SQL: 15 упражнений с решениями
Добрый день! В этом наборе упражнений мы поработаем с SQL и T-SQL. С помощью этих упражнений мы будем создавать разные запросы SQL и T-SQL, чтобы отточить навыки работы с запросами.
Независимо от того, являетесь ли вы новичком или опытным разработчиком, эти упражнения помогут укрепить знания и подготовиться к реальным собеседованиям. Статья предоставляет возможность проверить свои знания и навыки, решая предложенные задачи.
В моем канале вы найдете подробный разбор SQL задач с собеседований, полезные гайды и уроки для программистов
А здесь целая папка бесплатных полезных ресурсов и каналов.
Упражнений по SQL являются отличным способом для начинающих разработчиков улучшить свои навыки работы с языком SQL. Упражнения покрывают широкий спектр тем, включая выборку данных, фильтрацию, сортировку, группировку и объединение таблиц. Каждое упражнение сопровождается подробным объяснением и примерами решений, что помогает читателю лучше понять концепции и применить их на практике.
Пишите свои решение в комментариях и давайте погрузимся в работу и начнём решать задачи.
Задание 1
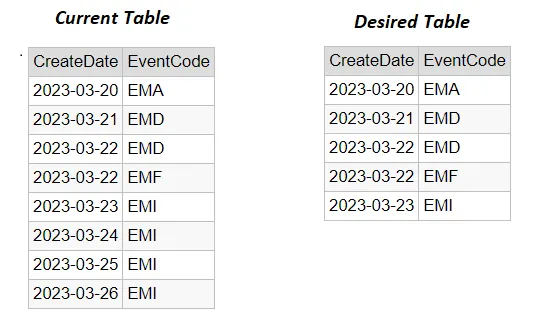
Дана таблица событий. Я хотел бы исключить определённые значения, которые появляются несколько раз. EMI должен появиться только один раз и только первый EMI с 23 марта. Другие дубликаты, такие как EMD, могут остаться.
13 упражнений по SQL с решениями
Вот запрос для создания таблицы и вставки данных:
DROP TABLE IF EXISTS #Movements
CREATE TABLE #Movements
(
CreateDate date,
EventCode nvarchar(3)
)
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-20', 'EMA')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-21', 'EMD')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-22', 'EMD')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-22', 'EMF')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-23', 'EMI')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-24', 'EMI')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-25', 'EMI')
INSERT INTO #Movements (CreateDate,EventCode) VALUES ('2023-03-26', 'EMI')
SELECT * FROM #MovementsРешение
Этот запрос решает представленную выше задачи:
select t.*
from #Movements t
LEFT JOIN (
SELECT EventCode, MIN(CreateDate) as CreateDate
FROM #Movements
WHERE EventCode = 'EMI'
GROUP BY EventCode
) s on s.EventCode = t.EventCode and t.CreateDate > s.CreateDate
where s.CreateDate is nullЗадание 2
Дана таблица с данными о ценах продажи товаров за разные даты.

13 упражнений по SQL с решениями
Как вы можете видеть, желаемый результат заключается в том, чтобы DataEnd была на один день меньше даты следующего изменения цены.

13 упражнений по SQL с решениями
Вот запрос для создания таблицы и вставки данных:
create table ##sales(
item int,
date date,
price int
)
insert into ##sales(item, date, price)
values
(1,'2021-05-01', 200),
(1,'2021-06-11', 210),
(1,'2021-06-27', 225),
(1,'2021-08-01', 250),
(2,'2021-02-10', 600),
(2,'2021-04-21', 650),
(2,'2021-06-17', 675),
(2,'2021-07-23', 700)Решение
Этот простейший запрос является решением представленной выше задачи:
select item, date as DateStart, price,
lead(date,1, GETDATE()) over (partition by item order by date ) DateEnd
from ##salesЗадание 3
У меня есть 3 таблицы, называемые tables, years и codes. Результаты на рисунке ниже приведены для этих трёх таблиц.

13 упражнений по SQL с решениями
Вот запрос для создания таблицы и вставки данных:
declare @tables table (year int, code int, import decimal(5,2))
insert into @tables values
(2019,390107,10.00),
(2021,390107,175.00),
(2022,390107,102.00),
(2022,470101,101.00),
(2022,53015101,140.00)
declare @years table (year int)
insert into @years values
(2018),
(2019),
(2020),
(2021),
(2022)
declare @codes table (code int)
insert into @codes values
(390107),
(470101),
(470103),
(471103),
(53010101),
(53015101)Я хочу сделать запрос, который возвращает import для каждого года и для каждого кода, содержащегося в следующих таблицах (return import = 0, где нет записи для определённой комбинации года и кода).
Имея 6 codes и 5 years, я ожидаю 30 записей (по одной для каждой комбинации года и кода) вместе с соответствующим значением import из @tablee» для этой комбинации year/ code(или 0, если комбинация не найдена).

