Сжатие изображений с потерями
Идея, лежащая в основе всех алгоритмов сжатия с потерями, довольно проста: на первом этапе удалить несущественную информацию, а на втором этапе к оставшимся данным применить наиболее подходящий алгоритм сжатия без потерь. Основные сложности заключаются в выделении этой несущественной информации. Подходы здесь существенно различаются в зависимости от типа сжимаемых данных. Для звука чаще всего удаляют частоты, которые человек просто не способен воспринять, уменьшают частоту дискретизации, а также некоторые алгоритмы удаляют тихие звуки, следующие сразу за громкими, для видеоданных кодируют только движущиеся объекты, а незначительные изменения на неподвижных объектах просто отбрасывают. Методы выделения несущественной информации на изображениях будут подробно рассмотрены далее.Прежде чем говорить об алгоритмах сжатиях с потерями, необходимо договориться о том, что считать приемлемыми потерями. Понятно, что главным критерием остаётся визуальная оценка изображения, но также изменения в сжатом изображении могут быть оценены количественно. Самый простой способ оценки — это вычисление непосредственной разности сжатого и исходного изображений. Договоримся, что под  мы будем понимать пиксел, находящийся на пересечении i-ой строки и j-ого столбца исходного изображения, а под
мы будем понимать пиксел, находящийся на пересечении i-ой строки и j-ого столбца исходного изображения, а под  — соответствующий пиксел сжатого изображения. Тогда для любого пиксела можно легко определить ошибку кодирования
— соответствующий пиксел сжатого изображения. Тогда для любого пиксела можно легко определить ошибку кодирования  , а для всего изображения, состоящего из N строк и M столбцов, можно вычислить суммарную ошибку
, а для всего изображения, состоящего из N строк и M столбцов, можно вычислить суммарную ошибку  . Очевидно, что, чем больше суммарная ошибка, тем сильнее искажения на сжатом изображении. Тем не менее, эту величину крайне редко используют на практике, т.к. она никак не учитывает размеры изображения. Гораздо шире применяется оценка с использованием среднеквадратичного отклонения
. Очевидно, что, чем больше суммарная ошибка, тем сильнее искажения на сжатом изображении. Тем не менее, эту величину крайне редко используют на практике, т.к. она никак не учитывает размеры изображения. Гораздо шире применяется оценка с использованием среднеквадратичного отклонения 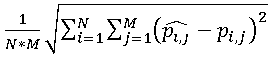 .Другой (хотя и близкий по сути) подход заключается в следующем: пиксели итогового изображения рассматриваются как сумма пикселей исходного изображения и шума. Критерием качества при таком подходе называют величину отношения сигнал-шум (SNR), вычисляемую следующим образом:
.Другой (хотя и близкий по сути) подход заключается в следующем: пиксели итогового изображения рассматриваются как сумма пикселей исходного изображения и шума. Критерием качества при таком подходе называют величину отношения сигнал-шум (SNR), вычисляемую следующим образом: 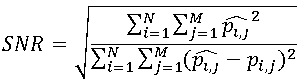 .Обе эти оценки являются т.н. объективными критериями верности воспроизведения, т.к. зависят исключительно от исходного и сжатого изображения. Тем не менее, эти критерии не всегда соответствуют субъективным оценкам. Если изображения предназначены для восприятия человеком, единственное, что можно утверждать: плохие показатели объективных критериев чаще всего соответствуют низким субъективным оценкам, в то же время хорошие показатели объективных критериев вовсе не гарантируют высоких субъективных оценок.С процессом квантования и дискретизации связано понятие визуальной избыточности. Значительная часть информации на изображении не может быть воспринята человеком: например, человек способен замечать незначительные перепады яркости, но гораздо менее чувствителен к цветности. Также, начиная с определённого момента, повышение точности дискретизации не влияет на визуальное восприятие изображения. Таким образом, некоторая часть информации может быть удалена без ухудшения визуального качества. Такую информацию называют визуально избыточной.Самым простым способом удаления визуальной избыточности является уменьшение точности дискретизации, но на практике этот способ можно применять только для изображений с простой структурой, т.к. искажения, возникающие на сложных изображениях, слишком заметны (см. Табл. 1)
