Строим распредёленное реактивное приложение и решаем задачи согласованности

Сегодня многие компании, начиная новый проект или улучшая существующие системы, задаются вопросом, какой вариант разработки более оправдан — воспользоваться «классическим» трехслойным подходом или же спроектировать систему как набор слабосвязанных компонентов?
В первом кейсе мы можем оптимально использовать весь накопленный опыт и существующую инфраструктуру, но придется терпеть долгие циклы планирований и релизов, сложности в тестировании и в обеспечении бесперебойной работы. Во втором же случае появляются риски в управлении инфраструктурой и самим распределенным приложением.
В этой статье я расскажу, как и почему мы в 2ГИС выбрали второй вариант для построения новой системы, как решали возникающие задачи и какие выгоды от этого получили. Под катом — про Amazon S3, Apache Kafka, Reactive Extensions (Rx), eventual consistency и GitHub, сжатые сроки и невозможность собрать команду необходимого размера из инженеров, использующих один стек технологий.
Что такое Advertising Management System и зачем нам реклама?
2ГИС получает прибыль от продажи рекламных возможностей компаниям, которые хотят быть более заметными для пользователей продуктов 2ГИС. В продажах рекламы есть две составляющие — это сам процесс продаж и управление рекламным контентом. В этой статье мы сосредоточимся на второй составляющей и рассмотрим некоторые детали системы под названием Advertising Management System (AMS) — приложения для управления рекламными материалами в 2ГИС.
В далёком 2011 году в 2ГИС была запущена система продаж, открывшая новые возможности для увеличения объёма и эффективности продаж рекламы. На тот момент видов рекламного контента было не так много, поэтому модуль управления рекламными материалами был частью системы продаж. С течением времени требования к модулю возрастали: появились новые типы контента, запустился процесс модерации, потребовался более прозрачный аудит изменений.
Всё это привело к тому, что в конце 2016-го был запущен новый проект по выделению модуля управления рекламным контентом в отдельную систему — AMS, где можно было бы изначально решить все текущие потребности и заложить необходимый фундамент для развития.
Основное назначение AMS — обеспечить автоматизацию процессов создания, модерации и выпуска рекламы в продукты 2ГИС. Пользователи системы — менеджеры по продажам 2ГИС, сами рекламодатели, а также модераторы 2ГИС. AMS работает во всех странах присутствия 2ГИС и локализована на несколько языков, основные из которых — русский и английский. Чтобы понять, как работает AMS, давайте рассмотрим основные этапы работы с рекламным материалом.
Представим себе, что некая фирма решила увеличить число заказов. Привлечь внимание пользователей можно, например, разместив логотип компании и короткий комментарий в поисковой выдаче, и выбрав фирменный цвет фона и добавив кнопку call-to-action в карточке. Все это делает сам рекламодатель или закрепленный за ним менеджер по продажам. Дальше рекламный материал отправляется на модерацию, и после проверки модератора доставляется во все продукты 2ГИС.
Основная отличительная особенность системы — все данные в ней версионируемы. Это означает, что любое изменение рекламного контента, будь то текст или бинарные данные, ведёт к тому, что создаётся новая версия рекламного материала «рядом» с предыдущей версией. Это позволяет всегда иметь полную информацию — кто, когда и какие именно изменения вносил. Это очень важно с точки зрения законодательства. Для решения этой задачи было решено хранить данные, из которых состоит рекламный материал, в Amazon S3-совместимом хранилище, предоставляющем версионирование «из коробки».
Тем не менее, чтобы эффективно спроектировать систему, необходимо иметь чёткий и понятный API уровня хранения данных, работающий в терминах нашей конкретной предметной области. Так появился внутренний Storage API, адаптирующий CRUD API S3- хранилища в API хранения рекламных материалов, то есть объектов строго определенной структуры. У этого Storage API есть собственное название — VStore (Versioned Storage), и его разработка ведется открыто на GitHub.
Изначально VStore задумывался как довольно простой REST-сервис, однако в процессе разработки стало очевидно, что на этом уровне также нужно решать некоторые другие задачи. Например, перекодирование и раздача бинарного контента или удаление неиспользованных данных («очистка мусора»). Но об этом чуть позже.
