Строительные блоки распределенных приложений. Первое приближение

В прошлой статье мы разобрали теоретические основы реактивной архитектуры. Пришло время поговорить о потоках данных, путях реализации реактивных Erlang/Elixir систем и шаблонах обмена сообщениями в них:
- Request-response
- Request-Chunked Response
- Response with Request
- Publish-subscribe
- Inverted Publish-subscribe
- Task distribution
SOA, MSA и обмен сообщениями
SOA, MSA — системные архитектуры, определяющие правила построения систем, в то время как messaging предоставляет примитивы для их реализации.
Я не хочу пропагандировать ту или иную архитектуру построения систем. Я за применение максимально эффективных и полезных для конкретного проекта и бизнеса практик. Какую бы парадигму мы ни выбрали, создавать системные блоки лучше с оглядкой на Unix-way: компоненты с минимальной связностью, отвечающие за отдельные сущности. Методы API выполняют максимально простые действия с сущностями.
Messaging ‒ как понятно из названия ‒ брокер сообщений. Его основная цель ‒ принимать и отдавать сообщения. Он отвечает за интерфейсы отправки информации, формирование логических каналов передачи информации внутри системы, маршрутизацию и балансировку, а также обработку отказов на системном уровне.
Разрабатываемый messaging не пытается конкурировать с rabbitmq или заменять его. Его основные черты:
- Распределенность.
Точки обмена можно создавать на всех узлах кластера, максимально близко к коду, использующему их. - Простота.
Направленность на минимизацию шаблонного кода и удобство использования. - Лучшая производительность.
Мы не пытаемся повторить функционал rabbitmq, а выделяем только архитектурный и транспортный слой, который максимально просто вписываем в OTP, минимизируя издержки. - Гибкость.
Каждый сервис может объединять в себе множество шаблонов обмена. - Отказоустойчивость, заложенная в дизайне.
- Масштабируемость.
Messaging растет вместе с приложением. По мере увеличения нагрузки можно выносить точки обмена на отдельные машины.
Замечание. С точки зрения организации кода, для сложных систем на Erlang/Elixir хорошо подходят мета-проекты. Весь код проекта находится в одном репозитории ‒ зонтичном проекте. При этом микросервисы максимально изолированы и выполняют простые операции, отвечающие за отдельную сущность. При таком подходе легко поддерживать API всей системы, просто вносить изменения, удобно писать юнит и интеграционные тесты.
Компоненты системы взаимодействуют напрямую или же через брокера. С позиции messaging, каждый сервис имеет несколько жизненных фаз:
- Инициализация сервиса.
На данном этапе происходит конфигурация и запуск исполняющего сервис процесса и зависимостей. - Создание точки обмена.
Сервис может использовать статическую точку обмена, заданную в конфигурации узла, либо же создавать точки обмена динамически. - Регистрация сервиса.
Чтобы сервис мог обслуживать запросы, его нужно зарегистрировать на точке обмена. - Нормальное функционирование.
Сервис производит полезную работу. - Завершение работы.
Возможны 2 вида завершения работы: штатное и аварийное. При штатном сервис отключается от точки обмена и останавливается. В аварийных случаях messaging выполняет один из сценариев обработки отказов.
Выглядит довольно сложно, но в коде не все так страшно. Примеры кода с комментариями будут приведены в разборе шаблонов чуть позже.
Exchanges
Точка обмена ‒ процесс messaging, реализующий логику взаимодействия с компонентами в рамках шаблона обмена сообщениями. Во всех примерах, представленных ниже, компоненты взаимодействуют через точки обмена, комбинация которых и образует messaging.
Message exchange patterns (MEPs)
Глобально шаблоны обмена можно разделить на двусторонние и односторонние. Первые подразумевают ответ на поступившее сообщение, вторые нет. Классическим примером двустороннего шаблона в клиент-серверной архитектуре является Request-response шаблон. Рассмотрим шаблон и его модификации.
Request–response или RPC
RPC используется когда нам нужно получить ответ от другого процесса. Этот процесс может быть запущен на том же узле или находиться на другом континенте. Ниже представлена схема взаимодействия клиента и сервера через messaging.
