Дообучение saiga2_7b_lora
Всем привет дорогие читатели!
В данном руководстве я бы хотел рассказать и показать вам, как дообучить 7-миллиардную модель Сайги Ильи Гусева @Takagi под свои задачи. Данная статья является своеобразным туториалом по дообучению модели на Kaggle. Однако в наше время написано много статей про дообучение LLM, но все они в большинстве англоязычные или авторы используют свои вычислительные мощности загоняя в тупик тех, у кого возможности обучать на своём «железе» нет.

Сгенерировано GigaChat
Начнём пожалуй с вопроса «Почему Kaggle, а не Google Collab?»
Преимущество Kaggle над Google Collab для меня заключается в том, что вычислительные мощности, которые представляет данная платформа, выдаются на 30 часов каждую неделю (если говорить про GPU). Плюс Notebook, в котором вы сейчас работаете, не завершит свою работу в течении 12 часов (если какой-то код там выполняется), в отличие от Collab`а, который может вам завершить работу если вы решили отдохнуть и запустили код на обучение.
Выделенного времени более чем достаточно если вы изначально создадите все скрипты для обучения вашей модели.
Датасет
Как должен выглядеть свой датасет для обучения? Этим вопросом я задавался постоянно, когда приходилось обучать любую LLM. И в один момент пришло осознание.

Куда же без мемов
Для начала разберём, что на вход подаётся модели. Важный момент! Не то, какой промт вы ей передаёте, а то какой формат имеет системный, пользовательский промт и ответ модели.
Для этого я использовал код, который был предложен на Hugging Face для модели Сайги от Ильи Гусева. По хорошему можно было разобраться в файлах обучения LLama на GitHub проекта rulm и посмотреть как был «предобработан» датасет для обучения модели, но спасибо автору, что он в карточке модели предоставил код для её запуска.
Ссылка на код для проведения данного эксперемента
Итак, нас интересует строка 9 в методе generate.
def generate(model, tokenizer, prompt, generation_config):
data = tokenizer(prompt, return_tensors="pt")
data = {k: v.to(model.device) for k, v in data.items()}
output_ids = model.generate(
**data,
generation_config=generation_config
)[0]
output_ids = output_ids[len(data["input_ids"][0]):]
output = tokenizer.decode(output_ids, skip_special_tokens=True)
return output.strip()А именно output и параметр skip_special_tokens, который отвечает за вывод специальных токенов (о них поговорим ниже). Изменяем значение на False. Далее для наглядности напишем метод для взаимодействия с классом Conversation.
def get_message(inputs):
conversation = Conversation()
conversation.add_user_message(inputs)
prompt = conversation.get_prompt(tokenizer)
print('Промт', '\n', '*'*100)
print(prompt)
print('*'*100)
output = generate(model, tokenizer, prompt, generation_config)
return outputВ данном методе мы создаем объект класса, вызываем добавление пользовательского промта и получаем промт, который передается в модель, но мы его перед этим выведем.
Теперь нам нужно сформировать любой запрос, чтобы посмотреть формат промта для модели и ответа модели.
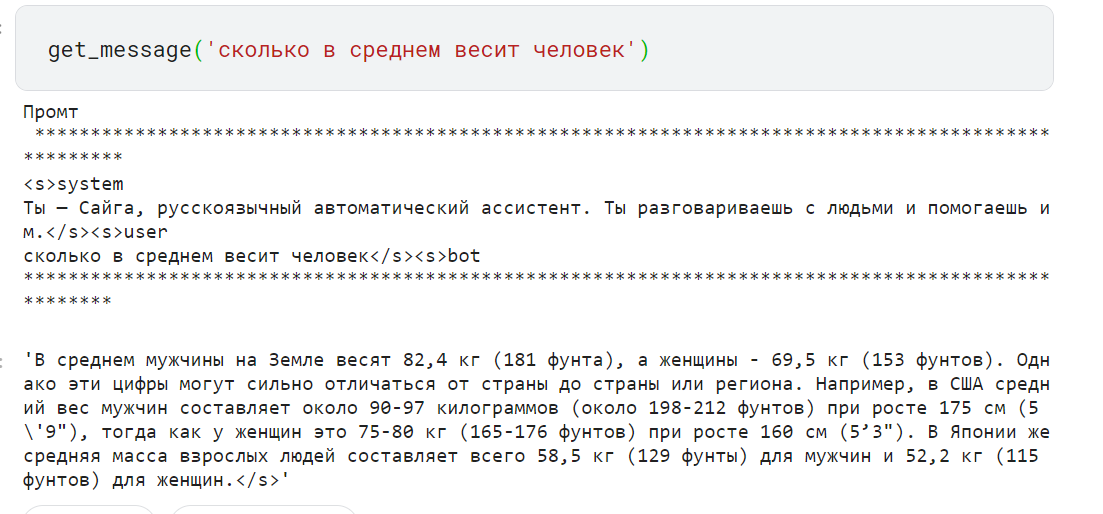
Рисунок 1 — Пример запроса и ответа модели
На рисунке видно, что мы не просто передаем запрос и разделяем все промты специальными токенами.