S3 отлично позволяет хранить данные, но не даёт возможности выполнять эффективные поисковые запросы. Поэтому в проекте появилась также привычная SQL-база данных, где лежат метаданные о рекламных материалах для поисковых сценариев, а также данные, необходимые для реализации полноценных бизнес-кейсов.
В начале работы над проектом нам нужно было решить еще одну проблему — на тот момент у нас не было возможности собрать команду необходимого размера из инженеров, использующих один стек технологий. А сроки, как всегда, были довольно сжатыми.
Поэтому команду мы собрали из разных «миров», а система была спроектирована как набор изолированных модулей, которые можно было бы писать, используя разные языки программирования, и запускать в Docker-контейнерах. Нам очень повезло, что в это же время в 2ГИС стал активно эксплуатироваться Kubernetes. Так мы встали на путь микросервисов.
Инфраструктура AMS
На текущий момент AMS состоит из четырёх крупных модулей:
- VStore решает вопросы версионированного хранения объектов строго определённой структуры и полностью абстрагирует S3-хранилище, максимально эффективно взаимодействуя с ним. На этом уровне выполняется контроль контента рекламных материалов на соответствие сконфигурированным правилам (количество символов в тексте, размер и формат растровых изображений, валидация векторной графики и много чего ещё). Вся раздача контента — ответственность VStore.
- AMS API по сути и есть бекенд всей системы. AMS API использует VStore для выполнения кейсов, требующих создания или редактирования рекламных материалов, включая работу с бинарными данными. Всю метаинформацию о рекламных материалах AMS API хранит в реляционной БД. Фронтенд AMS, а также другие системы компании, взаимодействуют с AMS API.
- Фронтэнд AMS — UI-приложение для выполнения всех пользовательских кейсов с рекламными материалами. Именно этим приложением пользуются в своей работе менеджеры по продажам 2ГИС и рекламодатели.
- Админка AMS нужна для того, чтобы настраивать те самые правила и ограничения на контент рекламных материалов в зависимости от типа и языка публикации. Эти правила продиктованы продуктами 2ГИС, где и будет отображена реклама.
Эти модули реализуются независимо на разных языках в изолированных репозиториях. Все контракты взаимодействия тщательно согласуются, поэтому разработка движется параллельно и эффективно. Каждый из этих модулей запускается как один или несколько Docker-контейнеров, поднимаемых на Kubernetes.
Вообще, Kubernetes — это одна из частей общей платформы 2ГИС, на которой работают многие сервисы компании. Эта платформа также включает в себя унифицированную инфраструктуру логирования, построенную на ELK, а также все возможности мониторинга сервисов с помощью Prometheus. Для простого и удобного билда и деплоя любых приложений в компании используется внутренний специально настроенный GitLab. Зачем и как всё это создавалось, читайте в этой статье.
Процесс сборки всех компонентов AMS и их развёртывания во всех дата-центрах 2ГИС также автоматизирован. Модули имеют свои внутренние релизные циклы и версии, которые согласуются с версиями остальных компонентов. Всё это позволяет за минуты поднять изолированный тестовый стенд для проверки изменений в любой части системы или развернуть приложения на стейджинге или в продакшне. Подробнее узнать о том, как это устроено, можно, посмотрев запись доклада с DevDay.
Ближе к делу
Микросервисы и слабая связанность — это, конечно, хорошо: изоляция, параллельная разработка на нескольких языках, простота в управлении изменениями. Однако, такой способ композиции приложения требует решения ряда архитектурных задач. И первая из них — коммуникация между компонентами.
Передавать данные можно двумя способами — синхронно и асинхронно. В первом случае мы отправляем запрос на определенный эндпоинт. Запросы заблокированы до тех пор, пока не придёт ответ, либо не закончится время ожидания. Этот способ позволяет реализовать кейсы, где требуется подтверждение действия и результата исполнения операции. Второй способ — это отправка и получение сообщений, то есть реализация паттерна producer/consumer.
В реальности приходится использовать оба эти способа совместно. Так, для синхронных кейсов мы используем HTTP-протокол и REST-сервисы, а вся передача сообщений построена на Apache Kafka.
Рассмотрим базовый кейс AMS — создание рекламного материала. Напомню, что рекламный материал может состоять из набора разных элементов, контент которых либо текстовый, либо бинарный. Поэтому, чтобы создать рекламный материал, нужно:
- Определить тип и количество элементов.
