Теория вероятностей в машинном обучении. Часть 1: модель регрессии
В данной статье мы подробно рассмотрим вероятностную постановку задачи машинного обучения: что такое распределение данных, дискриминативная модель, i.i.d.-гипотеза и метод максимизации правдоподобия, что такое регрессия Пуассона и регрессия с оценкой уверенности, и как нормальное распределение связано с минимизацией среднеквадратичного отклонения.
В следующей части (статья готовится) рассмотрим метод максимизации правдоподобия в классификации: в чем роль кроссэнтропии, функций сигмоиды и softmax и как кроссэнтропия связана с «расстоянием» между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии.
В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям, таким как метод апостериорного максимума, методы Монте-Карло и вариационный вывод. Рассмотрим, как применение этих методов порождает типичные для машинного обучения понятия, такие как стохастический градиентный спуск, регуляризация, ансамблирование, подбор архитектуры и гиперпараметров. Также поговорим о роли априорных гипотез в машинном обучении.
Бывало ли у вас такое, что разбираясь в некой сложной области вам сначала не удается систематизировать в голове всю имеющуюся информацию, а затем вы что-то узнаете или догадываетесь, и пазл внезапно складывается в стройную и непротиворечивую картину? Именно такую роль может сыграть понимание байесовского вывода в машинном обучении.
Как писал Пьер-Симон Лаплас в начале XIX века, «теория вероятностей — это здравый смысл, выраженный в вычислениях». Поэтому разрабатывать алгоритмы машинного обучения можно и не опираясь на теорию вероятностей и байесовский вывод. Но с изучением этих областей то, что раньше казалось просто здравым смыслом, приобретает большую строгость и обоснования.
Впрочем, в машинном обучении любые теории строятся на очень зыбкой почве, поскольку машинное обучение — это не чистая математика, а наука о применении алгоритмов обучения на данных к реальному миру. Любая математическая теория основана на аксиомах и условиях (например, в статистике таким условием часто является «независимость и одинаковая распределенность обучающих примеров»). В реальности эти условия могут не выполняться, и иногда даже не иметь четкого смысла. Об этой теме мы тоже поговорим подробнее.
Возможно, изложение в статье покажется слишком подробным и затянутым, но эти вещи невозможно объяснить в двух словах. Большое количество деталей и пояснений позволяет надеяться, что ничего важного не будет упущено, и в понимании не останется пробелов.
Содержание текущей части
В первом разделе мы рассмотрим связь между машинным обучением и статистическим выводом.
Во втором разделе поговорим о моделях: рассмотрим вероятностную модель регрессии и ее обучение методом максимизации правдоподобия.
В третьем разделе поговорим о данных: рассмотрим понятие вероятностного распределения данных, задачу максимизации метрики на распределении и i.i.d.-гипотезу.
В четвертом разделе снова вернемся к методу максимизации правдоподобия, используя материал из третьего раздела, и введем понятие статистической модели.
В пятом разделе рассмотрим модель регрессии с оценкой уверенности в виде формул и программного кода.
Звездочкой* отмечены дополнительные разделы, которые не повлияют на понимание дальнейшего материала.
1. Машинное обучение и статистический вывод
2. Вероятностная модель регрессии
2.1. Регрессия, классификация и промежуточные варианты
2.2. Вероятностное моделирование
2.3. Модель регрессии
2.4. Обсуждение
2.5. Функция потерь Хьюбера*
3. Вероятностное распределение данных
3.1. Понятие распределения данных
3.2. Дискриминативные модели
3.3. Генеративные модели*
3.4. i.i.d.-гипотеза и качество обобщения
3.5. Проблемы i.i.d.-гипотезы*
4. Статистические модели
4.1. Простые статистические модели
4.2. Статистические модели в машинном обучении
5. Регрессия с оценкой уверенности*
5.1. Моделирование дисперсии в модели регрессии*
5.2. Регрессия с константной оценкой дисперсии*
1. Машинное обучение и статистический вывод
Статистический вывод (оценка параметров и проверка гипотез) часто включается в курсы машинного обучения. Но многими он воспринимается лишь как досадная заноза, которая только отнимает время и далее нигде не используется. Однако машинное обучение и статистический вывод тесно связаны и решают почти одну и ту же задачу.
