Тестирование конфигурации для Java-разработчиков: практический опыт

С тестами для кода всё понятно (ну, хотя бы то, что их надо писать). С тестами для конфигурации всё куда менее очевидно, начиная с самого их существования. Кто-то их пишет? Важно ли это? Сложно ли это? Каких именно результатов можно добиться с их помощью?
Оказывается, это тоже очень полезно, начать делать это очень просто, и при этом в тестировании конфигурации есть много своих нюансов. Каких именно — расписано под катом на основании практического опыта.
В основе материала — расшифровка доклада Руслана cheremin Черемина (Java-разработчика в Deutsche Bank). Далее — речь от первого лица.
Меня зовут Руслан, я работаю в Deutsche Bank. Начнем мы с этого:

Здесь очень много текста, издалека может показаться, что это русский. Но это неправда. Это очень древний и опасный язык. Я сделал перевод на простой русский:
- Все персонажи выдуманы
- Пользуйтесь с осторожностью
- Похороны за свой счет
Опишу вкратце, о чем я вообще сегодня собираюсь говорить. Предположим, у нас есть код:

То есть изначально у нас была какая-то задача, для ее решения пишем код, и он, предположительно, зарабатывает нам деньги. Если этот код почему-то работает неправильно — он решает неправильную задачу и зарабатывает нам неправильные деньги. Бизнес такие деньги не любит — они плохо смотрятся в финансовых отчетах.
Поэтому для нашего важного кода у нас есть тесты:

Обычно есть. Сейчас уже, наверное, почти у всех есть. Тесты проверяют, что код решает правильную задачу и зарабатывает правильные деньги. Но сервис не ограничивается кодом, и рядом с кодом есть еще конфигурация:

По крайней мере, почти во всех проектах, где я участвовал, такая конфигурация была, в том, или ином виде. (Я могу вспомнить только пару случаев из своих ранних UI-лет, где не было файлов конфигурации, а все конфигурировалось через UI) В этой конфигурации лежат порты, адреса, параметры алгоритмов.
Почему конфигурацию важно тестировать?
Вот в чём фишка: ошибки в конфигурации вредят исполнению программы ничуть не меньше ошибок в коде. Они тоже могут заставлять код выполнять неправильную задачу — и далее смотри выше.
А находить ошибки в конфигурации еще сложнее, чем в коде, так как конфигурация обычно не компилируется. Я привел в пример properties-файлы, вообще есть разные варианты (JSON, XML, кто-то в YAML хранит), но важно, что ничто из этого не компилируется и, соответственно, не проверяется. Если вы случайно опечатаетесь в Java-файле — скорее всего, он просто не пройдет компиляцию. А случайная опечатка в property никого не взволнует, она так и пойдет в работу.
И IDE ошибки в конфигурации тоже не подсвечивает, потому что она знает про формат (например) property-файлов только самое примитивное: что должны быть ключ и значение, а между ними «равно», двоеточие или пробел. А вот о том, что значение должно быть числом, сетевым портом или адресом — IDE ничего не знает.
И даже если протестировать приложение в UAT или в Staging-окружении — это тоже ничего не гарантирует. Потому что конфигурация, как правило, в каждом окружении своя, и в UAT вы протестировали только UAT-конфигурацию.
Еще одна тонкость в том, что даже в продакшне ошибки конфигурации порой проявляются не сразу. Сервис может вовсе не стартовать — и это еще хороший сценарий. Но он может стартовать, и работать очень долго — до момента X, когда потребуется именно тот параметр, в котором ошибка. И тут вы обнаруживаете, что сервис, который в последнее время даже практически не менялся, внезапно перестал работать.
После всего, что я сказал — казалось бы, тестирование конфигураций должно быть актуальной темой. Но на практике выглядит как-то так:
По крайней мере, у нас так было — до определенного момента. И одна из задач моего доклада — чтобы у вас тоже перестало выглядеть так. Я надеюсь, что у меня получится вас к этому подтолкнуть.
Три года назад у нас в Дойче Банке, в моей команде, работал QA-лидом Андрей Сатарин. Именно он принес идею тестирования конфигураций — то есть просто взял и закоммитил первый такой тест. Полгода назад, на предыдущем Heisenbug, он делал доклад про тестирование конфигурации, как он его видит. Рекомендую посмотреть, потому что там он дал широкий взгляд на проблему: как со стороны научных статей, так и со стороны опыта крупных компаний, которые сталкивались с ошибками конфигурации и их последствиями.
Мой доклад будет более узким — о практическом опыте. Я буду рассказывать про то, с какими проблемами я, как разработчик, сталкивался, когда писал тесты конфигураций, и как я решал эти проблемы. Мои решения могут не быть лучшими решениями, это не best practices — это мой личный опыт, я старался не делать широких обобщений.
Общий план доклада:
- «Что можно успеть до обеда в понедельник»: простые полезные примеры.
- «Понедельник, два года спустя»: где и как можно сделать лучше.
- Поддержка для рефакторинга конфигурации: как добиться плотного покрытия; программная модель конфигурации.
Первая часть — мотивационная: я опишу самые простые тесты, с которых все начиналось у нас. Будет большое количество разнообразных примеров. Я надеюсь, что хоть один из них у вас срезонирует, то есть вы увидите у себя какую-то похожую проблему, и ее решение.
Сами по себе тесты в первой части простые, даже примитивные — с инженерной точки зрения там нет rocket science. Но именно то, что их можно сделать быстро — особенно ценно. Это такой «легкий вход» в тестирование конфигурации, и он важен, потому что есть психологический барьер перед написанием этих тестов. И я хочу показать, что «так делать можно»: вот, мы делали, у нас неплохо получилось, и пока никто не умер, уже года три живем.
Вторая часть про то, что делать после. Когда вы написали много простых тестов — встает вопрос поддержки. Какие-то из них начинают падать, вы разбираетесь с ошибками, которые они, предположительно, высветили. Оказывается, что это не всегда удобно. А еще встает вопрос о написании более сложных тестов — ведь простые случаи вы уже покрыли, хочется что-то поинтереснее. И тут снова нет best practices, я просто опишу какие-то решения, которые сработали у нас.
Третья часть про то, как тестирование может поддержать рефакторинг достаточно сложной и запутанной конфигурации. Опять case study — как мы это сделали. С моей точки зрения это пример того, как тестирование конфигурации может масштабироваться для решения более крупных задач, а не только для затыкания мелких дырочек.
Часть 1. «Так делать — можно»
Сейчас сложно понять, какой был первый тест конфигурации у нас. Вот в зале Андрей сидит, он может сказать, что я наврал. Но мне кажется, что начиналось все с этого:

Ситуация такая: у нас есть n сервисов на одном хосте, каждый из них поднимает свой JMX-сервер на своем порту, экспортирует какие-то мониторинговые JMX-ы. Порты для всех сервисов сконфигурированы в файле. Но файл занимает несколько страниц, и там еще множество других свойств — зачастую оказывается, что порты разных сервисов конфликтуют. Несложно ошибиться. Дальше всё тривиально: какой-то сервис не поднимается, за ним не поднимаются за зависимые от него — тестеры бесятся.
Решается эта проблема в несколько строк. Этот тест, который (как мне кажется) был у нас первым, выглядел так:

В нем ничего сложного: идем по папке, где лежат файлы конфигурации, загружаем их, парсим как properties, отфильтровываем значения, имя которых содержат «jmx.port», и проверяем, что все значения — уникальные. Нет необходимости даже конвертировать значения в integer. Предположительно, там одни порты.
Моя первая реакция, когда я это увидел, была смешанной:
Первое ощущение: что это такое в моих красивых unit-тестах? Зачем мы полезли в файловую систему?
А затем пришло удивление: «Что, так можно было?»
Я об этом говорю, потому что, кажется, есть какой-то психологический барьер, мешающий писать такие тесты. С тех пор прошло уже три года, в проекте полным-полно таких тестов, но я часто вижу, что мои коллеги, натыкаясь на сделанную ошибку в конфигурации, не пишут на нее тесты. Для кода уже все привыкли писать регрессионные тесты — чтобы найденная ошибка больше не воспроизводилась. А для конфигурации так не делают, что-то мешает. Тут есть какой-то психологический барьер, с которым надо справляться — поэтому я упоминаю о такой своей реакции, чтобы вы её у себя тоже узнали, если появится.
Следующий пример почти такой же, но немного изменен — я убрал все «jmx». В этот раз мы проверяем все свойства, которые называются «что-то там-port». Они должны представлять собой целые значения, и являться валидным сетевым портом. За Matcher validNetworkPort () скрывается наш кастомный hamcrest Matcher, который проверяет, что значение выше диапазона системных портов, ниже диапазона эфемерных портов, ну и нам известно, что какие-то порты у нас на серверах заранее заняты — вот весь их список тоже спрятан в этом Matcher.
Этот тест по-прежнему очень примитивный. Заметьте, что в нем нет указаний, какое конкретно свойство мы проверяем — он массовый. Один-единственный такой тест может проверить 500 свойств с именем »…port», и верифицировать, что все они — целые числа, в нужном диапазоне, со всеми нужными условиями. Один раз написали, дюжина строчек — и всё. Это очень удобная возможность, она появляется, потому что конфигурация имеет простой формат: две колонки, ключ и значение. Поэтому её можно так массово обрабатывать.
Еще один пример теста. Что мы здесь проверяем?

Он проверяет, что в продакшн не просачиваются реальные пароли. Все пароли должны выглядеть как-то так:

Такого рода тестов на property-файлы можно написать очень много. Я не буду приводить больше примеров — не хочу повторяться, идея очень простая, дальше всё должно быть понятно.
… и после написания достаточного количества таких тестов всплывает интересный вопрос:, а что мы подразумеваем под конфигурацией, где находится ее граница? Вот property-файл мы считаем конфигурацией, его мы покрыли —, а что ещё можно покрыть в таком же стиле?
Что считать конфигурацией
Оказывается, что в проекте есть множество текстовых файлов, которые не компилируются — по крайней мере, в процессе обычного билда. Они никак не верифицируются до момента исполнения на сервере, то есть ошибки в них проявляются поздно. Все эти файлы — с некоторой натяжкой — можно называть конфигурацией. По крайнер мере, тестироваться они будут примерно одинаково.
Например, у нас есть система SQL-патчей, которые накатываются на базу данных в процессе деплоя.

