Сравнение аналитических in-memory баз данных

В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
Всё это время мы проводили масштабное тестирование нескольких in-memory СУБД. Любой разговор с администраторами DWH в это время можно было начать с фразы «Ну как, кто лидирует?», и не прогадать. В ответ люди получали длинную и очень эмоциональную тираду о сложностях тестирования, премудростях общения с доселе неизвестными вендорами и недостатках отдельных испытуемых.
Подробности, результаты и некое подобие выводов из тестирования — под катом.
Цель тестирования — присмотреть себе быструю аналитическую in-memory базу данных, отвечающую нашим требованиям, и оценить сложность её интеграции с остальными системами хранилища данных.
Также мы включили в тестирование две СУБД, не позиционирующиеся как in-memory решение. Мы рассчитывали на то, что имеющиеся в них механизмы кэширования, при условии примерного соответствия объёма данных объёму оперативной памяти серверов, позволят этим СУБД приблизиться в производительности к классическим in-memory решениям.
Описание кейса использования
Предполагается, что выбранная в результате тестирования СУБД будет работать в качестве front-end БД хранилища для выборочного набора данных (2–4 Тб, однако объём данных может расти со временем): принимать на себя запросы от BI-системы (SAP BusinessObjects) и часть ad-hoc запросов некоторых пользователей. Запросы, в 90% случаев, это SELECT’ы c от 1 до 10 join-ами по условиям равенства и, иногда, условиям вхождения дат в интервал.
Нам нужно, чтобы такие запросы работали значительно быстрее, чем они работают сейчас в основной БД хранилища — Greenplum.
Также важно, чтобы количество одновременно выполняемых запросов не сильно влияло на время выполнения каждого запроса — оно должно быть примерно постоянным.
На наш взгляд, целевая БД должна обладать следующей функциональностью:
- горизонтальная масштабируемость;
- возможность выполнять локальные join-ы — использовать «правильный» ключ распределения в таблицах
- поколоночное хранение данных;
- умение работать с кэшем и большим объёмом доступной памяти.
Загрузка данных в целевую систему предполагается из основной БД хранилища — Greenplum, а потому для нас также важно наличие способа быстро и надёжно доставить данные (желательно, инкрементально) из Greenplum в целевую БД.
Также важна возможность интеграции с SAP BO. К счастью, с этой системой хорошо работает почти всё, что имеет стабильный ODBC-драйвер для Windows.
Из мелких, но весомых требований можно выделить оконные функции, резервирование (способность хранить несколько копий данных на разных нодах), простота дальнейшего расширения кластера, параллельная загрузка данных.
Стенд для тестирования
На каждую БД было выделено два физических сервера:
- 16 физических ядер (32 с HT)
- 128 Гб ОП
- 3.9 Тб дискового пространтства (RAID 5 из 8 дисков)
- Сервера связаны 10 Гбит-ой сетью.
- ОС для каждой БД была выбрана исходя из рекомендаций по установке этой самой БД. То же касается настроек ОС, ядра и прочего.
Критерии тестирования
- Скорость выполнения тестовых запросов
- Возможность интеграции с SAP BO
- Наличие быстрого и подходящего способа импорта данных
- Наличие стабильного ODBC-драйвера
- В случае, если продукт не распространяется свободно, удалось в адекватное время связаться с представителями компании производителя и получить инсталляцию (дистрибутив) БД, необходимую для тестирования
БД, вошедшие в тестирование
Greenplum

Старый, добрый, хорошо знакомый нам Greenplum. Про него у нас есть отдельная статья.
Строго говоря, Greenplum не является in-memory БД, однако экспериментально доказано, что за счёт свойств XFS, на которой он хранит данные, при определённых условиях он ведёт себя как таковая.
Так, например, при чтении, если количество памяти достаточно, а также если данные, запрашиваемые запросом, уже лежат в памяти (закэшированы), диски для получения данных затронуты не будут вообще — все данные Greenplum возьмёт из памяти. Надо понимать, что такой режим работы не свойственен для Greenplum, а потому специализированные in-memory DB должны (в теории) справляться с такой задачей лучше.
Для тестирования Greenplum был установлен по умолчанию, без зеркал (только primary-сегменты). Все настройки дефолтные, таблицы сжаты zlib.
Yandex Clickhouse
Колоночная СУБД для аналитики и отчётов в реальном времени от известного поискового гиганта.
СУБД установлена с учётом рекомендаций производителя, движок для локальных таблиц — MergeTree, поверх локальных таблиц были созданы Distributed-таблицы, которые и участвовали в запросах.
SAP HANA
HANA (High performance ANalytics Appliance) позиционируется как универсальный инструмент для аналитической и транзакционной нагрузки. Умеет хранить данные поколоночно. Имеются нужные для продуктовой базы Disaster recovery, зеркалирование и репликация. HANA позволяет гибко настроить партиции (шарды) для таблиц: как по hash, так и по интервалу значений.
