Так dd вы ещё не использовали: исследование скорости чтения и записи

Недавно, я вновь побывал в роли технического эксперта, когда занимался переводом книги «Understanding Software Dynamics» от Richard L. Sites. В ходе работы над главой — про скорость работы с жёстким диском, мне поступил вопрос от коллеги: каким образом можно просто и быстро измерить скорость чтения и записи твердотельных носителей информации, в разрабатываемых в компании устройствах? При этом стояла задача реализовать всё это наиболее простыми способами, чтобы они были переносимы между совершенно разными платформами и архитектурами. Носители же информации могут быть любыми: USB Flash, eMMC, SD, NAND и прочее, прочее. Единственное, что их объединяет — это Linux.
Задача захватила меня с головой…Тем более, когда я понимал, что решение не такое тривиальное, как хотелось бы. При этом нужно дать какой-то простой и переносимый инструмент для его реализации.
Решение, с одной стороны, очевидное — это утилита dd. Но так ли просто измерить скорость твердотельного диска, а я уж не говорю о настоящем жёстком диске? В попытке ответить на этот вопрос моему коллеге, у меня получилось настоящее исследование, которым и хочу с вами поделиться.
Поскольку при тестировании диска нужно производить как операции записи на диск, так и операции чтения, то дабы сократить объём статьи в два раза, буду приводить примеры только операции записи на диск, как наиболее тяжёлые, для чтения будет всё аналогично, только будут другие цифры. Но всё что я тут ниже буду рассказывать, относится и к операциям чтения, просто цифры будут немного другие.
❯ Пару слов об утилите dd
Для тех, кто не знаком с этой утилитой или не пользуется *nix системами краткий ликбез про эту команду. Конечно, лучше, чем в вики не скажешь, поэтому позволю несколько цитат оттуда:
dd (data definition) — программа UNIX, предназначенная как для копирования, так и для конвертации файлов. Название унаследовано от оператора DD (Data Definition) из языка JCL.
Название утилиты dd иногда в шутку расшифровывают, как «disk destroyer», «data destroyer», «delete data» или «добей диск», так как утилита позволяет производить низкоуровневые операции на жёстких дисках — при малейшей ошибке (такой, как реверс параметров if и of) можно потерять часть данных на диске (или даже все данные). Есть и более «уважительное» прозвище — «disk duplicator», потому что на практике основное её применение — это копии, образы и бэкапы разделов.
Я всё же настоятельно рекомендую прочитать man dd перед её использованием, поскольку её возможности достаточно обширны, но кратко описание команды можно также взять с вики:
Базовые параметрыdd [--help] [--version] [status] [if=файл] [of=файл] [ibs=байты] [obs=байты] [bs=байты] [cbs=байты] [skip=блоки] [seek=блоки] [count=блоки] [conv={ascii, ebcdic, ibm, block, unblock, lcase, ucase, swab, noerror, notrunc, sync}]
- status=progress — отображает статистику передачи, возможны 3 варианта 'none', 'noxfer', 'progress' GNU Coreutils 8.24+ (Ubuntu 16.04 and newer).
- if=файл — читает данные из файла вместо стандартного ввода.
- of=файл — пишет данные в файл вместо стандартного вывода.
- bs=n — размер блока.
- ibs=nn и obs=nn — задаёт, сколько байтов нужно считывать или записывать за раз.
- count=n — сколько блоков скопировать.
- seek=n — сколько блоков пропустить от начала в выходном файле перед копированием.
- skip=n — сколько блоков пропустить от начала во входном файле перед копированием.
- conv=фильтр, фильтр — применить фильтры конвертации. Типы фильтров:
- ascii — сконвертировать в ASCII из EBCDIC…
- ebcdic — …и наоборот.
- block — выравнивание блоков.
- lcase — преобразовать к нижнему регистру.
- ucase — преобразовать к верхнему регистру.
- swab — менять местами пары байт.
- noerror — игнорировать ошибки ввода-вывода.
Простой пример утилиты dd — это как сделать копию главной загрузочной записи MBR жёсткого диска:
dd if=/dev/hda of=bootloader.mbr bs=512 count=1
ВАЖНО: При работе с утилитой dd нужно соблюдать большую внимательность, потому что ей легко и просто уничтожить все данные на жёстком диске. Недавно, вышеупомянутый коллега, таким образом снёс себе систему. Да, чего уж там скрывать, я сам неоднократно стирал совсем не те диски. Поэтому обычно по десять раз всё проверяю.
Резюмируя, утилита позволяет читать и записывать данные как на диск, так и в файл. А поскольку в операционных системах семейства *nix всё есть файл, то это практически равнозначно! Хотя нет, и ниже поясню почему.
❯ Можно ли dd использовать для тестирования скорости записи и что не так с этим тестом?
Для начала продемонстрирую один эксперимент, демонстрирующий разницу скорости работы утилиты dd.
Смотрите, я хочу создать файл, заполненный нулями. Для этого вычитаю файл-устройство /dev/zero и запишу его в регулярный файл на диске.
Отличие будет в количестве данных считываемых за раз: в первом случае я буду читать 1 байт за раз, а в другом случае 1МиБ. Кстати, особенность операционной системы линукс состоит в том, что она не гарантирует запись на диск после окончания операции dd. Данные просто были скопированы в ядро, поэтому после утилиты dd нужно выполнить команду sync для того, чтобы данные попали на диск из буфера ядра.
Критерием выполнения операции будет общее время исполнения dd и sync.
В результате получится две команды:
Для первого случая, читаем 1 байт за раз и записываем миллион штук:
time $(dd if=/dev/zero of=test.raw bs=1 count=1M && sync)
Во втором случае читаем 1 мегабайт за раз и пишем один раз:
time $(dd if=/dev/zero of=test.raw bs=1M count=1 && sync)
Вроде бы незначительная разница в двух командах, и многие не глядя делают первый вариант. Но какая разница в скорости выполнения. Даже скриншотом приложу, чтобы вы не думали, что я мухлюю:

Сравните две цифры: 1,910 секунды и 0,01 секунды! Разница в скорости в сто девяносто один раз!!!
А причина достаточно простая, жёсткий диск — это блочное устройство и работа с ним ведётся блоками данных. Если вы читаете или пишете (как в случае выше) 1 байт, вы всё равно записываете блок данных, который больше 1 байта, а может быть размером от 512 и более байт, которое кратно 512 байтам.
Блочные устройства помечаются в папке /dev/ буквой «b»:

Как вы понимаете, размер блока определяется особенностями работы конкретного физического устройства и реализацией драйвера внутри ядра.
Но ради всех дисков и решений погружаться в дебри кода ядра и схемотехники дисков совсем не хочется, а хочется понять при каком размере блока можно получить максимальную скорость записи на диск.
Таким образом, мы подходим к основной части исследования: какой оптимальный размер блока для записи на диск?
❯ Какой размер блока оптимален для записи на дисковое устройство?
Ответ не совсем очевиден: он зависит от аппаратных особенностей реализации устройства, для памяти типа NAND — это будет блок одного размера (вероятнее размером со страницу), для жёстких дисков другого.
Поэтому я определился с подопытным кроликом. Для этих варварских экспериментов, которые дико снизят ресурс любого флеш-накопителя, решил принести в жертву неиспользуемую флешку на 16 ГБ (обращаю внимание, что реальный её размер 14,32 ГиБ).

Жертвенный носитель
Для того чтобы не лопатить вручную команды, набросал простенький скриптик на питоне, на который я потратил два дня, который запускает команду dd. Да, можно было непосредственно писать в файл прямо с питона, но у меня была задача проверить именно эту утилиту. С исходным файлом кода скрипта можно ознакомиться на гитхабе.
Смысл его в том, что он по очереди перебирает размер блока (bs) от минимального 512 байт до максимального 16МиБ, и записывает данные в указанный пользователем файл.
Практика показала, что оптимально для исследований размер записи не менее 1 ГиБ, и количество записей — не менее 9 (разброс показаний погрешности).
Таким образом, если флешка у нас является файл-устройством /dev/sdg, то команда для тестирования будет выглядеть следующим образом:
sudo python3 dd_speed_test.py -o /dev/sdg -s 1024 -n 9 --logfile="disk_test.txt"
Прошу вас, обязательно проверьте файл-устройство, куда вы пишете, иначе вы потеряете ваши данные!
Поскольку данных много, то я решил брать от них два параметра: среднее и медианное значение. Более доверяю медианному, потому что оно ближе к реальности. Конечно, если бы это было научное исследование, тут хорошо бы учитывать разброс значений, чтобы понимать максимум и минимум. Но не буду перегружать статью. В результате этого эксперимента получил такую табличку:

Ничто так не украшает статью, как хороший график, который построен следующим скриптом.

