Splunk Distributed Search. Или как построить Indexer кластер на Splunk?
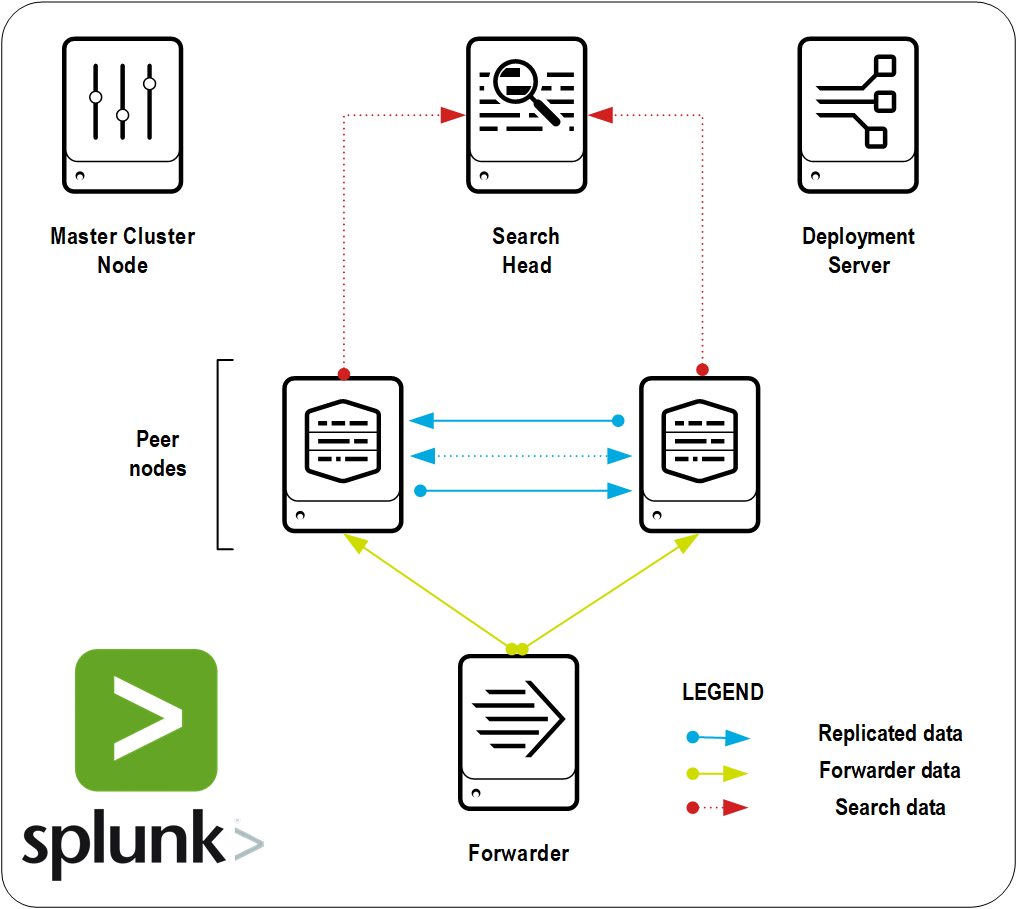
Нам часто задают вопрос, как развернуть кластер на Splunk. У многих пользователей в процессе эксплуатации возникает потребность перехода от standalone к конфигурации кластера, которая обеспечивает устойчивую систему хранения и индексации данных, а также постоянную доступность данных, которая не будет зависеть от сбоев в работе оборудования. И поэтому, в рамках данной статьи мы расскажем, как развернуть Indexer кластер на Splunk, который позволит постоянно иметь доступ ко всем хранящимся данным, даже если упадет один из индексеров.
Задача
Построим кластер, который будет загружать данные, реплицировать их, создавая две копии на индексерах.
Для этого нам необходимо:
Indexers (2)— узлы, на которых будут реплицироваться данные;
Search Head — компонент, который представляет собой графический интерфейс для поиска по данным, хранящимся в индексерах, построения дашбордов, создания алертов и тд;
Cluster Master — главный узел, который координирует действия всех остальных узлов;
Forwarder (s) — компоненты, отвечающие за пересылку данных;
Deployment Server — компонент, отвечающий за рассылку на все форвардеры параметров отправления данных (В нашем случае будет находится вместе с Search Head).
