Суп с котом: забавная задачка с LeetCode
Есть на LeetCode задачка. Medium уровня, на динамическое программирование, ничего особенного. Однако, если присмотреться внимательнее, она окажется интереснее, чем на первый взгляд. Кроме того, можно получить более быстрое решение, чем «официальное».
Условие (в адаптации для постсоветского читателя)
Недалеко от вокзала, есть маленькая столовая. Каждое утро в ней варят две одинаковых кастрюли супа: один с говядиной  , другой, собственно, с котом
, другой, собственно, с котом  . Порция супа составляет
. Порция супа составляет  миллилитров.
миллилитров.
Клиенты каждой категории приходят в случайном порядке, каждая категория с вероятностью  %.
%.
Если какого-то вида супа для текущего клиента не хватило — ему подают сколько есть, не доливая ни того, ни другого. При этом заказ считается исполненным.
При заданном объёме кастрюли  мл требуется определить, какова вероятность того, что говядина закончится раньше, и припозднившиеся гости будут жрать кушать только и исключительно несчастного кота. Кроме того, к ответу надо добавить
мл требуется определить, какова вероятность того, что говядина закончится раньше, и припозднившиеся гости будут жрать кушать только и исключительно несчастного кота. Кроме того, к ответу надо добавить  вероятности того, что оба супа закончатся одновременно. Результат требуется получить с погрешностью не более
вероятности того, что оба супа закончатся одновременно. Результат требуется получить с погрешностью не более  .
.
Объем кастрюли  может принимать значения от
может принимать значения от  до
до  .
.
Наблюдения и размышления
Прежде всего, заметим, что объем половника у них  мл, поэтому, вместо того, чтобы считать в миллилитрах, будем считать в половниках. Тогда объём кастрюли будет
мл, поэтому, вместо того, чтобы считать в миллилитрах, будем считать в половниках. Тогда объём кастрюли будет  половников. Если
половников. Если  не кратно
не кратно  , то округляем в большую сторону — как указано в условии, остатки считаются за полную порцию.
, то округляем в большую сторону — как указано в условии, остатки считаются за полную порцию.
В начальный момент у нас имеется ![m_A[0]= \lceil n/25 \rceil](https://habrastorage.org/getpro/habr/upload_files/a79/98d/fcd/a7998dfcd2a049b3b69ecf42ff92ece4.svg) половников говядины и
половников говядины и ![m_B[0]= \lceil n/25 \rceil](https://habrastorage.org/getpro/habr/upload_files/3ae/f92/750/3aef92750f9648a4211a236d90dd5ec8.svg) половников кота.
половников кота.
После первого заказа может остаться:
![m_A[1]=m_A[0]-100/25; \space m_B[1]=m_B[0]](https://habrastorage.org/getpro/habr/upload_files/801/5da/adb/8015daadb59e6a24a0c70a9f8ff7e5b3.svg) , если гость особо уважаемый;
, если гость особо уважаемый; ![m_A[1]=m_A[0]-75/25; \space m_B[1]=m_B[0]-25/25](https://habrastorage.org/getpro/habr/upload_files/9e3/3b8/140/9e33b8140e3142554d29ad60bd4aee53.svg) , если гость просто уважаемый;
, если гость просто уважаемый; ![m_A[1]=m_A[0]-50/25; \space m_B[1]=m_B[0]-50/25](https://habrastorage.org/getpro/habr/upload_files/a8c/de2/978/a8cde2978b67e8bdd58000828a839fdd.svg) , если гость обычный;
, если гость обычный; ![m_A[1]=m_A[0]-25/25; \space m_B[1]=m_B[0]-75/25](https://habrastorage.org/getpro/habr/upload_files/5b3/776/0cb/5b37760cb111ec9fe1dc1e6c6cc536c2.svg) , если гость алкаш.
, если гость алкаш.
Или, после  -го заказа:
-го заказа:
![m_A[i]=m_A[i-1]-4; \space m_B[i]=m_B[i-1]](https://habrastorage.org/getpro/habr/upload_files/e6b/f8f/7f5/e6bf8f7f56f2a41908a1672ffd7fa13a.svg) , если гость особо уважаемый;
, если гость особо уважаемый; ![m_A[i]=m_A[i-1]-3; \space m_B[i]=m_B[i-1]-1](https://habrastorage.org/getpro/habr/upload_files/d43/75a/8fd/d4375a8fdccd8bdf73033a76c8261684.svg) , если гость просто уважаемый;
, если гость просто уважаемый; ![m_A[i]=m_A[i-1]-2; \space m_B[i]=m_B[i-1]-2](https://habrastorage.org/getpro/habr/upload_files/e23/cd5/ecd/e23cd5ecd9f8452e2572c8d9c395288a.svg) , если гость обычный;
, если гость обычный; ![m_A[i]=m_A[i-1]-1; \space m_B[i]=m_B[i-1]-3](https://habrastorage.org/getpro/habr/upload_files/572/dcf/245/572dcf245aecf85cb1e3c0fdc79c58fc.svg) , если гость алкаш.
, если гость алкаш.