- Если есть элементы с бинарным контентом, нужно создать ограниченную по времени сессию для загрузки бинарных файлов.
- Передать на клиентскую часть прототип рекламного материала, чтобы отрисовать UI.
- При загрузке бинарного контента необходимо его проверить (тип и размер картинки, наличие альфа-канала) и вернуть на клиента ссылку; в случае, если проверки не прошли, удалить загруженный файл.
- Если все обязательные значения заполнены и новый рекламный материал отправлен на сервер, нужно проверить все текстовые значения (гипертекст, количество символов всего и в каждом слове, количество слов и прочее).
- Если все проверки прошли, нужно создать рекламный материал в версионированном хранилище с помощью VStore и сохранить метаинформацию (название, привязку к фирме, статус модерации) в реляционной БД.
Что здесь может пойти не так? В случае распредёленного приложения — очень многое.
Если какой-либо из REST-сервисов недоступен, то в силу синхронности самого кейса рекламный материал не будет создан. Но всё же есть нюанс.
Представим себе ситуацию, когда AMS API создаёт объект через VStore, отправляя POST-запрос. VStore удачно его обрабатывает, отправляя ответ. Несмотря на все успехи, существует вероятность того, что этот ответ не дойдет до AMS API, например, из-за «мигания» сети. Что тогда? Тогда AMS API посчитает, что объект не создан и скажет об этом пользователю (для упрощения будем считать, что нет никаких retry-циклов). Но при попытке ещё раз создать этот объект мы либо создадим дубль (если сгенерируем новый идентификатор), либо не сможем закончить создание, так как объект уже существует. В обоих случаях получим рассогласование хранилищ.
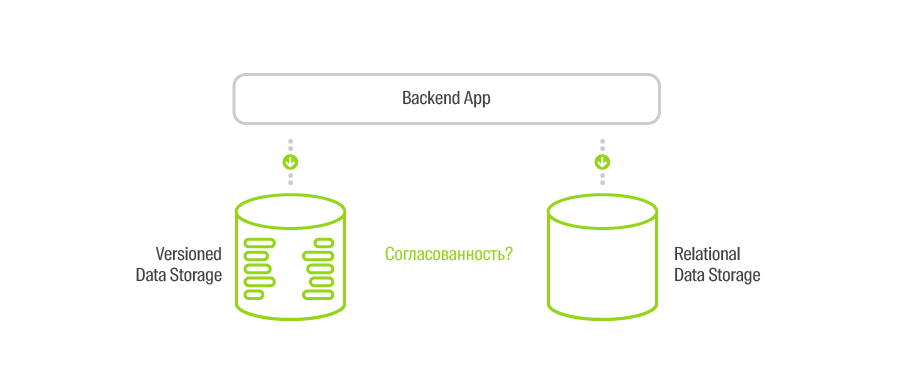
Ещё один хитрый кейс
Прежде чем перейти к описанию решения, взглянем на ещё один момент.
Допустим, мы создаём рекламный материал. Подготовили сессию для загрузки бинарного контента и позволяем пользователю загрузить картинку. Предварительно всё проверив, мы загружаем её в хранилище и возвращаем некий ключ (ссылку).
Но что, если пользователю не понравилось, как выглядит загруженная картинка, и он загрузил другую (или третью, четвертую)? На самом деле, в состав рекламного материала войдет только последняя загруженная картинка, а все остальные не будут использованы вообще.
А что, если после всех манипуляций пользователь решил вообще не создавать рекламный материал и ушёл? Весь загруженный бинарный контент стал мусором, который нужно удалить.
Как это сделать гарантированно и эффективно?
Серебряная пуля
В этой статье я пару раз пользовался термином «микросервисы», и это могло вызвать резонное негодование у любителей поспорить о терминологии. Ведь, действительно, о микросервисах часто говорят как о наборе совершенно независимых небольших приложений, каждое из которых имеет свой контракт взаимодействия, модель предментной области и собственное хранилище данных. В нашем же случае, все бекенд-сервисы пользуются общими хранилищами.