Они написаны для SQL*Plus. SQL*Plus — это инструмент из 60-х, и он требует всякого странного: например, чтобы конец файла был обязательно на новой строке. Разумеется, люди регулярно забывают поставить туда конец строки, потому что они не родились в 60-х.
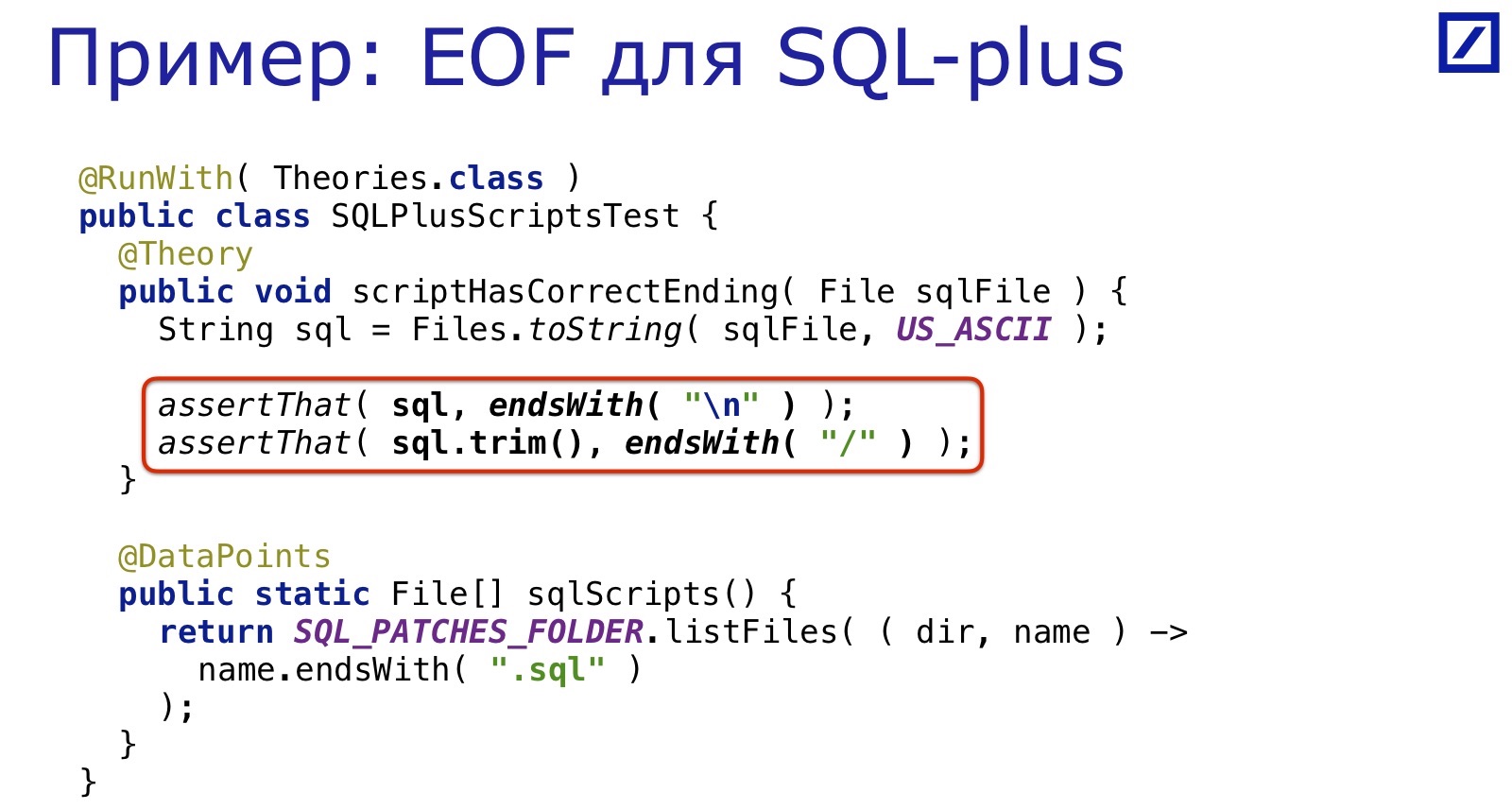
И снова решается той же дюжиной строчек: отбираем все SQL-файлы, проверяем, что в конце есть завершающий слэш. Просто, удобно, быстро.
Другой пример «как бы текстового файла» — crontabs. У нас кронтабами сервисы запускаются и останавливаются. В них чаще всего возникают две ошибки:
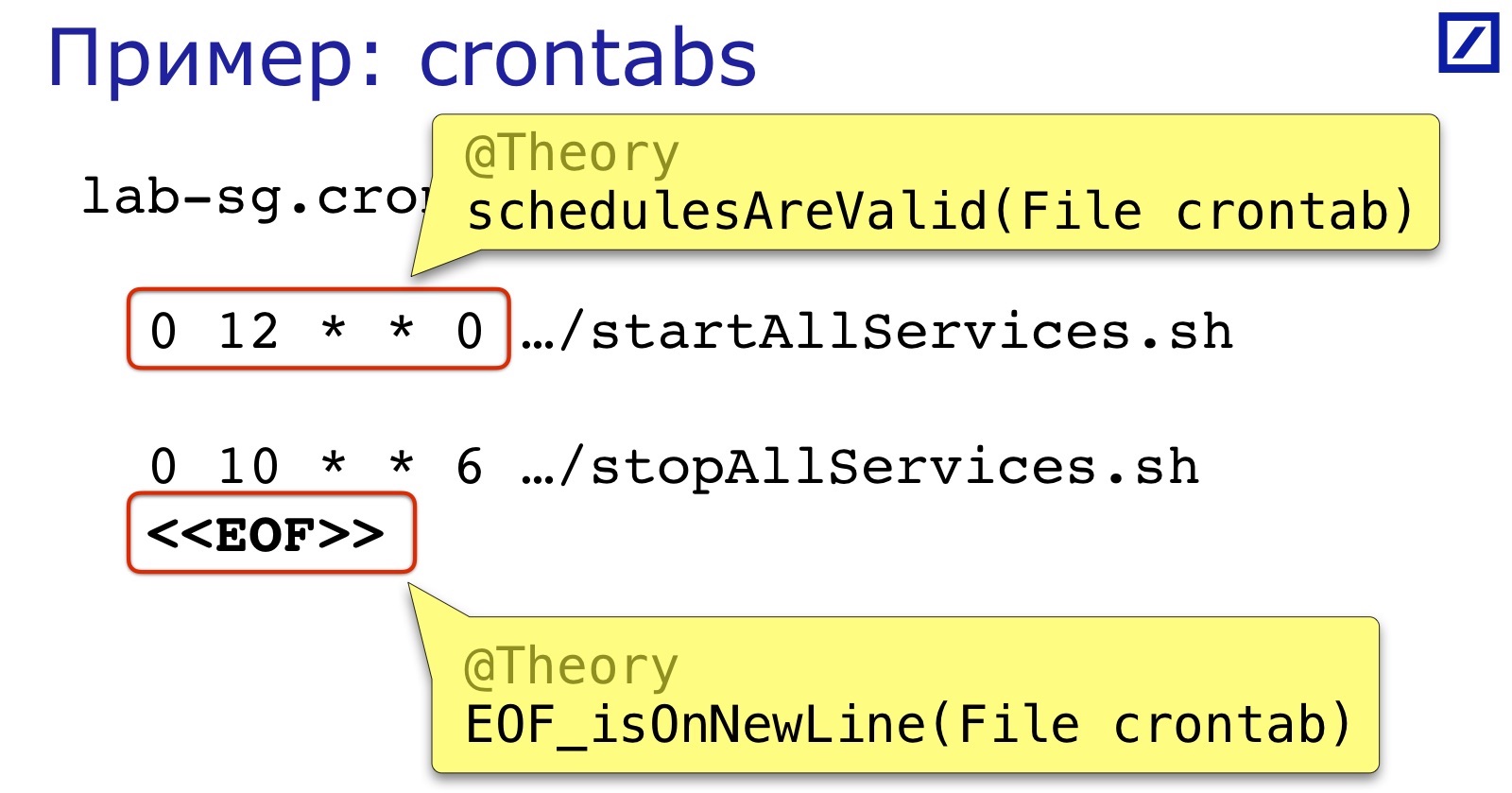
Во-первых, формат schedule expression. Он не то чтобы сложный, но никто его не проверяет до запуска, поэтому легко поставить лишний пробел, запятую и подобное.
Во-вторых, как и в предыдущем примере, конец файла тоже обязательно должен быть на новой строке.
И всё это довольно легко проверить. Про конец файла понятно, а для проверки расписания можно найти готовые библиотеки, которые парсят cron expression. Перед докладом я погуглил: их было как минимум шесть. Это я нашел шесть, а вообще может быть больше. Когда мы писали, взяли простейшую из найденных, потому что нам не надо было проверять содержимое выражения, а только его синтаксическую корректность, чтобы cron его успешно загрузил.
В принципе, можно накрутить больше проверок — проверить, что стартуете вы в нужный день недели, что не останавливаете сервисы посреди рабочего дня. Но нам это оказалось не так полезно, и мы не стали заморачиваться.
Еще идея, которая отлично работает — shell-скрипты. Конечно, писать на Java полноценный парсер bash-скриптов — это удовольствие для смелых. Но суть в том, что большое количество этих скриптов не является полноценным bash-ем. Да, есть bash-скрипты, где прямо код-код, ад и преисподняя, куда заглядывают раз в год и, матерясь, убегают. Но множество bash-скриптов — это те же конфигурации. Там есть какое-то количество системных переменных и переменных окружения, которые устанавливаются в нужное значение, тем самым конфигурируют другие скрипты, которые эти переменные используют. И такие переменные легко grep«нуть из этого bash-файла и что-то про них проверить.