Тут мы, внезапно, замечаем, что общее количество супа с каждой порцией уменьшается ровно на  половника, а разность
половника, а разность  увеличивается либо на 4, либо на 2, либо не меняется, либо уменьшается на 2. Учитывая, что с утра
увеличивается либо на 4, либо на 2, либо не меняется, либо уменьшается на 2. Учитывая, что с утра  , она всегда чётная, как и сумма, которая в начальный момент
, она всегда чётная, как и сумма, которая в начальный момент  .
.
Введём новые переменные:  и
и  .
.
В начальный момент ![s[0] = \lceil n/25 \rceil ; \space d[0] = 0](https://habrastorage.org/getpro/habr/upload_files/623/611/6a6/6236116a6b9f0751f60b753b4b49c60e.svg) .
.
После  -го заказа эти величины меняются следующим образом:
-го заказа эти величины меняются следующим образом:
![s[i] = s[i-1]-2](https://habrastorage.org/getpro/habr/upload_files/dab/688/fbe/dab688fbe5701a0db1f88899cfe779a5.svg)
![d[i] = d[i-1]+[-1;0;1;2]|_{p=0.25}](https://habrastorage.org/getpro/habr/upload_files/873/a1f/80d/873a1f80d18551e097db9ef3fe80f945.svg)
Рассмотрим вероятность ![P[i,D]](https://habrastorage.org/getpro/habr/upload_files/16f/e1e/71c/16fe1e71c4feabf43f711d9bd65f1bc7.svg) того, что после заказа
того, что после заказа  разность равна
разность равна  . Если в этот момент
. Если в этот момент ![d[i]=D](https://habrastorage.org/getpro/habr/upload_files/605/1e1/9d5/6051e19d52fd8c2f1abb4e024df2d3a5.svg) , значит:
, значит:
либо перед этим было
![d[i-1]=D-2](https://habrastorage.org/getpro/habr/upload_files/a9c/5a9/98a/a9c5a998a28760a9333981d74feb66ea.svg) , но пришёл особо уважаемый гость и разность изменилась на
, но пришёл особо уважаемый гость и разность изменилась на  ;
; либо было
![d[i-1]=D-1](https://habrastorage.org/getpro/habr/upload_files/37a/45b/5d1/37a45b5d1f7961c08c320a20d38afbe9.svg) , но пришёл просто уважаемый гость и разность изменилась на
, но пришёл просто уважаемый гость и разность изменилась на  ;
; либо было
![d[i-1]=D](https://habrastorage.org/getpro/habr/upload_files/9f6/2a2/7ca/9f62a27ca08ec63ed9bedf8f81f0ea9a.svg) , пришёл обычный гость и разность не изменилась;
, пришёл обычный гость и разность не изменилась; либо было
![d[i-1]=D+1](https://habrastorage.org/getpro/habr/upload_files/25c/5de/cac/25c5decaceb35bc03fdb43b53f41fb35.svg) , но пришёл алкаш и разность изменилась на
, но пришёл алкаш и разность изменилась на  .
.
Все эти события имеют место с вероятностью  . Тогда:
. Тогда:
![\begin{split} P[i,D] &= P[i-1,D-2] \cdot 0.25 + P[i-1,D-1] \cdot 0.25 +\\ &+P[i-1,D] \cdot 0.25 + P[i-1,D+1] \cdot 0.25 \end{split}](https://habrastorage.org/getpro/habr/upload_files/fcb/d7a/a97/fcbd7aa978cd98183f974b36fd7e6b3f.svg)
Таким образом, если мы создадим массив ![P[i,D]](https://habrastorage.org/getpro/habr/upload_files/601/ad8/a7b/601ad8a7b94bb31255cbf4a65a36b33d.svg) , зададим
, зададим ![P[0,:]=0; \space P[0,0]=1](https://habrastorage.org/getpro/habr/upload_files/e87/ff3/db9/e87ff3db91e41ed6d97574f3253e71e9.svg) , то сможем последовательно посчитать вероятности после каждого заказа.
, то сможем последовательно посчитать вероятности после каждого заказа.
Но в какой-то момент один (или оба) супа закончатся. Когда это произойдёт?
Возвращаясь от наших переменных  обратно к количествам супов, получим:
обратно к количествам супов, получим:

Количество супа с говядиной становится равным  при
при ![d[i]=s](https://habrastorage.org/getpro/habr/upload_files/b49/82a/2c4/b4982a2c453ff4db3d584d39a1f679c9.svg) , а супа с котом при
, а супа с котом при ![d[i]=-s](https://habrastorage.org/getpro/habr/upload_files/5ec/d65/d0f/5ecd65d0feef2b967f7f6c61bfb45036.svg) . То есть, как только будет достигнуто состояние, в котором
. То есть, как только будет достигнуто состояние, в котором ![|d[i]| \ge s](https://habrastorage.org/getpro/habr/upload_files/b0e/627/8ef/b0e6278efb78b38fffdeada549e4662e.svg) , мы должны прекратить сервировку. Это значит, что соответствующие им вероятности
, мы должны прекратить сервировку. Это значит, что соответствующие им вероятности ![P[i,D]](https://habrastorage.org/getpro/habr/upload_files/74d/ae6/4a3/74dae64a3fa7464df76f72d4e39e15d4.svg) , где
, где  , не внесут вклада в вероятности последующих событий и их надо обнулить. Если при этом первым закончился суп с говядиной, то есть
, не внесут вклада в вероятности последующих событий и их надо обнулить. Если при этом первым закончился суп с говядиной, то есть ![d[i]>0» src=«https://habrastorage.org/getpro/habr/upload_files/449/fa8/435/449fa8435047f8a63ef7f2b6f4d3bcd4.svg» />, то мы должны сначала добавить эту вероятность к окончательному ответу.</p>
<p>А когда закончатся оба супа, тогда их полусумма <img alt=](https://habrastorage.org/getpro/habr/upload_files/c5c/d7e/ddb/c5cd7eddb32a74c412364c354a4bd710.svg) станет равна
станет равна  . Таким образом, максимальное количество порций равно
. Таким образом, максимальное количество порций равно  , при чем последняя может быть неполной.