.Обе эти оценки являются т.н. объективными критериями верности воспроизведения, т.к. зависят исключительно от исходного и сжатого изображения. Тем не менее, эти критерии не всегда соответствуют субъективным оценкам. Если изображения предназначены для восприятия человеком, единственное, что можно утверждать: плохие показатели объективных критериев чаще всего соответствуют низким субъективным оценкам, в то же время хорошие показатели объективных критериев вовсе не гарантируют высоких субъективных оценок.С процессом квантования и дискретизации связано понятие визуальной избыточности. Значительная часть информации на изображении не может быть воспринята человеком: например, человек способен замечать незначительные перепады яркости, но гораздо менее чувствителен к цветности. Также, начиная с определённого момента, повышение точности дискретизации не влияет на визуальное восприятие изображения. Таким образом, некоторая часть информации может быть удалена без ухудшения визуального качества. Такую информацию называют визуально избыточной.Самым простым способом удаления визуальной избыточности является уменьшение точности дискретизации, но на практике этот способ можно применять только для изображений с простой структурой, т.к. искажения, возникающие на сложных изображениях, слишком заметны (см. Табл. 1)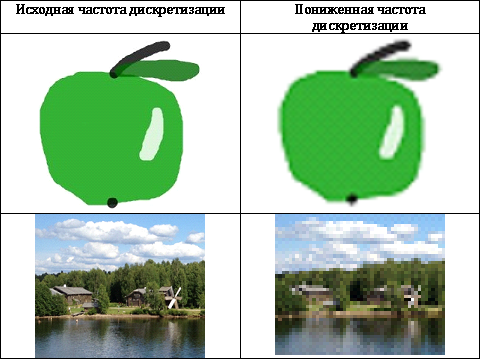 Для удаления избыточной информации чаще уменьшают точность квантования, но нельзя уменьшать её бездумно, т.к. это приводит к резкому ухудшению качества изображения.Рассмотрим уже известное нам изображение с. Предположим, что изображение представлено в цветовом пространстве RGB, результаты кодирования этого изображения с пониженной точностью квантования представлены в Табл. 2.
Для удаления избыточной информации чаще уменьшают точность квантования, но нельзя уменьшать её бездумно, т.к. это приводит к резкому ухудшению качества изображения.Рассмотрим уже известное нам изображение с. Предположим, что изображение представлено в цветовом пространстве RGB, результаты кодирования этого изображения с пониженной точностью квантования представлены в Табл. 2. В рассмотренном примере используется равномерное квантование как наиболее простой способ, но, если важно более точно сохранить цветопередачу, можно использовать один из следующих подходов: либо использовать равномерное квантование, но значением закодированной яркости выбирать не середину отрезка, а математическое ожидание яркости на этом отрезке, либо использовать неравномерное разбиение всего диапазона яркостей.Внимательно изучив полученные изображения, можно заметить, что на сжатых изображениях возникают отчётливые ложные контуры, которые значительно ухудшают визуальное восприятие. Существуют методы, основанные на переносе ошибки квантования в следующий пиксел, позволяющие значительно уменьшить или даже совсем удалить эти контуры, но они приводят к зашумлению изображения и появлению зернистости. Перечисленные недостатки сильно ограничивают прямое применение квантования для сжатия изображений.Большинство современных методов удаления визуально избыточной информации используют сведения об особенностях человеческого зрения. Всем известна различная чувствительность человеческого глаза к информации о цветности и яркости изображения. В Табл. 3 показано изображение в цветовом пространстве YIQ, закодированное с разной глубиной квантования цветоразностных сигналов IQ:
В рассмотренном примере используется равномерное квантование как наиболее простой способ, но, если важно более точно сохранить цветопередачу, можно использовать один из следующих подходов: либо использовать равномерное квантование, но значением закодированной яркости выбирать не середину отрезка, а математическое ожидание яркости на этом отрезке, либо использовать неравномерное разбиение всего диапазона яркостей.Внимательно изучив полученные изображения, можно заметить, что на сжатых изображениях возникают отчётливые ложные контуры, которые значительно ухудшают визуальное восприятие. Существуют методы, основанные на переносе ошибки квантования в следующий пиксел, позволяющие значительно уменьшить или даже совсем удалить эти контуры, но они приводят к зашумлению изображения и появлению зернистости. Перечисленные недостатки сильно ограничивают прямое применение квантования для сжатия изображений.Большинство современных методов удаления визуально избыточной информации используют сведения об особенностях человеческого зрения. Всем известна различная чувствительность человеческого глаза к информации о цветности и яркости изображения. В Табл. 3 показано изображение в цветовом пространстве YIQ, закодированное с разной глубиной квантования цветоразностных сигналов IQ: 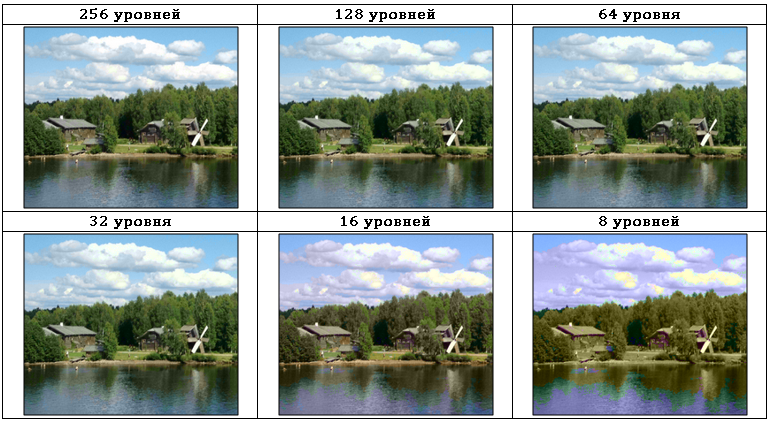 Как видно из Табл. 3, глубина квантования цветоразностных сигналов может быть понижена с 256 до 32 уровней с минимальными визуальными изменениями. В то же время потери в I и Q составляющих весьма существенны и показаны в Табл. 4
Как видно из Табл. 3, глубина квантования цветоразностных сигналов может быть понижена с 256 до 32 уровней с минимальными визуальными изменениями. В то же время потери в I и Q составляющих весьма существенны и показаны в Табл. 4 Несмотря на простоту описанных методов, в чистом виде они применяются редко, чаще всего они служат одним из шагов более эффективных алгоритмов.Мы уже рассматривали кодирование с предсказанием как весьма эффективный метод сжатия информации без потерь. Если совместить кодирование с предсказанием и сжатие посредством квантования, получится весьма простой и эффективный алгоритм сжатия изображения с потерями. В рассматриваемом методе будет квантоваться ошибка предсказания. Именно точность её квантования будет определять как степень сжатия, так и искажения, вносимые в сжатое изображение. Выбор оптимальных алгоритмов для предсказания и для квантования — довольно сложная задача. На практике широко используют следующие универсальные (обеспечивающие приемлемое качество на большинстве изображений) предсказатели:
Несмотря на простоту описанных методов, в чистом виде они применяются редко, чаще всего они служат одним из шагов более эффективных алгоритмов.Мы уже рассматривали кодирование с предсказанием как весьма эффективный метод сжатия информации без потерь. Если совместить кодирование с предсказанием и сжатие посредством квантования, получится весьма простой и эффективный алгоритм сжатия изображения с потерями. В рассматриваемом методе будет квантоваться ошибка предсказания. Именно точность её квантования будет определять как степень сжатия, так и искажения, вносимые в сжатое изображение. Выбор оптимальных алгоритмов для предсказания и для квантования — довольно сложная задача. На практике широко используют следующие универсальные (обеспечивающие приемлемое качество на большинстве изображений) предсказатели:  Мы же в свою очередь подробно рассмотрим самый простой и в тоже время весьма популярный способ кодирования с потерями — т.н. дельта-модуляцию. Этот алгоритм использует предсказание на основе одного предыдущего пиксела, т.е.
Мы же в свою очередь подробно рассмотрим самый простой и в тоже время весьма популярный способ кодирования с потерями — т.н. дельта-модуляцию. Этот алгоритм использует предсказание на основе одного предыдущего пиксела, т.е.  . Полученная после этапа предсказания ошибка квантуется следующим образом:
. Полученная после этапа предсказания ошибка квантуется следующим образом: 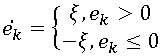 На первый взгляд это очень грубый способ квантования, но у него есть одно неоспоримое преимущество: результат предсказания может быть закодирован единственным битом. В Табл. 5 показаны изображения, закодированные с помощью дельта-модуляции (обход по строкам) с различными значениями ξ.