Время записи 1 ГиБ данных на диск в зависимости от размера блока данных
Видно, что самая быстрая запись идёт блоком — размером 1 киБ, а самая медленная — блоком размером 512 байт (хотя, казалось бы). Размер, который я использую в быту — 1 МиБ, вполне себе находится в допуске самых быстрых.
Обращаю внимание, что эти данные — результаты эмпирического исследования скорости записи на конкретную флешку, хотя, разумеется, с твердотельными накопителями графики, вероятнее всего, будут схожими.
Вывод главы: наиболее оптимальным блоком данных, при непосредственной записи на диск оказался размер в 1 киБ.
А теперь интересный вопрос, а можно ли измерять скорость записи на диск, не стирая данные на нём, а записывая в файл в файловой системе?
❯ Особенности организации записи файла на диск
Для того чтобы показать, как делается запись данных на диск с файловой системой, я сделаю виртуальное файл-устройство и буду его конвертировать в картинку. Если цвет белый — это байт 0xFF, а если какой-либо другой, то значит отличные от 0xFF.
Для удобства, размер картинки с разрешением 1536х1024 выбрал наиболее приближённой к размеру дискетки: 1536*1024=1572864 байт.
Итак, создаю тестовый RAW-файл, заполняя его 0xFF (белый цвет).
time dd if=/dev/zero bs=1572864 count=1 | LC_ALL=C tr "\000" "\377" | dd of=test.raw
Создаю файловую систему в этом файле
mkfs.fat test.raw -n TEST_FAT
При этом это реальная файловая система в файле, в чём можно убедиться командой file:
file test.raw
test.raw: DOS/MBR boot sector, code offset 0x3c+2, OEM-ID "mkfs.fat", sectors/cluster 4, root entries 512, sectors 3072 (volumes <=32 MB), Media descriptor 0xf8, sectors/FAT 3, sectors/track 16, reserved 0x1, serial number 0x1f307932, label: "TEST_FAT ", FAT (12 bit)
Если сейчас этот RAW-файл с файловой системой конвертнуть в картинку, следующей командой:
convert -size 1536x1024 -depth 8 gray:test.raw fat.png
то мы увидим, что в начале были сделаны какие-то записи структуры файлов. В картинке в GIMP специально сделал синюю рамку, чтобы была лучшая наглядность.

Преобразованная виртуальная файловая система в изображение
Чёрная полоска вначале этой белой картинки и есть файловая система, которая даже занимает какое-то место.
Теперь можно примонтировать файловую систему.
udisksctl loop-setup -f test.raw
udisksctl mount -b /dev/loop0
У меня после первой команды монтируется автоматом в Linux Mint, поэтому вторая не требуется.
Можно посмотреть информацию об этом файл-устройстве:
df -a /dev/loop0
Файл.система 1K-блоков Использовано Доступно Использовано% Cмонтировано в
/dev/loop0 1516 0 1516 0% /media/dlinyj/TEST_FAT
Обратите внимание, что свободно 1516 блоков, что на 20 блоков по одному килобайту меньше, чем размер созданного файла. Вероятнее всего, 20 КиБ занимает файловая система.
А теперь самое главное, ради чего мы здесь собрались, записываем тестовый файл размером 1 МиБ в эту виртуальную файловую систему.
dd if=/dev/zero of=/media/dlinyj/TEST_FAT/test bs=1M count=1 && sync
И смотрим, как же выглядит файловая система после записи. Просто смотреть на картинку после записи особого смысла нет, поэтому сделаю diff полученного файла с тем, который был до записи:
convert -size 1536x1024 -depth 8 gray:test.raw fat_and_file.png
compare fat.png fat_file.png diff.png
Результирующее изображение произведённых изменений:

Изменения, внесённые в файловую систему виртуального устройства
Большой красный прямоугольник — это как раз наши записанные 1МиБ данных, а тонкая красная полоска — это записи в файловой системе о том, где хранятся эти кластеры данных.
Почему это важно? Потому что на запись каждого блока, надо читать файловую систему и редактировать таблицу данных файловой системы и записывать её обратно. То есть, идёт на каждую порцию данных дополнительные накладные расходы на правку файловой системы. И это означает, что запись на диск в файл должна быть медленнее, чем непосредственная запись на диск.
Но так ли это на самом деле? Ответ вас может сильно удивить, и он удивил даже меня. Она может быть даже быстрее (и будет быстрее, если неверно выбрать размер блока). И сейчас объясню почему.
❯ Измерение скорости записи на диск, при работе с файлом
Прежде чем делать выводы, давайте также проведём исследование с созданием файла на флешке, с использованием утилиты dd и проверим, какой же размер блока будет оптимальным.
Для начала, после зверских опытов с флешкой, создадим на ней файловую систему. Первично диск нужно разметить командой fdisk:

После этого, во вновь созданном разделе создаю файловую систему FAT32. И монтирую её.
mkfs.fat -F 32 /dev/sdg1 -n TEST_FLASH
udisksctl mount -b /dev/sdg1
Что ж, настало время теста:
python3 dd_speed_test.py -o /media/dlinyj/TEST_FLASH/testfile -s 1024 -n 9 --logfile="file_test.txt"
Результаты такого тестирования представлены в таблице ниже.

