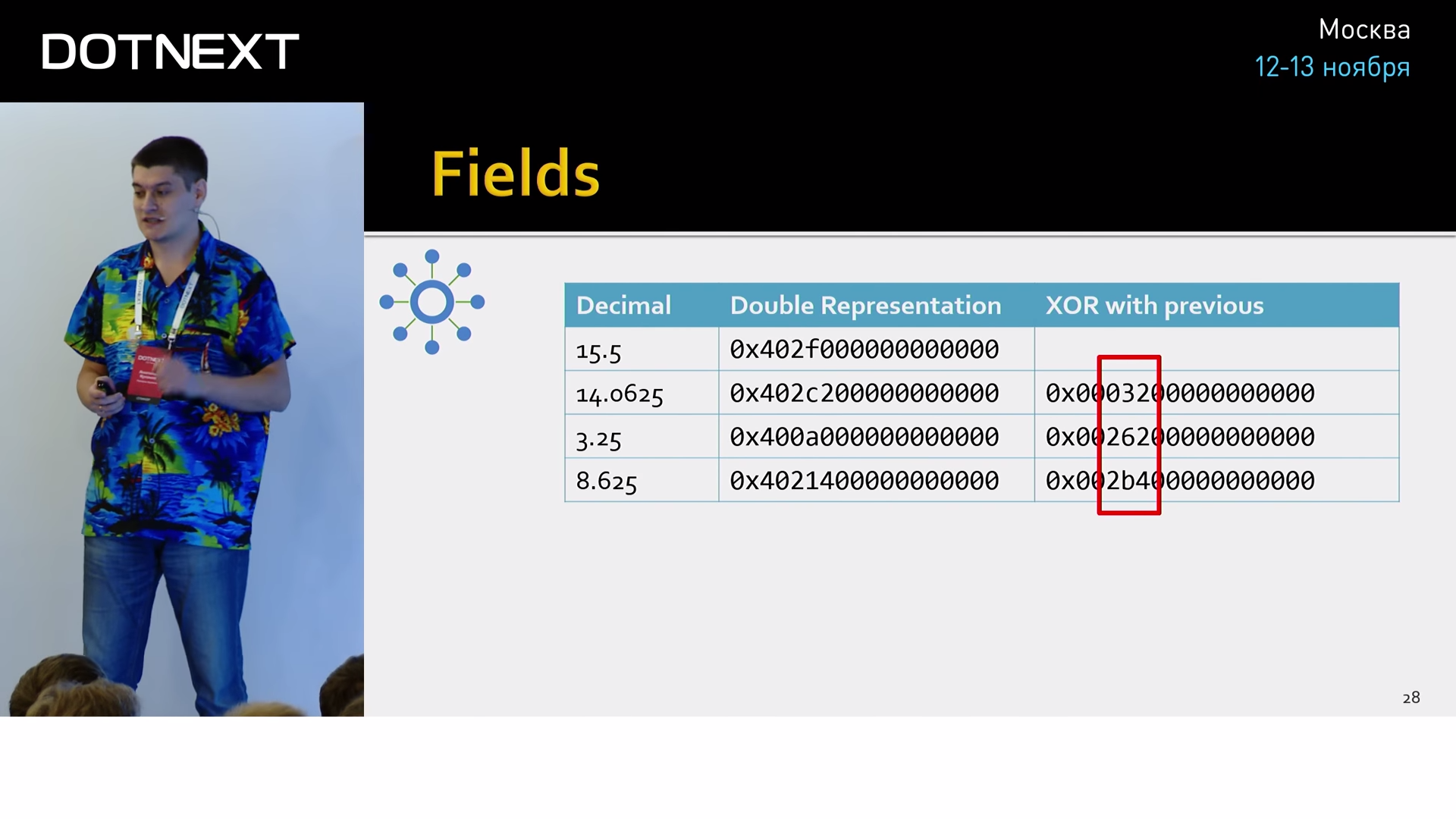
Его можно сохранить, используя куда меньшее количество бит, чем оригинальное значение. И рядом с ним сохранить количество ноликов с наименьшей стороны. Но на практике всё ещё веселее. По статистике Facebook, 51% всех значений совпадают с предыдущим, т.е. их XOR даст ноль.

И как вы, наверное, догадались, для хранения этого специального случая достаточно одного бита. И это ещё не всё, XOR в данном примере — это лишь самый банальный предсказатель. Существуют другие предсказатели, которые динамически подстраиваются под ваши текущие данные и таким образом способны предсказывать значения с очень высокой вероятностью, что в результате позволяет упаковывать в 1 бит даже весьма нетривиальные колебания.
Соответственно, если данные будут приходить с одним и тем же интервалом и никогда не будут меняться, мы можем упаковать это в два бита. Конечно, в реальном мире так не происходит, и на практике данные изменяются, что заставляет Facebook тратит 1.37 байт на одно значение. И это всего лишь при помощи тех примитивных алгоритмов, которые мы сейчас рассмотрели.
Это довольно интересные алгоритмы, про них можно говорить часами, но давайте вернемся с небес на землю и посмотрим на наше приложение и его окружение.

- Для нашего приложения важны, прежде всего, метрики, из-за которых оно способно работать. То есть, hardware, операционная система. Источником этих метрик выступают Performance Counters. В них вы найдете кучу полезной информации, начиная от CPU, места на диске, памяти и заканчивая более высокоуровневыми платформами, такими как: .NET, Garbage Collector, JIT, IIS, SignalR и так далее.

- Еще обычно существуют третьесторонние компоненты, с которыми мы взаимодействуем. И у всех нормальных третьесторонних игроков обязательно есть API статистики, которые мы можем вычитать: Seq, MongoDB, MS SQL — все эти продукты имеют такой API, при помощи которого вы можете прийти, запросить их состояние и посмотреть, например, как они себя сейчас чувствуют.

- Также не будем забывать про наши любимые ETW, там тоже много всего интересного, если вдруг вы не нашли в первых пунктах того, что искали, обратитесь к ним.
- И самые главные, самые высокоуровневые метрики, которые у нас есть — это, конечно же, метрики нашего собственного приложения, вашего бизнес-домена. Какого размера документ открывает пользователь, сколько пользователей залогинилось, среднее время бизнес-транзакции — вот это всё.
Как вы видите, источников информации довольно-таки много, и неудивительно, что существуют специальные программные средства, которые позволяют вам удобно собирать эту информацию, агрегировать ее и сохранять. Одно из таких средств — это агент Telegraf. В стандартную его поставку входят более сотни плагинов для мониторинга широкого спектра популярных программ. Системные счётчики, популярные базы данных, веб-серверы, очереди и ещё куча всего.

Большое сообщество, гибкие настройки, отличная система плагинов делают этот инструмент незаменимым помощником в мониторинге. Telegraf способен не просто собирать информацию из разных источников и форматов, а также способен обрабатывать и агрегировать её на клиенте, что может сильно уменьшить объём и нагрузку на центральный сервер.
Давайте посмотрим на практике, каким образом работает Telegraf. Начнем, как ни странно, с Grafana.
Я специально не упоминал Grafana до этого момента, чтобы вы поняли, насколько низок в неё порог входа. Всё, что вам нужно знать: Grafana — это графический веб-интерфейс, который способен визуализировать временные ряды из TSDB. У Grafana есть хранилище, в котором содержится много различных плагинов, готовых дашбордов для существующих популярных систем, разных data source и так далее, одним из них мы сейчас воспользуемся.
Найдем дашборд, который называется Influx Windows Host Overview, он нужен как раз для того, чтобы сделать дашборд для Telegraf под Windows.