На первый взгляд это очень грубый способ квантования, но у него есть одно неоспоримое преимущество: результат предсказания может быть закодирован единственным битом. В Табл. 5 показаны изображения, закодированные с помощью дельта-модуляции (обход по строкам) с различными значениями ξ. Наиболее заметны два вида искажений — размытие контуров и некая зернистость изображения. Это наиболее типичные искажения, возникающие из-за перегрузки по крутизне и из-за т.н. шума гранулярности. Такие искажения характерны для всех вариантов кодирования с потерями с предсказанием, но именно на примере дельта-модуляции они видны лучше всего.Шум гранулярности возникает в основном на однотонных областях, когда значение ξ слишком велико для корректного отображения малых колебаний яркости (или их отсутствия). На Рис. 1 жёлтой линией отмечена исходная яркость, а синие столбцы показывают шум, возникающий при квантовании ошибки предсказания.
Наиболее заметны два вида искажений — размытие контуров и некая зернистость изображения. Это наиболее типичные искажения, возникающие из-за перегрузки по крутизне и из-за т.н. шума гранулярности. Такие искажения характерны для всех вариантов кодирования с потерями с предсказанием, но именно на примере дельта-модуляции они видны лучше всего.Шум гранулярности возникает в основном на однотонных областях, когда значение ξ слишком велико для корректного отображения малых колебаний яркости (или их отсутствия). На Рис. 1 жёлтой линией отмечена исходная яркость, а синие столбцы показывают шум, возникающий при квантовании ошибки предсказания. Ситуация перегрузки по крутизне принципиально отличается от ситуации с шумом гранулярности. В этом случае величина ξ оказывается слишком малой для передачи резкого перепада яркости. Из-за того, что яркость закодированного изображения не может расти также быстро, как яркость исходного изображения, возникает заметная размытость контуров. Ситуация с перегрузкой по крутизне поясняется на Рис. 2
Ситуация перегрузки по крутизне принципиально отличается от ситуации с шумом гранулярности. В этом случае величина ξ оказывается слишком малой для передачи резкого перепада яркости. Из-за того, что яркость закодированного изображения не может расти также быстро, как яркость исходного изображения, возникает заметная размытость контуров. Ситуация с перегрузкой по крутизне поясняется на Рис. 2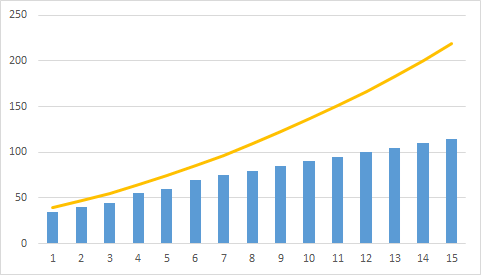 Легко заметить, что шум гранулярности уменьшается вместе с уменьшением ξ, но вместе с этим растут искажения из-за перегрузки по крутизне и наоборот. Это приводит к необходимости оптимизации величины ξ. Для большинства изображений рекомендуется выбирать ξ∈[5;7].Все рассмотренные ранее методы сжатия изображений работали непосредственно с пикселами исходного изображения. Такой подход называют пространственным кодированием. В текущем разделе мы рассмотрим принципиально иной подход, называемый трансформационным кодированием.Основная идея подхода похожа на рассмотренный ранее способ сжатия с использованием квантования, но квантоваться будут не значения яркостей пикселов, а специальным образом рассчитанные на их основе коэффициенты преобразования (трансформации). Схемы трансформационного сжатия и восстановления изображений приведены на Рис. 3, Рис. 4.
