Страх и ненависть и пагинация
А в чем проблема?

Как бы нам не хотелось этого отрицать, практика показывает, что подавляющее большинство своего времени типичный iOS-разработчик проводит за работой с табличками. Проектирование сервисного слоя — это интригующе, разработка универсального роутинга в приложении — захватывающе, а от настройки гибких политик кэширования вообще крышу сносит, но работа с табличными интерфейсами — это наши серые будни. Иногда луч света все же попадает и в эту область, и вместо очередной возни с constraint’ами перед нами может встать задача реализации постраничной загрузки — или, как это модно называть в мобильных приложениях, infinite scroll’а.
Грузить сразу все новости, объявления, списки фильмов с удаленного ресурса как минимум не эффективно, поэтому в большинстве случаев сервер предоставляет клиентам различные механизмы разбития всего объема данных на части ограниченного размера.
Как говорится, so far so good. Мы загружаем первую партию данных, отображаем их в таблице, прокручиваем её до конца, загружаем следующую партию — и так до бесконечности. К сожалению — ну или к счастью, мы же любим вызов — на этом все только начинается.
В зависимости от сложности проекта и степени костыльности API, достаточно простая задача рискует переродиться в Нечто. Нечто именно с большой буквы, потому что это создание в итоге обретает свою собственную жизнь и начинает рушить судьбы всех, кто его коснется. Ближе к делу — приведу пример из реальной жизни, случившийся, тем не менее, в совсем абстрактном проекте.
Условия, с которыми нужно было работать:
- любой из загруженных элементов может быть изменен с течением времени;
- на стороне клиента нужно уметь прятать посты авторов из черного списка — учитывая, что сервер продолжает их возвращать;
- несмотря на локальную фильтрацию, при запросе следующей страницы пользователь должен получить не меньше 20 новых элементов;
- выдача целиком пересобирается раз в час — некоторые посты добавляются, некоторые — исчезают, и обязательно меняются все позиции в списке;
- обращение к серверу идет не напрямую, а через CDN, что влечет за собой интересные артефакты;
- единственный механизм постраничной загрузки, который может предложить сервер — это limit/offset.
Плохие новости — сделать в подобных случаях все правильно сложно. Хорошие новости — у меня в запасе есть целый структурированный арсенал костылей, который помогает справиться с большинством возникающих вопросов и проблем.
Декомпозиция
Сколь угодно сложная проблема или задача становится решаемой, если разбить её на ограниченное количество шагов. Наш случай не исключение. Чтобы понять принцип работы всей системы постраничной загрузки в вашем приложении достаточно декомпозировать её на несколько секций:
- Правила изменения количества элементов в выдаче:
- Лента статична. Пример: Список заведений в редакционной подборке. Будучи один раз составленным, он уже не меняется.
- Новые элементы добавляются строго сверху. Пример: История просмотра страниц приложения. В самом простом виде единственное её изменение — это добавление в начало списка новых просмотров страниц.
- Любая часть выдачи может быть изменена. Пример: Список писем в почтовом клиенте. Пользователь может удалять, перемещать и получать новые письма, поэтому список может быть изменен на любой позиции.
- Правила изменения актуальности выдачи:
- Выдача всегда остается актуальной. Пример: Все то же почтовое приложение. Элементы его могут меняться постепенно, нет строго детерминированной точки перехода из одного состояния в другое.
- Выдача может быть переформирована в неопределенный момент времени. Пример: Новостное приложение с интеллектуальным ранжированием. Раз в час выдача новостей пересобирается и наиболее актуальные материалы перебираются в самый верх списка.
- Правила обновления контента:
- Отображаемые данные не обновляются. Пример: Ячейки с названиями ресторанов. Смена названий настолько редка, что этой вероятностью можно смело пренебречь.
- Отображаемые данные могут быть изменены. Пример: Ячейки со счетчиком лайков. С течением времени этот счетчик меняется — и нужно уметь обновлять эти данные для уже закэшированных элементов.
Задача реализации постраничной загрузки чаще всего делится на две крупные части: подгрузка данных вниз и обновление ленты, обычно совершаемое при pull-to-refresh. К каждой из этих задач требуется свой подход, целиком зависящий от приведенной выше схемы.