Машинное обучение заключается в написании и применении алгоритмов, которые обучаются на данных, автоматически выводя общие закономерности из частных примеров.
Статистический вывод заключается в оценке параметров распределений и проверке гипотез на основе наблюдений, то есть опять-таки в получении общих выводов из частных примеров.
Процесс выведения общих правил из частных примеров называется обобщением (generalization), или индуктивным выводом (inductive inference). Чем же тогда отличаются эти два раздела науки? Граница между ними довольно расплывчата. Вообще говоря, большую часть машинного обучения можно считать статистическим выводом, что мы более формально рассмотрим в дальнейшем.
Иногда говорят, что в статистике целью обычно является вывод (inference) о том, верна ли гипотеза или как связаны между собой переменные, а в машинном обучении целью обычно является предсказание (prediction) или генерация чего-либо (Bzdok et al., 2018), хотя эти две цели часто близки. В машинном обучении, как правило, используются более сложные модели, тогда как в традиционной статистике модели обычно проще, но за счет этого они более интерпретируемы и больше внимания уделяется оценке уверенности в сделанных выводах (Breiman, 2001).

2. Вероятностная модель регрессии
2.1. Регрессия, классификация и промежуточные варианты
Задачи классификации и регрессии отличаются типом целевого признака: в регрессии целевой признак количественный (иногда его называют «числовой»), в классификации — категориальный. Отличие категориального от количественного признака заключается не в его типе (int или float), а скорее в предполагаемой метрике сходства на множестве его значений:
В количественном признаке чем больше модуль разности между двумя значениями, тем сильнее они непохожи друг на друга. Например, предсказать значение 2 вместо 1 будет в меньшей степени ошибкой, чем предсказать 10 вместо 1.
В категориальном признаке все значения, называемые классами, одинаково непохожи друг на друга. Например, предсказать 2-й класс вместо 1-го будет в той же степени ошибкой, что и предсказать 10-й класс вместо 1-го. При этом множество значений дискретно и, как правило, конечно.
Все остальные отличия в алгоритмах (в формате выходных данных, функции потерь и метрике качества) обусловлены описанной выше разницей между этими типами. Вообще, при желании задачу классификации технически можно решать как регрессию, то есть напрямую предсказывать номер класса и округлять его до целого числа. Регрессию, наоборот, можно свести к классификации, выполнив дискретизацию множества значений целевого признака. Такие модели кое-как обучатся, но чаще всего их качество на валидации будет существенно ниже, впрочем бывают и исключения (Müller et al., 2021).
В случае иерархической классификации (Silla and Freitas, 2011) целевой признак на первый взгляд является категориальным, но на деле некоторые классы могут быть ближе по смыслу и положению в иерархии друг к другу, чем другие. Например, в классификации животных предсказать овчарку вместо лабрадора является в меньшей степени ошибкой, чем предсказать бегемота вместо лабрадора. Это означает, что на множестве значений целевого признака есть какая-то нетривиальная метрика сходства, и ее желательно учесть в алгоритме обучения.
Будет ли это по прежнему задачей классификации? Сложно сказать. Базовые понятия «классификации» и «регрессии» не покрывают все разнообразие промежуточных вариантов (так же как есть промежуточные варианты между молотком, топором и другими инструментами) (Bernholdt et al., 2019, Twomey et al., 2019). Важно лишь то, что при выборе формата выходных данных и функции потерь нужно учитывать метрику сходства на множестве значений целевого признака. Это один из способов внесения в модель априорной (известной или предполагаемой заранее) информации, к чему мы будем еще не раз возвращаться.
