Стратификация, или как научиться доверять данным
Посмотрите на эти два набора точек и подумайте: какой из них вам кажется более «случайным»? Распределение на левом рисунке явно неравномерно. Есть места, в которых точки сгущаются, а есть и такие, в которых точек почти нет: из-за этого даже может показаться, что левый график более тёмный. На правом рисунке локальные сгущения и разрежения тоже присутствуют, но меньше бросаются в глаза.
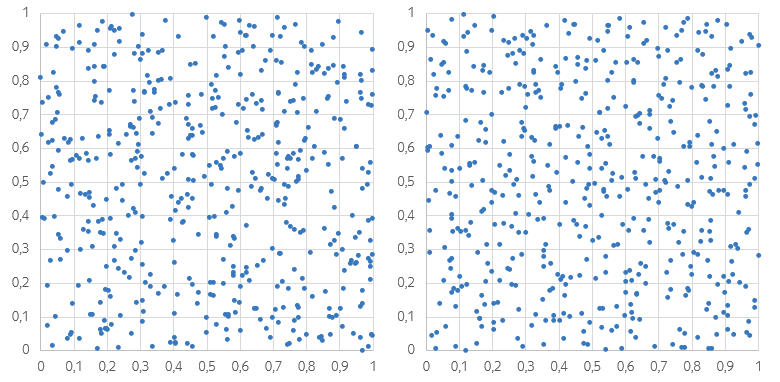
Меж тем, именно левый график получен при помощи «честного» генератора случайных чисел. Правый график тоже содержит сплошь случайные точки;, но эти точки сгенерированы так, чтобы все маленькие квадраты содержали равное количество точек.
Стратификация — метод выбора подмножества объектов из генеральной совокупности, разбитой на подмножества (страты). При стратификации объекты выбираются таким образом, чтобы итоговая выборка сохраняла соотношения размеров страт (либо контролируемо нарушала эти соотношения, см. пункт 3). Скажем, в рассмотренном примере генеральная совокупность — точки внутри единичного квадрата; стратами являются наборы точек внутри квадратов меньшего размера.
Стратификацию разумно применять при любом семплинге. Скажем, в социологических исследованиях необходимо соблюдать стратификацию как минимум по возрасту и месту проживания респондентов. В машинном обучении стратификация бывает полезна как на этапе сбора данных, так в процессе кросс-валидации .
1. Простой пример: вычисление площади фигуры

Для начала, чтобы продемонстрировать мощь стратификации, я использую сгенерированные во введении наборы точек для вычисления площади закрашенной фигуры — четверти круга с радиусом, равным 0.4. Случайные точки будут бросаться внутрь единичного квадрата и увеличивать счётчик при попадании внутрь круга. Отношение полученного числа к общему числу бросков будет оценкой площади фигуры по методу Монте-Карло.

Простейший (нестратифицированный) способ генерации случайных точек для этой задачи можно реализовать так:
import random
random.seed(100)
for i in range(500):
x, y = random.random(), random.random()
print x, yСтратификацию можно реализовать разными способами, я выбрал следующий: все маленькие квадратики пронумерованы, и при генерации очередная точка попадает в квадратик со следующим номером; номера зациклены. Этот метод работает хорошо только если общее число точек кратно числу страт, но, к счастью, в данном случае так и есть.
import random
random.seed(100)
cellsCount = 10
cellId = 0
for i in range(500):
cellVerticalIdx = (cellId / cellsCount) % cellsCount
cellHorizontalIdx = cellId % cellsCount
cellId += 1
left = float(cellVerticalIdx + 0) / cellsCount
right = float(cellVerticalIdx + 1) / cellsCount
top = float(cellHorizontalIdx + 1) / cellsCount
bottom = float(cellHorizontalIdx + 0) / cellsCount
x, y = random.random(), random.random()
x = left + x * (right - left)
y = bottom + y * (top - bottom)
print x, yТеперь будем генерировать наборы точек многократно и проследим за невязкой — величиной отклонения полученной оценки площади от истинного значения. Код для простого алгоритма находится здесь, а для стратифицированного — здесь.