В наличии многоуровневое партиционирование, на разных уровнях можно применять различные типы партиций. В одну партицию можно записать до 2 миллиардов записей.
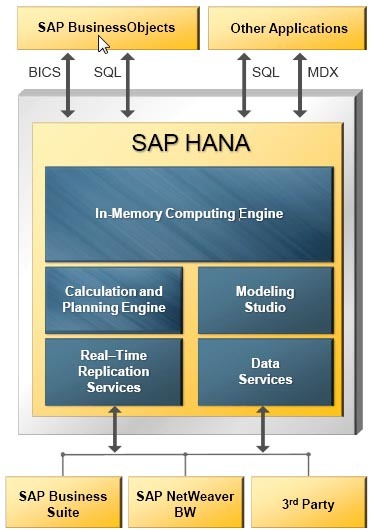
Архитектура решения на базе SAP HANA
Одна из интересных возможностей этой СУБД — потабличная настройка «unload priority» — приоритета выгрузки из памяти, от 1 до 10. Она позволяет гибко управлять ресурсами памяти и скоростью доступа к таблицам: если таблица используется редко, то ей устанавливается наименьший приоритет. В таком случае таблица будет редко загружаться в память и будет одной из первых выгружаться при нехватке ресурсов.
Exasol
Продукт в России практически неизвестный, тёмная лошадка. Из крупных компаний с этой СУБД работают только Badoo (о чём на Хабре есть статья) и ещё пара не-IT компаний, чьё имя на слуху — полный список есть на официальном сайте.
Вендор обещает феерически быструю аналитику, стабильность камня в лесу и простоту администрирования на уровне кофемолки.
Работает Exasol на своей ОС — ExaOS (свой дистрибутив GNU/Linux на основе CentOS/RHEL). Установка СУБД как минимум необычна, так как это не установка отдельного куска ПО на готовую ОС, а установка ОС на отдельную лицензионную машину (в нашем случае виртуальную) из скачанного образа и минимальная настройка (разбиение дисков, сетевые интерфейсы, разрешить загрузку по PxE) рабочих нод.
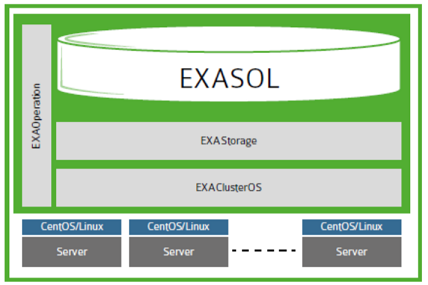
Упрощённая архитектура Exasol
Красота этой системы в том, что, так как на ноды ничего устанавливать не надо (ОС, параметры ядра и прочие радости), добавление новой ноды в кластер происходит очень быстро. С того момента, как сервер установлен и скоммутирован (bare-metal, без ОС), можно ввести ноду в кластер менее чем за полчаса. Все управление базой осуществляется через веб-консоль. Лишним функционалом она не перегружена, но и урезанной ее назвать нельзя.
Данные хранятся в памяти поколоночно и неплохо сжимаются (настроек сжатия при этом обнаружить не удалось).
Если при обработке запроса надо данных больше чем есть ОЗУ, база начнет использовать своп (спилл) на диски. Запрос не упадет (привет Hana и memSQL), просто будет работать медленней.
Exasol автоматически создает и удаляет индексы. Если вы делаете запрос впервые и СУБД решает, что с индексом запрос будет работать быстрее, то индекс будет создан в процессе отработки запроса. А если этот индекс 30 дней никому не был нужен, то база сама его удалит.
Вот какая умная лошадка.
Memsql
In-memory СУБД на основе mySQL. Кластерная, присутствуют аналитические функции. По умолчанию хранит данные построчно.
Чтобы сделать поколоночное хранение, нужно при создании таблицы добавить специальный индекс:
KEY `keyname` (`fieldaname`) USING CLUSTERED COLUMNSTORE
При этом rowstore-данные хранятся в памяти всегда, а вот columnstore-данные, в случае нехватки памяти, могут быть автоматически сброшены на диск.
Ключ дистрибуции называется SHARD KEY. Автоматически для каждого поля в shard key создается btree индекс.
Базовая версия — полностью бесплатная, без ограничений по объему данных и оперативной памяти. В платной версии есть high availability, онлайн бэкапы и ресторы, репликация между дата-центрами и управление правами пользователей.