13 упражнений по SQL с решениями
Решение
Этот запрос вычисляет общий объём импорта для каждого кода за каждый год в таблицах @years и @codes, используя данные из таблицы @table. Он делает это, используя перекрёстное соединение (CROSS JOIN) для объединения данных из таблиц @years и @codes, а затем использует LEFT JOIN для ввода данных импорта из @table.
SELECT Y.year,
C.code,
ISNULL(T.import, 0) AS import
FROM @years Y
CROSS JOIN @codes C
LEFT JOIN @table T
ON T.year = Y.year AND T.code = C.code
order by y.yearЗадание 4
Операция удаления выполняется медленно, и перестройка индекса, похоже, не решает проблему. У меня есть простой запрос на удаление:
Delete from sales
where ImportLogId = @ImportLogidТаблица ImportLog содержит около 3 миллионов записей. У меня есть некластеризованный индекс, созданный в таблице ImportLog в ImportLogID. Фрагментация составляет менее 10%, но всё равно выполнение запроса занимает больше времени, а когда я перестраиваю индекс вручную, он выполняется в течение секунды. Через день та же проблема повторяется.
Вот план выполнения в поиске лучшего решения данной задачи:

13 упражнений по SQL с решениями
Решение
Проблема заключается не в удалении записей. Проблема заключается в последующем сканировании таблицы оптовой продажи.
Проиндексируйте столбец внешнего ключа в WholesalerSale, чтобы ускорить эту проверку:
CREATE INDEX IX_WholesalerSale_ImportSaleId ON WholesalerSales (ImportSaleId);Задание 5
У меня есть таблица под названием Employee . Исходя из таблицы ниже, как я могу получить неверный вывод?

13 упражнений по SQL с решениями
Вот запрос для создания таблицы и вставки данных:
create table ##Employee (
id int identity(1,1) primary key,
name varchar(255),
paymenttype varchar(255),
payment bigint
)
insert into ##Employee (name, paymenttype, payment)
values
('John ', 'Salary' , 100),
('Peter ', 'Salary' , 100),
('John ', 'Bonus ' , 20 ),
('Russel', 'Salary' , 100),
('Bill ', 'Salary' , 100),
('Bill ', 'Bonus ' , 40 ),
('John ', 'Salary' , 100)Решение
Этот запрос вычисляет общую сумму заработной платы и бонусов для каждого сотрудника в таблице ##Employee. Он делает это с помощью функции SUM в сочетании с регистровым выражением CASE. Выражение CASE проверяет значение столбца PaymentType для каждой строки и возвращает значение столбца Payment, если типом платежа является либо «Зарплата», либо «Бонус», в противном случае оно возвращает 0.
SELECT
Name,
SUM(CASE WHEN PaymentType = 'Salary' THEN Payment ELSE 0 END) AS Salary,
SUM(CASE WHEN PaymentType = 'Bonus' THEN Payment ELSE 0 END) AS Bonus
FROM ##Employee
GROUP BY Name;Задание 6
У меня есть две таблицы под названием Ingresaron и Salieron:

13 упражнений по SQL с решениями

13 упражнений по SQL с решениями
Мне надо получить такой результат. Как это сделать?

13 упражнений по SQL с решениями
Вот запрос для создания таблицы и вставки данных:
create table Ingresaron (DepartmentId int,Fecha_Lunes date,Entraron int);
insert into Ingresaron (DepartmentId,Fecha_Lunes,Entraron) values
(26,'2022-08-01',1),
(26,'2022-08-15',2),
(26,'2022-08-22',3),
(26,'2022-08-08',3);
create table Salieron (DepartmentId int,Fecha_Lunes date,Salieron int);
insert into Salieron (DepartmentId,Fecha_Lunes,Salieron) values
(26,'2022-08-15',3),
(26,'2022-08-22',4),
(26,'2022-08-08',2),
(26,'2022-08-29',1);Решение
Этот запрос использует оператор FULL JOIN для объединения данных из таблиц ingresaron и Salieron. Оператор FULL JOIN вернёт все строки из обеих таблиц, даже если в другой таблице нет совпадающих строк.
select coalesce(ing.DepartmentId, s.DepartmentId) as DepartmentId,
coalesce(ing.Fecha_lunes, s.Fecha_lunes) as Fecha_lunes,
s.Salieron,
ing.Entraron
from ingresaron ing
full join Salieron s
on ing.DepartmentId = s.DepartmentId and ing.Fecha_lunes = s.Fecha_lunes;Задание 7
Удалите дублирующие данные из таблицы person.