Костыли
Этот раздел — ключевая часть всего материала. Я собрал все костыли, которые вынужденно использовал при реализации сложного механизма постраничной загрузки на limit/offset.
Небольшой ликбез. Limit/offset — это наиболее часто встречающийся подход к реализации постраничной загрузки данных. Offset — это сдвиг относительно первого элемента. Limit — количество загружаемых данных.Пример: пользователь хочет загрузить 10 новостей, начиная с двадцатой. offset: 10, limit: 20.
Подгрузка вниз / Лента изменяется
Если лента может быть изменена, не важно каким образом, то при попытке запросить следующую страницу мы можем столкнуться со сдвигом элементов вверх или вниз. Решение проблемы состоит из двух шагов. Первый относится к смещениям вниз. Представим ситуацию, при которой у нас уже загружена первая страница из пяти элементов. До следующего запроса структура данных на сервере изменилась и сверху выдачи добавились два новых элемента. Теперь при загрузке следующей страницы мы получим два элемента, которые у нас уже есть в кэше.
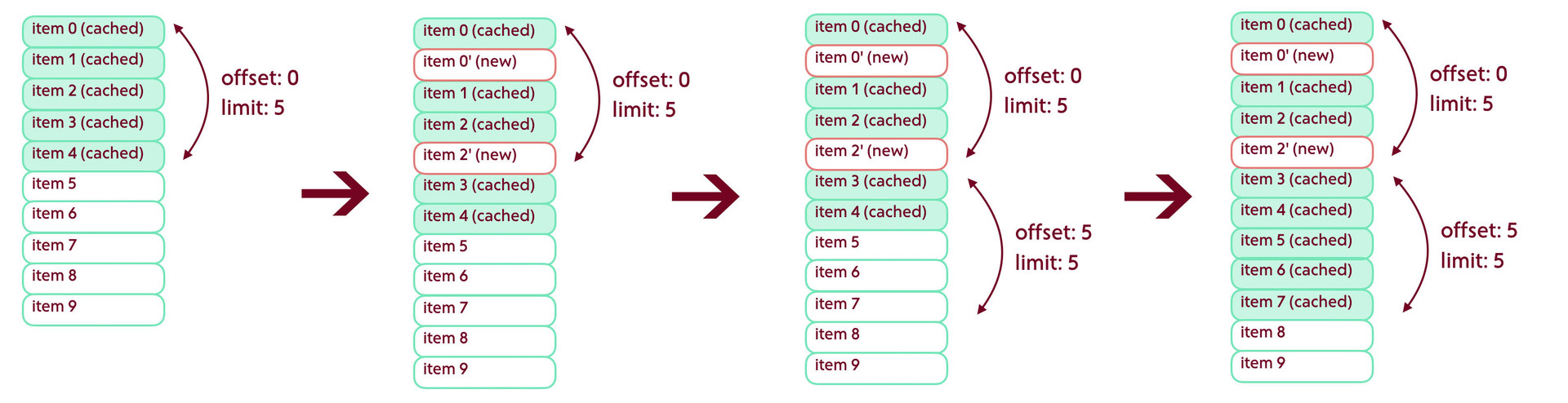
Ситуация может быть и хуже, если за время отсутствия синхронизации на сервер добавилось элементов больше, чем установлено в свойстве limit — тогда мы не получим ни одного нового элемента. Если в качестве offset’а мы будем использовать общее количество элементов в кэше, то застрянем в этой точке навсегда, так как продолжим запрашивать те элементы, которые уже были загружены.
Проблема решается достаточно просто. При получении очередной порции данных мы подсчитываем количество пересечений с закэшированным контентом — и в дальнейшем используем полученное значение как сдвиг offset’а. В приведенном выше примере этот сдвиг будет равен 2.
paging.startIndex = cachedPosts.count + intersections;
paging.count = 5;Подгрузка вниз / Любая часть выдачи может быть изменена
Рассмотрим следующую ситуацию: мы загрузили страницу, но затем первые два элемента были удалены. Запросив следующую порцию данных, получаем дырку в два элемента. Если ничего не предпринять, приложение об этом ничего не узнает — и данные никогда не загрузятся.