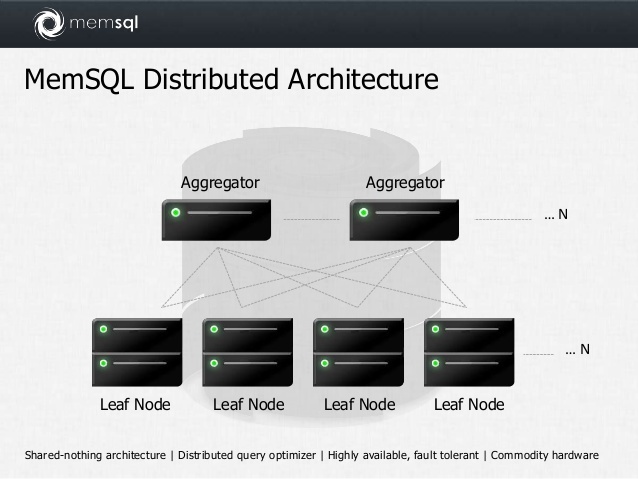
Упрощённая архитектура Memsql
Impala
Продукт Cloudera, SQL движок, разработанный на С++, входит в экосистему Apache Hadoop. Работает с данными, хранящимися в HDFS и HBase. В качестве хранилища метаданных использует HiveMetastore, входящий в состав СУБД Hive. В отличие от Hive, не использует MapReduce. Поддерживает кеширование часто используемых блоков данных. Позиционируется как СУБД для обработки аналитических запросов, требующих быстрого ответа. Умеет работать с основными BI-инструментами. Полная поддержка ANSI SQL, присутствуют оконные функции.
Impala доступна в виде пакета и парцела в репозитории Cloudera. При проведении тестирования использовался дистрибутив Cloudera CDH 5.8.0. Для установки был выбран минимальный набор сервисов для работы Impala: Zookeeper, HDFS, Yarn, Hive. Большая часть настроек использовалась по умолчанию. Для Impala было выделено суммарно 160 Гб памяти с обоих серверов. Для контроля утилизации ресурсов серверов контейнерами использовались cgroups.
Были выполнены все оптимизации, рекомендованные в статье, а именно:
— в качестве формата хранения таблиц в HDFS был выбран Parquet;
— оптимизированы типы данных, где это можно было сделать;
— предварительно выполнялся сбор статистики для каждой таблицы (compute stats);
— данные всех таблиц были записаны в кэш HDFS (alter table… set cached in…);
— оптимизированы join«ы (насколько это было возможно).
На первоначальном этапе планирования тестирования и определения СУБД для участия Impala была отброшена, поскольку мы уже работали с ней несколько лет назад и на тот момент она не выглядела production-ready. Ещё раз посмотреть в сторону «Антилопы» нас убедили коллеги по отрасли, убеждая, что за прошедшее время она очень похорошела и научилась грамотно работать с памятью.
Impala Daemon — основной сервис, который служит для принятия, обработки, координирования, распределения по кластеру и выполнения запроса. Поддерживает интерфейсы ODBC и JDBC. Также имеет CLI-интерфейс и интерфейс для работы с Hue (Web UI для анализа данных в Hadoop). Выполняется в качестве демона на каждом из воркеров кластера.
Impala Statestore — используется для проверки состояния инстансов Impala Daemon, работающих в кластере. Если на каком-либо воркере выходит из строя Impala Daemon, то Statestore уведомляет об этом инстансы на остальных воркерах, чтобы запросы к ушедшему в offline инстансу не передавались. Как правило, работает на мастер-ноде кластера, не является обязательным.
Impala Catalog Server — этот сервис служит для получения и агрегации метаданных из HiveMetastore, HDFS Namenode, HBase в виде структуры, поддерживаемой Impala Daemon. Также этот сервис используется для хранения метаданных, используемых исключительно самой Impala, таких, например, как пользовательские функции. Как правило, работает на мастер-ноде кластера.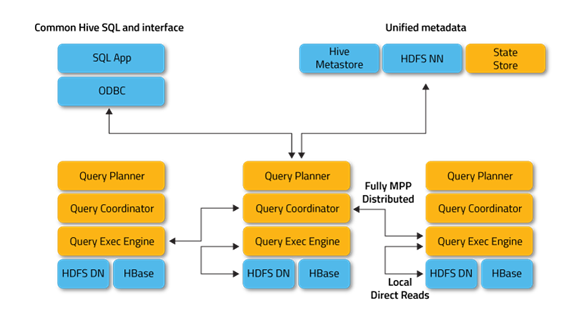
