Как стать датасайнтистом, если тебе за 40 и ты не программист
Бытует мнение, что стать датасайентистом можно только имея соответствующее высшее образование, а лучше ученую степень.
Однако мир меняется, технологии становятся доступны и для простых смертных. Возможно, я кого-то удивлю, но сегодня любой бизнес-аналитик в состоянии освоить технологии машинного обучения и добиться результатов, конкурирующих с профессиональными математиками, и, возможно, даже лучших.
Дабы не быть голословным, я расскажу вам свою историю — как из экономиста я стал дата-аналитиком, получив необходимые знания через онлайн-курсы и участвуя в соревнованиях по машинному обучению.

Сейчас я ведущий аналитик в группе больших данных в QIWI, но еще три года назад я был довольно далек от датасайнс и об искусственном интеллекте слышал только из новостей. Но потом все изменилось, во многом благодаря Coursera и Kaggle.
Итак, обо всем по порядку.
О себе
Я экономист, довольно долго работал бизнес-консультантом. Моя специализация — разработка методологии бюджетирования и отчетности для последующей автоматизации. Если по-простому — это про то, чтобы сначала нормально выстроить процесс, чтобы потом от автоматизации был результат.
3 года назад, в 42 года, когда почувствовал, что от успехов в консалтинге я начинаю бронзоветь, и стал задумываться о необходимости перемен. О следующей карьере. У меня уже был опыт, как начать карьеру с нуля (в 30 лет я поменял спокойную жизнь экономиста на консалтинг), поэтому перемены меня не пугали.
Это не приходит в голову сразу, но когда задумываешься, становится очевидно, что несмотря на то, что я уже проработал 20 лет, впереди еще примерно 25 лет до пенсии (уже давно пришло понимание, что надо ориентироваться на пенсию в 70 лет или даже позже). В общем, впереди дорога, длиннее, чем та, что уже прошел, и хорошо бы ее пройти с актуальной специальностью. А значит, стоило поучиться. В тот период я фрилансил, и ради будущего я сократил число проектов и смог выделить достаточно времени на учёбу.
Пока я думал, куда дальше двигать, я открыл для себя Coursera. Западный подход к образованию, когда тебе в первую очередь объясняют смысл, общую идею, а уже потом детали, мне оказался близок. В отличие от брутальной советской системы образования, предполагающей, что выплывут только достойные, тут дают шанс таким, как я, у кого есть пробелы в базовом образовании.
Начинал я с курсов бизнес-аналитики. Это было крайне полезно для меня как консультанта. Эти же курсы помогли мне лучше понять роль AI-технологий для развития бизнеса и, самое главное, увидеть свою роль в этом. Это так же, как и с другими технологиями — совсем не обязательно, что те, кто разрабатывают новые технологии, будут лучшими в их применении. Чтобы технологии реально помогали бизнесу, важно этот бизнес понимать. Экспертиза в бизнес-процессах не менее важна, чем понимание самих технологий машинного обучения, обработки больших данных и тд.
И я погрузился в курсы по датасайнс, статистике, программированию.
С перерывами, я за год освоил более 30 курсов на Coursera и уже не чувствовал себя инопланетянином в мире бигдаты и машинного обучения.
Kaggle
Некоторые курсы рекомендовали Kaggle как отличную площадку для практики. Не повторяйте моей ошибки — я пришел туда, только когда уже чувствовал, что накопил достаточно знаний. А стоило сделать это на полгода раньше, когда появилось первое понимание, что и как. Был бы на полгода круче. Ведь это не просто одна из площадок для соревнований, это лучшая (в настоящее время) площадка для освоения машинного обучения на практике, которая полезна как начинающим, так и супергуру. И там ты растешь, что называется, день за два — только курсы без практики на дадут такого эффекта.
Моим первым соревнованием был конкурс от банка Santander — предсказание уровня удовлетворенности клиентов. Я был новичком и хотел проверить уровень своих знаний в деле. Я совместил свой опыт как клиента банка, навыки анализа бизнес-кейсов и технологии машинного обучения и сделал довольно неплохую модель, с которой я забрался в топ-50 на public leaderbord. Это было куда выше моих ожиданий от первого конкурса, учитывая, что в нем участвовало более 5 тысяч человек.
Но не все было так просто. На хэппиэнд я тогда не заработал. Есть такая распространенная среди новичков проблема, как «переобучение модели», с которой я познакомился на практике. Локальная валидация была организована слабо, я слишком сильно ориентировался на паблик, и как результат — на закрытой части теста я улетел на 500+ позиций вниз. Конечно, я был расстроен, но урок пошел впрок: хорошая валидация — основа машинного обучения, и ей надо заниматься серьезно. Сейчас этот компонент — одна из сильных сторон моих моделей.
Несмотря на слабый первый результат, появилась уверенность, что попасть в топ реально, надо больше практики и дополнительных знаний.