Этот дашборд состоит из двух частей: первая — настройки самого Telegraf, здесь описано, какие Performance Counters и в каких форматах он должен репортить, чтобы его подхватила Grafana.
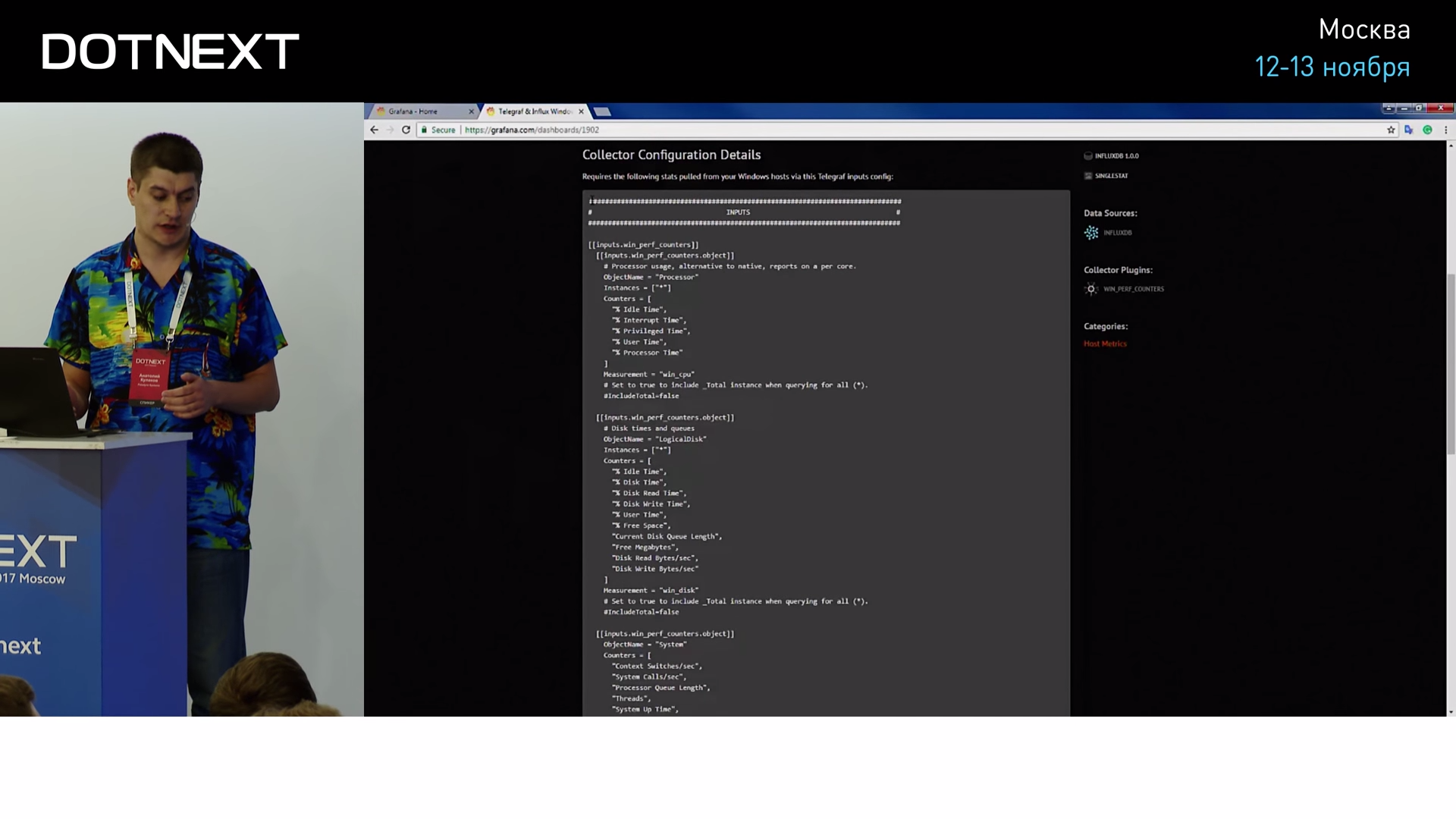
Копируем эти настройки, вставляем в настройки самого Telegraf:
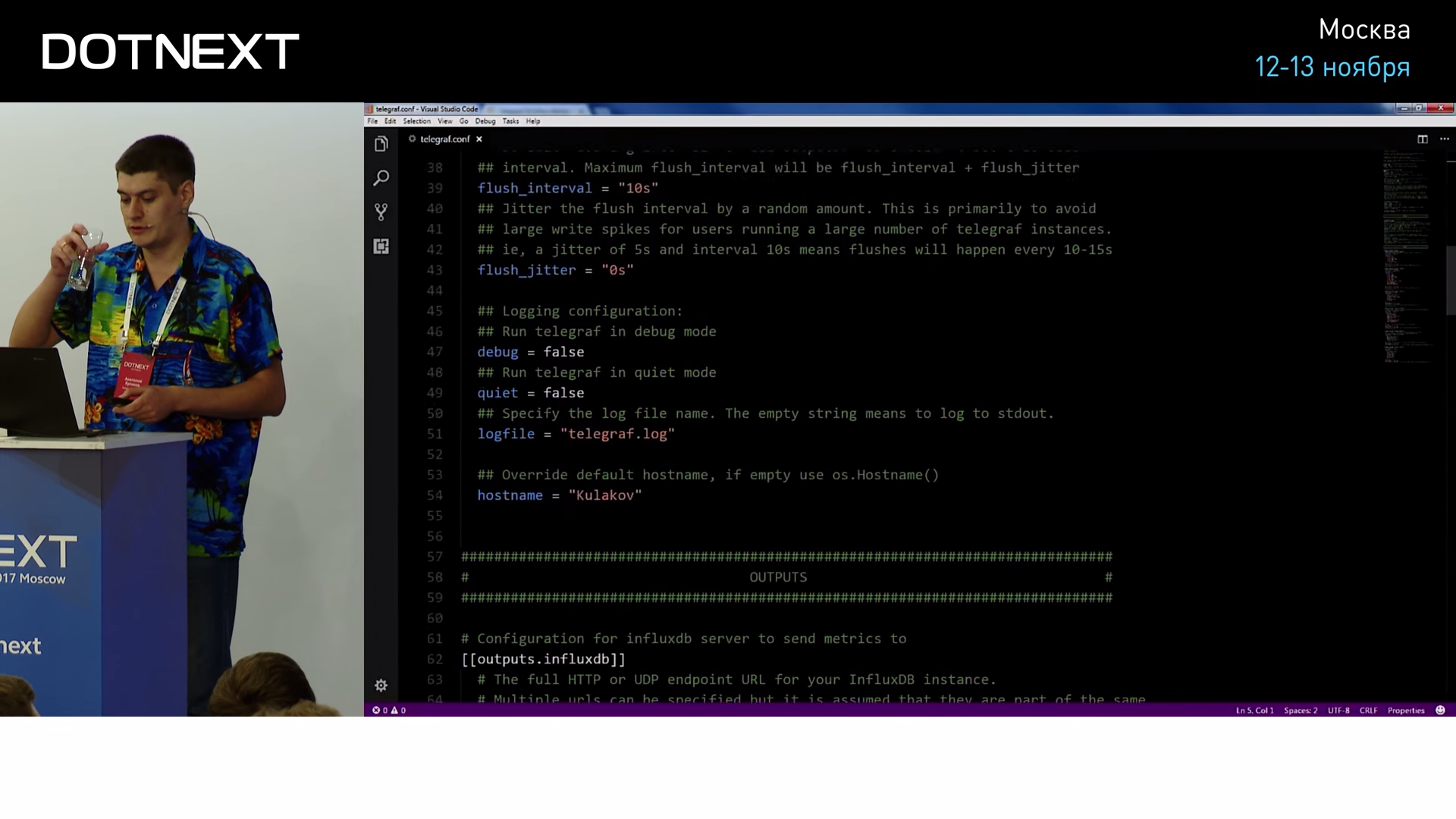
Как видите, настройки довольно интуитивные и понятные, вы задаете имя счетчика производительности и настраиваете период опроса:
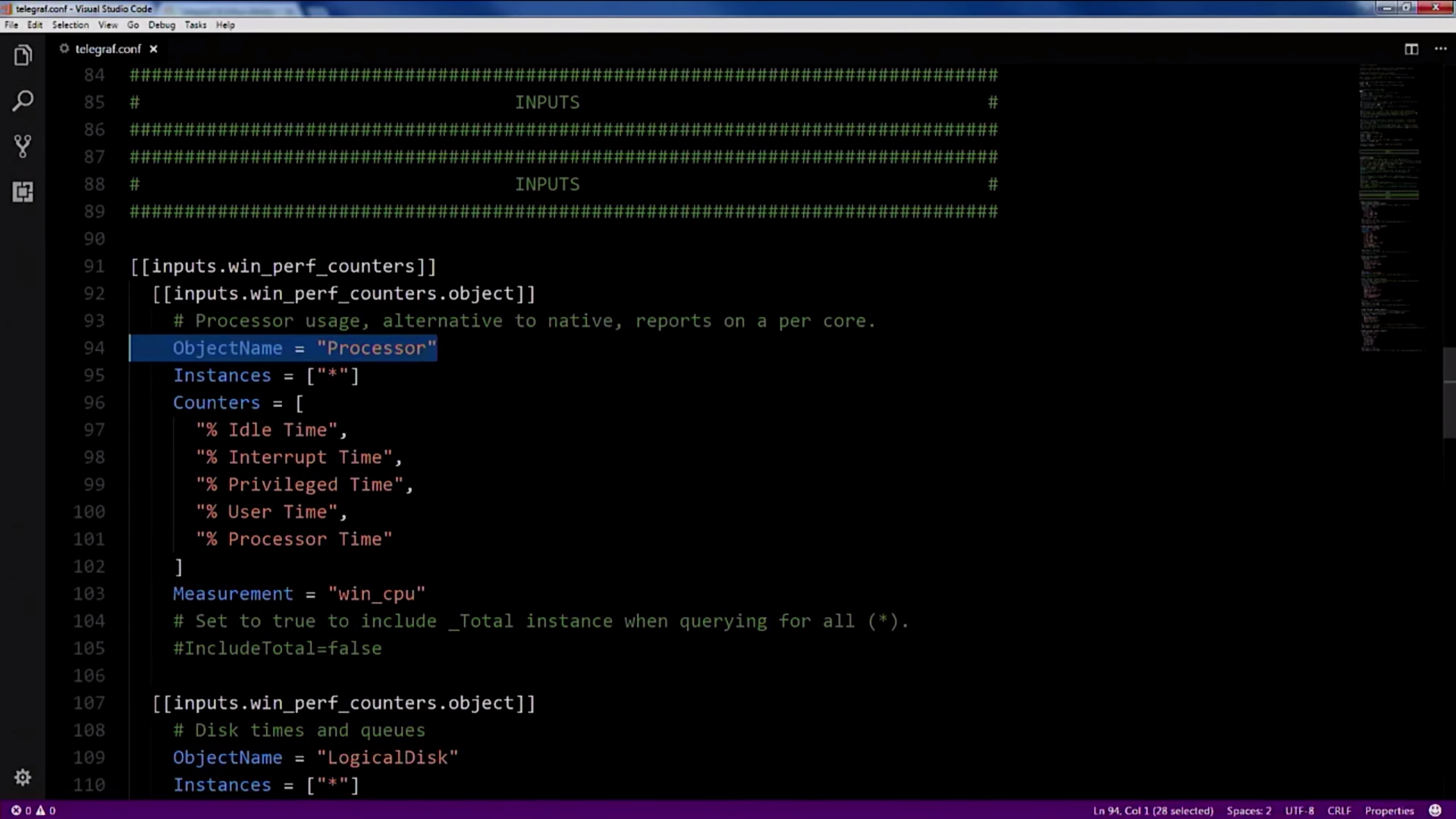
Всё это Telegraf собирает и отправляет в Influx.
Вернемся к нашему дашборду. Как я говорил, он состоит из двух частей, теперь поговорим про вторую. Вторая часть — это уникальный номер дашборда, копируем его, переходим к нашей локальной Grafana, импортируем дашборд 19:04 по этому уникальному номеру, в этот момент Grafana сходит в интернет, скачает дашборд и в следующую секунду покажет нам много интересной информации о нашей системе.
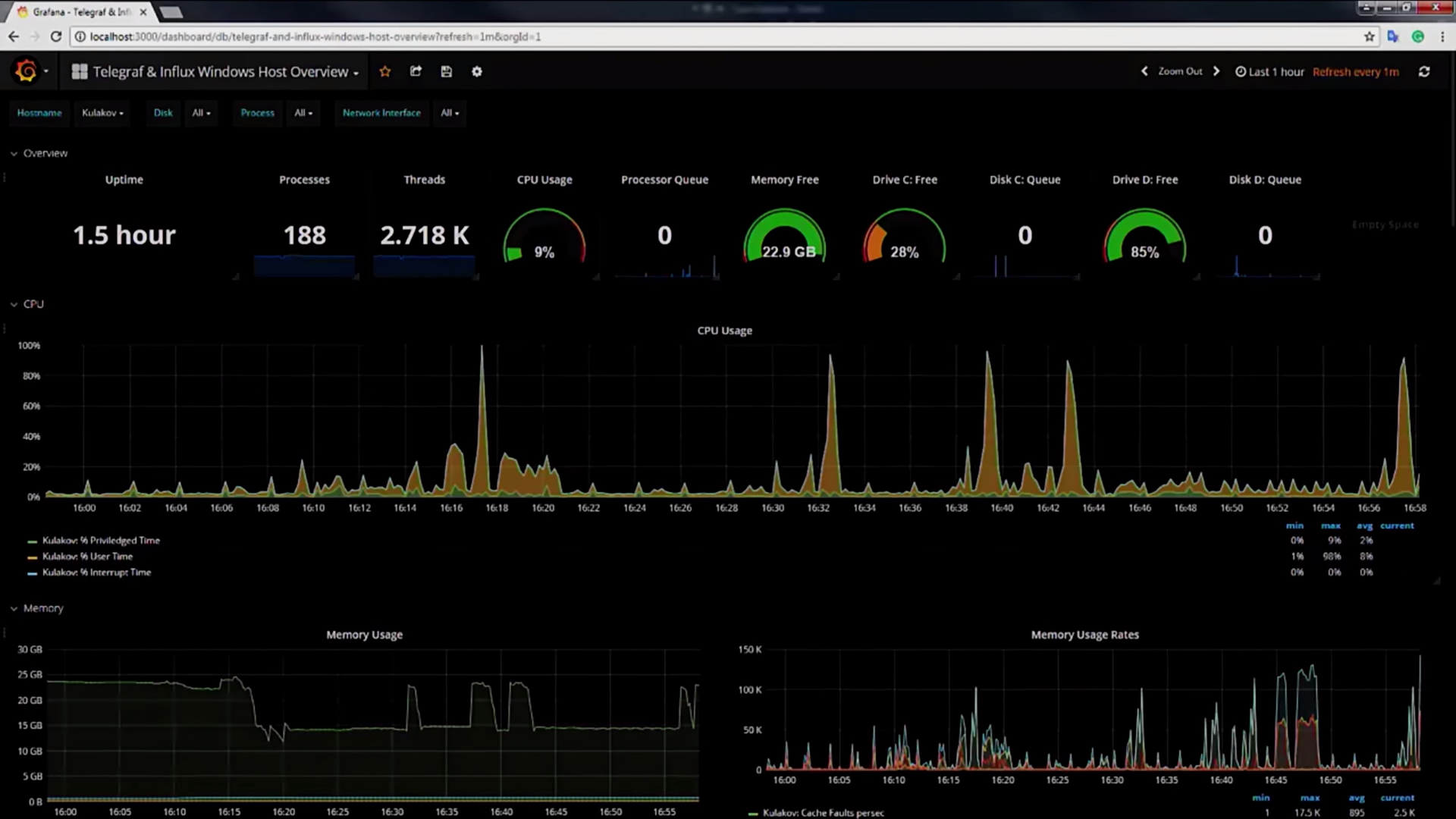
Здесь полная информация о тредах, процессах, использовании CPU, памяти, дисков, ваших сетевых интерфейсов, сколько пакетов к вам пришло, сколько ушло, количество хэндлов и так далее. Я специально залогировал все процессы в системе, но в вашем продакшн-коде вам нужно ограничиться только теми процессами, которые нужны для вашей работы.
Как я уже сказал, Telegraf взаимодействует с Grafana не напрямую, между ними есть Influx. InfluxDB — это самая популярная база данных временных рядов на данный момент.
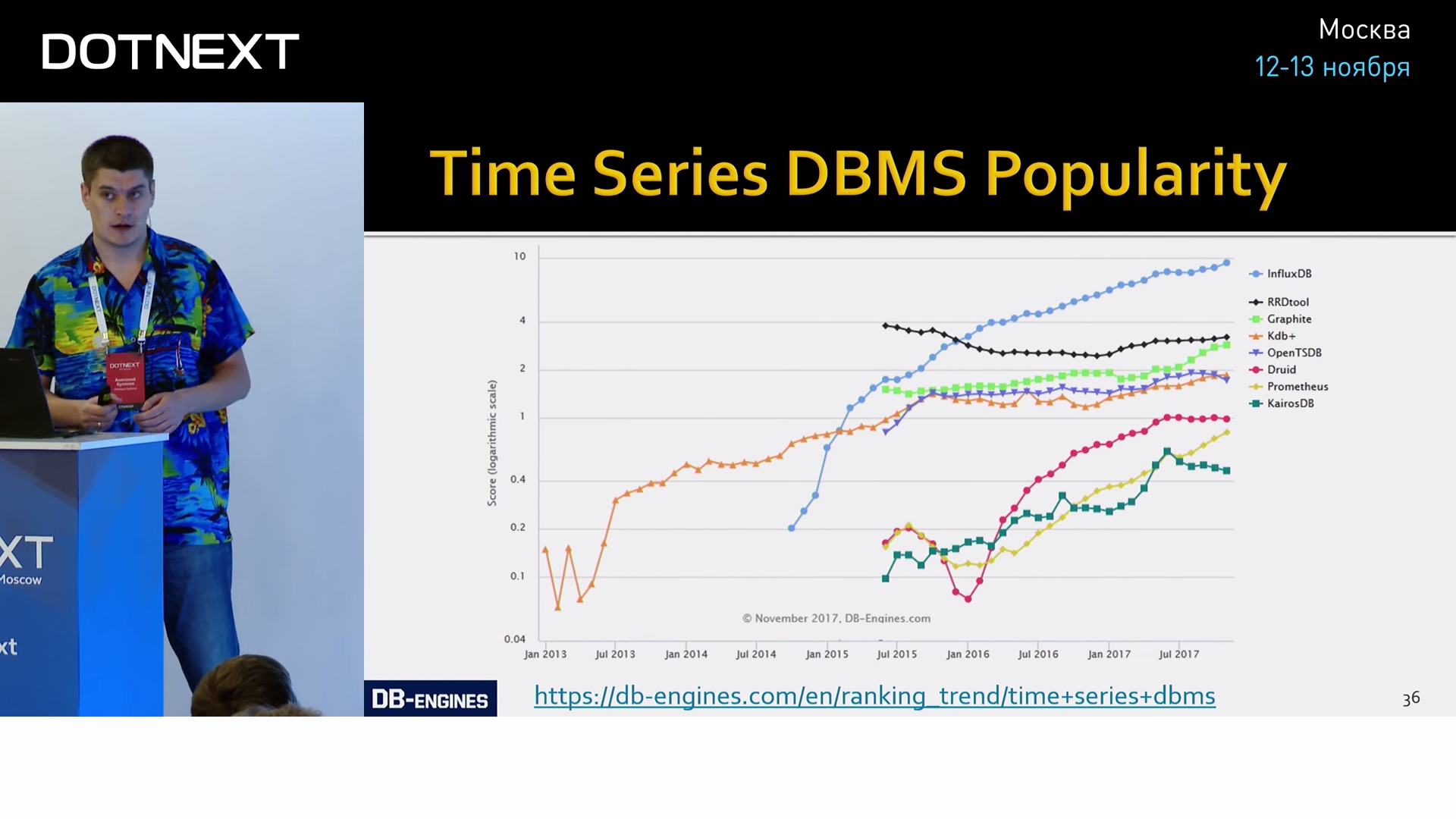
Она очень быстро обогнала всех своих конкурентов и сейчас не собирается сбавлять обороты. И наши тесты показали, что это вполне заслуженно.
Давайте на примере Influx посмотрим на специфику данных, с которыми обычно работают TSDB, и что их отличает от реляционных баз данных:

- Во-первых, это миллионы дата-поинтов и миллионы серий. Это как если бы вы в вашей реляционной базе данных начали создавать миллионы таблиц и заполнять их миллионами значений, такое на практике довольно редко встречается. А для Influx это стандартная ситуация.
- Частая запись. Дело в том, что данные в метрики пишутся постоянно, даже если пользователь ничего не делает. Метрики пишутся о том, что он ничего не делает, до сих пор ничего не делает и так далее.
- Такая же ситуация и с чтением. Аналитика, дашборды, алертинг, все требуют постоянного чтения, поэтому здесь тоже очень большие нагрузки.
- Удаление. Оно происходит большими пачками, потому что главная причина удаления — это просто «протухание» данных.
- Обновлений почти что нет, и ими можно пренебречь.
В терминах CRUD Influx является CR-системой, для него очень важны быстрые создания и чтение данных. Обновления и удаления случаются очень редко и в довольно специфических и хорошо оптимизируемых ситуациях.
«Под капотом» она хранит данные в своём собственном формате time-structured merge-tree.
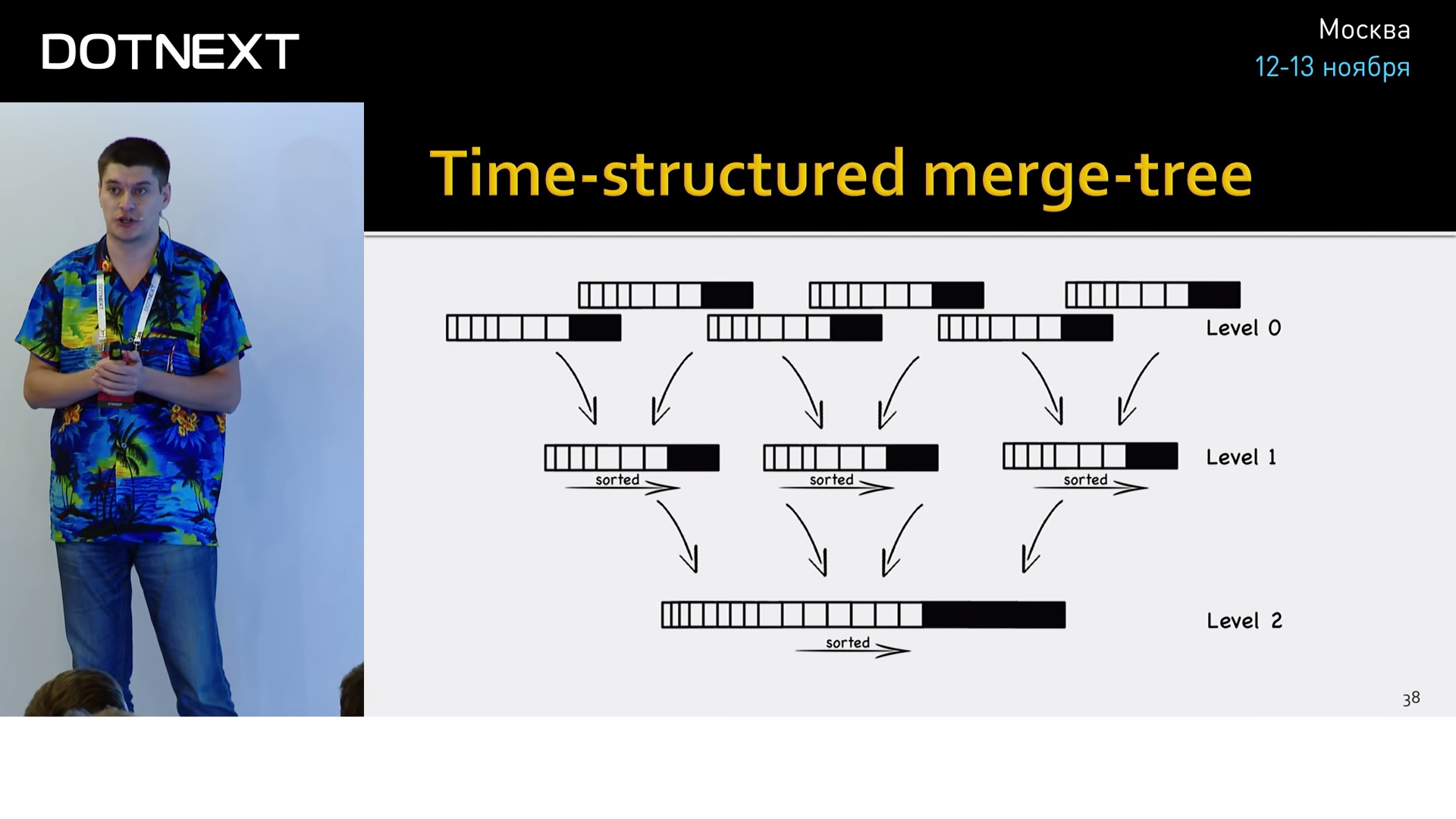
Это оптимизация всем известного log-structured merge-tree (LSM-дерево) применительно к временным рядам, который хорошо зарекомендовал себя на практике. Это структура данных, оптимизированная для быстрого доступа по индексу в условиях частых вставок. Применяемая, например, в логах транзакций практически всех современных БД.
Еще одним большим преимуществом Influx является SQL-подобный синтаксис запросов.

