Сжатие без потерь — главная концепция в нашей жизни

Бывало так, что из долгой поездки вы помните только несколько моментов? А все отпуска за много лет сливаются в единое целое? А из школьного класса помните фамилии только нескольких человек? Это вовсе не потеря памяти, как может показаться. Наоборот, это признак крайне развитого интеллекта, который научился эффективно сжимать данные.
На самом деле воспоминания из памяти можно вытянуть (разархивировать) через регрессивный гипноз. Просто в данный момент они не нужны, поэтому хранятся в сжатом виде на ленточных накопителях в дальних уголках памяти.
Все мы знаем и используем компьютерные архиваторы: ZIP, RAR, Brotli и т. д. Но мало кто видит в них модель интеллекта. Это даже как-то странно на первый взгляд. Хотя если подумать, то идеальное сжатие — это синоним понимания.
Если взглянуть на теорию сжатия информации, а также на растущую сложность алгоритмов, которые переходят на нейросети, то на наших глазах как будто появилось и развивается некое живое существо. Можно пофантазировать, что когда-нибудь его сложность станет настолько выше нашего понимания, что любую информацию в мире оно сможет сжать до цифры »42».

Если без шуток, все алгоритмы сжатия делятся на две большие категории: сжатие с потерями и без потерь. Первая категория часто используется для сжатия фото, видео и звука, то есть аналоговых нейронных сигналов (зрение, слух), вторая — для цифровых. Сжатие без потерь используется в архивации данных и резервном копировании. Во многом полагается на поиск дубликатов в массиве цифровой информации.
Первым в мире архиватором можно считать код Морзе (1838), который для кодирования более частых букв в английском языке (e, t) использует более короткие коды.
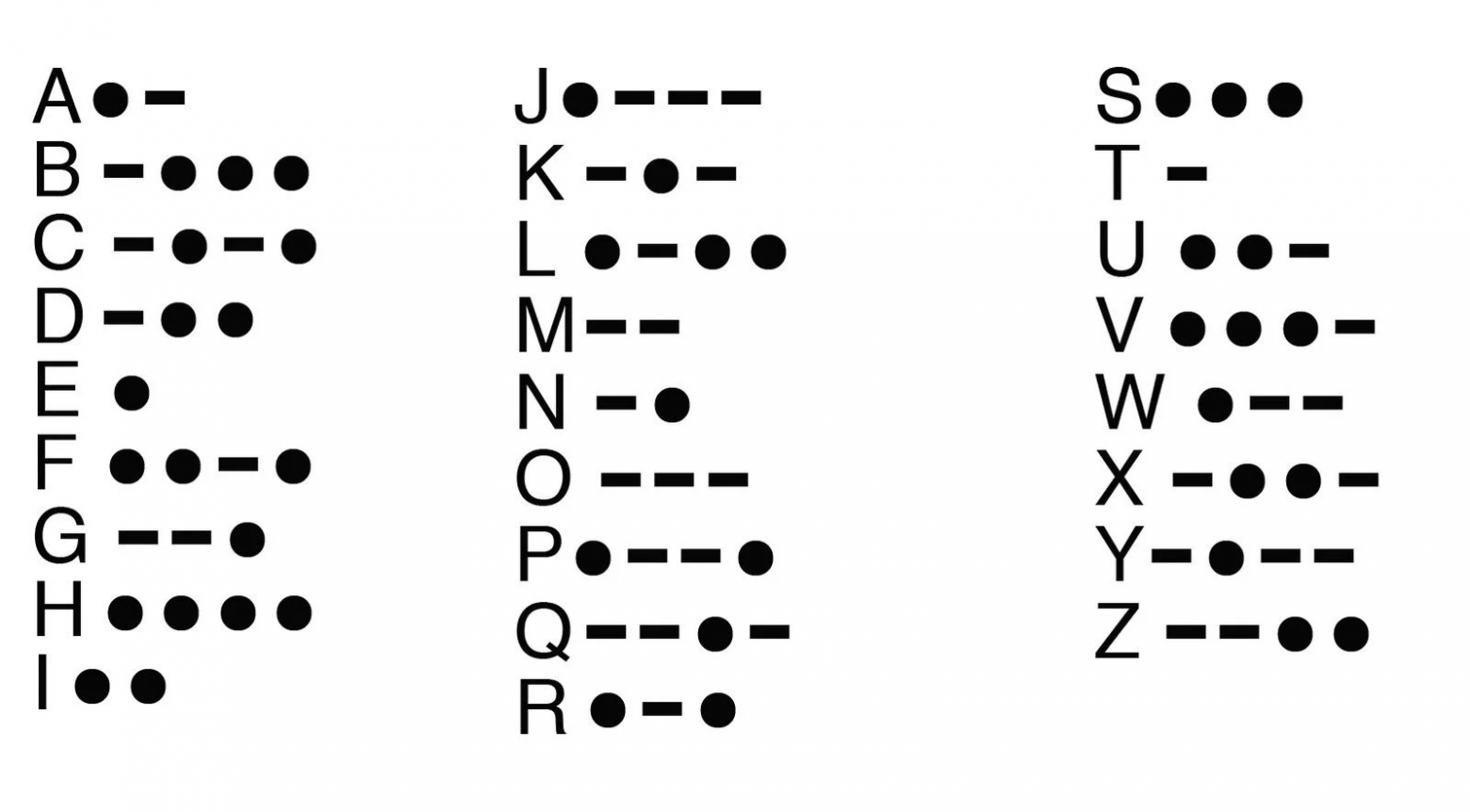
История компьютерных алгоритмов сжатия без потерь берёт начало в 1949 году, когда Клод Шеннон и Роберт Фано изобрели алгоритм Шеннона — Фано, в котором коды символов в блоке основаны на вероятности появления символа. Вероятность появления символа обратно пропорциональна длине кода, что приводит к более короткому способу представления данных.
Через два года пришла очередь студента Дэвида Хаффмана, который учился в группе у Роберта Фано в MIT и подготовил курсовую работу, где описал самый эффективный на то время метод бинарного кодирования, ныне известный как код Хаффмана (изображён на КДПВ), похожий на код его преподавателя.
▍ Эпоха LZ77
