Тестирование флеш СХД. Hitachi HUS VM с модулями FMD
сегодня в 11:18
Российский офис компании Hitachi Data Systems любезно предоставил нам доступ к своей виртуальной лаборатории, в которой, специально под наши тесты, был подготовлен стенд включавший систему хранения начального уровня Hitachi Unified Storage VM (HUS VM). Основной отличительной особенностью архитектуры данного решения являются специально разработанные Hitachi модули флэш-накопителей — Flash Module Drive (FMD). Кроме самого флеш-накопителя каждый такой модуль содержит свой собственный контроллер для буферизации, сжатия данных и прочих дополнительных сервисных операций. Методика тестирования
В ходе тестирования решались следующие задачи: исследования процесса деградации производительности СХД при длительной нагрузке на запись (Write Cliff);
исследование производительности СХД HUS VM при различных профилях нагрузки;
исследование влияния размера блока LUN на производительность.
Конфигурация тестового стенда
Методика тестирования
В ходе тестирования решались следующие задачи: исследования процесса деградации производительности СХД при длительной нагрузке на запись (Write Cliff);
исследование производительности СХД HUS VM при различных профилях нагрузки;
исследование влияния размера блока LUN на производительность.
Конфигурация тестового стенда
 Рисунок 1. Структурная схема тестового стенда.
Тестовый стенд состоит из четырех серверов, подключенных каждый четырьмя соединениями 8Gb к двум FC коммутаторам, каждый из которых имеет по четыре соединения 8Gb FC к СХД HUS VM. Настройкой зон на FC коммутаторах установлены по 4 независимых пути доступа от каждого сервера к СХД HUS VM.Сервер; СХДВ качестве дополнительного программного обеспечения на тестовый сервер установлен Symantec Storage Foundation 6.1, реализующий: Функционал логического менеджера томов (Veritas Volume Manager);
Функционал отказоустойчивого подключения к дисковым массивам (Dynamic Multi Pathing) для тестов группы 1 и 2. Для тестов группы 3 используется нативный Linux DMP)
Посмотреть утомительные подробности и всякие умные слова.
На тестовом сервере выполнены следующие настройки, направленные на снижение латентности дискового ввода-вывода: Изменен планировщик ввода-вывода с «cfq» на «noop» через присвоение значения noop параметру; /sys/<путь_к_устройству_Symantec_VxVM>/queue/scheduler
Добавлен следующий параметр в /etc/sysctl.conf минимизирующий размер очереди на уровне логического менеджера томов Symantec: «vxvm.vxio.vol_use_rq = 0»;
увеличен предел одновременных запросов ввода-вывода на устройство до 1024 через присвоение значения 1024 параметру /sys/<путь_к_устройству_Symantec_VxVM>/queue/nr_requests
отключена проверка возможности слияния операций в/в (iomerge) через присвоение значения 1 параметру /sys/<путь_к_устройству_Symantec_VxVM>/queue/nomerges
отключено упреждающее чтение через присвоение значения 0 параметру /sys/<путь_к_устройству_Symantec_VxVM>/queue/read_ahead_kb
Увеличен размер очереди на FC адаптерах путем добавления в конфигурационный файл /etc/modprobe.d/lpfc.conf опции lpfc lpfc_lun_queue_depth=64 (options lpfc lpfc_lun_queue_depth=64);
На СХД выполняются следующие конфигурационные настройки по разбиению дискового пространства: На СХД HUS VM из 28 модулей FMD создается 7 RAID-групп RAID1 2D+2D, которые включаются в один DP пул общей емкостью 22,4 TB.
В этом пуле создаются 32 тома DP-VOL одинакового объема с суммарным объемом, покрывающим всю емкость дискового массива. Каждому из четырех тестовых серверов презентуется по восемь созданных томов, доступных по всем четырем путям каждый.