, при чем последняя может быть неполной.
Рассмотрим, например, ![s[0]=7](https://habrastorage.org/getpro/habr/upload_files/3cc/b3c/9fd/3ccb3c9fd0b0983b9acac5f053441c9e.svg) .
.

Рисунок 1
Возможные состояния супов  на каждом шаге
на каждом шаге  отмечены кружочечком.
отмечены кружочечком.
Границы серой области показывают уменьшение  на каждом шаге. Если
на каждом шаге. Если ![d[i]](https://habrastorage.org/getpro/habr/upload_files/d2f/e93/1c4/d2fe931c477d14833a16866d11de6ccf.svg) попало в серую область, значит после данного заказа какой-то из супов закончился. Если закончился суп с говядиной — кружок зелёный, если закончился суп с котом — красный, если оба — двухцветный.
попало в серую область, значит после данного заказа какой-то из супов закончился. Если закончился суп с говядиной — кружок зелёный, если закончился суп с котом — красный, если оба — двухцветный.
В голубых кружочках указана искомая вероятность того, что суп с говядиной закончится раньше. Для каждого шага  она равна сумме всех зелёных значений, лежащих ниже или на том же уровне (двухцветный входит с коэффициентом
она равна сумме всех зелёных значений, лежащих ниже или на том же уровне (двухцветный входит с коэффициентом  ).
).
Стрелками показано, какое состояние может получиться на следующем шаге (чтобы не загромождать, показаны только крайние случаи).
Отметим, что состояния, где один из супов закончился, на последующие не влияют, но если бы мы продолжали их строить, то они давали бы вклад только в серой области (отмечено прозрачной зеленой и красной заливкой) — если суп закончился, то обратно он не появится. Запомним этот факт, он нам понадобится позже.
Рассмотрим также случай для чётного ![s[0]](https://habrastorage.org/getpro/habr/upload_files/165/be8/36d/165be836dfe513f3c2ee7da8c48bd3ed.svg) .
.

Рисунок 2
Мы видим, что для нечетного ![s[0]](https://habrastorage.org/getpro/habr/upload_files/a9b/1ea/1e0/a9b1ea1e0c207e1f955a4b97b2bdad5d.svg) и следующего за ним четного
и следующего за ним четного ![s[0]](https://habrastorage.org/getpro/habr/upload_files/b83/fd6/3a6/b83fd63a641f45fbb7966e67a4a2a1ab.svg) количество раздач не меняется.
количество раздач не меняется.
Алгоритм №1. Динамическое программирование
Таким образом стандартное решение данной задачи в неоптимизированном случае выглядит следующим образом.
Находим начальное

Создаем массив вероятностей
 , состоящий из
, состоящий из  строк,
строк,  столбцов. Обозначим
столбцов. Обозначим  индекс элемента соответствующего
индекс элемента соответствующего  . Пусть индексация начинается с 0, тогда
. Пусть индексация начинается с 0, тогда  . Строка
. Строка  соответствует началу дня, когда
соответствует началу дня, когда  порций съедено, строка
порций съедено, строка  — когда оба супа кончились;
— когда оба супа кончились; Задаём
![P[0,d0]=1](https://habrastorage.org/getpro/habr/upload_files/8c5/93e/501/8c593e501de41e0e3e100ad8b0747c23.svg) , все остальные элементы в этой строке равны
, все остальные элементы в этой строке равны  ;
; Инициализируем переменную, в которой будем хранить результат
 ;
; Инициализируем переменную, в которой будем хранить текущее значение полусуммы
 ;
; Запускаем цикл по строкам
 от
от  до
до  включительно;
включительно; Вычисляем
 на текущем шаге:
на текущем шаге:  . Если
. Если  получилась меньше
получилась меньше  , то присваиваем
, то присваиваем  (любой остаток считается полноценной порцией);
(любой остаток считается полноценной порцией); Запускаем цикл по всем столбцам
 от
от  до
до  ;
; Для каждого
 элемента строки считаем вероятность:
элемента строки считаем вероятность: ![\begin{split} P[i,j] &= P[i-1,j-2] \cdot 0.25 + P[i-1,j-1] \cdot 0.25 \\ &+ P[i-1,j] \cdot 0.25 + P[i-1,j+1] \cdot 0.25 \end{split}](https://habrastorage.org/getpro/habr/upload_files/228/cbf/02d/228cbf02d761764481104e9d623991d9.svg)
Если индекс переполняется, соответствующее слагаемое не учитываем;
Если оба супа закончились одновременно
 , прибавляем половину
, прибавляем половину ![P[i,j]](https://habrastorage.org/getpro/habr/upload_files/322/e17/1a5/322e171a5d855e7950c4a17cd6a2748d.svg) к
к  ;
; Иначе если только суп с котом закончился
 , зануляем его
, зануляем его ![P[i,j] = 0](https://habrastorage.org/getpro/habr/upload_files/29b/21f/f58/29b21ff584d0aa7a01a09b0b09e0f271.svg) ;
; Иначе если закончился суп с говядиной
 , прибавляем полученную вероятность к ответу
, прибавляем полученную вероятность к ответу ![ans=ans+P[i,j]](https://habrastorage.org/getpro/habr/upload_files/4be/987/ddf/4be987ddf6246e406bc2f3fb7f5a78c5.svg) и зануляем
и зануляем ![P[i,j] = 0](https://habrastorage.org/getpro/habr/upload_files/50b/6e5/b77/50b6e5b77779d6ed4f6c4cfdd45e1c02.svg) ;
; Переходим к следующему элементу
 и повторяем 9–13;
и повторяем 9–13; Переходим к следующей строке
 и повторяем 9–13;
и повторяем 9–13; Ответ находится в
 .