Легко заметить, что шум гранулярности уменьшается вместе с уменьшением ξ, но вместе с этим растут искажения из-за перегрузки по крутизне и наоборот. Это приводит к необходимости оптимизации величины ξ. Для большинства изображений рекомендуется выбирать ξ∈[5;7].Все рассмотренные ранее методы сжатия изображений работали непосредственно с пикселами исходного изображения. Такой подход называют пространственным кодированием. В текущем разделе мы рассмотрим принципиально иной подход, называемый трансформационным кодированием.Основная идея подхода похожа на рассмотренный ранее способ сжатия с использованием квантования, но квантоваться будут не значения яркостей пикселов, а специальным образом рассчитанные на их основе коэффициенты преобразования (трансформации). Схемы трансформационного сжатия и восстановления изображений приведены на Рис. 3, Рис. 4.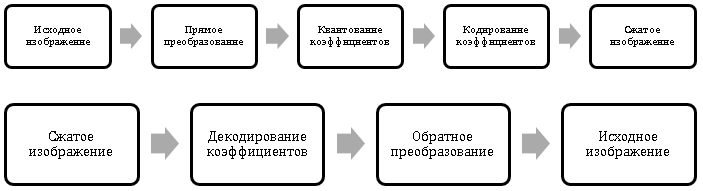 Непосредственно сжатие происходит не в момент кодирования, а в момент квантования коэффициентов, т.к. для большинства реальных изображений большая часть коэффициентов может быть грубо квантована.Для получения коэффициентов используют обратимые линейные преобразования: например преобразование Фурье, дискретное косинусное преобразование или преобразование Уолша-Адамара. Выбор конкретного преобразования зависит от допустимого уровня искажения и имеющихся ресурсов.В общем случае изображение размерами N*N пикселов рассматривается как дискретная функция от двух аргументов I (r, c), тогда прямое преобразование можно выразить в следующем виде:
Непосредственно сжатие происходит не в момент кодирования, а в момент квантования коэффициентов, т.к. для большинства реальных изображений большая часть коэффициентов может быть грубо квантована.Для получения коэффициентов используют обратимые линейные преобразования: например преобразование Фурье, дискретное косинусное преобразование или преобразование Уолша-Адамара. Выбор конкретного преобразования зависит от допустимого уровня искажения и имеющихся ресурсов.В общем случае изображение размерами N*N пикселов рассматривается как дискретная функция от двух аргументов I (r, c), тогда прямое преобразование можно выразить в следующем виде:  Набор
Набор  как раз и является искомым набором коэффициентов. На основе этого набора можно восстановить исходное изображение, воспользовавшись обратным преобразованием:
как раз и является искомым набором коэффициентов. На основе этого набора можно восстановить исходное изображение, воспользовавшись обратным преобразованием: 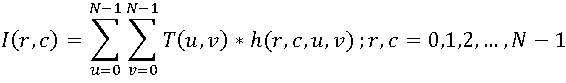 Функции
Функции  называют ядрами преобразования, при этом функция g — ядро прямого преобразования, а функция h — ядро обратного преобразования. Выбор ядра преобразования определяет как эффективность сжатия, так и вычислительные ресурсы, требуемые для выполнения преобразования.Широкораспространённые ядра преобразованияНаиболее часто при трансформационном кодировании используются ядра, перечисленные ниже.
называют ядрами преобразования, при этом функция g — ядро прямого преобразования, а функция h — ядро обратного преобразования. Выбор ядра преобразования определяет как эффективность сжатия, так и вычислительные ресурсы, требуемые для выполнения преобразования.Широкораспространённые ядра преобразованияНаиболее часто при трансформационном кодировании используются ядра, перечисленные ниже.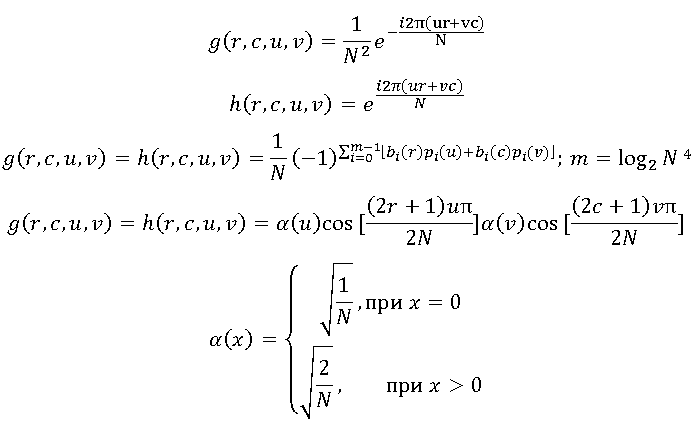 Использование первых двух ядер этих ядер приводит к упрощённому варианту дискретного преобразования Фурье. Вторая пара ядер соответствует довольно часто используемому преобразованию Уолша-Адамара. И, наконец, наиболее распространённым преобразованием является дискретное косинусное преобразование: Широкая распространённость дискретного косинусного преобразования обусловлена его хорошей способностью производить уплотнение энергии изображения. Строго говоря, есть более эффективные преобразования. Например, преобразование Кархунена-Лоэва имеет наилучшую эффективность в плане уплотнения энергии, но его сложность практически исключает возможность широкого практического применения.Сочетание эффективности уплотнения энергии и сравнительной простоты реализации сделало дискретное косинусное преобразование стандартом трансформационного кодирования.Графическое пояснение трансформационного кодирования