Некоторые важные для нас характеристики всех БД, собранные в одну таблицу на Google Docs
| Greenplum | Exasol | Clickhouse | Memsql | SAP Hana | Impala | |
| Вендор | EMC | Exasol | Yandex | Memsql | SAP | Apache / Cloudera |
| Используемая версия | 4.3.8.1 | 5.0.15 | 1.1.53988 | 5.1.0 | 1.00.121.00.1466466057 | 2.6.0 |
| Мастер-ноды | Мастер-сегмент. Резервируется. |
Точка входа — любая нода. Есть license-нода, резервируется. | Точка входа — любая нода | Точка входа — любая нода | Есть мастер-нода. Резервируется. | Точка входа — любая нода. Однако, нужен Hive metastore server. |
| Используемая ОС | RHEL 6.7 | EXA OS (проприетарная) | Ubuntu 14.04.4 | RHEL 6.7 | RHEL 6.7 | RHEL 6.7 |
| Возможное железо | Любое | Любое с поддержкой PXE Boot | Любое | Любое | Только из списка SAP | Любое |
| Импорт из Greenplum | External http tablesPipes | External http tablesJDBC import | External http tables | CSV с локального сервераSPARK | CSV с локального сервера | External GPHDFS tables |
| Интеграция с SAP BO(источник для юниверсов) | Да, ODBC | Да, ODBC | Нет данных | Нет данных | Да | Да, ODBCSIMBA |
| Интеграция с SAS | Да, SAS ACCESS | Да, ODBC | Нет данных | Нет данных | Нет данных | Да, SAS ACCESS |
| Оконные функции | Есть | Есть | Нет | Есть | Есть | Есть |
| Дистрибуция по нодам | По полю/полям | По полю/полям | По полю/полям | По полю/полям | По полю/полямШарды раскидываютсяпо нодам вручную | Рандомно |
| Колоночное хранение | Есть | Есть | Есть | Есть на дискеНет в пямяти | Есть | Есть (Parquet) |
| При нехватке памяти при выполнении запроса | Данные спилятся на диск | Данные спилятся на диск | Запрос падает | Запрос падает | Запрос падает | Данные спилятся на диск |
| Отказоустойчивость | Есть, механизм зеркал | Есть, механизм зеркал | Есть, на уровне таблиц | Есть | Есть | Есть, силами HDFS |
| Способ распространения | Open source, APACHE-2 | Закрытый код, платная | Open source, APACHE-2 | Закрытый код, бесплатная | Закрытый код, платная | Open source, APACHE-2 |
Результаты тестирования
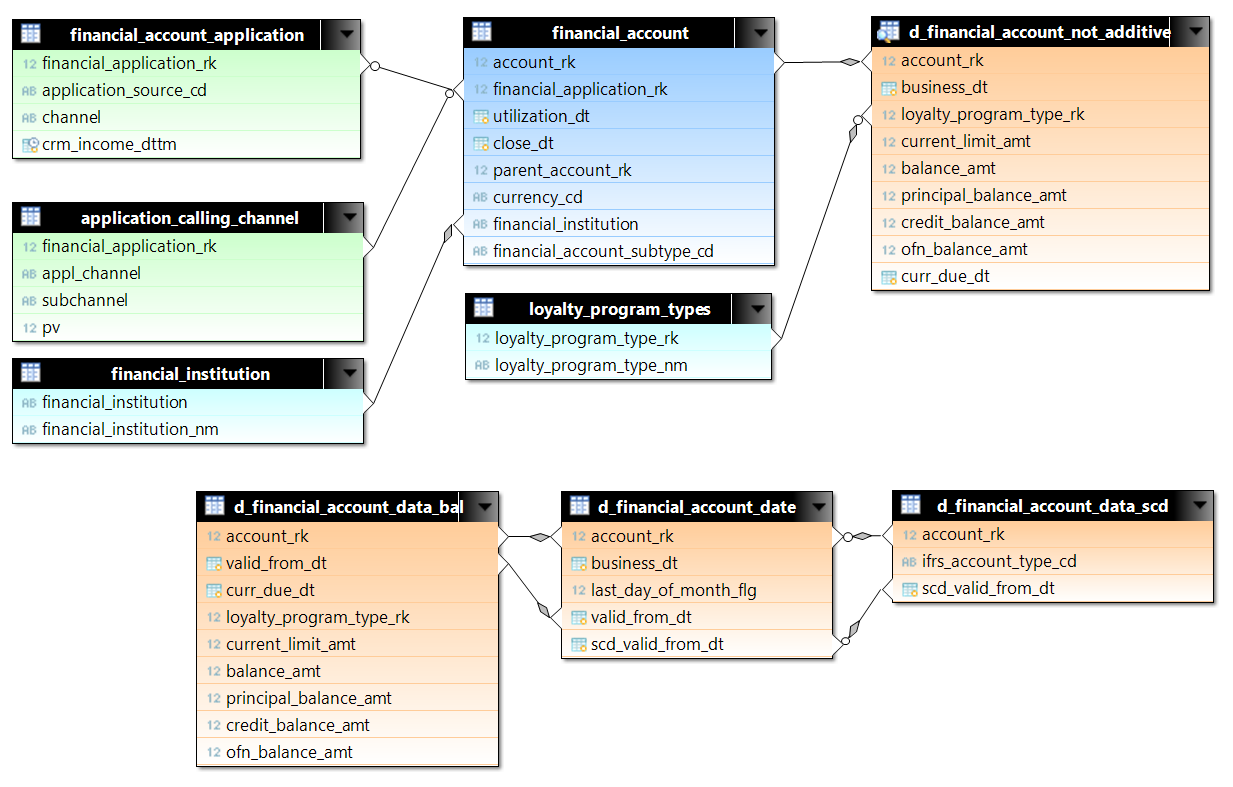
Для тестирования были подобраны запросы с d_financial_account_not_additive. d_financial_account_not_additive — это представление (view) с данными по каждому счету на каждый день. View сделано на основе трех таблиц с целью оптимизации места на диске, и, соответственно, чтения с диска. Для тестирования была выбрана часть данных по первому миллиону счетов с начала 2015 года. Это чуть больше 522 миллионов строк. К not_additive мы присоединяем данные по счетам (financial_account) и по заявкам (financial_account_application и application_calling_channel). В Greenplum (для примера) для таблиц заданы ключи распределения по сегментам: для счетов это account_rk, для заявок — financial_application_rk. В запросах join-ы между основными таблицами происходят по равенству, поэтому мы можем ожидать hash join, без nested loop, когда нужно сравнить построчно большое количество строк из разных таблиц.