Развертывание кластера
1. Определение требований
Прежде чем разворачивать кластер необходимо определить требования к кластеру:
• Replication factor — количество копий данных.
Необходимо выбрать такой коэффициент, который будет оптимальным с точки зрения увеличения емкости памяти и отказоустойчивостью системы. Увеличение фактора репликации в ходе эксплуатации системы возможно, но приведет к замедлению кластера во время создания дополнительных копий.
В нашем случае Replication factor = 2
• Search factor
Коэффициент поиска сообщает кластеру, сколько копий индексированных данных поддерживается для поиска. Это помогает определить скорость, с которой кластер может восстанавливаться после потери узла. Более высокий коэффициент поиска позволяет кластеру восстанавливаться быстрее, но он также требует большего объема памяти и вычислительной мощности. Search factor должен быть меньше или равен Replication factor. В нашем случае Search factor = 1.
2. Установка Splunk Enterprise
Количество экземпляров как минимум должно равняться Replication factor + 2. В нашем случае это 4 экземпляра. Подробную пошаговую инструкцию по установке можно найти здесь.
2 экземпляра необходимо для индексеров, но можно сделать и больше, чтобы увеличить производительность индексации. А еще 2 экземпляра для Cluster Master и Search Head.
3. Включение кластеризации
Для каждого экземпляра Splunk необходимо определить его роль в кластере.
Создадим Cluster Master:
Settings — Indexer Clustering — Enable Indexer clustering — Master node
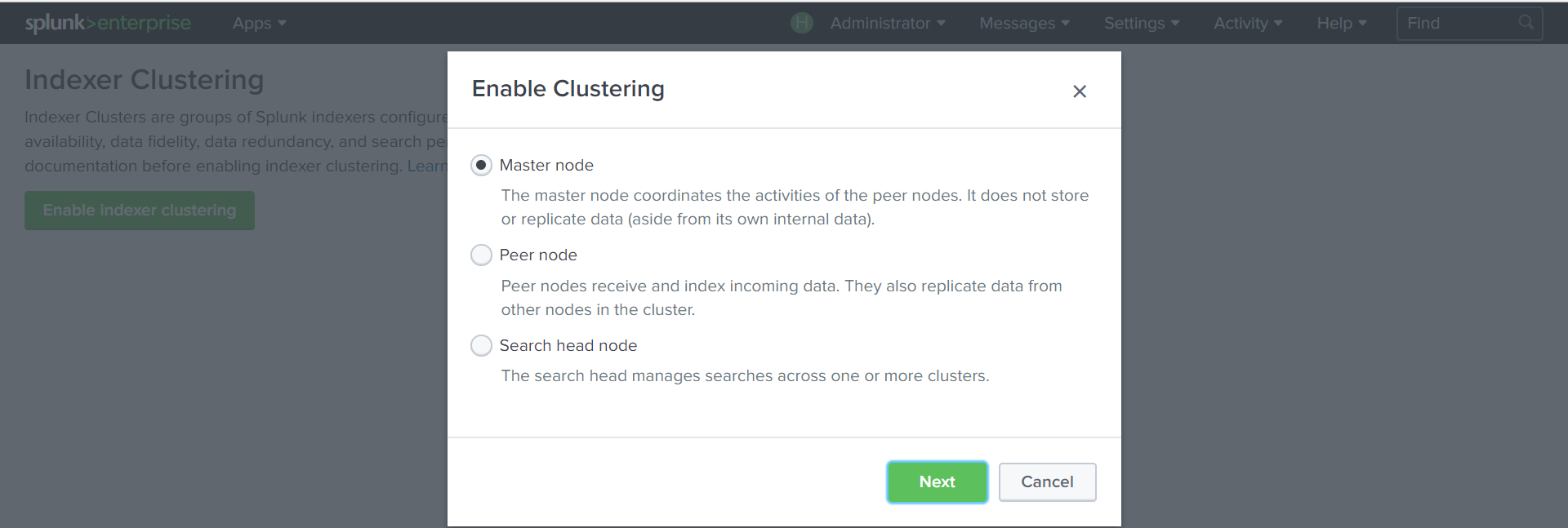
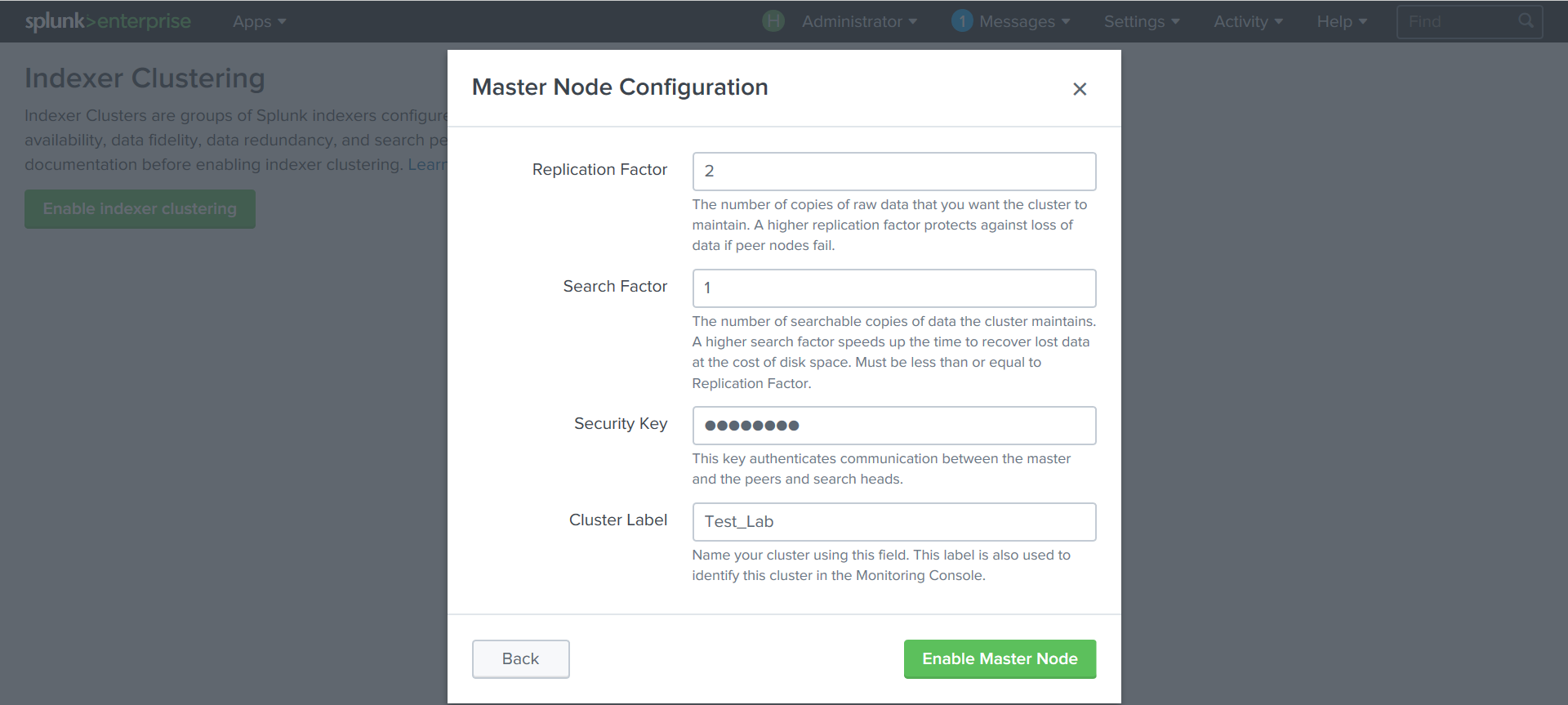
Зададим параметры кластера: коэффициент репликации, поиска, ключ, по которому будут аутентифицироваться узлы кластера.
