Чтение старых статей Хабра с картинками
 Некоторое время назад решил я освежить знания и почитать что-нибудь о графах. «Ну конечно же, на Хабре должны быть хорошие статьи!» — подумал я, и оказался прав. Статьи есть и их много. Но выглядит они преимущественно вот так: раз, два, три. Откройте и догадайтесь с одной попытки почему что-то понять из этих статей совершенно невозможно, хотя написано вполне понятным языком. Нет картинок! Ну, а как изучать графы без картинок? Никак.Новичок на Хабре недоуменно спросит: «Как так — нет картинок? Есть же habrastorage.org!». Да, есть. Но был он не всегда, а автоматически на него перезаливаться картинки и вовсе стали только в июле 2013-го. А до этого картинки хостились где-попало — на всяких радикалах, имейджхаках, даже на дропбокс, бывало, люди наивно пытались что-то выкладывать. В итоге мы имеем на Хабре кучу статей 2006–2013 года с отсутствующими картинками.
Некоторое время назад решил я освежить знания и почитать что-нибудь о графах. «Ну конечно же, на Хабре должны быть хорошие статьи!» — подумал я, и оказался прав. Статьи есть и их много. Но выглядит они преимущественно вот так: раз, два, три. Откройте и догадайтесь с одной попытки почему что-то понять из этих статей совершенно невозможно, хотя написано вполне понятным языком. Нет картинок! Ну, а как изучать графы без картинок? Никак.Новичок на Хабре недоуменно спросит: «Как так — нет картинок? Есть же habrastorage.org!». Да, есть. Но был он не всегда, а автоматически на него перезаливаться картинки и вовсе стали только в июле 2013-го. А до этого картинки хостились где-попало — на всяких радикалах, имейджхаках, даже на дропбокс, бывало, люди наивно пытались что-то выкладывать. В итоге мы имеем на Хабре кучу статей 2006–2013 года с отсутствующими картинками.
Давайте это пофиксим!
ПланПеред нами на первом этапе стоят следующие задачи: Скачать все статьи от возникновения Хабра и до вышеупомянутого поста 188436, примерно обозначающую начало принудительной перезаливки картинок на habrastorage.org Найти в тексте статей ссылки на все картинки, размещённые не на Хабре, Гиктаймсе, Мегамозге или Хабрасторадже Проверить доступность этих картинок (GET делать не обязательно, достаточно запроса HEAD с проверкой кода возврата и типа контента) Экспорт списка недоступных картинок в файл Реализация В общем, только ленивый ещё не парсил Хабр, ну, а мы же не ленивые. Тем более, что там на Python + requests писать: Заливаем код на виртуалку в облаке, запускаем, возвращаемся через 2 дня (можно было бы, конечно, парсить в несколько потоков —, но мне помнится, где-то в FAQ Хабр просил не дёргать его ботами чаще чем 2 раза в секунду).
Результаты
Всего в статьях «До Пришествия Хабрастораджа» было найдено 157601 картинок, размещённых на «левых» хостингах изображений. Из них 92549 ссылок всё ещё валидны, а 65052 ссылок — уже нет.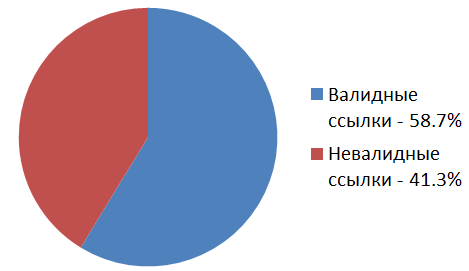
Ну ок, у нас есть ссылки на 65052 недоступных картинок в статьях на Хабре. Что с этим делать? Достать их из кеша archive.org, конечно же! Он для того и придумывался!
Проверить наличие картинки в веб-архиве можно нехитрым запросом:
http://archive.org/wayback/available? url=%image_url% Например, отсутствующая в статье habrahabr.ru/post/63982/ ссылка на картинку img513.imageshack.us/img513/3580/pic1e.jpg вполне доступна по ссылке http://web.archive.org/web/20131103061340/http://img513.imageshack.us/img513/3580/pic1e.jpg
Есть, правда, одна беда. Иногда интернет-архив утверждает, что у него имеется ссылка на закешированную картинку, а на самом деле её нет. Врёт, в общем. Т.е. нам придётся проверять и каждую ссылку на закешированную картинку. Ну, ничего, проверим.
Заливаем, запускаем, ждём полдня.
Результаты
В веб-архиве оказалось доступно 13863 картинки из тех, которые больше недоступны по оригинальным ссылкам в статьях на Хабре.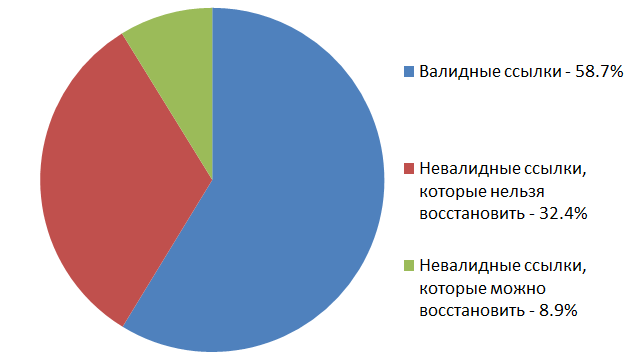
Весь этот эксперимент дал нам неплохую «среднюю температуру по больнице»: мы теперь знаем, что у залитой на случайный хостинг картинки есть шанс около 58% уцелеть в течение следующих 2–9 лет. Ещё мы знаем, что archive.org штука полезная и иногда помогает, но шансы восстановить с его помощью битую ссылку на картинку на Хабре — 21.3%.
Выводы к первой части статьи Итак, теперь у нас есть массив с ещё валидными ссылками на картинки и второй массив, с битыми ссылками и соответствующими им ссылками на доступные картинки в веб-архиве. В этом месте можно было бы попросить администрацию Хабра взять эти данные и написать 4 строки кода, чтобы перезалить это всё на habrastorage.org и обновить ссылки в имеющихся статьях, но я не знаю, будут ли они этим заниматься. А читать-то статьи в нормальном виде хочется! И поэтому мы пойдём своим путём. Можно, конечно, сказать «Читайте статьи прямо с веб-архива!», но это как-то не особо поучительно и к чему бы был весь этот сбор данных.Вторым порывом может стать желание написать расширение для Хрома, подменяющие плохие ссылки на хорошие, но делать этого мне не хочется по целому ряду причин:
Это не очень интересно, на Хабре уже была сотня статей о написании расширений к Хрому Расширения теперь вроде бы обязательно размещать в маркете Для Firefox придётся писать отдельное расширение, а с IE вообще непонятно что делать (BHO писать? Бр-р-р-р!). Ну и плюс всякие там Оперы, Вивальди, Сафари, Яндекс.браузеры и остальной зоопарк. Совершенно непонятно, как это поможет в чтении с мобильного телефона или планшета Поэтому мы пойдём другим путём и напишем кое-что, решающее все вышеуказанные проблемы. Что именно? А об этом вы узнаете из следующей статьи.
P.S. Логическое разделение на две статьи добавлено для удобства чтения, поскольку использованный во второй статье метод не имеет никакого отношения к картинкам на Хабре, ну и наоборот.