Программное обеспечение, используемое в процессе тестирования
Для создания синтетической нагрузки (выполнения синтетических тестов) на СХД используется утилита Flexible IO Tester (fio) версии 2.1.4. При всех синтетических тестах используются следующие конфигурационные параметры fio секции [global]: thread=0
direct=1
group_reporting=1
norandommap=1
time_based=1
randrepeat=0
ramp_time=10
Для снятия показателей производительности при синтетической нагрузке применяются следующие утилиты: iostat, входящая в состав пакета sysstat версии 9.0.4 с ключами txk;
vxstat, входящая в состав Symantec Storage Foundation 6.1 c ключами svd;
vxdmpadm, входящая в состав Symantec Storage Foundation 6.1 c ключами -q iostat;
fio версии 2.1.4, для формирования сводного отчета по каждому профилю нагрузки.
Снятие показателей производительности во время выполнения теста утилитами iostat, vxstat, vxdmpstat производится с интервалом 5с.
Программа тестирования.
Тестирование состояло из 3-х групп тестов: Поинтересоваться подробностями
Группа 1: Тесты, реализующие длительную нагрузку типа random write генерируемой одним сервером.
Тесты выполнялись посредством создания синтетической нагрузки программой fio на блочное устройство (Block Device), представляющее собой логический том типа stripe, 16 column, stripe unit size=1MiB, созданный с использованием Veritas Volume Manager из 16-ми LUN на тестируемой системе и презентованных одному тестовому серверу.При создании тестовой нагрузки используются следующие дополнительные параметры программы fio: rw=randwrite
blocksize=4K и 64K
numjobs=64
iodepth=64
Группа тестов состоит из двух тестов, отличающихся размером блока операций ввода/вывода: тесты на запись блоками 4K и 64K, выполняемые на полностью размеченном СХД. Суммарный объем презентуемых LUN равен полезной емкости СХД. Длительность тестов 5 часов.По результатам тестов, на основании данных выводимых командой vxstat, формируются графики, совмещающие результаты тестов:
Рисунок 1. Структурная схема тестового стенда.
Тестовый стенд состоит из четырех серверов, подключенных каждый четырьмя соединениями 8Gb к двум FC коммутаторам, каждый из которых имеет по четыре соединения 8Gb FC к СХД HUS VM. Настройкой зон на FC коммутаторах установлены по 4 независимых пути доступа от каждого сервера к СХД HUS VM.Сервер; СХДВ качестве дополнительного программного обеспечения на тестовый сервер установлен Symantec Storage Foundation 6.1, реализующий: Функционал логического менеджера томов (Veritas Volume Manager);
Функционал отказоустойчивого подключения к дисковым массивам (Dynamic Multi Pathing) для тестов группы 1 и 2. Для тестов группы 3 используется нативный Linux DMP)
Посмотреть утомительные подробности и всякие умные слова.
На тестовом сервере выполнены следующие настройки, направленные на снижение латентности дискового ввода-вывода: Изменен планировщик ввода-вывода с «cfq» на «noop» через присвоение значения noop параметру; /sys/<путь_к_устройству_Symantec_VxVM>/queue/scheduler
Добавлен следующий параметр в /etc/sysctl.conf минимизирующий размер очереди на уровне логического менеджера томов Symantec: «vxvm.vxio.vol_use_rq = 0»;
увеличен предел одновременных запросов ввода-вывода на устройство до 1024 через присвоение значения 1024 параметру /sys/<путь_к_устройству_Symantec_VxVM>/queue/nr_requests
отключена проверка возможности слияния операций в/в (iomerge) через присвоение значения 1 параметру /sys/<путь_к_устройству_Symantec_VxVM>/queue/nomerges
отключено упреждающее чтение через присвоение значения 0 параметру /sys/<путь_к_устройству_Symantec_VxVM>/queue/read_ahead_kb
Увеличен размер очереди на FC адаптерах путем добавления в конфигурационный файл /etc/modprobe.d/lpfc.conf опции lpfc lpfc_lun_queue_depth=64 (options lpfc lpfc_lun_queue_depth=64);
На СХД выполняются следующие конфигурационные настройки по разбиению дискового пространства: На СХД HUS VM из 28 модулей FMD создается 7 RAID-групп RAID1 2D+2D, которые включаются в один DP пул общей емкостью 22,4 TB.