Почему это важно? Его предыдущие оппоненты очень сильно грешили плохой проработкой этого аспекта, они просили нас составлять запросы из такой богомерзкой смеси, как регулярные выражения, JSON и больная психика авторов. Это вообще невозможно было поддерживать, где-то через неделю вы приходите, смотрите на свои запросы, и у вас вытекают глаза. И именно нормальный синтаксис запросов позволил Influx выстрелить на массовую публику.
Если мы говорим о том, что у нас постоянно копятся данные, необходимо понимать, что мы с ними делаем. Для этого есть Retention policy (специальный механизм, который предполагает удаление данных через какой-то промежуток времени, если они вам не нужны). Но это слишком банально. Если это скрестить с такой фичей, как Continuous Queries (это что-то вроде materialized view, предрасчет сложных агрегатов на сервере), получится такой интересный механизм, как downsampling. Приведем пример.

Допустим, вы хотите измерять количество запросов, приходящих на ваш сайт. Вы вполне можете делать это в реальном времени, в графиках наблюдать загрузку всего этого и как-то на это реагировать. Через сутки real-time значения для вас являются избыточными, и вы вполне можете сагрегировать их до десятисекундных интервалов, вычислить агрегаты (min, max, count, какие вам интересны) и сохранить тот же набор данных, только в гораздо меньшем размере, следовательно, вы будете использовать гораздо меньше места. Через неделю вы можете увеличить период до одной минуты, через месяц — до часа, и оставить эти данные в архиве, например, для сравнения производительности вашего приложения через год.
По поводу производительности: прежде чем я назову цифры, здесь необходимо оговориться, что в такой узкоспециализированной сфере на производительность влияет абсолютно всё: количество метрик, насыщенность тегов, частота запросов, сложность аналитических алгоритмов, которые постоянно дергают Influx и читают эти данные. Самый банальный совет — всегда пробуйте на своих данных, на своем окружении и смотрите, что получится у вас. Но все-таки некоторые цифры хочется привести, чтобы вы понимали, зачем я об этом рассказываю:
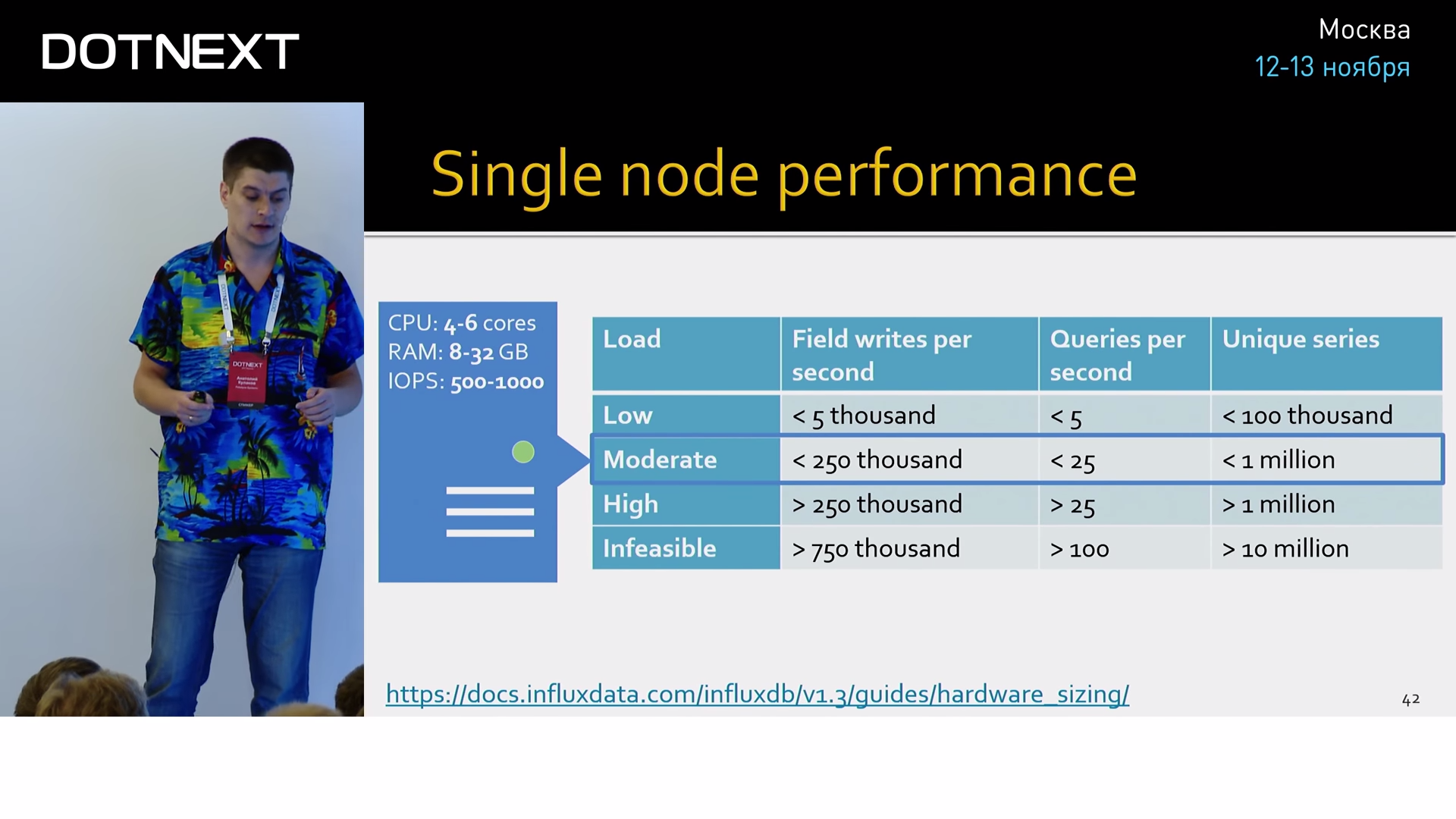
Если вы довольствуетесь 250 тысячами записей в секунду и вам хватает миллиона серий, вам вполне будет достаточно машины с шестью ядрами и 32 ГБ оперативки в пределе. Это такой средний сервачок. Если же вам нужны более лояльные условия, железо там будет совсем смешным. Мы в своих проектах для многих своих Influx-ов даже не выделяем отдельного сервера, потому что он не влияет на продакшн нашей системы почти никак, мы прямо там его и запускаем.
Помните идею хранить time series в обычной базе данных? Давайте посмотрим, что из этого может получиться:

В левом углу ринга типичные представители TSDB — это InfluxDB и OpenTSDB. OpenTSDB — это вторая по популярности TSDB, поэтому она попала в этот тест.
В правом — типичные представители документоориентированных БД.
У вас, конечно же, может возникнуть резонанс, что не очень честно сравнивать документоориентированные БД, со всей их мощностью, с узкоспециализированными хранилищами. Тем не менее, такое сравнение имеет смысл, потому что на практике для временных рядов люди часто используют именно такие БД. И хотелось бы показать, что у разработчиков может получиться, если они перейдут на специализированные средства.
От elastic отключены все дополнительные функции (индексирование, поиск и так далее), чтобы максимально сблизить его с конкурентами.
Итак, запись. На запись Influx рвет всех от 5 до 27 раз:

Сжатие данных удается ему от 9 до 84 раз лучше, чем всем остальным:

На чтении он примерно сравним с MongoDB, что по факту означает в 168 раз быстрее Cassandra.