Общий объём данных составил около 200 Гб в несжатом виде (рассчитываем, что весь этот объём с небольшим запасом влезает в память).
Число строк в используемых таблицах:
| Таблица | Число строк |
| d_financial_account_date | 522726636 |
| d_financial_account_data_bal | 229255701 |
| financial_account_application | 52118559 |
| application_calling_channel | 28158924 |
| d_financial_account_data_scd | 3494716 |
| financial_account | 2930425 |
| currency_rates | 3948 |
| dds_calendar_date | 731 |
| loyalty_program_types | 35 |
| financial_institution | 5 |
SELECT
date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm,
d_financial_account_not_additive.business_dt,
financial_account.financial_account_subtype_cd,
case when d_financial_account_not_additive.ofn_balance_amt <0 then 1 else 0 end,
loyalty_program_by_day.loyalty_program_type_nm,
financial_account.currency_cd,
sum(d_financial_account_not_additive.balance_amt*Table__14.rate),
sum(d_financial_account_not_additive.balance_amt)
FROM
prod_emart.loyalty_program_types loyalty_program_by_day RIGHT OUTER JOIN prod_emart.d_financial_account_not_additive d_financial_account_not_additive ON (d_financial_account_not_additive.loyalty_program_type_rk=loyalty_program_by_day.loyalty_program_type_rk
AND loyalty_program_by_day.valid_to_dttm > now())
INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk)
INNER JOIN (
SELECT
r.currency_from_cd,
r.currency_to_cd,
r.rate,
r.rate_dt
FROM
prod_emart.currency_rates r
WHERE
( r.currency_to_cd='RUR' )
union all
SELECT
'RUB',
'RUR',
1,
d.calendar_dt
FROM
prod_emart.dds_calendar_date d
) Table__14 ON (Table__14.currency_from_cd=financial_account.currency_cd)
WHERE
( Table__14.rate_dt=d_financial_account_not_additive.business_dt
)
AND
(
d_financial_account_not_additive.business_dt >= to_date(( 2016 - 2)::character varying ||'-01-01', 'YYYY-MM-DD')
AND
d_financial_account_not_additive.business_dt <= (current_date-1)
AND
financial_account.financial_account_subtype_cd IN ( 'DEP','SAV','SVN','LEG','CUR' )
)
GROUP BY
date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt),
d_financial_account_not_additive.business_dt,
financial_account.financial_account_subtype_cd,
case when d_financial_account_not_additive.ofn_balance_amt <0 then 1 else 0 end,
loyalty_program_by_day.loyalty_program_type_nm,
financial_account.currency_cd
select count(*) from (SELECT
date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm,
d_financial_account_not_additive.business_dt,
financial_account.financial_account_subtype_cd,
loyalty_program_by_day.loyalty_program_type_nm,
application_calling_channel.appl_channel,
case when ( financial_account_application.application_product_type )='010222' then 'Y' else 'N' end ,
case when ( financial_account_application.application_product_type )='020202' then 'Y' else 'N' end,
case when financial_account.parent_account_rk is null then 'N' else 'Y' end,
prod_emart.financial_institution.financial_institution_nm,
sum(d_financial_account_not_additive.principal_balance_amt),
sum(d_financial_account_not_additive.interest_balance_amt),
sum(d_financial_account_not_additive.f2g_balance_amt),
sum(d_financial_account_not_additive.f2n_balance_amt),
sum(d_financial_account_not_additive.overdue_fee_balance_amt),
sum(d_financial_account_not_additive.pastdue_gvt_balance_amt),
sum(d_financial_account_not_additive.annual_fee_balance_amt),
sum(d_financial_account_not_additive.sim_kke_balance_amt)
FROM
prod_emart.loyalty_program_types loyalty_program_by_day RIGHT OUTER JOIN prod_emart.d_financial_account_not_additive d_financial_account_not_additive ON (d_financial_account_not_additive.loyalty_program_type_rk=loyalty_program_by_day.loyalty_program_type_rk
AND loyalty_program_by_day.valid_to_dttm > now())
INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk)
LEFT OUTER JOIN prod_emart.financial_account_application ON financial_account.financial_application_rk=financial_account_application.financial_application_rk
LEFT OUTER JOIN prod_emart.application_calling_channel on financial_account.financial_application_rk=application_calling_channel.financial_application_rk
LEFT OUTER JOIN prod_emart.financial_account parent_account ON (financial_account.parent_account_rk=parent_account.account_rk)
LEFT OUTER JOIN prod_emart.financial_institution ON (financial_account.financial_institution=financial_institution.financial_institution)
WHERE
(
d_financial_account_not_additive.business_dt >= to_date('2014-01-01', 'YYYY-MM-DD')