2.2. Вероятностное моделирование
В задачах классификации и регрессии (и многих других задачах) требуется найти зависимость между исходными данными  и целевыми данными
и целевыми данными  в виде функции
в виде функции  . Обычно модель имеет параметры, которые подбираются в ходе обучения, поэтому модель можно записывать как функцию от входных данных
. Обычно модель имеет параметры, которые подбираются в ходе обучения, поэтому модель можно записывать как функцию от входных данных  и параметров
и параметров  . Поскольку параметров обычно много, то
. Поскольку параметров обычно много, то  — это некий массив чисел. Предсказанное моделью значение
— это некий массив чисел. Предсказанное моделью значение  (в отличие от истинного значения) обычно обозначается крышечкой (циркумфлексом):
(в отличие от истинного значения) обычно обозначается крышечкой (циркумфлексом):  .
.
Общая идея вероятностного моделирования заключается в том, что вместо одного числа модель должна предсказывать распределение вероятностей на множестве  при заданном значении
при заданном значении  . В теории вероятностей это называется условным распределением и записывается как
. В теории вероятностей это называется условным распределением и записывается как  или просто
или просто  . Поскольку модель имеет параметры, то вероятностную модель записывают как
. Поскольку модель имеет параметры, то вероятностную модель записывают как  — эта запись читается как «вероятность
— эта запись читается как «вероятность  при
при  и
и  » (позже рассмотрим конкретные примеры).
» (позже рассмотрим конкретные примеры).
Таким образом мы позволим модели «сомневаться» в предсказании. Выполнив такой переход, мы ничего не теряем: распределение вероятностей  несет больше информации, чем точечная оценка
несет больше информации, чем точечная оценка  . Зато мы получаем важное преимущество. Величина
. Зато мы получаем важное преимущество. Величина  определена для всех
определена для всех  , поэтому мы можем количественно оценить ошибку модели: чем меньшую вероятность модель назначает верному
, поэтому мы можем количественно оценить ошибку модели: чем меньшую вероятность модель назначает верному  , тем сильнее ошибка. Так мы естественным образом можем задать функцию потерь.
, тем сильнее ошибка. Так мы естественным образом можем задать функцию потерь.
2.3. Модель регрессии
Пусть мы имеем нейронную сеть с одним скрытым слоем шириной в  нейронов и хотим применить ее для решения задачи регрессии с
нейронов и хотим применить ее для решения задачи регрессии с  = 10 входными признаками. Такая сеть имеет 2 матрицы весов и 2 вектора bias’ов:
= 10 входными признаками. Такая сеть имеет 2 матрицы весов и 2 вектора bias’ов:  . Нетрудно посчитать, что, например, матрица
. Нетрудно посчитать, что, например, матрица  содержит
содержит  = 10000 весов, а всего количество весов равно 12001. Пусть в качестве функции активации используется
= 10000 весов, а всего количество весов равно 12001. Пусть в качестве функции активации используется  . Преобразование входных данных в выходные осуществляется по следующей формуле (всю сеть обозначим как функцию
. Преобразование входных данных в выходные осуществляется по следующей формуле (всю сеть обозначим как функцию  ):
):

Примечание. Умножение вектора  на матрицу
на матрицу  может выполняться слева (
может выполняться слева ( ) или справа (
) или справа ( ), в зависимости от того, работаем мы с векторами-строками или векторами-столбцами. Например, в TensorFlow используется умножение справа, и матрица весов имеет размер (in, out), в PyTorch — умножение слева, и матрица весов имеет размер (out, in).
), в зависимости от того, работаем мы с векторами-строками или векторами-столбцами. Например, в TensorFlow используется умножение справа, и матрица весов имеет размер (in, out), в PyTorch — умножение слева, и матрица весов имеет размер (out, in).
Меняя параметры  , можно получить совершенно разные функции
, можно получить совершенно разные функции  . Обучение сети заключается в том, что мы подбираем такие
. Обучение сети заключается в том, что мы подбираем такие  , чтобы минимизировать ошибку предсказания на обучающей выборке. Но способ расчета ошибки предсказания можно выбрать по-разному:
, чтобы минимизировать ошибку предсказания на обучающей выборке. Но способ расчета ошибки предсказания можно выбрать по-разному:
Алгоритмический подход. Мы выбираем способ расчета ошибки произвольным образом на основании здравого смысла, руководствуясь любыми соображениями. Например можем взять в качестве ошибки среднеквадратичное отклонение  или среднее абсолютное отклонение
или среднее абсолютное отклонение  . Нетрудно видеть, что
. Нетрудно видеть, что  . Поэтому MSE, в сравнении с MAE, не так сильно штрафует несущественные ошибки, но сильнее штрафует большие ошибки. Таким образом, MAE более устойчив к выбросам (подробнее см., например, здесь).