В конце 1970-х компьютеры стали более популярными и появился первый софт для сжатия резервных копий. Сначала он использовал коды Хаффмана, а в 1977 году был изобретён революционный алгоритм Лемпеля — Зива — Уэлча (LZ77) — первый алгоритм с использованием словарей. В частности, там изначально использовался динамический словарь (также известен как скользящее окно), который идеально подходит для поиска повторяющихся последовательностей битов.
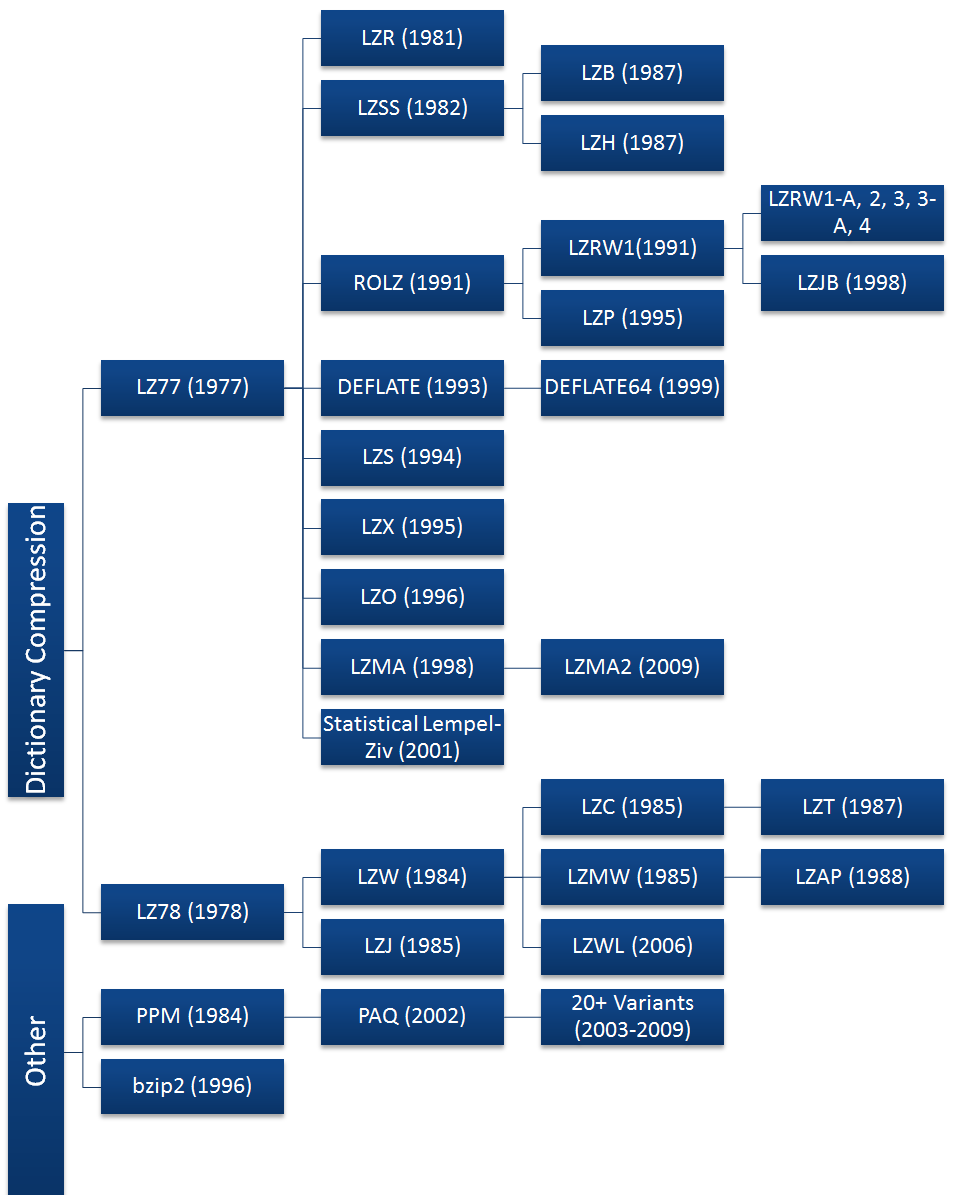
Иерархия алгоритмов сжатия без потерь общего назначения с 1977 по 2011 годы
LZ77 определил разработку архиваторов на десятилетия, с дальнейшими техническими усовершенствованиями и множеством ответвлений, изображённых на диаграмме вверху. Использование LZ78 (со статическим словарём) было затруднено из-за появления в 1984 году производного алгоритма LZW, который удалось запатентовать с требованием лицензионных отчислений. После этого владелец патента начал подавать в суд на других разработчиков и даже конечных пользователей за использование формата GIF без лицензии.
С распространением интернета в 80–90-е годы производные алгоритмы LZ77 легли в основу новых форматов сжатия файлов: ZIP (1989), GIF (1987), PNG (1994), RAR (комбинация PPM и LZSS, 1993) и др. Первым массовым архиватором стал опенсорсный ARC в 1985 году и PKARC (ZIP) в 1989 году. Затем производные LZ77 начали использоваться буквально везде, включая HTTP и SSL.