.
Вот программка на C++. Разумеется, можно сделать красиво, можно заметить, что массив избыточен, что нам надо хранить только предыдущую и следующую строчки и т.п.
double soupServings(int n) {
int s0 = (n-1)/25+1;
vector> P((s0+1)/2+1, vector(2*s0+1,0.));
int d0 =s0;
P[0][d0] = 1.;
double ans = 0.;
int s = s0;
for (int i = 1; i< P.size(); ++i) {
s -= 2;
if (s<0) s = 0;
for (int j = 0; j< P.front().size(); ++j) {
if (j-2 >= 0) P[i][j] += P[i-1][j-2]*0.25;
if (j-1 >= 0) P[i][j] += P[i-1][j-1]*0.25;
P[i][j] += P[i-1][j]*0.25;
if (j+1 < P.front().size()) P[i][j] += P[i-1][j+1]*0.25;
if (j==d0 && s <= 0) {
ans += P[i][j]*0.5;
P[i][j] = 0;
}
else if (j-d0 >= s) {
ans += P[i][j];
P[i][j] = 0;
}
else if (j-d0 <= -s) P[i][j] = 0;
}
}
return ans;
И все бы хорошо, но временная сложность получается  , также как и затраты памяти. А допустимое значение
, также как и затраты памяти. А допустимое значение  может быть аж
может быть аж  . То есть нам надо будет несколько эксабайт памяти и очень много времени.
. То есть нам надо будет несколько эксабайт памяти и очень много времени.
Однако, мы можем заметить, что с ростом  ответ приближается к
ответ приближается к  , и при
, и при  менее, чем на
менее, чем на  . А требуемая точность и есть
. А требуемая точность и есть  . То есть мы можем просто добавить в начале строчку
. То есть мы можем просто добавить в начале строчку if (n>5000) return 1.;. При  мы имеем
мы имеем ![s[0]=200](https://habrastorage.org/getpro/habr/upload_files/44f/454/a45/44f454a4563b82ca2e33b010b4014b4e.svg) , то есть получается массив
, то есть получается массив  , а если оптимизировать и того меньше. Именно такой тип решения и предлагается в качестве «официального» на LeetCode.
, а если оптимизировать и того меньше. Именно такой тип решения и предлагается в качестве «официального» на LeetCode.
Наблюдения и размышления (продолжение)
Вышеизложенное всем известно и никому не интересно. А что, если придумать решение  по времени и
по времени и  по затратам памяти? Давайте придумаем.
по затратам памяти? Давайте придумаем.
Прежде всего вспомним, что область влияния состояний, которые соответствуют закончившемуся супу, ограничена серыми областями на рисунке. Что будет, если мы не будем обнулять эти вероятности? Раз они остаются в серой зоне, мы можем их оставить «на потом», и сложить уже только на последнем шаге.

Рисунок 3.
Мы получили весьма интригующую картину. Вероятности оказались симметричны, более того, получившееся дерево одинаково для всех  , разница только в том, где его обрубать.
, разница только в том, где его обрубать.
К сожалению, ответ не совпадает. И мы видим, почему. Состояние с ![d[i]=-1](https://habrastorage.org/getpro/habr/upload_files/26c/502/559/26c502559f401345543089956ef3deba.svg) на предпоследнем шаге влияет на правую серую область и на центральное значение, а также состояние с
на предпоследнем шаге влияет на правую серую область и на центральное значение, а также состояние с ![d[i]=+1](https://habrastorage.org/getpro/habr/upload_files/0df/49c/379/0df49c3798d4b14fd78ac2bbb360134a.svg) на предпоследнем шаге влияет на центральное.
на предпоследнем шаге влияет на центральное.