На рисунке 1 видно что предобработанная строка с запросом заканчивается на »… bot», а ответ модели заканчивается на »… ». Именно поэтому модель понимает, где начать генерировать текст (с токена »bos_token_id») и в конце своей генерации ставит токен »eos_token_id».
Данные токены заложены в конфигурации токенизатора, это можно проверить с помощью кода ниже.
print(tokenizer.bos_token_id)
print(tokenizer.eos_token_id)
print(tokenizer.decode([1]))
print(tokenizer.decode([2]))На выходе мы получаем

Рисунок 2 — Вывод id токенов и декодирование
В промте также присутствуют слова »system»,»user» и »bot», которые идут сразу же после токена »bos». Их тоже надо будет учитывать при создании датасета. Токенизация представлена на рисунке 3.

Рисунок 3 — Токенизация слов «system», «user» и «bot»
Теперь подытожим и соберём всё вместе, чтобы понять на каких строках будет обучатся наша модель.
"""system
Тут какой-то системный промтuser
Тут мы задаём запросbot
Тут модель генерирует текст"""Вот и всё, пример одного экземпляра датасета уже сделан (шутка нет).
Осталось подготовить наши данные в определенном формате и уже можно создавать методы для предобработки датасета.
Какой формат датасета можно использовать?
Для удобства можно составить «неправильный» json, в котором будут записаны все наши данные.
Формат датасета в двух словах. Это json в котором каждая новая строка представляет собой словарь с ключами »system»,»user» и »bot». Значение для каждого ключа заполняем системным, пользовательским и ответом бота соответственно.
В конечном итоге у вас должен получится примерно такой вид

Рисунок 4 — Пример датасета в json файле
Я же создал датасет разделил его на 2 файла: train.json и val.json. Файл валидации служит для оценки модели на i-ой эпохе и проверки переобучения модели.
Подготовим ноутбук для предобработки и обучения модели
Для начала загружаем модель LLama2 и адаптер LoRa (обязательно ставим параметр is_trainable = True)
MODEL_NAME = "IlyaGusev/saiga2_7b_lora"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
st_time = time.time()
# bnb_config = BitsAndBytesConfig(
# load_in_4bit=True,
# bnb_4bit_quant_type="nf4",
# bnb_4bit_compute_dtype= torch.float16,
# bnb_4bit_use_double_quant=False,
# )
config = PeftConfig.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
load_in_8bit = True,
torch_dtype=torch.float16,
device_map="auto",
# quantization_config=bnb_config
)
model = PeftModel.from_pretrained(
model,
MODEL_NAME,
torch_dtype=torch.float16,
# torch_dtype=torch.bfloat16,
is_trainable = True,
# device_map="auto"
).to(device)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, use_fast=False)
generation_config = GenerationConfig.from_pretrained(MODEL_NAME)
print(generation_config)
print(f'Прошло времени {time.time() - st_time}')Теперь загрузим наши данные с помощью метода load_dataset
data = load_dataset(
"json",
data_files={
'train' : '/kaggle/input/fine-tunning-llama/train.json' ,
'validation' : '/kaggle/input/fine-tunning-llama/val.json'
}
)
dataCоставим метод для предобработки данных, чтобы каждый элемент датасета был словарём с ключами input_ids, attention_mask, labels
CUTOFF_LEN = 3584
def generate_prompt(data_point):
promt = f"""system
{data_point['system']}user
{data_point['user']}bot
{data_point['bot']}"""
# print(promt)
return promt
def tokenize (prompt, add_eos_token=True):
result = tokenizer(
prompt,
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
return_tensors=None,
)
if (
result["input_ids"][-1] != tokenizer.eos_token_id and len(result["input_ids"]) < CUTOFF_LEN
and add_eos_token
):
result["input_ids"].append(tokenizer.eos_token_id)
result["attention_mask"].append(1)
result["labels"] = result["input_ids"].copy()
return result
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(data_point)
tokenized_full_prompt = tokenize(full_prompt)
# print(tokenized_full_prompt)
return tokenized_full_promptСделаем предобработку для каждого элемента
train_data = (
data["train"].map(generate_and_tokenize_prompt)