▍ Новые алгоритмы. Нейросети. Сжатие на GPU
С одной стороны, большинство современных архиваторов используют базовые техники, но внедряются и принципиально новые подходы. В начале 2000-х получил популярность алгоритм PAQ, основанный на смешивании контекста (context mixing, CM, о нём ниже), а в 2019 году известный программист Фабрис Беллар представил уникальный архиватор NNCP, спроектированный на нейросетевой архитектуре трансформер (в 2021 году вышла вторая версия). Основные принципы описаны в научных статьях 2019 и 2021 гг. Последняя версия 3.1 — и она уже вышла на первое место в мире по коэффициенту сжатия стандартного массива текстов Large Text Compression Benchmark (109 байт англоязычной Википедии). С этого началось использование нейросетей в сжатии данных.
Текущие лидеры Large Text Compression Benchmark (всего 122 участника):
В пятёрку лидеров вошли nncp, cmix, tensorflow-compress, cmix-hp и starlit. Большинство участников топ-20 используют алгоритм смешивания контекста (CM), хотя у отдельных разработок вроде NNCP уникальные алгоритмы сжатия. Видны множественные эксперименты с нейросетями. Описание всех программ и алгоритмов см. здесь.
CMIX и многие другие архиваторы 2002–2019 годов используют смешивание контекста с предварительной обработкой по словарю — в своё время революционную технику, когда несколько статистических моделей интеллектуально комбинируются таким образом, что прогнозируют следующий символ лучше, чем любая из моделей сама по себе.
PAQ (2002) — один из наиболее перспективных алгоритмов CM, с момента его создания было создано десятки вариантов, причём некоторые достигли рекордных коэффициентов сжатия.
Архиватор CMIX считался мировым лидером по сжатию до появления NNCP. Он основан на коде paq8hp12any и paq8l (современные модели из семейства PAQ).
Из других новинок последних лет можно упомянуть алгоритм Brotli-G, основанный на обычном Brotli (классический LZ77 + код Хаффмана), но оптимизированный для GPU. То есть получается сжатие с аппаратным ускорением. Учитывая потенциальное использование нейросетей, такое аппаратное ускорение весьма уместно. По эффективности Brotli в числе аутсайдеров, но это первый в мире архиватор на GPU. Да и он изначально создавался для шифрования трафика в интернете и был ориентирован в первую очередь на скорость в реальном времени, а не на сжатие. Поддержка есть во всех современных браузерах.
▍ Сжатие информации как эквивалент интеллекта
Понятно, почему Фабрис Беллар решил использовать нейросети именно для сжатия данных. Это очень логично в свете того, что некоторые учёные соотносят сжатие данных с общим интеллектом.
Дело в том, что эффективное сжатие требует понимания данных. Чем лучше понимание, тем больше паттернов, куда эти данные укладываются. И тем эффективнее сжатие. Например, в миллиардах цифр на экране мы вдруг увидели координаты точек окружности, и тогда можем сжать терабайты информации в три числа (координаты центра и радиус). Почти как в анекдоте про школьника с архиватором, который всё архивирует в 1 байт, только разархивировать не может.
Таким образом, сжатие информации требует её понимания. Отсюда аналогия с интеллектом, который тоже находит смысл в окружающих явлениях. В миллиардах хаотических событий окружающего мира мы видим физические объекты и даже абстрактные понятия, и «сжимаем» их до одного слова, схемы или образа.
В качестве примера можно вспомнить диаграммы Фейнмана, которые «сжимают» описание сложных физических процессов до одной простой картинки.
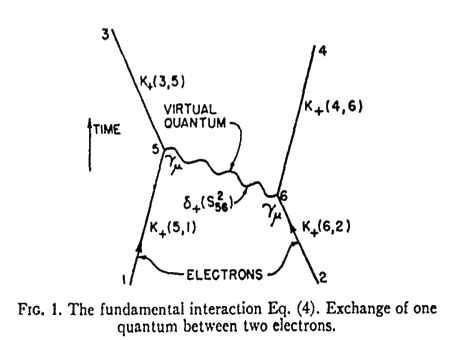
Первая опубликованная диаграмма Фейнмана под названием «Фундаментальное взаимодействие» показывает классический случай, когда два электрона обмениваются виртуальным фотоном, источник
Это и есть работа интеллекта. Ричард Фейнман получил Нобелевскую премию по сути за самое эффективное сжатие информации.
