New Adventures in Responsive Web Design
Предлагаем вашему вниманию подборку всевозможных лайфхаков и трюков по оптимизации объема загружаемого кода и файлов, а также общего ускорения загрузки веб-страниц.
В основе статьи расшифровка выступления Виталия Фридмана из Smashing Magazine на декабрьской конференции Holy JS 2017 Moscow.
Чтобы нам с вами не было скучно, я решил подать эту историю в формате небольшой игры, назвав ее Responsive Adventures.

В игре будет пять уровней, и начнем мы с простого уровня — компрессии.
Уровень 1 — Компрессия

Компрессия — это сжатие, а сжимать во frontend можно, например, изображения, текст, шрифты и так далее. Если имеется необходимость максимально оптимизировать страницу в плане текста, то на практике обычно используют библиотеку для сжатия данных gzip. Чаще всего применяют наиболее распространенную реализацию gzip — zlib, которая использует комбинацию алгоритмов кодирования LZ77 и Huffman.
Обычно нас интересует, как сильно библиотека должна сжимать, ведь чем лучше она это делает, тем больше времени занимает данный процесс. Обычно мы выбираем либо быстрое сжатие, либо хорошее, так как одновременно быстрого и хорошего сжатия добиться невозможно. Но как разработчики мы заботимся о двух аспектах: размере файлов и скорости компрессии/декомпрессии — для статического и динамического веб-контента.
Существуют алгоритмы сжатия данных Brotli и Zopfli. Zopfli можно рассматривать как более эффективный, но при этом более медленный вариант gzip. Brotli — это новый формат сжатия и декомпрессии без потерь.

В будущем мы сможем использовать Brotli. Но сейчас не все браузеры его поддерживают, а нам необходима полная поддержка.
Brotli и Zopfli
- Brotli значительно медленнее при сжатии данных в сравнении с gzip, но обеспечивает гораздо лучшую компрессию.
- Brotli — это формат сжатия без потерь с открытым исходным кодом.
- Декомпрессия у Brotli быстрая — сопоставима с zlib.
- Brotli дает преимущество при работе с большими файлами при медленных соединениях.
- Brotli сжимает эффективнее на 14–39%.
- Идеально подходит для HTML, CSS, JavaScript, SVG и всего текстового.
- Поддержка Brotli ограничена соединениями HTTPS.
- Zopfli часто используется для сжатия на лету, но при этом является хорошей альтернативой для однократного сжатия статического содержимого.


Стратегия сжатия Brotli/Zopfli
Стратегия выглядит следующим образом:
- Предварительно сжимать статические ресурсы с помощью Brotli + Gzip.
- Сжимать при помощи Brotli HTML на лету с уровнем сжатия 1–4.
- Проверить поддержку Brotli на CDN (KeyCDN, CDN77, Fastly).
- Использовать Zopfli, если нет возможности установить/поддерживать Brotli на сервере.
Уровень 2 — изображения

А вот что мы будем делать с изображениями?
Давайте представим, у вас есть хороший landing page со шрифтами и изображениями. Необходимо, чтобы страница загружалась очень быстро. И мы говорим об экстремальном уровне оптимизации изображений. Это проблема, и она не надуманная. Мы предпочитаем о ней не говорить, ведь в отличие от JS изображения не блокируют рендеринг страницы. На самом деле это большая проблема, ведь размер изображений со временем увеличивается. Сейчас в ходу уже 4K-экраны, скоро будет 8K.

В целом 90% пользователей видят на странице 5,4 МБ изображений — это очень много. Эта проблема, которая требует решения.
Конкретизируем проблему. Что если у вас есть большая картинка с прозрачной тенью, как на примере ниже.

Как ее сжать? Ведь png достаточно тяжела, а после компрессии тень будет выглядеть не очень хорошо. Какой формат выбрать? JPEG? Тень так же будет выглядеть недостаточно хорошо. Что можно сделать?

Один из самых лучших вариантов — разделить изображения на две составляющие. Основу изображения поместить в jpeg, а тень в png. Далее соединить две картинки в svg.