И конечно, красивый график, куда ж без него.

Время записи в регулярный файл на диске в зависимости от размера блока
Видно, что чем больше размер блока, тем быстрее идёт запись. Но внимательный читатель посмотрел на числа, и всё встаёт на свои места, если наложить график времени непосредственной записи на диск — на график записи в файл.

Сравнение времени записи прямой на диск и в файл в зависимости от размера блока
Можно увидеть, что по сути — размер bs никак не влияет на скорость записи в файл! А скорость записи показывает практически самые лучшие показатели, как при непосредственной записи на диск.
Почему же так получается, и можно ли тестировать таким образом скорость записи на диск? Всё достаточно просто: происходит кеширование внутри ядра, в том числе записей в файловую систему. И потом запись происходит на самой оптимальной скорости на диск, прямо из буфера ядра. Как можно убедиться, на 1, 2 и 4 киБ таки проигрывает максимальной скорости записи на диск.
А можно ли получить реальную скорость записи, когда запись производится непосредственно? Да, отключив буферизацию.
❯ Отключаю буферизацию записи
Отключить кеширование можно с помощью команды hdparam, с помощью опции -W, которая согласно документации, позволяет управлять размером буфера.
-W Get/set the IDE/SATA drive´s write-caching feature.
Сделаем его равным нулю:
sudo hdparm -W0 /dev/sdc
/dev/sdc:
setting drive write-caching to 0 (off)
SG_IO: bad/missing sense data, sb[]: f0 00 05 00 00 00 00 14 00 00 00 00 20 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
SG_IO: bad/missing sense data, sb[]: f0 00 05 00 00 00 00 14 00 00 00 00 20 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
SG_IO: bad/missing sense data, sb[]: f0 00 05 00 00 00 00 14 00 00 00 00 20 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
write-caching = not supported
Ну и произведём тестирование с отключенным буфером (бедная флешка):
python3 dd_speed_test.py -o /media/dlinyj/TEST_FLASH/disk_file -s 1024 -n 9 --logfile="cache_off.txt"В результате получаются цифры намного более близкие к реальности, чем в предыдущем тесте.

