Соединяй и властвуй. Нестандартный взгляд на keep-alive
 Большинство современных серверов поддерживает соединения keep-alive. Если на страницах много медиаконтента, то такое соединение поможет существенно ускорить их загрузку. Но мы попробуем использовать keep-alive для куда менее очевидных задач.
Большинство современных серверов поддерживает соединения keep-alive. Если на страницах много медиаконтента, то такое соединение поможет существенно ускорить их загрузку. Но мы попробуем использовать keep-alive для куда менее очевидных задач.
How it worksПрежде чем переходить к нестандартным способам применения, расскажу, как работает keep-alive. Процесс на самом деле прост донельзя — вместо одного запроса в соединении посылается несколько, а от сервера приходит несколько ответов. Плюсы очевидны: тратится меньше времени на установку соединения, меньше нагрузка на CPU и память. Количество запросов в одном соединении, как правило, ограничено настройками сервера (в большинстве случаев их не менее нескольких десятков). Схема установки соединения универсальна:1. В случае с протоколом HTTP/1.0 первый запрос должен содержать заголовок **Connection: keep-alive**.Если используется HTTP/1.1, то такого заголовка может не быть вовсе, но некоторые серверы будут автоматически закрывать соединения, не объявленные постоянными. Также, к примеру, может помешать заголовок **Expect: 100-continue**. Так что рекомендуется принудительно добавлять keep-alive к каждому запросу — это поможет избежать ошибок.
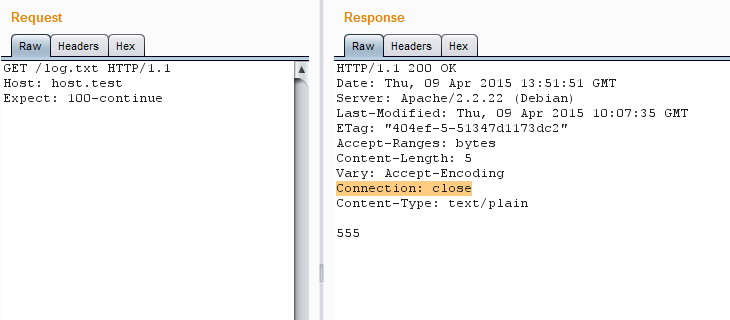 Expect принудительно закрывает соединение
Expect принудительно закрывает соединение
2. Когда указано соединение keep-alive, сервер будет искать конец первого запроса. Если в запросе не содержится данных, то концом считается удвоенный CRLF (это управляющие символы \r\n, но зачастую срабатывает просто два \n). Запрос считается пустым, если у него нет заголовков Content-Length, Transfer-Encoding, а также в том случае, если у этих заголовков нулевое или некорректное содержание. Если они есть и имеют корректное значение, то конец запроса — это последний байт контента объявленной длины.
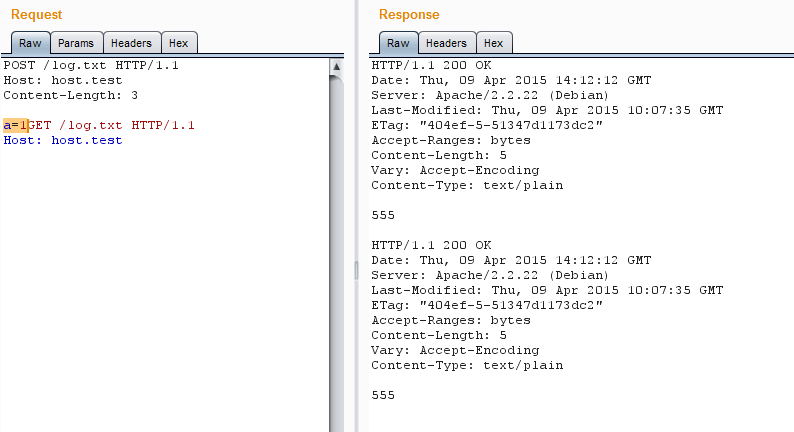 За последним байтом объявленного контента может сразу идти следующий запрос
За последним байтом объявленного контента может сразу идти следующий запрос
3. Если после первого запроса присутствуют дополнительные данные, то для них повторяются соответствующие шаги 1 и 2, и так до тех пор, пока не закончатся правильно сформированные запросы.
Иногда даже после корректного завершения запроса схема keep-alive не отрабатывает из-за неопределенных магических особенностей сервера и сценария, к которому обращен запрос. В таком случае может помочь принудительная инициализация соединения путем передачи в первом запросе HEAD.
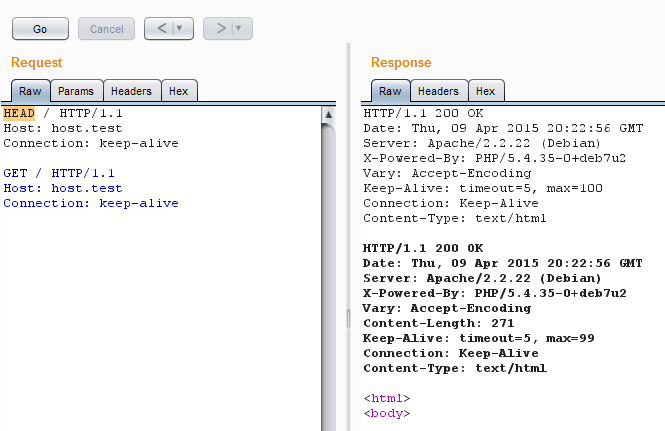 Запрос HEAD запускает последовательность keep-alive
Запрос HEAD запускает последовательность keep-alive
Тридцать по одному или один по тридцать? Как бы забавно это ни звучало, но первый и самый очевидный профит — это возможность ускориться при некоторых видах сканирования веб-приложений. Разберем простой пример: нам нужно проверить определенный XSS-вектор в приложении, состоящем из десяти сценариев. Каждый сценарий принимает по три параметра.Я накодил небольшой скрипт на Python, который пробежится по всем страницам и проверит все параметры по одному, а после выведет уязвимые сценарии или параметры (сделаем четыре уязвимые точки) и время, затраченное на сканирование.
import socket, time, re print (»\n\nScan is started…\n»)
s_time = time.time ()
for pg_n in range (0,10): for prm_n in range (0,3): s = socket.socket (socket.AF_INET, socket.SOCK_STREAM) s.connect ((«host.test», 80)) req = «GET /page»+str (pg_n)+».php? param»+str (prm_n)+»= HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n»
s.send (req) res = s.recv (64000) pattern = » HTTP/1.1\r\nHost: host.test\r\nConnection: keep-alive\r\n\r\n»
req += «HEAD /page0.php HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n»
s.send (req)
# Timeout for correct keep-alive
time.sleep (0.15)
res = s.recv (640000000)
pattern = »