В контексте функционального анализа рассмотренные преобразования можно рассматривать как разложение по набору базисных функций. В то же время в контексте обработки изображений эти преобразования можно воспринимать как разложение по базисным изображениям. Чтобы пояснить эту идею, рассмотрим квадратное изображение I размером n*n пикселов. Ядра преобразований не зависят ни от коэффициентов преобразования, ни от значения пикселов исходного изображения, поэтому обратное преобразование можно записать в матричном виде:
Использование первых двух ядер этих ядер приводит к упрощённому варианту дискретного преобразования Фурье. Вторая пара ядер соответствует довольно часто используемому преобразованию Уолша-Адамара. И, наконец, наиболее распространённым преобразованием является дискретное косинусное преобразование: Широкая распространённость дискретного косинусного преобразования обусловлена его хорошей способностью производить уплотнение энергии изображения. Строго говоря, есть более эффективные преобразования. Например, преобразование Кархунена-Лоэва имеет наилучшую эффективность в плане уплотнения энергии, но его сложность практически исключает возможность широкого практического применения.Сочетание эффективности уплотнения энергии и сравнительной простоты реализации сделало дискретное косинусное преобразование стандартом трансформационного кодирования.Графическое пояснение трансформационного кодирования
В контексте функционального анализа рассмотренные преобразования можно рассматривать как разложение по набору базисных функций. В то же время в контексте обработки изображений эти преобразования можно воспринимать как разложение по базисным изображениям. Чтобы пояснить эту идею, рассмотрим квадратное изображение I размером n*n пикселов. Ядра преобразований не зависят ни от коэффициентов преобразования, ни от значения пикселов исходного изображения, поэтому обратное преобразование можно записать в матричном виде:  Если эти матрицы расположить в виде квадрата, а полученные значения представить в виде пикселов определённого цвета, можно получить графическое представление базисных функций, т.е. базисные изображения. Базисные изображения преобразования Уолша-Адамара и дискретного косинусного преобразования для n=4 приведены в Табл. 7.
Если эти матрицы расположить в виде квадрата, а полученные значения представить в виде пикселов определённого цвета, можно получить графическое представление базисных функций, т.е. базисные изображения. Базисные изображения преобразования Уолша-Адамара и дискретного косинусного преобразования для n=4 приведены в Табл. 7.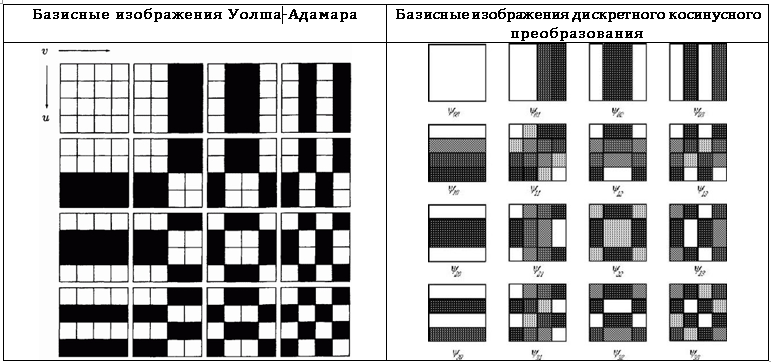 Особенности практической реализации трансформационного кодирования
Общая идея трансформационного кодирования была описана ранее, но, тем не менее, практическая реализация трансформационного кодирования требует прояснения нескольких вопросов.Перед кодированием изображение разбивается на квадратные блоки, а затем каждый блок подвергается преобразованию. От выбора размера блока зависит как вычислительная сложность, так и итоговая эффективность сжатия. При увеличении размера блока растёт как эффективность сжатия, так и вычислительная сложность, поэтому на практике чаще всего используются блоки размером 8×8 или 16×16 пикселов.После того, как для каждого блока вычислены коэффициенты преобразования, необходимо их квантовать и закодировать. Наиболее распространёнными подходами являются зональное и пороговое кодирование.При зональном подходе предполагается, что наиболее информативные коэффициенты будут находиться вблизи нулевых индексов полученного массива. Это значит, что соответствующие коэффициенты должны быть наиболее точно квантованы. Другие коэффициенты можно квантовать значительно грубее или просто отбросить. Проще всего понять идею зонального кодирования можно, посмотрев на соответствующую маску (Табл. 8):
Особенности практической реализации трансформационного кодирования