. Поэтому MSE, в сравнении с MAE, не так сильно штрафует несущественные ошибки, но сильнее штрафует большие ошибки. Таким образом, MAE более устойчив к выбросам (подробнее см., например, здесь).
Определившись с тем, как сильно нам нужно штрафовать большие ошибки в сравнении с маленькими, мы можем выбрать функцию потерь. Далее, поскольку в обучающей выборке много примеров, сложим величину ошибки на всех примерах и будем минимизировать полученную сумму.
Вероятностный подход. Будем рассматривать значение  как мат. ожидание нормального распределения с некой фиксированной дисперсией
как мат. ожидание нормального распределения с некой фиксированной дисперсией  . Так мы получим распределение вероятностей для
. Так мы получим распределение вероятностей для  при данном
при данном  :
:

Иногда то же самое записывают другим способом:

Формула плотности вероятности нормального распределения:

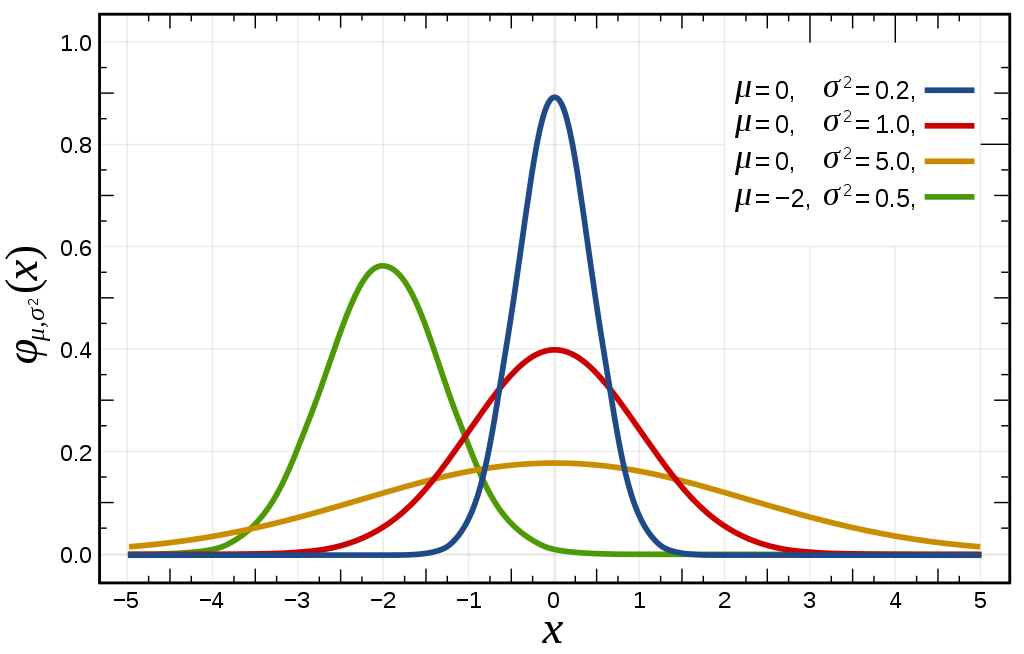
Эта формула выглядит несколько громоздкой, но на самом деле она несложная. Если мы обозначим  , то основу формулы (4) составляет выражение
, то основу формулы (4) составляет выражение  . График этой функции выглядит как характерный симметричный «колокол» с центром в
. График этой функции выглядит как характерный симметричный «колокол» с центром в  . Коэффициент
. Коэффициент  определяет «сжатие» колокола по горизонтальной оси, коэффициент
определяет «сжатие» колокола по горизонтальной оси, коэффициент  определяет «сжатие» по вертикальной оси. Эти коэффициенты выбраны так, чтобы интеграл функции от
определяет «сжатие» по вертикальной оси. Эти коэффициенты выбраны так, чтобы интеграл функции от  до
до  был равен единице (что требуется для всех распределений), и чтобы распределение имело дисперсию
был равен единице (что требуется для всех распределений), и чтобы распределение имело дисперсию  .