Например, проверить, что на каждом environment’е установлена JAVA_HOME, или что в LD_LIBRARY_PATH находится какая-то используемая нами jni-библиотека. Как-то мы переезжали с одной версии Java на другую, и расширили тест: проверяли, что JAVA_HOME содержит »1.8» именно на том подмножестве enviroment, которые мы постепенно переводили на новую версию.
Вот такие несколько примеров. Подведу по первой части выводы:
- Тесты конфигурации поначалу смущают, есть психологический барьер. Но после его преодоления находится много мест в приложении, которые не покрыты проверками и их можно покрыть.
- Потом пишутся легко и весело: много «низко висящих фруктов», которые быстро дают большую пользу).
- Уменьшают затраты на обнаружение и исправление ошибок конфигурации. Так как это, по сути, unit-тесты, вы можете выполнить их на своем компьютере, даже до коммита, — это сильно сокращает Feedback Loop. Многие из них, конечно, и так проверялись бы на этапе тестового деплоя, например. А многие не проверились бы — если это production-конфигурация. А так они проверяются прямо на локальном компьютере.
- Дарят вторую молодость. В том смысле, что возникает ощущение, что можно еще много интересного протестировать. Ведь в коде уже не так просто найти, что можно протестировать.
Часть 2. Более сложные случаи
Перейдем к более сложным тестам. После покрытия большой части тривиальных проверок, вроде показанных здесь, встает вопрос: можно ли проверять что-то сложнее?
Что значит «сложнее»? Тесты, что я сейчас описывал, имеют примерно такую структуру:

Они проверяют что-то относительно одного конкретного файла. То есть мы идем по файлам, применяем к каждому проверку некого условия. Таким образом многое можно проверить, но есть полезные сценарии посложнее:
- UI-приложение соединяется с сервером своего environment-а.
- Все сервисы одного environment-а соединяются с одним и тем же management-сервером.
- Все сервисы одного environment-а используют одну и ту же базу данных
Например, UI-приложение соединяется с сервером своего environment. Скорее всего, UI и сервер — это разные модули, если не вообще проекты, и у них разные конфигурации, вряд ли они используют одни файлы конфигурации. Поэтому придется их слинковать так, чтобы все сервисы одного environment«а соединялись с одним ключевым management-сервером, через который распространяются команды. Опять же, скорее всего, это разные модули, разные сервисы и вообще разные команды их разрабатывают.
Или все сервисы используют одну и ту же базу данных, то же самое — сервисы в разных модулях.
На самом деле есть такая картина: множество сервисов, в каждом из них своя структура конфигов, нужно несколько из них свести и проверить что-то на пересечении:

Конечно, можно ровно так и сделать: загрузить один, второй, где-то вытащить что-то, в коде теста склеить. Но вы представляете, какого размера будет код и насколько он будет читабелен. Мы с этого начинали, но потом поняли, насколько это непросто. Как сделать лучше?
Если помечтать, как бы было удобнее, то я намечтал, чтобы тест выглядел так, как я его человеческим языком объясняю:
@Theory
public void eachEnvironmentIsXXX( Environment environment ) {
for( Server server : environment.servers() ) {
for( Service service : server.services() ) {
Properties config = buildConfigFor(
environment,
server,
service
);
//… check {something} about config
}
}
}
Для каждого environment выполняется некоторое условие. Чтобы это проверить, надо от environment найти список серверов, список сервисов. Далее загрузить конфиги и на пересечении проверить что-то. Соответственно, мне нужна такая вещь, я назвал ее Deployment Layout.
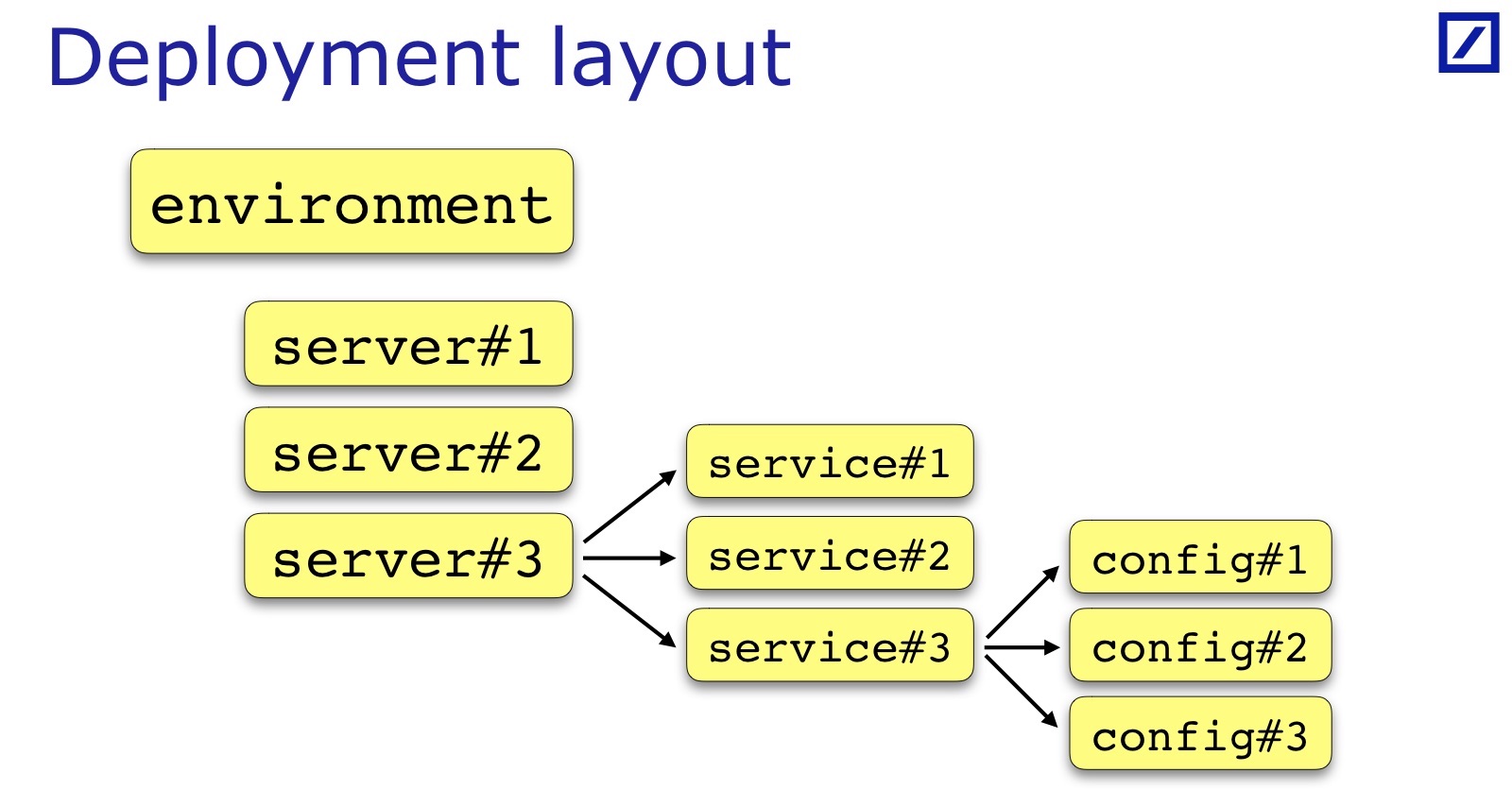
Нужна возможность из кода получить доступ к тому, как деплоится приложение: на какие сервера какие сервисы кладутся, в рамках каких Environment — получить эту структуру данных. И исходя из нее, я начинаю грузить конфигурацию и обрабатывать ее.
Deployment Layout специфичен для каждой команды и каждого проекта. Нарисованное мной — это общий случай: обычно есть какой-то набор серверов, сервисов, у сервиса иногда бывает набор конфиг-файлов, а не один. Иногда требуются дополнительные параметры, которые полезны для тестов, их приходится добавлять. Например, может быть важна стойка, в которой находится сервер. Андрей в своем докладе приводил пример, когда для их сервисов было важно, чтобы Backup/Primary сервисы обязательно были в разных стойках — для его случая нужно будет в deployment layout держать еще указание на стойку:
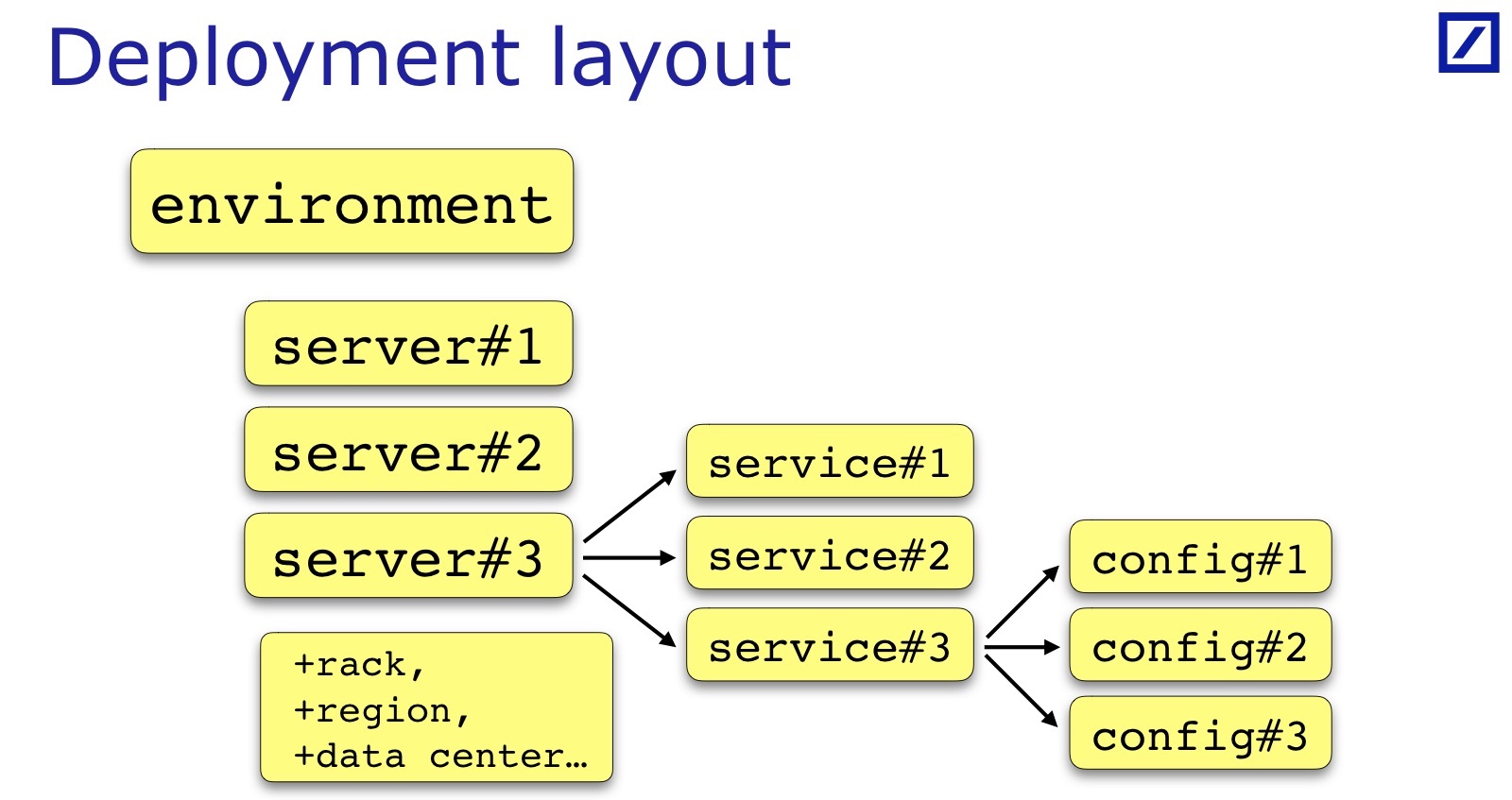
