TestOps: писать автотесты недостаточно
Совсем недавно я услышал замечательную историю о проекте внутри крупной российской IT-компании, ищущей руководителя в отдел тестирования. Задача была простая: есть отдел из 20 человек, которые за последние несколько лет наколбасили несколько тысяч автотестов и спроектировали пачку тестов ручных. В целом все работало, но СТО на собеседовании сказал примерно следующее: «Ваша задача — выкинуть все это к чертям собачьим и сделать нормально. А то когда предыдущий QA Lead ушел, мы поняли, что вся эта инфраструктура у нас нигде не используется.»
Ситуация невообразимая. Так не бывает. У нас точно не так. У нас же не так?
Проблемы «works on my machine» и «ответственность за нерабочий код лежит на том, кто его деплоит», ровно о том же. И пока разработчикам рассказывали про спасительный DevOps, тестировщики и QA-специалисты как-то со стороны смотрели на это «не шаля, никого не трогая, примус починяя». Ну что, пришло время набросить и на этот вентилятор.
В этой статье мы с Артемом Ерошенко из Qameta Software попробуем разобраться, что такое «делать тестирование нормально» в новых проектах.
Что делают тестировщики? А что должны делать?
Конечно, тестировщики-автоматизаторы пишут и поддерживают тесты. Это первое, что приходит в голову. А когда они написаны, их нужно использовать. Это тоже кажется очевидным? Чтобы понять, что это так, ответьте для себя на 4 вопроса про ваши тесты:
Вашим тестам верят?
Ваши тесты проходят стабильно и персистентно?
Тест-сьюты прогоняются быстро?
Результаты прогонов понятны тем, для кого вы их пишете? (это не вы)
Если ответ хотя бы на один вопрос вызывает у вас сомнения, продолжайте читать. Так что же у нас есть в автоматизации?
Пишем автотесты: если тестов не писать, никакого тестирования не будет. Все просто: нет ручек — нет конфетки.
Запускаем тесты — это отдельная история. Несмотря на DevOps, семимильными шагами шагающий в мире разработки, тесты часто деплоят так, что о стабильности и воспроизводимости речи не идет.
Разбираем результаты: если нет понятной системы генерации отчетов, команда тестирования будет заниматься не разработкой тестов и подготовкой инфраструктуры, а разбором отчетов.
Показываем отчеты: часто бывает, что внутри команды тестирования все хорошо, но никто из стейкхолдеров в бизнесе не понимает, что делают люди внутри этой команды. Это вызывает вопросы и потери времени на бюрократические войны.
Итак, высокоуровневые грабли разобрали, давайте посмотрим, что можно сделать, чтобы их избежать!
Пишем автотесты
Выбирайте подходящие инструменты. Обратите внимание, что подходящий инструмент и «правильный» — это не всегда одно и то же:
Подходящий инструмент решает конкретную задачу. Вам не нужен швейцарский нож, в котором вы будете использовать одну-две функции (как обычно бывает). Иначе вы будете работать с кучей зависимостей и лишней сложности, иногда теряя инструменты, потому ваш маленький кусочек «испортили» в очередном крупном релизе.
Подходящий инструмент легко расширяется. Каждый сервис имеет свою специфику, поэтому даже если поначалу инструмент кажется полностью подходящим, со временем вам захочется «поработать напильником» по мелочи: рекурсивные pageObject, NTLM аутентификация, нативные операции на десктопе, да кто знает, что еще вам понадобится? Давайте посмотрим на примеры таких инструментов:
Для конфигурации хорошо подойдет Owner, проперти он умеет собирать из любого источника.
Для работы с API подойдут Retrofit или Feign.
Для Web«а подойдут Selenide или Atlas.
Подходящий инструмент легко объяснить коллеге. Понятные инструменты не только помогут вам упростить масштабирование команды, но и упростят работу с bus-фактором. Здесь главное не увлекаться и оставаться понятным. Объяснение в формате «Так, ну тут все просто: helm апдейтишь, потом катишь в canary и внимательно в эластике за логами следишь» скорее всего приведет к тому, что вас посчитают снобом, а человек потратит больше времени на поиски деталей реализации, чем сэкономит на автоматизации. В результате вы останетесь со своей рутиной, а коллега подумает, что все очень сложно и скорее опустит руки.
Легко заменить. Новые инструменты будут выходить и иногда лучше подходить, так что думайте о том, сколько будет стоить отказ от инструмента в будущем: можно взять Allure Report, проставить аннотации в коде и все будет работать, а если вы решите переехать — просто удалить одну зависимость, которая ничего не сломает. Тулы, которые остаются в проекте из-за того, что их «хрен выпилишь» — прямая дорога к техническому долгу. Привет core-системам на COBOL и Perl.