13 упражнений по SQL с решениями

13 упражнений по SQL с решениями
Решение
Этот запрос использует общее табличное выражение (CTE) для удаления дубликатов из таблицы person. CTE выбирает столбец name и использует функцию ROW_NUMBER для присвоения уникального номера каждой строке в каждом разделе name. Затем запрос удаляет все строки, в которых столбец row_numbers больше 1. Это эффективно удаляет все повторяющиеся строки для заданного значения имени. Наконец, запрос выбирает оставшиеся значения имён из таблицы person.
with cte as(
SELECT
[name]
,row_numbers=ROW_NUMBER() OVER(PARTITION BY [name] ORDER BY [name])
FROM [dbo].[person]
)
DELETE FROM CTE WHERE row_numbers > 1
select name from [dbo].[person]Задание 8
У меня есть текущая таблица со столбцами даты и количества. Я хочу получить желаемую таблицу, как показано на рисунке ниже. Уточнение: мне нужно получить общее количество для каждого подъёма, за исключением 2022–12–01 на эту дату.

13 упражнений по SQL с решениями
Вот тестовый код:
Create Table #table_name([date] DATE, [count] INT);
Insert Into #table_name Values
('2022-12-04',1),
('2022-12-03',2),
('2022-12-02',1),
('2022-12-01',3),
('2022-11-30',1),
('2022-11-29',1),
('2022-11-28',1),
('2022-11-27',2);Решение
Это запрос, который выбирает столбцы dt и count_sum, причём dt является производным столбцом, который является либо полной датой, либо только месяцем и годом значения даты в столбце date, в зависимости от того, является ли день даты первым днём месяца.
Если днём значения date является первый день месяца, date преобразуется в строку вида 'YYYY-MM-DD' с помощью функции Cast. Если день не является первым днем месяца, функция Format используется для преобразования значения date в строку вида 'YYYY-MM'.
Результаты подзапроса check_date затем группируются по dt, а сумма значений count вычисляется для каждой группы с помощью функции sum. Результирующие строки упорядочиваются по dt в порядке убывания с использованием предложения order by.
with check_date as
(
select case
when Day([date])=1
Then Cast([date] as varchar(10))
else Format([date], 'yyyy-MM')
end As dt,
[count]
from #table_name
)
select dt, sum([count]) as count_sum
from check_date
group by dt
order by dt descЗадание 9
У меня есть текущая таблица с Doctor, Case_Number и Field. Мне нужна желаемая таблица из одной строки для каждого Case_Number со столбцами всех типов полей и тем, что каждый врач сделал в каждом конкретном случае.

13 упражнений по SQL с решениями
Вот тестовый код:
DECLARE @Cases TABLE (
CaseID INT IDENTITY,
Doctor NVARCHAR(50),
Case_Number INT,
Field NVARCHAR(50)
)
INSERT INTO @Cases (Doctor, Case_Number, Field) VALUES
('Brian', 2234, 'Injection'),
('Brian', 2234, 'Surgery '),
('Flor ', 2234, 'Surgery '),
('Flor ', 2234, 'Discharge'),
('Brian', 1156, 'Injection'),
('Brian', 3459, 'Surgery '),
('Flor ', 3459, 'Surgery '),
('Brian', 3459, 'H-Test ')Решение
Столбцы Injection, Surgery, H-Test и Discharge выводятся с использованием функции MAX с выражением CASE. Для каждого из этих столбцов выражение CASE вычисляет значение столбца field и возвращает «X», если оно совпадает с именем выбранного столбца, и » » (один пробел), если это не так.
Функция MAX используется для того, чтобы гарантировать, что значение «X» выбрано, если оно существует, и » » выбрано, если его нет. Это связано с тем, что функция MAX вернёт максимальное значение среди своих аргументов, поэтому, если есть значение «X», оно будет возвращено, а если нет, то вместо него будет возвращено значение » ».
Результирующие строки группируются по столбцам doctor и case_number, а результирующий вывод будет содержать одну строку для каждой уникальной комбинации значений doctor и case_number, со столбцом для каждого из производных столбцов, показывающим, присутствовало ли соответствующее значение поля в исходной таблице @Cases.
SELECT doctor, case_number,
MAX(CASE WHEN field = 'Injection' THEN 'X' ELSE ' ' END) AS Injection,
MAX(CASE WHEN field = 'Surgery' THEN 'X' ELSE ' ' END ) AS Surgery,
MAX(CASE WHEN field = 'H-Test' THEN 'X' ELSE ' ' END ) AS [H-Test],
MAX(CASE WHEN field = 'Discharge' THEN 'X' ELSE ' ' END) AS Discharge
FROM @Cases
GROUP BY doctor, case_numberЗадание 10
У меня есть текущая таблица с firstDate, LastDate и Code. Я хочу получить желаемую таблицу, как показано на рисунке ниже. Чтобы было понятно, объедините все строки с аналогичным кодом, взяв первую дату из 1-й строки и последнюю дату из последней строки.