)
val_data = (
data["validation"].map(generate_and_tokenize_prompt)
)Далее задаём параметры обучения
per_device_train_batch_size — размер батча на каждую видеокарту (так как у нас она одна, все вычесления будут происходить на ней)
gradient_accumulation_steps — накапливание градиента для экономии видеопамяти
max_steps — количество шагов обучения
learning_rate — скорость обучения
fp16 — используем точность fp16. О этом параметре можно почитать тут
logging_steps — вывод метрики потерь через данное количество шагов, которое здесь зададим
optim — оптимизатор
evaluation_strategy — стратегия вычислений, так как у нас стоят шаги (steps), то записываем steps
eval_steps — подсчет метрики потерь каждые N шагов, которые здесь укажем
save_steps — параметр сохранения чекпоинтов обучения через каждые N раз, которые здесь задаём
output_dir — параметр для сохранения модели и чекпоинтов
save_total_limit — количество сохранённых чекпоинтов
load_best_model_at_end — загрузка лучшей модели после обучения
report_to — сохранить историю обучения на какой-либо сервис
overwrite_output_dir — перезапись директории для сохранения модели
Мои параметры обучения
BATCH_SIZE = 4
MICRO_BATCH_SIZE = 2
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
LEARNING_RATE = 3e-4
TRAIN_STEPS = 100
OUTPUT_DIR = "/kaggle/working/tmp"
training_arguments = transformers.TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
# warmup_steps=200,
max_steps=TRAIN_STEPS,
learning_rate=LEARNING_RATE,
fp16=True,
logging_steps=10,
optim="adamw_torch",
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=10,
save_steps=10,
output_dir=OUTPUT_DIR,
save_total_limit=10,
load_best_model_at_end=True,
report_to=None,
overwrite_output_dir=True, # Overwrite the content of the output dir
)Далее выбираем data_collator для пакетной обработки наших данных (DataCollatorForSeq2Seq). И в конечном итоге запускаем обучение
data_collator = transformers.DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
)
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=training_arguments,
data_collator=data_collator
)
model = torch.compile(model)
trainer.train()
model.save_pretrained(OUTPUT_DIR)Готово!
Обучение завершено и можно запушить наш дообученный адаптер на Hugging Face
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("Your project", use_auth_token=True)Конвертирование модели в GGUF формат или как запустить модель на «калькуляторе»
Если вы хотите чтобы ваша модель работала и занимала меньше памяти и чтобы она запускалась у вас на «калькуляторе» с 6 гигабайтами RAM, то для этого необходимо будет квантовать вашу модель.
Важно упомянуть, что квантование модели будет означать небольшую потерю точности. В данном случае будем квантовать модель до 4 бит. О том как квантовать модель оставлю ссылку в конце статьи.
Для начала мы должны склеить наши дообученные слои LoRa с нашей моделью.
Клонируем репозитории rulm и llama.cpp
Далее прописываем необходимые пути:
self_instruct_dir — путь до self_instruct в проекте rulm
checkpoint — чекпоинт нашей лучшей модели
merged_model_name — куда мы хотим сохранить итоговую модель в формате PyTorch
Далее переходим в папку self_instruct_dir и вызываем скрипт convert_to_native нашими параметрами
Пример параметров
self_instruct_dir = '/kaggle/working/rulm/self_instruct'
checkpoint = "/kaggle/working/tmp/checkpoint-40"
merged_model_name = '/kaggle/tmp/merged_test_model.pt'
%cd {self_instruct_dir}!python -m src.tools.convert_to_native {checkpoint} {merged_model_name} --device=cuda --enable_offloading
Рисунок 5 — Склеенная модель в формате PyTorch
Конвертируем модель в GGUF формат
Перед конвертацией нам нужно сохранить Tokenizer в любую папку. Tokenizer берём той же самой модели Saiga
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("IlyaGusev/saiga2_7b_lora", use_fast=False)
tokenizer.save_pretrained('/kaggle/working/tmp/checkpoint-40/')Далее переходим в папку llama.cpp и задаём необходимые параметры для конвертирования модели.