.
Итак, мы считаем, что для каждого  величина
величина  распределена нормально, и мат. ожидание распределения является функцией от
распределена нормально, и мат. ожидание распределения является функцией от  , которую требуется найти. В отличие от предыдущего подхода, теперь мы можем рассчитать вероятность для любого значения
, которую требуется найти. В отличие от предыдущего подхода, теперь мы можем рассчитать вероятность для любого значения  при
при  и
и  .
.
Для каждого обучающего примера: чем меньше вероятность истинного значения  при заданных
при заданных  и
и  , тем сильнее ошибка предсказания на данном примере. Отсюда естественным образом вытекает функция потерь: нам нужно максимизировать
, тем сильнее ошибка предсказания на данном примере. Отсюда естественным образом вытекает функция потерь: нам нужно максимизировать  . Формула (2) задает вид этого распределения, а формула (4) помогает подсчитать конкретное численное значение
. Формула (2) задает вид этого распределения, а формула (4) помогает подсчитать конкретное численное значение  для каждого обучающего примера.
для каждого обучающего примера.
Поиск значений параметров  , при которых вероятность (правдоподобие) наблюдаемых данных
, при которых вероятность (правдоподобие) наблюдаемых данных  максимальна, называется методом максимизации правдоподобия (maximum likelihood estimation, MLE). Параметры, максимизирующие правдоподобие, часто обозначают как
максимальна, называется методом максимизации правдоподобия (maximum likelihood estimation, MLE). Параметры, максимизирующие правдоподобие, часто обозначают как  , мы будем обозначать их как
, мы будем обозначать их как  .
.
Пока что мы рассмотрели только один пример, но в обучающей выборке много примеров. Будем искать такие параметры  , чтобы максимизировать произведение вероятностей для всех примеров (позже рассмотрим, почему именно произведение, а не сумму). Максимизация некой величины эквивалентна максимизации ее логарифма, а логарифм произведения равен сумме логарифмов множителей:
, чтобы максимизировать произведение вероятностей для всех примеров (позже рассмотрим, почему именно произведение, а не сумму). Максимизация некой величины эквивалентна максимизации ее логарифма, а логарифм произведения равен сумме логарифмов множителей:

Формула (5) говорит, что нам нужно минимизировать функцию потерь, равную сумме  по всем обучающим примерам
по всем обучающим примерам  , где
, где  мы моделируем нормальным распределением (2). Подставив выражение для нормального распределения (4) получим:
мы моделируем нормальным распределением (2). Подставив выражение для нормального распределения (4) получим:

Первые два слагаемых в (6) являются константами и поэтому не влияют на положение максимума по  , значит их можно удалить. В третьем слагаемом знаменатель является константой, поэтому он тоже не влияет на положение максимума по
, значит их можно удалить. В третьем слагаемом знаменатель является константой, поэтому он тоже не влияет на положение максимума по  , его можно заменить на единицу. После этих действий подставим (6) в (5) и получим:
, его можно заменить на единицу. После этих действий подставим (6) в (5) и получим:

Ранее мы вводили обозначение  . Согласно формуле (7) нам надо минимизировать сумму среднеквадратичных отклонений
. Согласно формуле (7) нам надо минимизировать сумму среднеквадратичных отклонений  по всем обучающим примерам. Вспомним, что изначально в модели регрессии мы считали
по всем обучающим примерам. Вспомним, что изначально в модели регрессии мы считали  константой, для которой выбрано произвольное значение. Теперь выясняется, что константа
константой, для которой выбрано произвольное значение. Теперь выясняется, что константа  не влияет на оптимальные параметры
не влияет на оптимальные параметры  , поэтому в задаче поиска оптимальных параметров ее значение не играет роли.
, поэтому в задаче поиска оптимальных параметров ее значение не играет роли.
