Сравнение алгоритмов детекции лиц
Привет, Хабр! Очень часто я на просторах интернета натыкаюсь на такой вопрос: «А какое готовое решение по детекции лиц лучше всего использовать?» Так вот, я отобрал 5 решений с Github, которые показались мне хорошими, относительно новыми и лёгкими в использовании, и хотел бы сравнить их между собой. Всем, кому интересно, что из этого вышло, добро пожаловать под кат!

СУТЬ ЭКСПЕРИМЕНТА
Для начала, я отобрал на Kaggle с различных датасетов фотографии, на которых присутствуют лица и сформировал свой датасет. Датасет старался сделать максимально разнообразным. В полученном датасете имеются персоны в очках, курящие, в головных уборах, разных возрастов и национальностей, с бородой, а самое главное все фотографии были не самого высокого разрешения, на котором лица были немного размыты либо это размытие сделал я с помощью библиотеки OpenCV. Полученные фотографии разделил на 5 классов, в каждой из которых по 50 фотографий:
dummy faces — в эту папку попали лица статуй, героев симпсонов, аниме персонажей, барби
лица, на которых присутствуют маски
лица, которые сфотографированы в профиль
белокожие
темнокожие
Далее данные фотографии я разметил с помощью замечательной программы labelme. Размечать старался таким образом, чтобы в ограничительную рамку попали подбородок, лоб и щёки. Последние две части лица не обязательно могут попадать полностью:

После разметки я прогнал фотографии через каждый из алгоритмов и посчитал следующие метрики: Intersection over Union, precision и recall. Про данные метрики можно почитать тут и тут. Уточню, что в данном случае найденное лицо — true positive, не найденное лицо — false negative, а ложное срабатывание (условно, когда машину распознало как лицо) — false positive. Также вычислил скорость работы алгоритма. Ну что ж, теперь перейдём непосредственно к самим решениям!
RetinaFace
И начну я, пожалуй, с самого лучшего алгоритма по таким метрикам как Intersection over Union, precision и recall. Как можно увидеть в readme данного репозитория, то его эффективность обнаружения потрясающая:

Вдобавок, с помощью данного репозитория имеется возможность находить ключевые точки лица, выравнивать и распознавать лица. Результат работы данного алгоритма на моих данных показан в табличке ниже:

Facenet-pytorch
Следующий метод чуть хуже по метрикам машинного обучения предыдущего решения, зато на порядок выше по скорости отработки. Также у данного алгоритма есть возможность работы на GPU, что ускоряет работу алгоритма примерно на 40% и потребляет около 1ГБ видеопамяти (цифры, которые приведены в табличке ниже — это результат отработки алгоритма на CPU). Результаты представлены ниже:

DBFace
Это решение в описании проекта, также как и первое решение, показывает впечатляющие результаты:

На деле же оказалось немного хуже по метрикам машинного обучения, нежели первое решение, зато по скорости гораздо лучше:
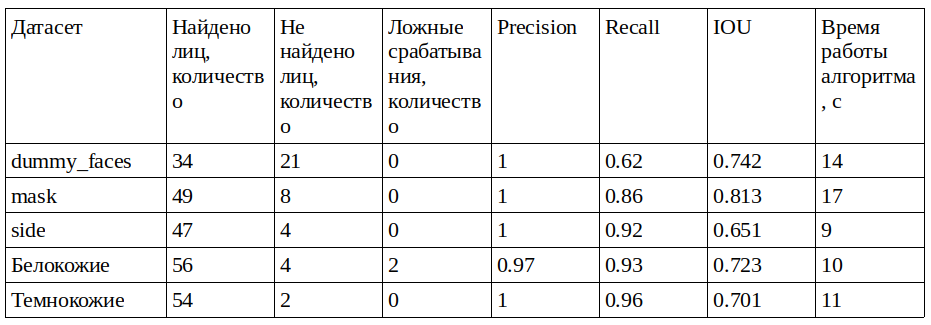
Face Recognition
Данное решение является одним из самых популярных, если судить по звёздам на Github, но точно не самым лучшим:

Я предполагаю, текущее решение может быть настолько популярно, так как кроме детекции лиц, тут есть много других полезных функций: возможность находить ключевые точки лица, распознавать лица, работать в реальном времени + разработка ведётся достаточно долго.
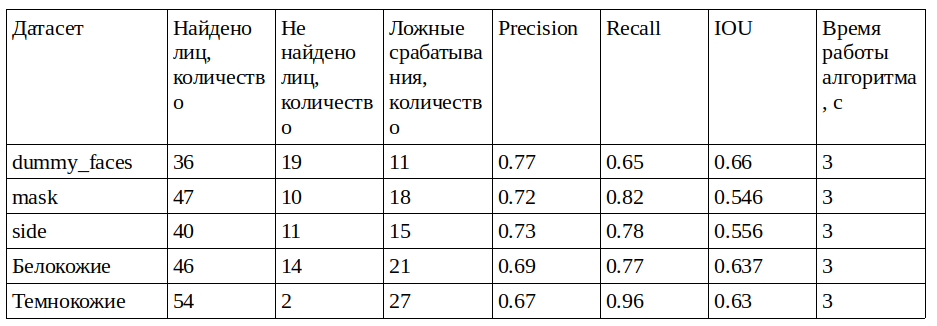
Ultra-Light-Fast-Generic-Face-Detector-1MB
Данный алгоритм работает очень быстро, что отрицательно отразилось на других метриках. Также у данного алгоритма есть возможность работы на GPU, но разницу по времени отработки алгоритма я не увидел. Вот какие результаты мне удалось получить:
ЗАКЛЮЧЕНИЕ
Все результаты были получены при стандартных параметрах. Наверняка, есть подкрутить некоторые параметры, то можно было бы увидеть ещё лучше результаты. Исходный код с реализацией каждого алгоритма и подсчётом метрик я выложил на Github. Там же доступны датасеты и разметка. Хочу отметить, что все эксперименты проводились на Ubuntu. Также я готов принимать pull request’ы с вашими решениями и результатами!