AND
d_financial_account_not_additive.business_dt <= (current_date-1)
AND
(
financial_account.financial_account_subtype_cd IN ( 'CCR','INS','CLN','VKR','EIC' )
OR
(
financial_account.financial_account_subtype_cd IN ( 'PHX' )
AND
(
parent_account.financial_account_subtype_cd Is Null
OR
parent_account.financial_account_subtype_cd NOT IN ( 'IFS' )
)
)
)
)
GROUP BY
date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt),
d_financial_account_not_additive.business_dt,
financial_account.financial_account_subtype_cd,
loyalty_program_by_day.loyalty_program_type_nm,
application_calling_channel.appl_channel,
case when ( financial_account_application.application_product_type )='010222' then 'Y' else 'N' end ,
case when ( financial_account_application.application_product_type )='020202' then 'Y' else 'N' end,
case when financial_account.parent_account_rk is null then 'N' else 'Y' end,
financial_institution.financial_institution_nm) sq
SELECT
date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm,
d_financial_account_not_additive.business_dt,
financial_account.financial_account_subtype_cd,
case when ( prod_emart.financial_account_application.application_product_type )='010222' then 'Y' else 'N' end ,
d_financial_account_not_additive.risk_status_cd,
case when financial_account.utilization_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end,
case when ( d_financial_account_not_additive.current_limit_amt) > 0 then 1 else 0 end,
prod_emart.financial_institution.financial_institution_nm,
--sum(d_financial_account_not_additive.credit_balance_amt),
sum(d_financial_account_not_additive.principal_balance_amt),
sum(d_financial_account_not_additive.current_limit_amt),
count(d_financial_account_not_additive.account_rk),
sum(case when d_financial_account_not_additive.current_limit_amt > 0 then d_financial_account_not_additive.principal_balance_amt / d_financial_account_not_additive.current_limit_amt end)
FROM
prod_emart.d_financial_account_not_additive
INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk)
LEFT OUTER JOIN prod_emart.financial_account_application on financial_account.financial_application_rk=prod_emart.financial_account_application.financial_application_rk
LEFT OUTER JOIN prod_emart.financial_institution ON (financial_account.financial_institution=prod_emart.financial_institution.financial_institution)
WHERE
(
d_financial_account_not_additive.business_dt >= to_date(( 2016 - 2)::character varying ||'-01-01', 'YYYY-MM-DD')
AND
d_financial_account_not_additive.business_dt <= (current_date-1)
AND
financial_account.financial_account_subtype_cd IN ( 'CCR','CLN','VKR','INS','EIC' )
AND
case when financial_account.close_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end
IN ( 0 )
)
GROUP BY
date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt),
d_financial_account_not_additive.business_dt,
financial_account.financial_account_subtype_cd,
case when ( prod_emart.financial_account_application.application_product_type )='010222' then 'Y' else 'N' end ,
d_financial_account_not_additive.risk_status_cd,
case when financial_account.utilization_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end,
case when ( d_financial_account_not_additive.current_limit_amt) > 0 then 1 else 0 end,
prod_emart.financial_institution.financial_institution_nm
SELECT count(*)
FROM
(
SELECT *
FROM prod_emart.d_financial_account_data_bal
) ALL INNER JOIN
(
SELECT *
FROM prod_emart.d_financial_account_date
) USING account_rk, valid_from_dt
SELECT
count(*)
FROM prod_emart.d_financial_account_data_bal a JOIN prod_emart.d_financial_account_date b
ON a.account_rk = b.account_rk AND a.valid_from_dt = b.valid_from_dt
LEFT JOIN prod_emart.d_financial_account_data_scd sc
ON a.account_rk = sc.account_rk AND b.scd_valid_from_dt = sc.scd_valid_from_dt;
-- В таблице - 291 157 926 408 строк
select count(*)
from
(SELECT * FROM WRK.D_FINANCIAL_ACCOUNT_DATE) t1 INNER JOIN (SELECT * FROM WRK.D_FINANCIAL_ACCOUNT_DATE) t2
on t1.account_rk = t2.account_rk;
select count(*)
,sum(t1.last_day_of_month_flg - t2.last_day_of_month_flg) as sum_flg
,sum(t1.business_dt - t2.valid_from_dt) as b1v2
,sum(t1.valid_from_dt - coalesce(t2.scd_valid_from_dt,current_date)) as v1s2
,sum(coalesce(t1.scd_valid_from_dt,current_date) - t1.business_dt) as s1b2
from
prod_emart.D_FINANCIAL_ACCOUNT_DATE t1 INNER JOIN prod_emart.D_FINANCIAL_ACCOUNT_DATE t2
on t1.account_rk = t2.account_rk;
Результаты указаны в секундах выполнения запроса.