Для тех, кто не знает, чем хорош Кэггл — сообщество готово помогать новичкам с преодолением каких-то затыков, обсуждает идеи, делится примерами «как работает». Ну и не менее важно — по окончании соревнований есть возможность изучить решения лидеров. Учась на чужом опыте, можно добиться быстрого прогресса. Не обязательно на все грабли наступать самому.
Тут же не могу не вспомнить об ОпенДатаСайнс (ods.ai) — русскоязычном сообществе датасайентистов. Тренировки по машинному обучению, которые организует ods — еще один способ глубже узнать предмет. Ну и как площадка для общения по любым вопросам также очень помогает. Если вы думаете о своем будущем в датасайнс, и вы еще не зарегались на ods — это серьезная ошибка.
Поскольку в вакансиях на позиции датасайентистов довольно часто упоминались ожидания высоких результатов на Кэггле, я увидел в этом для себя шанс — помимо того, что я набираюсь опыта, есть возможность заполнить пустое резюме более-менее релевантным опытом. Я стал относиться к Кэггл как к работе, где бонусом может стать начало карьеры.
Как только появлялось свободное время, я строил модели на Кэггле, и с каждым соревнованием результат становился лучше.
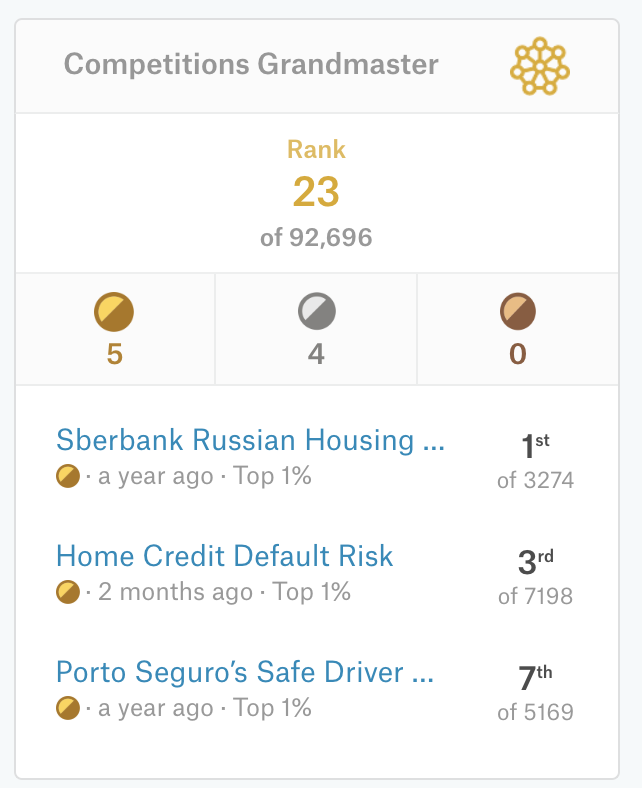
У меня было то, чего не было у большинства участников — умение анализировать бизнес-кейсы и мой опыт в консалтинге, это очень помогало при построении моделей. Через полгода я занял 7 место в очередном конкурсе от банка Santander и заработал свою первую золотую медаль.
Если настойчиво стремиться к определенной цели, ты ее достигнешь — в июне 2017 года, через год с небольшим моих битв на Кэггле, мы вместе с разработчиком из Латвии Агнисом Люкисом выиграли конкурс от Сбербанка по предсказанию цен на квартиры в Москве.

Нашими сильными сторонами было понимание кейса (это комплексная задача, к решению которой не стоило подходить в лоб, как делало большинство) и сильная локальная валидация. Мы закончили конкурс вторыми на паблике, но наша модель почти не пострадала от переобучения и не сильно просела на закрытых данных — в финале мы оказались первыми с гигантским отрывом.
Эта победа забросила меня в топ-50 глобального рейтинга Kaggle, что вылилось в предложения о работе. Изучив варианты, я выбрал банк, как место, где много задач, на которых можно прокачать скиллы, а также прочувствовать всю правду жизни при разработке моделей — все же в соревнованиях условия скорее тепличные.
Планы на карьерный рост у меня были амбициозными и вариант «не торопясь поработать несколько лет, чтобы дорасти до следующей ступени» не рассматривался. Надо было впахивать и на работе, и во вторую смену не забывать о Кэггле. Непросто, но кому нынче легко? И это дало результаты — еще 3 золотые медали и я заработал погоны Грандмастера на Кэггле плюс закрепился в глобальном топе (сейчас 23-й).
Как вишенка на торте — 3 призовое место в соревнованиях по банковскому скорингу, то, чем я профессионально занимался последний год. И, как видно, занимался хорошо.
Увы, но правда жизни в банке — это еще и очень консервативный и небыстрый процесс принятия решений. Внедрение моих моделей двигалось медленно. Перестраивать работу всего банка планов не было, поэтому проще было, хоть и с сожалением, но сменить работу.