Внедряйте новое постепенно. Представьте новый проект, в котором, помимо Web- или API-тестов, появляются экспериментальные штуки типа А/B-тестов или тестов на скриншотах с хранением в новой БД, а что-то параллельно пишут на только что занесенном Kotlin. И это в проекте из 200–300 тестов. Каждый новый инструмент по отдельности хорош, но вместе они делают процесс тестирования максимально непрозрачным.
 https://imgs.xkcd.com/comics/automation.png
https://imgs.xkcd.com/comics/automation.pngПредставьте, что на вашу основную работу вы тратите, допустим, 10 часов. В какой-то момент вы решаете ее автоматизировать и на это вы потратите еще 10 условных часов. Получается вот такая вот неэффективная с точки зрения времени штука:

Но допустим, что мы справились с задачей, и автоматизация позволяет нам сократить время с 10 часов до 5 (4 на работу и 1 час на поддержку автоматизации), как-то так:

В этот момент хочется отправиться к руководителю и заявить о победе, но не стоит торопиться. С точки зрения классического менеджера, вы все еще потратили больше времени, чем было бы без нового подхода. По сути, вам необходимо «компенсировать» вот этот зеленый горб на графике экономией синей области, а это произойдет только в будущем.
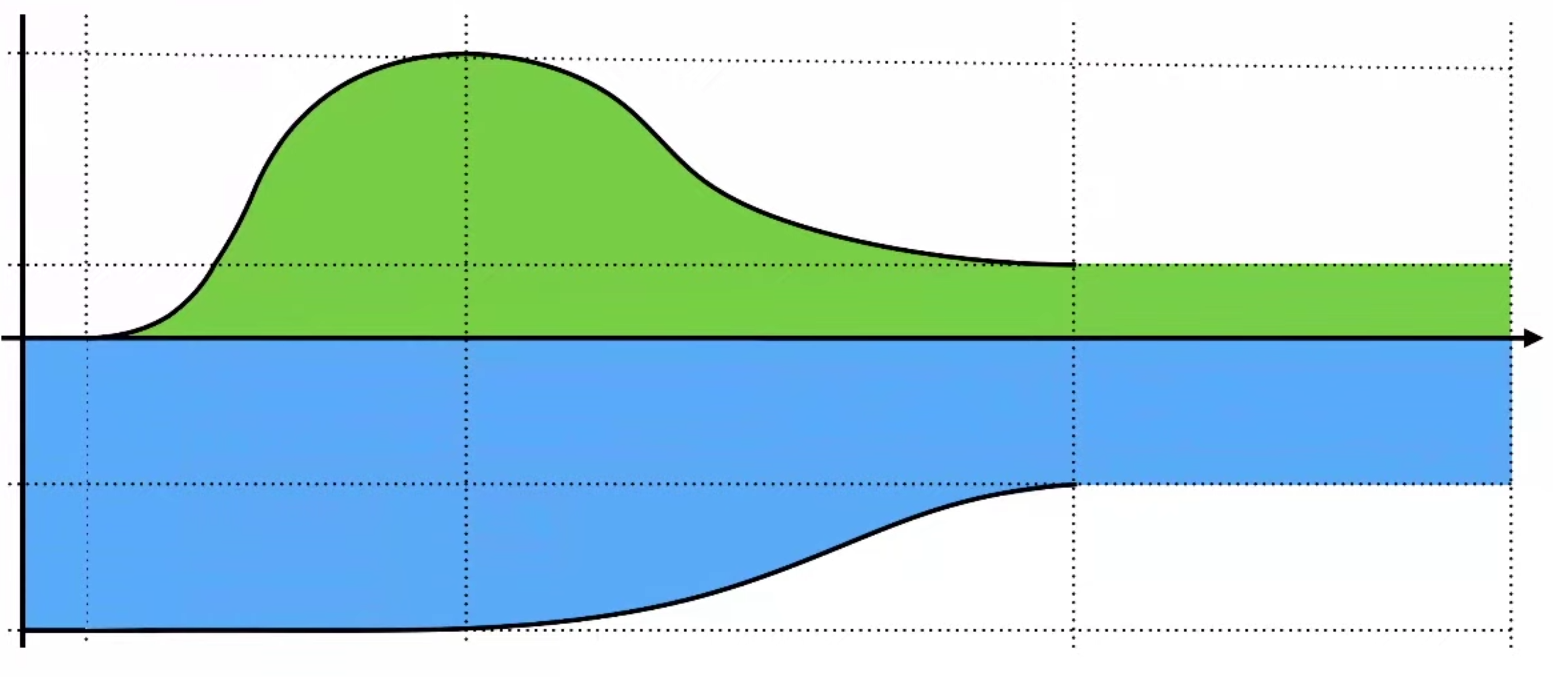
А теперь давайте вспомним, к чему это все — если вы постоянно затягиваете в проект что-то новое (БД для данных, новый язык программирования или фреймворк, API-тесты и пр.), ваш «долг» будет расти, а система — становиться монструозной. Собирайте ваш фреймворк по одному и не торопясь — итоговое решение получится намного более сбалансированным.