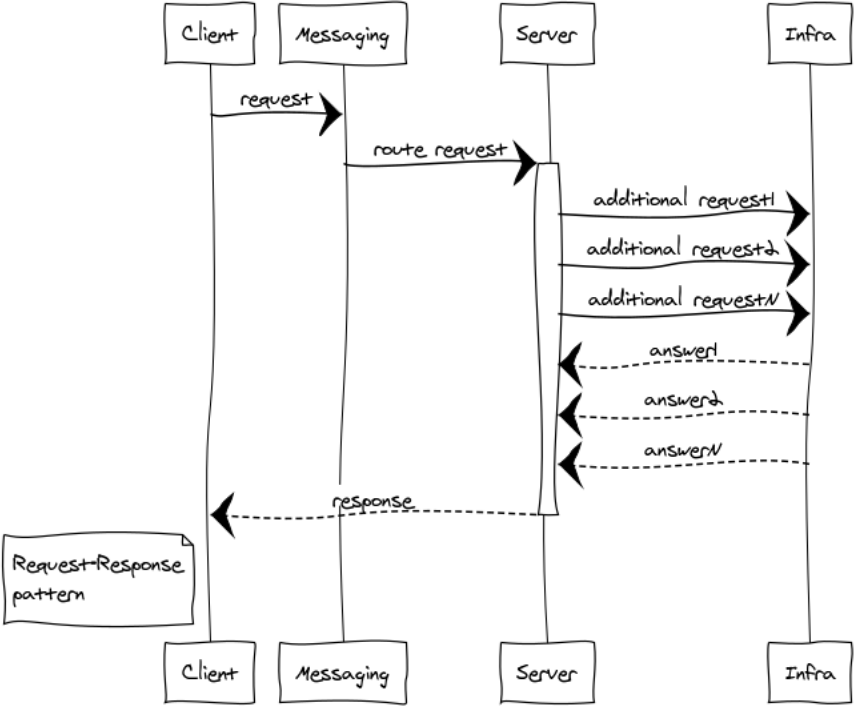
Поскольку messaging полностью асинхронный, то для клиента обмен делится на 2 фазы:
-
Отправка запроса
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).Exchange ‒ уникальное имя точки обмена
ResponseMatchingTag ‒ локальная метка для обработки ответа. Например в случае отправки нескольких одинаковых запросов, принадлежащим разным пользователям.
RequestDefinition ‒ тело запроса
HandlerProcess ‒ PID обработчика. Этому процессу придет ответ от сервера. -
Обработка ответа
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)ResponsePayload ‒ ответ сервера.
Для сервера процесс также состоит из 2 фаз:
- Инициализация точки обмена
- Обработка поступивших запросов
Проиллюстрируем кодом данный шаблон. Допустим, что нам необходимо реализовать простой сервис, предоставляющий единственный метод точного времени.
Код сервера
Вынесем определение API сервиса в api.hrl:
%% =====================================================
%% entities
%% =====================================================
-record(time, {
unixtime :: non_neg_integer(),
datetime :: binary()
}).
-record(time_error, {
code :: non_neg_integer(),
error :: term()
}).
%% =====================================================
%% methods
%% =====================================================
-record(time_req, {
opts :: term()
}).
-record(time_resp, {
result :: #time{} | #time_error{}
}).
Определим контроллер сервиса в time_controller.erl
%% В примере показан только значимый код. Вставив его в шаблон gen_server можно получить рабочий сервис.
%% инициализация gen_server
init(Args) ->
%% подключение к точке обмена
messaging:monitor_exchange(req_resp, ?EXCHANGE, default, self())
{ok, #{}}.
%% обработка события потери связи с точкой обмена. Это же событие приходит, если точка обмена еще не запустилась.
handle_info(#exchange_die{exchange = ?EXCHANGE}, State) ->
erlang:send(self(), monitor_exchange),
{noreply, State};
%% обработка API
handle_info(#time_req{opts = _Opts}, State) ->
messaging:response_once(Client, #time_resp{
result = #time{ unixtime = time_utils:unixtime(now()), datetime = time_utils:iso8601_fmt(now())}
});
{noreply, State};
%% завершение работы gen_server
terminate(_Reason, _State) ->
messaging:demonitor_exchange(req_resp, ?EXCHANGE, default, self()),
ok.
Код клиента
Для того чтобы отправить запрос сервису, в любом месте клиента можно вызвать messaging request API:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of
ok -> ok;
_ -> %% repeat or fail logic
end
В распределенной системе конфигурация компонентов может быть самой разной и в момент запроса messaging может еще не запуститься, или же контроллер сервиса не будет готов обслужить запрос. Поэтому нам необходимо проверить ответ messaging и обработать случай отказа.
После успешной отправки клиенту от сервиса придет ответ или ошибка.
Обработаем оба случая в handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) ->
?debugVal(Utime),
{noreply, State};
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) ->
?debugVal({error, ErrorCode}),
{noreply, State};
Request-Chunked Response
Лучше не допускать передачи огромных сообщений. От этого зависит отзывчивость и стабильная работа всей системы. Если ответ на запрос занимает много памяти, то разбивка на части является обязательной.