Ну и конечно же график.
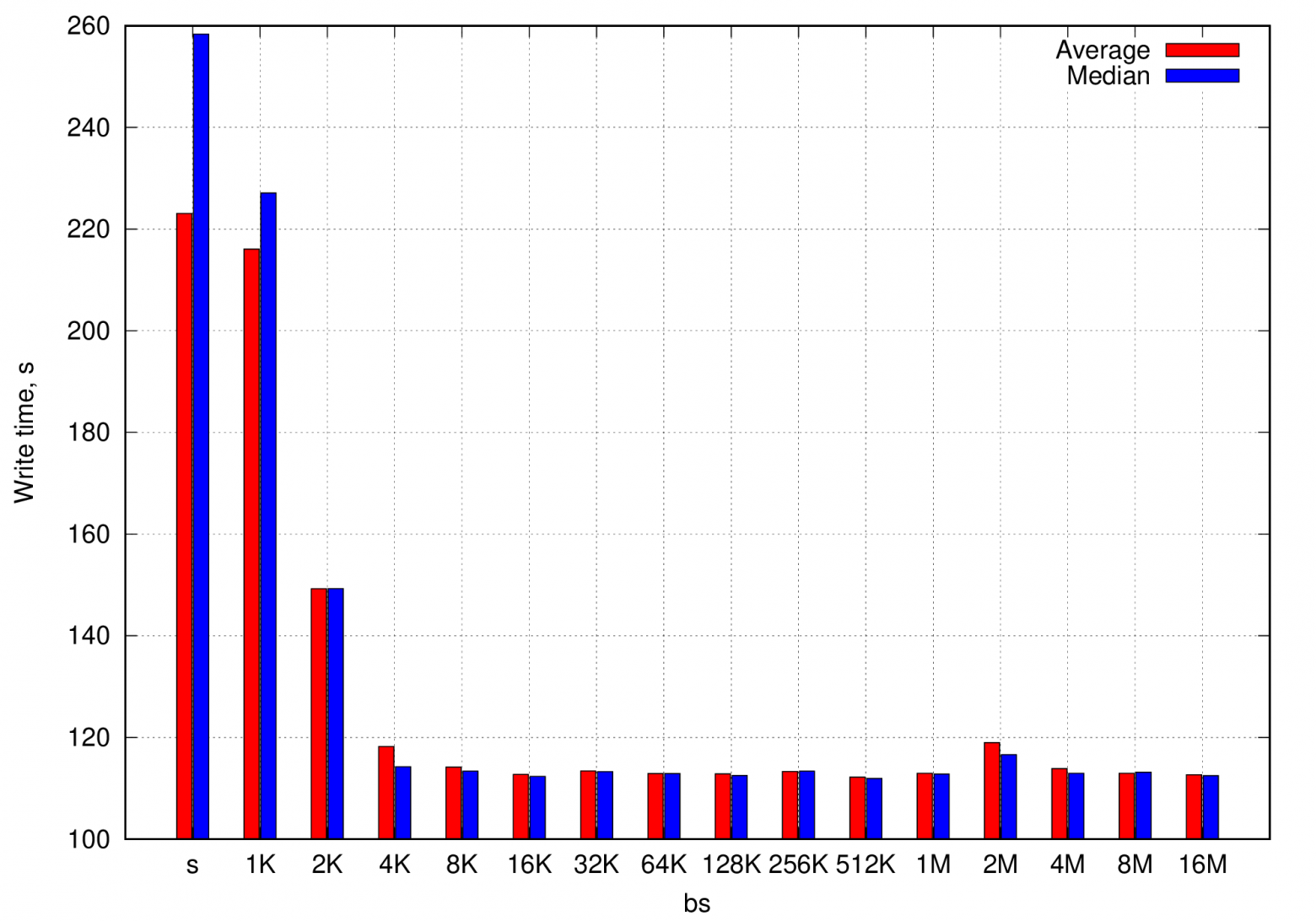
Время записи в файл на диске при отключенном кешировании
Ну вот, совсем другие числа. Отличаются практически в три раза!
Ну и нагляднее всего увидеть все три варианта на одном графике. Чтобы вы не запутались:
- Первая группа — это просто запись в файл.
- Вторая группа — это запись с отключенным кешированием.
- Третья — это непосредственная запись на диск.

Сравнение времени записи всех возможных вариантов при разной величине блока данных
Как можно увидеть, что самый быстрый способ записать данные на диск — это непосредственная запись с оптимальным размером блока.
❯ Вывод
Да, я прекрасно понимаю, что есть куча хороших утилит, для измерения скорости работы с жёстким диском. И уверен, что под Линукс есть много хорошего ПО. При этом — они более качественно, а главное более адаптивно к ядру и железу — проведут тестирования оборудования.
Однако, все эти утилиты нужно искать, собирать, проверять тестировать. А когда хочется здесь и сейчас, утилита dd вполне может показать в общих чертах относительные параметры, с которыми производилась запись. Но, оценивать придётся не те числа, с какой скоростью была произведена запись, а время выполнения команды, вместе с командой sync и помнить, что sync синхронизирует не только ваши данные, а вообще все буфера ядра. В общем и целом, неизвестных в этом вопросе пока может быть даже больше, чем известных.
Отвечая на главный вопрос коллеги: можно ли измерить скорость чтения-записи, работая с файлом?
Отвечаю: скорее нет, чем да. Слишком большая погрешность кеширования. В целом — это не самый оптимальный способ измерения скорости работы с диском. Поэтому, если точность параметров не нужна и допустимо измерение в попугаях (такое часто бывает), этим способом можно пользоваться.
❯ Полезные ссылки
- Репозиторий проекта к этой статье, если вы вдруг захотите повторить эти опыты.
- Если вы захотите писать свой тестер жёстких дисков, лучше использовать этот код. Это лучше, чем писать кривые непереносимые обёртки над dd.
- Linux and Unix Test Disk I/O Performance With dd Command — Весьма неплохая статья на английском, где подробно расписано, почему всё так получается и как оно работает. По сути, то что я тут рассказал, только в более сжатом виде.
Если вам интересна металлообработка, всякие DIY штуки, погроммирование и linux, то вы можете следить за мной ещё в телеграмме.