Не говоря об отвратительном синтаксисе запросов и нетривиальном способе установки у многих его конкурентов.
Как мы видим, Influx очень хорошо справляется с поставленной ему задачей. Посмотрим, как он поможет писать метрики вашего приложения. Есть такой замечательный пакет, который называется App Metrics, создан для того, чтобы легко и быстро снять метрики с ваших WebAPI-контроллеров, записать их в БД и визуализировать в Grafana. Давайте посмотрим, как это происходит:

Итак, типичное Owin-приложений, здесь нет ничего нестандартного, всё ожидаемо, кроме двух строчек, которые я оставил, это использование App Metrics:
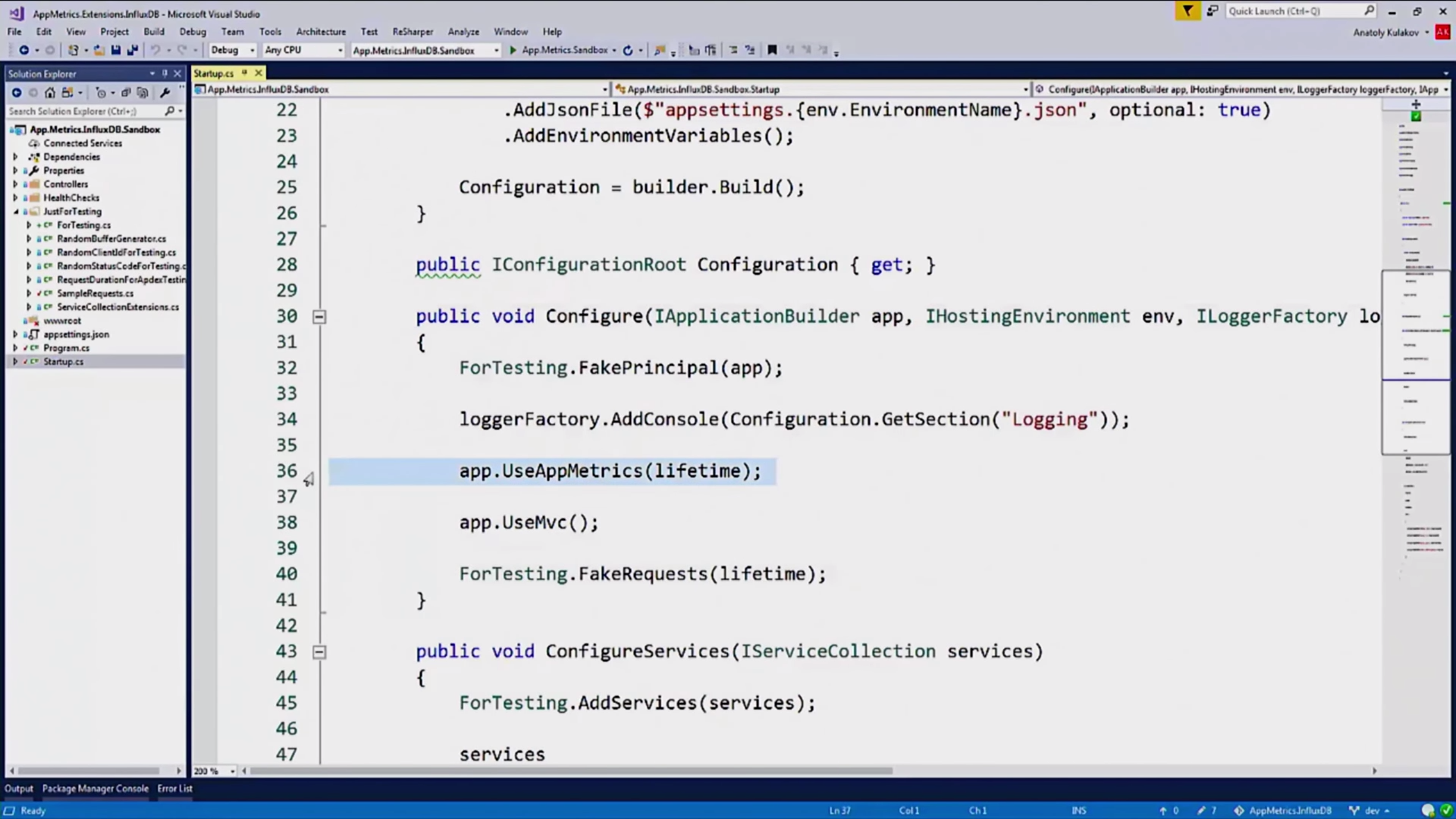
И, в конфигурации сервиса, использование InfluxDB для записи метрик туда:
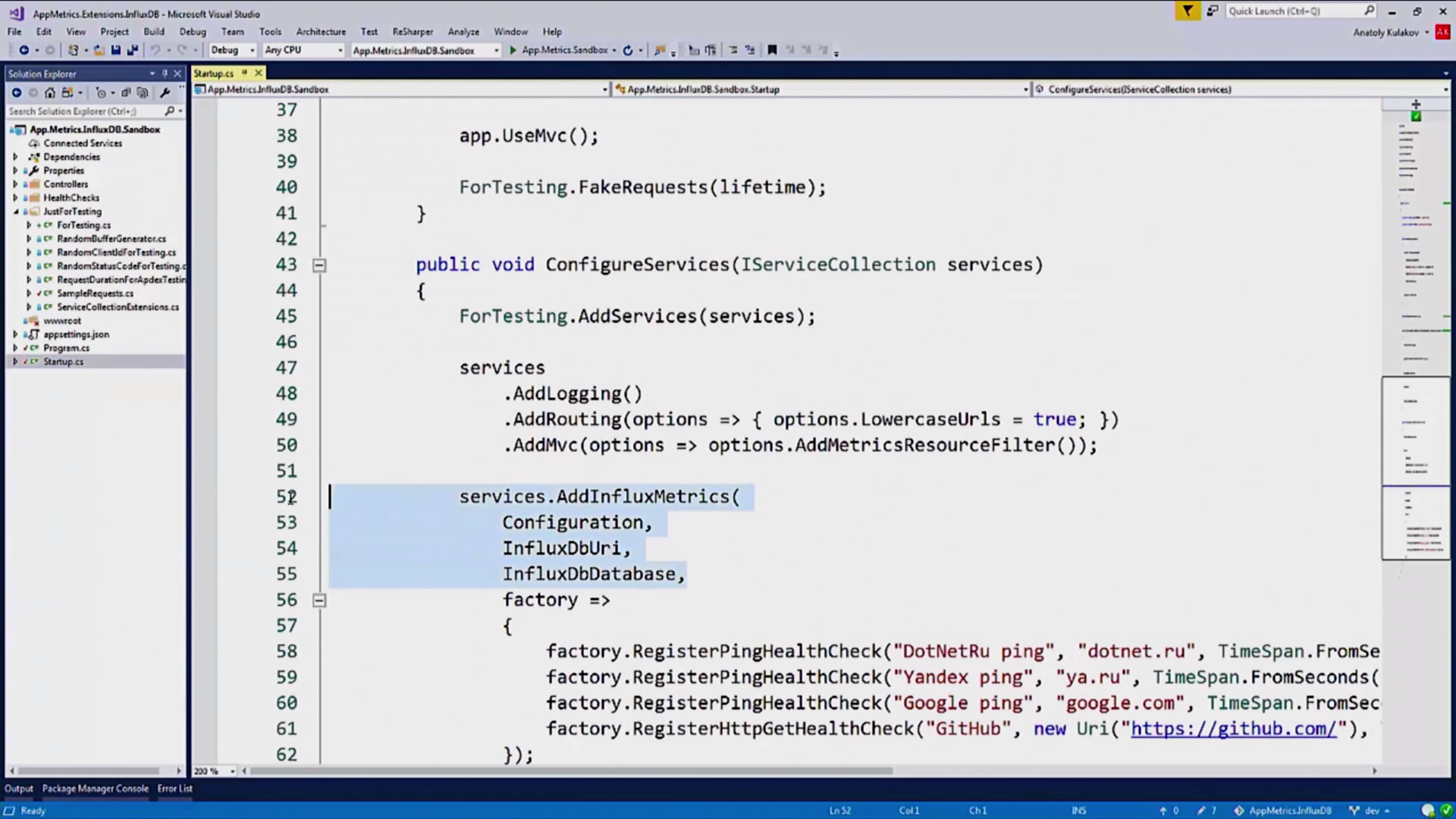
Здесь есть интересная секция, HealthChecks:
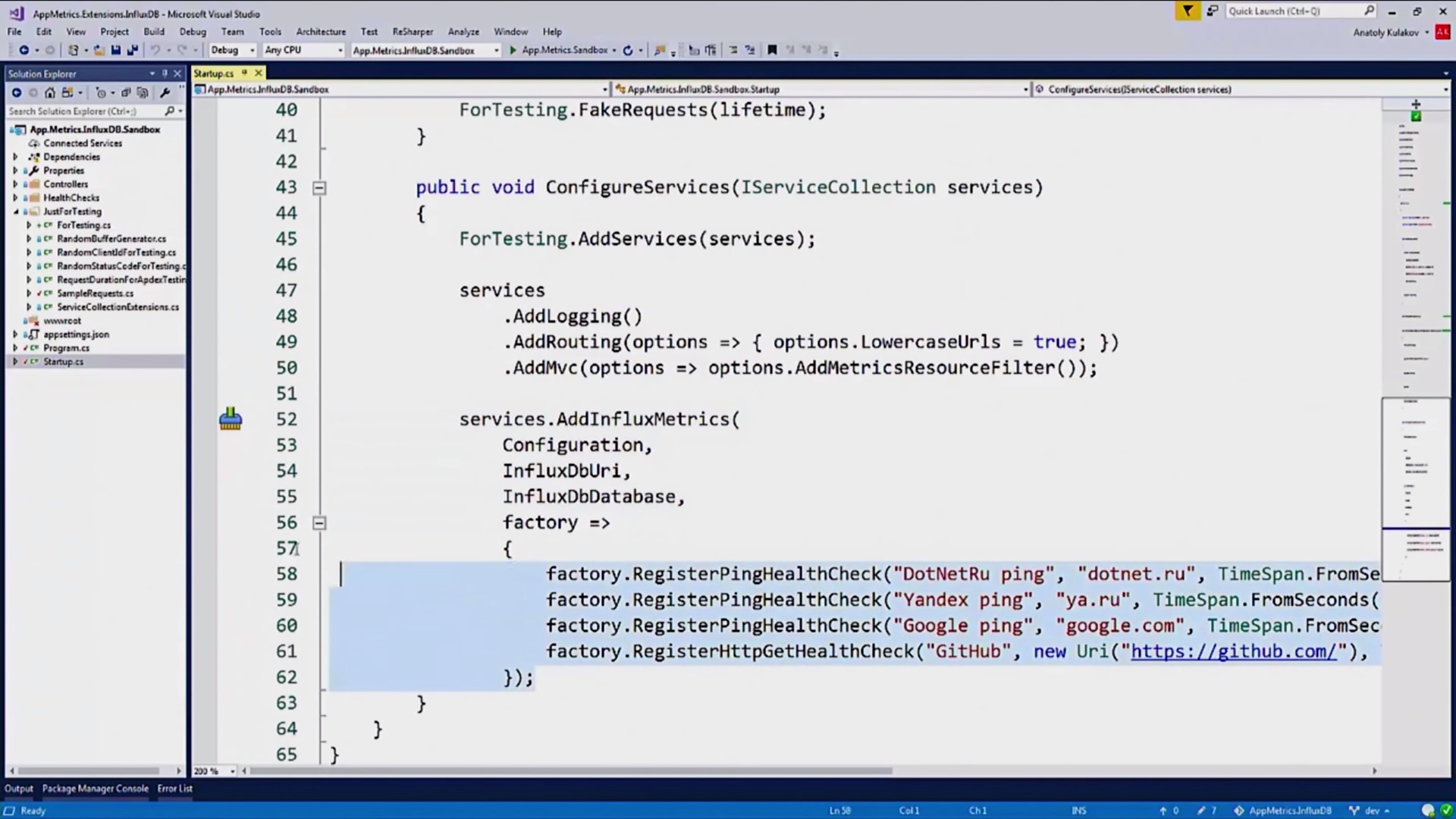
HealthChecks — это маленькие «проверяльщики» сторонних сервисов, от которых может зависеть ваше приложение. Дальше мы посмотрим на графиках, как они выглядят.
Я запускаю сервер, у меня также есть клиент, который атакует мой сервис запросами, чтобы мы увидели какие-то хорошие графики:
На сайте AppMetrics вы почитайте, что он может, как его устанавливать, как настраивать, я не буду на этом останавливаться.
Перейдем непосредственно к дашборду.