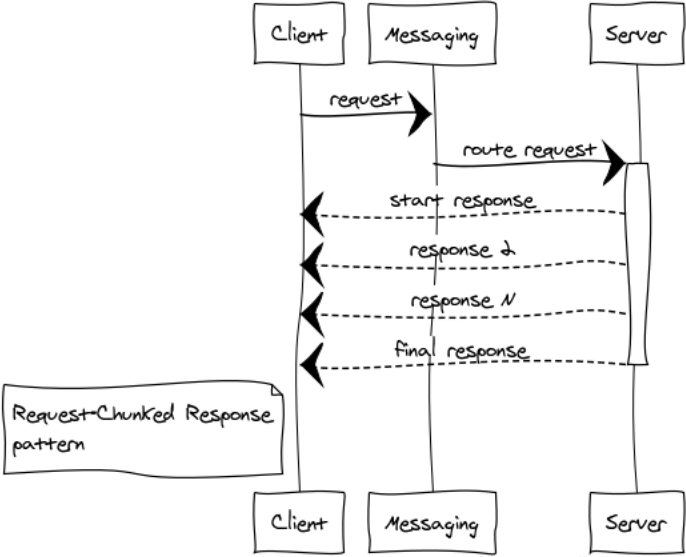
Приведу пару примеров таких случаев:
- Компоненты обмениваются бинарными данными, например файлами. Разбивка ответа на небольшие части помогает эффективно работать с файлами любого размера и не ловить переполнения памяти.
- Листинги. Например, нам нужно выбрать все записи из огромной таблицы в базе и передать другому компоненту.
Я называю такие ответы паровозом. В любом случае,1024 сообщений по 1 Мб лучше, чем единственное сообщение размером 1 Гб.
В Erlang кластере мы получаем дополнительный выигрыш ‒ уменьшение нагрузки на точку обмена и сеть, так как ответы сразу направляются получателю, минуя точку обмена.
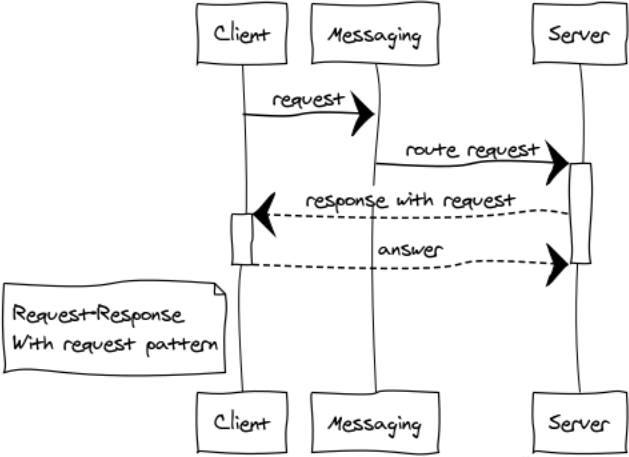
Response with Request
Это довольно редкая модификация паттерна RPC для построения диалоговых систем.
Publish-subscribe (data distribution tree)
Событийно-ориентированные системы по мере готовности данных доставляют их потребителям. Таким образом, системы более склонны к push-модели, чем к pull или poll. Эта особенность позволяет не тратить впустую ресурсы, постоянно запрашивая и ожидая данные.
На рисунке представлен процесс распространения сообщения к потребителям, подписанным на определенную тему.
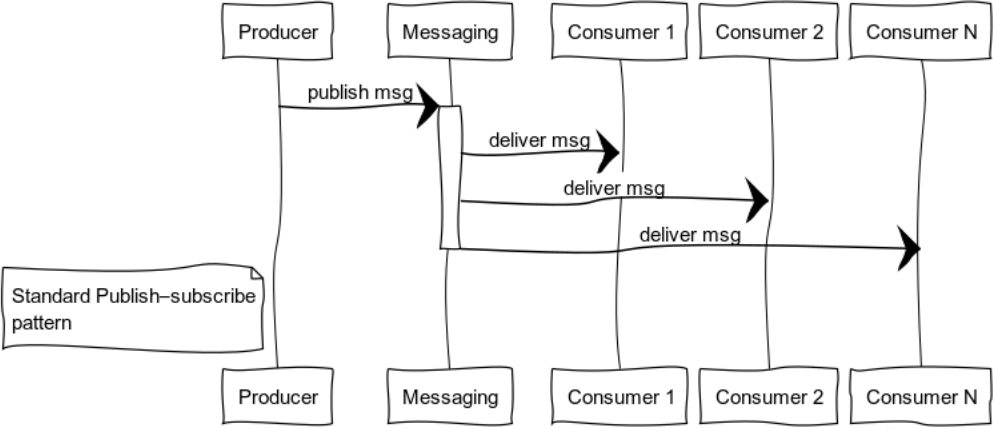
Классическими примерами использования этого шаблона является распространение состояния: игрового мира в компьютерных играх, рыночных данных на биржах, полезной информации в датафидах.