13 упражнений по SQL с решениями
CREATE TABLE ABCD(
id int,
FirstDate date,
LastDate date,
code varchar(23)
);
Insert into ABCD VALUES
(1, '2022-12-12','2022-12-12', 'A'),
(2, '2022-12-13','2022-12-13', 'A'),
(3, '2022-12-15','2022-12-15', 'A'),
(4, '2022-12-16','2022-2-16', 'B'),
(5, '2022-12-18','2022-12-18', 'A'),
(5, '2022-12-19','2022-12-19', 'A'),
(6, '2022-12-20','2022-12-20', 'C')Решение
Вот решение:
WITH ABCD_with_newvals AS
(SELECT *,
CASE WHEN LAG(code, 1) OVER (ORDER BY id) = [code] THEN 0 ELSE 1 END AS NewVal
FROM ABCD
),
ABCD_grouped AS
(SELECT *,
SUM(NewVal) OVER (ORDER BY id) AS GroupNum
FROM ABCD_with_newvals
)
SELECT GroupNum, Code, MIN(FirstDate) AS FirstDate, MAX(LastDate) AS LastDate
FROM ABCD_grouped
GROUP BY GroupNum, Code
ORDER BY GroupNum;Задание 11
У меня есть текущая таблица со столбцами countx, code и col3. Я хочу получить желаемую таблицу. Чтобы внести ясность, нужно провести группировку на основе столбца кода и суммировать количество строк по столбцу кода.

13 упражнений по SQL с решениями
Вот тестовый код:
CREATE TABLE test(
countx int,
code char(1),
col3 char(3)
);
insert into test values
(2,'A','xyz'),
(3,'A','1'),
(4,'A','f'),
(4,'B','d'),
(5,'B','2'),
(6,'B','yz')Решение
В этом запросе используется оконная функция SUM() с предложением OVER() и предложением PARTITION BY.
Функция SUM() вычисляет сумму всех значений countx в разделе текущей строки. Функция OVER() определяет окно или набор строк в результирующем наборе запроса. Функция PARTITION BY делит строки в результирующем наборе на разделы, к которым применяется SUM().
Оператор SELECT извлекает сумму countx для каждого code в виде countx_sum, столбца code и столбца col3 из тестовой таблицы. Строки упорядочены по столбцу кода.
SELECT SUM(countx) OVER (PARTITION BY code) AS countx_sum, code, col3
FROM test
ORDER BY code;Задание 12
У меня есть текущая таблица со столбцами id, line и cost. Я хочу получить желаемую таблицу, как показано на рисунке ниже. Чтобы было понятно, я хочу удалить последовательные повторяющиеся записи в таблице. В приведённой ниже таблице я хочу рассчитать общую стоимость без последовательного дублирования.
Например, строка 3 должна быть удалена, поскольку она последовательно дублируется строкой 2, ведь данные всех 3 столбцов одинаковы. То же самое относится и ко второй группе, строка 7 должна быть удалена, поскольку она дублирует строку 6. Общая стоимость в конце должна составить 10 долларов.

13 упражнений по SQL с решениями
Вот тестовый код:
DECLARE @vClaims TABLE (
ClaimID NVARCHAR(16),
ClaimLine SMALLINT,
Cost SMALLINT
)
INSERT INTO @vClaims
VALUES
('M0001R1616878951', 2, 10),
('M0001R1616878951', 2, -10),
('M0001R1616878951', 2, -10),
('M0001R1616878951', 3, 10),
('M0001R1616878951', 3, -10),
('M0001R1616878951', 3, 10),
('M0001R1616878951', 3, 10)Решение
Ниже представлено решение:
;WITH CTE_ClaimsWithSort AS (
SELECT
id ,
line,
cost,
RowNumber = ROW_NUMBER() OVER(ORDER BY (SELECT NULL))
FROM @test
), CTE_ClaimsFiltered AS (
SELECT
id ,
line ,
cost ,
RowNumber,
isDuplicate = IIF(
LAG(id) OVER(ORDER BY RowNumber) = id
AND LAG(line) OVER(ORDER BY RowNumber) = line
AND LAG(cost) OVER(ORDER BY RowNumber) = cost
, 1, 0)
FROM CTE_ClaimsWithSort
)
SELECT
id,
line,
cost,
RowNumber,
isDuplicate
FROM CTE_ClaimsFiltered WHERE isDuplicate = 0Задание 13
У меня есть таблица под названием Location. Данные выглядят так, как показано на рисунке ниже. Я хочу разделить элемент данных на основе разделителя:

13 упражнений по SQL с решениями
Вот тестовый код:
create table location( RecordId int, Location varchar(10))
insert into location select 1 , '/21/s15'
insert into location select 2 , '8/1/21c59'
insert into location select 3 , '1//'
insert into location select 4 , '9//72'Решение
create or alter function fnBuildABC@locationn varchar(10))
returns table
as
return
select
Left(location, p1.v - 1) A,
Substring(location, p1.v + 1, p2.v - p1.v - 1) B,
Stuff(location,1, p2.v , '') C
from (select location = @Location)l
cross apply(values(CharIndex('/', location)))p1(v)
cross apply(values(CharIndex('/', location, p1.v + 1)))p2(v);
select A, B, C from Location
cross apply fnBuildABC(Location);Задание 14
Выбрать самую актуальную запись с учетом статуса (успешная / отмененная транзакция) и временной метки

Задачу часто спрашивают на собеседованиях в формулировке «как удалить дубли / копии строк», и решить ее можно несколькими способами. Я привык мыслить в терминах историзации данных в Хранилище, и удаление мне ни к чему, поэтому для решения задачи я воспользуюсь ранжирующей функцией ROWNUMBER().
Решение
with decoded as (
select
"transaction_id"
,"is_successful"
,"ts"
,decode("is_successful", 'true', 0, 'false', 1, 2) as "order_is_successful"
from transactions
),
ordered as (
select
"transaction_id"
,"is_successful"
,"ts"
,row_number() over(partition by "transaction_id" order by "order_is_successful" asc, "ts" desc) as rn
from decoded
)
select
"transaction_id"
,"is_successful"
,"ts"
from ordered
where rn = 1
;
Задача 15
Задача про календарь
Напиши SQL-код, выводящий календарь на текущий месяц в виде:
Пн Вт Ср Чт Пт Сб Вс
| | | | | 1 | 2
3 | 4 | 5 | 6 | 7 | 8 | 9 10 | 11 | 12 | 13 | 14 | 15 | 16 17 | 18 | 19 | 20 | 21 | 22 | 23 24 | 25 | 26 | 27 | 28 | 29 | 30
Решение
with
current_date as (
select trunc(sysdate) as cd from dual
),
t as (
select
cd as today,
trunc(cd, 'MM') as first_day_of_month,
add_months(trunc(cd, 'MM'), 1) - 1 as last_day_of_month,
to_char(trunc(cd, 'MM'), 'IW') as week_of_fdm,
to_char(add_months(trunc(cd, 'MM'), 1) - 1, 'IW') as week_of_ldm
from current_date
),
days_set as (
select
level as lvl,
t.first_day_of_month -7 + level-1 as day,
to_char(t.first_day_of_month -7 + level-1, 'IW') as week_id
from t
connect by (t.first_day_of_month -7 + level-1) < (t.last_day_of_month +7)
),
days_and_week as (
select
days_set.lvl,
case
when days_set.day between t.first_day_of_month and t.last_day_of_month
then lpad(ltrim(to_char(days_set.day, 'DD'), '0'), 2, ' ')
when days_set.day < t.first_day_of_month
then ' '
when days_set.day > t.last_day_of_month
then ' '
else ''
end as dd,
week_id
from days_set, t
where days_set.week_id between t.week_of_fdm and week_of_ldm
)
select
'пн | вт | ср | чт | пт | сб | вс' as calendar
from dual
union all
select
listagg(dd, ' | ') within group(order by lvl)
from days_and_week
group by week_id
;Заключение
Решение упражнений по SQL помогает развить навыки работы с базами данных и анализа данных, что может быть полезно в различных областях, связанных с обработкой и анализом больших объемов информации.
Вот ссылки на источники: link1, link2, link3, Link4, Link5, Link6, Link7, Link8Задание 7