Общая идея трансформационного кодирования была описана ранее, но, тем не менее, практическая реализация трансформационного кодирования требует прояснения нескольких вопросов.Перед кодированием изображение разбивается на квадратные блоки, а затем каждый блок подвергается преобразованию. От выбора размера блока зависит как вычислительная сложность, так и итоговая эффективность сжатия. При увеличении размера блока растёт как эффективность сжатия, так и вычислительная сложность, поэтому на практике чаще всего используются блоки размером 8×8 или 16×16 пикселов.После того, как для каждого блока вычислены коэффициенты преобразования, необходимо их квантовать и закодировать. Наиболее распространёнными подходами являются зональное и пороговое кодирование.При зональном подходе предполагается, что наиболее информативные коэффициенты будут находиться вблизи нулевых индексов полученного массива. Это значит, что соответствующие коэффициенты должны быть наиболее точно квантованы. Другие коэффициенты можно квантовать значительно грубее или просто отбросить. Проще всего понять идею зонального кодирования можно, посмотрев на соответствующую маску (Табл. 8):  Число в ячейке показывает количество бит, отводимых для кодирования соответствующего коэффициента.В отличие от зонального кодирования, где для любого блока используется одна и та же маска, пороговое кодирование подразумевает использование уникальной маски для каждого блока. Пороговая маска для блока строится, исходя из следующих соображений: наиболее важными для восстановления исходного изображения являются коэффициенты с максимальным значением, поэтому, сохранив эти коэффициенты и обнулив все остальные, можно обеспечить как высокую степень сжатия, так и приемлемое качество восстановленного изображения. В Табл. 9 показан примерный вид маски для конкретного блока.
Число в ячейке показывает количество бит, отводимых для кодирования соответствующего коэффициента.В отличие от зонального кодирования, где для любого блока используется одна и та же маска, пороговое кодирование подразумевает использование уникальной маски для каждого блока. Пороговая маска для блока строится, исходя из следующих соображений: наиболее важными для восстановления исходного изображения являются коэффициенты с максимальным значением, поэтому, сохранив эти коэффициенты и обнулив все остальные, можно обеспечить как высокую степень сжатия, так и приемлемое качество восстановленного изображения. В Табл. 9 показан примерный вид маски для конкретного блока. Единицы соответствуют коэффициентам, которые будут сохранены и квантованы, а нули соответствуют выброшенным коэффициентам После применения маски полученная матрица коэффициентов должна быть преобразована в одномерный массив, причём для преобразования необходимо использовать обход змейкой. Тогда в полученном одномерном массиве все значимые коэффициенты будут сосредоточены в первой половине, а вторая половина будет практически полностью состоять из нулей. Как было показано в ранее, подобные последовательности весьма эффективно сжимаются алгоритмами кодирования длин серий.Вейвлеты — математические функции, предназначенные для анализа частотных компонент данных. В задачах сжатия информации вейвлеты используются сравнительно недавно, тем не менее исследователям удалось достичь впечатляющих результатов.В отличие от рассмотренных выше преобразований, вейвлеты не требуют предварительного разбиения исходного изображения на блоки, а могут применяться к изображению в целом. В данном разделе вейвлет сжатие будет пояснено на примере довольно простого вейвлета Хаара.Для начала рассмотрим преобразование Хаара для одномерного сигнала. Пусть есть набор S из n значений, при преобразовании Хаара каждой паре элементов ставится в соответствие два числа: полусумма элементов и их полуразность. Важно отметить, что это преобразование обратимо: т.е. из пары чисел можно легко восстановить исходную пару. На Рис. 5 показан пример одномерного преобразования Хаара:
Единицы соответствуют коэффициентам, которые будут сохранены и квантованы, а нули соответствуют выброшенным коэффициентам После применения маски полученная матрица коэффициентов должна быть преобразована в одномерный массив, причём для преобразования необходимо использовать обход змейкой. Тогда в полученном одномерном массиве все значимые коэффициенты будут сосредоточены в первой половине, а вторая половина будет практически полностью состоять из нулей. Как было показано в ранее, подобные последовательности весьма эффективно сжимаются алгоритмами кодирования длин серий.Вейвлеты — математические функции, предназначенные для анализа частотных компонент данных. В задачах сжатия информации вейвлеты используются сравнительно недавно, тем не менее исследователям удалось достичь впечатляющих результатов.В отличие от рассмотренных выше преобразований, вейвлеты не требуют предварительного разбиения исходного изображения на блоки, а могут применяться к изображению в целом. В данном разделе вейвлет сжатие будет пояснено на примере довольно простого вейвлета Хаара.Для начала рассмотрим преобразование Хаара для одномерного сигнала. Пусть есть набор S из n значений, при преобразовании Хаара каждой паре элементов ставится в соответствие два числа: полусумма элементов и их полуразность. Важно отметить, что это преобразование обратимо: т.е. из пары чисел можно легко восстановить исходную пару. На Рис. 5 показан пример одномерного преобразования Хаара:  Видно, что сигнал распадается на две составляющее: приближенное значение исходного (с уменьшенным в два раза разрешением) и уточняющую информацию.Двумерное преобразование Хаара — простая композиция одномерных преобразований. Если исходные данные представлены в виде матрицы, то сначала выполняется преобразование для каждой строки, а затем для полученных матриц выполняется преобразование для каждого столбца. На Рис. 6 показан пример двумерного преобразования Хаара.
Видно, что сигнал распадается на две составляющее: приближенное значение исходного (с уменьшенным в два раза разрешением) и уточняющую информацию.Двумерное преобразование Хаара — простая композиция одномерных преобразований. Если исходные данные представлены в виде матрицы, то сначала выполняется преобразование для каждой строки, а затем для полученных матриц выполняется преобразование для каждого столбца. На Рис. 6 показан пример двумерного преобразования Хаара. Цвет пропорционален значению функции в точке (чем больше значение, тем темнее). В результате преобразования получается четыре матрицы: одна содержит аппроксимацию исходного изображения (с уменьшенной частотой дискретизации), а три остальных содержат уточняющую информацию.Сжатие достигается путём удаления некоторых коэффициентов из уточняющих матриц. На Рис. 7 показан процесс восстановления и само восстановленное изображение после удаления из уточняющих матриц малых по модулю коэффициентов:
Цвет пропорционален значению функции в точке (чем больше значение, тем темнее). В результате преобразования получается четыре матрицы: одна содержит аппроксимацию исходного изображения (с уменьшенной частотой дискретизации), а три остальных содержат уточняющую информацию.Сжатие достигается путём удаления некоторых коэффициентов из уточняющих матриц. На Рис. 7 показан процесс восстановления и само восстановленное изображение после удаления из уточняющих матриц малых по модулю коэффициентов:  Очевидно, что представление изображения с помощью вейвлетов позволяет добиваться эффективного сжатия, сохраняя при этом визуальное качество изображения. Несмотря на простоту, преобразование Хаара сравнительно редко используется на практике, т.к. существуют другие вейвлеты, обладающие рядом преимуществ (например, вейвлеты Добеши или биортогональные вейвлеты).P.S. Другие главы монографии выложены в свободном доступе на gorkoff.ru
Очевидно, что представление изображения с помощью вейвлетов позволяет добиваться эффективного сжатия, сохраняя при этом визуальное качество изображения. Несмотря на простоту, преобразование Хаара сравнительно редко используется на практике, т.к. существуют другие вейвлеты, обладающие рядом преимуществ (например, вейвлеты Добеши или биортогональные вейвлеты).P.S. Другие главы монографии выложены в свободном доступе на gorkoff.ru