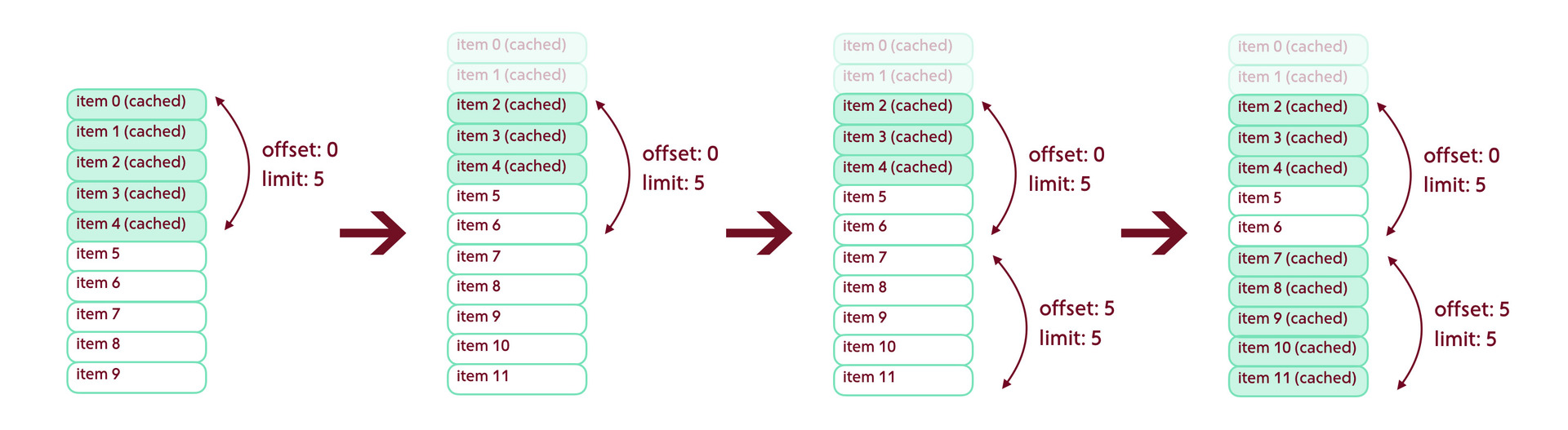
Выход из этой ситуации — всегда запрашивать данные с наложением в один элемент. Если при получении данных мы не найдем пересечений — можно либо отменить результат запроса, либо повторить его с другими параметрами.
paging.startIndex = startIndex - 1;
paging.count = 5;Небольшой лайфхак в копилку — если какие-то элементы в ленте потеряются, всегда можно сделать серьезное лицо и прочитать лекцию про интеллектуальное ранжирование данных, выполняемое на клиенте. Не поверят — покажите Facebook, у которых одна и та же выдача на каждом устройстве всегда выглядит абсолютно по-разному.
Подгрузка вниз / Выдача может быть реструктуризована в случайный момент времени
В таком случае самым простым вариантом реализации будет работа с так называемым слепком ленты. Под этим термином обычно понимают список идентификаторов всех записей выдачи. При первом открытии мы запрашиваем такой слепок и сохраняем его в базе, либо просто держим в памяти. Теперь для получения следующей страницы мы будем пользоваться не стандартным limit/offset, а более сложным запросом — просить сервер отдать посты по конкретным 20 идентификаторам.
NSRange pageRange = NSMakeRange = (startIndex, 20);
NSArray *postIds = [snapshot subarrayWithRange:pageRange];
[self makeRequestWithIds:postIds];Даже если выдача неожиданно будет реструктуризована, нам это не помешает — мы работаем с тем слепком, который был актуален на момент первого запроса — и для клиента лента будет отсортирована точно также, как в момент первого открытия.