Для наших целей важен регион сервера, конкретный дата-центр, в принципе, тоже, чтобы Backup/Primary были в разных дата-центрах. Это все дополнительные свойства серверов, они project-specific, но, а на слайде это такой общий знаменатель.
Откуда взять deployment layout? Кажется, что в любой крупной компании есть система Infrastructure Management, там все описано, она надежная, reliable и все такое… на самом деле нет.
По крайней мере, моя практика в двух проектах показала, что проще сначала захардкодить, а потом, года через три… оставить захардкоженной.
В одном проекте мы уже три года с этим живем. Во втором, вроде бы, мы все же через годик заинтегрируемся с Infrastructure Management, но все эти годы жили так. По опыту, задачу интеграции с IM имеет смысл откладывать, чтобы как можно быстрее получить готовые тесты, которые покажут, что они работают и полезны. А потом может оказаться, что эта интеграция может быть не так уж и нужна, потому что не так уж часто меняется распределение сервисов по серверам.
Захардкодить можно буквально вот так:
public enum Environment {
PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP,
PROD_US_PRIMARY, PROD_US_BACKUP,
PROD_SG_PRIMARY, PROD_SG_BACKUP )
…
public Server[] servers() {…}
}
public enum Server {
PROD_UK_PRIMARY("rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"),
PROD_US_PRIMARY("rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"),
PROD_SG_PRIMARY("rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"),
public Service[] services() {…}
}
Самый простой способ, который используется у нас в первом проекте, — перечисление Environment со списком серверов в каждом из них. Есть список серверов и, казалось бы, должен быть список сервисов, но мы схитрили: у нас есть стартовые скрипты (которые тоже часть конфигурации).