Грубо говоря, один человек умеет сжимать и понимать только простые объекты (минимальное сжатие, средний IQ), а другой более сложные (максимальное сжатие информации, высокий IQ), которые не поддаются пониманию первого архиватора. Чем выше коэффициент сжатия информации, тем качественнее и эффективнее модель данных для окружающего мира.
Кстати, на этом тезисе основан компрессионизм — теория мышления на основе сжатия данных. По сути, если рассматривать человеческий разум и интеллект в таком виде, то сжатие данных — это главная концепция в нашей жизни.
Авторы приводят примеры сжатия данных, которые основаны на понимании определённых высокоуровневых концепций. Например, бесконечная последовательность чисел
4, 6, 8, 12, 14, 18, 20, 24...
… сжимается до одной фразы «нечётные простые числа +1»
Здесь также понятна связь между сжатием данных и прогнозированием будущего. Это как в жизни: если у вас более качественная модель сжатия (понимания) мира, то вы лучше предсказываете поступки других людей. Теорема о кодировании информации Леонида Левина (1974) демонстрирует, что с высокой вероятностью самая компактная модель и оказывается самой верной (бритва Оккама).
В научной работе 2009 года Шмидхубер предложил рассматривать сжатие данных как простой принцип, который объясняет существенные аспекты субъективной красоты, новизны, удивления, интересности, внимания, любопытства, творчества, искусства, науки, музыки и шуток. Он утверждает, что данные становятся временно интересными, как только наблюдатель учится предсказывать (т. е. сжимать) их лучшим образом, делая их субъективно более простыми и «красивыми».
С этой точки зрения любопытство можно рассматривать как желание создать и обнаружить закономерности, которые позволяют достичь прогресса в сжатии, при этом уровень любопытства связан с требуемыми усилиями.
Аналогичным образом теория Магуайра о субъективной вероятности (2013), а также теория простоты Дессаллеса (2011) рассматривают сжатие данных как ключевую объяснительную конструкцию в феномене удивления. Когда люди сталкиваются со стимулом, который ожидается как случайный, но оказывается сжимаемым, это вызывает реакцию удивления (или смеха).
Согласно Магуайру, люди часто полагаются на сжатие данных, а не на теорию вероятности для принятия решений во многих сценариях реального мира. Если подумать, то сжатие и есть понимание. Главная концепция в нашей жизни.
 В свете этой концепции интересно следить за конкурсами на лучшее сжатие текстов из Википедии на натуральном языке, такими как Large Text Compression (109 первых байт из enwiki-20060303-pages-articles.xml) и Hutter Prize (108 первых байт, приз 500 тыс. евро, на фото справа — последний победитель — Артемий Маргаритов из Эдинбурга). По мнению учёных-компрессионистов, идеальное сжатие текста эквивалентно тесту Тьюринга для машин.
В свете этой концепции интересно следить за конкурсами на лучшее сжатие текстов из Википедии на натуральном языке, такими как Large Text Compression (109 первых байт из enwiki-20060303-pages-articles.xml) и Hutter Prize (108 первых байт, приз 500 тыс. евро, на фото справа — последний победитель — Артемий Маргаритов из Эдинбурга). По мнению учёных-компрессионистов, идеальное сжатие текста эквивалентно тесту Тьюринга для машин.
Возможно, сильный ИИ сможет сформироваться где-то в симбиозе чат-ботов (речь) и архиваторов (понимание смысла).
С одной стороны, сжатие рассматривается как ключ к идеальному математическому определению интеллекта. С другой стороны, создать идеальную модель сжатия настолько же трудно, как и познать принципы мышления. Или даже невозможно в силу потенциального противоречия теореме Гёделя, из которой можно сделать выводы о невычислимости функции сознания, а также о существовании принципиально непознаваемых явлений (предел Хайтина).
Играй в нашу новую игру прямо в Telegram!