Почему это хорошо? Потому что изображение, которое весило 1,5 МБ, теперь занимает 270 КБ. Это большая разница.
Но есть еще пара трюков. Вот один из них.
Возьмем два изображения, которые визуально отображаются на веб-сайте с одинаковыми пропорциями.

Первое — с очень плохим качеством, имеет реальный и визуальный размер 600×400 px, а ниже оно же, но визуально уменьшенное до 300×200 px.

Давайте сравним это изображение с изображением, которое имеет реальный размер 300×200 px, но сохранено с качеством 80%.

Большинство пользователей не в состоянии различить эти изображения, но картинка слева весит 21 КБ, а справа — 7 КБ.
Есть две проблемы:
- тот, кто решит сохранить картинку, сохранит ее в плохом качстве
- браузеру придется увеличивать или уменьшать изображения
Интересный тест, в котором использовался этот прием, провел шведский онлайн-журнал Aftonbladet. Изначальная настройка качества изображений была установлена в 30%.
В итоге их главная страница с 40 изображениями с применением данной техники заняла 450 КБ. Впечатляет!
Вот еще хорошая техника.
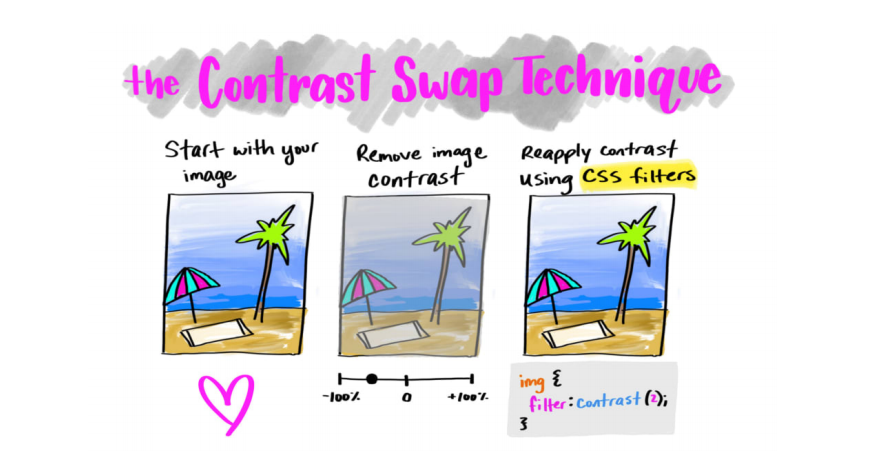
У нас есть картинка, и нам нужно уменьшить ее размер. За счет чего она будет лучше сжиматься? Контраст! Что если его убрать или уменьшить значительно, а потом вернуть при помощи CSS-фильтров? Но опять таки, тот, кто захочет скачать эту картинку, столкнется с плохим качеством.
Этим приемом можно добиться больших результатов. Вот несколько примеров: 



Все бы хорошо, но как же дополнительные задержки рендеринга? Ведь браузеру приходится применять фильтры к изображению. Но тут все достаточно позитивно: 27 мс против 23 мс без применения фильтров — разница несущественная.
Фильтры поддерживаются везде, кроме IE.

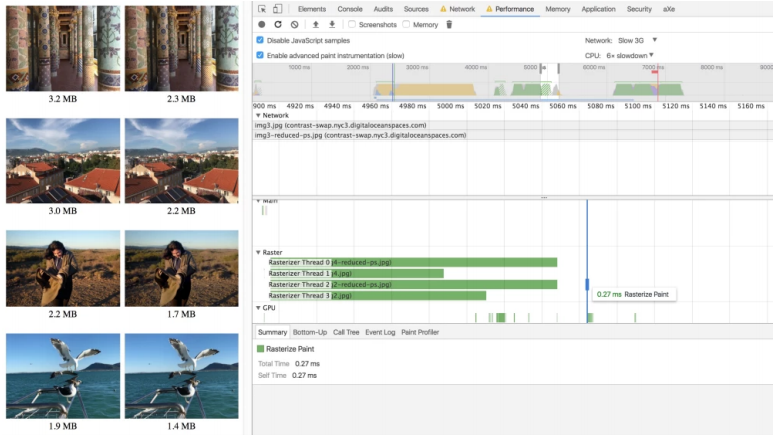
Какие еще есть приемы? Сравните два фото:


Разница — это размытие несущественных деталей фотографии, которое позволяет уменьшить размер до 147 КБ. Но этого недостаточно! Пойдем в кодирование JPEG. Предположим, у вас есть последовательный и прогрессивный JPEG.