В этом пуле создаются 32 тома DP-VOL одинакового объема с суммарным объемом, покрывающим всю емкость дискового массива. Каждому из четырех тестовых серверов презентуется по восемь созданных томов, доступных по всем четырем путям каждый.
Программное обеспечение, используемое в процессе тестирования
Для создания синтетической нагрузки (выполнения синтетических тестов) на СХД используется утилита Flexible IO Tester (fio) версии 2.1.4. При всех синтетических тестах используются следующие конфигурационные параметры fio секции [global]: thread=0
direct=1
group_reporting=1
norandommap=1
time_based=1
randrepeat=0
ramp_time=10
Для снятия показателей производительности при синтетической нагрузке применяются следующие утилиты: iostat, входящая в состав пакета sysstat версии 9.0.4 с ключами txk;
vxstat, входящая в состав Symantec Storage Foundation 6.1 c ключами svd;
vxdmpadm, входящая в состав Symantec Storage Foundation 6.1 c ключами -q iostat;
fio версии 2.1.4, для формирования сводного отчета по каждому профилю нагрузки.
Снятие показателей производительности во время выполнения теста утилитами iostat, vxstat, vxdmpstat производится с интервалом 5с.
Программа тестирования.
Тестирование состояло из 3-х групп тестов: Поинтересоваться подробностями
Группа 1: Тесты, реализующие длительную нагрузку типа random write генерируемой одним сервером.
Тесты выполнялись посредством создания синтетической нагрузки программой fio на блочное устройство (Block Device), представляющее собой логический том типа stripe, 16 column, stripe unit size=1MiB, созданный с использованием Veritas Volume Manager из 16-ми LUN на тестируемой системе и презентованных одному тестовому серверу.При создании тестовой нагрузки используются следующие дополнительные параметры программы fio: rw=randwrite
blocksize=4K и 64K
numjobs=64
iodepth=64
Группа тестов состоит из двух тестов, отличающихся размером блока операций ввода/вывода: тесты на запись блоками 4K и 64K, выполняемые на полностью размеченном СХД. Суммарный объем презентуемых LUN равен полезной емкости СХД. Длительность тестов 5 часов.По результатам тестов, на основании данных выводимых командой vxstat, формируются графики, совмещающие результаты тестов:
IOPS как функция времени; Bandwidth как функция времени; Latency как функция времени. Проводится анализ полученной информации и делаются выводы о: Наличие деградации производительности при длительной нагрузке на запись и на чтение; Производительности сервисных процессов СХД (Garbage Collection) ограничивающих производительность дискового массива на запись при длительной пиковой нагрузке; Степени влияния размера блока операций в/в на производительность сервисных процессов СХД; Объеме пространства, резервируемом на СХД для нивелирования сервисных