Делайте код-ревью.
Если вы сениор, то вы сможете на реальных примерах показать правильные паттерны и практики, и разобрать ошибки или неоптимальные решения.
Если вы джун — смотрите пулл-реквесты коллег и старайтесь перенять то, что было сделано хорошо, и запомнить то, что было исправлено (или из-за чего PR завернули).
И в любом случае во время ревью и новички, и профессионалы найдут для себя что-то новое. Например, можно увидеть необычные способы использования знакомых инструментов: нагрузку на прод web-тестами? пожалуйста! — можно найти вещи, которые вам и в голову не пришли просто потому, что вы знаете, как правильно. А может быть, ваши коллеги используют их неправильно.
Запускаем автотесты
Первый совет как для автоматизаторов, так и для ручных тестировщиков — научитесь работать с Docker. Это не очень сложно, но очень полезно в ситуациях, когда хочется проверить какие-то специфичные кейсы вроде «нужен вот такой-то плагин на Jenkins» или «хочу сравнить стабильность Selenoid и Selenium Grid, как бы их потестить». Понятное дело, что сразу в продакшене вам такие эксперименты проводить не разрешат (или это все будет очень сложно и долго). Посмотреть немного про Докер можно в Ошибке Выжившего.
Запускайте тесты на пулл-реквесты. Новый код может ломать проект, и это нормально для молодых проектов, поскольку структура может часто меняться в условиях появления новой функциональности или глубокого рефакторинга старой. А вот отвалившийся прод — это не нормально ни для кого. Давайте посмотрим, что можно сделать, чтобы все было хорошо:
Разработчик отводит новую ветку;
Заводит PR и прогоняет все тесты;
Командой фиксим тесты и ошибки;
Заводим ветку в stable. Обратите внимание, что это ветка спринта, и в мастер весь код попадает только после того, как все новые фичи и тесты спринта загорятся зеленым. Перед мерджем, конечно, тоже нужно будет прогнать все тесты.
Запускайте тесты часто. У вас всегда будут плавающие проблемы, которые могут быть вызваны разными факторами:
Нестабильные тесты;
Нестабильный тестинг;
ВременнЫе проблемы;
Работа инфраструктуры.
Чтобы свести количество таких факторов к минимуму, старайтесь гонять тесты на прогретой машине. Запускайте тесты по максимуму: в разных окружениях, в разных ветках, в разное время, — пока у вас нет сотен и тысяч тестов, которые будут часами выполняться на агенте, скорее всего, машина все равно будет простаивать.
Найдите потребителя результатов ваших тестов. Помните, что тесты вы пишете не для себя, поэтому результаты тестирования должны быть удобными.
Если вы делаете автотесты для тестировщика — дайте доступ к запуску из TMS.
В TestRail интеграция ручных и автотестов делается по API. Для этого можно добавить кнопку в TMS и на нее повесить скрипт с конфигурацией запуска вашего тест-сьюта на пайплане.
В Allure TestOps это можно сделать из UI, просто выставив нужное окружение в конфигурации запуска.
Если вы хотите, чтобы тестами пользовались разработчики — сделайте запуск в пайплайне, чтобы ваши коллеги могли сами запускать тест-сьюты на релизах, PR и мерджах.
С менеджерами немного сложнее, потому что результаты тестов сами по себе их не очень интересуют. В этом случае можно попробовать делать кастомные страницы, на которых показать данные о фичах, бранчах, результатах тестирования и прочем. Попробуйте настроить красивые дашборды в Grafana или Yandex.Datalens.
Разбор результатов
Перезапускайте ваши тесты. Тесты могут падать из-за миллиона разных факторов, начинающихся от проблем с сетью, заканчивая Луной в доме Сатурна. Отследить и исправить такие факторы можно не всегда, но если тесты проходят нестабильно, гоняйте их до позеленения. На самом деле, конечно, двух-трех прогонов будет достаточно, чтобы отсеять странности от проблем. Для этого в Gradle есть официальный Test Retry Gradle plugin, а в Maven — Rerun Failing Tests.
На ранних этапах flaky-тесты и их причины будут вашему заказчику неинтересны, ему будет интересно общее состояние продукта. Однако, чтобы не было ощущения, что мы «замыливаем» проблемы с красными тестами, делая несколько прогонов, можно запускать два инстанса с перезапуском (для заказчиков/стейкхолдеров) и без него (для себя, чтобы была возможность увидеть каждое непонятное падение, пострадать и посыпать голову пеплом).