Тогда давайте уменьшим число шагов на 1, а последний сделаем «ручками». Для нечетных  надо дополнительно обработать только один белый кружок
надо дополнительно обработать только один белый кружок ![d[i]=0](https://habrastorage.org/getpro/habr/upload_files/a3c/697/580/a3c697580f9f56ce9708098f6b714b6c.svg) .
.

Рисунок 4.
Для четных  ручками будем обрабатывать аж 3 кружка:
ручками будем обрабатывать аж 3 кружка: ![d[i] = -1, 0, 1](https://habrastorage.org/getpro/habr/upload_files/706/35a/da8/70635ada8a88fb3e819936afa6e4af74.svg)
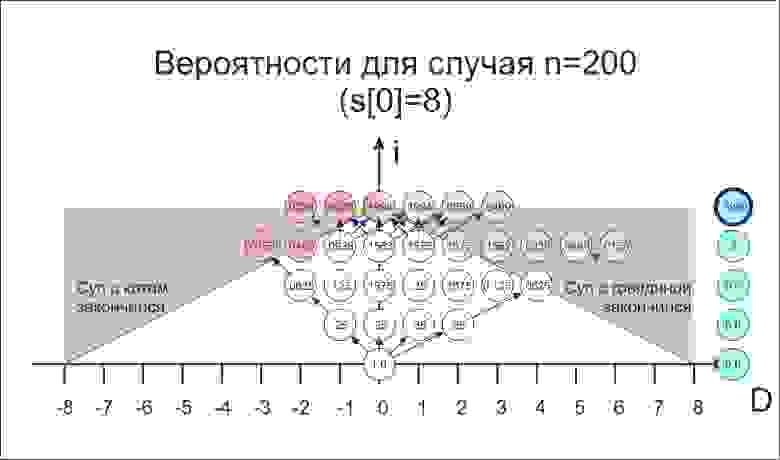
Рисунок 5.
Ура! Получилось.
Но что дальше? Нам все равно придется строить пирамиду. Или нет?
Избавившись от граничный условий, мы получили следующую задачу. Есть целое число  , в начальный момент
, в начальный момент ![d[0]=0](https://habrastorage.org/getpro/habr/upload_files/fd0/3cd/eeb/fd03cdeeb457dfea37f1dc20da2bf2f9.svg) . На каждом шаге к нему добавляется
. На каждом шаге к нему добавляется  ,
,  ,
,  ,
,  с одинаковой вероятностью, обозначим это событие как
с одинаковой вероятностью, обозначим это событие как ![[-1,0,1,2]|_{p=0.25}](https://habrastorage.org/getpro/habr/upload_files/81b/038/cf6/81b038cf626f730bc240d6b4523c822d.svg) . Найти вероятность того, что на шаге
. Найти вероятность того, что на шаге  получится
получится ![d[i]=D](https://habrastorage.org/getpro/habr/upload_files/331/e56/1d9/331e561d94a5086ab4778a0773eea98a.svg) .
.
Если бы у нас было, к примеру, только два возможных исхода, мы получили бы биномиальное распределение https://ru.wikipedia.org/wiki/Биномиальное_распределение.
О биномиальном распределении
Пусть мы бросаем монетку  раз. Какова вероятность, что выпадет ровно
раз. Какова вероятность, что выпадет ровно  орлов, считая, что вероятность выпадения орла и решки одинакова? Посчитаем количество таких исходов. Выпишем подряд индексы бросков
орлов, считая, что вероятность выпадения орла и решки одинакова? Посчитаем количество таких исходов. Выпишем подряд индексы бросков  . Переставим их так, чтобы все броски, при которых выпал орёл, были в начале списка. То есть для бросков, соответствующих
. Переставим их так, чтобы все броски, при которых выпал орёл, были в начале списка. То есть для бросков, соответствующих  первым индексам выпал орел, для остальных решка.
первым индексам выпал орел, для остальных решка.
![i_{орелЪ}[0], i_{орелЪ}[1], ..., i_{орелЪ}[x], \space \space i_{решка}[0], i_{решка}[1], ... , i_{решка}[i-x]](https://habrastorage.org/getpro/habr/upload_files/80f/639/b60/80f639b6013ec08bdc2b437072eb002d.svg)
Каждый индекс в списке встречается ровно  раз. Всего имеем
раз. Всего имеем  вариантов расположения индексов. Однако, если мы перетасуем индексы, которые соответствуют выпадению орла, только среди «своих», мы получим тот же самый случай. Аналогично для решки.
вариантов расположения индексов. Однако, если мы перетасуем индексы, которые соответствуют выпадению орла, только среди «своих», мы получим тот же самый случай. Аналогично для решки.
Таким образом, надо разделить общее число перестановок на число перестановок отдельно орлов и число перестановок отдельно решек. Получаем биномиальный коэффициент https://ru.wikipedia.org/wiki/Биномиальный_коэффициент:

Это число возможных исходов серии бросков, когда выпадает ровно  орлов. Чтобы найти вероятность, надо разделить его на общее число возможных исходов, которое равно — для каждого из бросков возможны два варианта, а всего бросков
орлов. Чтобы найти вероятность, надо разделить его на общее число возможных исходов, которое равно — для каждого из бросков возможны два варианта, а всего бросков  .