Последовательный JPEG грузится на странице построчно, прогрессивный — сначала в плохом качестве сразу целиком, а затем качество постепенно улучшается.
Если посмотреть, как работают кодировщики, то можно увидеть несколько уровней сканирования.

Множество разных уровней сканирования находятся в этом файле. Наша цель, как разработчиков, показать сразу детальную информацию об этой картинке. Тогда можно позаботиться о том, чтобы Ships Fast и Shows Soon были с какими-то коэффициентами, которые могут подходить картинке лучше, и тогда уже на первом уровне мы увидим структуру, а не просто нечто размытое. А на втором — практически все.


Существуют библиотеки и утилиты, которые позволяют делать такие трюки: Adept, mozjpeg или Guetzli.
Уровень 3

Помню, семь-десять лет назад — захотел шрифты, добавил font-face и готово. А сейчас нет, необходимо думать, что я хочу сделать и как необходимо загружать. Итак, какой оптимальный метод выбрать для загрузки шрифтов?

Мы можем использовать синтаксис font-face, чтобы избежать общих ловушек на этом пути:

Если мы хотим поддерживать лишь более менее нормальные браузеры, то можно написать еще короче:
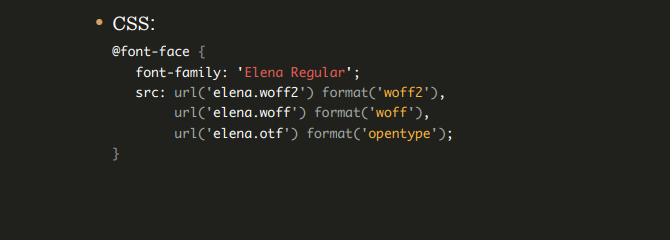
Что происходит, когда у нас есть этот font-face в css? Браузеры смотрят, есть ли в body или где-то еще указание на шрифт, и если есть, тогда браузер начинает его загружать. И нам приходится ждать.
Если шрифты еще не кэшированы, они будут запрашиваться, загружаться и применяться, отодвигая рендеринг.

Но разные браузеры действуют по-разному. Есть подходы отображения FOUT и FOIT.

FOIT (Flash of Invisible Text) — ничего не отображается, пока шрифты не загрузятся.
FOUT (Flash Unstyled Text) — контент отображается сразу с дефолтными шрифтами, а потом загружаются нужные шрифты.
Обычно браузеры ждут загрузки шрифтов три секунды, и если они не успели подгрузиться, то подставляются дефолтные шрифты. Есть браузеры, которые не ждут. Но самое неприятное, что есть браузеры, которые ждут до упора. Так не пойдет! Есть множество различных вариантов, как это обойти. Один из них — CSS Font Loading API. Создаем новый font-face в JS. Если шрифты загружаются, то навешиваем их в соответствующие места. Если не загружаются, навешиваем стандартные.
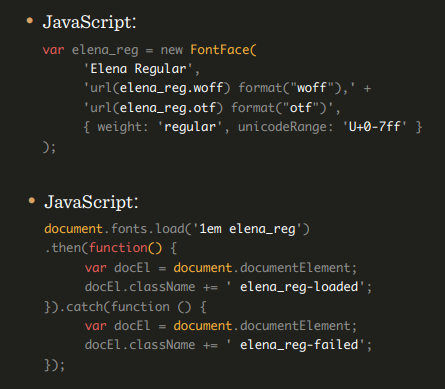
Также мы можем использовать новые свойства в CSS, например, font-rendering, который позволяет нам эмулировать либо FOIT, либо FOUT, но на самом деле они нам даже не нужны, потому что есть Font Rendering Optional.