Примечание. Значение  влияет на результат в байесовском выводе, который мы будем рассматривать в следующих частях.
влияет на результат в байесовском выводе, который мы будем рассматривать в следующих частях.
Резюме. В алгоритмическом подходе модель машинного обучения — это некая параметризованная функция  . Например, это может быть линейная регрессия, нейронная сеть, ансамбль решающих деревьев или машина опорных векторов (хотя две последние модели имеют переменное число параметров, но это не принципиально). Такая модель напрямую предсказывает значение
. Например, это может быть линейная регрессия, нейронная сеть, ансамбль решающих деревьев или машина опорных векторов (хотя две последние модели имеют переменное число параметров, но это не принципиально). Такая модель напрямую предсказывает значение  . В вероятностном подходе модель по-прежнему предсказывает число
. В вероятностном подходе модель по-прежнему предсказывает число  , но теперь это число считается не окончательным предсказанием
, но теперь это число считается не окончательным предсказанием  , а мат. ожиданием нормального распределения с некой фиксированной дисперсией
, а мат. ожиданием нормального распределения с некой фиксированной дисперсией  . Таким образом мы моделируем условное распределение
. Таким образом мы моделируем условное распределение  .
.
Важно понять, что между этими двумя подходами нет принципиальной разницы. Если вероятностная модель предсказывает, что » находится где-то вокруг точки
находится где-то вокруг точки  со среднеквадратичным отклонением
со среднеквадратичным отклонением  », то при точечной оценке модель предсказывает, что »
», то при точечной оценке модель предсказывает, что » равно
равно  », но при этом мы понимаем, что модель обычно не выдает идеально точных предсказаний, и интерпретируем ее предсказание как »
», но при этом мы понимаем, что модель обычно не выдает идеально точных предсказаний, и интерпретируем ее предсказание как » находится где-то вокруг точки
находится где-то вокруг точки  ».
».

Таким образом, вероятностная модель просто формализует то, что при точечной оценке мы предполагали неформально. Вспомним цитату Лапласа о том, что теория вероятностей — лишь здравый смысл, выраженный в вычислениях.
2.4. Обсуждение
На примере регрессии мы увидели, что вероятностный подход позволяет вывести выражение для функции потерь, которое в алгоритмическом подходе мы выбирали произвольно. Однако нормальное распределение в (2) мы выбрали произвольно. Вместо него мы могли бы взять, например, распределение Пуассона или Лапласа. В случае распределения Лапласа мы пришли бы к тому, что надо минимизировать среднее абсолютное отклонение  . Отсюда получается, что выбор распределения
. Отсюда получается, что выбор распределения  в вероятностном подходе эквивалентен выбору функции ошибки
в вероятностном подходе эквивалентен выбору функции ошибки  в алгоритмическом подходе.
в алгоритмическом подходе.
Какой же подход лучше — вероятностный или алгоритмический? Вероятностный подход удобно применять в тех случаях, когда есть объективные причины предполагать, что  имеет тот или иной вид:
имеет тот или иной вид:
Пример 1. Иногда мы знаем, что  — это количество неких событий, которые произошли в условиях
— это количество неких событий, которые произошли в условиях  — например, количество посетителей тренажерного зала в зависимости от погоды. Тогда распределение
— например, количество посетителей тренажерного зала в зависимости от погоды. Тогда распределение  скорее всего похоже на распределение Пуассона, параметр которого является функцией от
скорее всего похоже на распределение Пуассона, параметр которого является функцией от  . Мы можем расписать аналог формулы (2) для распределения Пуассона и из него вывести функцию потерь, которую следует применять. В результате мы получаем регрессию Пуассона. Кроме того, преимущество в том, что мы получаем не точечную оценку, а распределение вероятностей на
. Мы можем расписать аналог формулы (2) для распределения Пуассона и из него вывести функцию потерь, которую следует применять. В результате мы получаем регрессию Пуассона. Кроме того, преимущество в том, что мы получаем не точечную оценку, а распределение вероятностей на  .
.