Это оказалось совсем не сложно — благодаря результатам на Кэггле, поиск не занял много времени, и уже несколько месяцев я копаю миллиардные таблицы в QIWI. У нас куча интересных задач, уверен, что довольно скоро мы сможем превратить наши данные в прибыль для компании — бэкграунд экономиста в этом очень помогает. Кэгглоопыт здесь также оказался в кассу по нескольким кейсам.
А теперь о том, как добиться успеха в соревнованиях
Самая важная часть — понять задачу и найти все драйверы, которые могут влиять на результат. Чем лучше вы разберетесь в кейсе, тем больше шансов выступить круто. Нагенерить сотни или даже тысячи стат фич может каждый, а вот придумать такие, которые заточены именно под эту задачу и хорошо объясняют таргет, куда сложнее. Вложитесь в это, и быстро окажетесь в топе. Стоит применять любой релевантный опыт (бизнесовый, бытовой и тд) — это сильно помогает.
Затем — локальная валидация. Ваш главный враг — переообучение, особенно если вы используете такую сильную технологию, как градиентный бустинг. Знаю, насколько психологически сложно перестать ориентироваться на public leaderboard, но если не хотите разочарований, правильный ответ — используйте кросс-валидацию, скажите «Нет» отложенной выборке. Конечно, есть исключения, но даже в задачах с временными рядами можно прикрутить кросс-валидацию, сильно повысив надежность модели. Не всегда схема локальной валидации будет простой, но стоит потратить на нее время — и в соревнованиях, и в реальной жизни. Наградой будут стабильные модели.
Само собой, надо хорошо изучить основные инструменты. Зная принципы разных технологий, вы сможете адекватно выбирать наилучший инструмент для решения конкретной задачи. Для табличных данных сейчас лидер градиентный бустинг, а конкретно — Lightgbm. Но важно уметь использовать и другие методы, от логрега до нейросетей — и в жизни, и в соревнованиях лишними не будут.
Кстати, лучший способ понять, какие технологии рулят сейчас, когда все меняется стремительно — посмотреть, какие библиотеки используют лидеры соревнований. В последние годы многие стоящие технологии прорвались в мир через Кэггл.
Гиперпараметры. Важно знать ключевые гиперпараметры используемых инструментов. Обычно не так много параметров надо менять. Мое убеждение — не стоит тратить много времени на подбор гиперпараметров. Конечно, найти хорошие гиперпараметры необходимо, но зацикливаться на этом не стоит.
Обычно, когда модель обозначилась, я подбираю более или менее стабильный сет параметров и возвращаюсь к их тюнингу только ближе к концу, когда другие идеи иссякли. Здравый смысл подсказывает, что время, потраченное на создание и тестирование новых переменных, библиотек, нестандартных идей, может дать куда больший прирост модели, чем улучшение от перехода от хорошего набора гиперпараметров к идеальному.
Если вы делаете ставку на Kaggle как на фичу, которая прокачает ваше резюме — рассматривайте это именно как работу, не пожалеете. Мне это помогло, поможет и вам.
Ну и еще раз о конкуренции. Она тут очень высока, поэтому в одиночку побеждать весьма и весьма сложно. Командная работа очень полезна, синергия идей позволяет прыгнуть выше головы. Не стесняйтесь этим пользоваться.
Итого
Ну и немного мотивации под конец. В первую очередь я доказал сам себе, что могу стать датасайнтистом в свои 44 года. Рецепт оказался на удивление прост — онлайн-образование, бизнес-ориентированное мышление, работоспособность и целеустремленность.
Теперь я всячески подбиваю своих друзей проделать тот же путь. Новая цифровая экономика нуждается (и будет нуждаться) в высококлассных специалистах. Coursera + Kaggle — это просто отличные возможности для старта.
Когда-то ведь и Excel был новым и непонятным инструментом (я даже помню, как непросто проходили первые бои с традиционным калькулятором). А сейчас ведь ни у кого нет сомнений, что специалист, разбирающийся в своем бизнесе, может выжать из Excel куда больше реальной пользы, чем сами разработчики Excel.
Пройдет немного времени, и владение инструментами машинного обучения станет таким же обязательным, как владение Excel, так почему бы не подготовиться к этому заранее и выиграть конкуренцию на рынке труда уже сейчас?
Тем более, конкуренции бояться не стоит. Чем больше людей со стороны бизнеса придет в датасайнс — тем больше денег. Внедрение новых технологий в традиционных отраслях экономики может ускорить именно бизнес, а для этого бизнес должен начать понимать возможности, которые открывают новые технологии уже сегодня. По сути любой бизнес-аналитик, освоив несколько курсов, может оказаться на передовой прогресса и помочь своей компании обогнать консервативных конкурентов.
Надеюсь, мой опыт поможет кому-то принять важное решение.
Если у вас есть какие-то вопросы о Kaggle, пишите, я с радостью отвечу в комментариях.