Видно, что оценка, полученная стратифицированным методом, выигрывает по точности и имеет меньшую дисперсию.
В этот момент вы можете возразить, что нужно было просто взять регулярную сетку и таким образом сделать дисперсию равной нулю. Однако такая оценка не была бы несмещённой! К тому же рассматриваемая задача является модельной, а на множестве людей или, скажем, поисковых запросов никакой регулярной сеткой воспользоваться не удастся.
2. Кросс-валидация
Следующие примеры относится к области машинного обучения.
Ситуация первая: в задаче существуют объективные зависимости, которые нужно учитывать для адекватной оценки качества моделей. Например, в задачах кластеризации функция близости двух объектов может зависеть от размера кластера, и нужно добиваться равномерного распределения размеров кластеров между обучающими и тестовыми выборками. Если этого не делать, оценки качества будут заниженными.
Ситуация вторая: нестационарный характер восстанавливаемых зависимостей, т.е. их изменчивость во времени. Так, предсказание посещаемости торговых центров существенно зависит от того, является ли выбранный день выходным. Для получения адекватных оценок обобщающей способности все дни в обучающей выборке должны предшествовать дням, входящим в тестовую выборку. Если этого не делать, оценки качества будут завышены, как правило — чрезвычайно сильно.
Продемонстрирую стратификацию на модельной задаче первого типа. Рассмотрим такую зависимость:
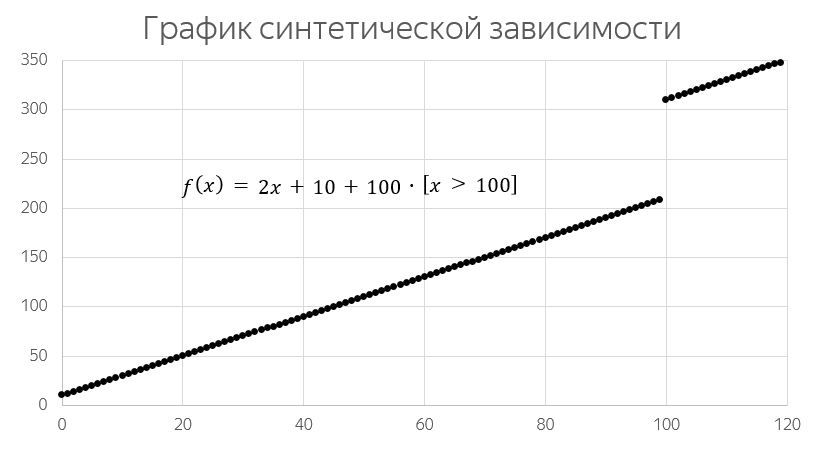
Пусть эта зависимость приближается одномерной линейной моделью. Лишь небольшая часть примеров отклоняется от простого линейного приближения, и именно эти примеры будут давать основной вклад в величину ошибки модели. По существу, чем больше таких «выбросов» попадёт в тестовую выборку, тем меньше их окажется в обучающей выборке, тем выше будет ошибка на тестовой выборке. Можно даже сказать, что измерению всякий раз подвергается не метод обучения, а степень равномерности распределения выбросов между обучающей и тестовой выборками!
Генерацию выборки, обучение одномерной линейной модели, многократный процесс кросс-валидации, в т.ч. стратифицированной, а также построение вариационных рядов я реализовал вот так. Не буду сейчас вдаваться в детали реализации (тем более что она не слишком аккуратна), а сразу приведу графики вариационных рядов полученных оценок:

Действительно, без стратификации оценки имеют большую дисперсию и, кроме того, занижены. Нужно, однако, понимать, что стратифицированная оценка будет корректной только в том случае, если доля выбросов в выборке репрезентативна доле выбросов в генеральной совокупности.
3. Немного математики
Методы стратификации часто используются в онлайн-экспериментах, это достаточно естественно для веб-сервисов: поведение пользователей зависит от характеристик устройств, операционных систем, версий браузеров, характеристик самих пользователей и так далее. Поэтому без стратификации в A/B-тестах легко столкнуться с тем, что, скажем, доля мобильных пользователей в разбиениях различается на 0.5% и интегральные метрики измеряют эффект от этого перекоса, а не от вносимого изменения.
Стратифицированный подход в данном случае предписывает разбивать наблюдения на страты (по версиям устройств, ОС, браузеров и т.д.), вычислять метрики внутри страт, взвешивать их сообразно размерам этих страт и таким образом получать значения интегральных показателей.
Классической работой в этой области является статья Online Stratified Sampling: Evaluating Classifiers at Web-Scale от Microsoft Research, которую я решительно рекомендую к прочтению.
В общем случае будем считать, что дана генеральная совокупность размера  , из которой выбираются без повторений
, из которой выбираются без повторений  представителей для оценки вероятности
представителей для оценки вероятности  принадлежности элемента совокупности некоторому классу
принадлежности элемента совокупности некоторому классу  .
.
Генеральная совокупность разбита на  непересекающихся подмножеств — страт. Внутри
непересекающихся подмножеств — страт. Внутри  -й страты размера
-й страты размера  возможно вычислить оценку
возможно вычислить оценку  вероятности принадлежности элемента страты классу . Тогда стратифицированная оценка вероятности будет вычисляться как
вероятности принадлежности элемента страты классу . Тогда стратифицированная оценка вероятности будет вычисляться как

Дисперсия этой величины благодаря независимости выборов внутри каждой из страт вычисляется просто:

Интересно, что для минимизации дисперсии требуется семплить из страт непропорционально их размерам!
Если выбираются объектов из генеральной совокупности, количество  объектов из -й страты для минимизации дисперсии оказывается пропорциональным произведению размера страты на стандартное отклонение величины внутри этой страты:
объектов из -й страты для минимизации дисперсии оказывается пропорциональным произведению размера страты на стандартное отклонение величины внутри этой страты:

Единственная сложность здесь в том, что для осуществления оптимального семплинга нужно заранее знать дисперсии внутри страт. Впрочем, на практике они часто известны с достаточной точностью.
Теперь понятно, что делать с систематическими смещениями в данных: их можно нивелировать стратификацией и последующим перевзвешиванием. Например, если в данных существенно смещены социально-демографические показатели, можно стратифицировать именно по ним, а веса страт взять из соответствующей официальной статистики.
Заключение и прагматика

При работе с данными, так же как и при социологических исследованиях, потребность в качественной стратификации может быть чрезвычайной. При анализе логов веб-панелей типа SimilarWeb или Alexa можно получить некорректные результаты из-за нерепрезентативности множества пользователей, поставивших себе расширение. Клиентские части сервисов теряют часть информации при логировании, причём чаще для пользователей со слабыми сетевыми соединениями. Подобного рода ошибки могут портить аналитику и, в конечном счёте, приводить к неверным решениям в развитии продуктов и бизнеса.
Всякий раз при обработке очередного набора данных полезно спросить себя: репрезентативен ли он? Не нужно ли его дополнительно стратифицировать и перевзвесить? Что известно о его происхождении и возможных искажениях?
Если ответов нет или они неудовлетворительны — очень может быть, что данные вас обманут.