Так или иначе, я придерживаюсь мнения, что термин «микросервисы» можно использовать и в этом случае, а наличие одной модели предметной области логично ведёт к использованию общих хранилищ. Так, имея одну core domain model, мы можем переиспользовать её в разных компонентах, а, значит, можем и переиспользовать логику сохранения и чтения данных. Это вполне рационально, так как изменения в базовой доменной модели неминуемо повлияют на бизнес-логику всех частей приложения. Главное здесь — правильно определить границы и ответственности приложения, и корректно выделить core domain model.
Но давайте посмотрим, как мы можем решать большую часть задач по согласованию данных, основываясь на двух имеющихся у нас инструментах — версионированном хранилище (S3) и инфраструктуре передачи сообщений (Apache Kafka).
Если взглянуть чуть пошире, то можно увидеть, что версионирование данных — одна из реализаций свойства неизменяемости (immutable). Имея это свойство и гарантию порядка версий/сообщений, мы всегда можем построить систему, данные в которой будут согласованы в конечном итоге (eventual consistency).
Давайте немного изменим реализацию кейса создания рекламного материала, добавив немного сайд-эффектов (изменения выделены жирным):
- Определить тип и количество элементов.
- Если есть элементы с бинарным контентом, нужно отправить сообщение о попытке создания сессии и создать ограниченную по времени сессию для загрузки бинарных файлов.
- Передать на клиентскую часть прототип рекламного материала, чтобы отрисовать UI.
- При загрузке бинарного контента, необходимо его проверить (тип и размер картинки, наличие альфа-канала и прочее), отправить сообщение, что файл с конкретным ключом был загружен, и вернуть на клиента ссылку; в случае, если проверки на прошли, удалить загруженный файл и не отправлять сообщение.
- Если все обязательные значения заполнены и новый рекламный материал отправлен на сервер, нужно проверить все текстовые значения (гипертекст, количество символов всего и в каждом слове, количество слов и прочее).
- Если все проверки прошли, нужно отправить сообщение о попытке создания объекта с заданным ключом, создать рекламный материал в версионированном хранилище с помощью VStore и сохранить метаинформацию (название, привязку к фирме, статус модерации) в реляционной БД.
Таким образом, вместе с изменениями в данных мы ещё отправляем события в порядке их возникновения. Это всё, что нужно, чтобы реализовать огромное количество сценариев. Причём их реализация может быть совершенно независимой друг от друга с помощью всё тех же микросервисов, запускаемых в качестве отдельных фоновых процессов.
Теперь задача согласованности данных в хранилищах решается сравнительно легко: фоновый процесс получает события о попытках создания объекта, выясняет, удалось ли создать объект, и проверяет его наличие в SQL-хранилище. Если в синхронном кейсе, описанном выше, всё же случился сбой, он будет устранен асинхронно. Интервал времени, во время которого система будет рассогласованной, будет тем ниже, чем эффективнее мы работаем с Apache Kafka. И вот тут очень пригождается реактивный подход.
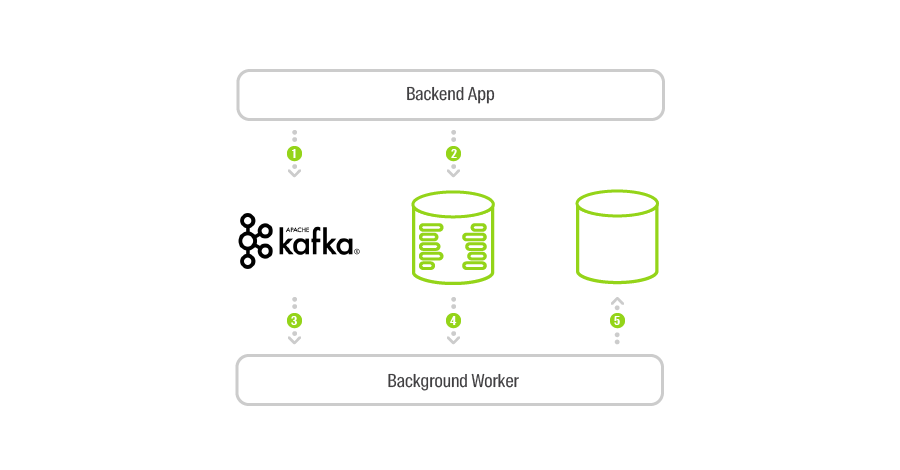
Давайте теперь посмотрим, как, имея те же сообщения в Kafka, можно эффективно реализовать очистку неиспользуемых бинарных файлов. Всё просто.