процессов СХД. Группа 2: Тесты производительности дискового массива при разных типах нагрузки, генерируемой 4-мя серверами на блочное устройство. Тесты выполнялись посредством создания синтетической нагрузки программой fio на блочное устройство (block device), представляющее собой логический том типа stripe, 8 column, stripe unit size=1MiB, созданный с использованием Veritas Volume Manager из 8-ми LUN на тестируемой системе и презентованный тестовым серверам.В ходе тестирования исследуются следующие типы нагрузок:
профили нагрузки (изменяемые параметры ПО fio: randomrw, rwmixedread): случайная запись 100%; случайная запись 30%, случайное чтение 70%; случайное чтение 100%. размеры блока: 1КБ, 8КБ, 16КБ, 32КБ, 64КБ, 1МБ (изменяемый параметр ПО fio: blocksize); способы обработки операций ввода-вывода: синхронный, асинхронный (изменяемый параметр ПО fio: ioengine); количество процессов, генерирующих нагрузку: 1, 2, 4, 8, 16, 32, 64, 128, 160, 192 (изменяемый параметр ПО fio: numjobs); глубина очереди (для асинхронных операций ввода-вывода): 32, 64 (изменяемый параметр ПО fio: iodepth). Группа тестов состоит из набора тестов, представляющего собой все возможные комбинации перечисленных выше типов нагрузки. Для нивелирования влияния сервисных процессов СХД (Garbage Collection) на результаты тестов, между тестами реализуется пауза равная объему записанной в ходе теста информации разделенному на производительность сервисных процессов СХД (определяется по результатам выполнения 1-ой группы тестов).По результатам тестов на основании данных, выводимых ПО fio по завершению каждого из тестов, формируются следующие графики для каждой комбинации следующих типов нагрузки: профиля нагрузки, способа обработки операций ввода-вывода, глубины очереди, совмещающие в себе тесты с разными значениями блока ввода-вывода:
IOPS как функция от кол-ва процессов, генерирующих нагрузку; Bandwidth как функция от кол-ва процессов, генерирующих нагрузку; Latеncy (clat) как функция от кол-ва процессов, генерирующих нагрузку; Проводится анализ полученных результатов, делаются выводы о нагрузочных характеристиках дискового массива при jobs=1, при latencyГруппа 3: Тесты производительности дискового массива при разных типах нагрузки, генерируемой одним и двумя серверами на блочное устройство. Тесты проводится аналогично тестам группы 2, за исключением того, что нагрузка генерируется с одного, а затем с двух серверов и исследуются максимальные показатели производительности. По окончании тестов приводятся максимальные показатели производительности, делается вывод о влиянии количества серверов, с которых генерируется нагрузка на производительность СХД Результаты тестирования Группа 1: Тесты, реализующие длительную нагрузку типа random write с изменением размера блока операций ввода/вывода (в/в).При длительной нагрузке независимо от размера блока, падения производительности со временем не зафиксировано. Такое явление, как «Write Cliff» отсутствует. Следовательно, любые максимальные показатели производительности можно считать средними.
