SQL HowTo: TOP-N на субинтервалах
Периодически сталкиваюсь с однотипными задачами вида «показать TOP-N позиций на каждом из вложенных интервалов некоторого периода».
Это может быть »5 лучших по успеваемости студентов в каждом семестре за последний учебный год», или «помесячная динамика позиции 10 наиболее продающихся товаров», или, как у нас в сервисе визуализации PostgreSQL-планов explain.tensor.ru, »3 наиболее активных страны за каждый день»:

«Все флаги в гости будут к нам»
Давайте попробуем создать эффективный, но компактный запрос для PostgreSQL, который сможет решить такую задачу — например, за последний месяц.
Для начала нам понадобится сама таблица первичных «фактов», по которой мы будем вычислять свои «топы» — сгенерируем в ней миллион каких-то случайных записей «за последний год»:
CREATE TABLE fact4agg AS
SELECT
now()::date - (random() * 365)::integer dt -- дата "факта"
, chr(ascii('a') + (random() * 26)::integer) code -- код агрегации
FROM
generate_series(1, 1e6);Раз выборку мы будем делать «за период», то индекс по дате нам точно пригодится:
CREATE INDEX ON fact4agg(dt);Генерация субинтервалов
При первом подходе к задаче может показаться, что достаточно посчитать и вывести группировку по «фактам» в разрезе каждого дня. Но это будет ошибкой, поскольку в некоторых днях может не оказаться ни одного факта.
Конечно, подобные пропуски можно будет устранить и на бизнес-логике, но она для этого все-таки приспособлена не слишком хорошо, поэтому сделаем это сразу на БД с помощью функции generate_series, получив серию дат:
WITH params(dtb, dte) AS (
VALUES(now()::date - 30, now()::date)
)
SELECT
dt::date
FROM
params
, generate_series(dtb, dte, '1 day') dt;Небольшой нюанс здесь заключается лишь в том, что эта функция выдает timestamp, а нам необходим тип date. Если вам требуется другой интервал — например, неделя или месяц — просто задайте другой шаг: '1 week' или '1 month'.
Первичный отбор данных
Ничего сильно хитрее, чем «прямо взять и посчитать», для вычисления агрегатов (если мы их нигде не храним в отдельной таблице, как это описано в серии статей про агрегаты в БД) применить не выйдет:
WITH params(dtb, dte) AS (
VALUES(now()::date - 30, now()::date)
)
SELECT
dt
, code
, count(*) qty
FROM
params
, fact4agg
WHERE
dt BETWEEN dtb AND dte
GROUP BY
1, 2;К счастью, наличие индекса позволяет нам отобрать и сгруппировать все необходимые данные достаточно быстро — всего за 65ms:

Index Scan
Но если мы поменяем наш индекс на более подходящий для Index Only Scan, тот же запрос окажется вдвое быстрее и в 200 раз более эффективным по объему вычитываемых данных!
DROP INDEX fact4agg_dt_idx;
CREATE INDEX ON fact4agg(dt)
INCLUDE(code);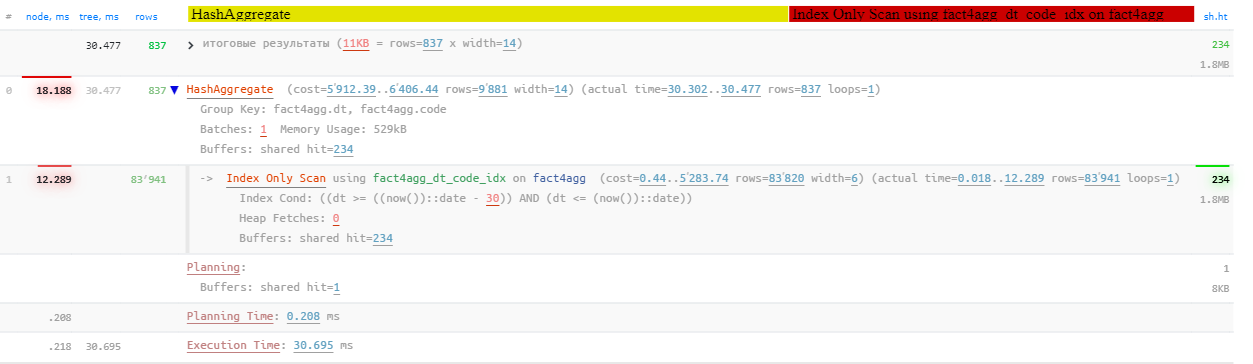
Index Only Scan
Отбираем TOP-3
Поскольку мы условились, что делать на бизнес-логике несвойственные ей операции мы не хотим, то договоримся, что 3 «лидирующих» записи за каждый день мы отдадим одним json.
И самый простой приходящий на ум вариант выглядит как «так давайте пронумеруем нужные с помощью оконных функций и отберем только их». Правда, это приведет нас к не очень красивому «трехэтажному» запросу:
WITH params(dtb, dte) AS (
VALUES(now()::date - 30, now()::date)
)
SELECT
dt
, json_agg(
json_build_object('code', code, 'qty', qty)
ORDER BY qty DESC -- "сворачиваем" в json[] с нужной сортировкой
)
FROM
(
SELECT
*
, row_number() OVER(PARTITION BY dt ORDER BY qty DESC) rn -- нумеруем в нужном порядке
FROM
(
SELECT
dt
, code
, count(*) qty
FROM
params
, fact4agg
WHERE
dt BETWEEN dtb AND dte
GROUP BY
1, 2
) T
) T
WHERE
rn <= 3 -- отбираем только 3 первых
GROUP BY
1;Но давайте обратим внимание, что мы сортировали данные тут, минимум, дважды — сначала при нумерации, а потом — при свертке в json. Нельзя ли этого избежать?…
Оказывается, можно, если сразу все «сворачивать в массив», и уже от него брать 3 первых элемента. Но не все так просто…
ERROR: cannot subscript type json because it does not support subscriptingНельзя просто так взять сегмент из json-массива, зато из массива json’ов — можно:
WITH params(dtb, dte) AS (
VALUES(now()::date - 30, now()::date)
)
SELECT
dt
, to_json(
(
array_agg(
to_jsonb(T) - 'dt' -- свернули всю строку в jsonb и удалили лишний ключ
ORDER BY qty DESC -- сортируем в нужном порядке
) -- свернули в jsonb[]
)[:3] -- взяли 3 первых элемента
) json -- сконвертировали в "обычный" json
FROM
(
SELECT
dt
, code
, count(*) qty
FROM
params
, fact4agg
WHERE
dt BETWEEN dtb AND dte
GROUP BY
1, 2
) T
GROUP BY
1;Тут мы вместо перечисления всех полей в результирующем json просто «свернули» всю строку в jsonb и удалили в нем избыточный ключ dt.
Затем «свернули» все в jsonb[], взяли от него первые 3 элемента и превратили в «обычный» json-массив.
Итоговый запрос
Остается лишь собрать генерацию субинтервалов и агрегаты в единый запрос:
WITH params(dtb, dte) AS (
VALUES(now()::date - 30, now()::date)
)
SELECT
*
FROM
(
SELECT
dt::date
FROM
params
, generate_series(dtb, dte, '1 day') dt
) X
LEFT JOIN
(
SELECT
dt
, to_json(
(
array_agg(
to_jsonb(T) - 'dt'
ORDER BY qty DESC
)
)[:3]
) json
FROM
(
SELECT
dt
, code
, count(*) qty
FROM
params
, fact4agg
WHERE
dt BETWEEN dtb AND dte
GROUP BY
1, 2
) T
GROUP BY
1
) Y
USING(dt)
ORDER BY
dt;Убедимся фактическим планом, что мы своими агрегатами ничего сильно не попортили:

Всего 42ms (даже меньше, чем весь отбор данных при Index Scan!), да и план не слишком страшный получился.