Существует еще один способ — критический FOFT с Data URI. Вместо загрузки через JavaScript API веб-шрифт внедряется непосредственно в разметку как встроенный Data URI.
Двухступенчатый рендеринг: сначала римский шрифт, а потом остальные:
- Загрузка полных шрифтов со всеми весами и стилями
- Минимальное подмножество шрифтов (A-Z, 0–9, пунктуация)
- Используйте sessionStorage для обратных посещений
- Загрузите подстрочный шрифт (Roman) в первую очередь
Данный метод заблокирует первоначальное отображение, но поскольку мы встраиваем лишь малое подмножество простого шрифта, это малая цена для того, чтобы устранить FOUT. При этом данный метод имеет самую быструю стратегию загрузки шрифтов на сегодняшний день.
Я подумал, что можно сделать еще лучше. Вместо использования sessionStorage мы встраиваем веб-шрифт в разметку и используем Service Workers.
Например, у нас есть какой-то шрифт, но он весь нам не нужен. И мы делаем не то, чтобы subsetting, а именно выбираем, что для данной страницы нужно. Например, берем italic, уменьшаем его, сначала подгружаем его, отображаем на странице, и он будет выглядеть как normal, bold будет как normal, все будет как normal. Потом подгружается все как нужно. Далее делаем subsetting и отправляем это в Service Workers.
Потом, когда пользователь приходит на страницу первый раз, проверяем наличие шрифта, если его нет, то отображаем сразу текст, асинхронно загружаем этот шрифт и добавляем в Service Workers, если коротко. Когда пользователь заходит второй раз шрифт по идеи должен быть уже в Service Workers. Далее проверяем есть ли он и если есть, то сразу берем его оттуда, а если нет, то все эти действия происходят заново.
Здесь существует проблема с кэшированием. Какова вероятность того, что кто-то приходит на ваш сайт и у него все файлы, которые должны быть в кеше, присутствуют в нем?

Изображение выше демонстрирует результаты исследования 2007 года, где говорится о том, что 40–60% пользователей имеют пустой кэш, и 20% всех просмотров страниц происходят с пустым кэшем. Почему так? Потому что браузеры не умеют кэшировать? Нет, просто мы посещаем большое количество сайтов и если бы все кэшировалось, то накопитель ПК или смартфона заполнился бы очень быстро.
Браузеры удаляют из кэша то, что считают уже не нужным.

Давайте посмотрим на примере Chrome, что происходит в нем, когда мы пытаемся открыть какую-либо страницу в Сети. Если посмотреть на строку fonts, видно, что шрифты оказываются в memory cache или HTTP cache в лучшем случае в 70% случаев. На самом деле это неприятные цифры. Если шрифты загружаются каждый раз заново, каждый раз пользователь приходит на сайт и наблюдает смену стиля шрифтов. С точки зрения UX не очень хорошо.
Необходимо заботиться о том, чтобы шрифты действительно оставались в кэше. Раньше мы полагались на local storage, а сейчас более разумно полагаться на Service Workers. Потому что если я положил что-то в Service Workers, то оно там и будет.
Что еще можно сделать? Можно использовать unicode-range. Многие думают, что происходит динамический subsetting, то есть у нас есть шрифт, он динамически разбирается, и подгружается только указанная часть в unicode-range. На самом деле это не так, и загружается весь шрифт.

Действительно, это полезно, когда у нас есть unicode-range, например, для кириллицы и для английского текста. Вместо того, чтобы загружать шрифт, который имеет английский и русский тексты, можем разбить его на несколько частей и подгружать русский, если у нас есть на странице русский текст, и тоже самое делать с английским.
Что можно еще сделать? Есть классная вещь, которую необходимо использовать всегда и везде — preload.

Preload дает возможность загружать ресурсы в начале загрузки страницы, что в свою очередь позволяет с меньшей вероятностью блокировать рендеринг страницы. Данный подход повышает производительность.
Мы также можем использовать font-display: optional. Это новое свойство в css. Как оно работает?