| Запрос |
Greenplum |
Exasol |
Clickhouse |
Memsql |
SAP Hana |
Impala |
| N1 |
14 |
< 1 |
- |
108 |
6 |
78 |
| N2 |
131 |
11 |
- |
- |
127 |
Error |
| N3 |
67 |
85 |
— |
- |
122 |
733 |
| T1 |
14 |
1.8 |
64 |
70 |
20 |
100 |
| T2 |
17 |
4.2 |
86 |
105 |
20 |
127 |
| D1 |
1393 |
284 |
- |
45 |
1500 |
- |
| D2 |
> 7200 |
1200 |
- |
> 7200 |
Error |
— |
Выявленные нюансы в работе БД
Yandex Clickhouse
В процессе тестирования выяснилось, что эта БД для наших задач не подходит — джойны в ней представлены только номинально. Так, например:
- поддерживается только JOIN с подзапросом в качестве правой части;
- условия в join-е не пробрасываются внутрь подзапроса;
- распределённые join-ы выполняются неэффективно.
Оказалось практически невозможным переписать «тяжёлые» запросы (N1-N3) на синтаксис Clickhouse. Также печалит ограничение по памяти — результат любого из подзапросов в любом запросе должен вмещаться в память на одном (!) сервере из кластера.
Несмотря на то, что для BI-задач эта БД оказалась непригодна, по результатам тестирования она нашла применение в хранилище в другом проекте.
Отдельно хочется отметить очень подробную и удобную документацию, доступную на официальном сайте (к сожалению, пока она покрывает не все аспекты использования БД), а также поблагодарить разработчиков Yandex за оперативные ответы на наши вопросы при проведении тестирования.SAP HANA
Основную часть по настройке серверов и оптимизации запросов произвели коллеги из одной консалтинговых компаний, являющихся представителями SAP в России. Без них посмотреть на базу и оценить ее преимущества мы бы не смогли: как показала практика, для работы с HANA требуется наличие опыта.
Очень интересно показала себя HANA при подсчете количества строк join-а таблицы самой на себя:
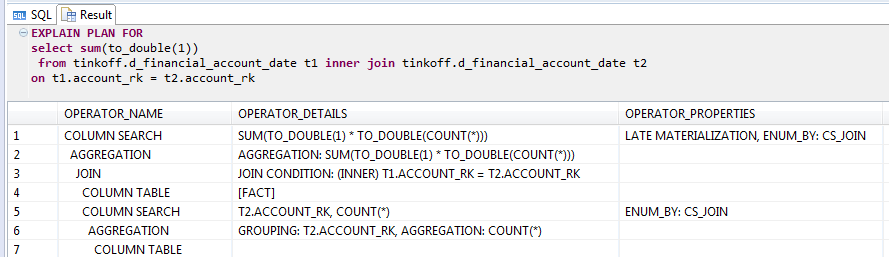
EXPLAIN запроса с join-ом таблицы самой с собой в HANA
Оптимизатор вычисляет результат с помощью статистики даже не выполняя join. Неплохой трюк, но если в where дописать условие, которое всегда True, например »1 = 1», то трюк не сработает и мы получим 25 минут, почти столько же сколько и у Greenplum.
На текущий момент HANA при выполнении запроса не умеет размещать промежуточные результаты запросов на диске. Поэтому если памяти не хватает, сессия обрывается, и пользователь остается без результатов.
Как выяснилось в процессе тестирования, даже при условии, что данные двух таблиц, участвующих в join-е, распределены по нодам кластера правильно, join по факту выполняется только на одной ноде кластера. Перед выполнением запроса данные со всего кластера просто переливаются на одну ноду и уже там происходит обсчет join-а. За отведенное под тестирование время победить такую логику и заставить join выполняться локально не смогли.
Кстати, производитель рекомендует по возможности использовать однонодовую конфигурацию БД, что и подтверждают результаты нашего тестирования — заставить конфигурацию из двух машин оптимально работать в разы сложнее, чем из одной.
Главное впечатление от работы с базой — работает очень быстро и удивительно стабильно, прямо вот так, из коробки. Практически во всех наших тестах видно преимущество в скорости по сравнению с другими СУБД. Однако, в отличие от многих других СУБД, это черный ящик — у вас нет возможности даже подключиться к ноде по ssh и запустить iotop, htop и так далее.
Отсутствие контроля своих же серверов, безусловно, заставляет напрячься. Хотя справедливости ради надо отметить, что все нужные данные по работе базы и нагрузке на железо есть в системных view внутри базы.