.
Но у нас не два, а четыре варианта для каждого шага. И тут мы вспоминаем, что четыре — это дважды два. Что если вместо каждого броска с четырьмя исходами, делать два броска с двумя исходами? Вместо того, чтобы выбирать одно из четырех возможных слагаемых ![[-1, 0, 1, 2]|_{p=0.25}](https://habrastorage.org/getpro/habr/upload_files/91c/8a1/7f8/91c8a17f8b0ee7cbe36735ea9860f5bf.svg) , выберем сначала одно из двух
, выберем сначала одно из двух ![[0, 2]|_{p=0.5}](https://habrastorage.org/getpro/habr/upload_files/269/bd6/1bb/269bd61bb0c62d7baa0e5eca361bcd88.svg) , а потом еще одно из другой пары
, а потом еще одно из другой пары ![[0, -1]|_{p=0.5}](https://habrastorage.org/getpro/habr/upload_files/e7c/22c/6c0/e7c22c6c0a31dd2572cec8f1e07ef126.svg) .
.
Выпишем все возможные исходы:
выбрали
 и
и  :
:  , вероятность
, вероятность  ;
; выбрали
 и
и  :
:  , вероятность ;
, вероятность ; выбрали
 и
и  :
:  , вероятность ;
, вероятность ; выбрали
 и
и  :
:  , вероятность .
, вероятность .
Получается, два бинарных события в сумме дают нам искомое событие с четырьмя исходами. Такой трюк можно провернуть далеко не в каждом случае, но здесь можно.
Какова вероятность, что после  пар бросков
пар бросков ![d[i]=D](https://habrastorage.org/getpro/habr/upload_files/5cd/8dd/7a4/5cd8dd7a4f544600740a34abca32a19f.svg) ?
?
Пусть в паре ![[0, 2]|_{p=0.5}](https://habrastorage.org/getpro/habr/upload_files/822/9ad/11b/8229ad11be2cdfbc5efa7a145f8d3509.svg)
 раз выпала двойка, вероятность этого равна
раз выпала двойка, вероятность этого равна  .
.
В свою очередь, в паре ![[0, -1]|_{p=0.5}](https://habrastorage.org/getpro/habr/upload_files/6b8/db0/125/6b8db01254f5a1f7f1cffb7c4b085c49.svg)
 раз выпала
раз выпала  , вероятность
, вероятность  .
.
Чтобы получить  необходимо, чтобы
необходимо, чтобы  . Просуммируем вероятности:
. Просуммируем вероятности:
![P[i,D]=\sum_{2q-k=D} \left[ 2^{-i}\binom{i}{q} \cdot 2^{-i}\binom{i}{k} \right]](https://habrastorage.org/getpro/habr/upload_files/cbc/1c7/7a2/cbc1c77a273a840ddb204951b31e3132.svg)
Выразим  через
через  :
:
![P[i,D]=2^{-2i}\sum_{q} \left[ \binom{i}{q} \binom{i}{2q-D} \right]](https://habrastorage.org/getpro/habr/upload_files/601/ec2/152/601ec21528a0407790400562aaa3b506.svg)
Видим, что  не может быть меньше, чем
не может быть меньше, чем  , и больше, чем
, и больше, чем  .
.
![P[i,D]=2^{-2i}\sum_{q=max(0,\lceil D/2 \rceil)}^{min(i, \lfloor (i+D)/2 \rfloor )} \left[ \binom{i}{q} \binom{i}{2q-D} \right]](https://habrastorage.org/getpro/habr/upload_files/3dd/009/874/3dd009874eaa5885e2323f332bef6f21.svg)
Формулу получили, осталось применить её к нашей задаче.
Посчитаем вероятность того, что на шаге  супа с котом больше или столько же, сколько супа с говядиной
супа с котом больше или столько же, сколько супа с говядиной ![d[i] \le 0](https://habrastorage.org/getpro/habr/upload_files/a8d/ea7/d02/a8dea7d02f1d8826b4d5a9c01f496d9f.svg) . Почему не наоборот? Потому что это число меньше, а значит, при одинаковой относительной погрешности вычисления будем иметь меньшую абсолютную погрешность. Кстати отметим, что минимальное возможное значение
. Почему не наоборот? Потому что это число меньше, а значит, при одинаковой относительной погрешности вычисления будем иметь меньшую абсолютную погрешность. Кстати отметим, что минимальное возможное значение ![d[i]](https://habrastorage.org/getpro/habr/upload_files/fc7/ed6/220/fc7ed62201e8be75163ba6451ccf6bf2.svg) на каждом шаге равно
на каждом шаге равно  . Оно соответствует случаю, когда каждый раз выпадала
. Оно соответствует случаю, когда каждый раз выпадала  .
.