model_dir — путь до «склеенной» модели
checkpoint (можно было назвать tokenizer_path) — путь до сохранённого токенизатора
output_model — куда сохраняем нашу модель
ctx — количество tokens на входном слое (лучше оставить такое же значение как и у оригинальной модели)
Пример параметров
model_dir = '/kaggle/tmp/merged_test_model.pt'
checkpoint = "/kaggle/working/tmp/checkpoint-40"
output_model = "/kaggle/tmp/model-f16.gguf"Далее запускаем скрипт convert.py
!python convert.py {model_dir} --vocab-dir {checkpoint} --outfile {output_model} --outtype f16 --ctx 4096Квантование модели до 4 бит
Для начала вызываем ! make quantize
Далее также задаём параметры
model_gguf — наша 16 битная модель gguf
quant_model — куда сохраняем модель + название
quantization_type — тип квантования (используем q4_0)
После объявления параметров запускаем скрипт
! ./quantize {model_gguf} {quant_model} {quantization_type}Проверяем нашу модель
Скрипт для фикса библиотеки, чтобы запустить модель GGUF на GPU
%cd ~
!git clone --recursive https://github.com/ggerganov/llama.cpp.git
%cd llama.cpp
!make LLAMA_CUBLAS=1 -j libllama.so
# HACK: Use custom compiled libllama.so
%cp ~/llama.cpp/libllama.so /opt/conda/lib/python3.10/site-packages/llama_cpp/libllama.soСкрипт для запуска модели
from llama_cpp import Llama
from tqdm import tqdm
SYSTEM_PROMPT = "Ты извлекаешь термины и определения из текста"
SYSTEM_TOKEN = 1587
USER_TOKEN = 2188
BOT_TOKEN = 12435
LINEBREAK_TOKEN = 13
# model_path = '/kaggle/tmp/model-q4_K.gguf'
n_ctx = 2000 #
top_k = 30
top_p = 0.9
temperature = 0.01
repeat_penalty = 1.1
ROLE_TOKENS = {
"user": USER_TOKEN,
"bot": BOT_TOKEN,
"system": SYSTEM_TOKEN
}
def get_message_tokens(model, role, content):
message_tokens = model.tokenize(content.encode("utf-8"))
message_tokens.insert(1, ROLE_TOKENS[role])
message_tokens.insert(2, LINEBREAK_TOKEN)
message_tokens.append(model.token_eos())
return message_tokens
def get_system_tokens(model):
system_message = {
"role": "system",
"content": SYSTEM_PROMPT
}
return get_message_tokens(model, **system_message)
def chat_saiga(message, model):
system_tokens = get_system_tokens(model)
tokens = system_tokens
# model.eval(tokens)
message_tokens = get_message_tokens(model=model, role="user", content=message)
role_tokens = [model.token_bos(), BOT_TOKEN, LINEBREAK_TOKEN]
tokens += message_tokens + role_tokens
# print(tokens)
# detokenize = model.detokenize(tokens)
# print(model.tokenize(full_prompt))
generator = model.generate(
tokens,
top_k = top_k,
top_p = top_p,
temp = temperature,
repeat_penalty = repeat_penalty,
reset = True
)
# print(len([token for token in generator]))
result_list = []
for token in generator:
token_str = model.detokenize([token]).decode("utf-8", errors="ignore")
tokens.append(token)
if token == model.token_eos():
break
print(token_str, end="", flush=True)
result_list.append(token_str)
return ''.join(result_list)
try:
del model
except:
pass
# model_path = '/kaggle/working/model-q4_0.gguf'
model_path = '/kaggle/working/model-q4_0.gguf'
n_ctx = 3096 #
model = Llama(
model_path = model_path,
n_ctx = n_ctx,
n_gpu_layers=-1
)
Рисунок 6 — Вывод модели
В итоге модель переобучилась, но в целом она формирует нужный формат вывода, а именно список словарей терминов. Если подготовить более качественный датасет, то будут результаты намного выше.
Причина по которой создан данный туториал
Этот туториал появился, когда мы в AI-команде Инлайн работали над интеграцией Сайги с вызовом функций и для обращения к внешним API, чтобы LLM могла запрашивать внешнюю информацию для ответов на вопросы.
И мы хотели бы, чтобы каждый мог при желании сам попробовать дообучить и оценить свою модель LLM
Ссылки на полезные источники
Ссылка на Kaggle для полного цикла обучения
Ссылка на Kaggle для запуска модели Saiga2_7b
Ссылка на проект rulm
Ссылка на проект llama.cpp
Отдельно хочу поблагодарить за проделанную работу автора Saiga Илью Гусева и автора llama.cpp Георгия Герганова