Графики
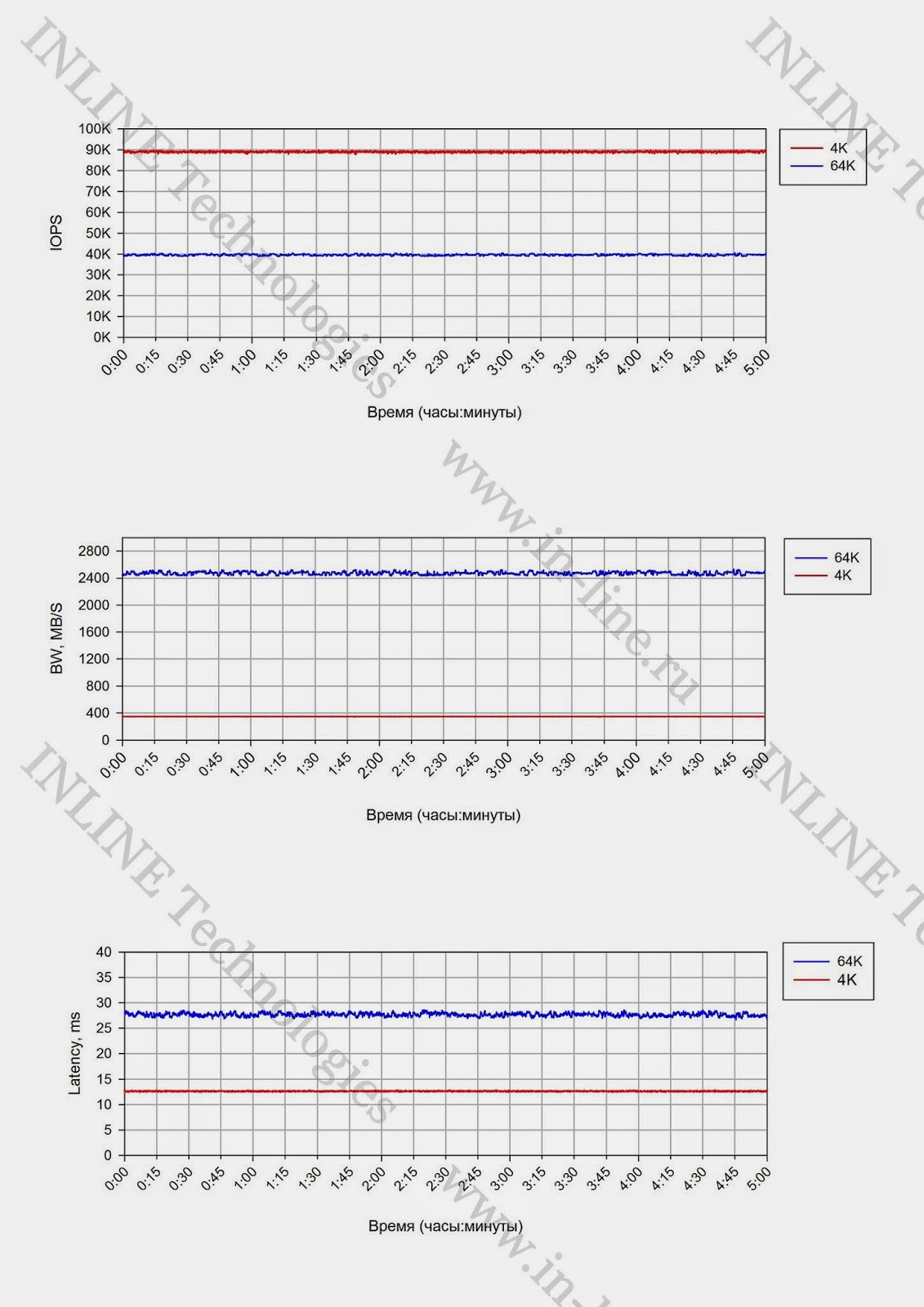 Изменение скорости операций в/в (iops), полосы пропускания (bandwidth) и задержек (Latency) при длительной записи блоками 4K и 64K
Группа 2: Тесты производительности дискового массива при разных типах нагрузки, генерируемой 4-мя серверами на блочное устройство.
Таблицы производительности блочного устройства.
Изменение скорости операций в/в (iops), полосы пропускания (bandwidth) и задержек (Latency) при длительной записи блоками 4K и 64K
Группа 2: Тесты производительности дискового массива при разных типах нагрузки, генерируемой 4-мя серверами на блочное устройство.
Таблицы производительности блочного устройства.
Графики производительности блочного устройства.
(Все картинки кликабельны)
Максимально зафиксированные параметры производительности:
Запись:147000 IOPS при latency 1.7ms (блок 4/8KB sync и async qd32)
Bandwidth: 3568МБ/c для больших блоков
Чтение:298000 IOPS при latency 0,5ms (блок 8KB sync);
390000 IOPS при latency 1,3ms (блок 8KB async qd 32);
419 000 IOPS при latency 2ms (4/8k async qd64);
Bandwidth: 5637МБ/с для средних блоков (32K).
Смешанная нагрузка (70/30 rw)224000 IOPS при latency 0.9ms (блок 4/8KB sync);
267000 IOPS при latency 3,8ms (блок 4/8KB async qd 64);
Bandwidth 6307МБ/с для средних блоков (32K)
Минимально зафиксированная latency: При записи — 0,144ms для блока 4K jobs=1
При чтении 0,36ms для блока 4K jobs=1
1. Производительность (iops) массива практически не отличается для блоков 4K и 8K, что позволяет сделать вывод о том, что массив оперирует блоками по 8K.2. Массив лучше работает со средними блоками (16K-64K), и показывает хорошую пропускную способность (bandwidth) при любом направлении в/в на средних блоках.3. При чтении и смешанном вводе-выводе средними блоками система достигает максимума пропускной способности при операциях средними блоками уже при 4–16 jobs. При увеличении количества jobs производительность значительно падает (практически в 2 раза)4. Мониторинг производительности СХД из её интерфейса, а так же производительности каждого сервера в отдельности, показал, что нагрузка во время тестов была очень хорошо сбалансирована между всеми компонентами стенда. (Между серверами, между fc адаптерами серверов и СХД, между полками, между BE SAS интерфейсами схд, между лунами, рейд-группами, флэш-картами).Группа 3: Тесты производительности дискового массива при разных типах нагрузки, генерируемой одним или двумя серверами на блочное устройство.
Максимально зафиксированные параметры производительности при тестах с одного сервера:
Запись:90000 IOPS (4/8K async jobs=128 qd=32/64)
Bandwidth: 2377МБ/c больших блоков (64K sync jobs=64)
Чтение:145 300 IOPS (4K async jobs=32 qd64);
Bandwidth: 3090МБ/с для средних блоков (64K async jobs=32 qd=32).
Смешанная нагрузка (70/30 rw)97 000 IOPS (4/8KB sync4K async jobs=32 qd=64);
Bandwidth МБ4274МБ/с средних блоков (16K)(64K async jobs=128 qd=32)
Минимально зафиксированная latency: При записи — 0, ms 25ms для блока 4K jobs=1
При чтении 0,4ms для блока 4/8K jobs=1
Максимально зафиксированные параметры производительности СХД при тестах с двух серверов:
Запись:137000 IOPS (8KB async и sync (c 1 мс задержкой))
Bandwidth: 2388МБ/c (1M больших блоков async и sync)
Чтение:232000 IOPS (4/8KB async);
Bandwidth: 5410МБ/с (блока 64K async, jobs=2)
Смешанная нагрузка (70/30 rw)214000 IOPS (блок 4/8KB async);
Bandwidth 5200 МБ/с для средних блоков (16K)
Минимально зафиксированная latency: При записи — 0, ms 138 ms для блока 4K jobs=1
При чтении 0,357ms для блока 4K jobs=1
Для наглядности мы составили таблицу максимальных показателей производительности HUS VM в зависимости от количества серверовгенерирующих нагрузку: 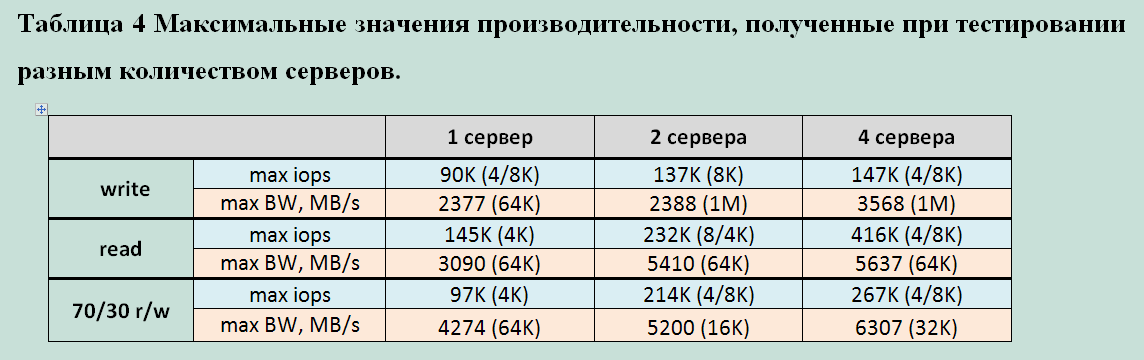 Очевидно, что производительность данной СХД напрямую зависит от количества подключенных к ней серверов. Скорее всего, это вызвано внутренними алгоритмами обработки потока данных и их ограничениями. Основываясь на показателях снятых, как с сервера, так и с СХД, можно с уверенностью сказать, что ни один компонент на пути следования данных не был перегружен. Потенциально, 1 сервер использованной конфигурации может генерировать больший поток данных.Выводы
Подводя итог можно сказать, что тесты выявили несколько характерных особенностей работы HUS VM c FMD модулями: Отсутствует деградация производительности на операциях записи (write cliff);
Размер кэша СХД не влияет на производительность FMD. Он используется внутренними алгоритмами обработки данных. Не отключается и не переводится в режим Write-Through;
Максимальная производительность системы напрямую зависит от количества серверов, генерирующих нагрузку. 4 сервера дают в 2–4 раза большую производительность чем один, хоть и не полностью загруженный. Причина, вероятно, кроется во внутренней логике системы.
Пропускная способность 6.3GB/s, полученная на блоках 32K — выглядит очень достойно. Специализированные flash решения выдают большое кол-во IOPS на мелких блоках, но на больших, судя по всему, упираются в пропускную способность внутренних шин. Тогда как у HUS VM такой проблемы не наблюдается.
В целом, HUS VM произвела впечатление очень стабильной и устойчивойHi-End системы со всей надежностью, функционалом и масштабируемостью. Своими индивидуальными особенностями и преимуществами архитектуры построенной на «умных» модулях (FMD).Отдельным преимуществом HUS VM стоит отметить её общезадачность. Использование специализированных Flash систем, неисключает потребности в обычных дисковых СХД, что приводит к усложнению общей подсистемы хранения. Массив с Enterprise функционалом (репликации, snapshot и т.п.) поддерживающий широкий выбор накопителей от механических дисков до специализированных флеш модулей позволяет подобрать оптимальную комбинацию под любую конкретную задачу. Полностью покрывая все вопросы доступности, хранения и защиты данных.
Очевидно, что производительность данной СХД напрямую зависит от количества подключенных к ней серверов. Скорее всего, это вызвано внутренними алгоритмами обработки потока данных и их ограничениями. Основываясь на показателях снятых, как с сервера, так и с СХД, можно с уверенностью сказать, что ни один компонент на пути следования данных не был перегружен. Потенциально, 1 сервер использованной конфигурации может генерировать больший поток данных.Выводы
Подводя итог можно сказать, что тесты выявили несколько характерных особенностей работы HUS VM c FMD модулями: Отсутствует деградация производительности на операциях записи (write cliff);
Размер кэша СХД не влияет на производительность FMD. Он используется внутренними алгоритмами обработки данных. Не отключается и не переводится в режим Write-Through;
Максимальная производительность системы напрямую зависит от количества серверов, генерирующих нагрузку. 4 сервера дают в 2–4 раза большую производительность чем один, хоть и не полностью загруженный. Причина, вероятно, кроется во внутренней логике системы.
Пропускная способность 6.3GB/s, полученная на блоках 32K — выглядит очень достойно. Специализированные flash решения выдают большое кол-во IOPS на мелких блоках, но на больших, судя по всему, упираются в пропускную способность внутренних шин. Тогда как у HUS VM такой проблемы не наблюдается.
В целом, HUS VM произвела впечатление очень стабильной и устойчивойHi-End системы со всей надежностью, функционалом и масштабируемостью. Своими индивидуальными особенностями и преимуществами архитектуры построенной на «умных» модулях (FMD).Отдельным преимуществом HUS VM стоит отметить её общезадачность. Использование специализированных Flash систем, неисключает потребности в обычных дисковых СХД, что приводит к усложнению общей подсистемы хранения. Массив с Enterprise функционалом (репликации, snapshot и т.п.) поддерживающий широкий выбор накопителей от механических дисков до специализированных флеш модулей позволяет подобрать оптимальную комбинацию под любую конкретную задачу. Полностью покрывая все вопросы доступности, хранения и защиты данных.
P.S. Автор выражает сердечную благодарность Павлу Катасонову, Юрию Ракитину, Дмитрию Власову и всем другим сотрудникам компании участвовавшим в подготовке данного материала.