Как и у всех других, у него есть уникальный номер, который мы копируем к себе, выбираем источник данных, и через секунду у нас появляется полная информация о наших API-контроллерах:

Пропускная способность, количество ошибок, разбитых по контроллерам, по типу эксепшнов, по коду возвратов, пропускная способность по каждой точке, по каждому роутингу в вашем приложении. Здесь вы очень легко можете посмотреть, какие точки отдают данные быстро, какие — медленно и так далее. Вот, кстати, наши HealthCheckers:
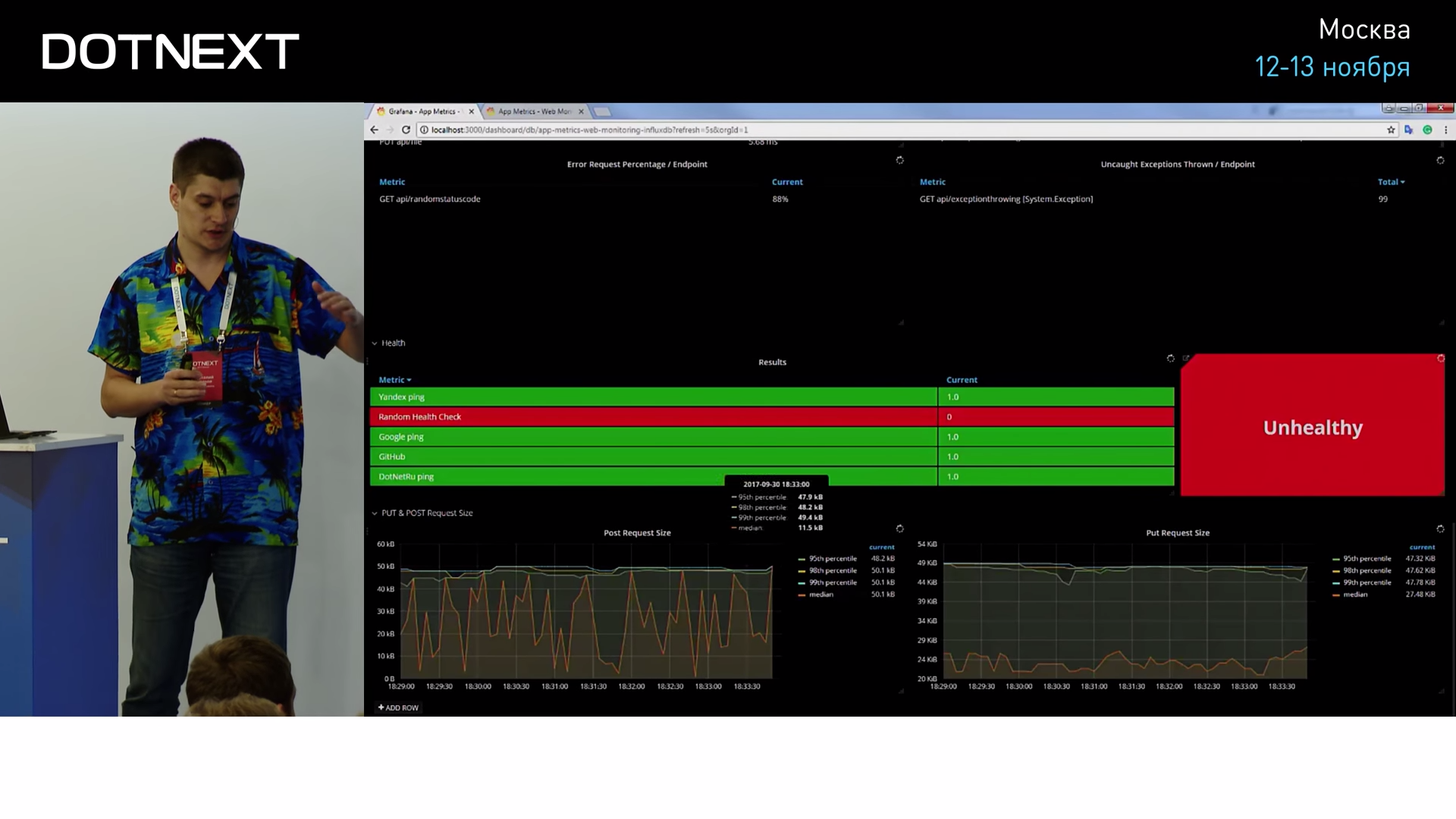
Они показывают, что некоторые сервисы доступны из нашего приложения, а некоторые — нет.
Перед вами, конечно же, может стоять жестокий выбор, какие графики использовать, какие метрики нужно собирать и так далее. Какие метрики нужно внедрить в наше приложение в первую очередь, чтобы получить максимальный эффект от всего этого? У меня есть небольшой алгоритм:
- Во-первых, установите Telegraf и дашборд, как в первом демо. Это поможет вам собирать основные характеристики вашего железа и операционной системы.
- Установите App Metrics и дашборд, как во втором демо. Наверняка у многих из вас есть Web API, и вы без труда сможете это сделать.
- Поиграйтесь с этим. Поживите с этим. Посмотрите на ваши графики, сравните, как изменяется нагрузка на процессор, когда к вам приходит запрос с большим body. Поменяйте цвета, попробуйте поменять местами графики, оптимизировать их порядок.
- Удалите все графики, которые вам не пригодились и которые вам больше не нужны.
- На этот момент у вас будет достаточно опыта, чтобы начать писать свои собственные графики, собственные метрики в БД и строить собственные графики на вашем бизнес-домене.
К сожалению, у меня нет дашборда, который подойдет для вашего бизнес-домена, который отобразит все ваши критически важные участки, этим вам придется заняться самим. Вы должны выяснить, какие метрики в вашем домене должны быть обязательно залогированы и отслежены. Я же могу вам показать то, каким образом вы можете писать в Influx и каким образом можно строить графики в Grafana.
Давайте опустимся на уровень ниже и посмотрим на примере, который мне поможет сделать замечательная библиотека BenchmarkDotNet. Итак, представьте мое бизнес-приложение: я пишу архиватор. Очень крутой архиватор, я добился шикарных значений, он сжимает просто блестяще. Я очень много экспериментирую с алгоритмами, и, чтобы эксперименты не вывели мой бизнес в трубу, я каждую ночь запускаю бенчмарк-тесты, которые все результаты моих измерений пишут в Influx. И каждое утро, когда я прихожу на работу, я открываю Grafana и вижу графики того, что я вчера натворил, улучшил или, наоборот, ухудшил.
Как это можно реализовать? В принципе, очень легко. Начнем знакомство мы с утилиты командной строки, которая называется influx.exe:
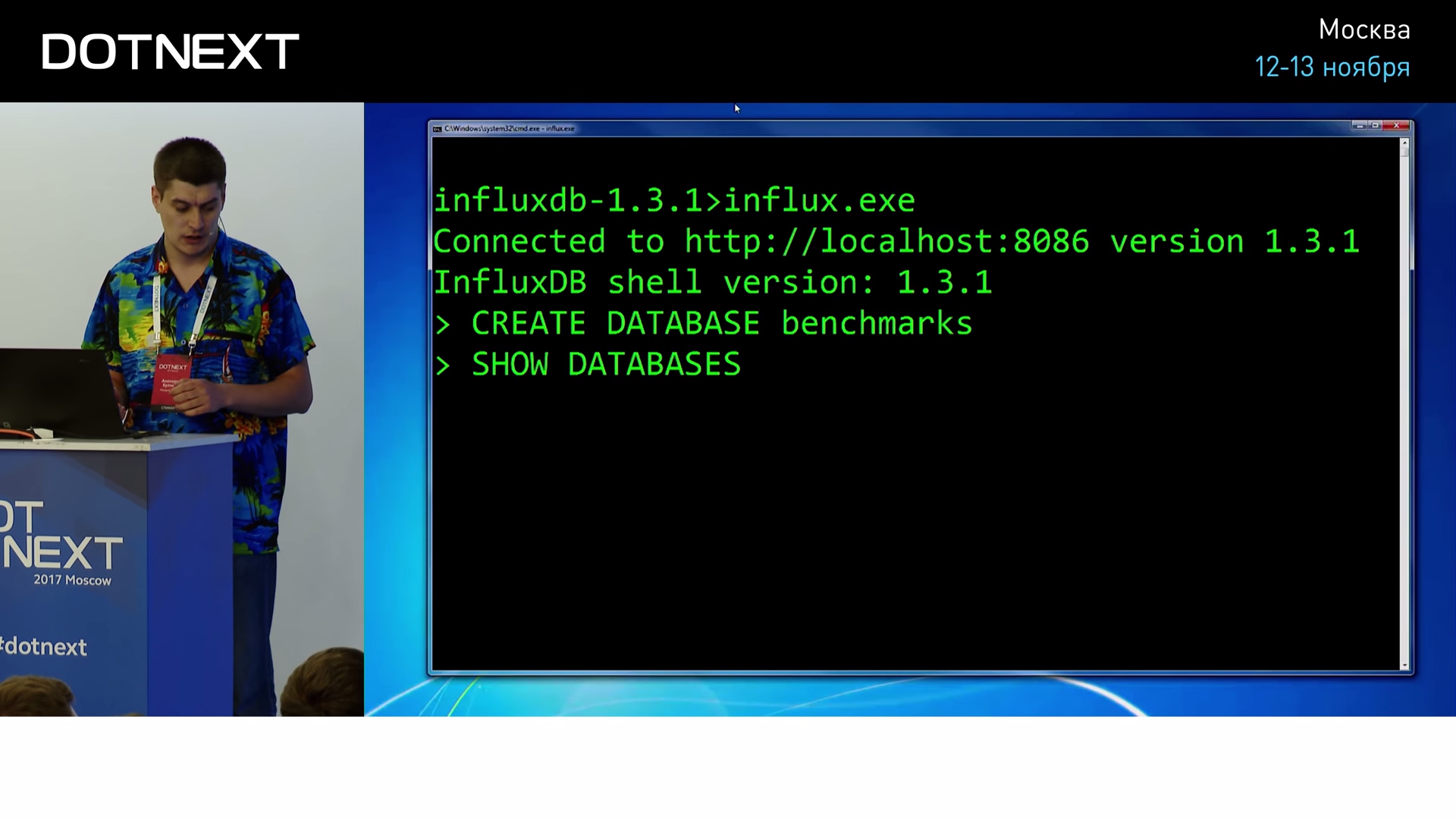
Она способна подключиться к любому серверу Influx и выполнить на нем произвольные запросы по выборке данных. Например, давайте создадим БД benchmarks, в которую мы будем писать результаты измерений.
Теперь перейдем к моему приложению: как я уже говорил, у меня есть два алгоритма, над которыми я сейчас работаю.
Есть быстрый алгоритм компрессии:

И медленный:

На них навешаны стандартные атрибуты BenchmarkDotNet, что позволяет мне запускать эти бенчмарки каждую ночь в автоматическом режиме. Единственный нестандартный атрибут, который здесь есть — это InfluxExporter, я его сам написал:
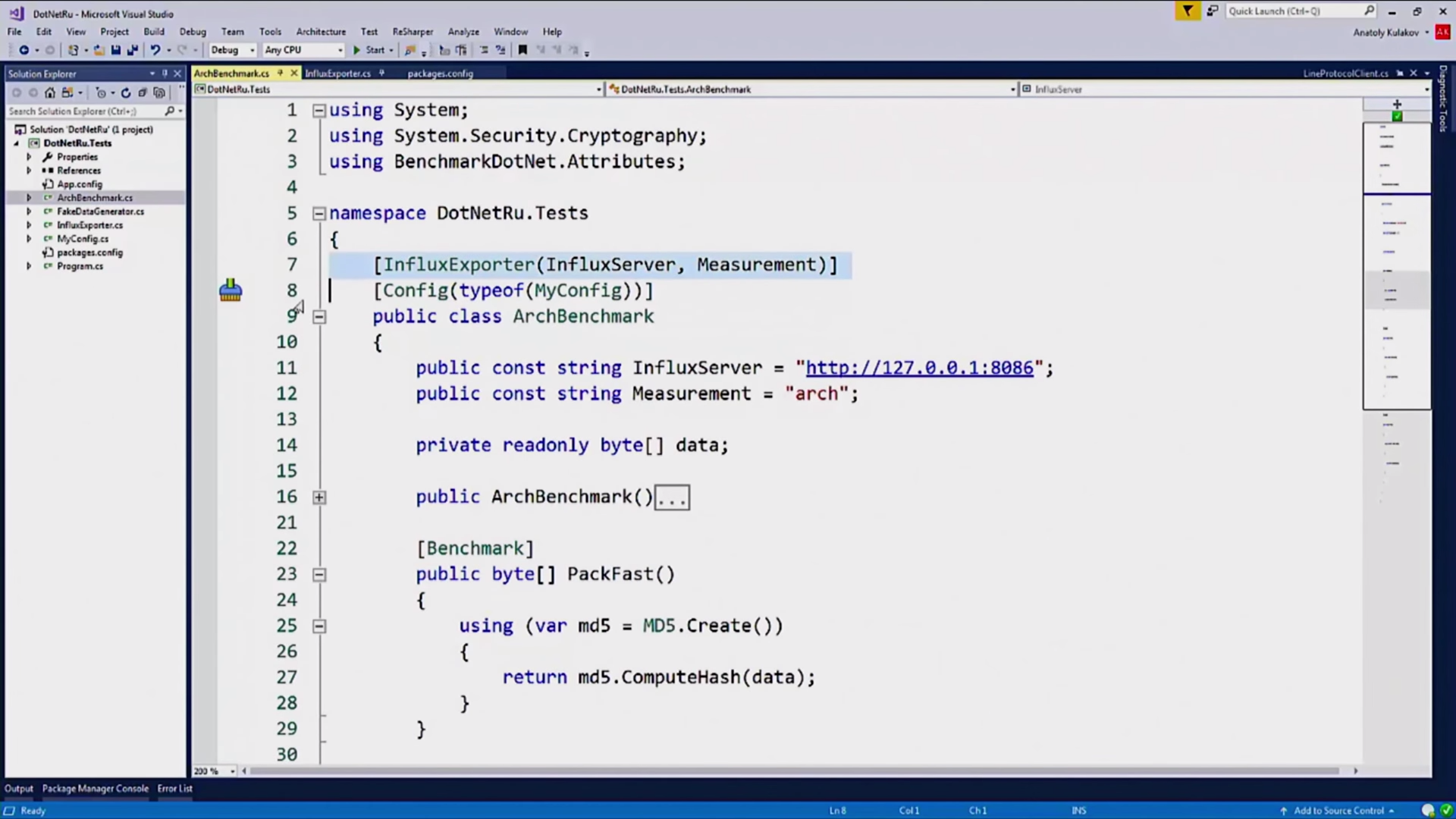
Он принимает в качестве параметра имя сервера и пишет туда значение. Он сделан вот так:

Он должен быть пронаследован от интерфейса IExporter, стандартного интерфейса BenchmarkDotNet, это нужно для того, чтобы получить результаты наших измерений от библиотеки.
Писать мы будем при помощи MetricsCollector:
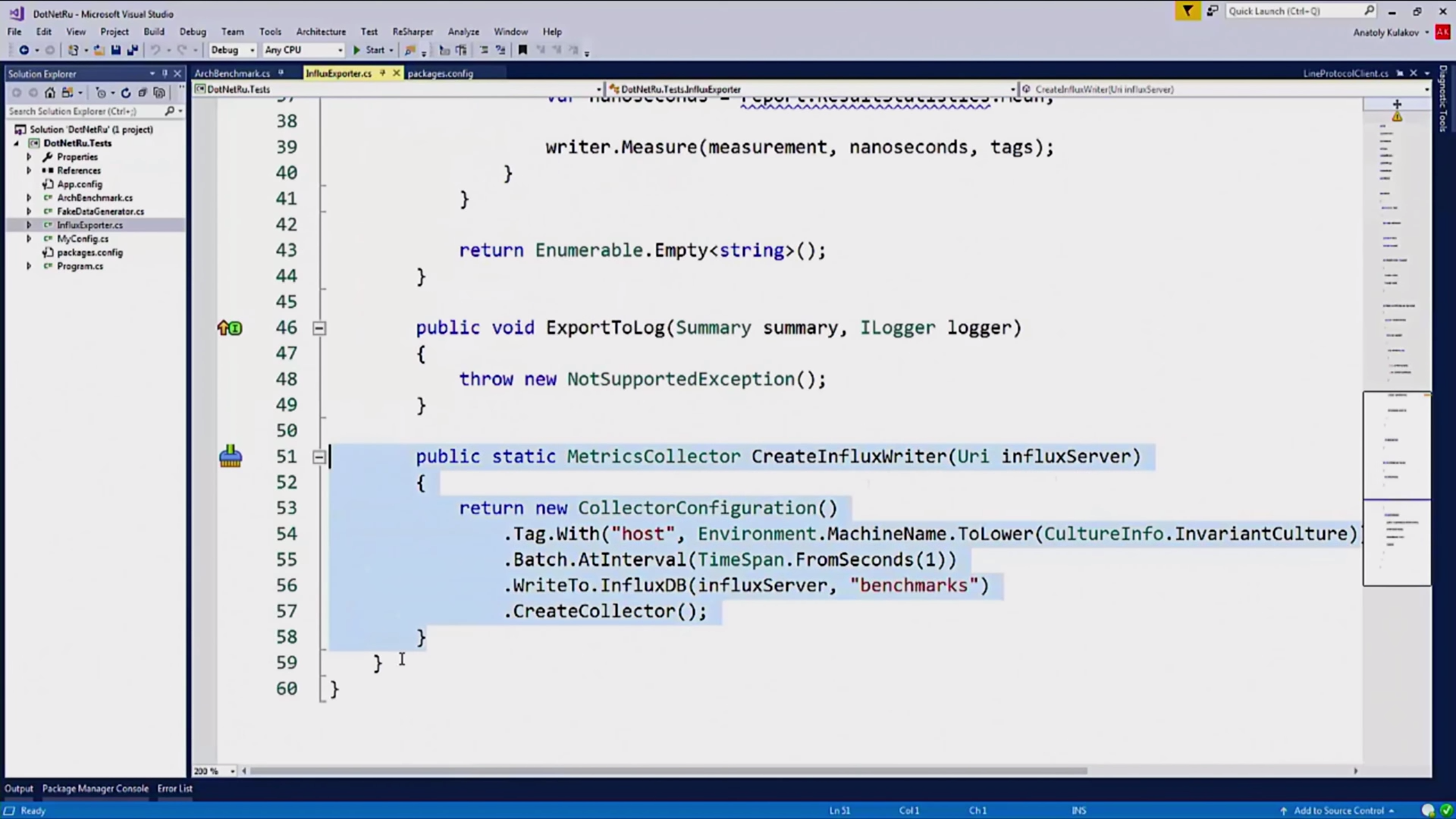
Это класс, который находится в пакете InfluxDBCollector. Очень хороший пакет, он дает нам возможность расширить наши метрики.