Создав ещё один фоновый микросервис, мы можем двигаться по очереди сообщений о фактах создания сессии. Как только сессия закончилась, и, следовательно, новые файлы загрузить нельзя, нам необходимо узнать, были ли в период активности сессии созданы или изменены объекты, которые ссылались на файлы из этой сессии. Kafka предоставляет API для работы с временными интервалами (так как у каждого сообщения в Kafka есть timestamp), поэтому сделать это несложно. Если мы выясним, что ни на один из файлов не было ссылок, мы можем удалять всю сессию со всеми файлами. Иначе мы удалим только неиспользованные файлы.

Имея описанную архитектуру приложения, довольно просто реализовывать совершенно различные сценарии — от отправки нотификаций пользователям до построения сложных аналитических моделей на основе событий, происходивших в системе. Всё, что для этого нужно — запустить ещё один фоновый процесс. Или отключить его в случае ненадобности.
Реактивный подход
Что это такое и как эта парадигма можем помочь нам эффективно работать с Apache Kafka? Давайте разбираться. Чтобы понять основную идею, приведу цитату из The Reactive Manifesto (перевод):
«Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving users effective interactive feedback.»
В контексте стоящей перед нами задачи особый акцент стоит сделать на словах «highly responsive» и «effective interactive feedback». Основной смысл в том, что применение реактивного подхода позволит нам построить систему так, чтобы получать мгновенный отклик и иметь минимально низкие задержки при получении и обработке сообщений.
Есть несколько инструментов, которые помогают реализовывать системы с применением «реактивщины». Мы использовали Reactive Extensions в имплементации для .NET. В центре этой библиотеки лежит понятие observable-последовательности, то есть коллекции, которая нотифицирует подписчиков о появлении новых элементов. Имея такую коллекцию, Rx.NET позволяет строить конвейер обработки сообщений, применяя всевозможные операции, самые простые из которых — фильтрация, проекция, группировка, буферизация и прочие.
Как подружить Kafka и Rx? Очень легко. API клиентской библиотеки для работы с Kafka требует от клиента задания функции, которая будет вызвана при появления нового сообщения (в .NET это подписка на событие) и цикличного вызова метода Poll. Rx.NET имеет специальный метод Observable.FromEventPattern для перехода от API такого типа к Observable. Вот здесь можно посмотреть реальный продакшн-код.
Таким образом, применение Rx.NET позволяет очень органично интегрировать Apache Kafka и наше приложение, получив при этом высокую эффективность, низкие задержки и очень простой и хорошо читаемый код.
Заключение
Распределённые приложения — это непросто. Если бы у нас не было причин делать AMS многокомпонентным, возможно, мы снова пошли бы по пути «классических» архитектур.
Напомню, что для построения решения нам требовалось:
- Поддержать эффективное версионирование любых данных.
- Вести разработку на разных технологических стеках и при этом иметь хорошее взаимопонимание внутри команды.
- Иметь очень короткие релизные циклы и выкатывать изменения в продакшн несколько раз в день.
- Обеспечить простоту тестирования за счёт относительной простоты и изолированности отдельных сервисов.
- Спроектировать приложение так, чтобы обеспечить отказоустойчивость и простоту масштабирования.
Кроме того, на момент старта проекта мы располагали:
- Платформой для работы приложений на основе Kubernetes.
- Грамотно настроенным и находящимся в поддержке кластером Apache Kafka.
- Значительным опытом разработки бекендов, что позволяло управлять технологическими рисками.
На текущий момент у нас 50–70 http-запросов в секунду (RPS), число сообщений, пересылаемых по Kafka, в секунду измеряется сотнями. Эту нагрузку обеспечивают в основном внутренние пользователи — сотрудники 2ГИС. Но приложение, спроектированное таким образом, даёт нам возможность увеличивать объём продаж через личный кабинет рекламодателя и быть готовыми к росту продаж в любых странах присутствия 2ГИС. Благодаря микросервисному подходу мы можем сравнительно просто реализовывать новые фичи и управлять стабильностью приложения.
Некоторые технические подробности работы VStore можно узнать из видеозаписи доклада на techno.2gis.ru.
Код VStore открыт и активно развивается на GitHub. Смотрите, комментируйте, задавайте вопросы.