Имеются JDBC, ODBC драйверы, отличная поддержка ANSI SQL и некоторых специфических особенностей Oracle (select 1 from dual, как пример). Еще в БД уже встроены JDBC-драйверы для подключения к внешним базам (Oracle, PostgreSQL, MySQL и другим), что очень удобно для загрузки данных.
EXASOL позволяет посмотреть план только выполненных запросов. Это связано с тем, что план создается на ходу во время выполнения за счет анализа промежуточных результатов. Отсутствие классического explain работе не мешает, но с ним привычнее.
Быстрая, удобная, стабильная, не требует долгого тюнинга — поставил и забыл. В общем, какая-то вся правильная. Но черный ящик, что настораживает.
Отдельно хочется отметить адекватность поддержки, которая оперативно отвечала на абсолютно все наши возникшие вопросы.Memsql
Ставится просто и быстро. Админка красивая, но не сильно толковая. Примеры: можно добавлять ноды в кластер, но удалять из админки нельзя/сложно/неочевидно; можно видеть текущие и завершенные запросы, но никаких подробностей о них увидеть нельзя.

В админке memsql можно твиттить число записей в секунду
При работе MemSQL очень любит нагрузить процессоры, ошибок с переполнением памяти почти не было.
MemSQL перед тем, как соединить две таблицы, делает repartitioning (перераспределение данных по нодам) по ключу join-а.
В нашем случае мы можем таблицу data_bal и date хранить со сложным shard key (account_rk, valid_from_dt), для scd-таблицы ключ шардирования будет (account_rk, scd_valid_from_dt). Соединением между data_bal и date в таком случае будет происходить быстро, далее при выполнении запроса данные будут перераспределены по account_rk и scd_valid_from_dt, и на следующем шаге уже по account_rk для соединения с таблицей financial_account. Как уверяет поддержка, repartitioning — это очень затратная по времени операция.
Таким образом, наши запросы оказались тяжеловатыми для базы из-за большого количества разноплановых join-ов. В Greenplum join-ы между перечисленными таблицами происходят локально, и, соответственно, быстрее, без перераспределения по узлам, так называемого Redistribute Motion.
В целом, MemSQL видится отличной СУБД для миграции с MySQL и не самой сложной аналитики.
Установка кластера Cloudera, в состав которого и входит Impala, достаточно проста и хорошо задокументирована.
Однако, стоить отметить, что скоростью работы Impala относительно других БД не отличилась — к примеру, запрос, который подсчитывал count (*) в d_financial_account_not_additive, работал в Impala 3,5 минуты, что значительно больше, чем у соперников, у которых результаты — это десятки секунд и меньше.
Также мы провели интересный эксперимент: как было написано ранее, во view d_financial_account_not_additive есть два join-а. В каждом из них происходит соединение по account_rk с типом данных integer, а также по полям с типом данных дата. В Impala нет типа данных date, поэтому мы использовали timestamp. Ради интереса была сделана замена timestamp на bigint, в котором хранился unix timestamp. Результат запроса сразу улучшился на минуту. На следующем шаге данные из account_rk и поля с датой, это valid_from_dt и scd_valid_from_dt, были объединены, чтобы обеспечить join только по одном полю. Это было сделано нехитрым способом:
account_valid_from = account_rk * 100000 + cast(unix_timestamp(valid_from_dt)/86400 as int)Join по одному полю дал нам еще около полуминуты выигрыша, но в любом случае это в несколько раз больше чем у других СУБД.
Основные запросы работали в несколько раз дольше. Запрос N2 падал из-за нехватки памяти, поэтому по нему нет результатов.
На текущий момент в Impala отсутствует распределение данных по узлам с hash-распределением, поэтому для используемых запросов мы вряд ли бы получили хорошее время выполнения.
Вместо заключения
Мы сознательно не хотим делать вывод из результатов тестирования вида «база А показала себя хорошо в том-то и том-то, а база Б — умеет твитить из админки в том-то и том-то, поэтому А лучше Б», предоставив это читателям. Надеемся, данный текст поможет кому-то открыть для себя новые продукты на рынке СУБД для ETL и BI, а кому-то — принять окончательное решение в выборе.
Эксперимент считаем состоявшимся, на основе его результатов, учитывая всё множество критериев, в данный момент выбираем СУБД для использования в BI-проекте.
Статья публикуется от имени четырёх человек, проводивших тестирование:
Максим Белоусов
Дмитрий Немчин (aka 4etvegr)
Георгий Безруких
Дмитрий Павлов (aka kapustor)
Иллюстрации, так чудесно описавшие тестируемые БД, взяты из концепта Virtua Hamster (так и не вышедшая игра для Sega 32).
Комментарии (1)
 SLASH_CyberPunk
SLASH_CyberPunk
11 октября 2016 в 11:33
0↑
↓
Почему не рассматривали HP Vertic?