Вернемся к исходной форме выражения:
![P[i,d[i] \le 0]=2^{-2i}\sum_{2q-k \le 0} \sum \left[ \binom{i}{q} \binom{i}{k} \right]](https://habrastorage.org/getpro/habr/upload_files/443/49d/16a/44349d16a167f4900be5687767e5aa7f.svg)
 не может быть больше, чем
не может быть больше, чем  , и в то же время
, и в то же время  . Если внешнее суммирование делать по
. Если внешнее суммирование делать по  , то его пределы будут от
, то его пределы будут от  до
до  . Тогда:
. Тогда:
![P[i,d \le 0]=2^{-2i}\sum_{q=0}^{\lfloor i/2 \rfloor}\sum_{k = 2q}^{i} \left[ \binom{i}{q} \binom{i}{k} \right]](https://habrastorage.org/getpro/habr/upload_files/8a7/03f/826/8a703f82618e70a67f0e967313cfbf24.svg)
Однако, если мы применим данную формулу на предпоследнем шаге, результат будет включать вероятности, которые мы хотели обрабатывать «ручками», для случая ![d[i]=0](https://habrastorage.org/getpro/habr/upload_files/cca/40e/64b/cca40e64b45e44d41154eb8bcf69d354.svg) , а для четных
, а для четных  также и
также и ![d[i]=-1](https://habrastorage.org/getpro/habr/upload_files/d4f/7c6/675/d4f7c667516e3fa63a8830d3ccd0caf2.svg) . К тому же, нам будут нужны сами эти вероятности отдельно, а также вероятность
. К тому же, нам будут нужны сами эти вероятности отдельно, а также вероятность ![d[i]=1](https://habrastorage.org/getpro/habr/upload_files/fdd/ef2/2d1/fddef22d190e34eefe1532a8eecddf01.svg) для четных
для четных  .
.
Выпишем формулы для них:
![P[i,0]=2^{-2i}\sum_{q=0}^{\lfloor i/2 \rfloor} \left[ \binom{i}{q} \binom{i}{2q} \right]](https://habrastorage.org/getpro/habr/upload_files/8d1/872/081/8d18720811e60ab6cde0a562e8deeeab.svg)
![P[i,-1]=2^{-2i}\sum_{q=0}^{\lfloor (i-1)/2 \rfloor} \left[ \binom{i}{q} \binom{i}{2q+1} \right]](https://habrastorage.org/getpro/habr/upload_files/c9f/76d/d57/c9f76dd570ae3622c13c3be6f967d998.svg)
![P[i,1]=2^{-2i}\sum_{q=1}^{\lfloor (i+1)/2 \rfloor} \left[ \binom{i}{q} \binom{i}{2q-1} \right]](https://habrastorage.org/getpro/habr/upload_files/191/73f/459/19173f4599b0af07fa127f72aa61ccf4.svg)
Посмотрев на рисунки 4 и 5 и подумав, получим окончательное выражение для искомой вероятности того, что суп с говядиной закончится раньше. Вспоминаем, что максимальное количество порций  , значит на предпоследнем шаге
, значит на предпоследнем шаге  :
:
для нечетных s:
![ans = 1 - P[i,d \le 0] + P[i,0] \cdot 0.25 \cdot 2.5 = 1 - P[i,d \le 0] + P[i,0] \cdot 0.625](https://habrastorage.org/getpro/habr/upload_files/e04/e9a/6d4/e04e9a6d491a2f1897b0591baa4330e6.svg)
для четных s:
![\begin{split} ans &= 1 - P[i,d \le 0] - P[i,1] + P[i,-1] \cdot 0.25 \cdot 1.5 + \\&+ P[i,0] \cdot 0.25 \cdot 2.5 + P[i,1] \cdot 0.25 \cdot 3.5 = \\ &= 1 - P[i,d \le 0] + P[i,-1] \cdot 0.375 + P[i,0] \cdot 0.625 - P[i,1] \cdot 0.125 \end{split}](https://habrastorage.org/getpro/habr/upload_files/785/e9e/f18/785e9ef182d47b6c7d303a68e5a0bcb0.svg)
Теперь бы все это посчитать.
Для начала, нам нужны биномиальные коэффициенты. Поскольку  у нас фиксировано, можно рассчитать их заранее. Проницательно отметив, что
у нас фиксировано, можно рассчитать их заранее. Проницательно отметив, что

будем считать только половину из них. Но если  велико, то и биномиальные коэффициенты большие, может случиться переполнение. К счастью, нам нужны не сами коэффициенты, а вероятности, то есть:
велико, то и биномиальные коэффициенты большие, может случиться переполнение. К счастью, нам нужны не сами коэффициенты, а вероятности, то есть:

Тут возникает обратная проблема:  — очень маленькая величина.
— очень маленькая величина.
А так как факториалы считаются последовательно, следующий выражается через предыдущий, то умножение на  даст
даст  .Чтобы решить эту проблему, будем делить на степени двойки постепенно. Сначала на 1, потом на 4, потом на 16 и т.д. Почему именно так? Потому что мы считаем только половину из
.Чтобы решить эту проблему, будем делить на степени двойки постепенно. Сначала на 1, потом на 4, потом на 16 и т.д. Почему именно так? Потому что мы считаем только половину из  биномиальных коэффициентов, соответственно, к концу дойдет до нужной степени. А самое главное, наибольшее значение как раз в середине:
биномиальных коэффициентов, соответственно, к концу дойдет до нужной степени. А самое главное, наибольшее значение как раз в середине:

Параллельно будем считать сумму:

Чуть раньше, вы наверное, удивлялись, как же так, ведь ![P[i,d \le 0]](https://habrastorage.org/getpro/habr/upload_files/3a3/3d2/8ad/3a33d28ad77ef462b34c8c44cb4a53b9.svg) содержит две суммы, почему же я заявляю время
содержит две суммы, почему же я заявляю время  ? А потому, что суммы по
? А потому, что суммы по  считается здесь один раз и за линейное время. Очень удобно: посчитал коэффициент и сразу прибавил.
