Современные типы архитектуры данных: Погружение в различные подходы к построению хранилищ данных
В эпоху цифровизации бизнеса, когда каждый клик и каждая транзакция превращаются в данные, важность их архитектуры становится ключевой для успеха компании. Современные архитектуры данных — это не просто хранилища, это сложные системы, обеспечивающие быстрый доступ, безопасность и возможность анализа огромных объемов информации.
Архитектура данных — это скелет любой информационной системы. Она определяет, как данные собираются, хранятся, обрабатываются и передаются. История архитектур данных начинается с простых файловых систем и доходит до современных облачных и распределенных решений. Этот эволюционный путь привел к появлению различных подходов к архитектуре хранилищ данных, каждый из которых обладает своими уникальными особенностями и преимуществами. Наиболее знаковыми в этом контексте являются классические подходы, разработанные Уильямом Инмоном и Ральфом Кимбаллом.
Типы архитектуры хранилища данных
Классические типы: Инмона и КимбаллаАрхитектура Инмона (3NF) ориентирована на создание единого, интегрированного хранилища данных, в то время как архитектура Кимбалла (звезда, dimensional modelling) фокусируется на построении многомерных моделей для аналитики. Кроме того, важное место занимает так называемый Modern stack, или архитектура больших данных, предлагающая гибкие и масштабируемые решения.
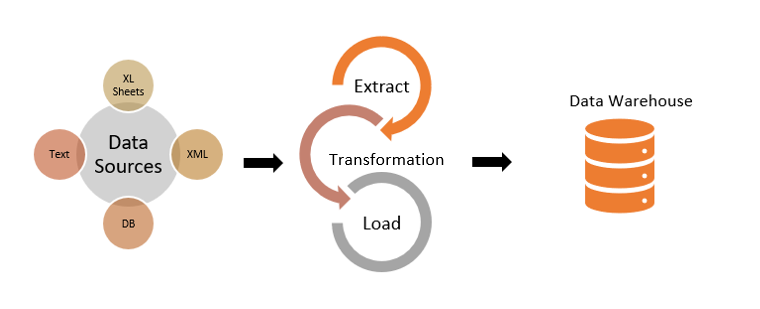
модель Инмона для хранения данных
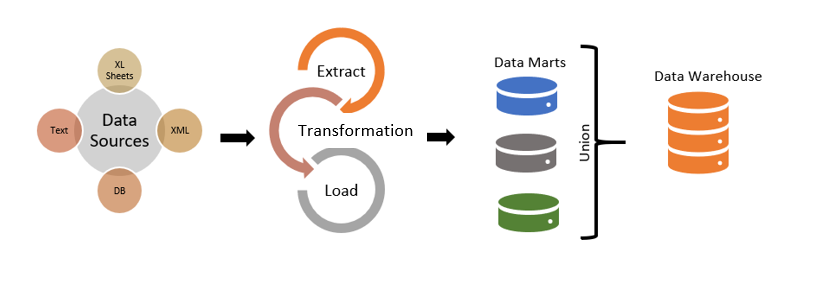
модель Кимбалла для хранения данных
Хранилища данных могут включать несколько слоев, обычно до трех (staging area, operational data store, детальный слой, презентационный слой), хотя в некоторых случаях их может быть больше.
Например, могут присутствовать следующие слои: stg lake, lake, stg ods, ods, stg dds, dds, stg cdm, cdm, а также специализированный слой для машинного обучения. Это предоставляет широкие возможности для организации и анализа данных в различных сценариях использования.

Примеры трехуровневой архитектуры данных
Лямбда и Каппа архитектуры
В контексте современных архитектур данных, Лямбда и Каппа архитектуры выделяются своей спецификой. Они представляют собой подходы к построению ETL (Extract, Transform, Load) pipelines, что является ключевым элементом в обработке данных.
Лямбда-архитектура: Адаптация к динамике рынка
Лямбда-архитектура представляет собой service-based подход, способный быстро адаптироваться к изменениям рынка и обеспечивать релевантность предложений. Эта архитектура становится особенно актуальной, когда речь идет о таких задачах, как рассылка персонализированных предложений о скидках, где необходимо учитывать как исторические данные клиентов, так и их текущее местоположение.
Компоненты Лямбда-архитектуры:
Пакетный уровень (Batch Layer) — «холодный путь»: Здесь данные хранятся в исходном виде и обрабатываются с задержкой. Этот уровень содержит «сырые» данные, включая нормативно-справочную информацию, изменяющуюся редко. Используя методы машинного обучения, на пакетном уровне проводится анализ исторических данных для сегментации клиентов и создания прогнозных моделей.
Скоростной уровень (Speed Layer) — «горячий путь»: Этот уровень обеспечивает анализ данных в реальном времени с минимальной задержкой. Он использует фреймворки потоковой обработки данных, такие как Apache Spark, Storm или Flink, для обработки информации с коротким жизненным циклом. В этом слое делаются некоторые компромиссы в точности в пользу скорости.