У font-display есть несколько значений. Давайте начнем с block. Данное свойство устанавливает блокировку шрифта на три секунды, в течение которых шрифт подгружается, потом происходит замена шрифта и далее непосредственно его отображение.
Свойство swap работает почти так же, но за некоторым исключением. Браузер сразу отрисовывает текст запасным шрифтом, а когда загрузится указанный, то произойдет замена.

Fallback устанавливает маленький период блокировки в 100 мс, период замены будет равен 3 с, после чего произойдет замена шрифта. Если за это время шрифт не подгрузился, то браузер отрисует текст с запасным шрифтом.
И наконец мы подошли к optional. Период блокировки равен 100 мс, если за это время шрифт не подгрузился, то текст отображается сразу. Если у вас медленное соединение, то браузер может перестать загружать шрифт. Когда шрифт загрузится, то все равно вы будете видеть дефолтный шрифт. Чтобы увидеть прописанный шрифт, необходимо перезагрузить страницу.
Уровень 4

Существует множество техник, которые мы использовали до появления http/2, например, конкатенация, спрайты и т.д. Но с появлением http/2 необходимость их использования отпала, потому что в отличии от http/1.1, в новой версии грузится почти все сразу, и это здорово, потому что можно использовать множество дополнительных возможностей.
В теории переход на http/2 обещает нам на 64% (на 23% на мобильных) более быструю загрузку страниц. Но на практике все работает медленнее.
Если большая часть вашей целевой аудитории постоянно заходит на ресурс, находясь в автобусе, машине и т.д., то вполне возможно, что http/1.1 окажется в более выгодном положении.
Посмотрите на результаты тестов ниже. По ним видно, что в некоторых ситуациях http/1.1 оказывается быстрее.
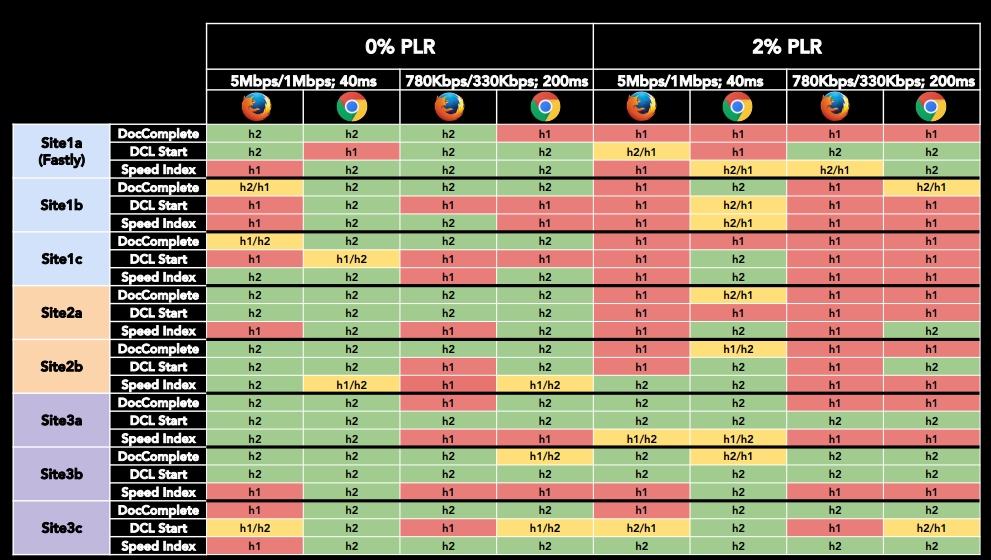
Есть замечательные фичи у http/2, например, HPACK, которую нужно использовать всегда и везде, а еще — server push. Но есть небольшая проблема. Возникает она в зависимости от браузера и сервера. Допустим, загружаем страницу, у нас нет никакого server push.

Если происходит повторная загрузка страницы, то все находится в кэше.