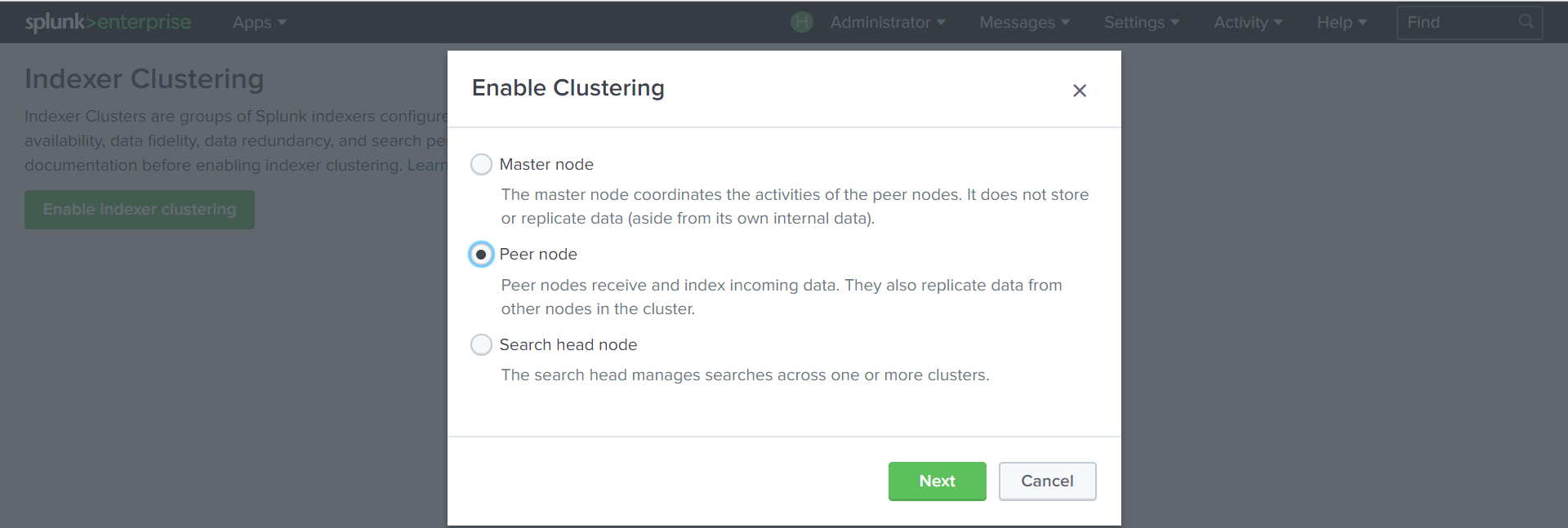
Создадим индексеры:
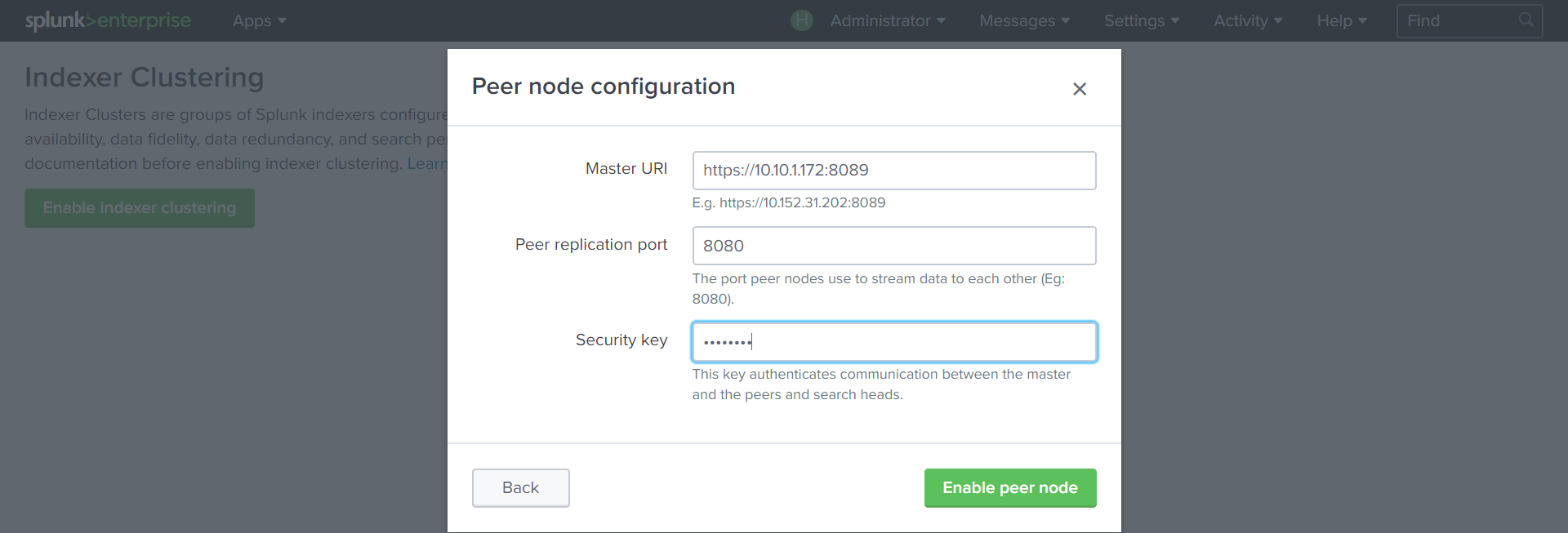
Settings — Indexer Clustering — Enable Indexer clustering –Peer node
Укажем адрес Cluster Master с портом 8089, порт, по которому будут реплицироваться данные (8080) и ключ, который создали на предыдущем шаге.