Они для каждого Environment запускают сервисы. И метод services () просто grep«ает из файла своего сервера все сервисы. Так сделано, потому что Environment’ов не так много, и сервера тоже нечасто добавляются или удаляются —, а вот сервисов много, и тасуются они довольно часто. Имело смысл сделать загрузку актуальной раскладки сервисов из скриптов, чтобы не менять захардкоженный layout слишком часто.
После создания такой программной модели конфигурации появляются приятные бонусы. Например, можно написать такой тест:

Тест, что на каждом Environment присутствуют все ключевые сервисы. Допустим, есть четыре ключевых сервиса, а остальные могут быть или нет, но без этих четырех смысла нет. Можно проверить, что вы их нигде не забыли, что у всех них есть бекапы в рамках того же Environment. Чаще всего подобные ошибки возникают при конфигурации UAT этих инстансов, но и в PROD может просочиться. В конце концов, ошибки в UAT тоже тратят время и нервы тестировщиков.
Возникает вопрос поддержания актуальности модели конфигурации. На это тоже можно написать тест.
public class HardCodedLayoutConsistencyTest {
@Theory
eachHardCodedEnvironmentHasConfigFiles(Environment env){
…
}
@Theory
eachConfigFileHasHardCodedEnvironment(File configFile){
…
}
}
Есть конфигурационные файлы, и есть deployment layout в коде. И можно проверить, что для каждого Environment/сервера/etc. есть соответствующий конфигурационный файл, а для каждого файла нужного формата — соответствующий Environment. Как только вы забудете что-то добавить в одно место, тест упадет.
В итоге deployment layout:
- Упрощает написание сложных тестов, сводящих воедино конфиги из разных частей приложения.
- Делает их нагляднее и читабельнее. Они выглядят так, как вы о них на высоком уровне думаете, а не так, как они ходят через конфиги.
- В ходе его создания, когда задаете люди вопросы, выясняется много интересного о деплойменте. Всплывают ограничения, неявные сакральные знания — например, относительно возможности хостинга двух Environment на одном сервере. Оказывается, что разработчики считают по-разному и соответственно пишут свои сервисы. И такие моменты полезно утрясти между разработчиками.
- Хорошо дополняет документацию (особенно если ее нет). Даже если есть — мне, как разработчику, приятнее это видеть в коде. Тем более, что там можно написать важные мне, а не кому-то, комментарии. А можно ещё и захардкодить. То есть, если вы решили, что не может быть на одном сервере два Environment, можно вставить проверку, и теперь так не будет. По крайней мере, вы узнаете, если кто-то попытается. То есть это документация с возможностью энфорсить ее. Это очень полезно.
Идём дальше. После того как тесты написали, они год «отстоялись», некоторые начинают падать. Некоторые начинают падать раньше, но это не так страшно. Страшно, когда падает тест, написанный год назад, вы смотрите на его сообщение об ошибке, и не понимаете.
Допустим, я понял и согласен, что это невалидный сетевой порт —, но где он? Перед докладом я посмотрел, что у нас в проекте 1200 property-файлов, раскиданных по 90 модулям, в них в сумме 24 000 строк. (Я хоть и был удивлен, но если посчитать, то это не такое большое число — на один сервис по 4 файла.) Где этот порт?
Понятно, что в assertThat () есть аргумент message, в него можно вписать что-то, что поможет идентифицировать место. Но когда ты пишешь тест, ты об этом не думаешь. И даже если думаешь — надо еще угадать, какое описание будет достаточно подробным, чтобы через год его можно было понять. Хотелось бы этот момент автоматизировать, чтобы был способ писать тесты с автоматической генерацией более-менее понятного описания, по которому можно найти ошибку.
Я опять же мечтал и намечтал нечто такое:
SELECT
environment, server, component, configLocation,
propertyName,
propertyValue
FROM
configuration(environment, server, component)
WHERE
propertyName like "%.port%”
and
propertyValue is not validNetworkPort()
Это такой псевдо-SQL — ну просто я знаю SQL, вот мозг и подкинул решение из того, что знакомо. Идея в том, что большинство тестов конфигураций состоят из нескольких однотипных кусочков. Cначала отбирается подмножество параметров по условию:

Потом относительно этого подмножества мы что-то проверяем относительно значения:

А потом, если нашлись свойства, значения которых не удовлетворяет желанию, это та «простыня», которую мы хотим получить в сообщении об ошибке:

Одно время я даже думал, не написать ли мне парсер типа SQL-like, благо сейчас это несложно. Но потом я понял, что IDE не будет его поддерживать и подсказывать, поэтому людям придется писать на этом самопальном «SQL» вслепую, без подсказок IDE, без компиляции, без проверки — это не очень удобно. Поэтому пришлось искать решения, поддерживаемые нашим языком программирования. Если бы у нас был .NET, то помог бы LINQ, он почти SQL-like.
В Java нет LINQ, максимально близкое, что есть — это стримы. Вот так должен выглядеть этот тест в стримах:
ValueWithContext[] incorrectPorts =
flattenedProperties( environment )
.filter( propertyNameContains( ".port" ) )
.filter(
!isInteger( propertyValue )
|| !isValidNetworkPort( propertyValue )
)
.toArray();
assertThat( incorrectPorts, emptyArray() );
flattenedProperties () берет все конфигурации этого environment, все файлы для всех серверов, сервисов и разворачивает их в большую таблицу. По сути это SQL-like таблица, но в виде набора Java-объектов. И flattenedProperties () возвращает этот набор строк в виде стрима.

Дальше вы по этому набору Java-объектов добавляете какие-то условия. В этом примере: отбираем содержащие в propertyName «port» и фильтруем те, где значения не конвертируются в Integer, или не из валидного диапазона. Это — ошибочные значения, и по идее, они должны быть пустым множеством.

Если они не пустое множество — выбрасываем ошибку, которая будет будет выглядеть так:

Часть 3. Тестирование как поддержка для рефакторинга
Обычно тестирование кода служит одной из самых мощных поддержек рефакторинга. Рефакторинг — это опасный процесс, многое переделывается, и хочется убедиться, что после него приложение по-прежнему жизнеспособно. Один из способов убедиться в этом — это сначала все обложить со всех сторон тестами, а потом уже рефакторить вместе с этим.
И вот передо мной стояла задача рефакторинга конфигурации. Есть приложение, которое написано лет семь назад одним умным человеком. Конфигурация этого приложения выглядит примерно так:

Это пример, там такого еще много. Тройной уровень вложенности подстановок, и это используется по всей конфигурации:

В самой конфигурации файлов немного, но зато они друг в друга включаются. Тут используется небольшое расширение i.u. Properties — Apache Commons Configuration, которое как раз поддерживает инклуды и разрешение подстановок в фигурных скобках.
И автор сделал фантастическую работу, используя всего две эти вещи. Мне кажется, он там построил машину Тьюринга на них. В некоторых местах реально кажется, что он пытается делать вычисления с помощью включений и подстановок. Не знаю, является ли эта система Тьюринг-полной, но он, по-моему, пытался доказать, что это так.
И человек ушел. Написал, приложение работает, и он ушел из банка. Все работает, только конфигурацию полностью никто не понимает.
Если взять отдельный сервис, то там получается 10 инклудов, до тройной глубины, и в сумме, если все развернуть, 450 параметров. На самом деле этот конкретный сервис использует 10–15% из них, остальные параметры предназначены для других сервисов, потому что файлы-то общие, используются несколькими сервисами. Но какие именно 10–15% использует этот конкретный сервис — не так просто понять. Автор, видимо, понимал. Очень умный человек, очень.
Задача, соответственно, состояла в упрощении конфигурации, ее рефакторинге. При этом хотелось сохранить работоспособность приложения, потому что в данной ситуации шансы на это невысоки. Хочется:
- Упростить конфигурацию.
- Чтобы после рефакторинга каждый сервис по-прежнему имел все свои необходимые параметры.
- Чтобы он не имел лишних параметров. 85% не относящихся к нему не должны загромождать страницу.
- Чтобы сервисы по-прежнему успешно соединялись в кластеры и выполняли совместную работу.
Проблема в том, что неизвестно, насколько хорошо они соединяются сейчас, потому что система с высоким уровнем резервирования. Например, забегая вперед: во время рефакторинга выяснилось, что в одной из production-конфигураций должно быть четыре сервера в обойме бэкапа, а на самом деле их было два. Из-за высокого уровня резервирования этого никто не замечал — ошибка случайно всплыла, но фактически уровень резервирования долгое время был ниже, чем мы рассчитывали. Речь о том, что мы не можем полагаться на то, что текущая конфигурация везде правильна.
Я веду к тому, что нельзя просто сравнить новую конфигурацию со старой. Она может быть эквивалентной, но оставаться при этом где-то неправильной. Надо проверять логическое содержимое.
Программа-минимум: каждый отдельный параметр каждого необходимого ему сервиса изолировать и проверить на корректность, что порт — это порт, адрес —- это адрес, TTL — положительное число и т.д. И проверить ключевые взаимосвязи, что сервисы в основном соединяются по основным end points. Этого хотелось добиться, как минимум. То есть, в отличие от предыдущих примеров, здесь задача стоит не в проверке отдельных параметров, а в накрытии всей конфигурации полной сетью проверок.
Как это протестировать?
public class SimpleComponent {
…
public void configure( final Configuration conf ) {
int port = conf.getInt( "Port", -1 );
if( port < 0 ) throw new ConfigurationException();
String ip = conf.getString( "Address", null );
if( ip == null ) throw new ConfigurationException();
…
}
…
}
Как эту задачу решал я? Есть какой-то простой компонент, в примере упрощён по максимуму. (Для тех, кто не сталкивался с Apache Commons Configuration: объект Configuration — это как Properties, только у него еще есть типизированные методы getInt (), getLong () и т.д.; можно считать, что это j.u.Properties на небольших стероидах.) Допустим, компоненту нужны два параметра: например, TCP-адрес и TCP-порт. Мы их вытаскиваем и проверяем. Какие здесь есть четыре общие части?

Это имя параметра, тип, значения по умолчанию (здесь они тривиальные: null и -1, иногда встречаются вменяемые значения) и какие-то валидации. Порт здесь валидируется слишком просто, неполно — можно задать порт, который будет её проходить, но не будет валидным сетевым портом. Поэтому хотелось бы этот момент тоже улучшить. Но в первую очередь хочется эти четыре вещи свернуть в нечто одно. Например, такое:
IProperty PORT_PROPERTY
= intProperty( "Port" )
.withDefaultValue( -1 )
.matchedWith( validNetworkPort() );
IProperty ADDRESS_PROPERTY
= stringProperty( "Address" )
.withDefaultValue( null )
.matchedWith( validIPAddress() );
Такой композитный объект — описание свойства, который знает свое имя, дефолтное значение, умеет делать валидацию (здесь я опять использую hamcrest matcher). И у этого объекта примерно такой интерфейс:
interface IProperty {
/* (name, defaultValue, matcher…) */
/** lookup (or use default),
* convert type,
* validate value against matcher
*/
FetchedValue fetch( final Configuration config )
}
class FetchedValue {
public final String propertyName;
public final T propertyValue;
…
}
То есть после создания объекта, специфичного для конкретной реализации, можно просить у него извлечь параметр, который он представляет, из конфигурации. И он вытащит этот параметр, в процессе проверит, если параметра нет — даст дефолтное значение, приведет к нужному типу, и вернёт его сразу вместе с именем.
То есть вот такое имя у параметра и такое актуальное значение, которое увидит сервис, если запросит из этой конфигурации. Это позволяет несколько строк кода завернуть в одну сущность, это первое упрощение, которое мне понадобится.
Второе упрощение, которое понадобилось мне для решения задачи — это представление компонента, которому нужно несколько свойств для своей конфигурации. Модель конфигурации компонента:

У нас был компонент, использующий эти два свойства, есть модель его конфигурации — интерфейс IConfigurationModel, который этот класс реализует. IConfigurationModel делает все, что делает компонент, но только ту часть, что относится к конфигурации. Если компоненту нужны параметры в определенном порядке с определёнными дефолтными значениями — IConfigurationModel эту информацию в себе сводит, инкапсулирует. Все остальные действия компонента ему не важны. Это модель компонента с точки зрения доступа к конфигурации.

Фишка такого представления в том, что модели комбинируемые. Если есть компонент, который