Рассмотрим код подписчика:
init(_Args) ->
%% подписываемся на обменник, ключ = key
messaging:subscribe(?SUBSCRIPTION, key, tag, self()),
{ok, #{}}.
handle_info(#exchange_die{exchange = ?SUBSCRIPTION}, State) ->
%% если точка обмена недоступна, то пытаемся переподключиться
messaging:subscribe(?SUBSCRIPTION, key, tag, self()),
{noreply, State};
%% обрабатываем пришедшие сообщения
handle_info(#'$msg'{exchange = ?SUBSCRIPTION, message = Msg}, State) ->
?debugVal(Msg),
{noreply, State};
%% при остановке потребителя - отключаемся от точки обмена
terminate(_Reason, _State) ->
messaging:unsubscribe(?SUBSCRIPTION, key, tag, self()),
ok.
Источник может вызывать функцию публикации сообщения в любом удобном месте:
messaging:publish_message(Exchange, Key, Message).
Exchange ‒ название точки обмена,
Key ‒ ключ маршрутизации
Message ‒ полезная нагрузка
Inverted Publish-subscribe
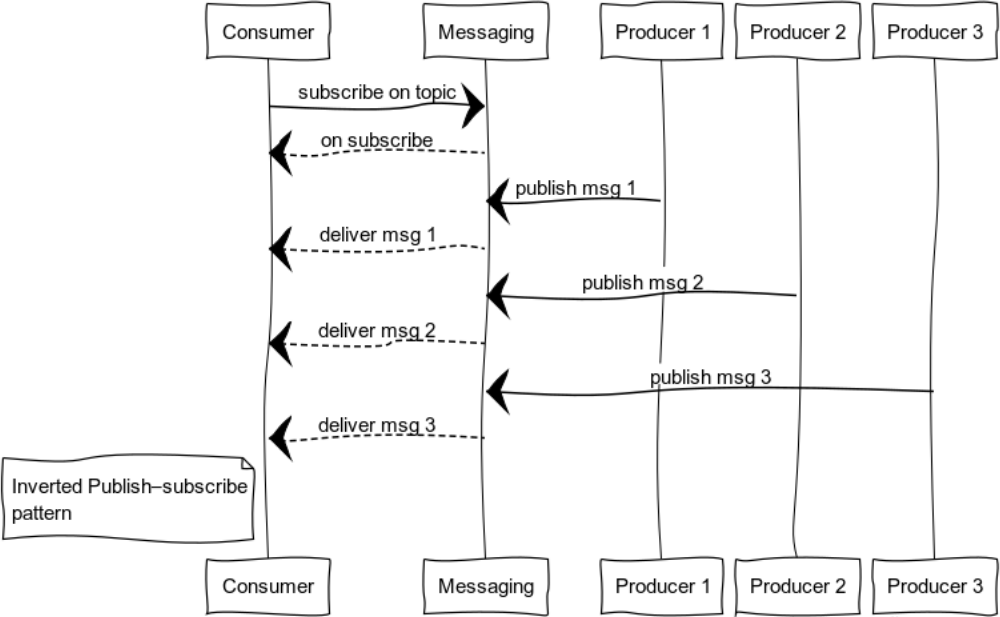
Развернув pub-sub, можно получить паттерн, удобный для логирования. Набор источников и потребителей может быть совершенно разным. На рисунке представлен случай с одним потребителем и множеством источников.
Task distribution pattern
Почти в каждом проекте возникают задачи отложенной обработки, такие как формирование отчетов, доставка уведомлений, получение данных из сторонних систем. Пропускная способность системы, выполняющей эти задачи, легко масштабируется путем добавления обработчиков. Всё, что нам остается, ‒ это сформировать кластер из обработчиков и равномерно распределять задачи между ними.
Рассмотрим возникающие ситуации на примере 3 обработчиков. Еще на этапе распределения задач возникает вопрос справедливости распределения и переполнения обработчиков. За справедливость будет отвечать round-robin распределение, а чтобы не возникало ситуации переполнения обработчиков, введем ограничение prefetch_limit. В переходных режимах prefetch_limit не даст одному обработчику получить все задачи.
