Тестируемая архитектура. Часть 2: абстрактность и наблюдаемое поведение
В прошлой части мы определили основную проблему: исходный код любой программы со временем устаревает. Это выражается в росте сложности разработки. Данное утверждение не требует доказательств, ведь почти каждый разработчик сталкивался с подобной ситуацией и понимает, о чем идет речь.
Основной способ борьбы с неизбежным усложнением ПО — модификация главной причины — структуры, тех самых деталей реализации, невидимых конечным пользователям. Но рефакторинг чрезвычайно непрост, особенно при работе с достаточно сложными или вовсе незнакомыми проектами. Причина тому — регресс, от которого призваны нас защитить тесты, но не любые, а те, которые обладают достаточными показателями в приведенных ранее свойствах.

Интересно, что разработка таких «правильных» тестов заставляет нас изменять архитектуру определенным образом.
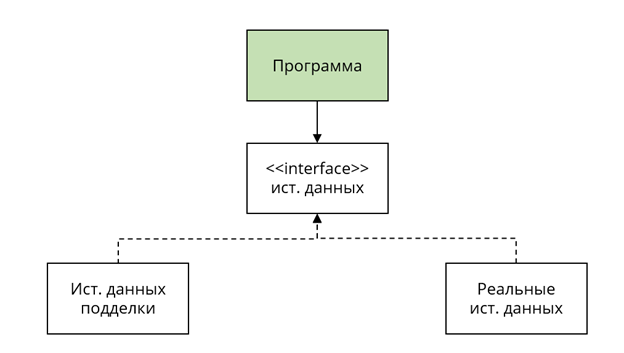
Архитектура, полученная в конце прошлой части.
Программа изначально была атомарным монолитом, а теперь разделена на три элемента: источники данных, их контракт и блок «Программа».
Компиляция как метод тестирования
Давайте ненадолго отвлечемся и отметим один занимательный факт: привычная система типов и процесс статической валидации (компиляции), построенной на ней, — это очередной метод тестирования! Доказательство данного утверждения заключается в наличии самой возможности оценки этого явления с точки зрения четырех основных свойств, описанных ранее:

Защита от регресса
Типы — эффективный способ предотвращения и борьбы с дефектами. Степень защиты зависит от следующих параметров:
a. Строгость системы типов. Чем она строже, тем лучше защита от выполнения неподдерживаемых операций. Почему именно операций? А об этом мы поговорим в отдельной серии статей о теории типов.
b. Соответствие модели, представленной в виде типов, реальному положению вещей: общей логике и свойствам домена. При правильном подходе большинство невалидных состояний приложения и композиций элементов будут перехвачены еще на этапе компиляции.
Сопротивляемость рефакторингу
Кажется, что типы не могут сопротивляться рефакторингу совсем, ведь они — деталь структуры, то есть то, что при рефакторинге и изменяется. Дело в том, что тип есть некоторое множество значений, объединенных по определенному признаку. Другими словами, это достаточно абстрактная сущность, которая может пережить большое количество рефакторингов и остаться неизменной.

Сигнатура функции (тип) осталась неизменной, а деталь реализации процедуры поменялась.
Поддерживаемость
Это самый субъективный показатель, ведь целиком и полностью зависит от опыта разработчика, но в общем случае можно считать его достаточно высоким ввиду популярности ЯП со строгой и статической системой типов.
Быстродействие
Вероятно, это самое большое преимущество такого метода тестирования. В наши дни программы компилируются за доли секунды, а значит разработчик поймет, сломал он что-то рефакторингом или нет, сразу, как только закончит набирать код в IDE.
Такие показатели в совокупности делают этот метод тестирования приоритетным. Если какой-то дефект можно исключить с помощью типов (еще на этапе компиляции), лучше так и сделать, нежели прибегать к другим, более затратным методам защиты от регресса.
Содержание компонентов
Вернемся к анализу получившейся архитектуры.
Клиентом будет называться импортирующий компонент, а сервером — импортируемый (то есть клиент использует сервер, а не наоборот).
Обратим внимание на то, что у клиентов (Тесты и Main) есть выбор в том, какие конкретные реализации источников данных использовать:

Но вместе с этим они зависят от строго конкретного интерфейса:

Зависимость от контракта является транзитивной, так как в первую очередь клиенты пытаются использовать блок «Программа»
Это можно сравнить с тем, как клиенты становятся зависимыми от типов аргументов тех функций, которые пытаются вызвать:
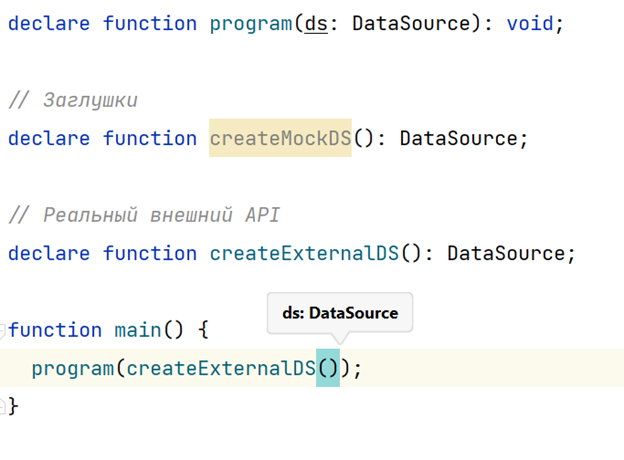
Main зависит от конкретного интерфейса DataSource. Конкретная реализация же не фиксирована и зависит от вызывающей стороны (от функции main в данном случае).
С другой стороны, заметим: как изменение внутренних деталей реализации функции может вызвать изменения в ее внешних аргументах, так и модификация внутреннего устройства блока программы имеет тенденцию (или возможность) вызвать перемены в ее внешнем интерфейсе (контракте для источников данных):

Но изменения в интерфейсе уже породят каскад неизбежных модификаций во всех его имплементаторах и провайдерах, коих обычно гораздо больше.

Здесь стоит отдельно упомянуть достаточно дискуссионный факт: единственная причина существования интерфейса — это его клиент. Именно клиент определяет требования, за счет чего он и подчеркивается как источник изменения интерфейса. Без клиента не существовал бы и контракт, и сервер, который его реализует. Можно сказать, что клиент и его внешний интерфейс связаны общей ответственностью.
Конечно, такая точка зрения слишком идеалистична и не учитывает реальное положение вещей в конкретном случае. Тем не менее, в рамках нашего рассказа именно клиент стоит во главе угла, этот факт и определит ход дальнейшего повествования.
Итого:
Изменения в блоке «Программа» нередко приводят к переменам и в ее внешних интерфейсах. Это вызывает каскад модификаций в реализациях измененного контракта и его провайдерах.
Используя программу, клиент неизбежно использует и ее публичные интерфейсы.
Таким образом можно сказать, что пара (клиент и интерфейс) образует компонент с высокой ответственностью, так называемое ядро системы. Ответственность является высокой по одной единственной причине: изменение этого компонента может вызвать многочисленные модификации в зависимых от него элементах, что было показано ранее на схеме.

Это значит, что разработчик должен обеспечить возможность изменять поведение блока программы, не изменяя или как можно реже модифицируя ее исходный код. Другими словами, она должна быть расширяемой. И часть этой сложной задачи уже решена в рамках организации тестирования! Программу можно использовать с разными источниками данных, не трогая ничего лишнего:

В итоге образуется два слоя:

Слой ядра, тестируемый компонент с высокой ответственностью.
Слой источников данных, нетестируемых компонентов. Единственное требование к элементам этой секции — простота. Они должны быть тривиальными, иначе итоговая защита от регресса будет небольшой.
Инверсия зависимостей
Ясно, что теперь можно изменить реализацию сервера (в нашем случае — конкретных имплементаций источников данных), не касаясь при этом исходного кода его клиентов (это доказывается самой возможностью использовать тестовые заглушки). Но что если вместо реализации сервер изменит свой внешний интерфейс?
Представим, что после очередного обновления API функция getAllUsers вместо простого списка пользователей стала возвращать данные в несколько ином формате:

Казалось бы, это изменение не удовлетворяет контракту в программе, а значит придется изменить интерфейс источников данных. Однако проблему можно решить, воспользовавшись техникой под названием «Адаптер»:
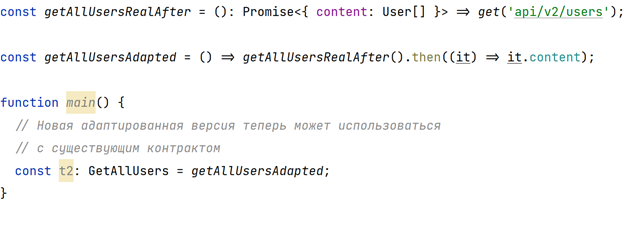
getAllUsersAdapted теперь можно передать ядру без модификаций исходного кода данного слоя.
Даже такое серьезное изменение в публичном контракте конкретного источника данных не заставило ядро измениться. Это говорит о том, что оно полностью не зависит от своих серверов, но в то же самое время серверы остаются зависимыми от контрактов, которые этим самым ядром и определяются.
Можно сказать, что появились две картины происходящего:
На уровне исполнения программы, на этапе runtime, управление передается от Core к Externals (именно ядро вызывает методы репозиториев):


Инверсия зависимостей произошла за счет внедрения дополнительного интерфейса и расположения его в границах компонента Core. Без этого направление зависимостей между runtime и compile time было бы совершено идентичным, что сделало бы ядро зависимым от конкретных источников данных, то есть нерасширяемым относительно данного вектора изменений.
Таким образом между слоями Core и Externals формируется так называемая неполная архитектурная граница. Неполная, потому что Externals ссылается напрямую на элемент слоя Core, на внешний интерфейс. Можно использовать Core с разными Externals, но Externals — только с одним конкретным слоем Core (его интерфейсом если быть точнее).
Открытость и закрытость
Давайте рассмотрим пример. Возьмем слово «лук». Оно состоит из двух компонентов:
Форма. Буквы «л», «у» и «к», идущие друг за другом, образуют «лицо» или «внешность» слова, если мы его видим, и его звучание, если слышим.
Содержание. Смысл слова «лук». Он не фиксирован, а зависит от контекста. Например, в рамках кулинарного шоу речь, скорее всего, пойдет об овоще, а в случае обсуждения соревнований по стрельбе значение будет совершенно иным.
Видно, как при смене контекста форма слова остается прежней, в то время как его содержание изменяется достаточно сильно. Можно сказать, что «лук» описывает множество, включающее в себя все возможные содержания данного слова, конкретные значения которых выбираются исходя из случая:

В мире ПО интерфейс — это форма, которая описывает множество (в данном случае — множество своих имплементаций). В то время как конкретный имплементатор может меняться от случая к случаю, описывающий его интерфейс будет оставаться нетронутым, как бы закрываясь от факта подмены реализации:

Можно увидеть ту же картину, как и в примере со словом «лук»: форма остается неизменной, в то время как содержание изменяется значительно.
Факт того, что интерфейс не всегда реагирует на изменения в своих конкретных реализациях, и делает первый более абстрактным концептом, то есть более устойчивым к изменениям компонентом. Такая устойчивость к изменениям нужна не столько самому интерфейсу, сколько клиентам, которые его используют:
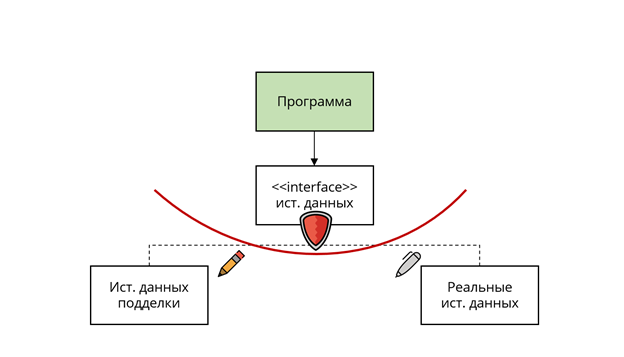
Интерфейс выступает в роли щита, защищающего своих клиентов от изменений в его имплементаторах.
Таким образом можно отметить, что инверсия зависимостей сделала Core закрытым от почти любых изменений в Externals, в то же самое время оставляя ядро открытым к добавлению новых наследников его внешнего интерфейса источников данных, то есть к расширению.
Это достаточно полезное свойство описывается принципом открытости-закрытости компонентов (англ. open-closed principle, OCP), который мы рассмотрим в отдельном цикле статей, посвященных принципам SOLID.
Наблюдаемое поведение
Отвлечемся от анализа структуры и попробуем понять, каким образом можно построить процесс верификации поведения в получившейся архитектуре.
Для начала стоит отметить что приложения бывают разными, а их поведение и окружение совершенно непохожи. Чтобы добавить конкретики, далее примеры будут основываться на типовом веб-приложении, на его клиентской части. Тем не менее сами принципы достаточно абстрактны, поэтому будут полезны вне зависимости от контекста исполнения.
Одним из главных параметров для того, чтобы выбрать способ тестирования, является граница системы. То есть черта, разделяющая программу и её пользователя:
Для разработчика библиотеки утилит коллекций, например, пользователем станет другой разработчик. Таким образом, тесты будут верифицировать поведение, манипулируя исключительно публичным API пакета, как это делал бы реальный клиент библиотеки.
Другой пример — тесты на производительность. Здесь клиентом системы является профилирующий инструмент, он рассматривает поведение системы как, допустим, показатели величины занимаемого процессорного времени и объема памяти.
Если разрабатывается конечное приложение, клиент системы — реальный пользователь, воспринимающий поведение программы через изображение на мониторе. Это и будет наблюдаемым поведением в таком контексте.
От точки, где была проведена граница, зависят не только конечные показатели эффективности тестирования, но и методы верификации.
Давайте остановимся на типовом клиентском приложении и выделим соответствующие методы верификации:
Направление стрелки соответствует направлению течения информации. В нашем случае информация идет от приложения к монитору, происходит вывод, другими словами.
Интересно, но монитор — это не единственное место, куда приложение проецирует информацию. Еще одной точкой вывода может стать локальное хранилище или сетевой интерфейс. В приведенной архитектуре методы, работающие с данными сущностями, уже были выделены в отдельный слой Externals.

Можно сказать, что локальное хранилище и сетевой интерфейс — это своеобразный «монитор». Стандартный снимок экрана в нем заменяется простым журналированием мутирующих методов. Важно контролировать то, в каком порядке и с какими аргументами последние были вызваны, ведь все это будет «замечено» сервером, то есть может повлиять на его наблюдаемое поведение (и, как следствие, — поведение его клиентов) в реальных условиях.

Журнал вызовов может быть представлен в следующем виде:

Методы представлены в массиве, так как важен порядок. То же верно и для аргументов и их значений.
При первом прогоне тестового сценария журнал записывается в так называемый baseline и используется в качестве целевого экземпляра. При последующих запусках тестов актуальные журналы сравниваются с теми, что записаны в baseline. Если они совпадают, то тест считается пройденным, в противном случае возникает ошибка.
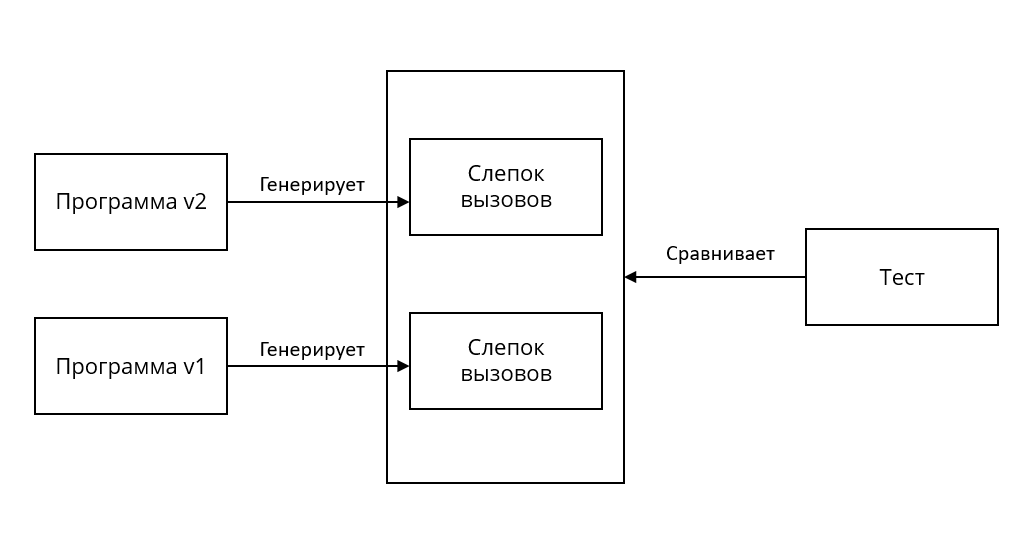
Если слепки вызовов совпали, то в таком случае, наблюдаемое поведение обеих версий программ считается идентичным.
Таким образом обычно и выполняется верификация поведения для данного источника вывода информации из приложения.
Команды и запросы
Помимо вывода информации (будь то монитор, сетевой интерфейс или что-либо еще), система также ожидает и ввода. Очевидными источниками (в случае человека и настольного компьютера) являются, например, клавиатура и мышь:

Сохраняя не совсем очевидную аналогию, то же самое можно сказать и про сервер. Вводом здесь будет считаться любой метод, возвращающий информацию. Если говорить про REST, то это любой GET-метод. Важно то, что такая функция не должна обладать сайд-эффектом, в противном случае это будет все тем же выводом информации из приложения.

Для простоты далее будем называть функции ввода информации в приложение запросами (queries), а те методы, которые выполняют вывод, — командами (commands).
Запросы — это методы, не предполагающие никаких сайд-эффектов. Но они могут быть (и чаще всего являются) не идемпотентными, то есть результат их выполнения не зависит от их аргументов.
Команды, наоборот, являются методами, обладающими внешним эффектом, при этом для нас совершено неважно, идемпотентные они или нет.
Стоит отметить, что сайд-эффект команды чаще всего проявляется в изменении информации, возвращаемой одним или несколькими запросами. Например, команда «удалить пользователя» изменит результат вызова метода для получения списка этих же пользователей (и других методов, связанных с изменяемым источником данных):

Такое упорядочивание (систематизация) содержимого Externals позволяет организовывать реактивность, кэширование и другие комплексные поведения внутри последнего в более простом и управляемом виде. В случае тестов факт наличия CQS (command and query separation) также может эксплуатироваться дополнительно. (Это будет показано в следующей части.)

Итоговая схема портов ввода/вывода приложения.
Пожалуй, на этом стоит закончить вторую часть повествования. В следующей главе мы поговорим о том, как выстроить процесс верификации поведения на основе приведенной структуры портов I/O, а также обсудим чрезвычайно важную роль принципа подстановки и его влияние на процесс тестирования. Ну и, конечно же, продолжим свое уверенное движение к той самой тестируемой архитектуре.