Сервисный уровень (Serving Layer): Сервисный уровень предоставляет интерфейс для объединения данных из пакетного и скоростного уровней. Он позволяет пользователям получить доступ к консолидированным, актуализированным данным для аналитических целей.
Лямбда-архитектура представляет собой гибкий подход, позволяющий быстро адаптироваться к изменениям и обеспечивать релевантность предложений, что критично в условиях динамичного рыночного окружения.
Применение λ-архитектуры в практике Big Data
Лямбда-архитектура обеспечивает обработку больших объемов данных с минимальной задержкой, выделяясь своей отказоустойчивостью и возможностью масштабирования. Это достигается за счет сочетания пакетной обработки и скоростного анализа, позволяя интегрировать новые данные, сохраняя при этом целостность и доступность исторической информации. Такие качества делают лямбда-архитектуру востребованной в реальных Big Data проектах, что подтверждается ее использованием ведущими компаниями, такими как Twitter, Netflix и Yahoo.
Ключевые сценарии использования λ-архитектуры включают:
Одноразовую обработку запросов с применением неизменяемых хранилищ данных.
Быструю отдачу ответов и интеграцию новых потоков данных.
Необходимость сохранения исторических данных без удаления с возможностью добавления обновлений.
Каппа-архитектура в Big Data: Упрощение и Эффективность
Каппа-архитектура представляет собой стройную модель обработки данных, где все данные рассматриваются как последовательный поток событий. Эти события систематически упорядочиваются в надежном журнале событий, где каждое новое событие обновляет текущее состояние. В отличие от лямбда-архитектуры, Каппа исключает пакетный уровень обработки, сосредотачиваясь на потоковой обработке в реальном времени и сохранении данных в виде непрерывно обновляемого представления.
Каппа-архитектура упрощает проектирование систем Big Data, удаляя необходимость в пакетной обработке и полагаясь на неизменяемый журнал событий, который служит основой для всех операций. Этот подход позволяет системам потоковых вычислений обрабатывать данные непосредственно из журнала, при необходимости дополняя их информацией из вспомогательных хранилищ.
Технологии, используемые в Каппа-архитектуре, включают:
Системы постоянного логирования событий, такие как Apache Kafka и Amazon Kinesis.
Фреймворки для потоковых вычислений, включая Apache Spark и Flink.
Разнообразные базы данных на сервисном уровне, от резидентных до специализированных решений для полнотекстового поиска.
Применение K-архитектуры и роль Apache Kafka
K-архитектура находит свое применение в сценариях, где:
Необходимо управление очередью событий и запросов в распределенной файловой системе.
Порядок событий не фиксирован, и потоковые фреймворки могут взаимодействовать с данными в любой момент.
Высокая доступность и устойчивость критичны, так как обработка данных происходит на каждом узле системы.
Apache Kafka, как мощный брокер сообщений, поддерживает эти требования, предоставляя быструю, надежную и масштабируемую платформу для сбора и агрегации данных. Это делает Каппа-архитектуру на базе Kafka идеальной для проектов, подобных LinkedIn, где необходимо обрабатывать и хранить большие объемы данных для обслуживания множественных идентичных запросов.
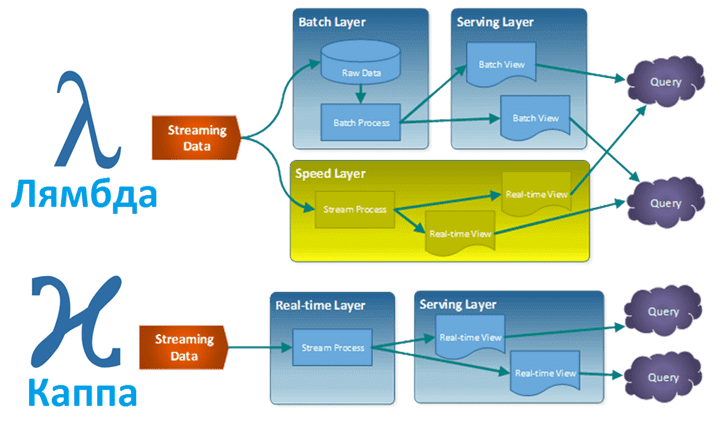
Отличие Лямбды и Каппы архитектуры
Заключение: cинтез популярных архитектур данных
Изучение различных архитектур данных, от лямбда и каппа-архитектур до микросервисов, открывает перед нами мир возможностей для управления и анализа информации. Эти подходы представляют собой фундамент, на котором строятся мощные и гибкие системы обработки данных, способные преобразовать бизнес-процессы и принятие решений.
Однако, освоение этих технологий требует не только времени и усилий, но и специализированных знаний. В этом контексте, выбор правильного партнера или платформы для реализации и поддержки вашей архитектуры данных может стать решающим фактором успеха.