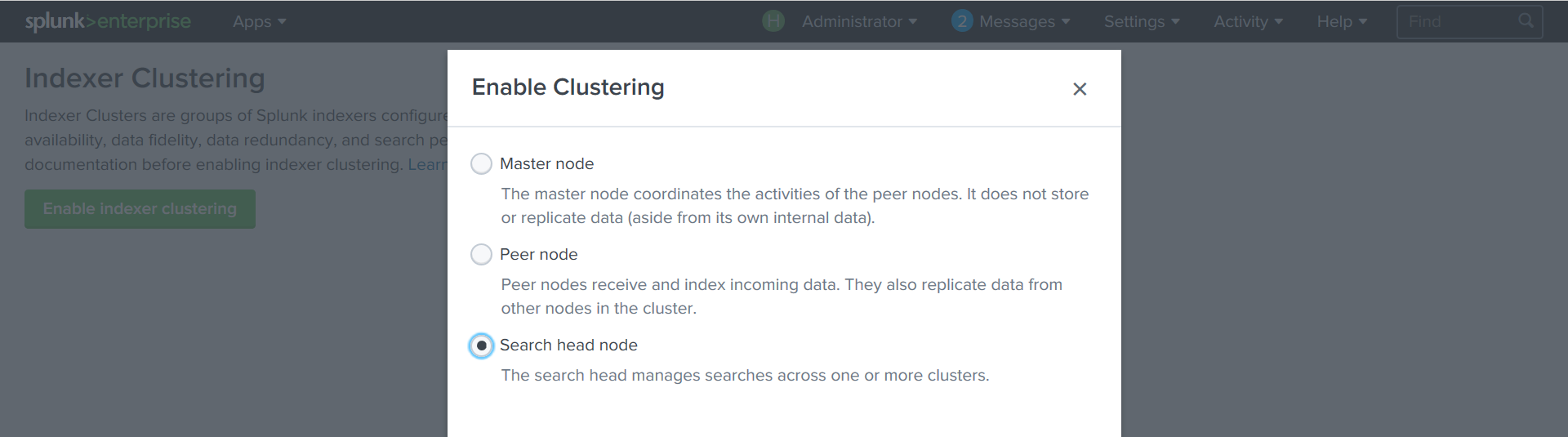
Создадим Search Head:
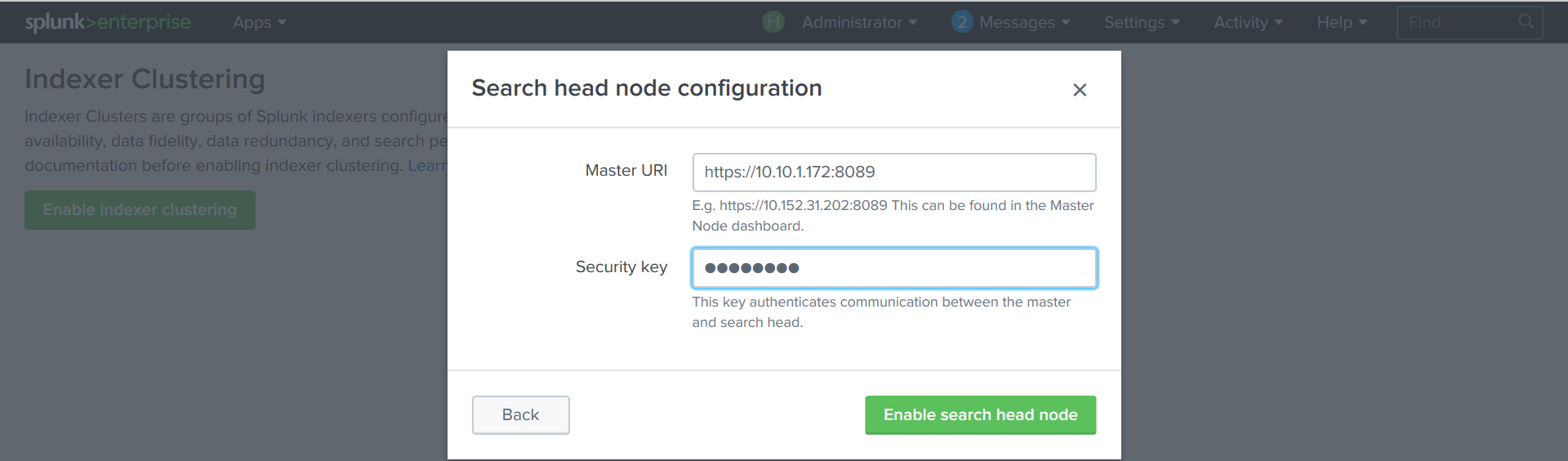
Settings — Indexer Clustering — Enable Indexer clustering — Search Head node.
Укажем адрес Cluster Master с портом 8089 и ключ.
После создания всех компонентов, необходимо перезагрузить Splunk на каждой машине.
4. Cоздание нового индекса
Далее создадим новый индекс test. За создание индексов отвечает Cluster Master, который создает указанные индекс на каждом индексере.
Для этого скопируем файл indexes.conf из …splunk/etc/master-apps/_cluster/default в каталог /opt/splunk/etc/master-apps/_cluster/local
Добавим в файл новый индекс и места хранения его данных:
[test]
repFactor = auto
homePath = $SPLUNK_HOME/var/lib/splunk/testdb/db/
coldPath = $SPLUNK_HOME/var/lib/splunk/testdb/colddb
thawedPath = $SPLUNK_HOME/var/lib/splunk/testdb/thaweddb
После перезагрузки Cluster Master и индексеров, новый индекс, в который мы сможем загружать данные, появится на каждом индексере.
5. Настройка Forwarder и Deployment Server
О том, как настраивать Forwarder и Deployment Server мы писали здесь. Поэтому в данной статье отметим различия в настройке для ситуации работы с кластерами.
В нашем случае мы настраивали Deployment Server на Search Head и указывали его IP-адрес при установке.
Для настройки форвардера на загрузку данных в кластер, необходим другой файл outputs.conf со следующим содержанием:
[tcpout]
defaultGroup=my_LB_peers
[tcpout: my_LB_peers]
autoLBFrequency=40
server=IP_indexer_1:9997, IP_indexer_2:9997
useACK=true
В файле outputs.conf необходимо указать IP адреса индексеров кластера.
После настройки Forwarder и Deployment Server можно загружать данные и выполнять поиски через Search Head. Следует отметить, что на SH в списке индексов не будет индекса test, но поиск по этому индексу осуществляться будет.
Заключение
Таким образом, мы развернули кластер, реплицирующий данные, создали в нем новый индекс и рассказали, как настроить отправку данных в кластер.
Обратите внимание:
Если в процессе развертывания у вас возникли ошибки, то проверьте следующие моменты:
1. Все порты должны быть открыты для файервола (8089, 8080, 9997)
2. Названия машин, используемых в Splunk не должны совпадать. Изменить их можно в каталоге …splunk/etc/system/local/server.conf
[general]
serverName = Indexer1
pass4SymmKey = $1$0rPdsD/7byyP
Если вам интересна эта тема или Splunk в целом, то пишите комментарии, мы будем рады вам ответить. Также в нашем блоге есть множество других статей, которые касаются Splunk и могут помочь вам узнать много интересного про реализованные кейсы, функционал и многое другое. Подписывайтесь в нашу группу VK и канал Telegram, если хотите быть в курсе новых статей. Также можете написать нам запрос через форму на нашем сайте.
Мы являемся официальным Premier Партнером Splunk.