Пример 2. Иногда мы знаем, что распределение  гетероскедастично, то есть дисперсия
гетероскедастично, то есть дисперсия  непостоянна и зависит от
непостоянна и зависит от  . Например, пусть
. Например, пусть  — доходы, а
— доходы, а  — расходы человека на питание. Понятно что в среднем
— расходы человека на питание. Понятно что в среднем  растет с ростом
растет с ростом  , но дисперсия
, но дисперсия  также растет: более богатый человек может тратить на еду много, а может тратить мало, в зависимости от предпочтений, тогда как более бедный человек скорее всего тратит мало. Поэтому в формуле (2) мы можем сделать дисперсию тоже функцией от
также растет: более богатый человек может тратить на еду много, а может тратить мало, в зависимости от предпочтений, тогда как более бедный человек скорее всего тратит мало. Поэтому в формуле (2) мы можем сделать дисперсию тоже функцией от  . Например, если мы используем нейронную сеть, то пусть она имеет 2 выходных нейрона: один нейрон предсказывает мат. ожидание нормального распределения для
. Например, если мы используем нейронную сеть, то пусть она имеет 2 выходных нейрона: один нейрон предсказывает мат. ожидание нормального распределения для  , а другой нейрон предсказывает дисперсию. Такой способ называется регрессией с оценкой (не)уверенности, в последнем разделе мы рассмотрим его подробнее. Пока что вы можете попробовать сами вывести требуемые формулы.
, а другой нейрон предсказывает дисперсию. Такой способ называется регрессией с оценкой (не)уверенности, в последнем разделе мы рассмотрим его подробнее. Пока что вы можете попробовать сами вывести требуемые формулы.
2.5. Функция потерь Хьюбера*
Часто мы используем нормальное распределение для  . Обоснован ли этот выбор? Иногда да. По центральной предельной теореме, если некая случайная величина
. Обоснован ли этот выбор? Иногда да. По центральной предельной теореме, если некая случайная величина  является суммой множества независимых случайных факторов, и каждый фактор вносит исчезающе малый вклад в сумму, то величина
является суммой множества независимых случайных факторов, и каждый фактор вносит исчезающе малый вклад в сумму, то величина  распределена приблизительно нормально. В реальности многие величины распределены приблизительно нормально. Однако распределения, которые встречаются в реальном мире, часто имеют более тяжелые хвосты, то есть большую вероятность встретить крайние значения. Скажем, рост или вес человека в популяции распределен приблизительно нормально, но рекордсмены по росту или весу (в ту или иную сторону) встречаются намного чаще, чем если бы распределение было строго нормальным.
распределена приблизительно нормально. В реальности многие величины распределены приблизительно нормально. Однако распределения, которые встречаются в реальном мире, часто имеют более тяжелые хвосты, то есть большую вероятность встретить крайние значения. Скажем, рост или вес человека в популяции распределен приблизительно нормально, но рекордсмены по росту или весу (в ту или иную сторону) встречаются намного чаще, чем если бы распределение было строго нормальным.
Поэтому разумно было бы моделировать  распределением, похожим на нормальное, но с более тяжелыми хвостами. Это снизило бы влияние выбросов. Например, распределение Лапласа имеет более тяжелые хвосты, чем нормальное распределение. Мы можем «склеить» эти два распределения, взяв центральную часть от нормального распределения и хвосты от распределения Лапласа. Если далее вывести функцию потерь по формуле (6) как минус логарифм плотности вероятности, то получим часто используемую функцию потерь Хьюбера. Эта функция потерь имеет гиперпараметр
распределением, похожим на нормальное, но с более тяжелыми хвостами. Это снизило бы влияние выбросов. Например, распределение Лапласа имеет более тяжелые хвосты, чем нормальное распределение. Мы можем «склеить» эти два распределения, взяв центральную часть от нормального распределения и хвосты от распределения Лапласа. Если далее вывести функцию потерь по формуле (6) как минус логарифм плотности вероятности, то получим часто используемую функцию потерь Хьюбера. Эта функция потерь имеет гиперпараметр  . Она не так сильно «штрафует» большие выбросы, как среднеквадратичная ошибка.