Настройте категории тестов. Как только вы начнете постоянно гонять тесты в разных бранчах, в разное время, в разных окружениях, определение причин падения теста и категоризация проблем станет актуальной задачей.
Просто представьте, что 5% ваших тестов падают, при этом всего у вас 100 тестов — разбор пяти падений не займет много времени. Но если за день запустить тот же самый тест-сьют 10 раз, то придется разбирать и в 10 раз больше падений, жертвуя своим драгоценным временем (которое мы пытаемся сделать более продуктивным).
В Allure Report эта задача решается тем, что у тестов есть четыре основных статуса: skipped, broken, failed, passed, —, а также есть простой JSON-реестр реестр категорий, который по Regex-сообщениям распределяет свалившиеся тесты. В результате получается понятный список категорий, по которым разложены тесты, и вам надо разбирать только 3–5–7 причин падения 5% из 1000 свалившихся тестов. Для команд побольше, в Allure TestOps есть возможность создавать дефекты и работать с категориями прямо из web-интерфейса, так что если сейчас прям кольнуло в сердце — попробуйте взглянуть на разбор результатов по-новому.
Не копите технический долг. Этот пункт сильно пересекается с созданием зоопарка инструментов, о котором я писал ранее, с одним дополнением. Каждый раз, когда вы обнаруживаете непонятное поведение инструмента, теста или инфраструктуры, заводите задачки на их исправление, а не оставайтесь пленниками костыльных обходных способов эти баги проигнорировать. На самом деле, если вы справитесь с тем, чтобы автоматизировать рутину по запускам тест-ранов, разбором результатов или обновлением документации, у вас появится время на работу с техническим долгом.
Чаще всего в техническом долге оказываются довольно интересные задачи: допилить инструменты, разобраться с инфраструктурой, — такие штуки обычно позволяют разобраться с проблемами, на которые многие забивают, хотя они сделают из вас более ценного специалиста, а в долгосрочной перспективе будут приносить выгоду компании.
Показываем отчеты
Отчеты нужны не вам. Помните об этом. Вам для понимания происходящего будет достаточно почитать стектрейс. Но большинству ваших коллег этого достаточно не будет.
Экспорт отчетов прогона автотестов в ТМС для коллег-тестировщиков. Можно сколько угодно говорить о том, что ручное и автоматизированное тестирование это два разных мира, но по факту, все тестировщики работают на единый результат. Постарайтесь сделать отчеты максимально подробно, чтобы вашим коллегам было удобно и понятно.
Экспорт результатов (багов и дефектов) в трекер для коллег-разработчиков. Следует стремиться к состоянию, когда разработчики видят ваши тесты, принимают их результаты и понимают, о чем говорят полученные отчеты.
Умейте делать кастомные отчеты быстро. Иногда коллегам или руководителям нужны какие-то специфичные данные о ходе тестирования или разработки. Для этого, конечно, важно правильно хранить и помечать все тесты, чтобы потом нарезать данные как в Allure.
Поймите, кому будут полезны отчеты о ходе и результатах тестирования и организуйте постоянную и стабильную инфраструктуру для их генерации.
Итоги
Давайте посмотрим, что у нас получается в итоге:
Тесты надо писать: выбирайте тулы и подходы, но не увлекайтесь. Оверхед на обслуживание вашего тулбокса должен быть меньше объема вашей операционной работы.
Тесты надо гонять: утром, вечером, перед PR и после ночных релизов. Чем больше — тем лучше. Готовьте и автоматизируйте инфраструктуру для многочисленных запусков в разных окружениях.
Хорошо бы понимать, как тесты прошли. Много запусков — много красных тестов. Старайтесь категоризировать типы ошибок автоматически.
И последнее — хорошо бы, чтобы результаты тестирования видел и понимал кто-то, кроме вас. Покажите тестерам, разработчикам и менеджерам результаты так, чтобы они могли их использовать в жизни.
А теперь давайте посмотрим на определение TestOps в Википедии:
TestOps is often considered a subset of DevOps, focusing on accelerating the practice of software testing within agile development methodologies. It includes the operations of test planning, managing test data, controlling changes to tests, organizing tests, managing test status, and gaining insights from testing activities to inform status and process improvements.
Вы поймете, что все это звенья единой системы, которая и называется TestOps. В апреле я постараюсь подготовить более «фундаменьальную» статью о TestOps, в которой постараюсь рассказать об этом подходе не столько со стороны практик и тулинга, сколько со стороны ее места в мире разработки, принципах и месте в DevOps.
P.S. Важно понимать, что Ops в контексте TestOps значит operations в тестировании, а не operations на стороне клиента.