Здесь я добавил имя хоста и где производилось измерение. Ещё он может упаковать наши метрики в батчи, чтобы мы отсылали данные раз в секунду, а не в real time.
И, непосредственно, измерение:
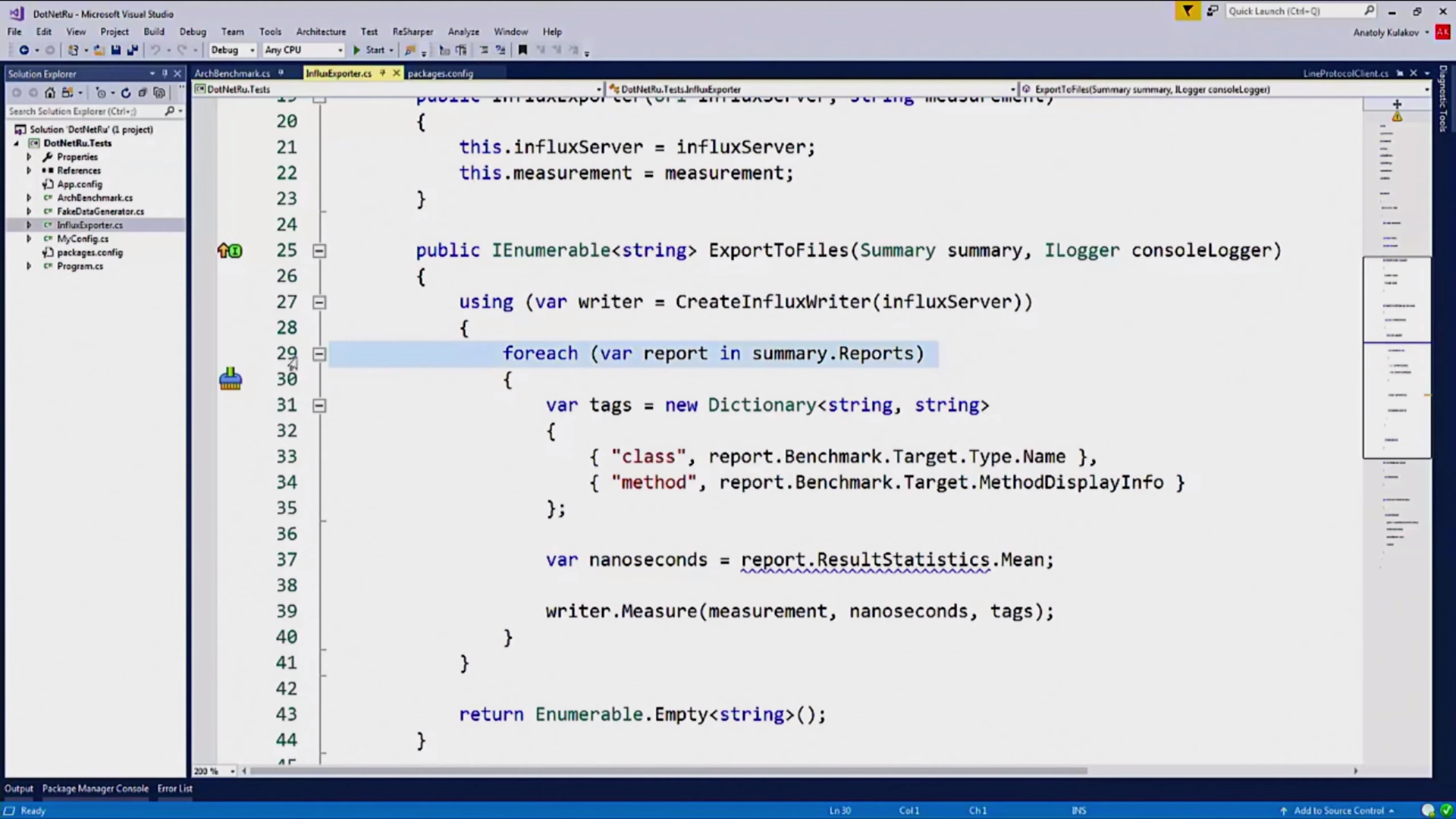
Этот метод дергается бенчмарком.
В InfluxDB всё это записывается с помощью так называемого LineProtocol, который представляет собой обычный текстовый протокол вот в таком виде:
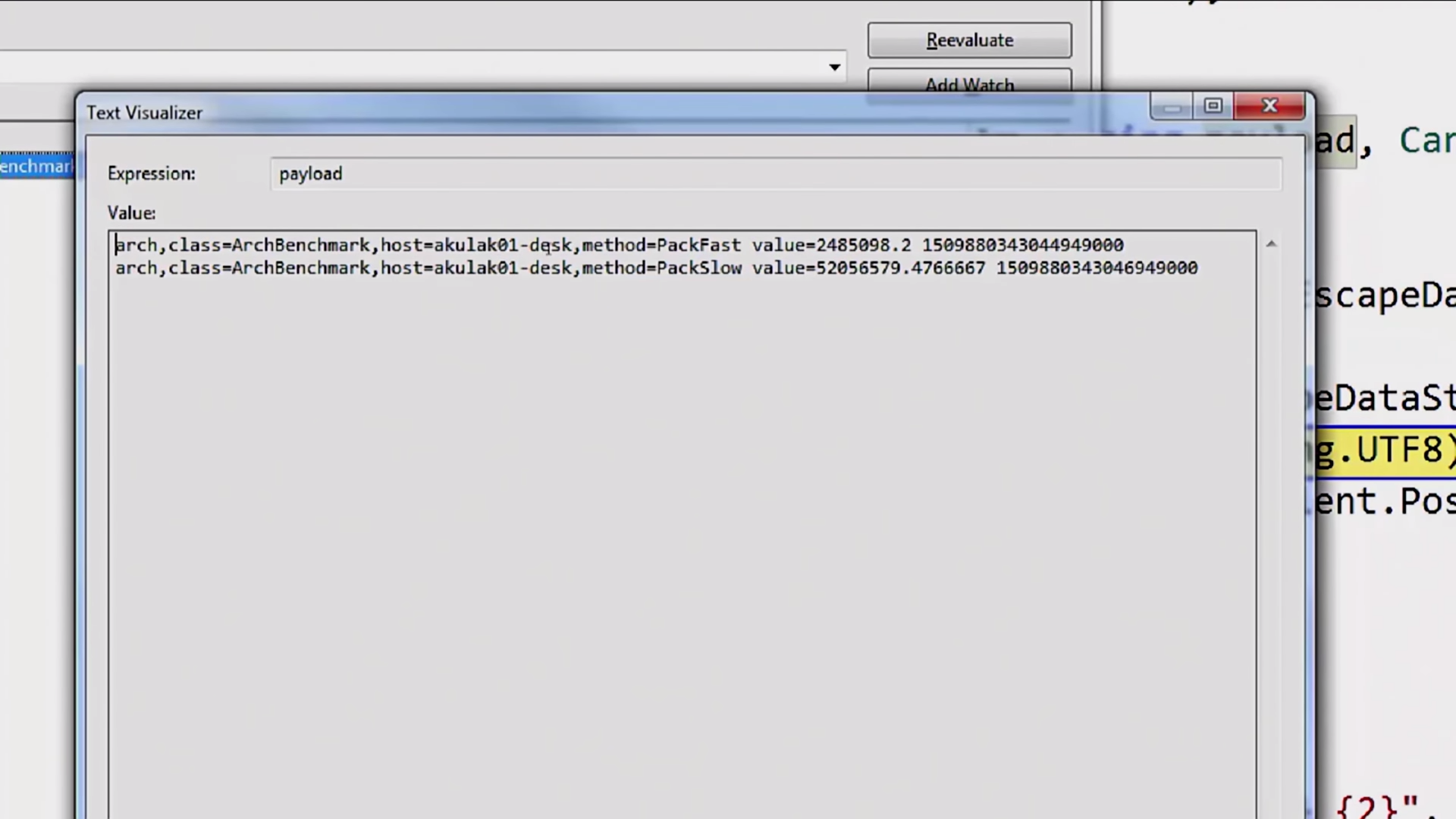
Здесь есть имя метрики, перечислены все теги и так далее.
Перейдем к Grafana. Чтобы начать ей пользоваться, нам необходимо создать Data Source.
Выбираем ему имя, ставим тип InfluxDB, адрес Influx и имя самой БД (которую мы создали в начале). Data Source готов, теперь мы можем строить дашборды на его основании.
У Influx есть множество типов графиков, я покажу всё на при