. Она не так сильно «штрафует» большие выбросы, как среднеквадратичная ошибка.

В целом, из формулы (5) видно, что функция потерь равна минус логарифму плотности вероятности для выбранного распределения. На самом деле графики плотности для многих распределений удобнее смотреть в логарифмическом масштабе по вертикальной оси. Например, нормальное распределение в логарифмическом масштабе выглядит как парабола с направленными вниз ветвями, а распределение Лапласа в логарифмическом масштабе выглядит как функция  . Зеркально отразив эти графики по оси
. Зеркально отразив эти графики по оси  , мы увидим график функции потерь. Скомбинировав нормальное распределение с хвостами от распределения Лапласа, получаем функцию потерь Хьюбера.
, мы увидим график функции потерь. Скомбинировав нормальное распределение с хвостами от распределения Лапласа, получаем функцию потерь Хьюбера.

Интересно, что функцию потерь Хьюбера можно рассматривать как среднеквадратичную ошибку + gradient clipping, применяемый к градиенту функции потерь по  . Gradient clipping означает, что если при обратном проходе
. Gradient clipping означает, что если при обратном проходе  по модулю больше некоего порога
по модулю больше некоего порога  , то он обрезается до этого порога:
, то он обрезается до этого порога:

Gradient clipping также применяется при обучении нейронных сетей, но в этом случае он действует не на градиент по  , а на градиент по весам.
, а на градиент по весам.
3. Вероятностное распределение данных
3.1. Понятие распределения данных
Как правило считается, что обучающие и тестовые данные берутся из одного и того же совместного распределения  , называемого распределением данных или генеральной совокупностью. Говоря о распределении
, называемого распределением данных или генеральной совокупностью. Говоря о распределении  или
или  , мы условно предполагаем наличие некоего «бесконечного генератора пар
, мы условно предполагаем наличие некоего «бесконечного генератора пар  », из которого взяты обучающая и тестовая выборка.
», из которого взяты обучающая и тестовая выборка.
Конечно, генеральная совокупность данных — это условность, и вопрос ее близости к истине довольно философский. Обычно мы имеем лишь конечную выборку данных, добытую тем или иным способом, но не имеем строгого определения для  . Но в целом мы считаем, что
. Но в целом мы считаем, что  наиболее велико для «типичных» пар
наиболее велико для «типичных» пар  , и равно нулю для невозможных пар (в которых либо
, и равно нулю для невозможных пар (в которых либо  , либо
, либо  ).
).
Например, пусть мы имеем датасет из объявлений о продаже автомобилей. Для нашего датасета верно, например, следующее:
Количество авто «Lada Granta» превосходит количество авто «Москвич-412»
Количество авто «Победа» с двигателем мощностью 500 л. с. равно нулю
Тогда мы можем считать датасет выборкой из распределения, в котором для  верно следующее:
верно следующее:
p (x|\text{марка}(x) = \text{«Москвич-412»})» src=«https://habrastorage.org/getpro/habr/upload_files/453/557/448/4535574480427d49dc355846deef707f.svg» />

Если распределение  невырождено (то есть не назначает всю вероятность одной точке), то это значит, что
невырождено (то есть не назначает всю вероятность одной точке), то это значит, что  не может быть однозначно определен из
не может быть однозначно определен из  , но может быть определен приблизительно.
, но может быть определен приблизительно.
3.2. Дискриминативные модели
Запишем одну из базовых формул теории вероятностей:

Модели, которые моделируют  , то есть ищут некое приближение для истинного
, то есть ищут некое приближение для истинного  , называют дискриминативными моделями. Иногда используют другую терминологию: Murphy, 2023 называет модели
, называют дискриминативными моделями. Иногда используют другую терминологию: Murphy, 2023 называет модели  предиктивными моделями, которые делятся на дискриминативные (классификация) и модели регрессии.
предиктивными моделями, которые делятся на дискриминативные (классификация) и модели регрессии.
Важная особенность всех таких моделей в том, что они не моделируют вероятность входных данных  . Это означает, что дискриминативная модел
. Это означает, что дискриминативная модел