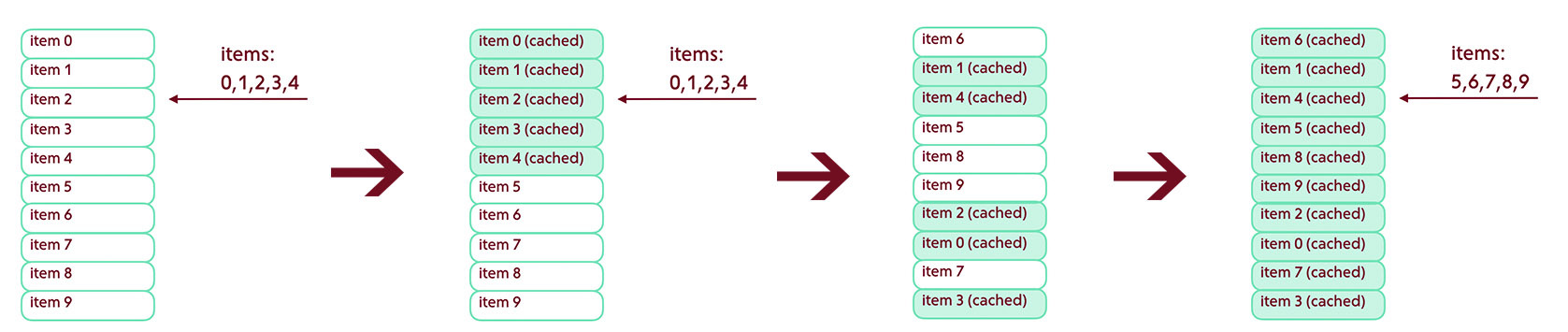
Обновление ленты / Элементы добавляются сверху
В этом случае нам в первую очередь необходимо уметь определять наличие дырок, образующихся в том случае, если со времени последней синхронизации было добавлено большое количество новых элементов.
Мы запрашиваем константное количество данных и проверяем наличие пересечений с данными из кэша. Если пересечения есть — все хорошо, можно продолжать работать в обычном режиме. Если пересечений нет — это значит, что мы пропустили несколько постов.

Что делать в этом случае — нужно решать для каждого конкретного приложения. Можно сбросить все данные, кроме запрошенных пяти элементов. Можно продолжать подгружать элементы сверху постранично, пока не будут обнаружены пересечения.
if (intersections == 0) {
[self dropCache];
}Обновление ленты / Любая часть выдачи может быть изменена
У проблемы есть два способа решения:
Сервер отдает diff«ы изменений в ленте, к примеру, основываясь на сохраненном Last-Modified последнего синхронизированного состояния выдачи. Параметр Last-Modified мы получаем из заголовков ответа сервера. Клиенту в таком случае останется просто применить эти изменения на состояние базы.
for (ShortPost *post in diff) { [self updateCacheWith:post]; }Если сервер так не умеет — приходится снова писать дополнительную сотню строк на клиенте. Нам нужно получить слепок постов (прямо как в одном из предыдущих пунктов) и сравнить его с текущим состоянием хранимых в кэше данных.
for (ShortPost *post in snapshot) { if (![cachedPosts containsObject:post]) { [self downloadPost:post]; } } for (Post *post in cachedPosts) { if (![snapshot containsObject:post]) { [self deletePost:post]; } }
Все отсутствующие в слепке элементы — удалить, все недостающие — загрузить.
Обновление ленты / Меняется сортировка
Если выдача была реструктуризована, мы должны об этом узнать. Проще всего это сделать, послав на сервер head-запрос и сравнив параметры etag или Last-Modified с сохраненными значениями.
NSString *lastModified = [self makeFeedHeadRequest];
if (![lastModified isEqual:cachedLastModified]) {
[self dropCache];
[self obtainPostSnapshot];
[self obtainFirstPage];
}Если результат сравнения отрицательный — состояние кэша сбрасывается, слепок id обновляется.
Обновление ленты / Элементы выдачи могут меняться
Если элементы списка содержат изменяющиеся со временем данные, вроде рейтинга или количества лайков — их нужно обновлять. Решение проблемы, в принципе, коррелирует с одним из предыдущих пунктов — мы работаем либо с diff«ом, возвращенным сервером, либо запрашиваем краткие структуры данных, содержащие только значимые поля. После этого вручную обновляем состояние элементов.
for (NSUInteger i = 0; i < cachedPosts.count; i++) {
Post *cachedPost = cachedPosts[i];
ShortPost *post = snapshot[i];
if (![cachedPost isEqual:post]) {
[cachedPost updatePostWithShortPost:post];
}
}Главное — максимально сократить количество передаваемых данных.
Советы на будущее
В завершении хочу дать несколько советов разной степени полезности.
Совет 1, очевидный
Бывает очень удобно иметь специальный объект, описывающий текущую выдачу. Назовите его списком, категорией, фидом — не важно.
@interface Feed: NSObject
@property (nonatomic, copy) NSArray *posts;
@property (nonatomic, copy) NSArray *snapshot;
@property (nonatomic, assign) NSUInteger offset;
@property (nonatomic, assign) NSUInteger maxCount;
@property (nonatomic, strong) NSDate *lastModified;
@end Он может содержать текущий offset, максимальное количество элементов ленты, дату Last-Modified, слепок id — все, что нужно для описания списка элементов.
Совет 2, архитектурный
Не стоит смешивать в одном месте запросы на получение данных и обработку результатов. Если пытаться сразу же отображать полученные от сервера данные, вы наверняка столкнетесь с рядом проблем и ограничений.
Отделяйте логику запроса данных от логики их получения, обработки и отображения.
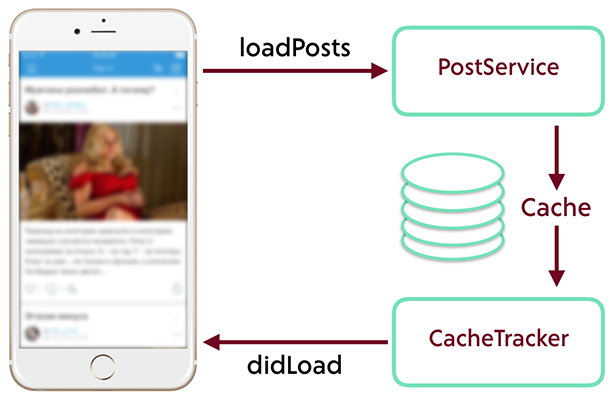
Абстрагируйтесь от сложностей и костылей, которые мы обсудили в этой статье. Наша главная цель — обеспечить постоянную синхронизацию состояния кэша и отображения. Если на экране отображается то же самое, что находится в базе данных — жизнь становится намного проще.
В этом, к примеру, может помочь NSFetchedResultsController, уведомления CoreData или схожие механизмы других ORM.
Совет 3, маскировочный
Инкапсулируйте всю логику обновления ленты и пагинации в отдельном объекте — фасаде над сервисами, занимающимися непосредственной загрузкой.
Именно в этом объекте находятся самые страшные вещи — вложенные блоки, сверка индексов и пересечений, логические ветвления. Для потребителей интерфейс фасада выглядит предельно простым и предоставляет основные методы для работы с постраничными данными — загрузка следующей страницы, обновление списка и полная его перезагрузка. Обратите особое внимание на то, что этот объект должен быть максимально хорошо протестирован.
Совет 4, самый главный
До последнего пытайтесь настоять на нормальной реализации постраничной загрузки на сервере. Limit/offset это, конечно, достаточно гибкое решение, однако клиент должен быть простым. Нет, правда, максимально простым!
Полезные ссылки
- Rambler.iOS #6: Pagination Demystified
- Paginating Real-Time Data with Cursor Based Pagination
- Twitter Docs: Pagination
- Facebook Graph API
Комментарии (2)
 vintage
vintage
22 июля 2016 в 10:58
+1↑
↓
Выдача списка != выдаче данных каждого его элемента. Можно сравнительно быстро выдать клиенту несколько тысяч идентификаторов, а потом уже грузить данные для них по мере необходимости. Если сервер такое не умеет, то надо допиливать сервер, а не вставлять костыли на клиенте.
- pull-to-refresh не нужен бесконечной ленте новостей. Контент внизу — должен быть всегда свежей подборкой непросмотренных новостей. Контент сверху — статичной историей просмотров. По мере скролла контент изымается из «подборки» и помещается в «историю». Такая реализация проще, надёжней и не выносит пользователю мозг.
 Novixon
Novixon
22 июля 2016 в 11:21
+1↑
↓
Я с Вами полностью согласен, что правильный сервер лучше неправильного клиента. Но в реальном мире приходится идти на компромиссы, например, чтобы выпустить продукт к срокам. Аналогичная ситуация может возникнуть, когда работаешь с каким-то очень старым API. Всё-таки полезно иметь представление о различных вариантах постраничной загрузки данных, за что и спасибо автору статьи.