А вот если мы сделаем server push, то наши css дойдут до пользователя гораздо быстрее.

Но также это значит, что даже если css в кэше, они все равно будут пересылаться.

То есть если вы пушите много файлов от сервера, они будут подгружаться много раз.
Идем дальше. Есть некоторые рекомендуемые рамки по времени загрузки страниц. Например, для средненького аппарата на android оно составляет пять секунд. Это не так много, если учитывать, что у нас, например, 3G.

Если посмотреть на рекомендуемое ограничение размера загружаемых файлов, необходимое для начала рендеринга, которое упоминает Google, то оно составляет 170 КБ.

Поэтому, когда речь заходит о фреймворках, то нам нужно думать о парсинге, компиляции, качестве сети, стоимости времени выполнения и т.д.
Существуют различные возможности загружать файлы, например, классический способ, который немного устарел — scout. Мы заводим файл scout.js, он находится в html, мы его подгружаем. Его задача — сделать остальное окружение максимально кэшируемым и при этом своевременно сообщать об изменениях в нем.

Это значит, что этому файлу необходимо малое время для хранения в кэше, и если что-то меняется в окружении, тогда scout сразу инициирует обновление. Это действенный способ, потому как нам каждый раз не нужно подгружать и подменять html.
А что делать с http/2? Ведь мы знаем, что можем посылать сколько угодно файлов и нет необходимости объединять их в пакеты. Давайте тогда грузить по 140 модулей, почему нет? На самом деле это очень плохая идея. Во-первых, если у нас есть множество файлов, и мы не используем библиотеку, например gzip для компрессии, то файлы будут большего размера. Во-вторых, браузеры еще не оптимизированы для таких рабочих процессов. В итоге мы начали экспериментировать и искать подходящее количество, и оказалось, что оптимально отправлять примерно 10 пакетов.
Пакеты лучше комплектовать, опираясь на частоту обновлений файлов: часто обновляемые в одних пакетах, а редко обновляемые в других, чтобы избежать лишних загрузок. Например, библиотеки паковать вместе с утилитами и т.д. Ничего особенного. А что же делать с css, как загружать его? Server push тут не подойдет.
В начале мы все загружали как минимизированные файлы, потом подумали, что часть необходимо загружать в критический css, ибо у нас всего 14 КБ, и их необходимо загрузить как можно быстрее. Начали делать loadCSS, писать логику, потом добавили display: none.

Но выглядело это все как-то плохо. В http/2, подумали, что необходимо все файлы разбивать, минифицировать и грузить. Оказалось, что самым лучшим вариантом был вариант, на изображении ниже.

Необычно! Данный вариант работает хорошо в Chrome, плохо в IE, в Firefox работа немного замедлялась, так как они поменяли рендеринг. Таким образом мы улучшили скорость работы на 120 мс.
Если посмотреть на работу с прогрессивным css и без. То с прогрессивным css все подгружается быстрее, но по частям, а вот без его использования медленнее, т.к. css располагается в header и блокирует страницу как js.
Уровень 5

И последний уровень, о котором я не могу не рассказать — Resource Hints. Это замечательная функция, которая позволяет делать множество полезных вещей. Пройдемся по некоторым из них.
Prefetch
Prefetch — указывает браузеру, что тот или иной файл нам скоро потребуется, и браузер грузит его с низким приоритетом.

Prerender
Prerender — данной функции уже нет, но она помогала раньше делать пререндер страницы. Возможно, у нее появится альтернатива…

Dns-prefetch
Dns-prefetch также ускоряет процесс загрузки страниц. Использование dns-prefetch предполагает, что браузер заранее подгружает адрес сервера указанного доменного имени.

Preconnect
Preconnect позволяет делать предварительный хэндшейк с указанными серверами.

Preload
Preload — указывает браузеру, какие ресурсы необходимо предварительно загрузить с высоким приоритетом. Preload можно использовать для скриптов и шрифтов.