считается здесь один раз и за линейное время. Очень удобно: посчитал коэффициент и сразу прибавил.
Кстати, вы помните, что  ?
?
Алгоритм №2.1. Расчет вероятностей биномиального распределения
Создаём массивы для хранения биномиальных коэффициентов
 и сумм
и сумм  размером
размером  каждый;
каждый; Инициализируем переменную
 , в которой будем хранить текущий биномиальный коэффициент деленный на какую-то (сами не знаем, какую, но можем сочинить) степень двойки;
, в которой будем хранить текущий биномиальный коэффициент деленный на какую-то (сами не знаем, какую, но можем сочинить) степень двойки; Записываем первый коэффициент
![binomials[0]=val \cdot 2^{-i}](https://habrastorage.org/getpro/habr/upload_files/fef/738/8e8/fef7388e8953be45aa962cc2d3e0b146.svg) (помним, что целочисленные степени двойки считаются очень просто);
(помним, что целочисленные степени двойки считаются очень просто); То же самое записываем в первую ячейку массива сумм
![sums[0]=binomials[0]](https://habrastorage.org/getpro/habr/upload_files/c34/d2d/e68/c34d2de680a98a5aa4d320a8c3d067e1.svg) ;
; Запускаем цикл по
 от
от  до
до  включительно;
включительно; Модифицируем значение:

Вы можете легко получить это выражение, если разделите
 на
на  ;
; Записываем биномиальный коэффициент с учетом уже использованных степеней двойки:
![binomials[k] = val \cdot 2^{-(i-2k+2)}](https://habrastorage.org/getpro/habr/upload_files/d54/fca/5b9/d54fca5b955121da5f21dc0446054206.svg) ;
; Вычисляем текущую сумму:
![sums[k]=sums[k-1]+binomials[k]](https://habrastorage.org/getpro/habr/upload_files/15b/60b/362/15b60b3621066a2842863225e0fee063.svg) ;
; Повторяем 6–9
Удобно сделать отдельный класс, который при инициализации будет считать коэффициенты (точнее, вероятности), а потом по запросу выдавать, в зависимости от того, из какой половины — посчитанной или симметричной — требуется коэффициент:
class Binom {
vector binomials;
vector sums;
int i;
public:
Binom(int _i) : i(_i), binomials(_i/2 + 1), sums(_i/2 + 1, 0) {
double val = 1.;
binomials.front() = val*exp2(-i);
sums.front() = binomials.front();
for (int k = 1; k < binomials.size(); k++) {
val *= (i-k+1.) / k;
binomials[k] = val*exp2(-(i-2*k+2));
sums[k] = sums[k-1] + binomials[k];
val /= 4;
}
}
double get_k(size_t k) {
if (k < 0) return 0.;
if (k < binomials.size()) return binomials[k];
if (k <= i) return binomials[i - k];
return 0;
}
double get_sum(int k) {
if (k < 0) return 0.;
if (k < sums.size()) return sums[k];
if (k < i) return 1. - sums[i - k - 1];
return 1.;
}
};
Отметим, что здесь мы возвращаем коэффициент 0, если  выходит за допустимые пределы, что сделает подсчет сумм удобнее. Сумма, соответственно, 0 для
выходит за допустимые пределы, что сделает подсчет сумм удобнее. Сумма, соответственно, 0 для  , 1 для
, 1 для  , но это добавили просто для согласованности, реально таких значений не будет.
, но это добавили просто для согласованности, реально таких значений не будет.
Наконец, начинаем считать. Только предварительно переобозначим индекс суммирования  в выражении для
в выражении для ![P[i,1]](https://habrastorage.org/getpro/habr/upload_files/033/757/081/033757081ce4974cb2bd370a8ffb8317.svg) . Вместо:
. Вместо:
![P[i,1]=2^{-2i}\sum_{q=1}^{\lfloor (i+1)/2 \rfloor} \left[ \binom{i}{q} \binom{i}{2q-1} \right]](https://habrastorage.org/getpro/habr/upload_files/75f/ae5/67b/75fae567b28c9363a4721cc2ba5694c2.svg)
напишем:
![P[i,1]=2^{-2i}\sum_{q=0}^{\lfloor (i-1)/2 \rfloor} \left[ \binom{i}{q+1} \binom{i}{2q+1} \right]](https://habrastorage.org/getpro/habr/upload_files/675/0e5/cd3/6750e5cd3f548580b4c53f30016c091d.svg)
И суммировать все выражения будем до  , все равно для неправильных значений коэффициенты будут 0.
, все равно для неправильных значений коэффициенты будут 0.
Да, вы ведь еще помните, что  ?
?
Алгоритм №2.2. O (n)/O (n)
Находим начальное
; Находим индекс пр