Messaging управляет очередями и приоритетом обработки. Обработчики получают задачи по мере их поступления. Выполнение задачи может завершиться успешно либо же отказом:
messaging:ack(Tack)‒ вызывается в случае успешной обработки сообщенияmessaging:nack(Tack)‒ вызывается во всех нештатных ситуациях. После возврата задачи messaging передаст ее на другой обработчик.
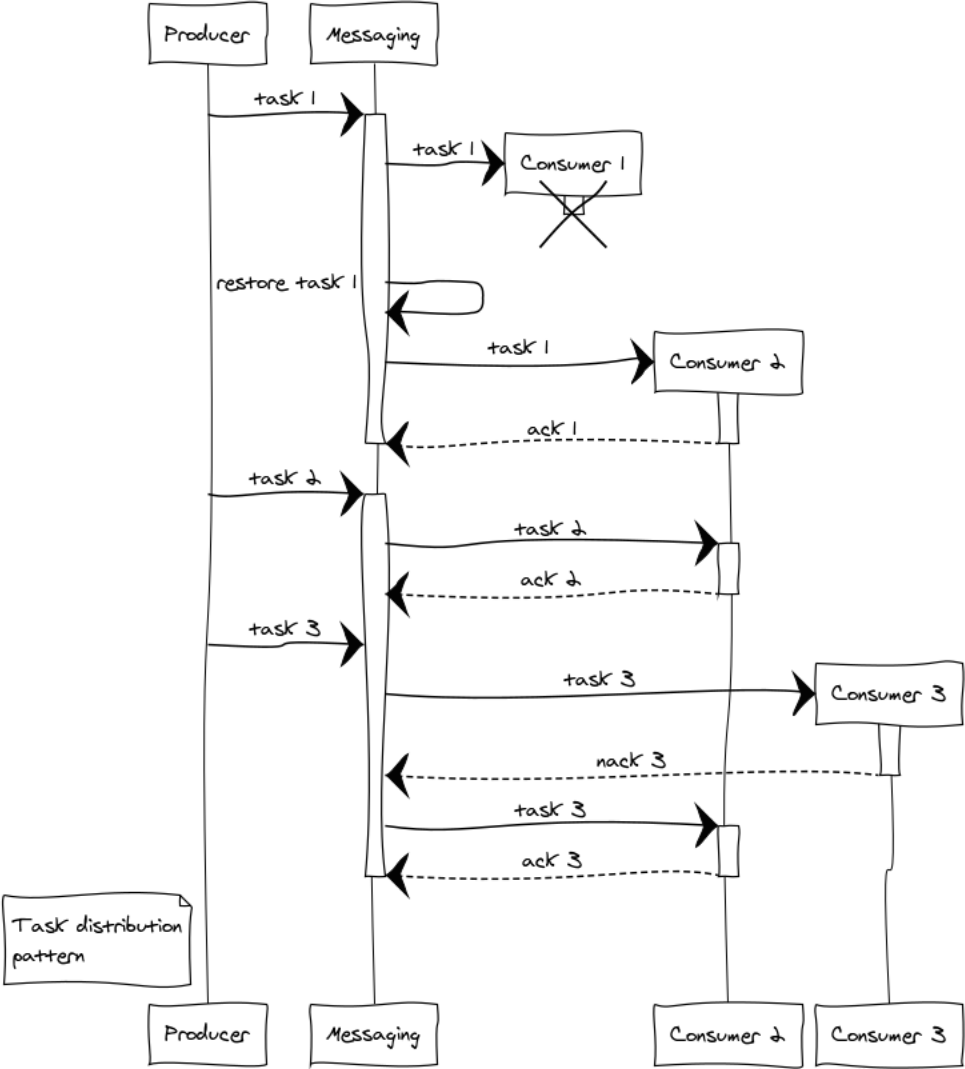
Предположим, при обработке трех задач случился сложный отказ: обработчик 1 после получения задачи упал, не успев сообщить что-либо точке обмена. В этом случае точка обмена после истечения ack timeout передаст задание другому обработчику. Обработчик 3 по какой-то причине отказался от задачи и отправил nack, в итоге задача тоже перешла другому обработчику который ее успешно выполнил.
Предварительный итог
Мы разобрали основные кирпичики распределенных систем и получили базовое понимание их применения в Erlang/Elixir.
Комбинируя базовые шаблоны, можно выстраивать сложные парадигмы для решения возникающих задач.
В заключительной части цикла мы рассмотрим общие вопросы организации сервисов, маршрутизации и балансировки, а также поговорим о практической стороне масштабируемости и отказоустойчивости систем.
Конец второй части.
Фото Marius Christensen
Иллюстрации подготовлены с помощью websequencediagrams.com