Помню в 2009 году прочитал статью «Gmail for Mobile HTML5 Series: Reducing Startup Latency», и она поменяла мои взгляды на классические правила. Посмотрите сами! У нас есть JS-код, но ведь он нам весь сейчас не нужен. Так почему нам большую часть JS-кода не закомментировать, а потом, когда нужно, раскомментировать и выполнить в eval?

И причина, по которой они так сделали, кроется в том, что у среднего смартфона время парсинга в 8–9 раз больше, чем у последнего iPhone.
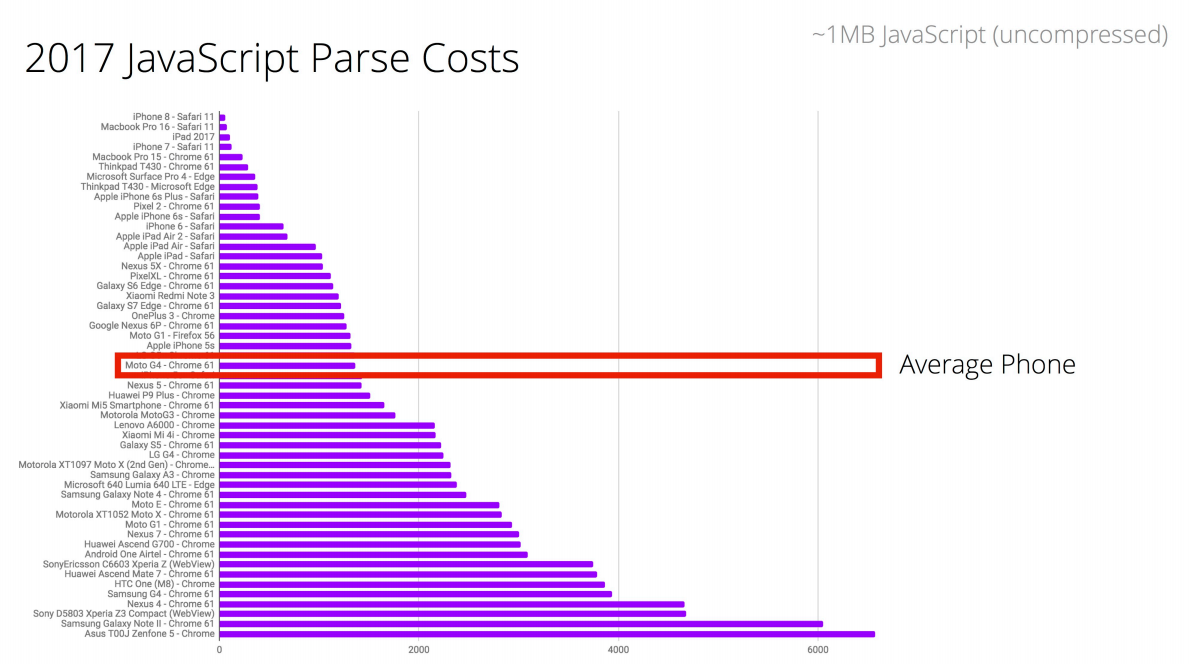
Давайте обратимся к статистике. Чтобы сделать парсинг 1 МБ кода на среднем телефоне, нужно 4 с.

Это очень много! Но нам не нужен 1 МБ сразу. Если опять обратиться к статистике, выяснится, что сайты используют всего лишь 40% JS-кода из того, что они загрузили.

И мы можем использовать preload взамен eval для таких же ситуаций.
var preload = document.createElement("link");
link.href= "myscript.js" ;
link.rel= "preload";
link.as= "script";
document.head.appendChild(link);
То есть мы храним файл в кэше, а потом, когда нужно, мы добавляем его на страницу.
Итак, это лишь половина того, чем планировал поделиться Виталий Фридман. Остальные фишки и лайфхаки будут в расшифровке его второго выступления на Holy JS 2017 Moscow, которую мы также подготовим и выложим в нашем блоге.
И если вы любите изнанку JS так же, как и мы, наверняка вам будут интересны вот эти доклады на нашей майской конференции HolyJS 2018 Piter, ключевым из которых мы опять поставили рассказ Виталия Фридмана:
