Azure DocumentDB
Недавно Microsoft анонсировало Azure DocumentDB preview.Как следует из названия — это документно-ориентированная база данных. Даже на хабре в 2 строчках об этом написали в этой и этой. Я же хочу более детально рассказать, что скрывается под этим названием.
Зачем Microsoft еще одна база данных, если есть Sql Azure, Sql Server на виртуалках, Tables, BLOBs?! Ни одна из этих фичей-баз не является документно-ориентированной базой данных.Sql Azure, Sql Server на виртуалках — это реляционные база данных. Table — это KeyValue база, в которой есть всего 1 индекс по первичному ключу. Плюс у нее фиксированная схема при создании. Blob — это хранилище файлов. Новый тип Microsoft не изобретала, а просто реализовала концепцию, которую каждый студент IT факультета слышит в курсе баз данных.
На чем основана DocumentDB? Это самописный сервис, стоящий особняком от остальных сервисов Microsoft. Хотя, если честно, Blob Storage там применяется для хранения бинарных объектов.В одной из статей в комментариях спросили —, а не на Table ли это построено? (Ребята сами написали обертку поверх Table). На что сотрудник MSFT ответил, что они сами написали. «DocumentDB is a new database engine built ground up for JSON documents.» Более подробно введением в DocumentDB можно прочест в этой статье. Часть этой статьи я расскажу ниже.
JS/JS engine Разработчики сообщили, что они реализовали стандарт ECMA и что это не очередная нестандартная реализация.«DocumentDB JavaScript server side SDK provides support for the most of the mainstream JavaScript language features as standardized by ECMA-262.«Движок JavaScript встроен в систему. Я задал вопрос: какой у них движок внутри, т.к. непонятно.
На форуме мне ответили примерно так: это не с нуля написанный движок — мы давно используем его на server side. Правда, я не понял где конкретно, даже прочитав ссылку, которую мне порекомендовали.
Протокол взаимодействия с DocumentDB На низком уровне взаимодействие идет через TCP, а сам API — это rest API.Т. е. get/post/put/delete.Обратно приходит ответ в виде json.Microsoft предоставляет SDK для .net, node.js, python.Всем остальным можно самим имплементировать работу с DocumentDB, т.к. API предоставляется через http протокол, и есть вот такое описание.Размеры и производительность базы данных Пока есть только заявление Microsoft, что сервис очень хорошо и потенциально бесконечно масштабируемый.Цитата: «A DocumentDB database is elastic by default — ranging from a few GB to petabytes of SSD backed document storage and provisioned throughput. Unlike a database in traditional RDBMS, a database in DocumentDB is not scoped to a single machine. With DocumentDB, as your application«s scale needs grow, you can create more collections or databases or both. Indeed, various first party applications within Microsoft have been using DocumentDB at a consumer scale by creating extremely large DocumentDB databases each containing thousands of collections with terabytes of document storage.«There is no practical scale limit to the size of a database account — any number of capacity units can be added over time subject to the offer restrictions.»
Как скейлятся разные коллекции очевидно. Т.к. отсутствуют join между коллекциями, то и каждая коллекция может быть от другой независимой, а также может находиться на совершенно другом физическом железе. Скейлить же одну коллекцию уже сильно проще.
Хранение Я не нашел в публичном доступе информации о том, как данные хранятся внутри DocumentDB. В MongoDB мы знаем, что все хранится в BSON. Поэтому я задал вопрос на форуме.В ответе было написано, что хранится именно json с небольшим числом дополнительных полей.
Для бинарных файлов есть 2 варианта: хранить их в DocumentDB или на собственном внешнем ресурсе (назывался даже onedrive, dropbox, azure tables). Если хранить в DocumentDB, то, на самом деле, бинарные объекты будут лежать в Blob Storage.
Запросы
Перед написание запросов, стоит глянуть картинку- что к чему привязано и что во что входит: 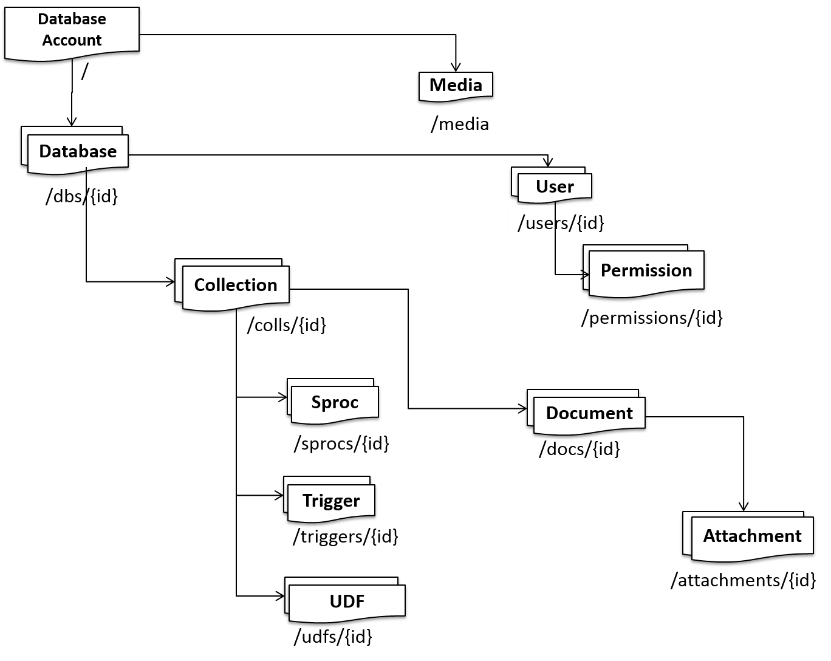
Способ написания запросов сочетает в себе sql-образный синтаксис и то, как пишут запросы в mongoDB для выбора результирующего набора данных. Глубже разобраться в вопросе можно здесь, а я расскажу о концептуальном написании запросов.
В DocumentDB запросы мы можем писать либо на sql, либо воспользоваться LINQ для .net.
Допустим у нас есть коллекция, в которой есть 2 документа: 

Пишем простой select * с условием where и получаем только 1 запись. В целом очень даже sql.

Не стоит думать, что размер выходного потока бесконечен. В документе по ограничениям указано, что на данный момент ограничение составляет 1 мб.
Второй пример с выборкой только части исходного документа.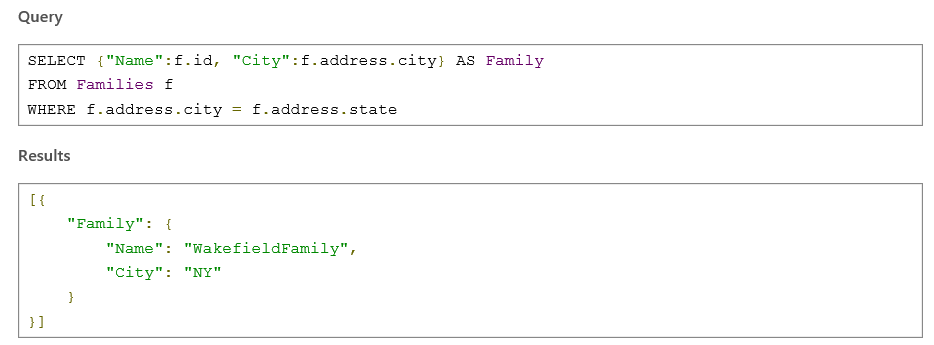
Программная модель Для DocumentDB можно писать триггеры, хранимые процедуры и UDF (user defined function). В отличии от mssql/oracle или других реляционных БД, здесь запросы мы будем писать на JavaScript. В принципе, на js можно накрутить любую логику, и за счет http-интерфейса общения с базой данных на этом можно написать хоть весь backend приложения… Но, судя по всему, разработчики DocumentDB позаботились о таких горячих головах и ввели ограничение на время исполнение любого клиентского кода в 5 секунд.В DocumentDb, как и в любой нормальной базе данных, есть транзакции, но на них останавливаться желания у меня не возникло.
Индексы и политика индексирования Индексы по умолчанию строятся автоматически. Мы же, как разработчики, можем отключить эту настройку и указать шаблон, по которому будет собираться индекс (по каким полям).Индекс может быть синхронным (consistent) и асинхронным (lazy). Синхронный строится сразу после вставок в коллекцию, а асинхронный с задержкой. Задержка нужна для оптимизации скорости записи при массовой записи.
Размер индекса вместе с самой коллекцией составляет полный объем потребляемой памяти.
Программирование под DocumentDB Моя рекомендация: прежде чем начать экспериментировать, прочесть статью об ограничениях по использованию Чтобы не ломать голову, почему 2 UDF не работает в одном запросе. В документе это описано.Каждой хранимке-триггеру-UDF выделяется фиксированный квант ресурсов операционной системы, в течение которого она должна быть выполнена.(Each stored procedure, trigger or a UDF gets a fixed quantum of operating system resources to do its work) Т.к. в документации я нашел только о 5 секундах на исполнение и ничего про другие ограничения (например, про память), то задал вопрос на форуме.
Further, stored procedures, triggers or UDFs cannot link against external JavaScript libraries and are blacklisted if they exceed the resource budgets allocated to them. Понять, как вытащить хранимку из blacklist.
Сами хранимки и тп компилируются в байткод. Надо понять, хранятся они в обоих видах или только в бинарном — для меня это пока вопрос открытый.
Upon registration a stored procedure, trigger, or a UDF is pre-compiled and stored as byte code which gets executed later.
Stored Procedure
В хранимых процедурах ничего интересного нет. Но на них удобно показывать концепции написания кода на js для DocumentDB.Создаем процедуру.  Регистрируем ее в DocumentDB
Регистрируем ее в DocumentDB  Вызываем
Вызываем  Триггеры
Зачем нужны триггеры очевидно из того, как они вызываются. А вызываются они по событию. Триггеры бывают 2 типов: Pre и Post. Т.е. они работают до и после операции. Триггер может быть запущен по выбранному типу операции (Create, Replace, Delete or All/POST/PUT/DELETE).Pre-триггеры имеют доступ к данных входного запроса.Post-триггер имеет доступ к данным, которые будут отданы клиенту.
Триггеры
Зачем нужны триггеры очевидно из того, как они вызываются. А вызываются они по событию. Триггеры бывают 2 типов: Pre и Post. Т.е. они работают до и после операции. Триггер может быть запущен по выбранному типу операции (Create, Replace, Delete or All/POST/PUT/DELETE).Pre-триггеры имеют доступ к данных входного запроса.Post-триггер имеет доступ к данным, которые будут отданы клиенту.
UDF Отличие UDF от Stored Procedure простое- UDF нельзя вызвать снаружи. Хранимую процедуру- можно.Цитата: «User-defined functions, or UDFs are used to extend the DocumentDB SQL query language grammar and implement custom business logic. They can only be called from inside queries. They do not have access to the context object and are meant to be used as compute-only JavaScript. Therefore, UDFs can be run on secondary replicas of the DocumentDB service.» А где запускаются by default мне не понятно.Миграция данных Пока никаких утилит миграции я не нашел, что логично, т.к. проект еще только в preview. Плюс есть проблема: переносить данные из реляционной базы требует переосмысления структуры хранения, схемы, денормализации, возможно. Наверное, пока таких утилит нету (и не факт что будут).Репликация На странице, где анонсировали эту фичу, есть фраза: «Data is automatically replicated to provide high availability.» Но ничего более подробного я пока не нашел. Поэтому я спросил о репликах.Краткий ответ был такой: есть алгоритм, который контролирует и т.п. По факту, есть 1 основная реплика, и, как минимум, 2 вторичных. Сейчас они все в одном датацентре, но разнесены по различному оборудованию (при падении одной железки, база останется жива.) Если нужна геораспределенность — напишите о вашем желании.
Monitoring и Alerts Как и у любого cloud service, у DocumentDB если система мониторинга. Вы можете собирать метрики среднее число запросов за период и общее количество запросов. Правда пока это доступно на preview портале Azure и недоступно на основном. Зачем эти метрики нужны, я думаю, очевидно.Также можно настроить оповещения на email о нарушении некоторых границ. Для этого надо настроить правило нотификации Alert Rule и указать кому отправить. Статья про настройку мониторинга и оповещений:
Т.к. я знаю что к сопровождению постоянно приходят какие-то нотификации, то было бы интересно иметь возможность об особо критичных проблемах присылать не только email, но и sms. Это я предложил на форуме.
Почему не MongoDB? Ее написали не они! Мое мнение — компания уровня Microsoft может написать свою документно-ориентированную базу данных, чтобы не зависеть от внешних вендоров. У нее для этого есть время, деньги, компитенции, необходимость.Чем DocumentDB лучше MongoDB? Пока она в preview, ее никто особо не ковырял, поэтому рассуждать сложно, особенно что касается сравнения производительности.Вопрос сравнения с mongo на сайте с feedback уже подняли до меня, я лишь поддержал.
В случае Azure от себя могу сказать, что DocumentDB сейчас настраивается в 2–3 клика мышкой (как и многие другие сервисы в Azure), а MongoDB надо себе ставить либо самому на виртуальную машину и разбираться с конфигурированием, либо запросить предварительно сконфигурированную виртуалку. Цитата от Microsoft
«Fully managed: Eliminate the need to manage database and machine resources. As a fully-managed Microsoft Azure service, you do not need to manage virtual machines, deploy and configure software, or deal with complex data-tier upgrades. Every database is automatically backed up and protected against regional failures. You can easily add a DocumentDB account and provision capacity as you need it, allowing you to focus on your application vs. operating and managing your database».
В DocumentDB вы будите писать sql подобные запросы, что сокращает порог вхождения для разрботка. В MongoDB вам придется освоить не такой привычный синтаксис операторов тк не sql base.
Ссылки
